python爬取英雄聯盟手游的全英雄皮膚
- 前言
- 分析頁面
- 具體代碼
- 下載工具類
- 獲取英雄串列的每個英雄
- 獲取英雄皮膚鏈接并下載
- 完整代碼
- 成果
- 總結
前言
近期這個鴿了好久的英雄聯盟手游終于上線了,雖然博主不是英雄聯盟端游玩家,但看到這個游戲上線還是超級開心的,受到了一些博主爬王者榮耀皮膚的啟發,我們來試試爬英雄聯盟的皮膚圖片吧,

分析頁面
來到英雄聯盟手游的官網,我們來看看這個英雄串列的展示形式吧
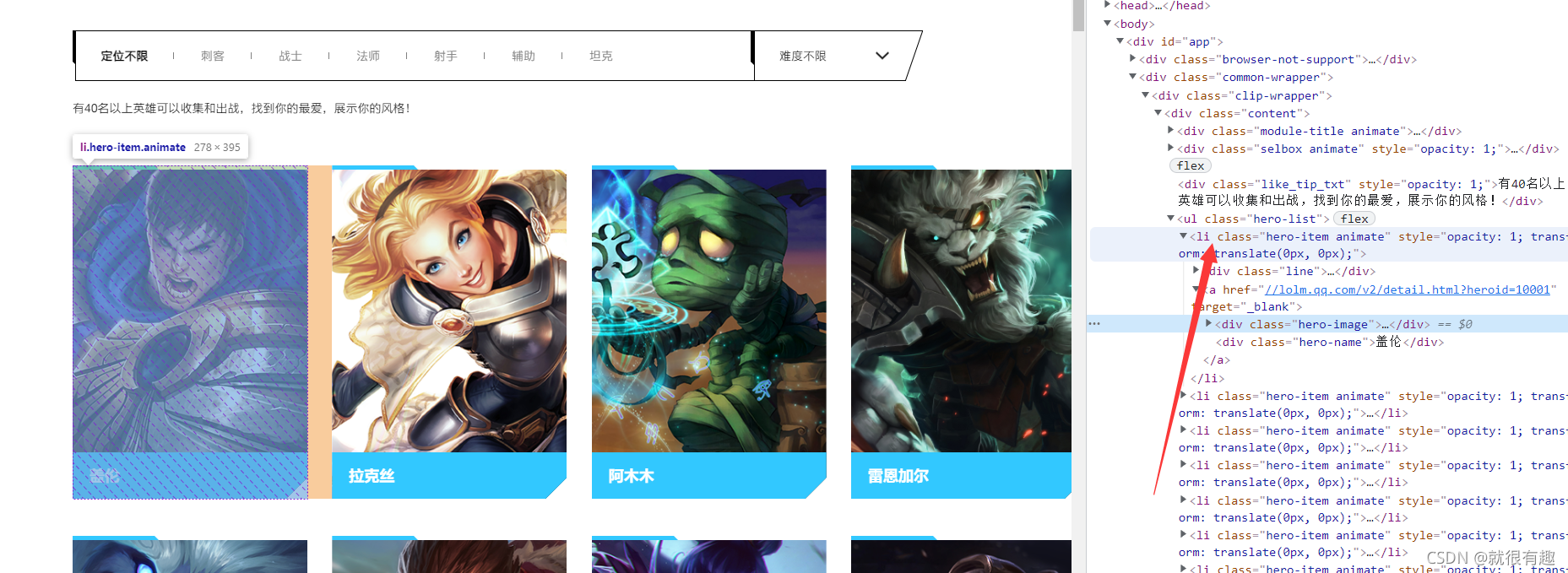
我們發現所有的英雄都是在一個li標簽之下,那么現在的目標就是獲取所有的li標簽就可以,來寫一手xpath
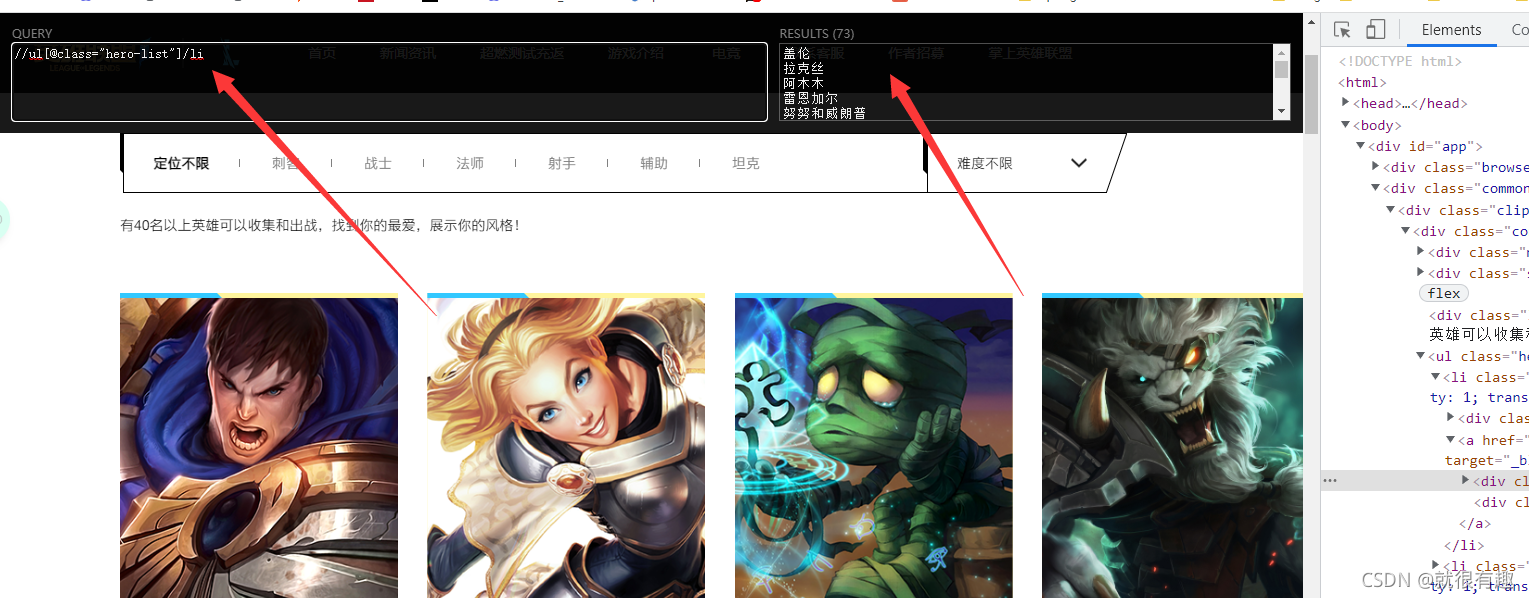
這就直接拿到了,接下來那就是點擊進入英雄詳情頁了,以蓋倫為例,來到下圖頁面

我們的目標是想要拿到黑色箭頭指向的圖片,還是老樣子,打開f12看看頁面結構
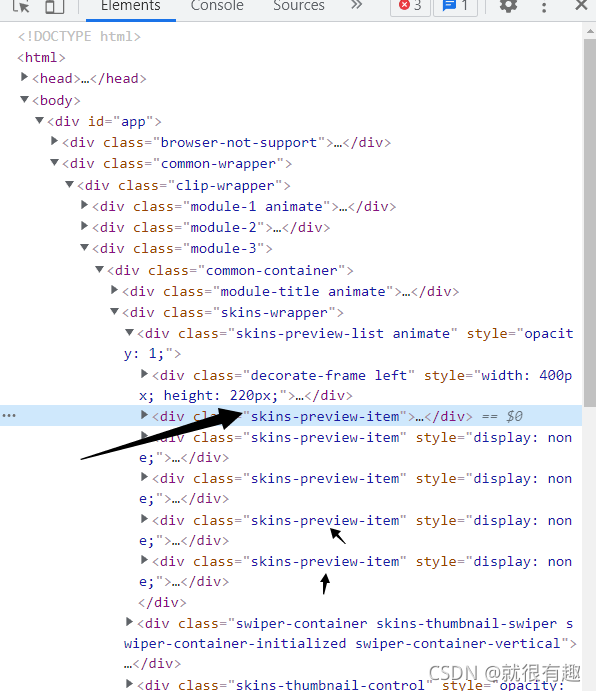
然后我們發現原來這幾個皮膚圖片都是存放在class為“skins-preview-item”的div中,這就很簡單了,拿到鏈接就完事了
xpath如下
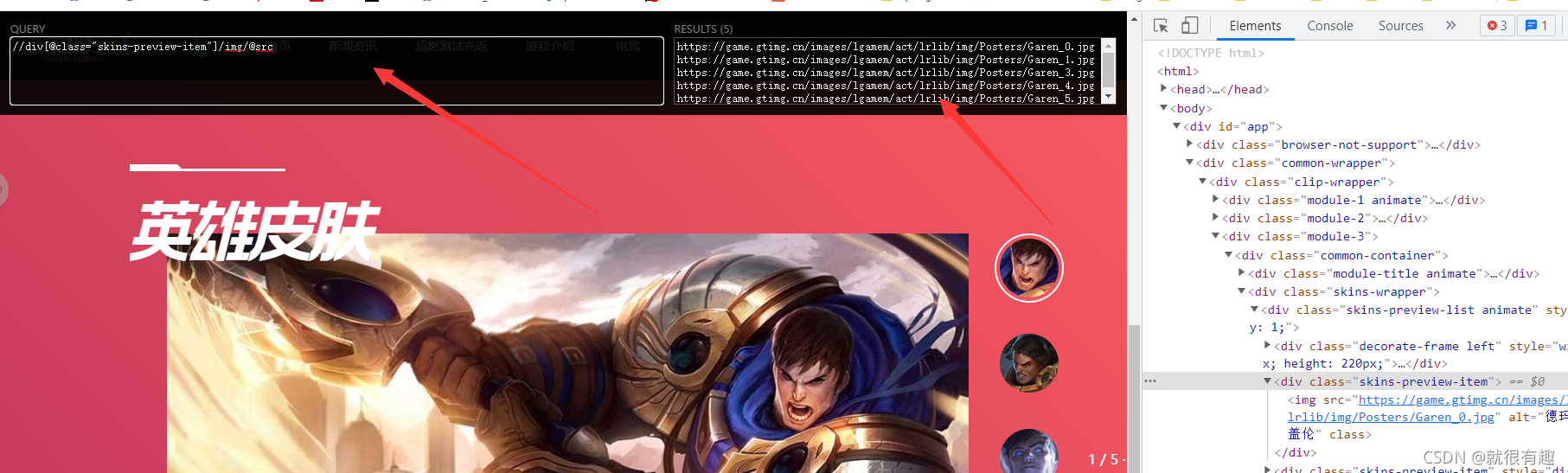
整個流程我們就了解了,那接下來就是快樂的代碼程序了

具體代碼
下載工具類
import os
from concurrent.futures.thread import ThreadPoolExecutor
import requests
import time
def createFolder(src):
os.makedirs(src)
def downloadFile(name, url):
try:
headers = {'Proxy-Connection': 'keep-alive'}
r = requests.get(url, stream=True, headers=headers)
print("=========================")
print(r)
length = float(r.headers['Content-length'])
f = open(name, 'wb')
count = 0
count_tmp = 0
time1 = time.time()
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk) # 寫入檔案
count += len(chunk) # 累加長度
# 計算時間 兩秒列印一次
if time.time() - time1 > 2:
p = count / length * 100
speed = (count - count_tmp) / 1024 / 1024 / 2
count_tmp = count
print(name + ': ' + formatFloat(p) + '%' + ' Speed: ' + formatFloat(speed) + 'M/S')
time1 = time.time()
f.close()
return 1;
except:
print("出現例外")
return 0;
def formatFloat(num):
return '{:.2f}'.format(num)
if __name__ == '__main__':
# 初始化執行緒池
# downloadFile('D://file//photo//hd.jpg',
# 'https://browser9.qhimg.com/bdr/__85/t01753453b660de14e9.jpg')
createFolder(r"E:\file\lol\1")
獲取英雄串列的每個英雄
heros = driver.find_elements(By.XPATH, '//ul[@class="hero-list"]/li')
for hero in heros:
driver.switch_to.window(driver.window_handles[0])
# 點擊來到英雄詳情頁面
hero.click()
獲取英雄皮膚鏈接并下載
skins = driver.find_elements(By.XPATH, '//div[@class="skins-preview-item"]/img')
for i in range(len(skins)):
FileDownload.downloadFile(r'E:\file\lol\{}\{}.jpg'.format(name.text,i),skins[i].get_attribute("src"))
完整代碼
# -*- codeing = utf-8 -*-
# @Time : 2021/10/22 21:43
# @Author : xiaow
# @File : lol.py
# @Software : PyCharm
import time
from api import FileDownload
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ == '__main__':
url = 'https://lolm.qq.com/v2/champions.html'
# 躲避智能檢測
option = webdriver.ChromeOptions()
# option.headless = True
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=option)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
driver.get(url)
# 實作緩慢下滑操作
js = "return action=document.body.scrollHeight"
# 初始化現在滾動條所在高度為0
height = 0
# 當前視窗總高度
new_height = driver.execute_script(js)
heros = driver.find_elements(By.XPATH, '//ul[@class="hero-list"]/li')
for hero in heros:
driver.switch_to.window(driver.window_handles[0])
# 來到英雄詳情頁面
hero.click()
time.sleep(3)
driver.switch_to.window(driver.window_handles[1])
name=driver.find_element(By.XPATH,'//p[@class="heroName_color"]')
print(name.text)
FileDownload.createFolder(r'E:\file\lol\{}'.format(name.text))
skins = driver.find_elements(By.XPATH, '//div[@class="skins-preview-item"]/img')
for i in range(len(skins)):
FileDownload.downloadFile(r'E:\file\lol\{}\{}.jpg'.format(name.text,i),skins[i].get_attribute("src"))
driver.close()
成果
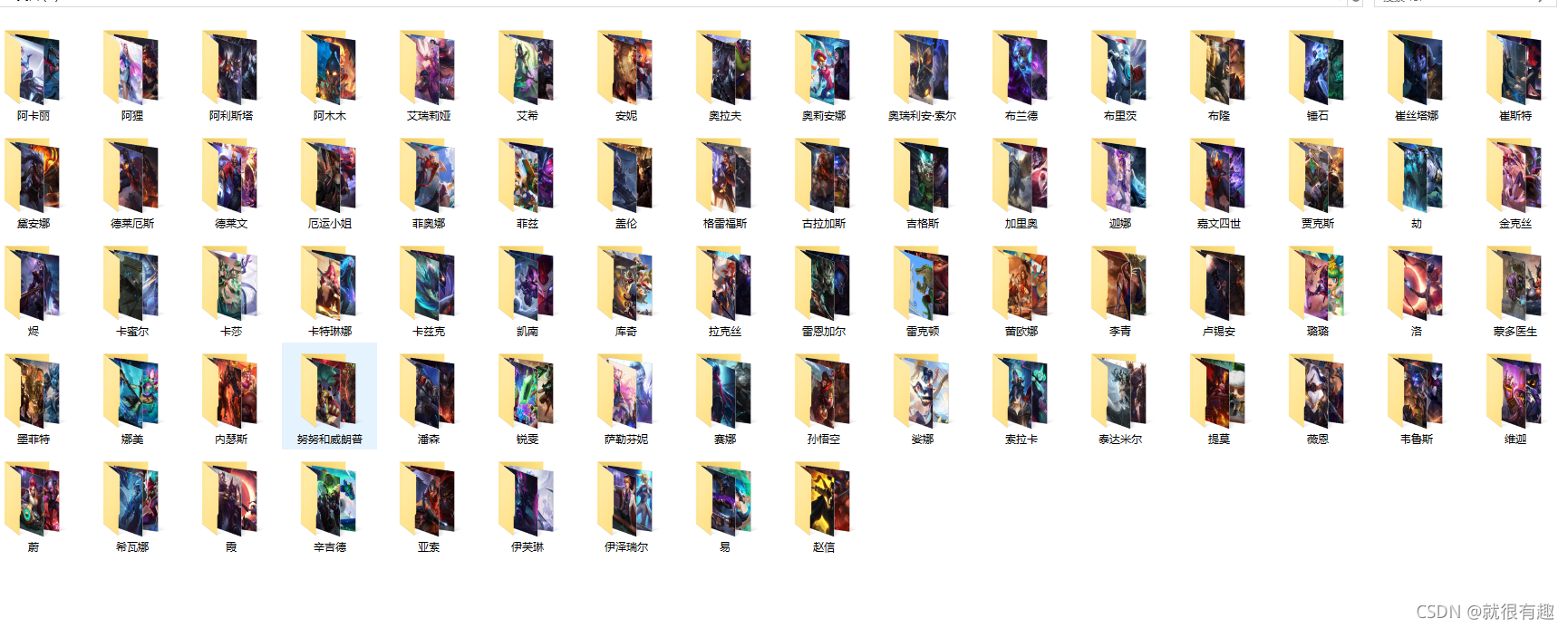
總結
整個程序非常常規并且簡單,兄弟們快來試試吧
僅供學習,侵權必刪
推薦下自己的爬蟲專欄,都是一些入門的爬蟲樣例,有興趣的兄弟們可以來看看,順便點一手關注
??爬蟲專欄,快來點我呀??
另外還有博主的爬蟲博客目錄
爬蟲樣例匯總,快來看看吧

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335459.html
標籤:其他
上一篇:C++入門篇(5)之類和物件總結
下一篇:演算法筆記:摩爾投票法