歡迎關注博客主頁:微信搜:import_bigdata,大資料領域硬核原創作者_王知無(import_bigdata)_CSDN博客
https://blog.csdn.net/u013411339
歡迎點贊、收藏、留言 ,歡迎留言交流!
本文由【王知無】原創,首發于 CSDN博客!
本文首發CSDN論壇,未經過官方和本人允許,嚴禁轉載!
本文是對《【硬剛大資料之學習路線篇】2021年從零到大資料專家的學習指南(全面升級版)》的面試部分補充,
前言
Hive從2008年始于FaceBook工程師之手,經過10幾年的發展至今保持強大的生命力,截止目前Hive已經更新至3.1.x版本,Hive從最開始的為人詬病的速度慢迅速發展,開始支持更多的計算引擎,計算速度大大提升,
本文我們將從原理、應用、調優分別講解Hive所支持的MapReduce、Tez、Spark引擎,
MapReduce引擎
我們在之前的文章中:
-
《硬剛Hive|4萬字基礎調優面試小總結》
-
《當我們在學習Hive的時候在學習什么?「硬剛Hive續集」》
對Hive的MapReduce引擎已經做過非常詳細的講解了,
本文首發自公眾號:《import_bigdata》,大資料技術與架構,
在Hive2.x版本中,HiveSQL會被轉化為MR任務,這也是我們經常說的HiveSQL的執行原理,
我們先來看下 Hive 的底層執行架構圖, Hive 的主要組件與 Hadoop 互動的程序:
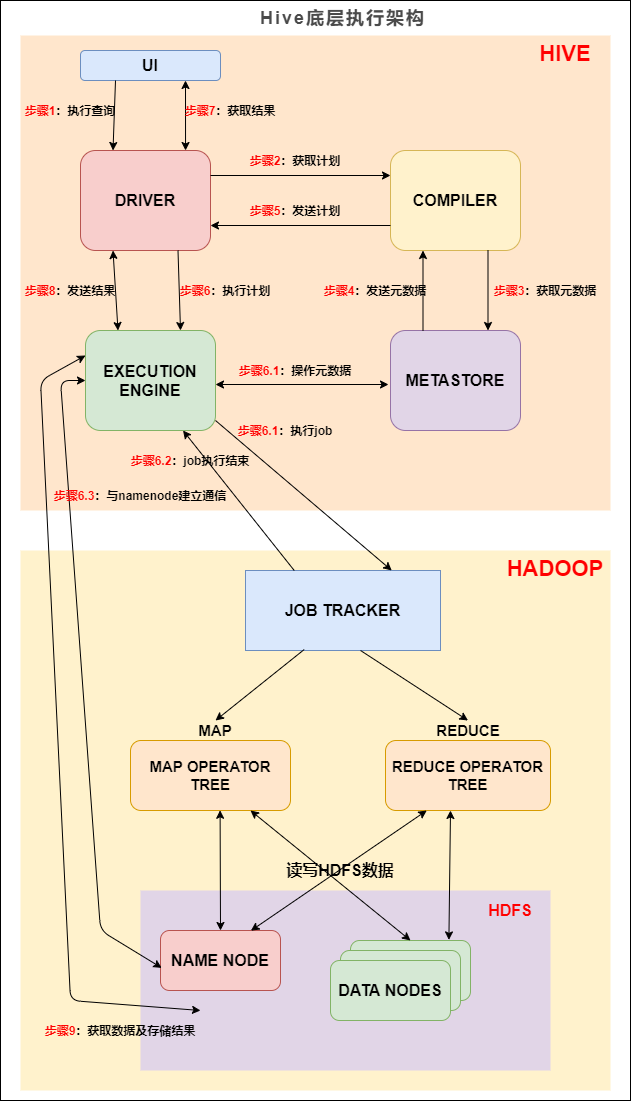
Hive底層執行架構
在 Hive 這一側,總共有五個組件:
-
UI:用戶界面,可看作我們提交SQL陳述句的命令列界面,
-
DRIVER:驅動程式,接收查詢的組件,該組件實作了會話句柄的概念,
-
COMPILER:編譯器,負責將 SQL 轉化為平臺可執行的執行計劃,對不同的查詢塊和查詢運算式進行語意分析,并最終借助表和從 metastore 查找的磁區元資料來生成執行計劃,
-
METASTORE:元資料庫,存盤 Hive 中各種表和磁區的所有結構資訊,
-
EXECUTION ENGINE:執行引擎,負責提交 COMPILER 階段編譯好的執行計劃到不同的平臺上,
上圖的基本流程是:
-
步驟1:UI 呼叫 DRIVER 的介面;
-
步驟2:DRIVER 為查詢創建會話句柄,并將查詢發送到 COMPILER(編譯器)生成執行計劃;
-
步驟3和4:編譯器從元資料存盤中獲取本次查詢所需要的元資料,該元資料用于對查詢樹中的運算式進行型別檢查,以及基于查詢謂詞修建磁區;
-
步驟5:編譯器生成的計劃是分階段的DAG,每個階段要么是 map/reduce 作業,要么是一個元資料或者HDFS上的操作,將生成的計劃發給 DRIVER,
如果是 map/reduce 作業,該計劃包括 map operator trees 和一個 reduce operator tree,執行引擎將會把這些作業發送給 MapReduce :
-
步驟6、6.1、6.2和6.3:執行引擎將這些階段提交給適當的組件,在每個 task(mapper/reducer) 中,從HDFS檔案中讀取與表或中間輸出相關聯的資料,并通過相關算子樹傳遞這些資料,最終這些資料通過序列化器寫入到一個臨時HDFS檔案中(如果不需要 reduce 階段,則在 map 中操作),臨時檔案用于向計劃中后面的 map/reduce 階段提供資料,
-
步驟7、8和9:最終的臨時檔案將移動到表的位置,確保不讀取臟資料(檔案重命名在HDFS中是原子操作),對于用戶的查詢,臨時檔案的內容由執行引擎直接從HDFS讀取,然后通過Driver發送到UI,
Hive SQL 編譯成 MapReduce 程序
美團博客中有一篇非常詳細的博客講解《Hive SQL的編譯程序》,
你可以參考: https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
編譯 SQL 的任務是在上節中介紹的 COMPILER(編譯器組件)中完成的,Hive將SQL轉化為MapReduce任務,整個編譯程序分為六個階段:
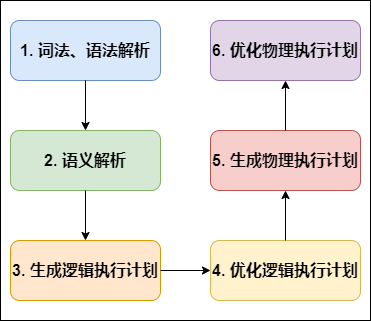
Hive SQL編譯程序
-
詞法、語法決議: Antlr 定義 SQL 的語法規則,完成 SQL 詞法,語法決議,將 SQL 轉化為抽象語法樹 AST Tree;
Antlr是一種語言識別的工具,可以用來構造領域語言,使用Antlr構造特定的語言只需要撰寫一個語法檔案,定義詞法和語法替換規則即可,Antlr完成了詞法分析、語法分析、語意分析、中間代碼生成的程序,
-
語意決議: 遍歷 AST Tree,抽象出查詢的基本組成單元 QueryBlock;
-
生成邏輯執行計劃: 遍歷 QueryBlock,翻譯為執行操作樹 OperatorTree;
-
優化邏輯執行計劃: 邏輯層優化器進行 OperatorTree 變換,合并 Operator,達到減少 MapReduce Job,減少資料傳輸及 shuffle 資料量;
-
生成物理執行計劃: 遍歷 OperatorTree,翻譯為 MapReduce 任務;
-
優化物理執行計劃: 物理層優化器進行 MapReduce 任務的變換,生成最終的執行計劃,
下面對這六個階段詳細決議:
為便于理解,我們拿一個簡單的查詢陳述句進行展示,對5月23號的地區維表進行查詢:
select * from dim.dim_region where dt = '2021-05-23';
階段一:詞法、語法決議
根據Antlr定義的sql語法規則,將相關sql進行詞法、語法決議,轉化為抽象語法樹AST Tree:
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
dim
dim_region
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_ALLCOLREF
TOK_WHERE
=
TOK_TABLE_OR_COL
dt
'2021-05-23'
階段二:語意決議
遍歷AST Tree,抽象出查詢的基本組成單元QueryBlock:
AST Tree生成后由于其復雜度依舊較高,不便于翻譯為mapreduce程式,需要進行進一步抽象和結構化,形成QueryBlock,
QueryBlock是一條SQL最基本的組成單元,包括三個部分:輸入源,計算程序,輸出,簡單來講一個QueryBlock就是一個子查詢,
QueryBlock的生成程序為一個遞回程序,先序遍歷 AST Tree ,遇到不同的 Token 節點(理解為特殊標記),保存到相應的屬性中,
階段三:生成邏輯執行計劃
遍歷QueryBlock,翻譯為執行操作樹OperatorTree:
Hive最終生成的MapReduce任務,Map階段和Reduce階段均由OperatorTree組成,
基本的運算子包括:
TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator`
Operator在Map Reduce階段之間的資料傳遞都是一個流式的程序,每一個Operator對一行資料完成操作后之后將資料傳遞給childOperator計算,
由于Join/GroupBy/OrderBy均需要在Reduce階段完成,所以在生成相應操作的Operator之前都會先生成一個ReduceSinkOperator,將欄位組合并序列化為Reduce Key/value, Partition Key,
階段四:優化邏輯執行計劃
Hive中的邏輯查詢優化可以大致分為以下幾類:
-
投影修剪
-
推導傳遞謂詞
-
謂詞下推
-
將Select-Select,Filter-Filter合并為單個操作
-
多路 Join
-
查詢重寫以適應某些列值的Join傾斜
階段五:生成物理執行計劃
生成物理執行計劃即是將邏輯執行計劃生成的OperatorTree轉化為MapReduce Job的程序,主要分為下面幾個階段:
-
對輸出表生成MoveTask
-
從OperatorTree的其中一個根節點向下深度優先遍歷
-
ReduceSinkOperator標示Map/Reduce的界限,多個Job間的界限
-
遍歷其他根節點,遇過碰到JoinOperator合并MapReduceTask
-
生成StatTask更新元資料
-
剪斷Map與Reduce間的Operator的關系
階段六:優化物理執行計劃
Hive中的物理優化可以大致分為以下幾類:
-
磁區修剪(Partition Pruning)
-
基于磁區和桶的掃描修剪(Scan pruning)
-
如果查詢基于抽樣,則掃描修剪
-
在某些情況下,在 map 端應用 Group By
-
在 mapper 上執行 Join
-
優化 Union,使Union只在 map 端執行
-
在多路 Join 中,根據用戶提示決定最后流哪個表
-
洗掉不必要的 ReduceSinkOperators
-
對于帶有Limit子句的查詢,減少需要為該表掃描的檔案數
-
對于帶有Limit子句的查詢,通過限制 ReduceSinkOperator 生成的內容來限制來自 mapper 的輸出
-
減少用戶提交的SQL查詢所需的Tez作業數量
-
如果是簡單的提取查詢,避免使用MapReduce作業
-
對于帶有聚合的簡單獲取查詢,執行不帶 MapReduce 任務的聚合
-
重寫 Group By 查詢使用索引表代替原來的表
-
當表掃描之上的謂詞是相等謂詞且謂詞中的列具有索引時,使用索引掃描
經過以上六個階段,SQL 就被決議映射成了集群上的 MapReduce 任務,
Explain語法
Hive Explain 陳述句類似Mysql 的Explain 陳述句,提供了對應查詢的執行計劃,對于我們在理解Hive底層邏輯、Hive調優、Hive SQL書寫等方面提供了一個參照,在我們的生產作業了是一個很有意義的工具,
Hive Explain語法
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
Hive Explain的語法規則如上,后面將按照對應的子句進行探討,
EXTENDED 陳述句會在執行計劃中產生關于算子(Operator)的額外資訊,這些資訊都是典型的物理資訊,如檔案名稱等,
在執行Explain QUERY 之后,一個查詢會被轉化為包含多個Stage的陳述句(看起來更像一個DAG),這些Stages要么是map/reduce Stage,要么是做些元資料或檔案系統操作的Stage (如 move 、rename等),Explain的輸出包含2個部分:
-
執行計劃不同Stage之間的以來關系(Dependency)
-
每個Stage的執行描述資訊(Description)
以下將通過一個簡單的例子進行解釋,
執行Explain 陳述句
EXPLAIN
SELECT SUM(id) FROM test1;
Explain輸出結果決議
-
依賴圖
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: test1
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: id
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: sum(id)
mode: hash
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: sum(VALUE._col0)
mode: mergepartial
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
一個HIVE查詢被轉換為一個由一個或多個stage組成的序列(有向無環圖DAG),這些stage可以是MapReduce stage,也可以是負責元資料存盤的stage,也可以是負責檔案系統的操作(比如移動和重命名)的stage,
我們將上述結果拆分看,先從最外層開始,包含兩個大的部分:
-
stage dependencies:各個stage之間的依賴性
-
stage plan:各個stage的執行計劃
先看第一部分 stage dependencies ,包含兩個 stage,Stage-1 是根stage,說明這是開始的stage,Stage-0 依賴 Stage-1,Stage-1執行完成后執行Stage-0,
再看第二部分 stage plan,里面有一個 Map Reduce,一個MR的執行計劃分為兩個部分
-
Map Operator Tree:MAP端的執行計劃樹
-
Reduce Operator Tree:Reduce端的執行計劃樹
這兩個執行計劃樹里面包含這條sql陳述句的 operator
-
TableScan:表掃描操作,map端第一個操作肯定是加載表,所以就是表掃描操作,常見的屬性:
alias:表名稱
Statistics:表統計資訊,包含表中資料條數,資料大小等
-
Select Operator:選取操作,常見的屬性 :
expressions:需要的欄位名稱及欄位型別
outputColumnNames:輸出的列名稱
Statistics:表統計資訊,包含表中資料條數,資料大小等
-
Group By Operator:分組聚合操作,常見的屬性:
aggregations:顯示聚合函式資訊.
mode:聚合模式,值有 hash:隨機聚合,就是hash partition;partial:區域聚合;final:最終聚合.
keys:分組的欄位,如果沒有分組,則沒有此欄位.
outputColumnNames:聚合之后輸出列名.
Statistics:表統計資訊,包含分組聚合之后的資料條數,資料大小等.
-
Reduce Output Operator:輸出到reduce操作,常見屬性:
sort order:值為空 不排序;值為 + 正序排序,值為 - 倒序排序;值為 ± 排序的列為兩列,第一列為正序,第二列為倒序.
-
Filter Operator:過濾操作,常見的屬性:
predicate:過濾條件,如sql陳述句中的where id>=1,則此處顯示(id >= 1).
-
Map Join Operator:join 操作,常見的屬性:
condition map:join方式 ,如Inner Join 0 to 1 Left Outer Join0 to 2
keys: join 的條件欄位
outputColumnNames:join 完成之后輸出的欄位
Statistics:join 完成之后生成的資料條數,大小等
-
File Output Operator:檔案輸出操作,常見的屬性:
compressed:是否壓縮
table:表的資訊,包含輸入輸出檔案格式化方式,序列化方式等
-
Fetch Operator 客戶端獲取資料操作,常見的屬性:
limit,值為 -1 表示不限制條數,其他值為限制的條數
Explain使用場景
那么Explain能夠為我們在生產實踐中帶來哪些便利及解決我們哪些迷惑呢?
本文首發自公眾號:《import_bigdata》,大資料技術與架構,
join 陳述句會過濾 Null 的值嗎?
現在,我們在hive cli 輸入以下查詢計劃陳述句
select a.id,b.user_name from test1 a join test2 b on a.id=b.id;
然后執行:
explain select a.id,b.user_name from test1 a join test2 b on a.id=b.id;
我們來看結果:
TableScan
alias: a
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: _col0
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: int)
1 _col0 (type: int)
...
從上述結果可以看到 predicate: id is not null 這樣一行,說明 join 時會自動過濾掉關聯欄位為 null 值的情況,但 left join 或 full join 是不會自動過濾null值的,大家可以自行嘗試下,
group by 分組陳述句會進行排序嗎?
select id,max(user_name) from test1 group by id;
直接來看 explain 之后結果:
TableScan
alias: test1
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), user_name (type: string)
outputColumnNames: id, user_name
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: max(user_name)
keys: id (type: int)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 9 Data size: 108 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: string)
...
我們看 Group By Operator,里面有 keys: id (type: int) 說明按照 id 進行分組的,再往下看還有 sort order: + ,說明是按照 id 欄位進行正序排序的,
哪條sql執行效率高
觀察如下兩條sql:
SELECT
a.id,
b.user_name
FROM
test1 a
JOIN test2 b ON a.id = b.id
WHERE
a.id > 2;
SELECT
a.id,
b.user_name
FROM
(SELECT * FROM test1 WHERE id > 2) a
JOIN test2 b ON a.id = b.id;
這兩條sql陳述句輸出的結果是一樣的,但是哪條sql執行效率高呢?
有人說第一條sql執行效率高,因為第二條sql有子查詢,子查詢會影響性能; 有人說第二條sql執行效率高,因為先過濾之后,在進行join時的條數減少了,所以執行效率就高了, 到底哪條sql效率高呢,我們直接在sql陳述句前面加上 explain,看下執行計劃不就知道了嘛!
在第一條sql陳述句前加上 explain,得到如下結果:
hive (default)> explain select a.id,b.user_name from test1 a join test2 b on a.id=b.id where a.id >2;
OK
Explain
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_0:a
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_0:a
TableScan
alias: a
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id > 2) (type: boolean)
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: _col0
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: int)
1 _col0 (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id > 2) (type: boolean)
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), user_name (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col2 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
在第二條sql陳述句前加上 explain,得到如下結果:
hive (default)> explain select a.id,b.user_name from(select * from test1 where id>2 ) a join test2 b on a.id=b.id;
OK
Explain
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_0:test1
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_0:test1
TableScan
alias: test1
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id > 2) (type: boolean)
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: _col0
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col0 (type: int)
1 _col0 (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: b
Statistics: Num rows: 6 Data size: 75 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (id > 2) (type: boolean)
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int), user_name (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 2 Data size: 25 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col0 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col2
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col2 (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 27 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
-
大家有什么發現,除了表別名不一樣,其他的執行計劃完全一樣,都是先進行 where 條件過濾,在進行 join 條件關聯,說明 hive 底層會自動幫我們進行優化,所以這兩條sql陳述句執行效率是一樣的,
-
以上僅列舉了3個我們生產中既熟悉又有點迷糊的例子,explain 還有很多其他的用途,如查看stage的依賴情況、排查資料傾斜、hive 調優等,小伙伴們可以自行嘗試,
explain dependency的用法
explain dependency用于描述一段SQL需要的資料來源,輸出是一個json格式的資料,里面包含以下兩個部分的內容:
-
input_partitions:描述一段SQL依賴的資料來源表磁區,里面存盤的是磁區名的串列,如果整段SQL包含的所有表都是非磁區表,則顯示為空,
-
input_tables:描述一段SQL依賴的資料來源表,里面存盤的是Hive表名的串列,
使用explain dependency查看SQL查詢非磁區普通表,在 hive cli 中輸入以下命令:
explain dependency select s_age,count(1) num from student_orc;
得到如下結果:
{"input_partitions":[],"input_tables":[{"tablename":"default@student_tb _orc","tabletype":"MANAGED_TABLE"}]}
使用explain dependency查看SQL查詢磁區表,在 hive cli 中輸入以下命令:
explain dependency select s_age,count(1) num from student_orc_partition;
得到結果:
{"input_partitions":[{"partitionName":"default@student_orc_partition@ part=0"},
{"partitionName":"default@student_orc_partition@part=1"},
{"partitionName":"default@student_orc_partition@part=2"},
{"partitionName":"default@student_orc_partition@part=3"},
{"partitionName":"default@student_orc_partition@part=4"},
{"partitionName":"default@student_orc_partition@part=5"},
{"partitionName":"default@student_orc_partition@part=6"},
{"partitionName":"default@student_orc_partition@part=7"},
{"partitionName":"default@student_orc_partition@part=8"},
{"partitionName":"default@student_orc_partition@part=9"}],
"input_tables":[{"tablename":"default@student_orc_partition", "tabletype":"MANAGED_TABLE"}]
explain dependency的使用場景有兩個:
-
場景一:快速排除,快速排除因為讀取不到相應磁區的資料而導致任務資料輸出例外,例如,在一個以天磁區的任務中,上游任務因為生產程序不可控因素出現例外或者空跑,導致下游任務引發例外,通過這種方式,可以快速查看SQL讀取的磁區是否出現例外,
-
場景二:理清表的輸入,幫助理解程式的運行,特別是有助于理解有多重子查詢,多表連接的依賴輸入,
下面通過兩個案例來看explain dependency的實際運用:
識別看似等價的代碼
有如下兩條看似相等的sql:
代碼一:
select
a.s_no
from student_orc_partition a
inner join
student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and a.part<=2;
代碼二:
select
a.s_no
from student_orc_partition a
inner join
student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part
where a.part>=1 and a.part<=2;
我們看下上述兩段代碼explain dependency的輸出結果:
代碼1的explain dependency結果:
{"input_partitions":
[{"partitionName":"default@student_orc_partition@part=0"},
{"partitionName":"default@student_orc_partition@part=1"},
{"partitionName":"default@student_orc_partition@part=2"},
{"partitionName":"default@student_orc_partition_only@part=1"},
{"partitionName":"default@student_orc_partition_only@part=2"}],
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
代碼2的explain dependency結果:
{"input_partitions":
[{"partitionName":"default@student_orc_partition@part=1"},
{"partitionName" : "default@student_orc_partition@part=2"},
{"partitionName" :"default@student_orc_partition_only@part=1"},
{"partitionName":"default@student_orc_partition_only@part=2"}],
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
通過上面的輸出結果可以看到,其實上述的兩個SQL并不等價,代碼1在內連接(inner join)中的連接條件(on)中加入非等值的過濾條件后,并沒有將內連接的左右兩個表按照過濾條件進行過濾,內連接在執行時會多讀取part=0的磁區資料,而在代碼2中,會過濾掉不符合條件的磁區,
識別SQL讀取資料范圍的差別
有如下兩段代碼:
代碼一:
explain dependency
select
a.s_no
from student_orc_partition a
left join
student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and b.part>=1 and b.part<=2;
代碼二:
explain dependency
select
a.s_no
from student_orc_partition a
left join
student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and a.part<=2;
以上兩個代碼的資料讀取范圍是一樣的嗎?答案是不一樣,我們通過explain dependency來看下:
代碼1的explain dependency結果:
{"input_partitions":
[{"partitionName": "default@student_orc_partition@part=0"},
{"partitionName":"default@student_orc_partition@part=1"}, …中間省略7個磁區
{"partitionName":"default@student_orc_partition@part=9"},
{"partitionName":"default@student_orc_partition_only@part=1"},
{"partitionName":"default@student_orc_partition_only@part=2"}],
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
代碼2的explain dependency結果:
{"input_partitions":
[{"partitionName":"default@student_orc_partition@part=0"},
{"partitionName":"default@student_orc_partition@part=1"}, …中間省略7個磁區
{"partitionName":"default@student_orc_partition@part=9"},
{"partitionName":"default@student_orc_partition_only@part=0"},
{"partitionName":"default@student_orc_partition_only@part=1"}, …中間省略7個磁區
{"partitionName":"default@student_orc_partition_only@part=9"}],
"input_tables": [{"tablename":"default@student_orc_partition","tabletype":"MANAGED_TABLE"}, {"tablename":"default@student_orc_partition_only","tabletype":"MANAGED_TABLE"}]}
可以看到,對左外連接在連接條件中加入非等值過濾的條件,如果過濾條件是作用于右表(b表)有起到過濾的效果,則右表只要掃描兩個磁區即可,但是左表(a表)會進行全表掃描,如果過濾條件是針對左表,則完全沒有起到過濾的作用,那么兩個表將進行全表掃描,這時的情況就如同全外連接一樣都需要對兩個資料進行全表掃描,
在使用程序中,容易認為代碼片段2可以像代碼片段1一樣進行資料過濾,通過查看explain dependency的輸出結果,可以知道不是如此,
explain authorization 的用法
通過explain authorization可以知道當前SQL訪問的資料來源(INPUTS) 和資料輸出(OUTPUTS),以及當前Hive的訪問用戶 (CURRENT_USER)和操作(OPERATION),
在 hive cli 中輸入以下命令:
explain authorization
select variance(s_score) from student_tb_orc;
結果如下:
INPUTS:
default@student_tb_orc
OUTPUTS:
hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194- 90f1475a3ed5/-mr-10000
CURRENT_USER:
hdfs
OPERATION:
QUERY
AUTHORIZATION_FAILURES:
No privilege 'Select' found for inputs { database:default, table:student_ tb_orc, columnName:s_score}
從上面的資訊可知:
-
上面案例的資料來源是defalut資料庫中的 student_tb_orc表;
-
資料的輸出路徑是hdfs://node01:8020/tmp/hive/hdfs/cbf182a5-8258-4157-9194-90f1475a3ed5/-mr-10000;
-
當前的操作用戶是hdfs,操作是查詢;
-
觀察上面的資訊我們還會看到AUTHORIZATION_FAILURES資訊,提示對當前的輸入沒有查詢權限,但如果運行上面的SQL的話也能夠正常運行,為什么會出現這種情況?Hive在默認不配置權限管理的情況下不進行權限驗證,所有的用戶在Hive里面都是超級管理員,即使不對特定的用戶進行賦權,也能夠正常查詢,
Tez引擎
Tez是Apache開源的支持DAG作業的計算框架,是支持HADOOP2.x的重要引擎,它源于MapReduce框架,核心思想是將Map和Reduce兩個操作進一步拆分,分解后的元操作可以任意靈活組合,產生新的操作,這些操作經過一些控制程式組裝后,可形成一個大的DAG作業,
Tez將Map task和Reduce task進一步拆分為如下圖所示:
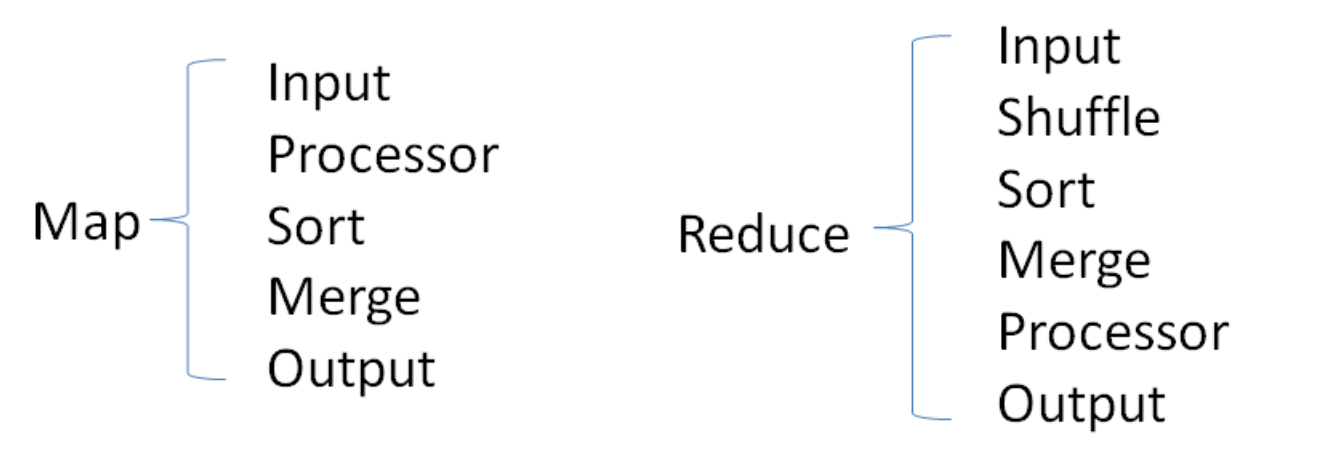
Tez的task由Input、processor、output階段組成,可以表達所有復雜的map、reduce操作,如下圖:
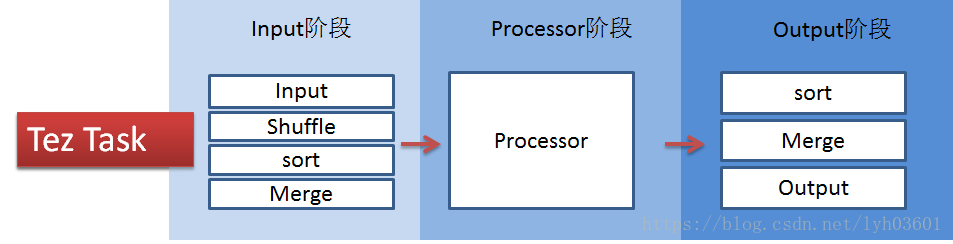
本文首發自公眾號:《import_bigdata》,大資料技術與架構,
Tez的實作
Tez對外提供了6種可編程組件,分別是:
1)Input:對輸入資料源的抽象,它決議輸入資料格式,并吐出一個個Key/value
2)Output:對輸出資料源的抽象,它將用戶程式產生的Key/value寫入檔案系統
3)Paritioner:對資料進行分片,類似于MR中的Partitioner
4)Processor:對計算的抽象,它從一個Input中獲取資料,經處理后,通過Output輸出
5)Task:對任務的抽象,每個Task由一個Input、Ouput和Processor組成
6)Maser:管理各個Task的依賴關系,并按順依賴關系執行他們
除了以上6種組件,Tez還提供了兩種算子,分別是Sort(排序)和Shuffle(混洗),為了用戶使用方便,它還提供了多種Input、Output、Task和Sort的實作,具體如下:
1)Input實作:LocalMergedInput(檔案本地合并后作為輸入),ShuffledMergedInput(遠程拷貝資料且合并后作為輸入)
2)Output實作:InMemorySortedOutput(記憶體排序后輸出),LocalOnFileSorterOutput(本地磁盤排序后輸出),OnFileSortedOutput(磁盤排序后輸出)
3)Task實作:RunTimeTask(非常簡單的Task,基本沒做什么事)
4)Sort實作:DefaultSorter(本地資料排序),InMemoryShuffleSorter(遠程拷貝資料并排序)
為了展示Tez的使用方法和驗證Tez框架的可用性,Apache在YARN MRAppMaster基礎上使用Tez編程介面重新設計了MapReduce框架,使之可運行在YARN中,為此,Tez提供了以下幾個組件:
1)Input:SimpleInput(直接使用MR InputFormat獲取資料)
2)Output:SimpleOutput(直接使用MR OutputFormat獲取資料)
3)Partition:MRPartitioner(直接使用MR Partitioner獲取資料)
4)Processor:MapProcessor(執行Map Task),ReduceProcessor(執行Reduce Task)
5)Task:FinalTask,InitialTask,initialTaskWithInMemSort,InitialTaskWithLocalSort ,IntermediateTask,LocalFinalTask,MapOnlyTask,
對于MapReduce作業而言,如果只有Map Task,則使用MapOnlyTask,否則,Map Task使用InitialTaskWithInMemSort而Reduce Task用FinalTask,當然,如果你想撰寫其他型別的作業,可使用以上任何幾種Task進行組合,比如”InitialTaskWithInMemSort –> FinalTask”是MapReduce作業,
為了減少Tez開發作業量,并讓Tez能夠運行在YARN之上,Tez重用了大部分YARN中MRAppMater的代碼,包括客戶端、資源申請、任務推測執行、任務啟動等,
Tez和MapReduce作業的比較:
-
Tez繞過了MapReduce很多不必要的中間的資料存盤和讀取的程序,直接在一個作業中表達了MapReduce需要多個作業共同協作才能完成的事情,
-
Tez和MapReduce一樣都運行使用YARN作為資源調度和管理,但與MapReduce on YARN不同,Tez on YARN并不是將作業提交到ResourceManager,而是提交到AMPoolServer的服務上,AMPoolServer存放著若干已經預先啟動ApplicationMaster的服務,
-
當用戶提交一個作業上來后,AMPoolServer從中選擇一個ApplicationMaster用于管理用戶提交上來的作業,這樣既可以節省ResourceManager創建ApplicationMaster的時間,而又能夠重用每個ApplicationMaster的資源,節省了資源釋放和創建時間,
Tez相比于MapReduce有幾點重大改進:
-
當查詢需要有多個reduce邏輯時,Hive的MapReduce引擎會將計劃分解,每個Redcue提交一個MR作業,這個鏈中的所有MR作業都需要逐個調度,每個作業都必須從HDFS中重新讀取上一個作業的輸出并重新洗牌,而在Tez中,幾個reduce接收器可以直接連接,資料可以流水線傳輸,而不需要臨時HDFS檔案,這種模式稱為MRR(Map-reduce-reduce*),
-
Tez還允許一次發送整個查詢計劃,實作應用程式動態規劃,從而使框架能夠更智能地分配資源,并通過各個階段流水線傳輸資料,對于更復雜的查詢來說,這是一個巨大的改進,因為它消除了IO/sync障礙和各個階段之間的調度開銷,
-
在MapReduce計算引擎中,無論資料大小,在Shuffle階段都以相同的方式執行,將資料序列化到磁盤,再由下游的程式去拉取,并反序列化,Tez可以允許小資料集完全在記憶體中處理,而MapReduce中沒有這樣的優化,倉庫查詢經常需要在處理完大量的資料后對小型資料集進行排序或聚合,Tez的優化也能極大地提升效率,
給 Hive 換上 Tez 非常簡單,只需給 hive-site.xml 中設定:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
設定hive.execution.engine為 tez 后進入到 Hive 執行 SQL:
hive> select count(*) as c from userinfo;
Query ID = zhenqin_20161104150743_4155afab-4bfa-4e8a-acb0-90c8c50ecfb5
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1478229439699_0007)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 2 2 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 6.19 s
--------------------------------------------------------------------------------
OK
1000000
Time taken: 6.611 seconds, Fetched: 1 row(s)
可以看到,我的 userinfo 中有 100W 條記錄,執行一遍 count 需要 6.19s, 現在把 engine 換為 mr
set hive.execution.engine=mr;
再次執行 count userinfo:
hive> select count(*) as c from userinfo;
Query ID = zhenqin_20161104152022_c7e6c5bd-d456-4ec7-b895-c81a369aab27
Total jobs = 1
Launching Job 1 out of 1
Starting Job = job_1478229439699_0010, Tracking URL = http://localhost:8088/proxy/application_1478229439699_0010/
Kill Command = /Users/zhenqin/software/hadoop/bin/hadoop job -kill job_1478229439699_0010
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-04 15:20:28,323 Stage-1 map = 0%, reduce = 0%
2016-11-04 15:20:34,587 Stage-1 map = 100%, reduce = 0%
2016-11-04 15:20:40,796 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1478229439699_0010
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 215 HDFS Write: 0 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
1000000
Time taken: 19.46 seconds, Fetched: 1 row(s)
hive>
可以看到,使用 Tez 效率比 MapReduce 有近3倍的提升,而且,Hive 在使用 Tez 引擎執行時,有 ==>> 動態的進度指示,而在使用 mr 時,只有日志輸出 map and reduce 的進度百分比,使用 tez,輸出的日志也清爽很多,
在我測驗的很多復雜的 SQL,Tez 的都比 MapReduce 快很多,快慢取決于 SQL 的復雜度,執行簡單的 select 等并不能體現 tez 的優勢,Tez 內部翻譯 SQL 能任意的 Map,Reduce,Reduce 組合,而 MR 只能 Map->Reduce->Map->Reduce,因此在執行復雜 SQL 時, Tez 的優勢明顯,
Tez 引數優化
優化參引數(在同樣條件下,使用了tez從300s+降到200s+)
set hive.execution.engine=tez;
set mapred.job.name=recommend_user_profile_$idate;
set mapred.reduce.tasks=-1;
set hive.exec.reducers.max=160;
set hive.auto.convert.join=true;
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=16;
set hive.optimize.skewjoin=true;
set hive.exec.reducers.bytes.per.reducer=100000000;
set mapred.max.split.size=200000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.hadoop.supports.splittable.combineinputformat=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Tez記憶體優化
1. AM、Container大小設定
tez.am.resource.memory.mb
引數說明:Set tez.am.resource.memory.mb tobe the same as yarn.scheduler.minimum-allocation-mb the YARNminimum container size.
hive.tez.container.size
引數說明:Set hive.tez.container.size to be the same as or a small multiple(1 or 2 times that) of YARN container size yarn.scheduler.minimum-allocation-mb but NEVER more than yarn.scheduler.maximum-allocation-mb.
2. AM、Container JVM引數設定
tez.am.launch.cmd-opts
默認值:80% * tez.am.resource.memory.mb,一般不需要調整
hive.tez.java.ops
默認值:80% * hive.tez.container.size 引數說明:Hortonworks建議"–server –Djava.net.preferIPv4Stack=true–XX:NewRatio=8 –XX:+UseNUMA –XX:UseG1G"
tez.container.max.java.heap.fraction
默認值:0.8,引數說明:task/AM占用JVM Xmx的比例,該引數建議調整,需根據具體業務情況修改;
3. Hive記憶體Map Join引數設定
tez.runtime.io.sort.mb
默認值:100,引數說明:輸出排序需要的記憶體大小,建議值:40% * hive.tez.container.size,一般不超過2G.
hive.auto.convert.join.noconditionaltask
默認值:true,引數說明:是否將多個mapjoin合并為一個,使用默認值
hive.auto.convert.join.noconditionaltask.size
默認值為10MB,引數說明:多個mapjoin轉換為1個時,所有小表的檔案大小總和的最大值,這個值只是限制輸入的表檔案的大小,并不代表實際mapjoin時hashtable的大小, 建議值:1/3 * hive.tez.container.size
tez.runtime.unordered.output.buffer.size-mb
默認值:100,引數說明:Size of the buffer to use if not writing directly to disk,建議值: 10% * hive.tez.container.size.
4. Container重用設定
tez.am.container.reuse.enabled
默認值:true,引數說明:Container重用開關
Spark引擎
Hive社區于2014年推出了Hive on Spark專案(HIVE-7292),將Spark作為繼MapReduce和Tez之后Hive的第三個計算引擎,該專案由Cloudera、Intel和MapR等幾家公司共同開發,并受到了來自Hive和Spark兩個社區的共同關注,通過該專案,可以提高Hive查詢的性能,同時為已經部署了Hive或者Spark的用戶提供了更加靈活的選擇,從而進一步提高Hive和Spark的普及率,
本文首發自公眾號:《import_bigdata》,大資料技術與架構,
總體設計
Hive on Spark總體的設計思路是,盡可能重用Hive邏輯層面的功能;從生成物理計劃開始,提供一整套針對Spark的實作,比如 SparkCompiler、SparkTask等,這樣Hive的查詢就可以作為Spark的任務來執行了,以下是幾點主要的設計原則,
-
盡可能減少對Hive原有代碼的修改,這是和之前的Shark設計思路最大的不同,Shark對Hive的改動太大以至于無法被Hive社區接受,Hive on Spark盡可能少改動Hive的代碼,從而不影響Hive目前對MapReduce和Tez的支持,同時,Hive on Spark保證對現有的MapReduce和Tez模式在功能和性能方面不會有任何影響,
-
對于選擇Spark的用戶,應使其能夠自動的獲取Hive現有的和未來新增的功能,
-
盡可能降低維護成本,保持對Spark依賴的松耦合,
基于以上思路和原則,具體的一些設計架構如下,
Hive 的用戶可以通過hive.execution.engine來設定計算引擎,目前該引數可選的值為mr和tez,為了實作Hive on Spark,我們將spark作為該引數的第三個選項,要開啟Hive on Spark模式,用戶僅需將這個引數設定為spark即可,
在hive中使用以下陳述句開啟:
hive> set hive.execution.engine=spark;
總體設計
Spark 以分布式可靠資料集(Resilient Distributed Dataset,RDD)作為其資料抽象,因此我們需要將Hive的表轉化為RDD以便Spark處理,本質上,Hive的表和Spark的 HadoopRDD都是HDFS上的一組檔案,通過InputFormat和RecordReader讀取其中的資料,因此這個轉化是自然而然的,
Spark為RDD提供了一系列的轉換(Transformation),其中有些轉換也是面向SQL 的,如groupByKey、join等,但如果使用這些轉換(就如Shark所做的那樣),就意味著我們要重新實作一些Hive已有的功能;而且當 Hive增加新的功能時,我們需要相應地修改Hive on Spark模式,有鑒于此,我們選擇將Hive的運算子包裝為Function,然后應用到RDD上,這樣,我們只需要依賴較少的幾種RDD的轉換,而主要的計算邏輯仍由Hive提供,
由于使用了Hive的原語,因此我們需要顯式地呼叫一些Transformation來實作Shuffle的功能,下表中列舉了Hive on Spark使用的所有轉換,
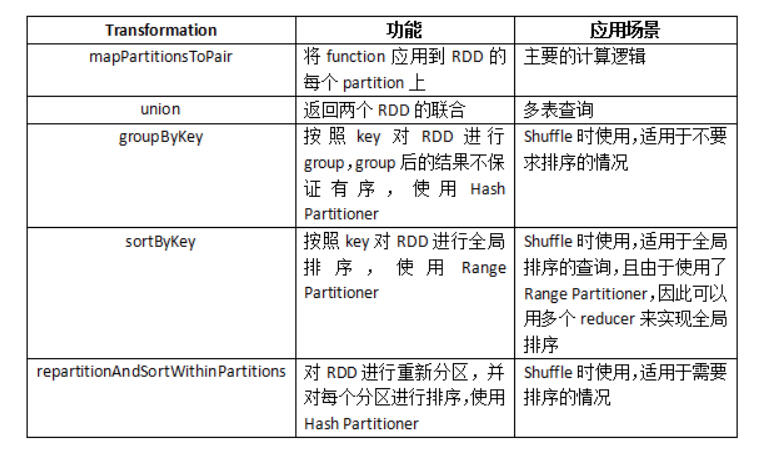
Hive on Spark
對repartitionAndSortWithinPartitions 簡單說明一下,這個功能由SPARK-2978引入,目的是提供一種MapReduce風格的Shuffle,雖然sortByKey也提供了排序的功 能,但某些情況下我們并不需要全域有序,另外其使用的Range Partitioner對于某些Hive的查詢并不適用,
物理執行計劃
通過SparkCompiler將Operator Tree轉換為Task Tree,其中需要提交給Spark執行的任務即為SparkTask,不同于MapReduce中Map+Reduce的兩階段執行模式,Spark采用DAG執行模式,因此一個SparkTask包含了一個表示RDD轉換的DAG,我們將這個DAG包裝為SparkWork,執行SparkTask 時,就根據SparkWork所表示的DAG計算出最終的RDD,然后通過RDD的foreachAsync來觸發運算,使用foreachAsync是因為我們使用了Hive原語,因此不需要RDD回傳結果;此外foreachAsync異步提交任務便于我們對任務進行監控,
SparkContext生命周期
SparkContext 是用戶與Spark集群進行互動的介面,Hive on Spark應該為每個用戶的會話創建一個SparkContext,但是Spark目前的使用方式假設SparkContext的生命周期是Spark應 用級別的,而且目前在同一個JVM中不能創建多個SparkContext,這明顯無法滿足HiveServer2的應用場景,因為多個客戶端需要通過同一個HiveServer2來提供服務,鑒于此,我們需要在單獨的JVM中啟動SparkContext,并通過RPC與遠程的SparkContext進行通信,
任務監控與統計資訊收集
Spark提供了SparkListener介面來監聽任務執行期間的各種事件,因此我們可以實作一個Listener來監控任務執行進度以及收集任務級別的統計信 息(目前任務級別的統計由SparkListener采集,任務進度則由Spark提供的專門的API來監控),另外Hive還提供了Operator級 別的統計資料資訊,比如讀取的行數等,在MapReduce模式下,這些資訊通過Hadoop Counter收集,我們可以使用Spark提供的Accumulator來實作該功能,
細節實作
Hive on Spark決議SQL的程序
SQL陳述句在分析執行程序中會經歷下圖所示的幾個步驟
-
語法決議
-
操作系結
-
優化執行策略
-
交付執行
語法決議
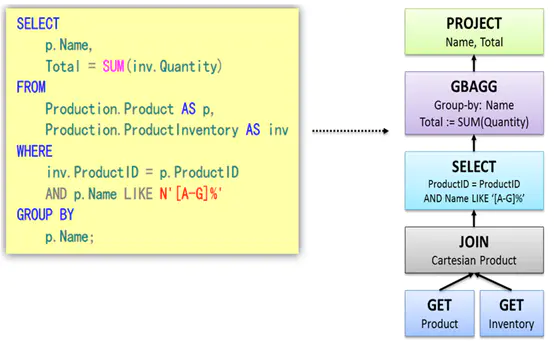
語法決議之后,會形成一棵語法樹,如下圖所示,樹中的每個節點是執行的rule,整棵樹稱之為執行策略,
策略優化
形成上述的執行策略樹還只是第一步,因為這個執行策略可以進行優化,所謂的優化就是對樹中節點進行合并或是進行順序上的調整,
以大家熟悉的join操作為例,下圖給出一個join優化的示例,A JOIN B等同于B JOIN A,但是順序的調整可能給執行的性能帶來極大的影響,下圖就是調整前后的對比圖,
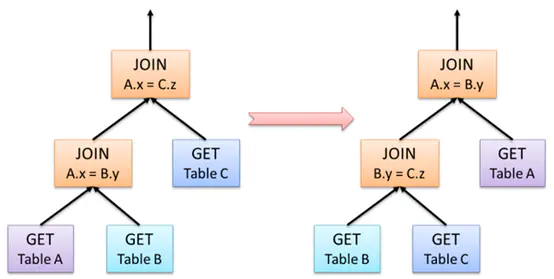
在Hash Join中,首先被訪問的表稱之為“內部構建表”,第二個表為“探針輸入”,創建內部表時,會將資料移動到資料倉庫指向的路徑;創建外部表,僅記錄資料所在的路徑,
再舉一例,一般來說盡可能的先實施聚合操作(Aggregate)然后再join
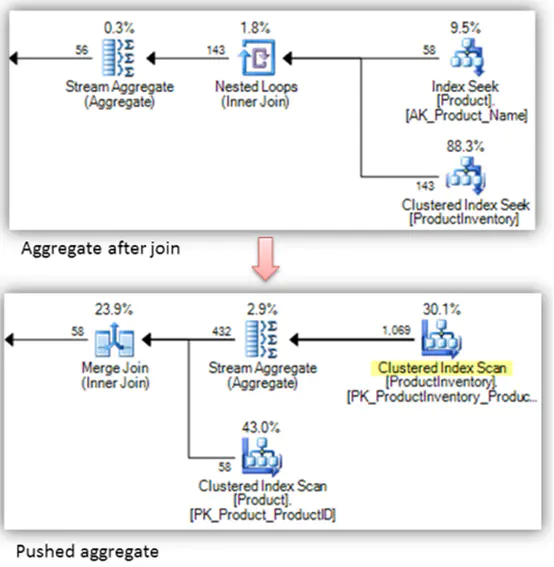
這種優化自動完成,在調優時不需要考慮,
SQL到Spark作業的轉換程序
-
native command的執行流程
由于native command是一些非耗時的操作,直接使用Hive中原有的exeucte engine來執行即可,這些command的執行示意圖如下:

-
SparkTask的生成和執行
我們通過一個例子來看一下一個簡單的兩表JOIN查詢如何被轉換為SparkTask并被執行,下圖左半部分展示了這個查詢的Operator Tree,以及該Operator Tree如何被轉化成SparkTask;右半部分展示了該SparkTask執行時如何得到最終的RDD并通過foreachAsync提交Spark任務,
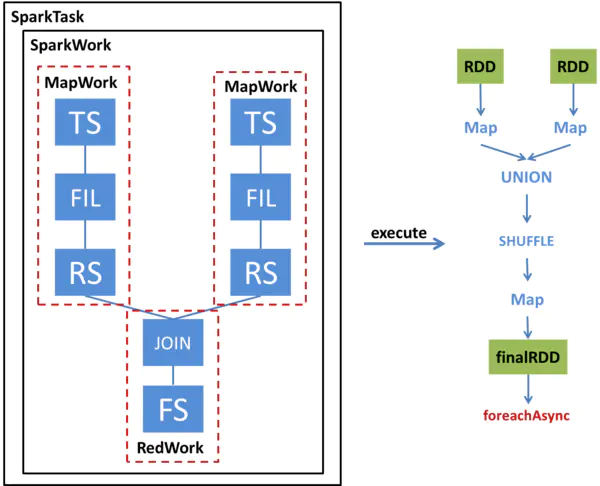
SparkCompiler遍歷Operator Tree,將其劃分為不同的MapWork和ReduceWork,
MapWork為根節點,總是由TableScanOperator(Hive中對表進行掃描的運算子)開始;后續的Work均為ReduceWork,ReduceSinkOperator(Hive中進行Shuffle輸出的運算子)用來標記兩個Work之間的界線,出現ReduceSinkOperator表示當前Work到下一個Work之間的資料需要進行Shuffle,因此,當我們發現ReduceSinkOperator時,就會創建一個新的ReduceWork并作為當前Work的子節點,包含了FileSinkOperator(Hive中將結果輸出到檔案的運算子)的Work為葉子節點,
與MapReduce最大的不同在于,我們并不要求ReduceWork一定是葉子節點,即ReduceWork之后可以鏈接更多的ReduceWork,并在同一個SparkTask中執行,
從該圖可以看出,這個查詢的Operator Tree被轉化成了兩個MapWork和一個ReduceWork,
執行SparkTask步驟:
-
根據MapWork來生成最底層的HadoopRDD,
-
將各個MapWork和ReduceWork包裝成Function應用到RDD上,
-
在有依賴的Work之間,需要顯式地呼叫Shuffle轉換,具體選用哪種Shuffle則要根據查詢的型別來確定,另外,由于這個例子涉及多表查詢,因此在Shuffle之前還要對RDD進行Union,
-
經過這一系列轉換后,得到最終的RDD,并通過foreachAsync提交到Spark集群上進行計算,
在logicalPlan到physicalPlan的轉換程序中,toRdd最關鍵的元素
override lazy val toRdd: RDD[Row] =
analyzed match {
case NativeCommand(cmd) =>
val output = runSqlHive(cmd)
if (output.size == 0) {
emptyResult
} else {
val asRows = output.map(r => new GenericRow(r.split("\t").asInstanceOf[Array[Any]]))
sparkContext.parallelize(asRows, 1)
}
case _ =>
executedPlan.execute().map(_.copy())
}
SparkTask的生成和執行
我們通過一個例子來看一下一個簡單的兩表JOIN查詢如何被轉換為SparkTask并被執行,下圖左半部分展示了這個查詢的Operator Tree,以及該Operator Tree如何被轉化成SparkTask;右半部分展示了該SparkTask執行時如何得到最終的RDD并通過foreachAsync提交Spark任務,
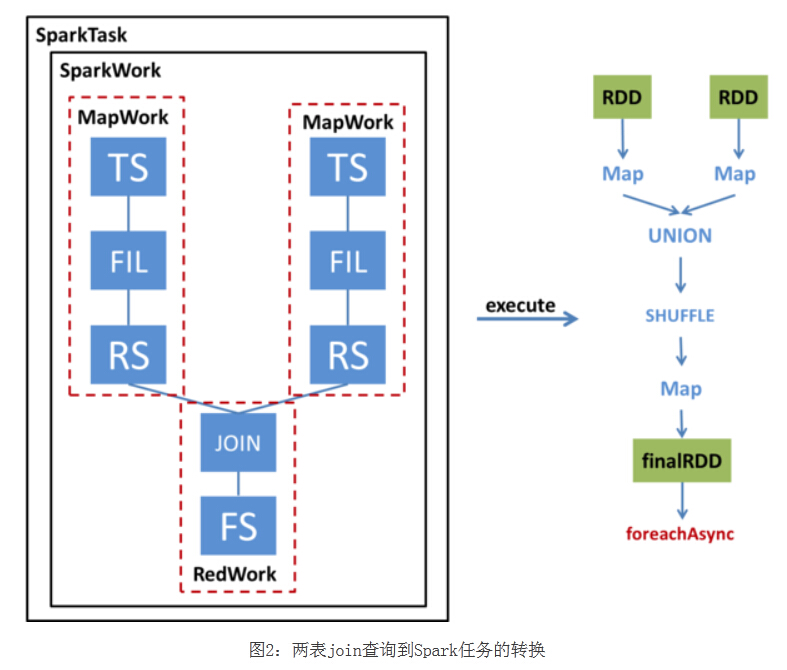
SparkCompiler遍歷Operator Tree,將其劃分為不同的MapWork和ReduceWork,MapWork為根節點,總是由TableScanOperator(Hive中對表 進行掃描的運算子)開始;后續的Work均為ReduceWork,ReduceSinkOperator(Hive中進行Shuffle輸出的運算子) 用來標記兩個Work之間的界線,出現ReduceSinkOperator表示當前Work到下一個Work之間的資料需要進行Shuffle,因此, 當我們發現ReduceSinkOperator時,就會創建一個新的ReduceWork并作為當前Work的子節點,包含了 FileSinkOperator(Hive中將結果輸出到檔案的運算子)的Work為葉子節點,與MapReduce最大的不同在于,我們并不要求 ReduceWork一定是葉子節點,即ReduceWork之后可以鏈接更多的ReduceWork,并在同一個SparkTask中執行,
從該圖可以看出,這個查詢的Operator Tree被轉化成了兩個MapWork和一個ReduceWork,在執行SparkTask時,首先根據MapWork來生成最底層的 HadoopRDD,然后將各個MapWork和ReduceWork包裝成Function應用到RDD上,在有依賴的Work之間,需要顯式地呼叫 Shuffle轉換,具體選用哪種Shuffle則要根據查詢的型別來確定,另外,由于這個例子涉及多表查詢,因此在Shuffle之前還要對RDD進行 Union,經過這一系列轉換后,得到最終的RDD,并通過foreachAsync提交到Spark集群上進行計算,
運行模式
Hive on Spark支持兩種運行模式:本地和遠程,當用戶把Spark Master URL設定為local時,采用本地模式;其余情況則采用遠程模式,本地模式下,SparkContext與客戶端運行在同一個JVM中;遠程模式 下,SparkContext運行在一個獨立的JVM中,提供本地模式主要是為了方便除錯,一般用戶不應選擇該模式,因此我們這里也主要介紹遠程模式 (Remote SparkContext,RSC),下圖展示了RSC的作業原理,
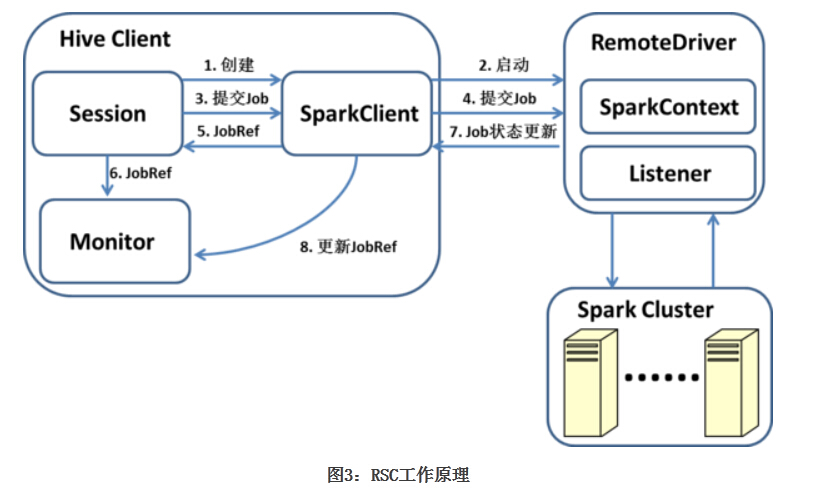
用戶的每個Session會創建一個SparkClient,SparkClient會啟動RemoteDriver行程,并由RemoteDriver創 建SparkContext,SparkTask執行時,通過Session提交任務,任務的主體就是對應的SparkWork,SparkClient 將任務提交給RemoteDriver,并回傳一個SparkJobRef,通過該SparkJobRef,客戶端可以監控任務執行進度,進行錯誤處理, 以及采集統計資訊等,由于最終的RDD計算沒有回傳結果,因此客戶端只需要監控執行進度而不需要處理回傳值,RemoteDriver通過 SparkListener收集任務級別的統計資料,通過Accumulator收集Operator級別的統計資料(Accumulator被包裝為 SparkCounter),并在任務結束時回傳給SparkClient,
SparkClient 與RemoteDriver之間通過基于Netty的RPC進行通信,除了提交任務,SparkClient還提供了諸如添加Jar包、獲取集群資訊等接 口,如果客戶端需要使用更一般的SparkContext的功能,可以自定義一個任務并通過SparkClient發送到RemoteDriver上執 行,
理論上來說,Hive on Spark對于Spark集群的部署方式沒有特別的要求,除了local以外,RemoteDriver可以連接到任意的Spark集群來執行任務,在我 們的測驗中,Hive on Spark在Standalone和Spark on YARN的集群上都能正常作業(需要動態添加Jar包的查詢在yarn-cluster模式下還不能運行,請參考HIVE-9425),
優化
Yarn的配置
yarn.nodemanager.resource.cpu-vcores和yarn.nodemanager.resource.memory-mb,這兩個引數決定這集群資源管理器能夠有多少資源用于運行yarn上的任務, 這兩個引數的值是由機器的配置及同時在機器上運行的其它行程共同決定,本文假設僅有hdfs的datanode和yarn的nodemanager運行于該節點,
-
配置cores
基本配置是datanode和nodemanager各一個核,作業系統兩個核,然后剩下28核配置作為yarn資源,也即是yarn.nodemanager.resource.cpu-vcores=28
-
配置記憶體
對于記憶體,預留20GB給作業系統,datanode,nodemanager,剩余100GB作為yarn資源,也即是 yarn.nodemanager.resource.memory-mb=100*1024
Spark配置
假設Yarn節點機器配置,假設有32核,120GB記憶體,
給Yarn分配資源以后,那就要想著spark如何使用這些資源了,主要配置物件:
execurtor 和driver記憶體,executro配額,并行度,
-
executor記憶體
設定executor記憶體需要考慮如下因素:
-
executor記憶體越多,越能為更多的查詢提供map join的優化,由于垃圾回收的壓力會導致開銷增加,
-
某些情況下hdfs的客戶端不能很好的處理并發寫入,所以過多的核心可能會導致競爭,
為了最大化使用core,建議將core設定為4,5,6(多核心會導致并發問題,所以寫代碼的時候尤其是靜態的鏈接等要考慮并發問題)具體分配核心數要結合yarn所提供的核心數, 由于本文中涉及到的node節點是28核,那么很明顯分配為4的化可以被整除,spark.executor.cores設定為4 不會有多余的核剩下,設定為5,6都會有core剩余, spark.executor.cores=4,由于總共有28個核,那么最大可以申請的executor數是7,總記憶體處以7,也即是 100/7,可以得到每個executor約14GB記憶體,
要知道 spark.executor.memory 和spark.executor.memoryOverhead共同決定著executor記憶體,建議spark.executor.memoryOverhead站總記憶體的 15%-20%, 那么最終spark.executor.memoryOverhead=2G和spark.executor.memory=12G.
根據上面的配置的化,每個主機就可以申請7個executor,每個executor可以運行4個任務,每個core一個task,那么每個task的平均記憶體是 14/4 = 3.5GB,在executor運行的task共享記憶體, 其實,executor內部是用newCachedThreadPool運行task的,
確保spark.executor.memoryOverhead和spark.executor.memory的和不超過yarn.scheduler.maximum-allocation-mb,
-
driver記憶體
對于drvier的記憶體配置,當然也包括兩個引數,
-
spark.driver.memoryOverhead 每個driver能從yarn申請的堆外記憶體的大小,
-
spark.driver.memory 當運行hive on spark的時候,每個spark driver能申請的最大jvm 堆記憶體,該引數結合 spark.driver.memoryOverhead共同決定著driver的記憶體大小,
driver的記憶體大小并不直接影響性能,但是也不要job的運行受限于driver的記憶體. 這里給出spark driver記憶體申請的方案,假設yarn.nodemanager.resource.memory-mb是 X,
-
driver記憶體申請12GB,假設 X > 50GB
-
driver記憶體申請 4GB,假設 12GB < X <50GB
-
driver記憶體申請1GB,假設 1GB < X < 12 GB
-
driver記憶體申請256MB,假設 X < 1GB
這些數值是spark.driver.memory和 spark.driver.memoryOverhead記憶體的總和,對外記憶體站總記憶體的10%-15%, 假設 yarn.nodemanager.resource.memory-mb=100*1024MB,那么driver記憶體設定為12GB,此時 spark.driver.memory=10.5gb和spark.driver.memoryOverhead=1.5gb
注意,資源多少直接對應的是資料量的大小,所以要結合資源和資料量進行適當縮減和增加,
-
executor數
executor的數目是由每個節點運行的executor數目和集群的節點數共同決定,如果你有四十個節點,那么hive可以使用的最大executor數就是 280(40*7). 最大數目可能比這個小點,因為driver也會消耗1core和12GB,
當前假設是沒有yarn應用在跑,
Hive性能與用于運行查詢的executor數量直接相關, 但是,不通查詢還是不通, 通常,性能與executor的數量成比例, 例如,查詢使用四個executor大約需要使用兩個executor的一半時間, 但是,性能在一定數量的executor中達到峰值,高于此值時,增加數量不會改善性能并且可能產生不利影響,
在大多數情況下,使用一半的集群容量(executor數量的一半)可以提供良好的性能, 為了獲得最佳性能,最好使用所有可用的executor, 例如,設定spark.executor.instances = 280, 對于基準測驗和性能測量,強烈建議這樣做,
-
動態executor申請
雖然將spark.executor.instances設定為最大值通常可以最大限度地提高性能,但不建議在多個用戶運行Hive查詢的生產環境中這樣做, 避免為用戶會話分配固定數量的executor,因為如果executor空閑,executor不能被其他用戶查詢使用, 在生產環境中,應該好好計劃executor分配,以允許更多的資源共享,
Spark允許您根據作業負載動態擴展分配給Spark應用程式的集群資源集, 要啟用動態分配,請按照動態分配中的步驟進行操作, 除了在某些情況下,強烈建議啟用動態分配,
-
并行度
要使可用的executor得到充分利用,必須同時運行足夠的任務(并行),在大多數情況下,Hive會自動確定并行度,但也可以在調優并發度方面有一些控制權, 在輸入端,map任務的數量等于輸入格式生成的split數,對于Hive on Spark,輸入格式為CombineHiveInputFormat,它可以根據需要對基礎輸入格式生成的split進行分組, 可以更好地控制stage邊界的并行度,調整hive.exec.reducers.bytes.per.reducer以控制每個reducer處理的資料量,Hive根據可用的executor,執行程式記憶體,以及其他因素來確定最佳磁區數, 實驗表明,只要生成足夠的任務來保持所有可用的executor繁忙,Spark就比MapReduce對hive.exec.reducers.bytes.per.reducer指定的值敏感度低, 為獲得最佳性能,請為該屬性選擇一個值,以便Hive生成足夠的任務以完全使用所有可用的executor,
Hive配置
Hive on spark 共享了很多hive性能相關的配置,可以像調優hive on mapreduce一樣調優hive on spark, 然而,hive.auto.convert.join.noconditionaltask.size是基于統計資訊將基礎join轉化為map join的閾值,可能會對性能產生重大影響, 盡管該配置可以用hive on mr和hive on spark,但是兩者的解釋不同,
資料的大小有兩個統計指標:
-
totalSize- 資料在磁盤上的近似大小
-
rawDataSize- 資料在記憶體中的近似大小
hive on mr用的是totalSize,hive on spark使用的是rawDataSize,由于可能存在壓縮和序列化,這兩個值會有較大的差別, 對于hive on spark 需要將 hive.auto.convert.join.noconditionaltask.size指定為更大的值,才能將與hive on mr相同的join轉化為map join,
可以增加此引數的值,以使地圖連接轉換更具兇猛, 將common join 轉換為 map join 可以提高性能, 如果此值設定得太大,則來自小表的資料將使用過多記憶體,任務可能會因記憶體不足而失敗, 根據群集環境調整此值,
通過引數 hive.stats.collect.rawdatasize 可以控制是否收集 rawDataSize 統計資訊,
對于hiveserver2,建議再配置兩個額外的引數: hive.stats.fetch.column.stats=true 和 hive.optimize.index.filter=true.
Hive性能調優通常建議使用以下屬性:
hive.optimize.reducededuplication.min.reducer=4
hive.optimize.reducededuplication=true
hive.merge.mapfiles=true
hive.merge.mapredfiles=false
hive.merge.smallfiles.avgsize=16000000
hive.merge.size.per.task=256000000
hive.merge.sparkfiles=true
hive.auto.convert.join=true
hive.auto.convert.join.noconditionaltask=true
hive.auto.convert.join.noconditionaltask.size=20M(might need to increase for Spark, 200M)
hive.optimize.bucketmapjoin.sortedmerge=false
hive.map.aggr.hash.percentmemory=0.5
hive.map.aggr=true
hive.optimize.sort.dynamic.partition=false
hive.stats.autogather=true
hive.stats.fetch.column.stats=true
hive.compute.query.using.stats=true
hive.limit.pushdown.memory.usage=0.4 (MR and Spark)
hive.optimize.index.filter=true
hive.exec.reducers.bytes.per.reducer=67108864
hive.smbjoin.cache.rows=10000
hive.fetch.task.conversion=more
hive.fetch.task.conversion.threshold=1073741824
hive.optimize.ppd=true
預啟動YARN容器
在開始新會話后提交第一個查詢時,在查看查詢開始之前可能會遇到稍長的延遲,還會注意到,如果再次運行相同的查詢,它的完成速度比第一個快得多,
Spark執行程式需要額外的時間來啟動和初始化yarn上的Spark,這會導致較長的延遲,此外,Spark不會等待所有executor在啟動作業之前全部啟動完成,因此在將作業提交到群集后,某些executor可能仍在啟動, 但是,對于在Spark上運行的作業,作業提交時可用executor的數量部分決定了reducer的數量,當就緒executor的數量未達到最大值時,作業可能沒有最大并行度,這可能會進一步影響第一個查詢的性能,
在用戶較長期會話中,這個額外時間不會導致任何問題,因為它只在第一次查詢執行時發生,然而,諸如Oozie發起的Hive作業之類的短期繪畫可能無法實作最佳性能,
為減少啟動時間,可以在作業開始前啟用容器預熱,只有在請求的executor準備就緒時,作業才會開始運行,這樣,在reduce那一側不會減少短會話的并行性,
要啟用預熱功能,請在發出查詢之前將hive.prewarm.enabled設定為true,還可以通過設定hive.prewarm.numcontainers來設定容器數量,默認值為10,
預熱的executor的實際數量受spark.executor.instances(靜態分配)或spark.dynamicAllocation.maxExecutors(動態分配)的值限制, hive.prewarm.numcontainers的值不應超過分配給用戶會話的值,
注意:預熱需要幾秒鐘,對于短會話來說是一個很好的做法,特別是如果查詢涉及reduce階段, 但是,如果hive.prewarm.numcontainers的值高于群集中可用的值,則該程序最多可能需要30秒,請謹慎使用預熱,
另外,一個完整調優案例你可以參考: https://blog.csdn.net/u010010664/article/details/77066031
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/335489.html
標籤:其他
上一篇:大資料之hive安裝