前言
剛入門機器學習,只是將上課的知識點進行回顧整理,文章會有錯誤,希望各位大牛看到后能夠及時加以指正,
目錄
一、機器學習的概念
二、機器學習的分類
1、Regression(回歸)
2、Classification(分類)
3、Structured Learning(結構化學習)
三、機器學習的步驟
1、Function with Unknown Parameters(有引數的未知函式)
2、Define Loss from Training Data(損失函式L)
(1)Error Suface(誤差曲面)
3、Optimization(最優化)
四、Liner Model (線性模型)
一、機器學習的概念
機器學習(Machine Learning)顧名思義,就是讓機器擁有學習的能力,概括來說,機器學習,就是讓機器具備一種找函式的能力,
舉例來說:
1、我們想要讓機器語音識別,那么我們需要讓機器尋找一個函式,使得這個函式的輸入是一段音頻,輸出是這段音頻所對應的文字內容,
2、我們想要讓機器影像識別,那么我們需要讓機器尋找一個函式,使得這個函式的輸入是一張圖片,輸出的是圖片中的主要內容是什么,
3、我們想要機器下圍棋(Alpha Go),需要機器尋找一個函式,輸入是黑白棋的位置,輸出是下一步棋的落子,

二、機器學習的分類
機器學習的主要目的用于尋找函式,隨著函式的不同,機器學習有不同的類別,接下來就粗略的介紹一下這幾種類別,
1、Regression(回歸)
Regression問題的主要特征是要求我們尋找的函式,他的輸入是一個數值,同時,輸出的也是一個數值,
舉例來說,我們已經知道了今天的天氣狀況,需要預測出明天的PM2.5值,那么我們尋找到一個函式,輸入是今天的PM2.5值以及溫度,氣壓等引數,經過函式便可以輸出明天的PM2.5數值,這樣的一個輸入輸出都是數值的問題我們稱之為Regression(回歸)問題,
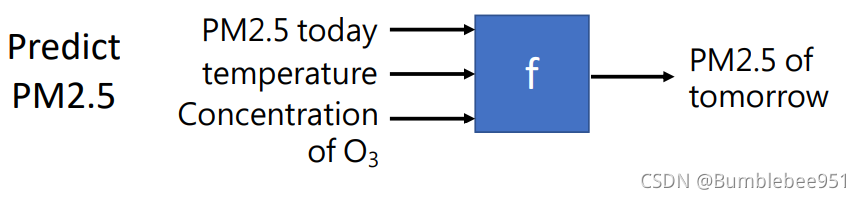
2、Classification(分類)
Classification問題的特征是需要機器做一個選擇,比如我們常用的郵箱,首先我們要準備一些選項(classes)比如郵件作為輸入,這個函式需要幫助我們判別這些郵件是否為垃圾郵件,輸出就是做出選擇,Yes or No?
同樣的,我們的Alpha Go也是一個Classifiation問題,輸入是棋盤上19×19個位置,輸出則是選擇出最適合下一步落子的位置,
3、Structured Learning(結構化學習)
除了我們需要機器輸出數值,和做一些選擇,面對實際生活問題,我們還需要機器能夠生成一些有結構的東西,比如畫一張圖,寫一篇文章等,
三、機器學習的步驟
我們前面已經說到機器學習實際上就是讓機器尋找函式,那么接下來就講解下,機器是如何尋找函式的,
1、Function with Unknown Parameters(有引數的未知函式)
我們用Youtube的后臺觀測人數來舉例,
首先我們需要寫一個帶有未知引數的函式,至于這個函式具體該怎么寫?這點是需要我們具備一定的Domain knowledge(領域知識),假設我們已經從后臺知道當天的點閱人數,那么想要預測明天的點閱人數,我們猜想第二天的點閱人數肯定和今天的有一定的線性關系,暫時寫為y =b + wx1,這里的x1是已知的今天點閱人數,y是預測的第二天的點閱人數,b和w是未知引數,需要我們不斷優化來得到,至于b和w該如何設定,這也要依靠我們的Domain knowledge,我們猜想第二天的點閱人數肯定和第一天的點閱人數有一定的關系,所以y = wx1然后再用一個b作為修正,
我們已經初步的定義了一個帶有未知引數的函式,這是尋找函式的第一步,
2、Define Loss from Training Data(損失函式L)
第二步,需要從我們的訓練資料中定義一個Loss(損失函式)Loss函式中的輸入便是第一步中的未知引數b和w,輸出的數值便可以告訴我們第一步定義的b和w所選的數值是好還是不好,如果輸出的L數值很大說明b和w定義的不好,如果L數值很小,說明我們定義的b和w還不錯,
接下來我們用已知Youtube的點閱次數來進行舉例,

圖示是2017年1.1號到2020.12.31每天的點閱人數,我們看到1.1號的點閱人數是4.8k也就是我們函式中的x1=4.8k,我們假設b為0.5k,w為1代入函式中可知1.2號的點閱人數為y = 0.5k + 1×4.8k = 5.3k, 注意:這里的5.3k是通過第一步中假設的函式計算出來的,而實際1.2號的觀測人數為4.9k,我們對比發現,第一步中假設的函式計算出來的值偏大,那么大多少呢?我們將估測的值用y表示,真實值用?來表示,他們誤差e用差的絕對值表示,
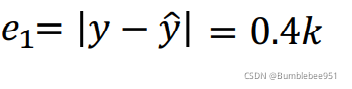
以上是用1.1號的值預測1.2號的值,那么也可以用1.2號的值來預測1.3號的值,注意:以上的數值都是訓練資料,即都為已知數值,來回計算是為了判斷我們第一步假設的函式是否合理,請注意區分,1.2號的點閱人數為4.9k,代入第一步中的函式y = 0.5k + 1×4.9k=5.4k而實際中1.3號的點閱人數為7.5k,所以再計算一次偏差,
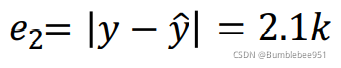
以此類推,我們利用第一步假設的函式預測出后一天的點閱數,然后再和真實值對比,計算出誤差并用e表示,這樣下來將三年中的訓練資料都進行計算得到各種e然后求和再去平均便得到了我們的L
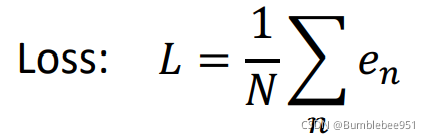
我們計算出來的這個L數值越大,說明我們選用的引數(b,w)越不好,越小越好,
(1)Error Suface(誤差曲面)
我們通過調整不同的b和w就能計算出不同的L,然后整合起來就可以得到一個等高線圖,
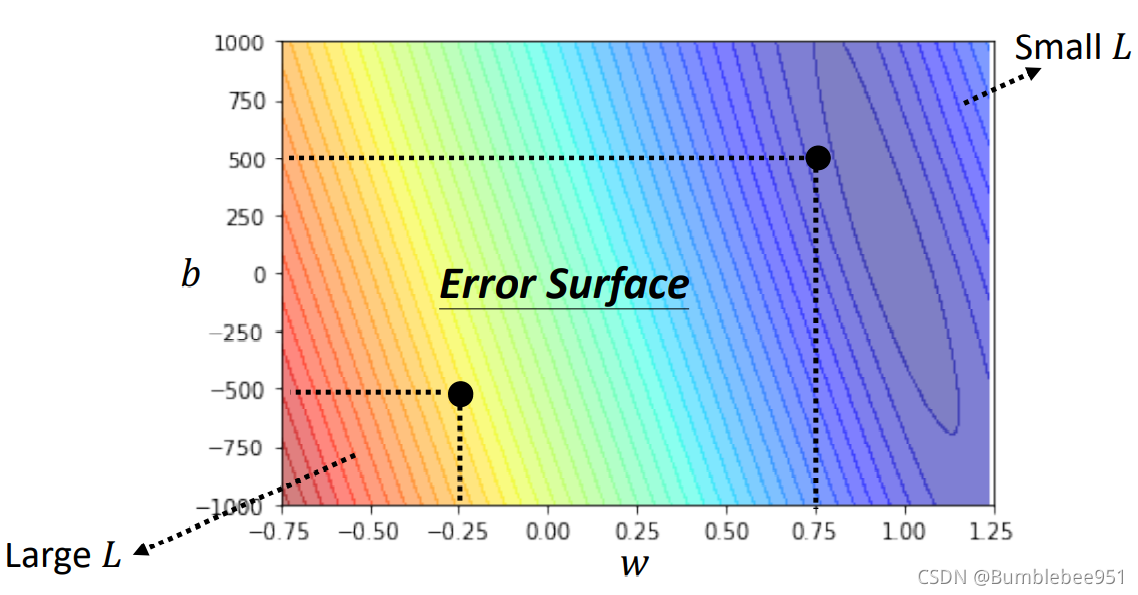
從等高線圖中可以看到,越紅色系說明L越大,誤差越大,藍色系則誤差較小,
以上便是機器學習的第二步,即計算損失函式L,并不斷地調整引數得到不同的L畫出等高線圖,
3、Optimization(最優化)
機器學習的第三步便是要解決一個最優化問題,也就是找到合適的b和w使得L最小,
在機器學習中,常用的Optimization方法便是Gradient Descent(梯度下降)方法,參考第二步畫出的Error Suface,為了簡化問題,我們假設只有一個未知變數w,
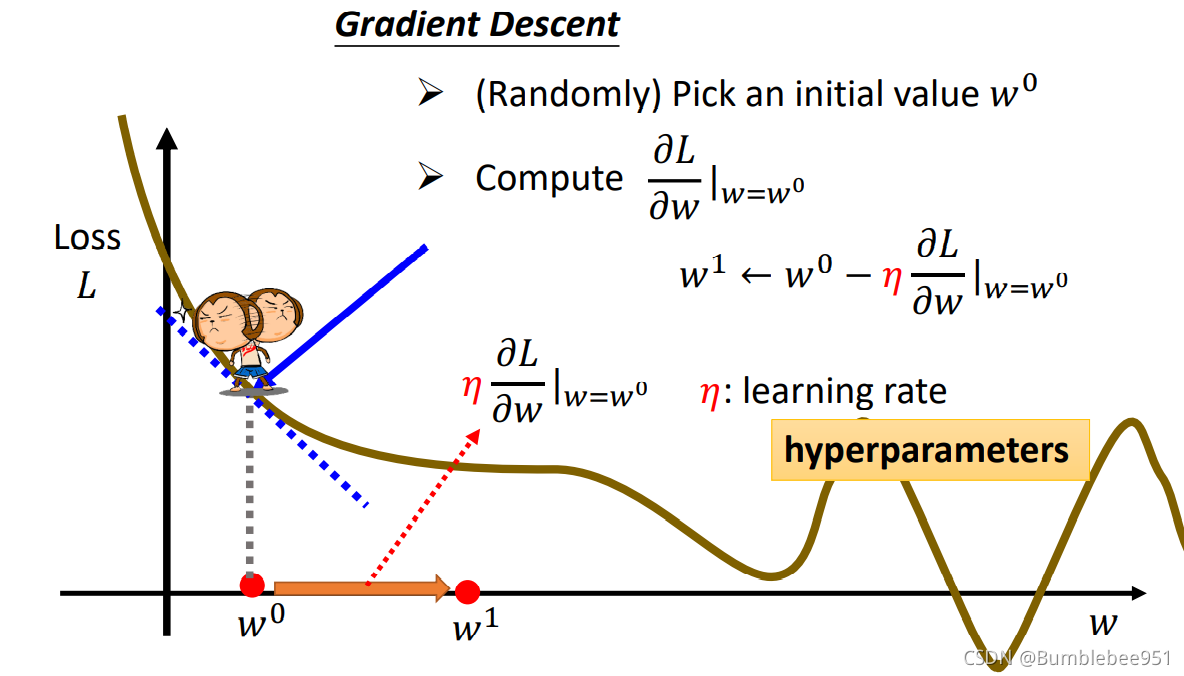
假設只有一個未知引數w,w和L所構成的Error Suface如圖所示,接下來我們便用梯度下降的方法來尋找合適的引數,
首先隨便取一個點設為w0,然后計算出在w0這個點,對應Error Suface上的斜率為多少,也就是w0對L進行求導,如果斜率為正,那么說明在影像上左低右高,為了取較低的L我們需要將w0往左跨一步,(斜率為負同理,數學知識,不再贅述),那么這一步該有多大呢?這一步的大小取決于兩個因素,
1、如果斜率很大,說明影像很陡,我們需要大跨一步才能將L降低,同理如果斜率很小,說明影像趨于平緩,跨度小一些即可,
2、除了斜率還有一項影響因素便是學習速率(learning rate)η,學習速率是自己設定的,如果設定值大說明引數更新快,學習就快,反之,設定值小,引數更新慢,學習較慢,
我們知道了這些影響因素便知道,如果斜率是負的(左高右低),那么需要我們在Error Suface上向右跨一步,這一步的大小是η乘上微分的結果,得到w1,
接下來就是重復上述操作,不斷地求導,根據斜率判斷移動方向,然后確定步伐大小,最侄訓停下來,
那么又有一個問題就是,什么時候會停下來呢?往往有兩種狀況情況,
第一種就是我們自己不想再更新,第二種就是我們在求導的程序中遇到了導數為0的情況,引數也不會再更新,
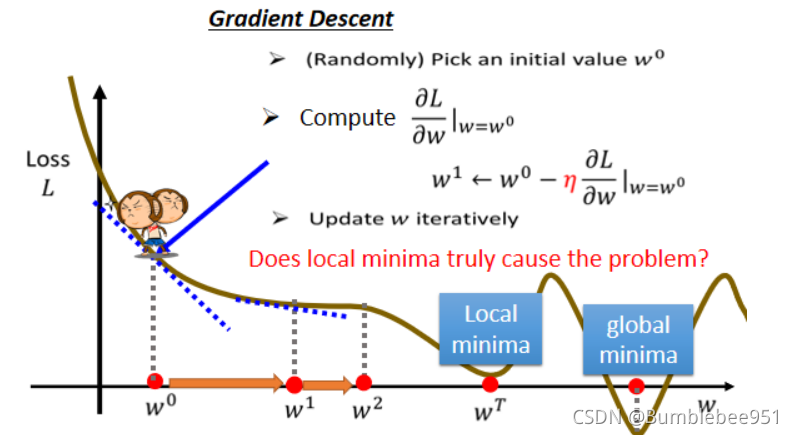
從上圖我們可以發現,Gradient Descent有一個巨大的問題就是,會有極小值和最小值的問題,也許我們更新到極小值(Local minima)時就沒有辦法繼續更新了,但是還有更小的值我們還沒有過去,這個問題我們在以后的內容做出解答,
剛才的例子是只有一個未知引數,我們在步驟一時的函式有兩個未知引數,我們在進行梯度下降的時候只需要將兩個引數w,b分別對L進行微分然后乘上學習速率η更新即可,
反應在Error Suface上就是先隨便取一個點,然后基于這個點上的w和b分別對L進行微分乘上-η,將w和b更新的方向結合起來就是一個向量,就可以在Error Sufae上表示出更新方向,
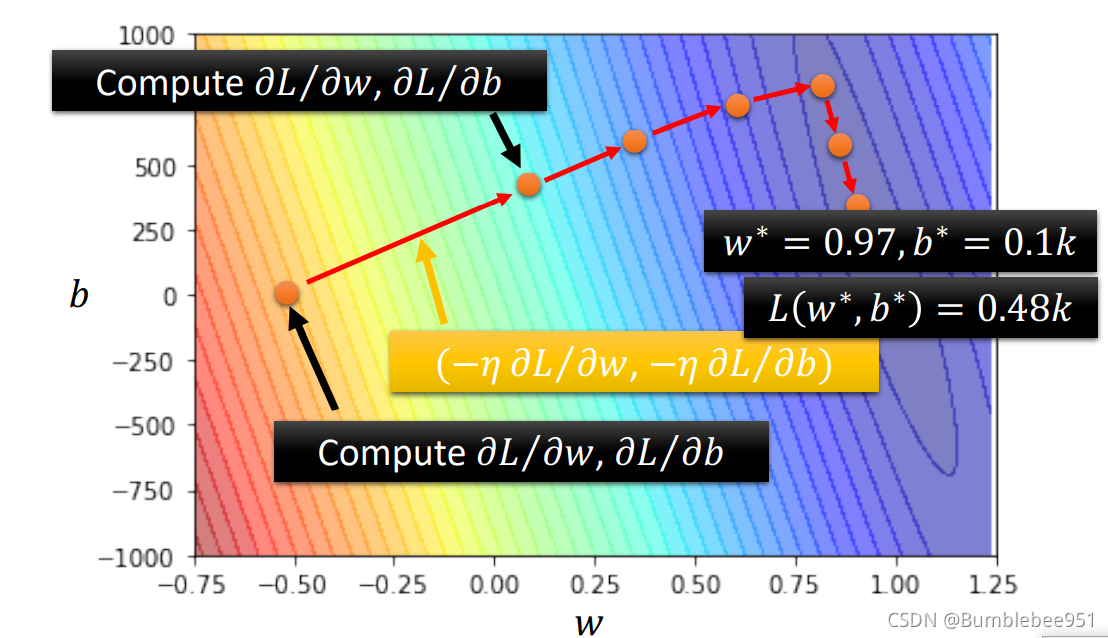
不斷地重復上述操作,最后可以得到不錯的w和b,得到不錯的w和b后我們的第一步的函式大致的就能確定了,
以上便是機器學習的三個步驟,總結一下就是:
1、根據自己的領域知識假設一個帶有未知引數的函式,
2、將未知引數作為輸入,設定一個損失函式,計算L的值,并且繪出Error Suface,
3、解一個最優化問題,將未知引數對L進行微分,然后逐步移動,最終找到最合適的引數,

四、Liner Model (線性模型)
剛才上面所說的三個步驟,都是在訓練模型的基礎上進行運算,也就是說我們在已知資料上計算Loss,接下來,我們要預測一下未來的點閱人數,
我們當前只有2017-2020.12.31的資料,然后通過訓練資料確定了w為0.97 b為0.1k時L最小為0.48K,注意:這里的數值都是在訓練資料中得到的,換句話說就是在自嗨,接下來我們用訓練資料中確定的w,b預測2021的點閱人數,也就是通過2020.12.31的點閱人數預測2021.1.1的人數,用2021.1.1的點閱人數預測2021.1.2的點閱人數,一直計算到2021.2.14這一天,并且將測驗資料中的L計算出來為0.58k,我們對比發現,用之前的w和b得到的訓練資料中的L為0.48k,然后同樣的w和b用到測驗資料中L為0.58k,這樣的偏差有些大,我們需要將L更小,
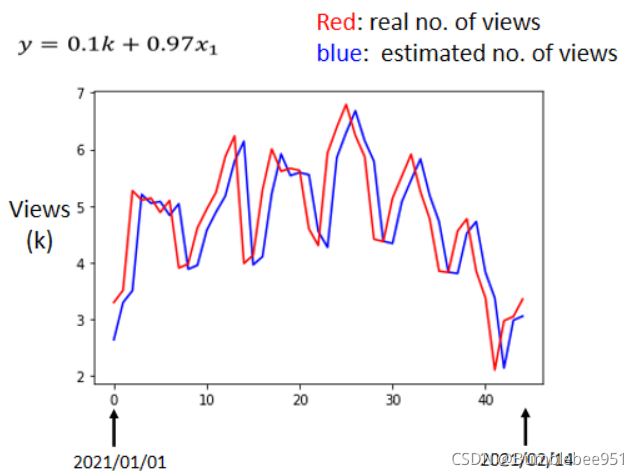
- 橫軸是代表的是時間,所以0這個點 最左邊的點,代表的是2021年1月1號,最右邊點,代表的是2021年2月14號
- 縱軸就是觀看的人次,這邊是用千人當作單位,
- 紅色的線是真實的觀看人次
- 藍色的線是機器用這一個函式,預測出來的觀看人次
觀察上圖我們可以看出,這個圖是有周期性的,也就是說,每隔7天點閱人數會降低一次,我們是否可以利用這個規律優化我們的模型呢?因為之前的模型只是通過前一天的預測第二天的人數,我們能否通過前七天的資料來預測,效果會不會更好一些?
所以我們要修改模型,修改模型的能力也是依靠我們的Domain knowledge,
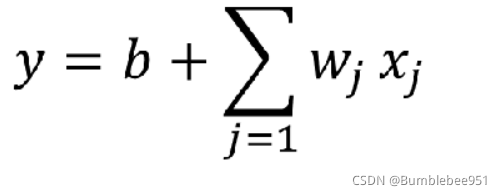
上圖意味著,我們j的范圍是1-7也就是把前七天的資料乘上不同的w然后加上b得出預測的結果,那么我們利用這個模型,在訓練資料上的得到的L為0.38k比之前的模型要好,在測驗資料上得到的L是0.49k之前是0.58k也有了好轉,那么我們根據這個模型然后設定不同的w和b再根據梯度下降的方法計算出最佳值如圖,

既然選擇前七天的作為參考資料,那么可不可以選擇前28天,甚至前56天的作為參考資料?我們可以理解為,考慮的越周到,預測出來的誤差越小
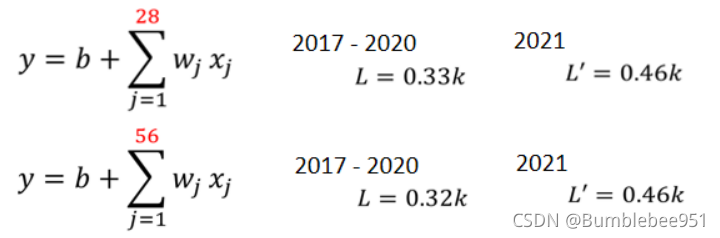
可以看到在測驗資料上,28天和56天的L都是一樣的,說明這個模型已經做的夠好了,
但是我們有沒有考慮到,之前的模型都是一個線性模型,線性模型太過于簡單,現實中可能不是這樣,要遠比這樣的復雜,比如他們的關系如果是二次函式的關系呢?或者是下圖所示的關系呢?
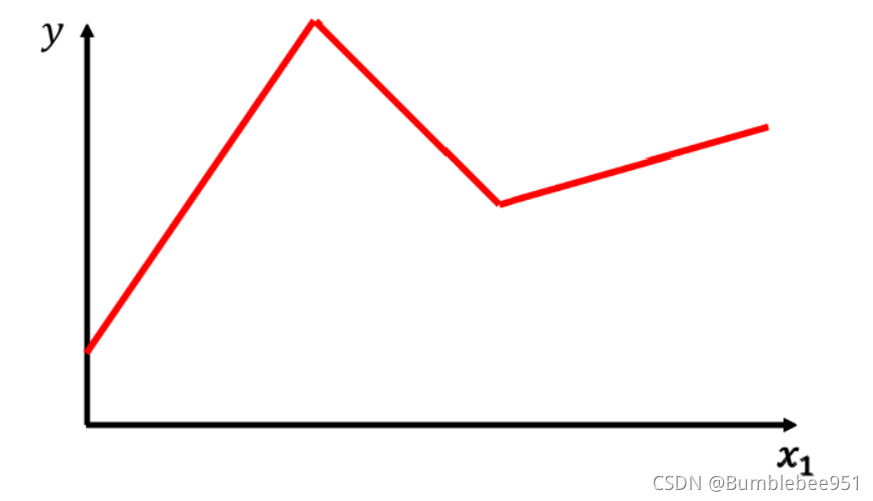
我們稱這樣的現象為Model Bias ,所以我們需要更復雜的,帶有未知引數的函式,
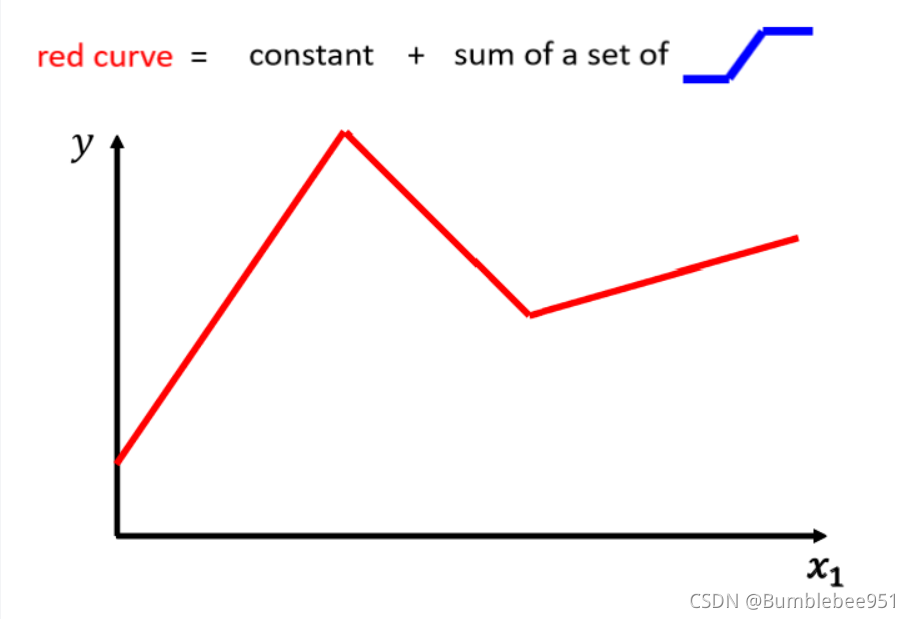
如圖所示的紅色折線,我們可以理解為他是若干個藍色線段的集合,那么怎么樣才能用若干個藍色線段表示成紅色線段呢?
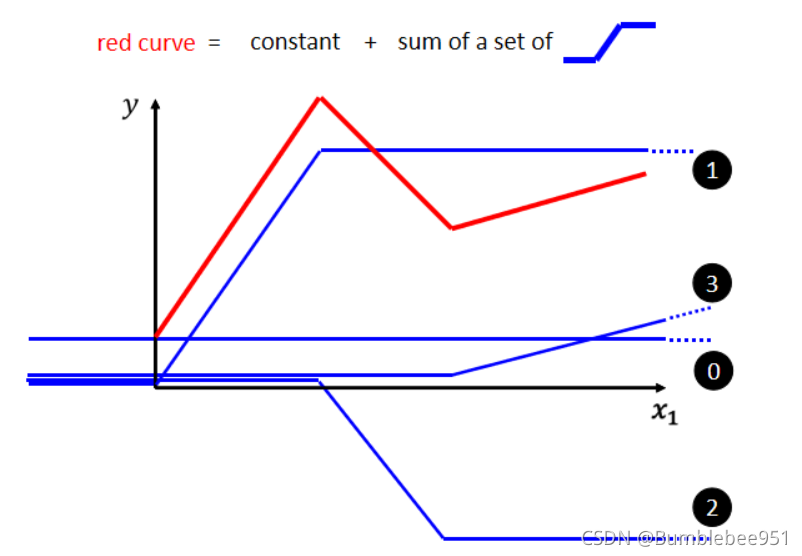
紅色線段等于一個常數加上若干個藍色線段,這個常數就是紅色線段和Y的交點,紅色線段的第一段等于常數(0號藍色線)加上1號藍色線,這里的1號藍色線斜率和紅色第一線段相同,以此類推,紅色線可以用常數(0)+1+2+3號藍色線段構成,
那么又有問題,如果是二次曲線怎么辦?
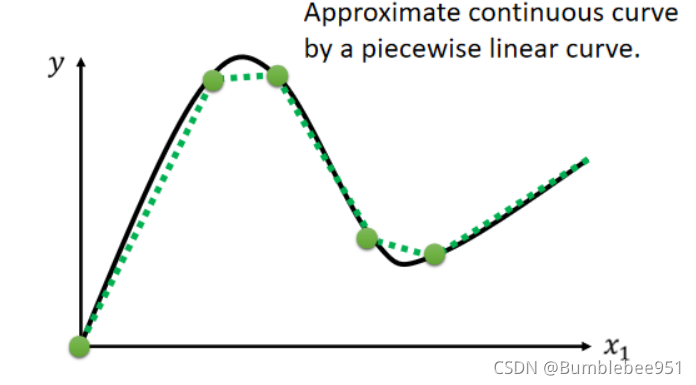
如果是曲線,我們可以劃分很多個小點用直線連起來,然后無線的逼近曲線,
我們通過上述可以得出,我們可以利用分段線性曲線逼近任何曲線,然后再用足夠的藍色線段來表示分段線性曲線,
接下來的問題就是,藍色線段該如何表示呢?
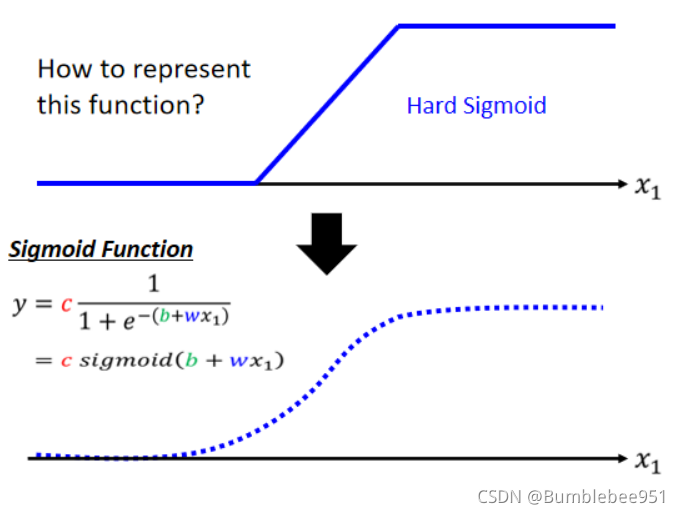
直接表示藍色線段可能有些困難,但是我們可以用S型曲線來逼近,S型函式是已知的
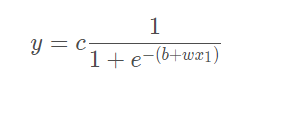
我們有了S型函式就可以表示藍色線段,各種各樣的藍色線段組合起來就是紅色曲線,我們可以通過調整S型函式的引數來構建不同的藍色線段,
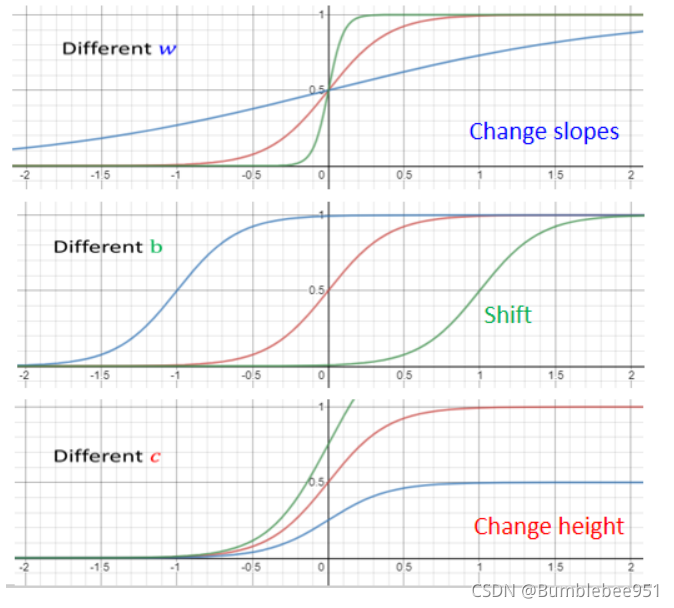
- 如果你今天改 w 你就會改變斜率你就會改變斜坡的坡度
- 如果你動了b 你就可以把這一個 Sigmoid Function 左右移動
- 如果你改 c 你就可以改變它的高度
所以根據上面所說的,我們只要有不同的w,b,c便可以得到不同的曲線,不同的曲線表達不同的藍色線段,不同的藍色線段組合成完整的紅色曲線用于逼近其他曲線,
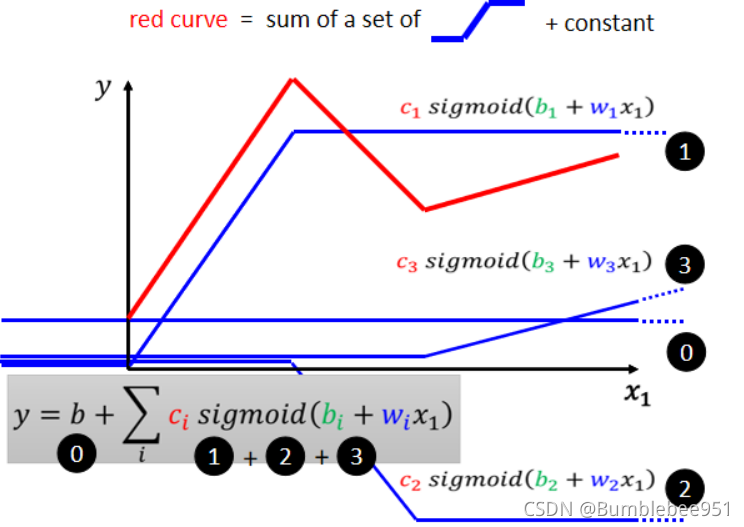
所以紅色的線段可以寫成0加上的123,而123代表不同的藍色線段,這些藍色線段的書寫形式都是一樣的,不同的地方在于c,w,b因為不同的引數代表不同的S函式,也就是不同的藍色線段,1號S函式就是c1 b1 w1 同理以此類推,相加后便是紅色曲線,
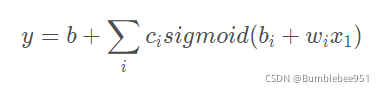
所以,我們現在將一個簡單的線性模型變成了一個有彈性的模型
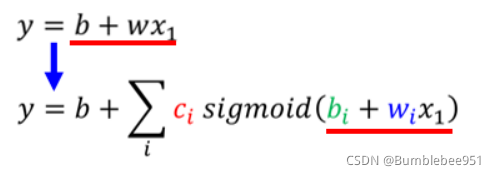
接下來,我們回顧下剛才的線性函式,我們為了優化模型,將1天的資料變為考慮7天的資料
我們為了更優化現在的新模型,也將這個思想轉化到新模型上
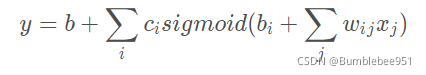
這里i是不同的藍色線段對應的引數(c b w)而j對應的是天數 第一天,第二天一直到第七天或者第二十八天,注意理解!
舉例來說 我們只考慮前一天 前兩天,跟前三天的情況
- 所以 j 等於 1 2 3,那所以輸入就是 x1 代表前一天的觀看人數,x2 兩天前觀看人數,x3 三天前的觀看人數
- 每一個 i 就代表了一個藍色的 Function,只是我們現在每一個藍色的 Function,都用一個 Sigmoid Function 來比近似它 那這邊呢,這個 1 2 3 就代表我們有三個 Sigmoid Function,那我們先來看一下括號里的事情,
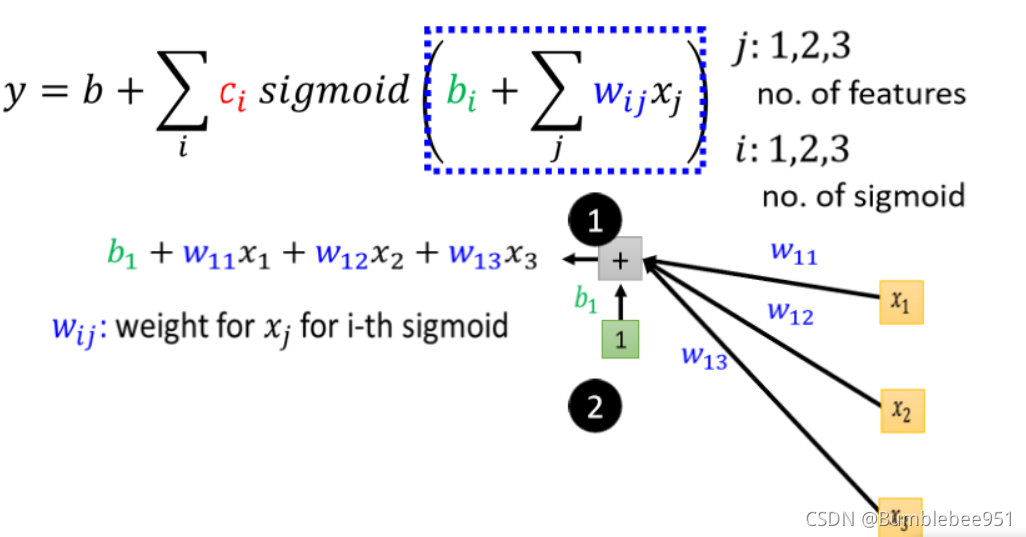
上面表示的意思是一個藍色線段考慮前三天的引數也就是(x1w1,x2w2,x3w3 ),這是一個藍色線段中的三個引數,那么我們有3個藍色線段
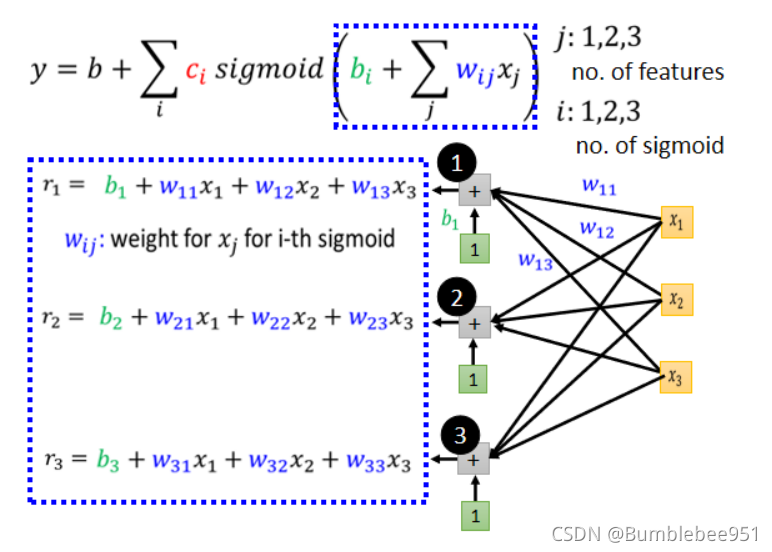
上面的r用于儲存三個藍色線段對應的三天引數的值,
將r1,r2,r3簡化為矩陣和向量相乘為
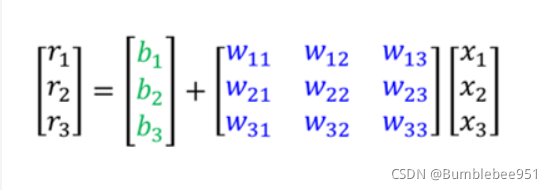
線性代數的知識,繼續簡化為

現在將括號內的所有式子簡稱為r,然后將r進行s函式變換可以得到不同的a
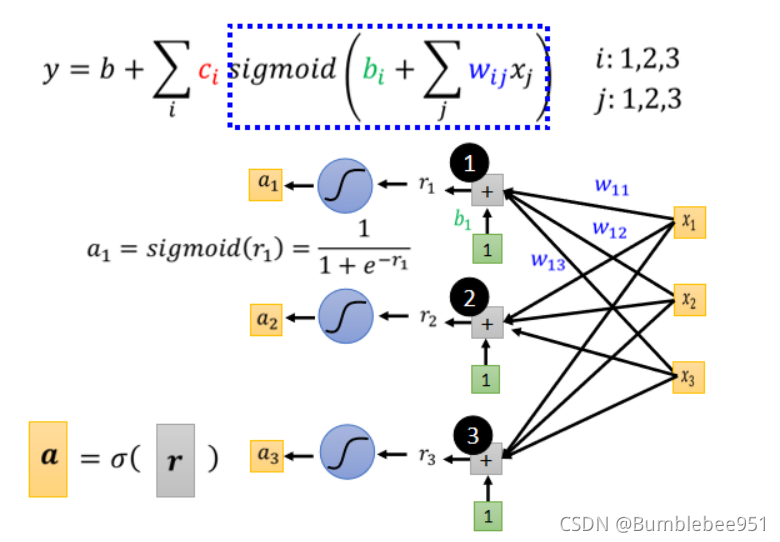
現在的意思是,將藍方框里的所有式子都變為a1,a2,a3,
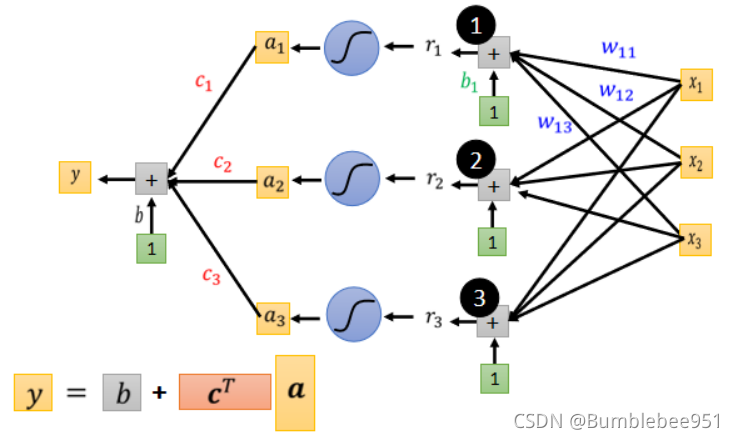
然后將所有的a和c相乘再加上常數b就可以得到紅色曲線,
至此,我們通過一些列復雜的變化終于得到了紅色曲線在不同的引數下的函式,也就是第一步找到了函式,然后就是第二步,通過這個復雜的函式,各種不同的引數,尋找L,找到L后就是第三步,將所有引數對L進行微分,進行梯度下降分析,解決最優化問題,
最終,我們通過這個復雜的函式,然后經過一系列步驟(定函式,尋找L,優化)終于找到了合適的引數
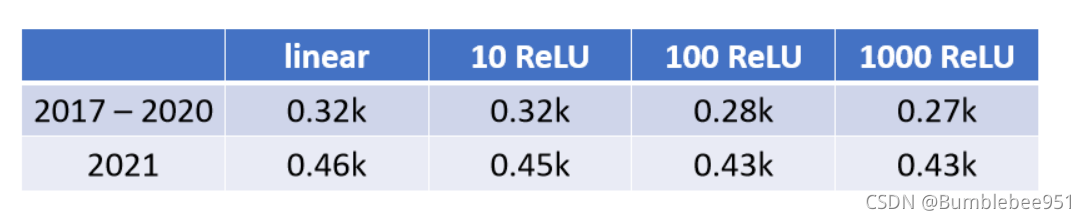
這是經過重新選擇的函式,然后經過一系列運算求得的L,我們發現比之前又低了很多,
接下來我們繼續優化:
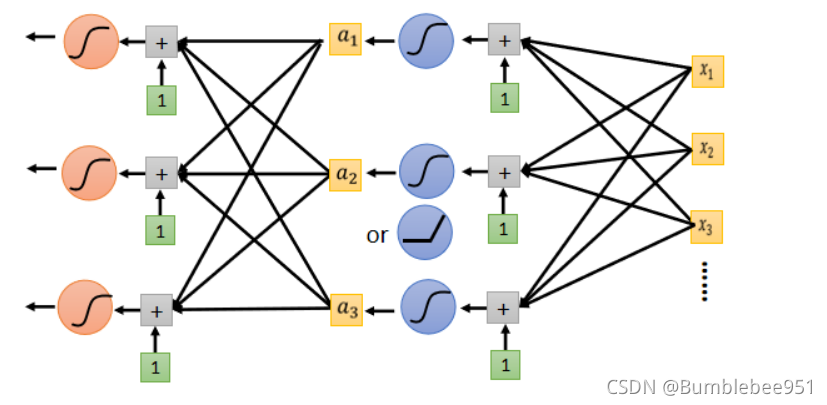
我們在之前的基礎上,再重復進行很多次運算,只不過選取的引數不同,構成一個神經網路,一層又一層的優化,最終得到了想要的L
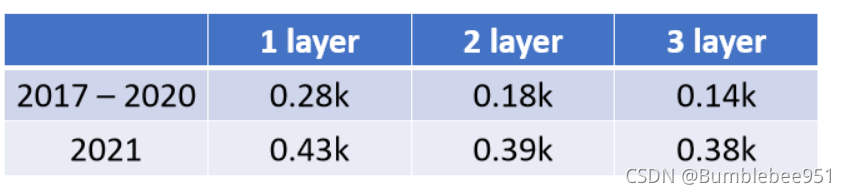
我們發現,層數越多誤差也就越小,我們將這一層又一層的方法稱為深度學習(Deep Learning)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335405.html
標籤:AI