文章目錄
- 線性表
- 順序表
- 順序表的定義及結構
- 順序表結構體定義
- 動態順序表的介面實作
- 順序表尾插尾刪
- 順序表頭插頭刪
- 任意位置插入洗掉
- 其他基本介面
- 陣列面試題
- Example 1 移除元素
- 思路 1
- 思路 2
- 思路 3
- Example 2 陣列去重
- Example 3 合并陣列
- 思路 1
- 思路 2
- 順序表的缺陷
- 鏈表
- 鏈表的定義及結構
- 單鏈表結構體的定義
- 單鏈表的介面實作
- 單鏈表尾插頭插
- 單鏈表尾刪頭刪
- 任意位置插入洗掉
- 其他基本介面
- 鏈表的分類
- 鏈表面試題
- Example 1 移除結點
- Example 2 反轉鏈表
- Example 3 中間結點
- Example 4 輸出結點
線性表
線性表是n個具有相同特性的資料元素的有限序列,線性表是一種在現實中應用廣泛的資料結構,常見的線性表有順序表,鏈表,堆疊,佇列,字串等,
線性表在邏輯上是線性結構,可以想象成一條直線,但在物理上不一定是連續的,線性表的物理存盤通常以陣列和鏈式結果的形式存盤,如圖:
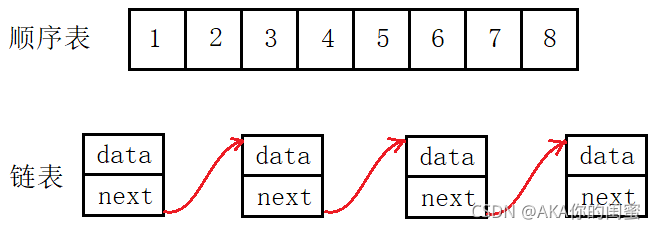
順序表
順序表的定義及結構
順序表是用一段物理地址連續的存盤單元依次存盤資料元素的線性結構,即陣列的形式存盤,順序表必須從頭向后依次存盤,在陣列上完成資料的增刪查改的操作,當然順序表一般分為動態順序表和靜態順序表,
順序表結構體定義
//1. 靜態順序表
#define NUM 1000//元素容量
typedef int SLDataType;//順序表元素型別
typedef struct SeqList {
SLDataType data[NUM];//順序表陣列
int size;//元素個數
}SL;//順序表結構體名
//2. 動態順序表
typedef int SLDataType;
typedef struct SeqList {
SLDataType* data;//元素陣列
int size;
int capacity;
}SL;
- 結構體的用途就是描述一個復雜物件,存放資料的陣列和記錄元素個數和容量的變數都是為了描述順序表這一個整體物件的不可缺少的成員變數,所以將其都放在一個名為順序表的結構體中,
- 靜態順序表定義相對簡單,但元素容量固定,變數
size用于記錄有效陣列元素個數,動態順序表使用動態開辟陣列,故增加一個變數capacity用于記錄陣列容量, - 使用
#define定義元素容量,對結構體型別和元素型別的重命名,同樣也是方便后期更改,達到“一改俱改”的效果,
動態順序表的介面實作
靜態順序表是定長陣列,只適用于資料存量確定的場景,而動順序表是動態開辟的陣列,可以靈活的增容,所以現實中基本上都是用動態順序表,下列是基本的增刪查改操作的介面函式,
//順序表初始化
void SeqListInit(SeqList* psl, size_t capacity);
//檢查空間
void CheckCapacity(SeqList* psl);
//順序表尾插
void SeqListPushBack(SeqList* psl, SLDataType x);
//順序表尾刪
void SeqListPopBack(SeqList* psl);
//順序表頭插
void SeqListPushFront(SeqList* psl, SLDataType x);
//順序表頭刪
void SeqListPopFront(SeqList* psl);
//順序表查找
int SeqListFind(SeqList* psl, SLDataType x);
//順序表任意位置插入
void SeqListInsert(SeqList* psl, size_t pos, SLDataType x);
//順序表任意位置洗掉
void SeqListErase(SeqList* psl, size_t pos);
//順序表銷毀
void SeqListDestory(SeqList* psl);
//順序表列印
void SeqListPrint(SeqList* psl);
順序表尾插尾刪
尾插有三種情況:順序表沒有空間或空間已滿需擴容,空間未滿直接插入,
尾刪也要考慮到有效元素個數為0的情況,
void SeqListPushBack(SL* ps, SLDataType x) {
CheckCapacity(ps);
ps->data[ps->size] = x;
ps->size++;
}
void SeqListPopBack(SL* ps) {
assert(ps->size > 0)
ps->size--;
}
考慮到特殊情況后,尾插尾刪就很簡單了,
順序表頭插頭刪
void SeqListPushFront(SL* ps, SLDataType x) {
CheckCapacity(ps);
int end = ps->size - 1;
//移動資料
while (end >= 0) {
ps->data[end + 1] = ps->data[end];
end--;
}
//插入
ps->data[0] = x;
ps->size++;
}
void SeqListPopFront(SL* ps) {
assert(ps->size > 0);
int begin = 1;
//移動資料并覆寫
while (begin < ps->size) {
ps->data[begin - 1] = ps->data[begin];
begin++;
}
ps->size--;
}
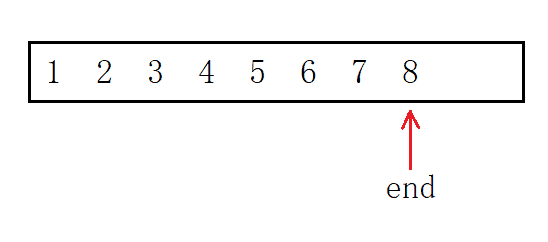
頭插首先將整體也就是下標從0到size-1的元素后移一個位置,為防止內容覆寫,則必須從后向前移,方法是定義“尾指標”,每次減一從后向前遍歷,最后增加一個元素即可,
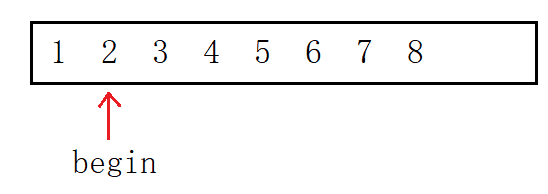
頭刪則是將下標為1到size-1的元素前移一個位置,定義“頭指標”指向第二個元素從前向后遍歷,正好將第一個元素覆寫,
任意位置插入洗掉
void SeqListInsert(SL* ps, int pos, SLDataType x) {
assert(pos >= 0 && pos <= ps->size);
CheckCapacity(ps);
int end = ps->size - 1;
while (end >= pos) {
ps->data[end + 1] = ps->data[end];
end--;
}
ps->data[pos] = x;
ps->size++;
}
void SeqListErase(SL* ps, int pos) {
assert(pos >= 0 && pos < ps->size && ps->size > 0);
int begin = pos + 1;
while (begin < ps->size) {
ps->data[begin - 1] = ps->data[begin];
begin++;
}
ps->size--;
}
指定位置的插入和洗掉其實就是分別把頭插頭刪的最終位置和起始位置換成指定下標pos,當然頭插頭刪也可以用指定位置插入洗掉的方法實作,
其他基本介面
void SeqListInit(SL* ps) {
ps->data = NULL;
ps->size = 0;
ps->capacity = 0;
}
void SeqListDestroy(SL* ps) {
free(ps->data);
ps->data = NULL;
ps->size = 0;
ps->capacity = 0;
}
結構體成員陣列使用的是動態開辟的空間所以記得初始化和銷毀記憶體,因為代碼執行程序中越界編譯器可能不會即使檢測出來,銷毀記憶體同時還有幫助檢測陣列越界的功能,
void CheckCapacity(SL* ps) {
if (ps->size == ps->capacity) {
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
SLDataType* ptr = (SLDataType*)realloc(ps->data, newcapacity * sizeof(SLDataType));
if (ptr == NULL) {
perror("mallocfail");
exit(-1);
}
ps->data = ptr;
ps->capacity = newcapacity;
}
}
不管是尾插,頭插還是任意位置插入都要考慮需擴容的情況,同樣,不管是尾刪,頭刪還是任意位置洗掉都要考慮有效元素個數為0的情況,故可將檢測順序表容量的代碼封裝成函式,以便呼叫,
動態開辟記憶體是有記憶體消耗的,異地擴復制內容也會增加時間消耗,所以盡量每次開辟大一點以減少開辟次數,
realloc開辟記憶體分為“原地擴”和“異地擴”,如果原空間后面有足夠大的空間就原地擴,反之則重新開辟一段空間將原空間的內容復制過去并釋放原空間回傳新空間地址,稱為異地擴,
int SeqListFind(SL* ps, SLDataType x) {
for (int i = 0; i < ps->size; i++) {
if (ps->data[i] == x) {
return i;
}
}
return -1;
}
void SeqListPrint(SL* ps) {
for (int i = 0; i < ps->size; i++) {
printf("%d ", ps->data[i]);
}
printf("\n");
}
陣列面試題
競賽面試普遍采用OJ(Online Judge)的方式,OJ題型分為IO型和介面型,
- IO型,就是輸入輸出函式都由被試者實作,系統進行輸入輸出操作,并檢查程式結果是否實作,
- 介面型,被試者僅需利用系統提供的介面寫出功能函式,由系統自主呼叫,檢查測驗用例是否正確,
Example 1 移除元素
移除元素
移除陣列 nums中所有數值等于 val 的元素,并回傳移除后陣列的新長度,
思路 1
時間復雜度為 O ( N 2 ) O(N^2) O(N2),空間復雜度為 O ( 1 ) O(1) O(1)
int removeElement(int* nums, int numsSize, int val) {
int number = numsSize;
int* pnums = nums;
while (pnums < nums + number) {
if (*pnums == val) {
int begin = pnums - nums;
//begin是該元素的下標,numsSize-begin是該元素之后的元素個數
while (begin < numsSize - 1) {
nums[begin] = nums[begin + 1];
begin++;
}
number--;
}
else {
pnums++;
}
}
return number;
}
思路 2
時間復雜度為 O ( N ) O(N) O(N),空間復雜度為 O ( N ) O(N) O(N)
int removeElement(int* nums, int numsSize, int val) {
int tmp[200] = { 0 };
int j = 0;
//轉移不是val的元素
for (int i = 0; i < numsSize; i++) {
if(nums[i] != val) {
tmp[j] = nums[i];
j++;
}
}
//賦值給nums
for(int i = 0; i < j; i++) {
nums[i] = tmp[i];
}
return j;
}
思路 3
快慢指標,通過指標分別指向,可以用指標也可以用下標的方式,
時間復雜度為 O ( N ) O(N) O(N),空間復雜度為 O ( 1 ) O(1) O(1)
int removeElement(int* nums, int numsSize, int val) {
int* src = nums;
int* dst = nums;
//1. 指標版
while (src - nums < numsSize) {
if (*src != val) {
*dst = *src;
dst++;
}
src++;
//是與不是,src都要++;只有賦值后dst才++
}
return dst - nums;
//2. 下標版
int src = 0, dst = 0;
while(src < numsSize) {
if(nums[src] != val) {
nums[dst] = nums[src];
dst++;
}
src++;
}
return dst;
}
Example 2 陣列去重
陣列去重
洗掉有序陣列 nums 中重復出現的元素,使每個元素只出現一次,回傳洗掉后陣列的新長度,
找到一段相同數字的區間,只留一個,
int removeDuplicates(int* nums, int numsSize) {
int begin = 0, end = 1;
int dst = 1;
if(numsSize == 0) {
return 0;
}
while (end < numsSize) {
if(nums[begin] == nums[end]) {
end++;
}
else {
begin = end;
nums[dst] = nums[begin];
end++;
dst++;
}
}
return dst;
}
Example 3 合并陣列
合并陣列
兩個按非遞減順序排列的整數陣列nums1和nums2,合并nums2到nums1中,使合并后的陣列同樣按非遞減順序排列,
思路 1
開辟新陣列,將兩陣列的元素相比取其小值放入新陣列中,
時間復雜度為 O ( M + N ) O(M+N) O(M+N),空間復雜度為 O ( M + N ) O(M+N) O(M+N)
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {
int i = 0, j = 0, dst = 0;
int nums3[200] = { 0 };
while (i < m && j < n) {
if (nums1[i] <= nums2[j]) {
nums3[dst] = nums1[i];
dst++, i++;
}
else {
nums3[dst] = nums2[j];
dst++, j++;
}
}
//剩余元素
while (i < m) {
nums3[dst] = nums1[i];
dst++, i++;
}
while (j < n) {
nums3[dst] = nums2[j];
dst++, j++;
}
for(int i = 0; i < m + n; i++) {
nums1[i] = nums3[i];
}
}
思路 2
無需開辟新陣列,從大到小比較和移動元素,
時間復雜度為 O ( m i n { m , n } ) O(min\lbrace m,n \rbrace) O(min{m,n}),空間復雜度為 O ( 1 ) O(1) O(1)
void merge(int* nums1, int nums1Size, int m,
int* nums2, int nums2Size, int n) {
int i = m - 1, j = n - 1;
int dst = m + n - 1;
while (i >= 0 && j >= 0) {
if (nums2[j] >= nums1[i]) {
nums1[dst] = nums2[j];
dst--, j--;
}
else {
nums1[dst] = nums1[i];
dst--, i--;
}
}
while (j >= 0) {
nums1[dst] = nums2[j];
dst--, j--;
}
}
比較i和j下標的元素,將其大者放入dst下標的位置,若i先走到0,則將j剩余的元素拷貝到dst,j走到0,標志程式運行結束,

順序表的缺陷
順序表即動態增長的陣列,動態陣列的優缺點是很明顯的,
- 缺點:動態擴容時,有時間消耗且產生記憶體碎片,存在一定程度上的空間浪費,頭部和任意位置的插入洗掉,需要挪動資料,
- 優點:支持隨機訪問,
增刪操作必須要挪動資料,時間消耗不可忽略,這是線性表最大的缺陷,為避免頻繁擴容,倍數擴容也會帶來不可避免的空間浪費,支持隨機訪問是線性表的重要的特點,很多演算法中要求結構支持隨機訪問,如二分查找和快排,
而鏈表利用指標將資料鏈接起來,結點之間不像陣列元素一樣強關聯,
- 優點:按需合理申請空間,不存在空間浪費,增刪結點時無需挪動資料,
- 缺點:結點之間需要通過指標鏈接,不支持隨機訪問,
鏈表不可以通過下標訪問任意結點(即隨機訪問),必須從頭結點開始遍歷,
鏈表
順序表采用線性的結構,連續的空間只需要起始地址就可以訪問所有元素,順序表存在的缺陷是順序表自身特點帶來的不可避免的缺陷,為解決這些問題,就出現了一種新的存盤形式:鏈表,
鏈表的定義及結構
鏈表是一種物理上的非連續、非順序的存盤結構,資料元素的邏輯順序通過鏈表中的指標鏈接次序實作,
- 邏輯結構:為表現資料元素之間的相互關系而想象出的邏輯圖,直觀清晰便于理解,

- 存盤結構:體現了資料在記憶體中的存盤形式,描述的是記憶體中實在的物理物體,又稱物理結構,

當然這也是最簡單的鏈表結構:單鏈表,鏈表包括雙頭鏈表、帶頭不帶頭鏈表、回圈鏈表等等,
單鏈表結構體的定義
typedef int SLTDataType;
typedef struct SListNode {
//資料域
SLTDataType data;
//指標域
struct SListNode* next;
}SLTNode;
單鏈表結構體的定義正凸顯了它的資料結構,每一個結點包含資料域和指標域,資料域用于存盤資料,指標域用于指向下一個結點,通過該指標就可以將所有的結點從頭串到尾,
單鏈表的介面實作
// 動態申請一個結點
SListNode* BuySListNode(SLTDateType x);
// 單鏈表列印
void SListPrint(SListNode* plist);
// 單鏈表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 單鏈表的頭插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 單鏈表的尾刪
void SListPopBack(SListNode** pplist);
// 單鏈表頭刪
void SListPopFront(SListNode** pplist);
// 單鏈表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 單鏈表在pos位置之后插入x
// 分析思考為什么不在pos位置之前插入?
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 單鏈表洗掉pos位置之后的值
// 分析思考為什么不洗掉pos位置?
void SListEraseAfter(SListNode* pos);
單鏈表尾插頭插
由上面單鏈表插入操作可以看出,操作單鏈表只能從頭結點開始遍歷,插入結點后須將前后鏈接起來,
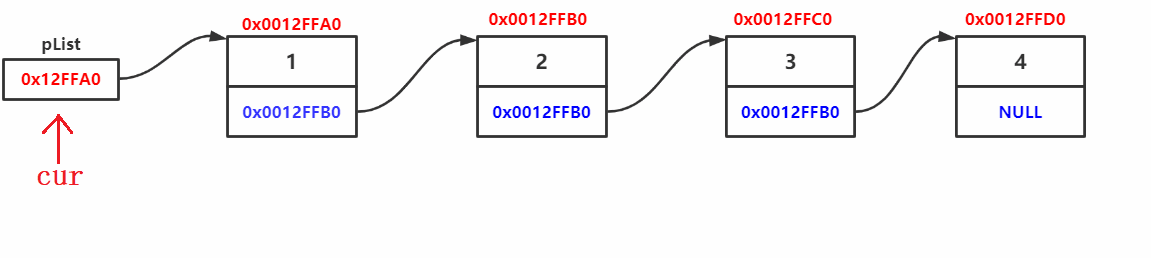
由于插入函式考慮到結點個數為0的情況,會修改實參plist,故傳二級指標&plist,
傳二級指標僅是為解決鏈表為空的情況,也可以選擇使用帶頭結點的方式,只要由頭結點之后再尾插就不會更改
plist,所以就不用傳二級指標,
- 由于單鏈表的特點,尾插必然要申請新結點,再將新結點的地址存入尾結點的指標域,
void SListPushBack(SLTNode** pphead, SLTDataType x) {
SLTNode* newNode = SListNewNode(x);
//無結點
if (*pphead == NULL) {
*pphead = newNode;
}
//有結點
else {
//找尾結點
SLTNode* tail = *pphead;
while (tail->next != NULL) {
tail = tail->next;
}
//尾結點鏈接
tail->next = newNode;
}
}

- 頭插則是申請新節點,先將新結點的地址存入頭指標,再將第二個結點
phead->next存入新結點的指標域,
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newNode = SListNewNode(x);
newNode->next = *pphead;
*pphead = newNode;
}

頭插必然要修改指標
plist的值,故必然要傳頭指標的地址,
插入操作需要考慮鏈表為空的情況,尾插需要遍歷鏈表找尾結點,可能會操作對空指標的解參考,所以要單獨考慮,頭插不會對空指標進行訪問,故頭插不需要單獨考慮,
單鏈表尾刪頭刪
- 尾刪,先釋放尾結點再置空尾指標,然后置空上一個結點的指標域,
//單鏈表尾刪
void SListPopBack(SLTNode** pphead) {
//結點個數=0
assert(*pphead);
//結點個數=1
if ((*pphead)->next == NULL) {
free(*pphead);
*pphead = NULL;
}
//結點個數>1
else {
//找尾結點
SLTNode* tail = *pphead;
//前驅指標
SLTNode* prev = NULL;
while (tail->next != NULL) {
prev = tail;
tail = tail->next;
}
//釋放尾結點
free(tail);
tail = NULL;
//置空前驅結點指標域
prev->next = NULL;
}
}
-
除了將最后一個結點釋放掉還要置空上一個結點的指標域,否則會構成野指標訪問非法記憶體,
-
由于單鏈表的缺陷,不可能通過某結點訪問其上一個結點,所以要定義一個前驅指標,在尾指標后移之前將其賦值給前驅指標,如此前驅指標會保持指向尾指標的前一個結點,
-
只要定義前驅指標就必須要考慮鏈表僅有一個結點的情況,此時不會進入回圈
prev始終是空指標,最后會操作空指標,
while (tail->next->next) { tail = tail->next; } free(tail->next); tail->next = NULL;若嫌定義前驅指標麻煩,可以只定義一個指標,但本質上都是一樣的,仍需考慮結點個數為1的情況,

- 頭刪,先將第二個結點賦值給
tmp,再將頭結點釋放,再將tmp賦值給頭指標,
void SListPopFront(SLTNode** pphead) {
//結點個數為0
assert(*pphead);
//結點個數>=1
SLTNode* tmpNode = (*pphead)->next;
free(*pphead);
*pphead = tmpNode;
}
由于鏈表必須從頭訪問,若先銷毀頭結點則無法向后遍歷,故需要臨時變數暫存第二個結點的地址,

尾刪要考慮到修改頭結點的情況,頭刪必然會改變頭指標,故頭刪尾刪都要傳頭指標的地址,
洗掉操作需要考慮鏈表為空的情況,使用前驅指標需要考慮結點個數為1的情況,否則都會造成對空指標的解參考,
任意位置插入洗掉
//單鏈表隨機前插
void SListInsertForward(SLTNode** pphead, SLTNode* pos, SLTDataType x) {
SLTNode* newNode = SListNewNode(x);
//頭插時
if (pos == *pphead) {
newNode->next = *pphead;
*pphead = newNode;
}
else {
//找前驅結點
SLTNode* prev = *pphead;
while (prev->next != pos) {
prev = prev->next;
}
prev->next = newNode;
newNode->next = pos;
}
}
隨機前插需要pos位置的前驅結點,因其本身特性,單鏈表并不適合隨機前插,更適合隨機后插,前插效率不高也顯得更復雜,C++庫中也沒有前插函式,
//單鏈表隨機后插
void SListInsertAfter(SLTNode* pos, SLTDataType x) {
SLTNode* newNode = SListNewNode(x);
//結點個數為0
if (pos == NULL) {
pos = newNode;
}
else {
newNode->next = pos->next;
pos->next = newNode;
}
}
//查找插入
int main() {
SLTNode* pos = SListFind(plist, 1);
if (pos != NULL) {
SListInsertAfter(pos, 2);
}
SListPrint(plist);
}
其他基本介面
void SListPrint(SLTNode* phead) {
SLTNode* cur = phead;
while (cur != NULL) {
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
SLTNode* SListNewNode(SLTDataType x) {
SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode));
if (newNode == NULL) {
perror("newNode::malloc");
exit(-1);
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}
SLTNode* SListFind(SLTNode* phead, SLTDataType x) {
assert(phead);
while (phead != NULL) {
if (phead->data == x) {
return phead;
}
phead = phead->next;
}
return NULL;
}
int main() {
//回圈查找
SLTNode* pos = plist;
while (pos != NULL) {
pos = SListFind(pos, x);
if (pos != NULL) {
printf("%p-%d-->", pos, pos->data);
pos = pos->next;
}
}
//修改元素
pos = SListFind(pos, 2);
if (pos != NULL) {
pos->data = 3;
}
}
鏈表的分類
單鏈表仍然存在不少的缺陷,單純使用單鏈表的增刪查改意義不大,
- 因其存在缺陷,很多OJ題都考察單鏈表
- 實際中單鏈表更多是作為復雜資料結構的子結構,如哈希桶,鄰接表等,
使用鏈表更多使用雙向鏈表存盤資料,
鏈表面試題
Example 1 移除結點
移除結點
洗掉鏈表中等于給定值val的所有結點,
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* prev = head;
struct ListNode* cur = head;
while (cur != NULL) {
if (cur->val == val) {
if (cur == head) {
head = cur->next;
free(cur);
cur = head;
}
else {
prev->next = cur->next;
free(cur);
cur = prev->next;
}
}
else {
prev = cur;
cur = cur->next;
}
}
return head;
}
Example 2 反轉鏈表
反轉鏈表
反轉一個單鏈表,
struct ListNode* reverseList(struct ListNode* head) {
int i = 0;
int val[5000] = { 0 };
struct ListNode* cur = head;
while (cur) {
val[i] = cur->val;
i++;
cur = cur->next;
}
cur = head;
i--;
while (cur && i >= 0) {
cur->val = val[i];
i--;
cur = cur->next;
}
return head;
}
逆置一個鏈表,不需要真的反轉,只需要把結點的資料逆置即可,將結點的資料存入陣列,再逆序陣列然后依次賦值給各個結點即可,
Example 3 中間結點
中間結點
給定一個帶有頭結點head的非空單鏈表,回傳鏈表的中間結點,如果有兩個中間結點,則回傳第二個中間結點,
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode* cur = head;
int count = 0;
while (cur) {
count++;
cur = cur->next;
}
int i = 0;
cur = head;
while (cur) {
if (i == count / 2) {
head = cur;
return head;
}
i++;
cur = cur->next;
}
return 0;
}
Example 4 輸出結點
輸出結點
輸入一個鏈表,輸出該鏈表中倒數第k個結點,
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k) {
// write code here
int count = 0;
struct ListNode* cur = pListHead;
while (cur) {
count++;
cur = cur->next;
}
cur = pListHead;
while (cur) {
if (count == k) {
return cur;
}
count--;
cur = cur->next;
}
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335457.html
標籤:其他
上一篇:H5實作回應式健身會所網頁設計(web期末大作業原始碼分享)
下一篇:C++入門篇(5)之類和物件總結