文章目錄
- 1 概述
- 2 Yolo系列模型
- 2.1 基石 - Yolov1
- 2.1.1 Yolov1的網路結構
- 2.1.2 Yolov1的feature map
- 2.1.3 Yolov1的訓練
- 2.1.4 Yolov1的預測
- 2.1.5 Yolov1小結
- 2.2 Yolo9000 - Yolov2
- 2.2.1 Better
- 2.2.1.1 引入了Batch normalization
- 2.2.1.2 高解析度的分類器
- 2.2.1.3 加入了anchor機制
- 2.2.1.4 loss的改動
- 2.2.1.5 Fine-Grained Features
- 2.2.1.6 多尺度訓練
- 2.2.2 Faster
- 2.2.3 Stronger
- 2.3 一小步 - Yolov3
- 2.4 技巧 - Yolov4
- 2.4.1 網路結構的改進
- 2.4.1.1 backbone中的激活函式改為Mish
- 2.4.1.2 backbone中的殘差模塊改成了CSP
- 2.4.1.3 detector中的新增了SPP模塊
- 2.4.1.4 detector中特征尺度的變化
- 2.4.2 損失函式的改進
- 2.4.3 nms的改進
- 2.4.4 其他
- 2.5 又一小步 - Yolov5
- 2.5.1 網路結構的改進
- 2.5.1.1 添加了CSP2模塊
- 2.5.2 其他
- 3 結束語
- 參考資料
1 概述
Yolo系列的模型是大多數做目標檢測的影像演算法工程師都在使用的,使用時經常也是先用了看看效果再說,如果效果不錯,有時間再回頭來研究一下模型,有時甚至就忘了回過頭來細究,這篇文章就是一個回頭的產物,
Yolo的每一個系列都令人驚艷,本文綜合了原始論文和網上各家的一些說法,把Yolo每個系列究竟產出了一些什么做一個系統的梳理,也方便我以后的再回頭,
如果Yolo之后有人繼續更新下去,本文也會盡量做到繼續更新,
文中的圖片都出自參考資料,非本人原創,
2 Yolo系列模型
2.1 基石 - Yolov1
Yolov1是目標檢測中one-stage方法的開山之作,它不同于two-stage需要先過一個RPN網路得到候選區域的方法,yolo直接在整張圖的feature map上進行目標的定位和分類,因此速度也比當時正紅的Fast R-CNN快很多,而且,也正是因為yolo看的是全域的資訊,yolo把背景誤判成目標的錯誤率比只看proposals的Fast R-CNN低很多,不過整體的準確率,還是Fast R-CNN高,
2.1.1 Yolov1的網路結構
Yolov1的網路結構如下圖所示,并不復雜,輸入是
448
×
448
×
3
448\times448\times3
448×448×3的圖片,輸出是一個
7
×
7
×
30
7\times7\times30
7×7×30的feature map,網路中共有24個全卷積和尾部的2個全連接,其中用到了大量的
1
×
1
1\times1
1×1卷積用來改變通道數,當然也有融合通道之間特征的作用,這里最后用的兩層全連接其實今天看來有點不解,后面的版本就沒有用了,這個網路結構就是大名鼎鼎的Darknet,
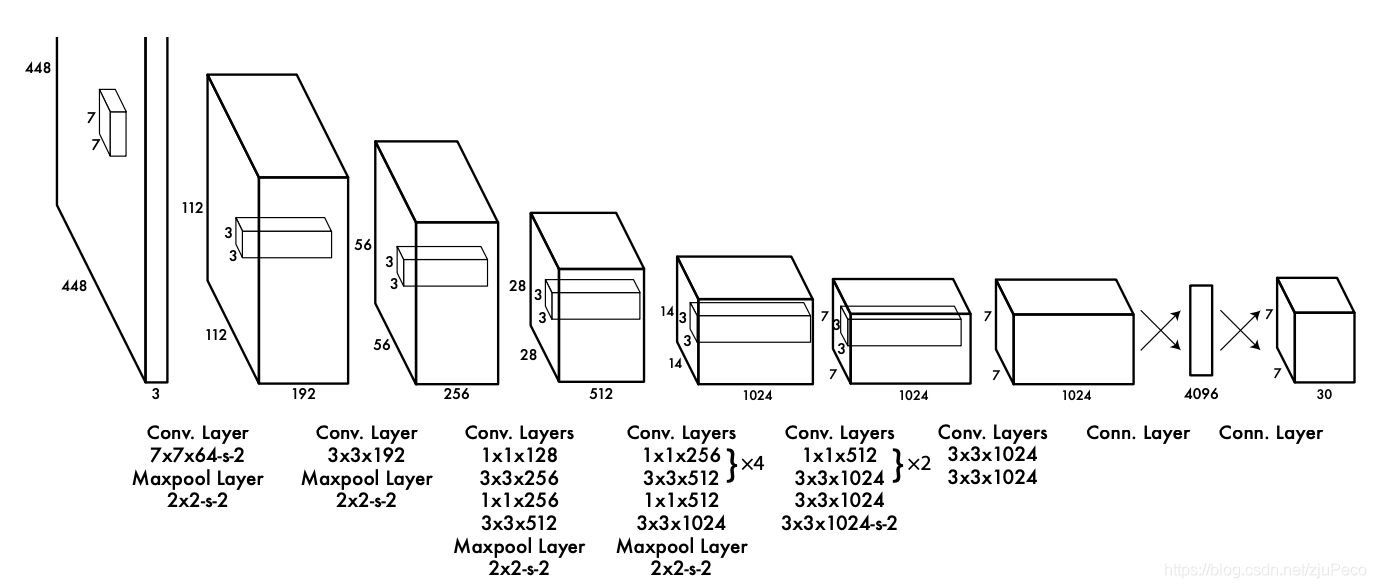
網路的卷積層在ImageNet上用分類任務進行了預訓練,使得卷積層可以抽到比較好的影像特征,但是預訓練時的輸入影像為 224 × 224 224\times224 224×224的,這其實會有點問題,在訓練檢測模型時,輸入為 448 × 448 448\times448 448×448,模型需要去適應這種解析度的轉換,對結果是有影響的,這個在之后的版本會優化,
2.1.2 Yolov1的feature map
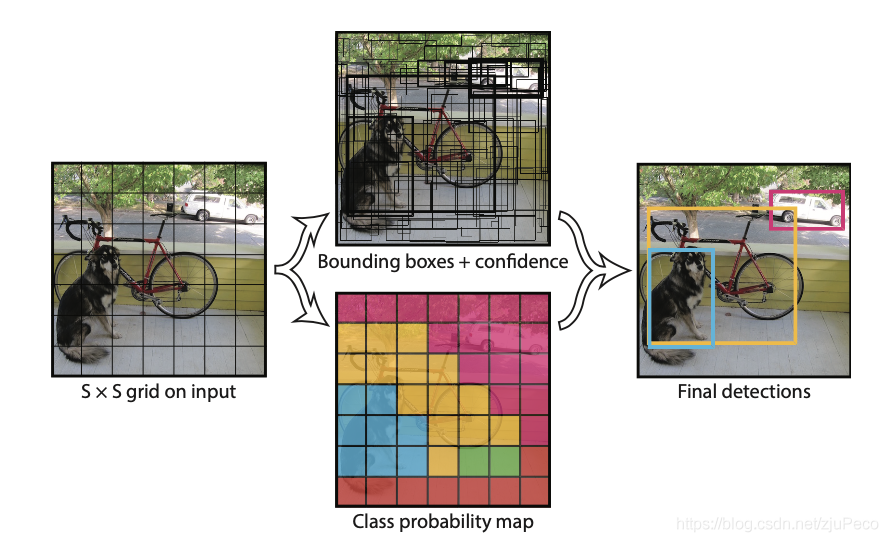
我們再來看下Yolov1輸出的 7 × 7 × 30 7\times7\times30 7×7×30的feature map,其中 7 × 7 7\times7 7×7是經過層層全卷積和全連接之后下采樣得到的結果,每個grid對應著原圖上相應位置的一塊區域,可以理解為將 448 × 448 448\times448 448×448的輸入長寬都等分為了7份,共有49個grids,
每個grid都對應了一個長度為30的向量,準確來說應該是一個 2 × 5 + 20 2\times5+20 2×5+20的向量,其中2表示2個預測框;5表示每個預測框的 [ x c e n t e r , y c e n t e r , w , h , c o n f i d e n c e ] [x_{center}, y_{center}, w, h, confidence] [xcenter?,ycenter?,w,h,confidence], c o n f i d e n c e confidence confidence指的是這個預測框內目標的置信度 P r ( O b j e c t ) × I O U p r e d t r u t h Pr(Object) \times IOU_{pred}^{truth} Pr(Object)×IOUpredtruth?,當沒有物體時, P r ( O b j e c t ) = 0 Pr(Object)=0 Pr(Object)=0, c o n f i d e n c e = 0 confidence=0 confidence=0,當有物體時, c o n f i d e n c e = I O U p r e d t r u t h confidence=IOU_{pred}^{truth} confidence=IOUpredtruth?;20表示20種目標類別的置信度,表示為 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi?∣Object),
在預測時,最終某個框內表示了某個目標的置信度為
c
o
n
f
i
d
e
n
c
e
×
P
r
(
C
l
a
s
s
i
∣
O
b
j
e
c
t
)
confidence \times Pr(Class_i|Object)
confidence×Pr(Classi?∣Object),
寫一個一目了然版的就是某個grid的30維向量為
[
x
c
1
,
y
c
1
,
w
1
,
h
1
,
c
o
n
f
i
d
e
n
c
e
1
,
x
c
2
,
y
c
2
,
w
2
,
h
2
,
c
o
n
f
i
d
e
n
c
e
2
,
c
a
t
e
1
,
.
.
.
,
c
a
t
e
20
]
[x_{c1}, y_{c1}, w_1, h_1, confidence_1, x_{c2}, y_{c2}, w_2, h_2, confidence_2, cate_1, ..., cate_{20}]
[xc1?,yc1?,w1?,h1?,confidence1?,xc2?,yc2?,w2?,h2?,confidence2?,cate1?,...,cate20?]
如果要知道某個grid第一個框表示 c a t e 1 cate_1 cate1?這個目標的概率,則為 c o n f i d e n c e 1 × c a t e 1 confidence_1 \times cate_1 confidence1?×cate1?,
仔細一想,會發現每個grid只能表示一個物體, c o n f i d e n c e i confidence_i confidencei?代表了有沒有物體和用哪個預測框, c a t e i cate_i catei?表示了這個物體是哪個目標類別,也就是 7 × 7 7\times7 7×7的feature map最多只能預測出49個目標,這對小目標和相鄰多目標很不友好,
2.1.3 Yolov1的訓練
訓練部分只講和loss相關的內容,其他的和Yolo本身關系不大,都是標準的pipeline,
訓練時,我們的label是每張圖片多個檢測框坐標和對應的物體類別,每個物體都會落在 7 × 7 7\times7 7×7的feature map中的某一個格子里,落到哪個格子里,那么那個格子里就負責預測這個物體,而每個格子又有兩個框,就取其中和真實物體的bbox的iou較大的那個預測框作為負責這個物體的預測框,這里負責的意思就是算loss的時候拿負責的框去算loss,
loss共由五個部分組成:
(1)中心定位誤差
就是負責這個物體的檢測框的中心點坐標和這個物體真實的中心點坐標差多少,
L 1 = ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( ( x i ? x ^ i ) 2 + ( y i ? y ^ i ) 2 ) (2-1) L_1 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} ((x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2)\tag{2-1} L1?=i=0∑S2?j=0∑B?Iijobj?((xi??x^i?)2+(yi??y^?i?)2)(2-1)
其中, S 2 S^2 S2表示 7 × 7 7\times7 7×7的feature map的格子的集合; B B B表示每個格子中bbox的集合; I i j o b j \mathbb{I}_{ij}^{obj} Iijobj?是一個指示函式,表示第 i i i個格子的第 j j j個框負責預測真實物體時進行后面的計算,否則為0; x i x_i xi?和 y i y_i yi?是ground truth的中心點坐標; x ^ i \hat{x}_i x^i?和 y ^ i \hat{y}_i y^?i?是負責這個物體的預測框的中心坐標,
(2)寬高誤差
就是負責這個物體的檢測框的寬高和這個物體真實的寬高差多少,
L 2 = ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( ( w i ? w ^ i ) 2 + ( h i ? h ^ i ) 2 ) (2-2) L_2 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} ((\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2)\tag{2-2} L2?=i=0∑S2?j=0∑B?Iijobj?((wi? ??w^i? ?)2+(hi? ??h^i? ?)2)(2-2)
其中, w i w_i wi?和 h i h_i hi?是ground truth的寬高; w ^ i \hat{w}_i w^i?和 h ^ i \hat{h}_i h^i?是負責這個物體的預測框的寬高,其他符號和 L 1 L_1 L1?中相同,
(3)正樣本confidence誤差
保證負責物體的預測框的confidence接近1,
L 3 = ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( C i ? C ^ i ) 2 (2-3) L_3 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{obj} (C_i - \hat{C}_i)^2\tag{2-3} L3?=i=0∑S2?j=0∑B?Iijobj?(Ci??C^i?)2(2-3)
其中, C i C_i Ci?表示這個格子內有物體中心的標簽, C ^ i \hat{C}_i C^i?表示這個格子內有物體中心的置信度,
(4)負樣本confidence誤差
保證不負責物體的預測框的confidence接近0,
L 4 = ∑ i = 0 S 2 ∑ j = 0 B I i j n o o b j ( C i ? C ^ i ) 2 (2-4) L_4 = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{I}_{ij}^{noobj} (C_i - \hat{C}_i)^2\tag{2-4} L4?=i=0∑S2?j=0∑B?Iijnoobj?(Ci??C^i?)2(2-4)
其中, I i j n o o b j \mathbb{I}_{ij}^{noobj} Iijnoobj?是一個指示函式,表示第 i i i個格子的第 j j j個框不負責預測真實物體時進行后面的計算,否則為0,
(5)類別誤差
表示負責預測的格子內的類別誤差,
L 5 = ∑ i = 0 S 2 I i o b j ∑ c ∈ c l a s s e s ( p i ( c ) ? p ^ i ( c ) ) 2 (2-5) L_5 = \sum_{i=0}^{S^2} \mathbb{I}_{i}^{obj} \sum_{c \in classes}(p_i(c) - \hat{p}_i(c))^2\tag{2-5} L5?=i=0∑S2?Iiobj?c∈classes∑?(pi?(c)?p^?i?(c))2(2-5)
其中, I i o b j \mathbb{I}_{i}^{obj} Iiobj?是一個指示函式,表示第 i i i個格子的負責預測真實物體時進行后面的計算,否則為0; p i ( c ) p_i(c) pi?(c)表示第 i i i個格子第 c c c個類別的標簽; p ^ i ( c ) \hat{p}_i(c) p^?i?(c)表示第 i i i個格子第 c c c個類別的置信度,
綜合, ( 2 ? 1 ) ? ( 2 ? 5 ) (2-1)-(2-5) (2?1)?(2?5)就有
L = λ c o o r d L 1 + λ c o o r d L 2 + L 3 + λ n o o b j L 4 + L 5 (2-6) L = \lambda_{coord}L_1 + \lambda_{coord}L_2 + L_3 + \lambda_{noobj}L_4 + L_5 \tag{2-6} L=λcoord?L1?+λcoord?L2?+L3?+λnoobj?L4?+L5?(2-6)
其中, λ c o o r d \lambda_{coord} λcoord?和 λ n o o b j \lambda_{noobj} λnoobj?是可以用來調整的超引數,也就是各個loss的權重,不難看出Yolov1把目標檢測看成了一個回歸問題,
2.1.4 Yolov1的預測
預測部分沒啥說的,就是對得到的98個預測框進行一個閾值的篩選之后,再做nms,
2.1.5 Yolov1小結
優點:
(1)速度快
(2)考慮圖片的全域特征,precision較高
缺點:
(1)每個格子只能預測一個物體,對密集型的物體檢測不友好
(2)下采樣次數多,最終所使用的特征比較粗糙
2.2 Yolo9000 - Yolov2
Yolov2在Yolov1的基礎上有很大的改動,這一節就針對改進部分依次說明,
2.2.1 Better
2.2.1.1 引入了Batch normalization
BN是一個非常有用的模塊,其有點如下:
- 加快收斂
- 改善梯度,遠離飽和區
- 允許大的學習率
- 對初始化不敏感
- 相當于正則化,使得有BN層的輸入都有相近的分布
有了BN之后,就可以不用dropout了,或者說不能像原來一樣用dropout了,這會導致訓練和測驗的方差偏移,可以參看文獻[5],
2.2.1.2 高解析度的分類器
Yolov1當中對backbone做預訓練的時候,用的是 224 × 224 224\times224 224×224的輸入,而yolov1為了高解析度用的是 448 × 448 448\times448 448×448的輸入,這樣就導致了模型要去適應這個解析度的轉換,于是,Yolov2干脆直接用 448 × 448 448\times448 448×448的輸入預訓練backbone了,這樣帶來了幾乎4%mAP的提升,這種簡單而高效且不用增加預測負擔的方法是我們最喜歡的,
2.2.1.3 加入了anchor機制
在Yolov1中沒有anchor的概念,所以 7 × 7 7\times7 7×7的feature map中預測的兩個預測框都是野蠻生長的,這兩個預測框很有可能就長的差不多,而且這樣去學習不同形狀的物體,對模型來說是比較困難的,
所以,Yolov2刪去了最后的全連接層,引入了anchor機制,Yolov2的輸入變成了 416 × 416 416 \times 416 416×416,feature map大小為 13 × 13 13\times13 13×13,每個格子有5個anchors,每個anchor的長寬大小和比例不同,各司其職,負責不同形狀的物體,有了anchor之后,模型就不需要直接去預測物體框的長寬了,只需要預測偏移量就可以了,這相對來說降低了難度,
這里提一句,之所以從 448 × 448 448 \times 448 448×448變成 416 × 416 416 \times 416 416×416就是為的使得feature map的size是一個奇數,這樣的好處是,許多圖片的中心點都是某個物體的中心,奇數保證中間是一個格子,而不是偶數那樣四個格子搶占中心點,
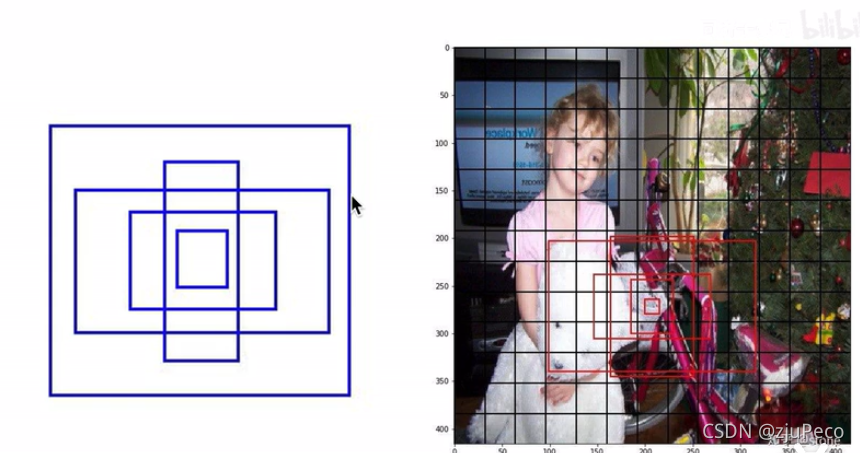
不過引入anchor也有不好的地方,本來不用anchor的時候,預測出來只有98個框,現在有845個框了,從最終結果來看,precision略有下降了,不過recall變高了許多,
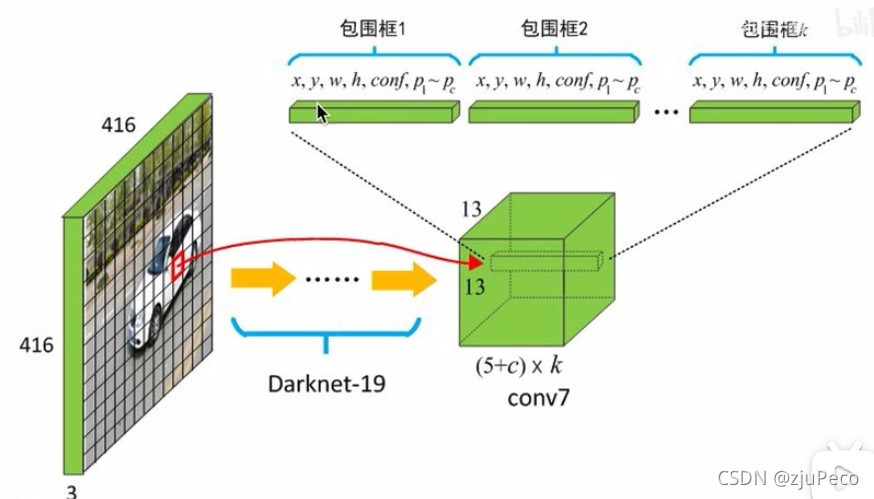
Yolov1的輸出是一個 7 × 7 × 30 7 \times 7 \times 30 7×7×30的,Yolov2的輸出是一個 13 × 13 × 125 13 \times 13 \times 125 13×13×125,其中 125 = ( 5 + 20 ) × 5 125 = (5 + 20) \times 5 125=(5+20)×5,括號里的 5 5 5表示 x i , y i , w i , h i , c o n f i x_i,y_i,w_i,h_i,conf_i xi?,yi?,wi?,hi?,confi?, 20 20 20表示每個類別的概率,共20個類別,最后的 5 5 5表示 5 5 5個預測框,圖4表示的非常清楚了,
可以看出,同一個格子里的每個預測框的類別是可以不同的,一個格子可以預測5個物體了,
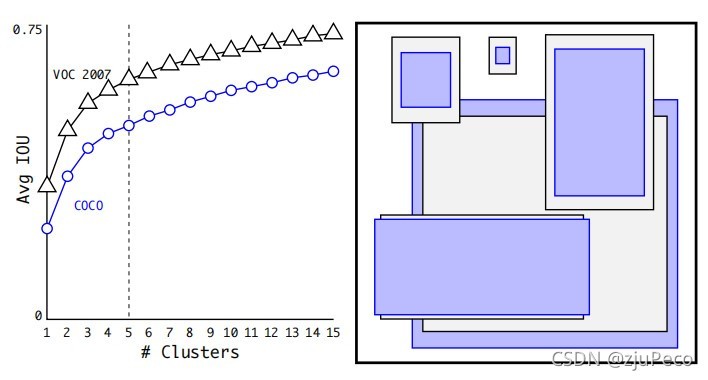
那么這5個anchor的預錨框是怎么確定的呢?甚至為什么是5個呢?根據論文中所述,anchor的形狀是在VOC 2007和COCO資料集上聚類得到的,聚類的類別個數從1到15都試過,最終在效果和性能的權衡之下選擇了5個類聚出來的錨框形狀,示意圖如上圖5所示,
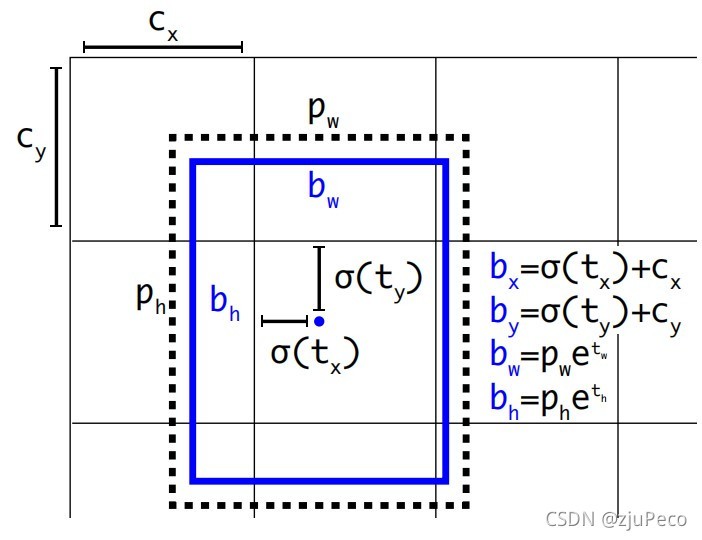
說了半天,模型究竟是怎么計算offset的呢?如上圖6所示,yolov2的anchor編碼在二階段的檢測模型的基礎上做了改進,圖6中 c x c_x cx?和 c y c_y cy?是每個格子的左上角坐標, t x t_x tx?和 t y t_y ty?是模型預測錨框中心點坐標時的輸出引數,加了 σ \sigma σ就把中心點的偏移量限定在了這個格子里,這樣不管模型怎么預測,中心點都飛不出這個格子, p w p_w pw?和 p h p_h ph?是預錨框的初始寬高, t w t_w tw?和 t h t_h th?是模型預測錨框寬高的輸出引數,這里就沒有限制最終錨框的形狀, b x b_x bx?, b y b_y by?, b w b_w bw?, b h b_h bh?是最終的預測框的中心點坐標和寬高,我把圖中的公式抄一份下來就是 ( 2 ? 7 ) (2-7) (2?7),
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h (2-7) \begin{aligned} b_x &= \sigma (t_x) + c_x \\ b_y &= \sigma (t_y) + c_y \\ b_w &= p_w e^{t_w} \\ b_h &= p_h e^{t_h} \\ \end{aligned} \tag{2-7} bx?by?bw?bh??=σ(tx?)+cx?=σ(ty?)+cy?=pw?etw?=ph?eth??(2-7)
除此之外,還有一個東西叫做 t o t_o to?, t o t_o to?是用來給出有物體的置信度的,
P r ( o b j e c t ) I O U ( b , o b j e c t ) = σ ( t o ) (2-8) P_r(object)IOU(b, object) = \sigma(t_o) \tag{2-8} Pr?(object)IOU(b,object)=σ(to?)(2-8)
2.2.1.4 loss的改動
Yolov2的loss我直接拿子豪兄做的圖了,這個也是網友們根據原始碼整理出來的,論文中并沒有說這件事,
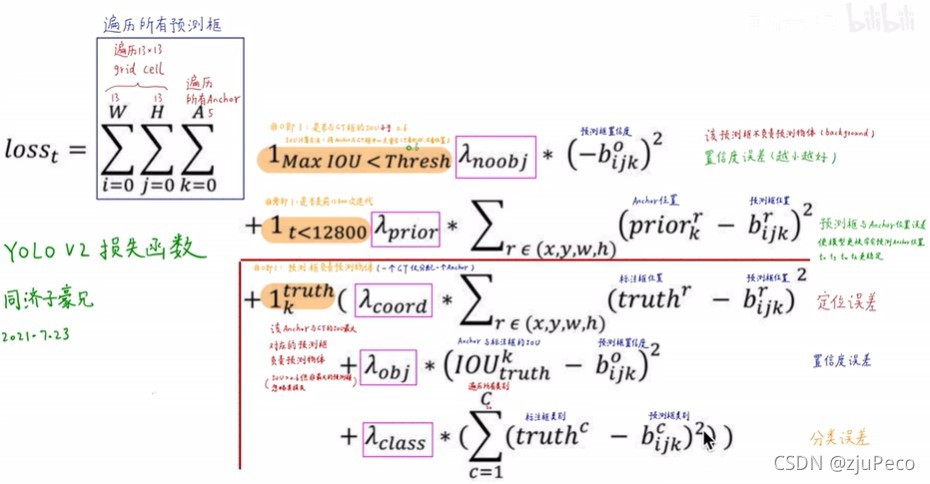
前面的三個求和就是指的下面的所有操作都是對每個格子每個預測框分別做的; I M a x I O U < T h r e s h \mathbb{I}_{MaxIOU<Thresh} IMaxIOU<Thresh?表示845個框分別和所有的ground truth求IOU,如果最大的IOU也小于閾值Thresh的話,就認為這個框是背景,其輸出的置信度 b i j k o b_{ijk}^o bijko?要越小越好; I t < 12800 \mathbb{I}_{t<12800} It<12800?表示前12800次迭代,也就是模型訓練的早期時候,這里讓模型的預測錨框接近預錨框,有點先重置一下的意思,不讓初始的錨框太橫七豎八; I k t r u t h \mathbb{I}_k^{truth} Iktruth?表示對負責預測ground truth的錨框進行的loss計算,所有的Loss也都是回歸運算,
2.2.1.5 Fine-Grained Features
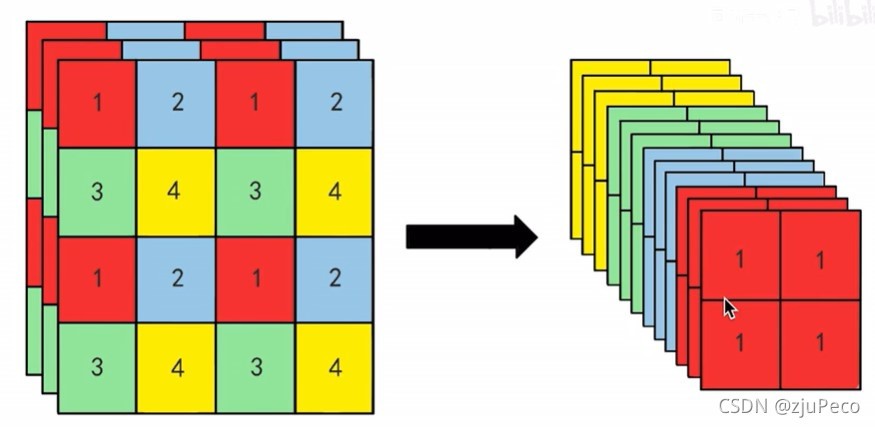
增加了細粒度的特征,方法就是把淺層的
26
×
26
×
512
26 \times 26 \times 512
26×26×512這層的輸出分成四份之后concat到原來的特征上,
26
×
26
×
512
26 \times 26 \times 512
26×26×512分成四份并concat就變成了
13
×
13
×
2048
13 \times 13 \times 2048
13×13×2048,這個和
13
×
13
×
1024
13 \times 13 \times 1024
13×13×1024的特征concat到一起變成了
13
×
13
×
3072
13 \times 13 \times 3072
13×13×3072,
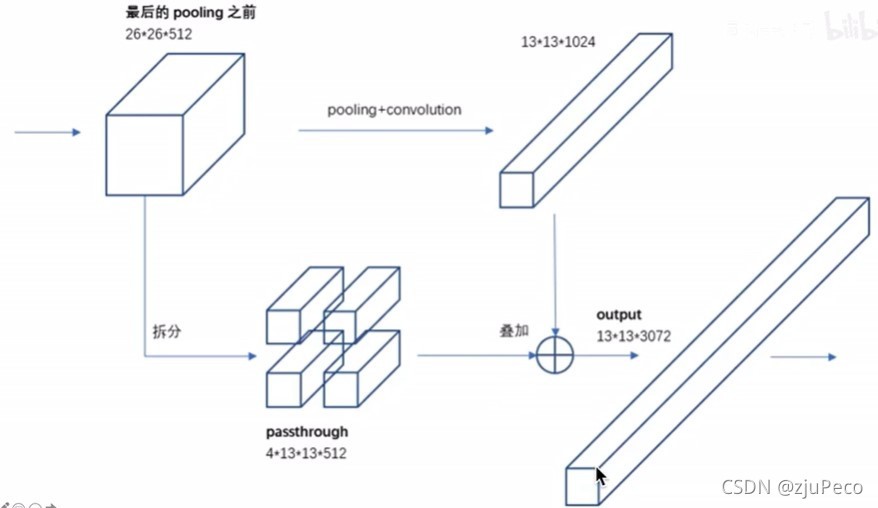
四分的方式有點空洞卷積的意思,如下圖9所示,
2.2.1.6 多尺度訓練
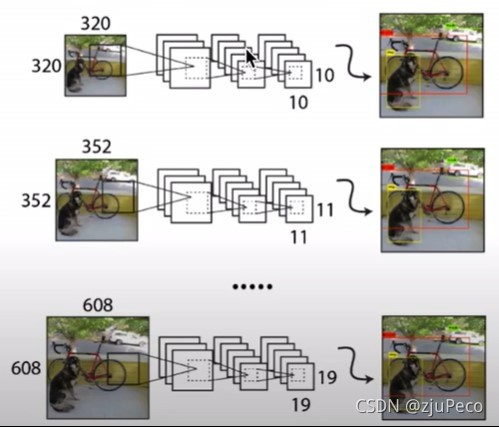
Yolov2每10個batches就會換一下輸入的尺度,使得模型泛化于不同尺度的輸入,這得益于adaptive pooling層,高解析度的輸入速度慢,但是對小目標的檢測效果要好很多,低解析度的輸入速度快,
2.2.2 Faster
這部分沒啥說的,就是把backbone給換成了Darknet-19,都是卷積層和pooling層,更加輕量了,
2.2.3 Stronger
這部分是作者對超多分類的一次嘗試,但估計效果沒有那么好,只是一個設想,
用來訓練檢測模型的資料集coco有80個類別,10萬的圖片,但用來分類的資料集imagenet有22k個類別,140萬的資料,作者想要把imagenet的資料和類別拿來用,于是就相處了層級分類這個辦法,如下圖11所示,
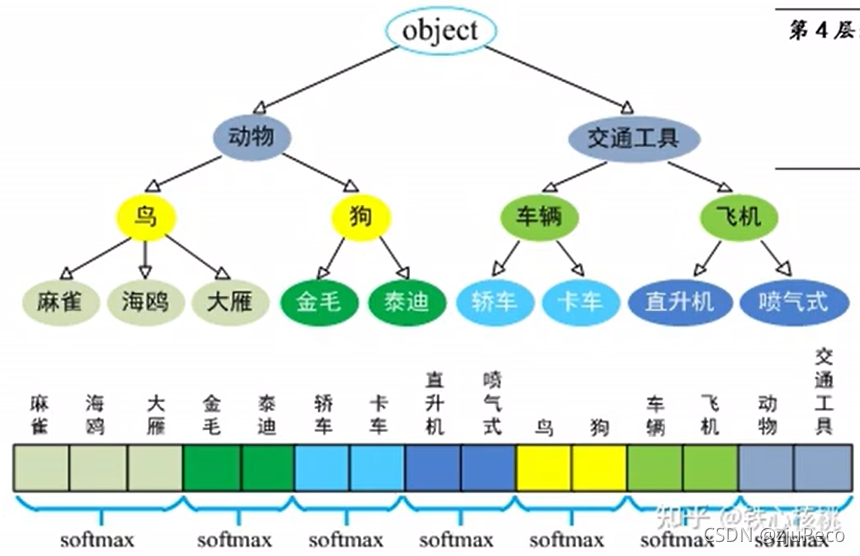
imagenet中的每個類別并不是完全兩兩互斥的,它們之間是有層級關系的,所以作者借助wordnet把類別進行了分層,同一層的類別分別進行softmax,這樣就做到了多層級的分類,檢測模型的類別都是包含在這些類別之中的,再將其應用到檢測模型即可,
這只是一個設想,了解一下即可,
2.3 一小步 - Yolov3
Yolov3相對于Yolov2沒有太多大的改進,用作者的話說就是"I managed to make some improvements to YOLO. But, honestly, nothing like super interesting, just a bunch of small changes that make it better."
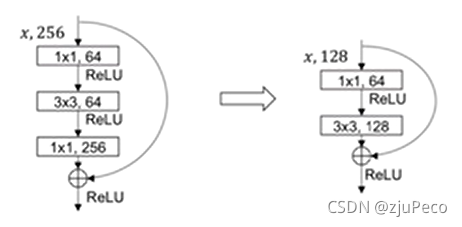
作者對backbone的網路結構進行了改進,將Darknet19結合Resnet,變成了Darknet53,作者把殘差塊輕量化了一下,如下圖12所示,
除此之外,還增加了多尺度訓練機制,增加了多尺度訓練的網路結構示意圖如下圖13所示,輸出三個尺寸的feature map,分別是
13
×
13
13 \times 13
13×13,
26
×
26
26 \times 26
26×26和
52
×
52
52 \times 52
52×52,大尺寸的feature map是小尺寸的feature map上采樣并結合淺層特征得到的,
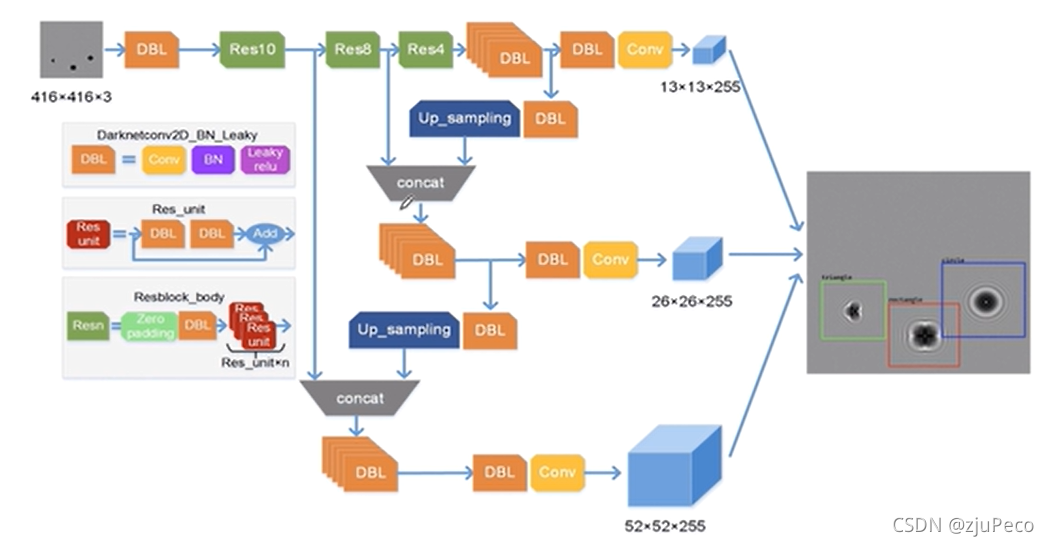
每個尺寸的feature map各司其職, 13 × 13 13 \times 13 13×13負責大目標物體, 26 × 26 26 \times 26 26×26負責中目標物體和 52 × 52 52 \times 52 52×52負責小目標物體,原因很簡單,越深層的資訊越抽象,越淺層的越粗糙,淺層還保留著小物體的資訊,深層就不一定還在了,
從圖13中可以看到feautre map的輸出channel變成了256,這個是因為Yolov3的anchor變成了9個,每個尺度的feature map有3個,然后類別變成了80類,所以每個尺度的feature map有
256
=
3
×
(
4
+
1
+
80
)
256=3 \times (4+1+80)
256=3×(4+1+80),

Yolov3就這些重要的改進,
2.4 技巧 - Yolov4
Yolov4可以說是目標檢測各種小技巧的大總結,它將技巧分為了bag of freebies(BoF)和bag of specials(BoS)兩種,BoF指的是只增加訓練的成本而不增加推理的成本的技巧,通常是前后處理;BoS指的是只增加一點推理成本卻可以顯著提高模型效果的技巧,通常是結構上的變化,
不同的BoF和BoS面對不同的問題和資料集有不同的效果,根據需求選擇即可,
BoF和BoS都有一大堆,要在這里全講完太費時間,也與這篇文章的目的相悖,這里只講一些重要的,且最終的Yolov4用上的技巧,下圖15是Yolov4真正用到的一些改進,

這里不會把上面的所有改進都講了,只挑一些重要的講,
2.4.1 網路結構的改進
2.4.1.1 backbone中的激活函式改為Mish
Yolov3中的卷積快都是CBL的結構,Yolov4改成了CBM,也就是把激活函式給改成了Mish,其示意圖如下圖16所示,

Leaky Relu激活函式是( a a a是很小的常數)
f ( x ) = { a x , i f x < 0 x , o t h e r w i s e (2-9) f(x) = \begin{cases} ax, &if \ x<0 \\ x, &otherwise \end{cases} \tag{2-9} f(x)={ax,x,?if x<0otherwise?(2-9)
Mish激活函式就是
f ( x ) = x ? t a n h ( l o g ( 1 + e x ) ) (2-10) f(x) = x \cdot tanh(log(1+e^x)) \tag{2-10} f(x)=x?tanh(log(1+ex))(2-10)
這里順便來說說常用的激活函式的優缺點,
sigmoid兩端很容易飽和,會造成梯度消失的問題,中間梯度很大,會造成梯度爆炸問題,用sigmoid做激活函式,神經網路不太好訓練,但是sigmoid的非線性表達能力很強,因為它不管怎么高階求導仍舊是非線性的,
tanh和sigmoid很像,不過它是以0為中心,
relu的問題是,它的負半軸沒梯度了,正半軸求個導是常數,非線性表達能力很弱,但是它快,所以用relu的網路一般網路層數很深,以此來彌補relu非線性能力表達弱的缺陷,
leaky relu負半軸做了優化,但還是非線性表達能力弱,
mish結合了relu和tanh的優點,它無上限,這樣可以保證沒有飽和區域,不會梯度消失,有下限,能夠保證具有一定的正則能力,同時非線性表達能力也不錯,
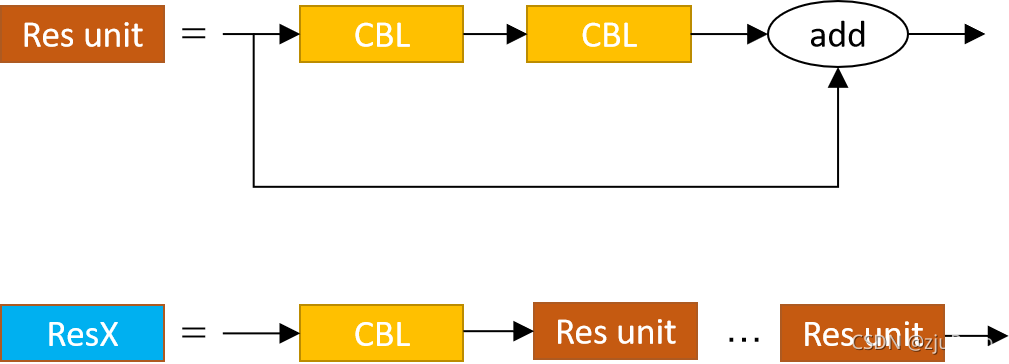
2.4.1.2 backbone中的殘差模塊改成了CSP
Yolov3中的殘差模塊如下圖17所示,resX中的X表示的是有X個Res unit,
Yolov4則是將殘差模塊替換為了CSP模塊,如下圖18所示,其中的CSPX中的X表示有X個Res unit,
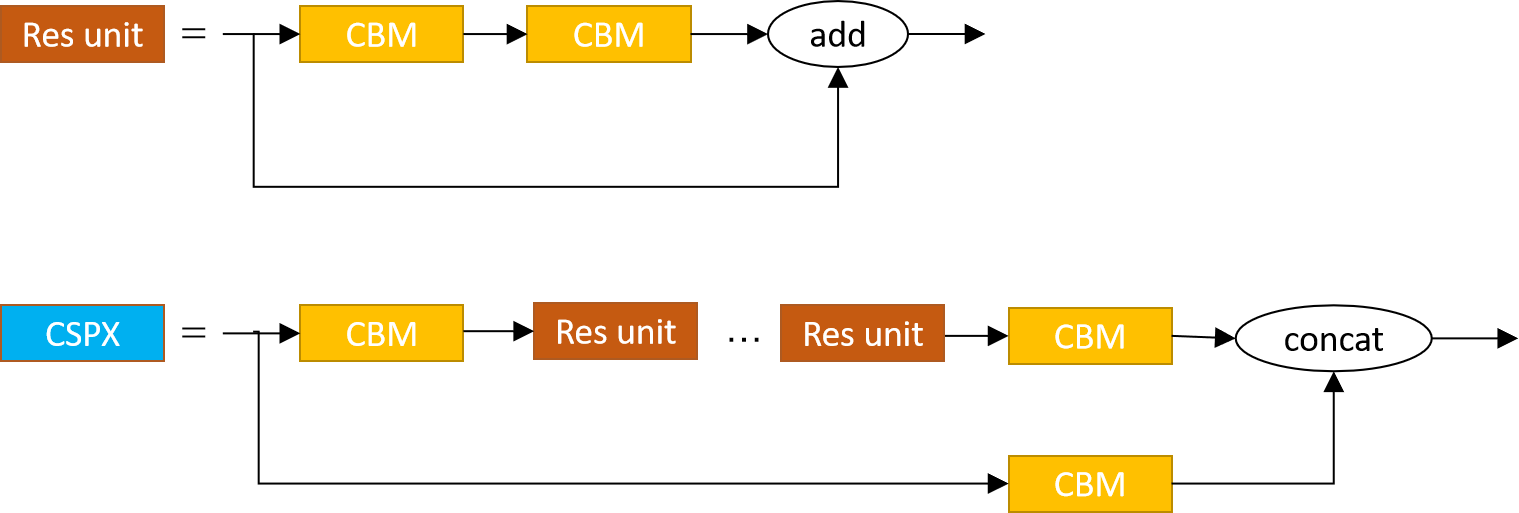
可以看出CSPX效仿殘差塊,額外加了一路,并且這一路中多了一個CBM,最后的add也變成了concat,相當于一堆殘差的外面再殘差了一遍,這里加個CBM直觀上是為了改變特征的shape,使其可以順利concat,除此之外,資料[8]中的猜想是,這是為了平衡上下兩路的資訊,相當于加了個電阻,每個這個電阻,就是個短路的狀態,資訊都從下面走了,有了這個電阻,就可以盡可能平衡上下路的資訊,這只是個猜想,
2.4.1.3 detector中的新增了SPP模塊
SPP的作用是增大感受野,它很簡單,就是一堆MaxPooling,每個MaxPooling的kernel size大小不同,就有不同感受野的結果,最后再全都concat起來即可,其示意圖如下圖19所示,

SPP之所以不放在backbone是因為這會造成大量的資訊丟失,而放在detector里卻起到了降維的作用,
2.4.1.4 detector中特征尺度的變化
Yolov4還讀detector中的尺度特征做了很大的修改,如下圖20和圖21分別是yolov3和yolov4的網路結構圖,
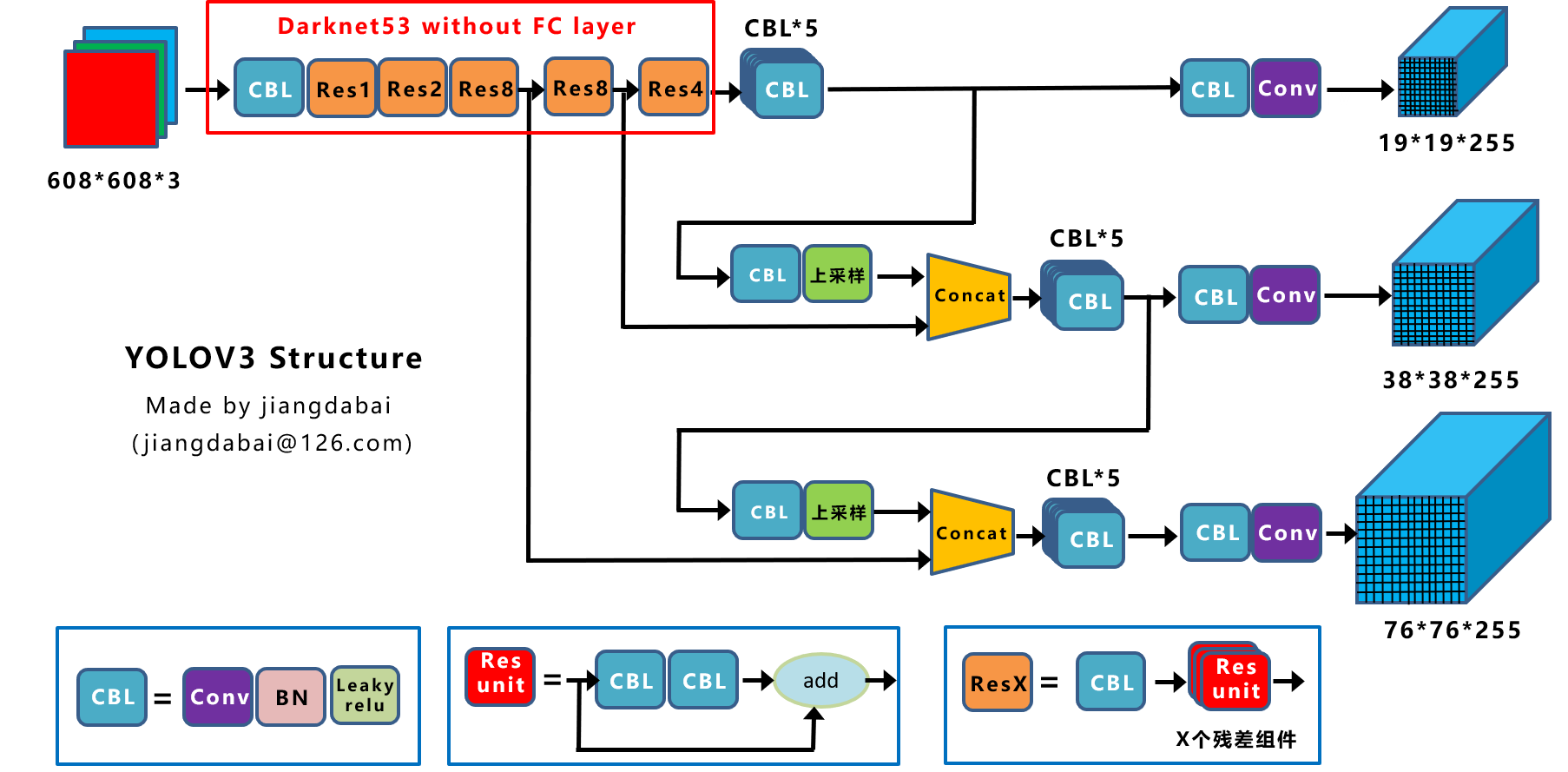
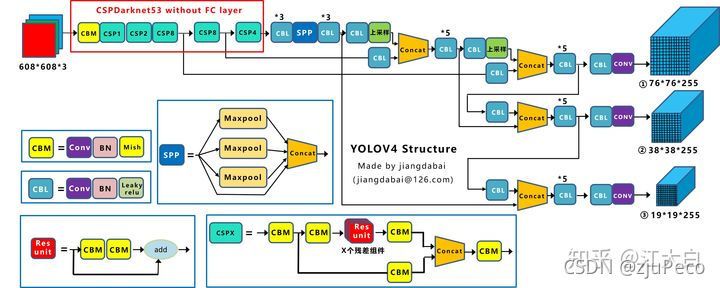
不難看出Yolov3是 19 × 19 19 \times 19 19×19 -> 38 × 38 38 \times 38 38×38 -> 76 × 76 76 \times 76 76×76的,而Yolov4是反過來的,這主要是為了增加特征融合性,也就是feature map中融合了更多層的資訊,特別是 19 × 19 19 \times 19 19×19這個feature map,融合的特征最多了,也就是對大目標的檢測效果更好了,應該說不管大小目標,總體都有提升,
2.4.2 損失函式的改進
(1)變為smoth_L1
之前Yolo的損失函式當中有大量的L2損失,在Yolov4中改成了smooth L1,smooth L1結合了L1和L2損失的優點,先來看下L1和L2損失的公式
L 1 = 1 n ∑ i = 1 n ∣ f ( x i ? y i ) ∣ L 2 = 1 n ∑ i = 1 n ( f ( x i ) ? y i ) 2 (2-11) L1 = \frac{1}{n} \sum_{i=1}^{n} |f(x_i - y_i)| \\ L2 = \frac{1}{n} \sum_{i=1}^{n} (f(x_i) - y_i)^2 \tag{2-11} L1=n1?i=1∑n?∣f(xi??yi?)∣L2=n1?i=1∑n?(f(xi?)?yi?)2(2-11)
L1的優點是倒數很穩定,但是是一個階段函式,在 ( 0 , 0 ) (0,0) (0,0)處是一個折線,L2的優點是在 ( 0 , 0 ) (0,0) (0,0)處是可導的,但是離 ( 0 , 0 ) (0,0) (0,0)越遠,導數越大,會產生爆炸,所以就有了結合L1和L2的smooth L1出現
s m o o t h L 1 = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ ? 0.5 o t h e r w i s e (2-12) smooth\ L1 = \begin{cases} 0.5x^2 & if\ |x| < 1 \\ |x| - 0.5 & otherwise \end{cases}\tag{2-12} smooth L1={0.5x2∣x∣?0.5?if ∣x∣<1otherwise?(2-12)
(2)iou loss改進
這里主要參考了文獻[10]
在Yolov3中的IOU loss就直接是 ( 1 ? I O U ) 2 (1-IOU)^2 (1?IOU)2,這里的iou就是交集比上并集,如下圖22所示,
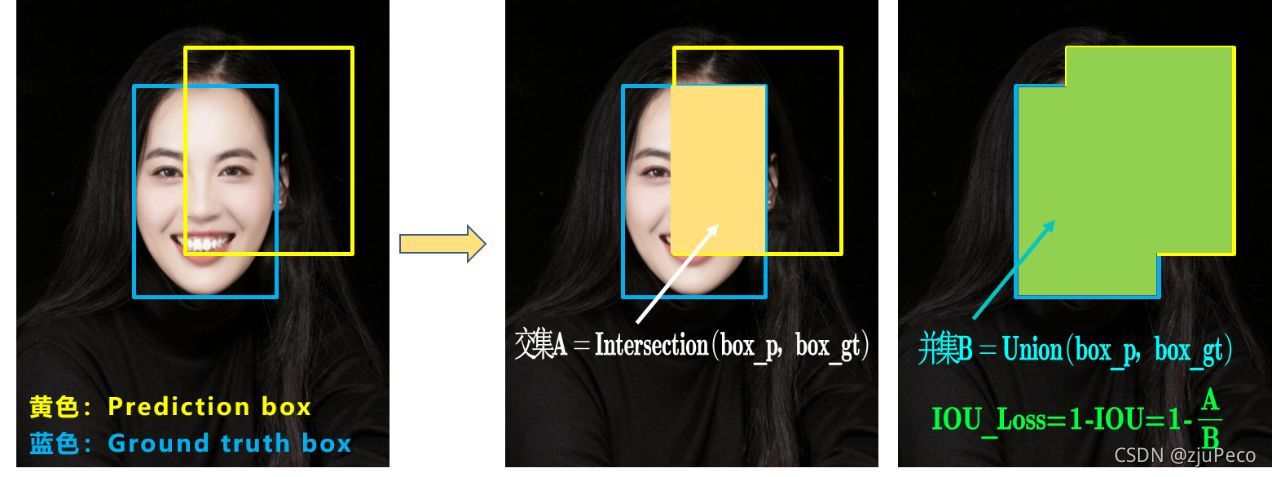
這里的IOU的計算方法優點缺點,且看下圖23,缺點一就是左圖所示,當預測框與真實框完全沒有交疊時,不管預測框離真實框多遠,IOU都是一樣的,但其實離真實框近的比離真實框遠的要好一些,缺點二就是中圖和右圖所示,當交集和并集一致時,不同方向的預測框得到的iou是一樣的,但其實右圖比中圖要好一點,因為中圖的中心點對齊需要預測框的水平和垂直都發生比較大的變化,而右圖只需要水平平移即可,

為了解決上述的兩個缺點,有了GIOU,如圖24所示,

GIOU的公式為
G I O U = I O U ? 差 集 / 最 小 外 接 矩 形 (2-13) GIOU = IOU - 差集/最小外接矩形 \tag{2-13} GIOU=IOU?差集/最小外接矩形(2-13)
最小外接矩形和差集的意思就是圖24中的左圖和中圖,不難看初,剛才提到的兩個缺點在這里已經解決了,不過還有一個問題,如圖25所示,

當預測框在真實框內部的時候,不管預測框在那個位置,GIOU都是一樣的,但是圖25的中圖顯然是優于左圖和右圖的,因為中圖的水平和垂直方向的坐標已經對齊了,只需要改變長寬即可,
這個時候,就又出現了一種DIOU,如圖26所示,

DIOU的公式為
D I O U = I O U ? ( D i s t a n c e _ 2 ) / ( D i s t a n c e _ C ) (2-14) DIOU = IOU - (Distance\_2) / (Distance\_C) \tag{2-14} DIOU=IOU?(Distance_2)/(Distance_C)(2-14)
其中, D i s t a n c e _ C Distance\_C Distance_C是最小外接矩形的對角線距離, D i s t a n c e _ 2 Distance\_2 Distance_2是預測框和真實框中心點的歐氏距離,
這樣一來就解決了圖25的缺點,但是,別急,還有一個缺點,DIOU沒有考慮長寬比,
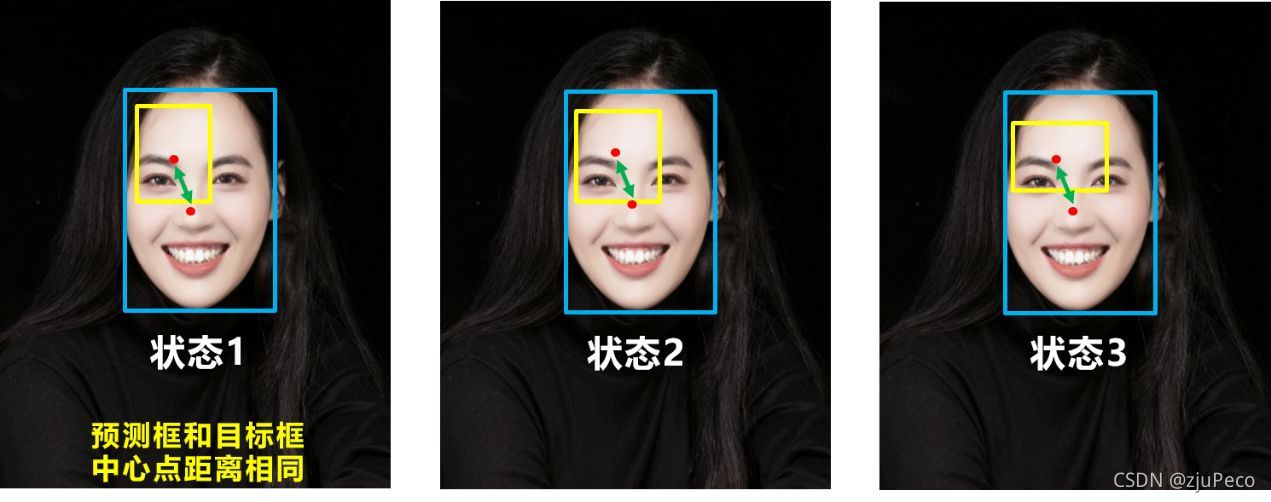
圖27中當預測中心點距離真實中心點一樣時,預測框的長寬比與真實框接近的,顯然是更優的,于是,就有了終極版的CIOU,
CIOU的公式為
C I O U = I O U ? D i s t a n c e _ 2 2 D i s t a n c e _ C 2 ? v 2 1 ? I O U + v (2-15) CIOU = IOU - \frac{Distance\_2^2}{Distance\_C^2} - \frac{v^2}{1 - IOU + v} \tag{2-15} CIOU=IOU?Distance_C2Distance_22??1?IOU+vv2?(2-15)
其中, v v v是長寬比的一致性引數,定義為
v = 4 π ( a r c t a n w g t h g t ? a r c t a n w p r e d h p r e d ) 2 (2-16) v = \frac{4}{\pi}(arctan\frac{w_{gt}}{h_{gt}} - arctan\frac{w_{pred}}{h_{pred}})^2 \tag{2-16} v=π4?(arctanhgt?wgt???arctanhpred?wpred??)2(2-16)
至此,iou經歷了這么多版本,最終確定為CIOU,
2.4.3 nms的改進
在訓練的時候用的是CIOU,但是在做nms的時候,用了diou-nms,用diou-nms可以把一些重疊度很高的框,但表示不同物體的給保留下來,至于為什么不用CIOU,我覺得是沒有必要,且會增加計算復雜度,我不太同意文獻[10]中說的CIOU在做nms時沒有真實框, v v v沒法計算的說法,兩個框做對比,把置信度高的當成真實框即可,
2.4.4 其他
其他比較重要的可能就是cutout,mosaic之類的資料增強的方法了,這個這里就不細講了,
2.5 又一小步 - Yolov5
Yolov5和Yolov4差不多可以說沒有做太多的改進,不過工程上更友好了一些,使用起來也更加方便,
2.5.1 網路結構的改進
2.5.1.1 添加了CSP2模塊
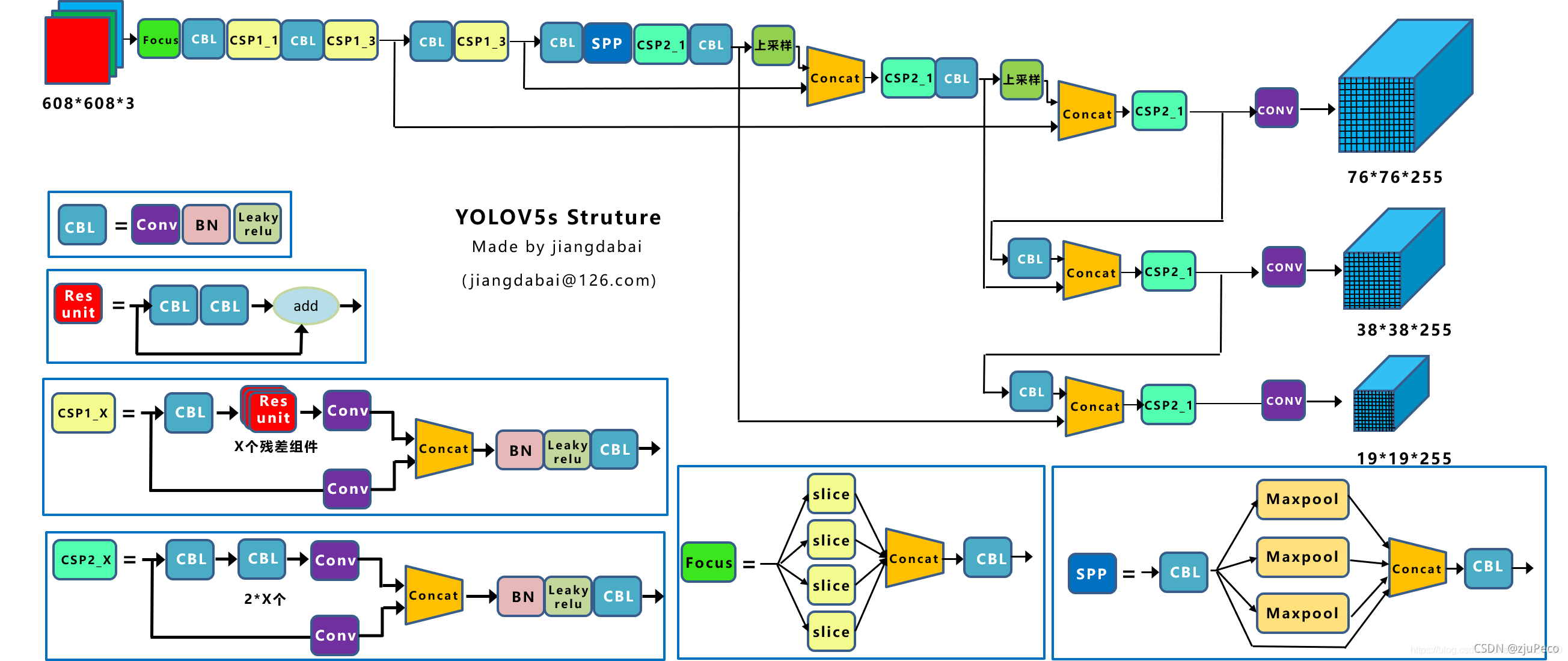
下圖28時Yolov5的網路結構圖,和Yolov4幾乎時一摸一樣,做了一點點改進,
(1)把CBM換回了CBL,可能是為了提升速度,
(2)設計了CSP2模塊,如圖28的左下角所示,就是把之前CSP中的殘差塊改成了CBL,
(3)添加了Focus模塊,這個其實就是Yolov2中的pass through,
2.5.2 其他
還有就是一些零零碎碎的東西,這里簡單列幾個比較有用的吧,
(1)添加了訓練前自動計算最佳預錨框的模塊,
(2)自適應圖片縮放,就是padding的時候,去掉一些沒用的黑邊,
3 結束語
這里根據網上各家的資料總結了很多,其中也有一些自己的理解,對我自身了解Yolo有很大的幫助,也希望給看到這篇博客的人有一些幫助,
參考資料
[1] You Only Look Once: Unified, Real-Time Object Detection
[2] 【子豪兄】YOLOV1目標檢測,看我就夠了
[3] YOLO9000: Better, Faster, Stronger
[4] 【精讀AI論文】YOLO V2目標檢測演算法
[5] Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift
[6] YOLOv3: An Incremental Improvement
[7] YOLO系列演算法之YOLOv3演算法精講
[8] 2021最新人工智能深度學習YOLOv4與YOLOv5教程
[9] YOLOv4: Optimal Speed and Accuracy of Object Detection
[10] 深入淺出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基礎知識完整講解
[11] 深入淺出Yolo系列之Yolov5核心基礎知識完整講解
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335323.html
標籤:其他
上一篇:2021-10-24