文章目錄
- 一、前言
- 二、降維/升維
- 增加非線性
- 跨通道資訊互動
- 三、 應用實體
- 四、卷積計算
- 為什么卷積核都是奇數呢?
一、前言
- 卷積核(convolutional kernel):可以看作對某個區域的加權求和;它是對應區域感知,它的原理是在觀察某個物體時我們既不能觀察每個像素也不能一次觀察整體,而是先從區域開始認識,這就對應了卷積,卷積核的大小一般有1x1,3x3和5x5的尺寸(一般是奇數x奇數),
卷積核的個數就對應輸出的通道數(channels),這里需要說明的是對于輸入的每個通道,輸出每個通道上的卷積核是不一樣的,比如輸入是28x28x192(WxDxK,K代表通道數),然后在3x3的卷積核,卷積通道數為128,那么卷積的引數有3x3x192x128,其中前兩個對應的每個卷積里面的引數,后兩個對應的卷積總的個數(一般理解為,卷積核的權值共享只在每個單獨通道上有效,至于通道與通道間的對應的卷積核是獨立不共享的,所以這里是192x128),
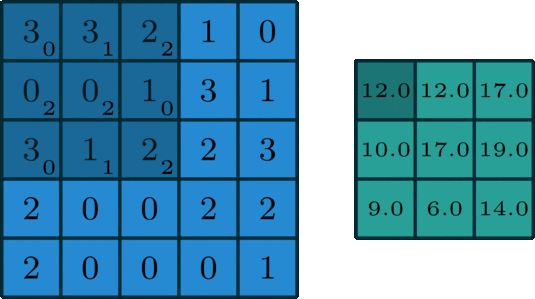
- 池化(pooling):卷積特征往往對應某個區域的特征,要得到global的特征需要將全域的特征執行一個aggregation(聚合),池化就是這樣一個操作,對于每個卷積通道,將更大尺寸(甚至是global)上的卷積特征進行pooling就可以得到更有全域性的特征,這里的pooling當然就對應了cross region,
與1x1的卷積相對應,而1x1卷積可以看作一個cross channel的pooling操作,pooling的另外一個作用就是升維或者降維,后面我們可以看到1x1的卷積也有相似的作用,
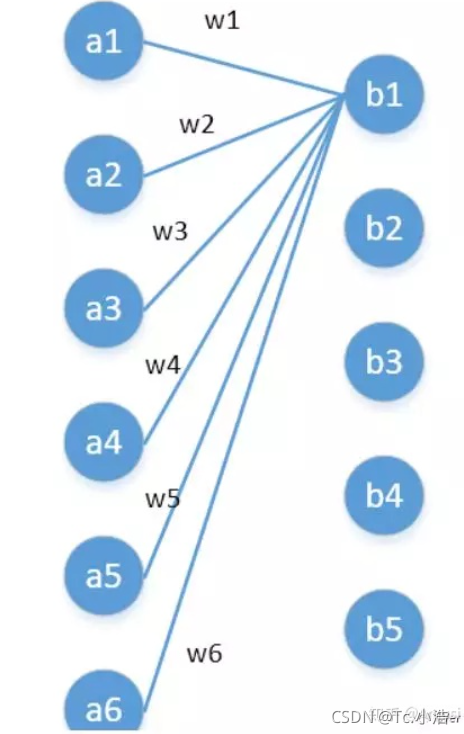
第一層有6個神經元,分別是a1—a6,通過全連接之后變成5個,分別是b1—b5,第一層的六個神經元要和后面五個實作全連接,本圖中只畫了a1—a6連接到b1的示意,可以看到,在全連接層b1其實是前面6個神經元的加權和,權對應的就是w1—w6,到這里就很清晰了,
第一層的6個神經元其實就相當于輸入特征里面那個通道數:6,而第二層的5個神經元相當于1*1卷積之后的新的特征通道數:5,
w1—w6是一個卷積核的權系數,若要計算b2—b5,顯然還需要4個同樣尺寸的卷積核,
二、降維/升維
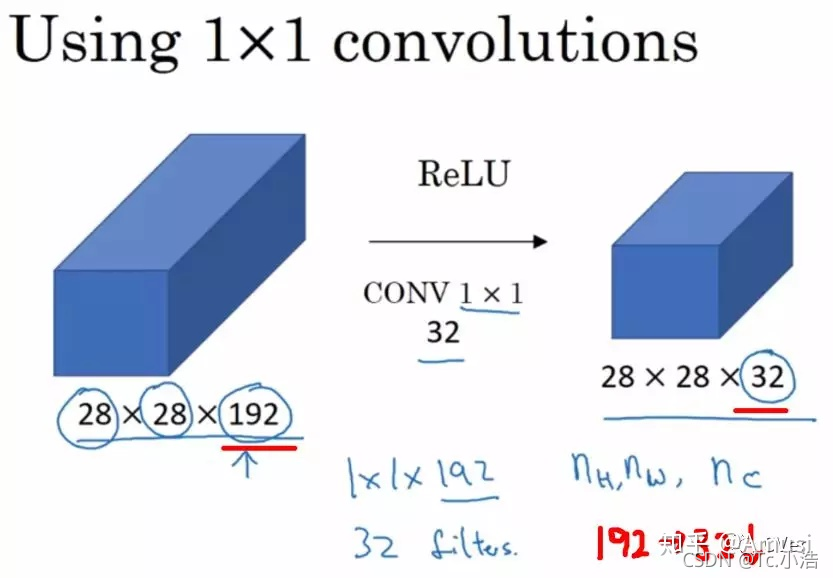
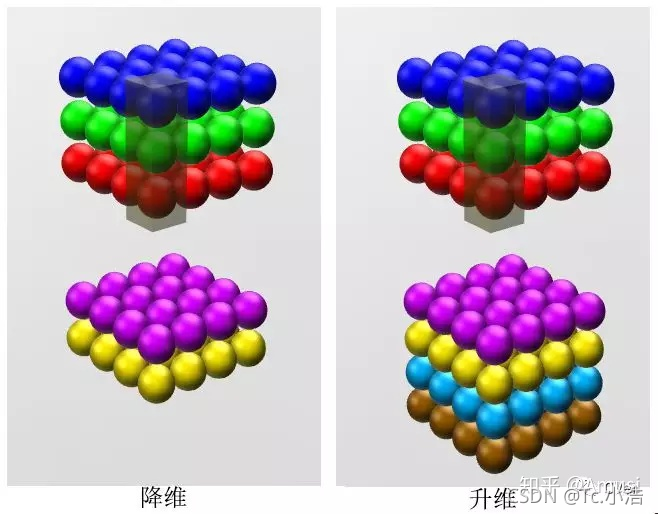
由于 1×1 并不會改變 height 和 width,改變通道的第一個最直觀的結果,就是可以將原本的資料量進行增加或者減少,這里看其他文章或者博客中都稱之為升維、降維,
增加非線性
1*1卷積核,可以在保持feature map尺度不變的(即不損失解析度)的前提下大幅增加非線性特性(利用后接的非線性激活函式),把網路做的很deep,
備注:一個filter對應卷積后得到一個feature map,不同的filter(不同的weight和bias),卷積以后得到不同的feature map,提取不同的特征,得到對應的specialized neuron,
跨通道資訊互動
使用1x1卷積核,實作降維和升維的操作其實就是channel間資訊的線性組合變化,3x3x64channels的輸入后面添加一個1x1x28channels的卷積核,就變成了3x3x28channels的輸出,原來的64個channels就可以理解為跨通道線性組合變成了28channels,這就是通道間的資訊互動,
注意:只是在channel維度上做線性組合,W和H上是共享權值的sliding window
三、 應用實體
ResNet
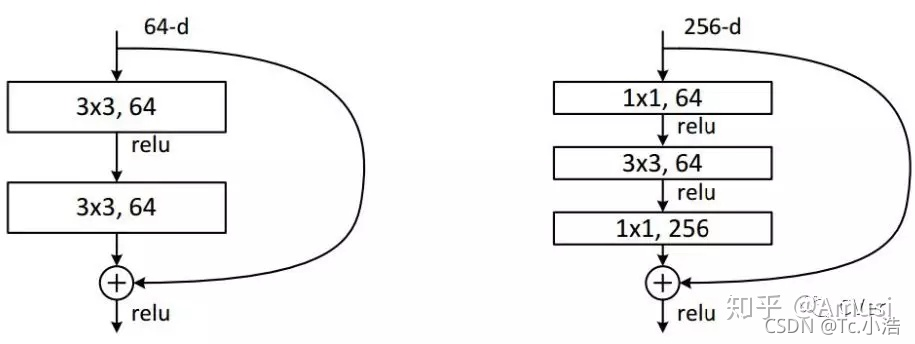
ResNet同樣也利用了1×1卷積,并且是在3×3卷積層的前后都使用了,不僅進行了降維,還進行了升維,引數數量進一步減少,如上圖的結構,
其中右圖又稱為”bottleneck design”,目的一目了然,就是為了降低引數的數目,第一個1x1的卷積把256維channel降到64維,然后在最后通過1x1卷積恢復,整體上用的引數數目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的話就是兩個3x3x256的卷積,引數數目: 3x3x256x256x2 = 1179648,差了16.94倍,
對于常規ResNet,可以用于34層或者更少的網路中,對于Bottleneck Design的ResNet通常用于更深的如101這樣的網路中,目的是減少計算和引數量(實用目的),
四、卷積計算
我們現在知道如何處理卷積中的深度,讓我們繼續討論如何處理其他兩個方向(高度和寬度)的卷積,以及重要的卷積演算法,
- 卷積核大小:卷積核大小決定了卷積的感受野大小,
- 步長:它定義了卷積核掃過特征圖時的步長大小,步長為1表示卷積核逐個掃過特征圖的像素,步長為2表示卷積核以每步移動2個像素(即跳過一個元素)掃描特征圖,我們可以用步長(>=2)對特征圖進行向下采樣,
- 填充:它定義了如何處理特征圖的邊框,如果必要的話,在輸入邊界進行全0填充,填充卷積(Tersorflow中padding=‘same’)將保持輸出和輸入的特征圖尺寸相同,另一方面,完全不使用填充的卷積( Tersorflow中padding=‘valid’)只對輸入的像素執行卷積,而不在輸入邊界填充0,輸出的特征圖尺寸小于輸入的特征圖尺寸,
下圖展示了一個卷積核大小為3、步長為1和填充為1的二維卷積,
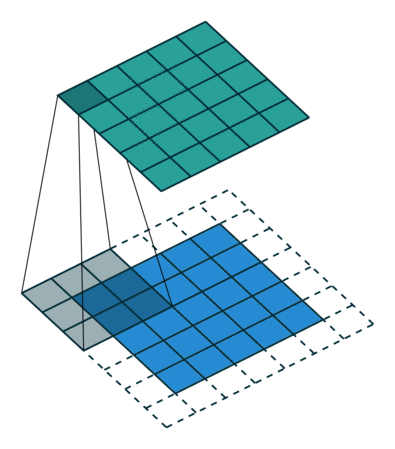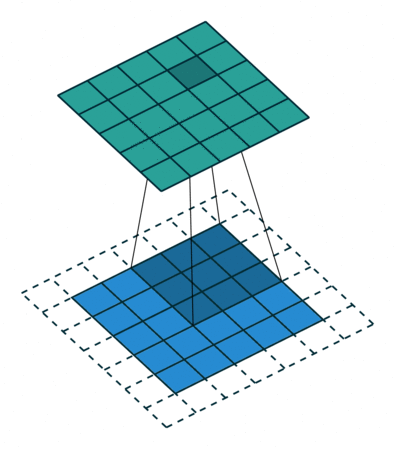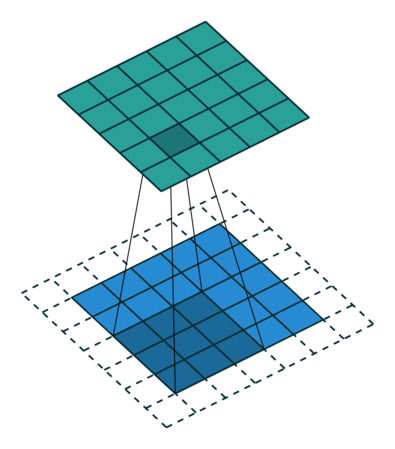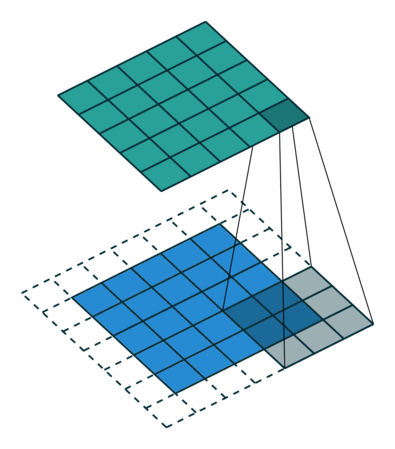
對于尺寸為i、卷積核大小為k、填充為p、步長為s的輸入圖像,卷積后的輸出影像尺寸o:
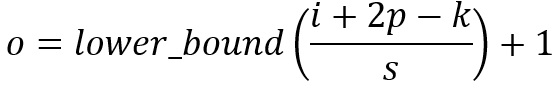
為什么卷積核都是奇數呢?
- 更容易padding:
在卷積時,我們有時候需要卷積前后的尺寸不變,這時候我們就需要用到padding,假設影像的大小,也就是被卷積物件的大小為n×n,卷積核大小為k,padding設定為 (k-1)/2時,我們由計算公式可知 o=(n-k+2((k-1)/2))/1 +1 = n ,即保證了卷積輸出也為n×n,保證了卷積前后尺寸不變,
但是如果k是偶數的話,(k-1)/2就不是整數了, - 更容易找到卷積錨點
在CNN中,進行卷積操作時一般會以卷積核模塊的一個位置為基準進行滑動,這個基準通常就是卷積核模塊的中心,若卷積核為奇數,卷積錨點很好找,自然就是卷積模塊中心,但如果卷積核是偶數,這時候就沒有辦法確定了,讓誰是錨點似乎都不怎么好,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336156.html
標籤:AI
下一篇:深度學習分布式訓練小結