學習總結
(1)隨機森林中的隨機主要來自三個方面:
- 其一為bootstrap抽樣導致的訓練集隨機性,
- 其二為每個節點隨機選取特征子集進行不純度計算的隨機性,
- 其三為當使用隨機分割點選取時產生的隨機性(此時的隨機森林又被稱為Extremely Randomized Trees),
(2)孤立森林演算法類比在切蛋糕,點密度稠密的一塊需要切很多刀才能分割完,而那些很早能分割完的應該是例外點(我們要把每個點都單獨存在一個子空間中),
孤立森林通過隨機選擇特征,然后隨機選擇特征的分割值,遞回地生成資料集的磁區,和資料集中「正常」的點相比,要隔離的例外值所需的隨機磁區更少,因此例外值是樹中路徑更短的點,路徑長度是從根節點經過的邊數,
【內容概要】理解隨機森林的訓練和預測流程,特征重要性和oob得分計算,孤立森林的原理以及訓練和預測流程
【打卡內容】側邊欄練習,知識回顧后三題,實作孤立森林演算法和用于分類的隨機森林演算法(可以用sklearn的決策樹或task2中自己實作的分類cart樹)
文章目錄
- 學習總結
- 一、隨機森林
- 1.1 演算法介紹
- 1.2 Totally Random Trees Embedding
- 二、孤立森林
- 2.1 例外得分的計算
- 2.2 限定樹的高度
- 2.3 訓練與預測
- 三、作業
- 5.1 什么是隨機森林的oob得分?
- 5.2 隨機森林是如何集成多個決策樹模型的?
- 5.3 敘述孤立森林的演算法原理和流程,
- 5.4 實作孤立森林演算法
- 5.5 實作用于分類的隨機森林演算法
- 5.6 隨機森林的主要引數
- (1)RF框架的引數
- (2)RF決策樹的引數
- Reference
一、隨機森林
1.1 演算法介紹
隨機森林是以決策樹(常用CART樹)為基學習器的bagging演算法,
(1)隨機森林當處理回歸問題時,輸出值為各學習器的均值;
(2)隨機森林當處理分類問題時有兩種策略:
- 第一種是原始論文中使用的投票策略,即每個學習器輸出一個類別,回傳最高預測頻率的類別;
- 第二種是sklearn中采用的概率聚合策略,即通過各個學習器輸出的概率分布先計算樣本屬于某個類別的平均概率,在對平均的概率分布取 arg ? max ? \arg\max argmax以輸出最可能的類別,
隨機森林中的隨機主要來自三個方面:
- 其一為bootstrap抽樣導致的訓練集隨機性,
- 其二為每個節點隨機選取特征子集進行不純度計算的隨機性,
- 其三為當使用隨機分割點選取時產生的隨機性(此時的隨機森林又被稱為Extremely Randomized Trees),
隨機森林中特征重要性的計算方式為:利用相對資訊增益來度量單棵樹上的各特征特征重要性(與決策樹計算方式一致),再通過對所有樹產出的重要性得分進行簡單平均來作為最終的特征重要性,
【練習】
r2_score和均方誤差的區別是什么?它具有什么優勢?
r2_score是判定系數:回歸模型的方差系數,
r2_score的計算公式如下:(本質上是以均值模型作為baseline model,計算該模型相較于它的好壞) R 2 ( y , y ^ ) = 1 ? ∑ i = 0 n ? 1 ( y i ? y i ^ ) 2 ∑ i = 0 n ? 1 ( y i ? y  ̄ ) 2 R^2(y,\hat{y})=1-\frac{\sum_{i=0}^{n-1}(y_i-\hat{y_i})^2}{\sum_{i=0}^{n-1}(y_i-\overline{y})^2} R2(y,y^?)=1?∑i=0n?1?(yi??y?)2∑i=0n?1?(yi??yi?^?)2??MSE是均方誤差,即線性回歸的損失函式,計算公式如下: M S E ( y , y ^ ) = 1 n ∑ i = 0 n ? 1 ( y i ? y ^ i ) 2 MSE(y,\hat{y})=\frac{1}{n}\sum_{i=0}^{n-1}(y_i-\hat{y}_i)^2 MSE(y,y^?)=n1?i=0∑n?1?(yi??y^?i?)2?其中分子是訓練出的模型的所有誤差,分母是使用y真=y真平均 預測產生的誤差,
二者的區別是 R 2 ( y , y ^ ) = 1 ? M S E ( y , y ^ ) σ 2 R^2(y,\hat{y})=1-\frac{MSE(y,\hat{y})}{\sigma^2} R2(y,y^?)=1?σ2MSE(y,y^?)??,其中 σ \sigma σ表示y的標準差???,
MSE是帶量綱的,而且結果為量綱的平方,而r2_score是不帶量綱的,可以比較模型在不同量綱資料(不同問題)上的好壞,
【oob樣本】:在訓練時,一般而言我們總是需要對資料集進行訓練集和驗證集的劃分,但隨機森林由于每一個基學習器使用了重復抽樣得到的資料集進行訓練,因此總存在比例大約為 e ? 1 e^{-1} e?1的資料集沒有參與訓練,這一部分資料稱為out-of-bag樣本(即oob樣本),
對每一個基學習器訓練完畢后,我們都對oob樣本進行預測,每個樣本對應的oob_prediction_值為所有沒有采樣到該樣本進行訓練的基學習器預測結果均值,這一部分的邏輯參見此處的原始碼實作,
在得到所有樣本的oob_prediction_后:
(1)對于回歸問題,使用r2_score來計算對應的oob_score_;
(2)而對于分類問題,直接使用accuracy_score來計算oob_score_,
1.2 Totally Random Trees Embedding
介紹一種Totally Random Trees Embedding方法,它能夠基于每個樣本在各個決策樹上的葉節點位置,得到一種基于森林的樣本特征嵌入,
【栗子】假設現在有4棵樹且每棵樹有4個葉子節點(共16個節點),依次對它們進行從0至15的編號,記樣本 i i i在4棵樹葉子節點的位置編號為 [ 0 , 7 , 8 , 14 ] [0,7,8,14] [0,7,8,14],樣本 j j j的編號為 [ 1 , 7 , 9 , 13 ] [1,7,9,13] [1,7,9,13],此時這兩個樣本的嵌入向量即為 [ 1 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 ] [1,0,0,0,0,0,0,1,1,0,0,0,0,0,1,0] [1,0,0,0,0,0,0,1,1,0,0,0,0,0,1,0]和 [ 0 , 1 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 0 ] [0,1,0,0,0,0,0,1,0,1,0,0,0,1,0,0] [0,1,0,0,0,0,0,1,0,1,0,0,0,1,0,0]
假設樣本 k k k對應的編號為 [ 0 , 6 , 8 , 14 ] [0,6,8,14] [0,6,8,14],那么其對應嵌入向量的距離應當和樣本 i i i 較近,而離樣本 j j j 較遠,即兩個樣本在不同樹上分配到相同的葉子結點次數越多,則越接近,因此,這個方法巧妙地利用樹結構獲得了樣本的隱式特征,
【練習】假設使用閔氏距離來度量兩個嵌入向量之間的距離,此時對葉子節點的編號順序會對距離的度量結果有影響嗎?
沒有關系,
閔式距離為: D ( x , y ) = ( ∑ u = 1 n ∣ x u ? y u ∣ p ) 1 p D(x,y)=(\sum_{u=1}^n|x_u-y_u|^p)^{\frac{1}{p}} D(x,y)=(u=1∑n?∣xu??yu?∣p)p1? 嵌入向量是依據決策森林樣本葉節點落位而進行multi_hot encoding的一個結果(對應位取值為1,其他為0),只要葉子節點編號的每個維度的權重一樣(這里都是1),
二、孤立森林
孤立森林演算法是基于 Ensemble 的例外檢測方法,因此具有線性的時間復雜度,且精準度較高,在處理大資料時速度快,所以目前在工業界的應用范圍比較廣,常見的場景包括:網路安全中的攻擊檢測、金融交易欺詐檢測、疾病偵測、噪聲資料過濾(資料清洗)等,
孤立森林是基于決策樹的演算法,從給定的特征集合中隨機選擇特征,然后在特征的最大值和最小值間隨機選擇一個分割值,來隔離離群值,這種特征的隨機劃分會使例外資料點在樹中生成的路徑更短,從而將它們和其他資料分開,孤立森林不通過顯式地隔離例外,來隔離了資料集中的例外點,
孤立森林的基本思想是:多次隨機選取特征和對應的分割點以分開空間中樣本點,那么例外點很容易在較早的幾次分割中就已經與其他樣本隔開,正常點由于較為緊密故需要更多的分割次數才能將其分開,
孤立森林的優勢:
- Partial models:在訓練程序中,每棵孤立樹都是隨機選取部分樣本;
- No distance or density measures:不同于 KMeans、DBSCAN 等演算法,孤立森林不需要計算有關距離、密度的指標,可大幅度提升速度,減小系統開銷;
- Linear time complexity:因為基于 ensemble,所以有線性時間復雜度,通常樹的數量越多,演算法越穩定;
- Handle extremely large data size:由于每棵樹都是獨立生成的,因此可部署在大規模分布式系統上來加速運算,
2.1 例外得分的計算
下圖中體現了兩個特征下的4次分割程序,可見右上角的例外點已經被單獨隔離開,
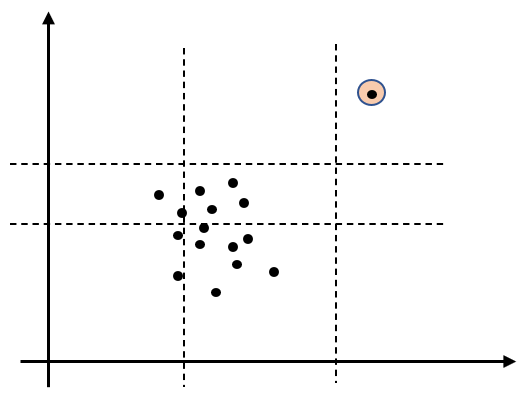
對于 n n n 個樣本而言,我們可以構建一棵在每個分支進行特征大小判斷的樹來將樣本分派到對應的葉子節點,為了定量刻畫例外情況,在這篇文獻中證明了樹中的平均路徑(即樹的根節點到葉子結點經過的節點數)長度 c c c為
c ( n ) = 2 H ( n ? 1 ) ? 2 ( n ? 1 ) n c(n) = 2H(n-1)-\frac{2(n-1)}{n} c(n)=2H(n?1)?n2(n?1)?
其中 H ( k ) H(k) H(k)為調和級數 ∑ p = 1 k 1 p \sum_{p=1}^k\frac{1}{p} p=1∑k?p1?
此時對于某個樣本 x x x,假設其分派到葉子節點的路徑長度為 h ( x ) h(x) h(x),我們就能用 h ( x ) c ( n ) \frac{h(x)}{c(n)} c(n)h(x)?的大小來度量例外的程度,該值越小則越有可能為例外點,由于單棵樹上使用的是隨機特征的隨機分割點,穩健度較差,因此孤立森林將建立 t t t棵樹(默認100),每棵樹上都在資料集上抽樣出 ψ \psi ψ個樣本(默認256個)進行訓練,為了總和集成的結果,我們定義指標——例外得分
s ( x , n ) = 2 ? E h ( x ) c ( n ) s(x,n)=2^{-\frac{\mathbb{E}h(x)}{c(n)}} s(x,n)=2?c(n)Eh(x)?
指數上的
E
h
(
x
)
\mathbb{E}h(x)
Eh(x)表示樣本
x
x
x在各樹的路徑平均值:
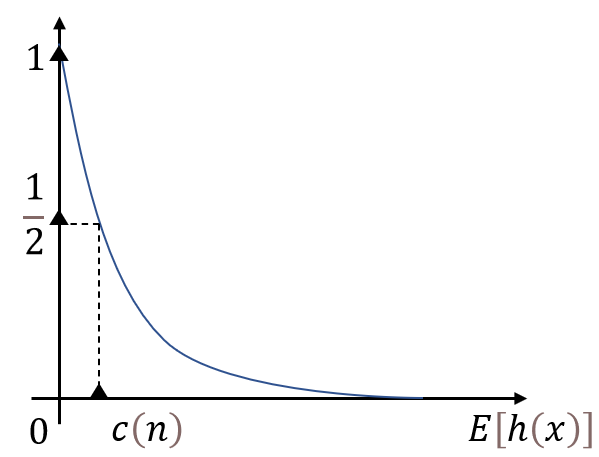
(1)當這個均值趨于0時,例外得分
s
(
x
,
n
)
s(x,n)
s(x,n)趨于1;
(2)當其趨于
n
?
1
n-1
n?1時(
n
n
n個樣本最多需要
n
?
1
n-1
n?1次分割,故樹深度最大為
n
?
1
n-1
n?1),
s
(
x
,
n
)
s(x,n)
s(x,n)趨于0(特別是在大樣本情況下
c
(
n
)
c(n)
c(n)遠小于
E
h
(
x
)
\mathbb{E}h(x)
Eh(x));
(3)當其趨于平均路徑長度
E
h
(
x
)
\mathbb{E}h(x)
Eh(x)時,
s
(
x
,
n
)
s(x,n)
s(x,n)趨于
1
2
\frac{1}{2}
21?,變化關系如圖所示,
2.2 限定樹的高度
雖然上述步驟明確了例外得分的計算,但是卻還沒有說明訓練時樹究竟應當在何時生長停止,可以規定樹的生長停止當且僅當樹的高度(路徑的最大值)達到了給定的限定高度,或者葉子結點樣本數僅為1,或者葉子節點樣本數的所有特征值完全一致(即空間中的點重合,無法分離),
如何決定樹的限定高度呢?
在例外點判別的問題中,例外點往往是少部分的因此絕大多數的例外點都會在高度達到
c
(
n
)
c(n)
c(n)前被分配至路徑較短的葉子結點,由于調和級數有如下關系(其中
γ
≈
0.5772
\gamma\approx0.5772
γ≈0.5772為歐拉常數):
lim ? n → ∞ H ( n ) ? log ? n = γ \lim_{n\to\infty} H(n)-\log n = \gamma n→∞lim?H(n)?logn=γ
因此 c ( n ) c(n) c(n)與 log ? n \log n logn數量級相同,故給定的限定高度可以設定為 log ? n \log n logn,
2.3 訓練與預測
此時,我們可以寫出模型訓練的偽代碼(圖片直接來自于原始論文):
首先下面這段是創建孤立樹,樹的高度限制I與子樣本數量有關,限制樹的高度是因為我們需要找路徑長度較短的點(它們更可能是例外點),

第二段就是是每課孤立樹的生長(即訓練程序),

在預測階段,應當計算樣本在每棵樹上被分配到葉子的路徑,但我們還需要在路徑長度上加上一項
c
(
T
.
s
i
z
e
)
c(T.size)
c(T.size),其含義為當前葉子節點上樣本數對應可生長的平均路徑值,這是由于我們為了快速訓練而對樹高度進行了限制,事實上那些多個樣本的節點仍然可以生長下去得到更長的路徑,而新樣本到達葉子結點后,平均而言還需要
c
(
T
.
s
i
z
e
)
c(T.size)
c(T.size)的路徑才能達到真正(完全生長的樹)的葉子結點,從而計算路徑的偽代碼如下圖所示:

在得到了各個樹對應的路徑后,我們就自然能計算 s ( x , n ) s(x,n) s(x,n)了,假設我們需要得到前 5 % 5\% 5%最可能為例外的點時,只需要對所有新樣本的 s ( x , n ) s(x,n) s(x,n)排序后輸出前 5 % 5\% 5%大的例外得分值對應的樣本即可,
三、作業
5.1 什么是隨機森林的oob得分?
在訓練時,一般而言我們總是需要對資料集進行訓練集和驗證集的劃分,但隨機森林由于每一個基學習器使用了重復抽樣得到的資料集進行訓練,因此總存在比例大約為 e ? 1 e^{-1} e?1的資料集沒有參與訓練,我們把這一部分資料稱為out-of-bag樣本,簡稱oob樣本,
每一個基學習器訓練完后,我們都對oob資料進行預測,每個樣本對應的oob_prediction_ 值為所有沒有采樣到該樣本進行訓練的基學習器預測結果均值,在得到所有的oob_prediction_ 的值后,如果問題是回歸問題,則用r2_score來計算oob_score_ ,如果問題是分類問題,則用accuarcy_score來計算oob得分,
5.2 隨機森林是如何集成多個決策樹模型的?
(1)隨機森林當處理回歸問題時,輸出值為各學習器的均值;
(2)隨機森林當處理分類問題時有兩種策略:
- 第一種是原始論文中使用的投票策略,即每個學習器輸出一個類別,回傳最高預測頻率的類別;
- 第二種是sklearn中采用的概率聚合策略,即通過各個學習器輸出的概率分布先計算樣本屬于某個類別的平均概率,在對平均的概率分布取 arg ? max ? \arg\max argmax以輸出最可能的類別,
(絕對平均和加權平均的區別)
5.3 敘述孤立森林的演算法原理和流程,
主要思想:多次隨機選取特征和對應的分割點以分開空間中樣本點,那么例外點很容易在較早的幾次分割中就已經與其他樣本隔開,正常點由于較為緊密故需要更多的分割次數才能將其分開,
孤立森林通過隨機選擇特征,然后隨機選擇特征的分割值,遞回地生成資料集的磁區,和資料集中「正常」的點相比,要隔離的例外值所需的隨機磁區更少,因此例外值是樹中路徑更短的點,路徑長度是從根節點經過的邊數,
孤立森林演算法的流程:
(1)訓練iForest:
從訓練集中采樣,構建孤立樹,對森林中每棵孤立樹進行測驗,記錄路徑長度;
(2)計算例外分數:
代入論文中證明的例外得分公式
s
(
x
,
n
)
=
2
?
E
h
(
x
)
c
(
n
)
s(x,n)=2^{-\frac{\mathbb{E}h(x)}{c(n)}}
s(x,n)=2?c(n)Eh(x)?指數上的
E
h
(
x
)
\mathbb{E}h(x)
Eh(x)表示樣本
x
x
x在各樹的路徑平均值:
(1)當這個均值趨于0時,例外得分
s
(
x
,
n
)
s(x,n)
s(x,n)趨于1;
(2)當其趨于
n
?
1
n-1
n?1時(
n
n
n個樣本最多需要
n
?
1
n-1
n?1次分割,故樹深度最大為
n
?
1
n-1
n?1),
s
(
x
,
n
)
s(x,n)
s(x,n)趨于0(特別是在大樣本情況下
c
(
n
)
c(n)
c(n)遠小于
E
h
(
x
)
\mathbb{E}h(x)
Eh(x));
(3)當其趨于平均路徑長度
E
h
(
x
)
\mathbb{E}h(x)
Eh(x)時,
s
(
x
,
n
)
s(x,n)
s(x,n)趨于
1
2
\frac{1}{2}
21?,變化關系如圖所示,
5.4 實作孤立森林演算法
from pyod.utils.data import generate_data
import matplotlib.pyplot as plt
import numpy as np
class Node:
def __init__(self, depth):
self.depth = depth
self.left = None
self.right = None
self.feature = None
self.pivot = None
class Tree:
def __init__(self, max_height):
self.root = Node(0)
self.max_height = max_height
self.c = None
def _build(self, node, X,):
if X.shape[0] == 1:
return
if node.depth+1 > self.max_height:
node.depth += self._c(X.shape[0])
return
node.feature = np.random.randint(X.shape[1])
pivot_min = X[:, node.feature].min()
pivot_max = X[:, node.feature].max()
node.pivot = np.random.uniform(pivot_min, pivot_max)
node.left, node.right = Node(node.depth+1), Node(node.depth+1)
self._build(node.left, X[X[:, node.feature]<node.pivot])
self._build(node.right, X[X[:, node.feature]>=node.pivot])
def build(self, X):
self.c = self._c(X.shape[0])
self._build(self.root, X)
def _c(self, n):
if n == 1:
return 0
else:
return 2 * ((np.log(n-1) + 0.5772) - (n-1)/n)
# 查找某個樣本的深度(即h(x))
def _get_h_score(self, node, x):
if node.left is None and node.right is None:
return node.depth
if x[node.feature] < node.pivot:
return self._get_h_score(node.left, x)
else:
return self._get_h_score(node.right, x)
def get_h_score(self, x):
return self._get_h_score(self.root, x)
class IsolationForest:
def __init__(self, n_estimators=100, max_samples=256):
self.n_estimator = n_estimators
self.max_samples = max_samples
self.trees = []
def fit(self, X):
for tree_id in range(self.n_estimator):
# 取樣
random_X = X[np.random.randint(0, X.shape[0], self.max_samples)]
tree = Tree(np.log(random_X.shape[0]))
tree.build(X)
# trees樹串列增加新樹
self.trees.append(tree)
def predict(self, X):
result = []
for x in X:
h = 0
for tree in self.trees:
h += tree.get_h_score(x) / tree.c
# power
score = np.power(2, - h/len(self.trees))
result.append(score)
return np.array(result)
if __name__ == "__main__":
np.random.seed(0)
# 生成資料,1%例外點,generate_data用的還是pyod庫的函式
X_train, X_test, y_train, y_test = generate_data(
n_train=1000, n_test=500,
contamination=0.05, behaviour="new", random_state=0
)
IF = IsolationForest()
IF.fit(X_train)
res = IF.predict(X_test)
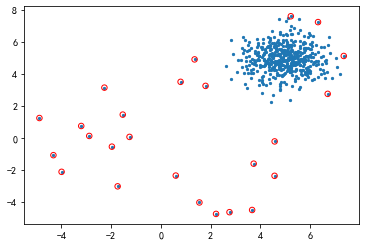
abnormal_X = X_test[res > np.quantile(res, 0.95)]
# 資料可視化
plt.scatter(X_test[:, 0], X_test[:, 1], s=5)
plt.scatter(
abnormal_X[:, 0], abnormal_X[:, 1],
s=30, edgecolors="Red", facecolor="none"
)
plt.show()
5.5 實作用于分類的隨機森林演算法
(可以用sklearn的決策樹或task2中自己實作的分類cart樹)
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 24 22:39:03 2021
@author: 86493
"""
import numpy as np
from sklearn.tree import DecisionTreeClassifier as Tree
class RandomForest:
def __init__(self, n_estimators, max_depth):
self.n_estimators = n_estimators
self.max_depth = max_depth
self.trees = []
def fit(self, X, y):
for tree_id in range(self.n_estimators):
indexes = np.random.randint(0, X.shape[0], X.shape[0])
random_X = X[indexes]
random_y = y[indexes]
tree = Tree(max_depth=3)
tree.fit(random_X, random_y)
self.trees.append(tree)
def predict(self, X):
results = []
for x in X:
result = []
for tree in self.trees:
result.append(tree.predict(x.reshape(1, -1))[0])
results.append(np.argmax(np.bincount(result))) # 回傳該樣本的預測結果,采取方案:多數投票
return np.array(results)
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier as RF
# from RandomForest_Classifier import RandomForest
import numpy as np
if __name__ == "__main__":
X, y = make_classification(n_samples=200, n_features=8, n_informative=4, random_state=0)
RF1 = RandomForest(n_estimators=100, max_depth=3)
RF2 = RF(n_estimators=100, max_depth=3)
RF1.fit(X, y)
res1 = RF1.predict(X)
RF2.fit(X, y)
res2 = RF2.predict(X)
print('預測一致的比例', (np.abs(res1 - res2) < 1e-5).mean())
# 預測一致的比例 0.985
5.6 隨機森林的主要引數
(1)RF框架的引數
RF框架的引數:RandomForestClassifier和RandomForestRegressor引數絕大部分相同,
(1)n_estimators(重點): 也就是最大的弱學習器的個數,一般來說n_estimators太小,容易欠擬合,n_estimators太大,計算量會太大,并且n_estimators到一定的數量后,再增大n_estimators獲得的模型提升會很小,所以一般選擇一個適中的數值,默認是100,
(2)oob_score :即是否采用袋外樣本來評估模型的好壞,默認識False,個人推薦設定為True,因為袋外分數反應了一個模型擬合后的泛化能力,
(3)criterion: 即CART樹做劃分時對特征的評價標準,分類模型和回歸模型的損失函式是不一樣的,分類RF對應的CART分類樹默認是基尼系數gini,另一個可選擇的標準是資訊增益,回歸RF對應的CART回歸樹默認是均方差mse,另一個可以選擇的標準是絕對值差mae,一般來說選擇默認的標準就已經很好的,
(2)RF決策樹的引數
(1)RF劃分時考慮的最大特征數max_features: 可以使用很多種型別的值,默認是"auto",意味著劃分時最多考慮
N
\sqrt{N}
N
?個特征;如果是"log2"意味著劃分時最多考慮
log
?
2
N
\log _{2} N
log2?N個特征;如果是"sqrt"或者"auto"意味著劃分時最多考慮
N
\sqrt{N}
N
?個特征,如果是整數,代表考慮的特征絕對數,如果是浮點數,代表考慮特征百分比,即考慮(百分比xN)取整后的特征數,其中N為樣本總特征數,一般我們用默認的"auto"就可以了,如果特征數非常多,我們可以靈活使用剛才描述的其他取值來控制劃分時考慮的最大特征數,以控制決策樹的生成時間,
(2)決策樹最大深度max_depth: 默認可以不輸入,如果不輸入的話,決策樹在建立子樹的時候不會限制子樹的深度,一般來說,資料少或者特征少的時候可以不管這個值,如果模型樣本量多,特征也多的情況下,推薦限制這個最大深度,具體的取值取決于資料的分布,常用的可以取值10-100之間,
(3)內部節點再劃分所需最小樣本數min_samples_split: 這個值限制了子樹繼續劃分的條件,如果某節點的樣本數少于min_samples_split,則不會繼續再嘗試選擇最優特征來進行劃分, 默認是2.如果樣本量不大,不需要管這個值,如果樣本量數量級非常大,則推薦增大這個值,
(4)葉子節點最少樣本數min_samples_leaf: 這個值限制了葉子節點最少的樣本數,如果某葉子節點數目小于樣本數,則會和兄弟節點一起被剪枝, 默認是1,可以輸入最少的樣本數的整數,或者最少樣本數占樣本總數的百分比,如果樣本量不大,不需要管這個值,如果樣本量數量級非常大,則推薦增大這個值,
(5)葉子節點最小的樣本權重和min_weight_fraction_leaf:這個值限制了葉子節點所有樣本權重和的最小值,如果小于這個值,則會和兄弟節點一起被剪枝, 默認是0,就是不考慮權重問題,一般來說,如果我們有較多樣本有缺失值,或者分類樹樣本的分布類別偏差很大,就會引入樣本權重,這時我們就要注意這個值了,
(6)最大葉子節點數max_leaf_nodes: 通過限制最大葉子節點數,可以防止過擬合,默認是"None”,即不限制最大的葉子節點數,如果加了限制,演算法會建立在最大葉子節點數內最優的決策樹,如果特征不多,可以不考慮這個值,但是如果特征分成多的話,可以加以限制,具體的值可以通過交叉驗證得到,
(7)節點劃分最小不純度min_impurity_split: 這個值限制了決策樹的增長,如果某節點的不純度(基于基尼系數,均方差)小于這個閾值,則該節點不再生成子節點,即為葉子節點 ,一般不推薦改動默認值1e-7,
上面決策樹引數中最重要的包括最大特征數max_features, 最大深度max_depth, 內部節點再劃分所需最小樣本數min_samples_split和葉子節點最少樣本數min_samples_leaf,
Reference
(1)https://datawhalechina.github.io/machine-learning-toy-code/index.html
(2)https://zhuanlan.zhihu.com/p/113325296
(3)例外檢測演算法 – 孤立森林(Isolation Forest)剖析—best
(4)https://github.com/buaamse/2021-08/blob/main/task04_RandomiForestTree.ipynb
(5)機器之心—孤立森林進行例外檢測(sklearn版)
(7)a同學筆記,b同學筆記
(8)scikit-learn隨機森林調參小結-劉建平
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336158.html
標籤:AI
上一篇:深度學習分布式訓練小結