目錄
這篇文章寫的比較匆忙,還有很多演算法沒有寫進去,而且也有很多演算法沒有寫完整,大家可以先看看我下面放的參考文獻,也可以先收藏我的文章,我在后續的學習中還會更新完善這篇文章,謝謝大家的支持~
Harris角點檢測原理詳解
1、演算法基本思想
2、用數學思想去刻畫角點特征
公式解釋:
4.E(u,v)運算式進一步演化
矩陣M的關鍵性
Harris角點演算法實作
Harris角點的性質
2. Harris角點檢測算子對亮度和對比度的變化不敏感
3. Harris角點檢測算子具有旋轉不變性
4. Harris角點檢測算子不具有尺度不變性
susan角點檢測演算法
SUSAN角點檢測演算法的具體步驟如下:
LBP演算法
1、LBP特征的描述
LBP的改進版本:
(1)圓形LBP算子:
(2)LBP旋轉不變模式
(3)LBP等價模式
2、LBP特征用于檢測的原理
從上圖可以看出LBP對光照具有很強的魯棒性
3、對LBP特征向量進行提取的步驟
HOG特征
(1)主要思想:
(2)具體的實作方法是:
(3)提高性能:
(4)優點:
具體每一步的詳細程序如下:
(1)標準化gamma空間和顏色空間
(2) 而梯度可分解為 x 方向的梯度 G{x} 和 y 方向的梯度 G{y} ,
(3)為每個細胞單元構建梯度方向直方圖
3.cell、block、windowsSize、stride的關系,
FAST角點檢測
2、opencv-Fast角點檢測演算法C++版代碼
3、opencv-Fast角點檢測演算法python版代碼
SIFT演算法
1、SIFT綜述
SIFT演算法的特點有:
SIFT演算法可以解決的問題:
2. 尺度空間
2.1 多解析度影像金字塔
2.2 高斯尺度空間
3. DoG空間極值檢測
4. 洗掉不好的極值點(特征點)
?
6. 生成特征描述
7. 總結
Harris角點檢測原理詳解
1、演算法基本思想
演算法基本思想是使用一個固定視窗在影像上進行任意方向上的滑動,比較滑動前與滑動后兩種情況,視窗中的像素灰度變化程度,如果存在任意方向上的滑動,都有著較大灰度變化,那么我們可以認為該視窗中存在角點,
2、用數學思想去刻畫角點特征

公式解釋:
>[u,v]是視窗的偏移量
>(x,y)是視窗內所對應的像素坐標位置,視窗有多大,就有多少個位置
>w(x,y)是視窗函式,最簡單情形就是視窗內的所有像素所對應的w權重系數均為1,但有時候,我們會將w(x,y)函式設定為以視窗中心為原點的二元正態分布,如果視窗中心點是角點時,移動前與移動后,該點的灰度變化應該最為劇烈,所以該點權重系數可以設定大些,表示視窗移動時,該點在灰度變化貢獻較大;而離視窗中心(角點)較遠的點,這些點的灰度變化幾近平緩,這些點的權重系數,可以設定小點,以示該點對灰度變化貢獻較小,那么我們自然想到使用二元高斯函式來表示視窗函式,這里僅是個人理解,大家可以參考下,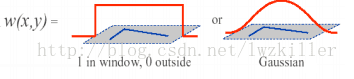
根據上述運算式,當視窗處在平坦區域上滑動,可以想象的到,灰度不會發生變化,那么E(u,v) = 0;如果視窗處在比紋理比較豐富的區域上滑動,那么灰度變化會很大,演算法最終思想就是計算灰度發生較大變化時所對應的位置,當然這個較大是指標任意方向上的滑動,并非單指某個方向,
4.E(u,v)運算式進一步演化

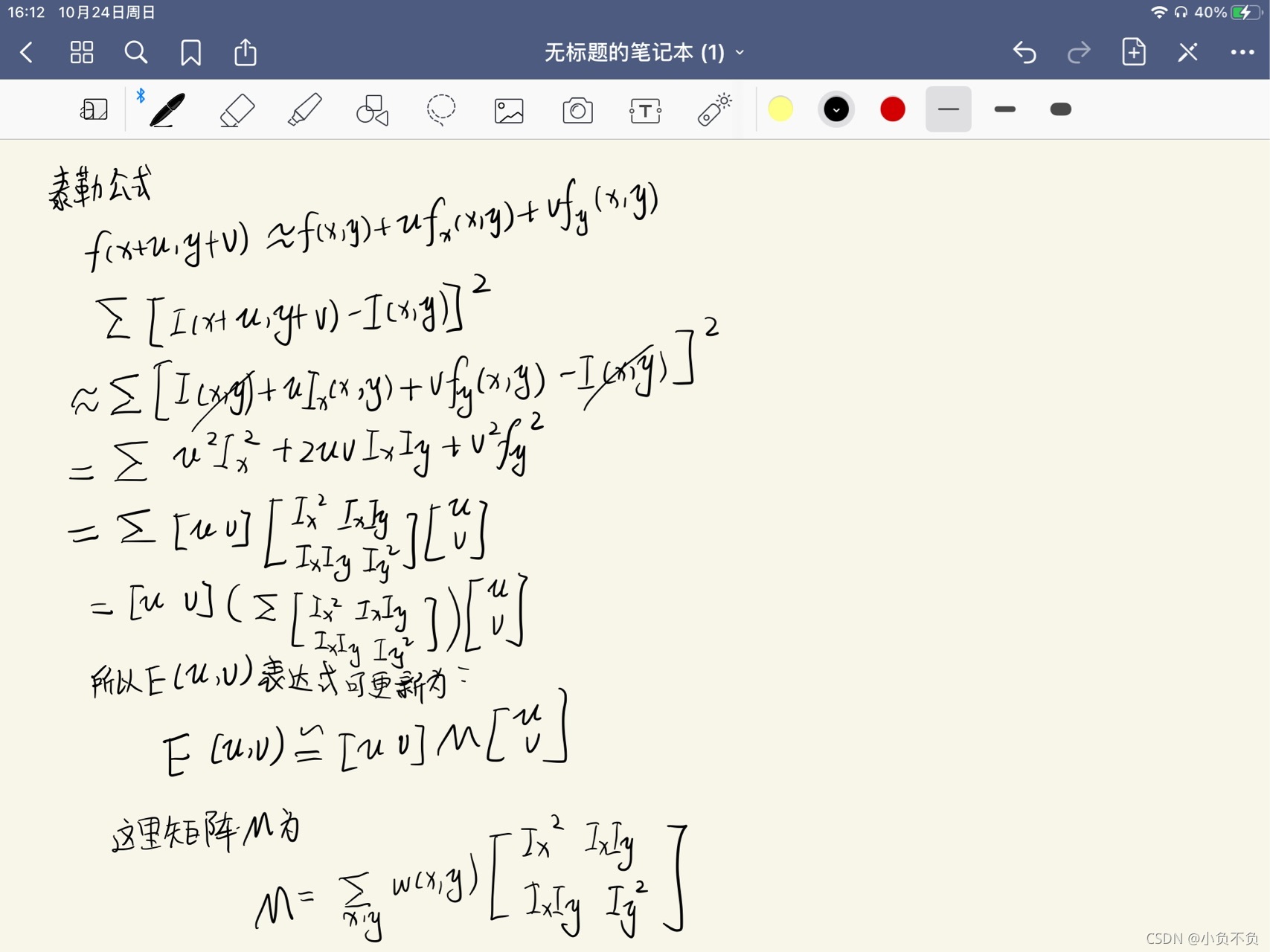
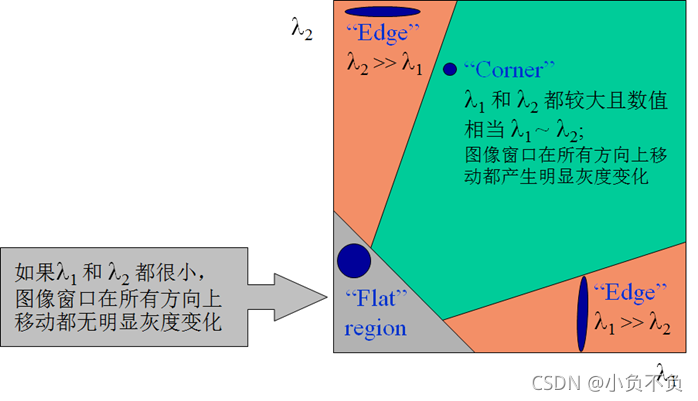
橢圓函式特征值與影像中的角點、直線(邊緣)和平面之間的關系如下圖所示,共可分為三種情況:
- 影像中的直線,一個特征值大,另一個特征值小,λ1?λ2λ1?λ2或λ2?λ1λ2?λ1,自相關函式值在某一方向上大,在其他方向上小,
- 影像中的平面,兩個特征值都小,且近似相等;自相關函式數值在各個方向上都小,
- 影像中的角點,兩個特征值都大,且近似相等,自相關函式在所有方向都增大,
矩陣M的關鍵性
難道我們是直接求上述的E(u,v)值來判斷角點嗎?Harris角點檢測并沒有這樣做,而是通過對視窗內的每個像素的x方向上的梯度與y方向上的梯度進行統計分析,這里以Ix和Iy為坐標軸,因此每個像素的梯度坐標可以表示成(Ix,Iy),針對平坦區域,邊緣區域以及角點區域三種情形進行分析:
下圖是對這三種情況視窗中的對應像素的梯度分布進行繪制
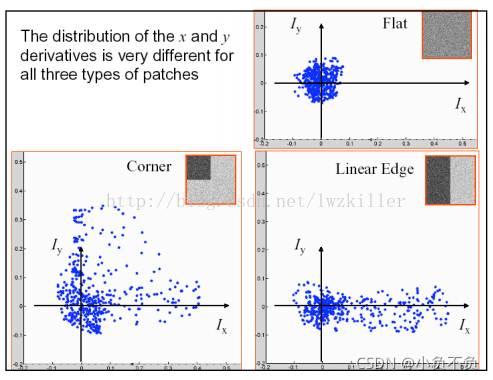
如果使用橢圓進行資料集表示,則繪制圖示如下
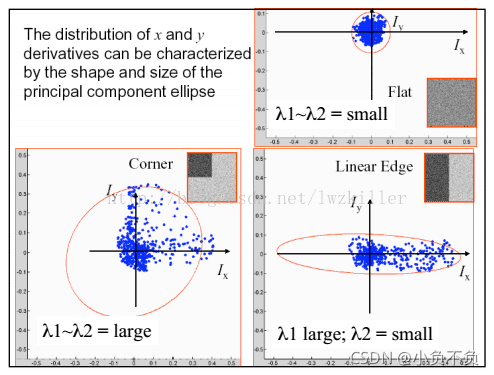
不知道大家有沒有注意到這三種區域的特點,平坦區域上的每個像素點所對應的(IX,IY)坐標分布在原點附近,其實也很好理解,針對平坦區域的像素點,他們的梯度方向雖然各異,但是其幅值都不是很大,所以均聚集在原點附近;邊緣區域有一坐標軸分布較散,至于是哪一個坐標上的資料分布較散不能一概而論,這要視邊緣在影像上的具體位置而定,如果邊緣是水平或者垂直方向,那么Iy軸方向或者Ix方向上的資料分布就比較散;角點區域的x、y方向上的梯度分布都比較散,我們是不是可以根據這些特征來判斷哪些區域存在角點呢?
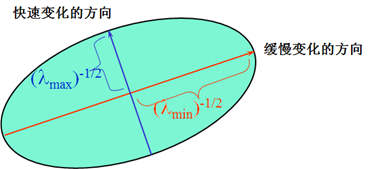
雖然我們利用E(u,v)來描述角點的基本思想,然而最終我們僅僅使用的是矩陣M,讓我們看看矩陣M形式,是不是跟協方差矩陣形式很像,像歸像,但是還是有些不同,哪兒不同?一般協方差矩陣對應維的隨機變數需要減去該維隨機變數的均值,但矩陣M中并沒有這樣做,所以在矩陣M里,我們先進行各維的均值化處理,那么各維所對應的隨機變數的均值為0,協方差矩陣就大大簡化了,簡化的最終結果就是矩陣M,是否明白了?我們的目的是分析資料的主要成分,相信了解PCA原理的,應該都了解均值化的作用,
如果我們對協方差矩陣M進行對角化,很明顯,特征值就是主分量上的方差,這點大家應該明白吧?不明白的話可以復習下PCA原理,如果存在兩個主分量所對應的特征值都比較大,說明什么? 像素點的梯度分布比較散,梯度變化程度比較大,符合角點在視窗區域的特點;如果是平坦區域,那么像素點的梯度所構成的點集比較集中在原點附近,因為視窗區域內的像素點的梯度幅值非常小,此時矩陣M的對角化的兩個特征值比較小;如果是邊緣區域,在計算像素點的x、y方向上的梯度時,邊緣上的像素點的某個方向的梯度幅值變化比較明顯,另一個方向上的梯度幅值變化較弱,其余部分的點都還是集中原點附近,這樣M對角化后的兩個特征值理論應該是一個比較大,一個比較小,當然對于邊緣這種情況,可能是呈45°的邊緣,致使計算出的特征值并不是都特別的大,總之跟含有角點的視窗的分布情況還是不同的,
因此可以得出下列結論:
>特征值都比較大時,即視窗中含有角點
>特征值一個較大,一個較小,視窗中含有邊緣
>特征值都比較小,視窗處在平坦區域

Harris角點演算法實作


其中k是常量,一般取值為0.04~0.06,這個引數僅僅是這個函式的一個系數,它的存在只是調節函式的形狀而已,
但是為什么會使用這樣的運算式呢?一下子是不是感覺很難理解?其實也不難理解,函式運算式一旦出來,我們就可以繪制它的影像,而這個函式圖形正好滿足上面幾個區域的特征, 通過繪制函式影像,直觀上更能理解,繪制的R函式影像如下: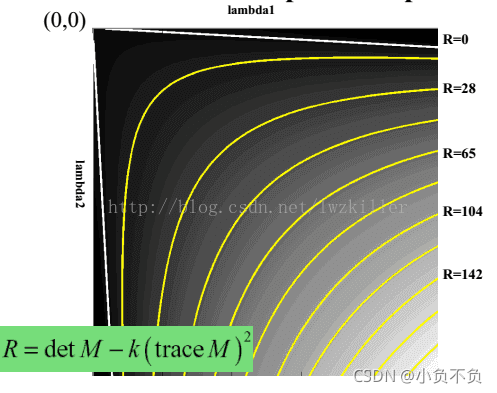
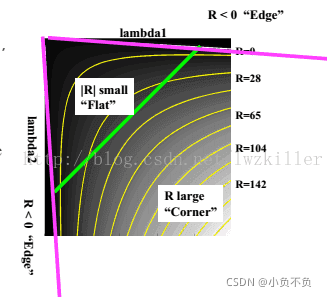
Harris角點的性質

由此,可以得出這樣的結論:增大αα的值,將減小角點回應值RR,降低角點檢測的靈性,減少被檢測角點的數量;減小αα值,將增大角點回應值RR,增加角點檢測的靈敏性,增加被檢測角點的數量,
2. Harris角點檢測算子對亮度和對比度的變化不敏感
這是因為在進行Harris角點檢測時,使用了微分算子對影像進行微分運算,而微分運算對影像密度的拉升或收縮和對亮度的抬高或下降不敏感,換言之,對亮度和對比度的仿射變換并不改變Harris回應的極值點出現的位置,但是,由于閾值的選擇,可能會影響角點檢測的數量,
3. Harris角點檢測算子具有旋轉不變性
Harris角點檢測算子使用的是角點附近的區域灰度二階矩矩陣,而二階矩矩陣可以表示成一個橢圓,橢圓的長短軸正是二階矩矩陣特征值平方根的倒數,當特征橢圓轉動時,特征值并不發生變化,所以判斷角點回應值RR也不發生變化,由此說明Harris角點檢測算子具有旋轉不變性,
4. Harris角點檢測算子不具有尺度不變性
如下圖所示,當右圖被縮小時,在檢測視窗尺寸不變的前提下,在視窗內所包含影像的內容是完全不同的,左側的影像可能被檢測為邊緣或曲線,而右側的影像則可能被檢測為一個角點
參考文章:Harris角點檢測原理詳解_lwzkiller的專欄-CSDN博客_harris角點檢測
susan角點檢測演算法
SUSAN演算法是1997年牛津大學的Smith等人提出的一種處理灰度影像的方法,它主要是用來計算影像中的角點特征,SUSAN演算法選用圓形模板(如圖1所示),將位于圓形視窗模板中心等待檢測的像素點稱為核心點,核心點的鄰域被劃分為兩個區域:亮度值相似于核心點亮度的區域即核值相似區(Univalue SegmentAs-similatingNueleus,USAN)和亮度值不相似于核心點亮度的區域,
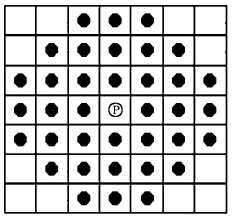
USAN的典型區域如圖2所示,模板在影像上移動時,當圓形模板完全在背景或者目標區域時,其USAN區域最大,如圖2(a);當核心在邊緣時,USAN區域減少一半,如圖2(c);當核心在角點時, USAN區域最小,如圖2(d),基于這一原理, Smith提出了最小核值相似區角點檢測演算法,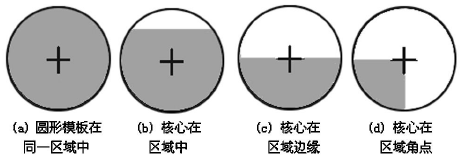
SUSAN角點檢測演算法的具體步驟如下:
(1)在影像上放置一個37個像素的圓形模板,模板在影像上滑動,依次比較模板內各個像素點的灰度與模板核的灰度,判斷是否屬于USAN區域,判別函式如下:
(2)統計圓形模板中和核心點有相似亮度值的像素個數n(r0),
其中,D(r0)是以r0為中心的圓形模板區域
(3)使用如下角點回應函式,若某個像素點的USAN值小于某一特定閾值,則該點被認為是初始角點,其中,g可以設定為USAN的最大面積的一半,
(4)對初始角點進行非極值抑制來求得最后的角點,
參考文章:https://blog.csdn.net/u013989576/article/details/49226611
LBP演算法
LBP(Local Binary Pattern,區域二值模式)是一種用來描述影像區域紋理特征的算子;它具有旋轉不變性和灰度不變性等顯著的優點,它是首先由T. Ojala, M.Pietik?inen, 和D. Harwood 在1994年提出,用于紋理特征提取,而且,提取的特征是影像的區域的紋理特征;
1、LBP特征的描述
原始的LBP算子定義為在3*3的視窗內,以視窗中心像素為閾值,將相鄰的8個像素的灰度值與其進行比較,若周圍像素值大于中心像素值,則該像素點的位置被標記為1,否則為0,這樣,3*3鄰域內的8個點經比較可產生8位二進制數(通常轉換為十進制數即LBP碼,共256種),即得到該視窗中心像素點的LBP值,并用這個值來反映該區域的紋理資訊,如下圖所示: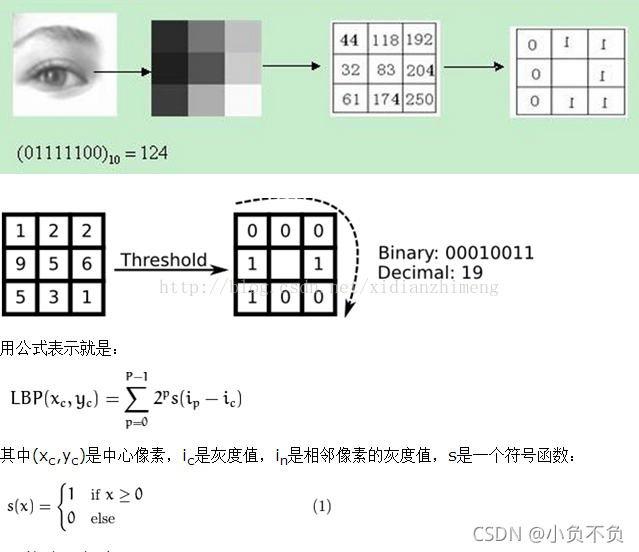
LBP的改進版本:
原始的LBP提出后,研究人員不斷對其提出了各種改進和優化,
(1)圓形LBP算子:
基本的 LBP 算子的最大缺陷在于它只覆寫了一個固定半徑范圍內的小區域,這顯然不能滿足不同尺寸和頻率紋理的需要,為了適應不同尺度的紋理特征,并達到灰度和旋轉不變性的要求,Ojala 等對 LBP 算子進行了改進,將 3×3 鄰域擴展到任意鄰域,并用圓形鄰域代替了正方形鄰域,改進后的 LBP 算子允許在半徑為 R 的圓形鄰域內有任意多個像素點,從而得到了諸如半徑為R的圓形區域內含有P個采樣點的LBP算子;
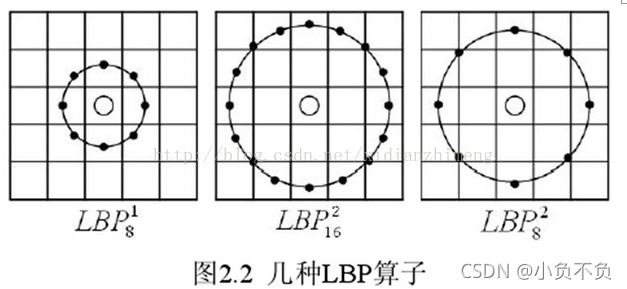
(2)LBP旋轉不變模式
從 LBP 的定義可以看出,LBP 算子是灰度不變的,但卻不是旋轉不變的,影像的旋轉就會得到不同的 LBP值,
Maenpaa等人又將 LBP 算子進行了擴展,提出了具有旋轉不變性的 LBP 算子,即不斷旋轉圓形鄰域得到一系列初始定義的 LBP 值,取其最小值作為該鄰域的 LBP 值,
圖 2.5 給出了求取旋轉不變的 LBP 的程序示意圖,圖中算子下方的數字表示該算子對應的 LBP 值,圖中所示的 8 種 LBP模式,經過旋轉不變的處理,最終得到的具有旋轉不變性的 LBP 值為 15,也就是說,圖中的 8 種 LBP 模式對應的旋轉不變的 LBP 模式都是00001111,
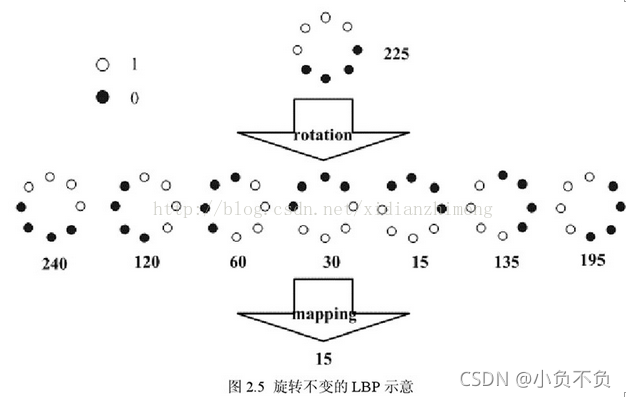
(3)LBP等價模式
一個LBP算子可以產生不同的二進制模式,對于半徑為R的圓形區域內含有P個采樣點的LBP算子將會產生P2 種模式,很顯然,隨著鄰域集內采樣點數的增加,二進制模式的種類是急劇增加的,例如:5×5鄰域內20個采樣點,有220=1,048,576種二進制模式,如此多的二值模式無論對于紋理的提取還是對于紋理的識別、分類及資訊的存取都是不利的,同時,過多的模式種類對于紋理的表達是不利的,例如,將LBP算子用于紋理分類或人臉識別時,常采用LBP模式的統計直方圖來表達影像的資訊,而較多的模式種類將使得資料量過大,且直方圖過于稀疏,因此,需要對原始的LBP模式進行降維,使得資料量減少的情況下能最好的代表影像的資訊,
為了解決二進制模式過多的問題,提高統計性,Ojala提出了采用一種“等價模式”(Uniform Pattern)來對LBP算子的模式種類進行降維,Ojala等認為,在實際影像中,絕大多數LBP模式最多只包含兩次從1到0或從0到1的跳變,因此,Ojala將“等價模式”定義為:當某個LBP所對應的回圈二進制數從0到1或從1到0最多有兩次跳變時,該LBP所對應的二進制就稱為一個等價模式類,如00000000(0次跳變),00000111(只含一次從0到1的跳變),10001111(先由1跳到0,再由0跳到1,共兩次跳變)都是等價模式類,除等價模式類以外的模式都歸為另一類,稱為混合模式類,例如10010111(共四次跳變)(這是我的個人理解,不知道對不對),
通過這樣的改進,二進制模式的種類大大減少,而不會丟失任何資訊,模式數量由原來的2P種減少為 P ( P-1)+2種,其中P表示鄰域集內的采樣點數,對于3×3鄰域內8個采樣點來說,二進制模式由原始的256種減少為58種,這使得特征向量的維數更少,并且可以減少高頻噪聲帶來的影響,
2、LBP特征用于檢測的原理
顯而易見的是,上述提取的LBP算子在每個像素點都可以得到一個LBP“編碼”,那么,對一幅影像(記錄的是每個像素點的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅圖片”(記錄的是每個像素點的LBP值),
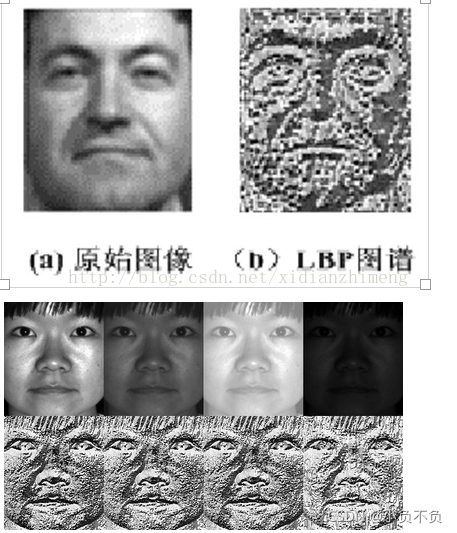
從上圖可以看出LBP對光照具有很強的魯棒性
LBP的應用中,如紋理分類、人臉分析等,一般都不將LBP圖譜作為特征向量用于分類識別,而是采用LBP特征譜的統計直方圖作為特征向量用于分類識別,
因為,從上面的分析我們可以看出,這個“特征”跟位置資訊是緊密相關的,直接對兩幅圖片提取這種“特征”,并進行判別分析的話,會因為“位置沒有對準”而產生很大的誤差,后來,研究人員發現,可以將一幅圖片劃分為若干的子區域,對每個子區域內的每個像素點都提取LBP特征,然后,在每個子區域內建立LBP特征的統計直方圖,如此一來,每個子區域,就可以用一個統計直方圖來進行描述;整個圖片就由若干個統計直方圖組成;
例如:一幅100*100像素大小的圖片,劃分為10*10=100個子區域(可以通過多種方式來劃磁區域),每個子區域的大小為10*10像素;在每個子區域內的每個像素點,提取其LBP特征,然后,建立統計直方圖;這樣,這幅圖片就有10*10個子區域,也就有了10*10個統計直方圖,利用這10*10個統計直方圖,就可以描述這幅圖片了,之后,我們利用各種相似性度量函式,就可以判斷兩幅影像之間的相似性了;
3、對LBP特征向量進行提取的步驟
(1)首先將檢測視窗劃分為16×16的小區域(cell);
(2)對于每個cell中的一個像素,將相鄰的8個像素的灰度值與其進行比較,若周圍像素值大于中心像素值,則該像素點的位置被標記為1,否則為0,這樣,3*3鄰域內的8個點經比較可產生8位二進制數,即得到該視窗中心像素點的LBP值;
(3)然后計算每個cell的直方圖,即每個數字(假定是十進制數LBP值)出現的頻率;然后對該直方圖進行歸一化處理,
(4)最后將得到的每個cell的統計直方圖進行連接成為一個特征向量,也就是整幅圖的LBP紋理特征向量;
然后便可利用SVM或者其他機器學習演算法進行分類了,
Reference:
黃非非,基于 LBP 的人臉識別研究,重慶大學碩士學位論文,2009.5
https://blog.csdn.net/xidianzhimeng/article/details/19634573
HOG特征
方向梯度直方圖(Histogram of Oriented Gradient, HOG)特征是一種在計算機視覺和影像處理中用來進行物體檢測的特征描述子,它通過計算和統計影像區域區域的梯度方向直方圖來構成特征,Hog特征結合SVM分類器已經被廣泛應用于影像識別中,尤其在行人檢測中獲得了極大的成功,需要提醒的是,HOG+SVM進行行人檢測的方法是法國研究人員Dalal在2005的CVPR上提出的,而如今雖然有很多行人檢測演算法不斷提出,但基本都是以HOG+SVM的思路為主,
(1)主要思想:
在一副影像中,區域目標的表象和形狀(appearance and shape)能夠被梯度或邊緣的方向密度分布很好地描述,(本質:梯度的統計資訊,而梯度主要存在于邊緣的地方),
(2)具體的實作方法是:
首先將影像分成小的連通區域,我們把它叫細胞單元,然后采集細胞單元中各像素點的梯度的或邊緣的方向直方圖,最后把這些直方圖組合起來就可以構成特征描述器,
(3)提高性能:
把這些區域直方圖在影像的更大的范圍內(我們把它叫區間或block)進行對比度歸一化(contrast-normalized),所采用的方法是:先計算各直方圖在這個區間(block)中的密度,然后根據這個密度對區間中的各個細胞單元做歸一化,通過這個歸一化后,能對光照變化和陰影獲得更好的效果,
(4)優點:
與其他的特征描述方法相比,HOG有很多優點,首先,由于HOG是在影像的區域方格單元上操作,所以它對影像幾何的和光學的形變都能保持很好的不變性,這兩種形變只會出現在更大的空間領域上,其次,在粗的空域抽樣、精細的方向抽樣以及較強的區域光學歸一化等條件下,只要行人大體上能夠保持直立的姿勢,可以容許行人有一些細微的肢體動作,這些細微的動作可以被忽略而不影響檢測效果,因此HOG特征是特別適合于做影像中的人體檢測的,
演算法流程圖
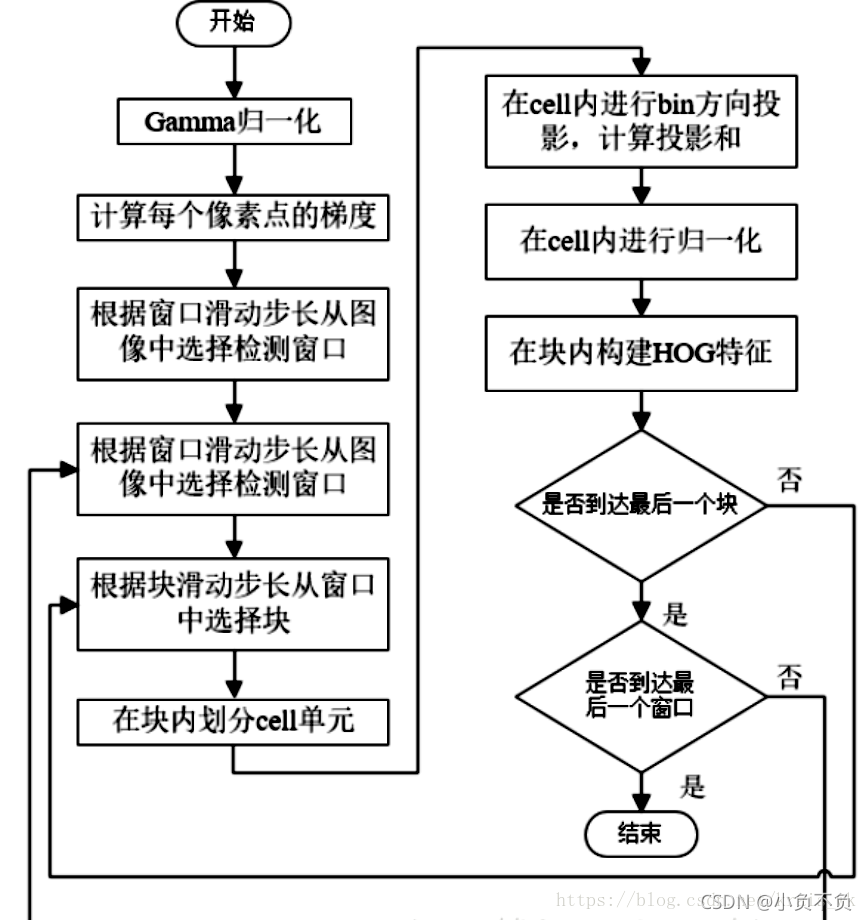
HOG特征提取方法就是將一個image(你要檢測的目標或者掃描視窗):
1)灰度化(將影像看做一個x,y,z(灰度)的三維影像);
2)采用Gamma校正法對輸入影像進行顏色空間的標準化(歸一化);目的是調節影像的對比度,降低影像區域的陰影和光照變化所造成的影響,同時可以抑制噪音的干擾;
3)計算影像每個像素的梯度(包括大小和方向);主要是為了捕獲輪廓資訊,同時進一步榷訓光照的干擾,
4)將影像劃分成小cells(例如8*8像素/cell);
5)統計每個cell的梯度直方圖(不同梯度的個數),即可形成每個cell的descriptor;
6)將每幾個cell組成一個block(例如3*3個cell/block),一個block內所有cell的特征descriptor串聯起來便得到該block的HOG特征descriptor,
7)將影像image內的所有block的HOG特征descriptor串聯起來就可以得到該image(你要檢測的目標)的HOG特征descriptor了,這個就是最終的可供分類使用的特征向量了,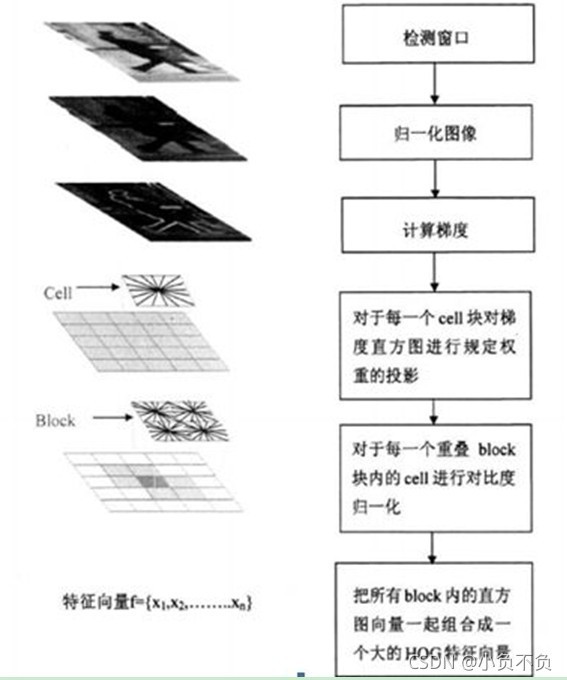
具體每一步的詳細程序如下:
(1)標準化gamma空間和顏色空間
為了減少光照因素的影響,首先需要將整個影像進行規范化(歸一化),在影像的紋理強度中,區域的表層曝光貢獻的比重較大,所以,這種壓縮處理能夠有效地降低影像區域的陰影和光照變化,因為顏色資訊作用不大,通常先轉化為灰度圖;
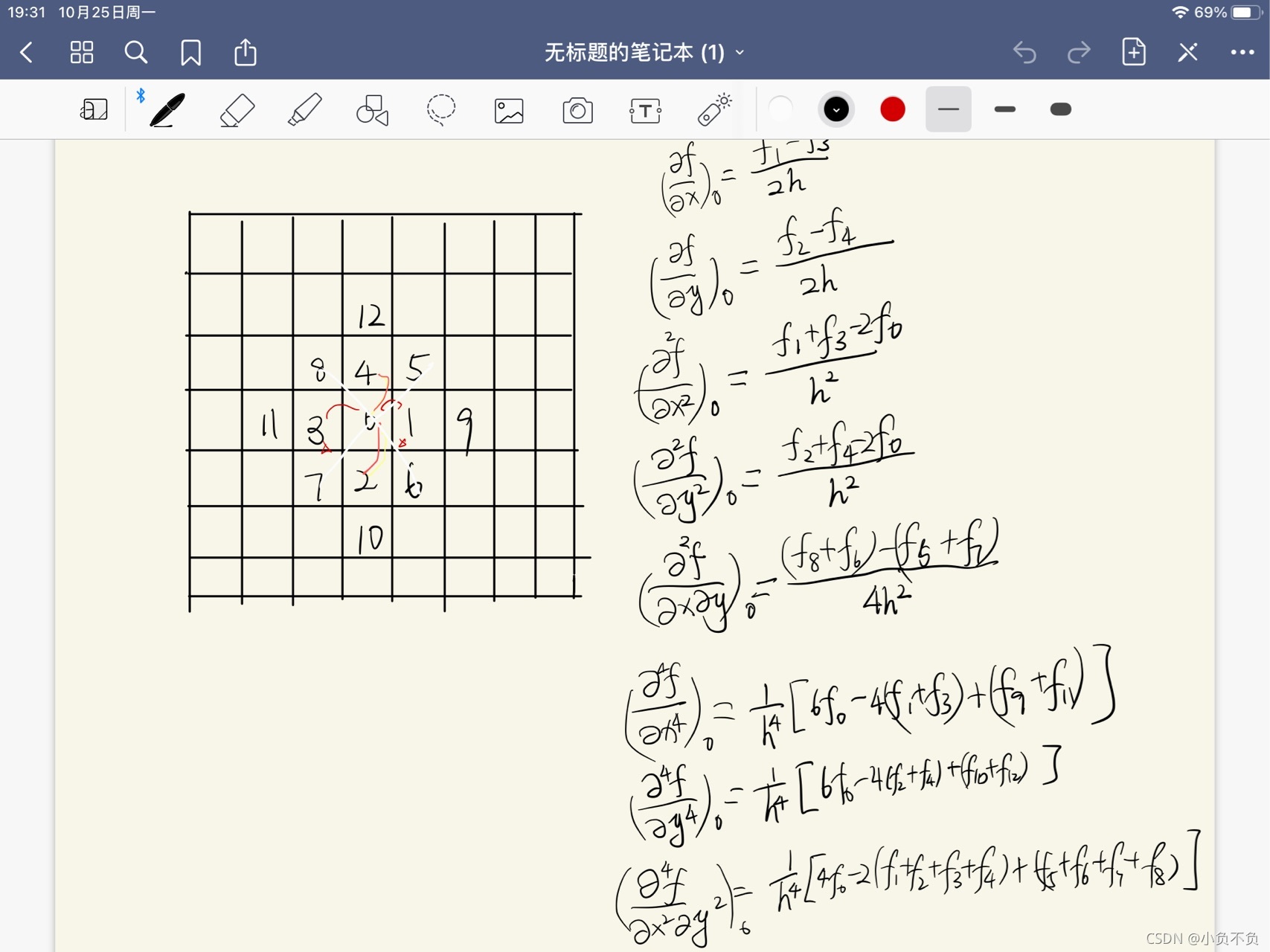
(2) 而梯度可分解為 x 方向的梯度 G{x} 和 y 方向的梯度 G{y} ,
某個像素點的 x 方向的梯度的計算可以通過這個像素點左右兩邊的像素值的差值的絕對值計算出來,而 y 方向的梯度可以通過該像素點上下兩邊的像素值的差值的絕對值計算,而根據下面的兩個公式可以計算每一個像素點的梯度方向和梯度幅值,

最常用的方法是:首先用[-1,0,1]梯度算子對原影像做卷積運算,得到x方向(水平方向,以向右為正方向)的梯度分量gradscalx,然后用[1,0,-1]T梯度算子對原影像做卷積運算,得到y方向(豎直方向,以向上為正方向)的梯度分量gradscaly,然后再用以上公式計算該像素點的梯度大小和方向,
(3)為每個細胞單元構建梯度方向直方圖
第三步的目的是為區域影像區域提供一個編碼,同時能夠保持對影像中人體物件的姿勢和外觀的弱敏感性,
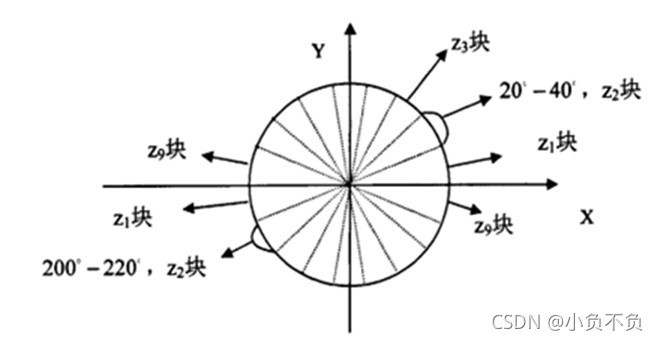
我們將影像分成若干個“單元格cell”,例如每個cell為8*8個像素,假設我們采用9個bin的直方圖來統計這8*8個像素的梯度資訊,也就是將cell的梯度方向360度分成9個方向塊,如圖所示:例如:如果這個像素的梯度方向是20-40度,直方圖第2個bin的計數就加一,這樣,對cell內每個像素用梯度方向在直方圖中進行加權投影(映射到固定的角度范圍),就可以得到這個cell的梯度方向直方圖了,就是該cell對應的9維特征向量(因為有9個bin),
像素梯度方向用到了,那么梯度大小呢?梯度大小就是作為投影的權值的,例如說:這個像素的梯度方向是20-40度,然后它的梯度大小是2(假設啊),那么直方圖第2個bin的計數就不是加一了,而是加二(假設啊),
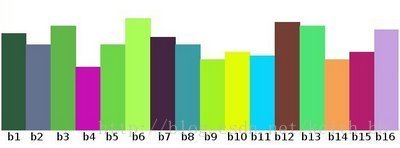
HOG是通過上面公式計算出來的梯度方向的角度是一個范圍在0-360度的弧度值,為了計算簡單,將梯度向的范圍約束為0-180度,并且分割為9個方向,每個方向20度,再將約束后的角度除以20,則現在的梯度方向角度值就變為范圍在[0,9),
細胞單元可以是矩形的(rectangular),也可以是星形的(radial),
3.cell、block、windowsSize、stride的關系,
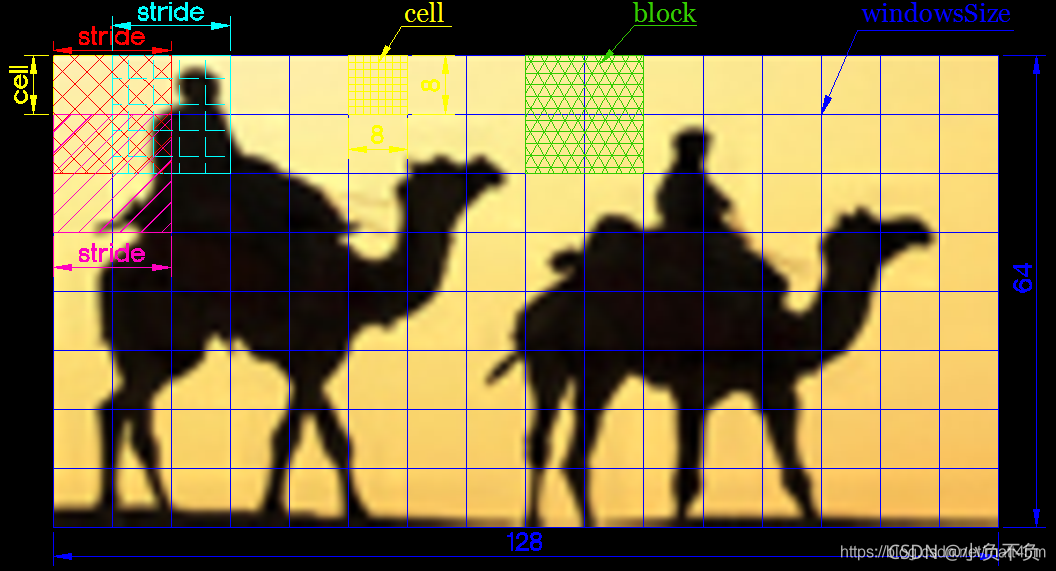
上圖中單個cell的為8X8個像素,把cell對應的方向直方圖轉換為單維向量,按規定組距對對應方向梯度個數進行編碼,得到單個cell的9個特征,每個block包含2X2個cell,那么每個block包含2X2個cell也就是2X2X9=36個特征,而每個block移動(stride)這里選擇overlap,就是為2分之一重疊,一個64X128大小的影像橫著有15個block,堅著有7個,最后得到的特征數為36X7X15=3780維,
參考文章:https://blog.csdn.net/matt45m/article/details/85325897
https://blog.csdn.net/zouxy09/article/details/7929348
FAST角點檢測
1、在影像中任選一點p, 假定其像素(亮度)值為 Ip
2、以3為半徑畫圓,覆寫p點周圍的16個像素,如下圖所示
3、設定閾值t,如果這周圍的16個像素中有連續的n個像素的像素值都小于 Ip?t或者有連續的n個像素都大于Ip+t, 那么這個點就被判斷為角點, 在OpenCV的實作中n取值為12(16個像素周長的 3/4).
4、一種更加快的改進是: 首先檢測p點周圍的四個點,即1, 5, 9, 12四個點中是否有三個點滿足超過Ip+t, 如果不滿足,則直接跳過,如果滿足,則繼續使用前面的演算法,全部判斷16個點中是否有12個滿足條件,

以上演算法的缺點:很可能大部分檢測出來的點彼此之間相鄰,我們要去除一部分這樣的點,為了解決這一問題,我們采用了非極大值抑制的演算法
非極大值抑制
對一個角點P建立一個3*3(或5*5,7*7)的視窗,如果該視窗內出現了另一個角點Q,則比較P與Q的大小,如果P大,則將Q點洗掉,如果P小,則將P點洗掉,
1、在速度上要比其他演算法速度快很多
2、受影像噪聲以及設定的閾值影響很大
3、FAST不產生多尺度特征而且FAST特征點沒有方向資訊,這樣就會失去旋轉不變性
2、opencv-Fast角點檢測演算法C++版代碼
#include <QCoreApplication> //該行為Qt環境使用,VS下請注釋或洗掉該行,
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
//**********************************************************************************************
// 【fast角點檢測演算法】
//**********************************************************************************************
int main()
{
string path = "/home/jason/1.jpg"; //圖片路徑
cv::Mat img, gray;
img = cv::imread(path); //讀取圖片
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY); //轉換為灰度圖
std::vector<KeyPoint> kp; //特征點向量
cv::FastFeatureDetector fast(32); //FAST特征檢測器, 32為閾值,閾值越大,特征點越少
fast.detect(gray, kp); //檢測fast特征點
cv::drawKeypoints(img, kp, img, cv::Scalar(0, 255, 0), cv::DrawMatchesFlags::DRAW_OVER_OUTIMG); //畫特征點
cv::namedWindow("img", cv::WINDOW_NORMAL);
cv::imshow("img", img);
cv::waitKey(0);
cv::imwrite("/home/jason/1.jpg", img);
return 0;
}
3、opencv-Fast角點檢測演算法python版代碼
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 13 21:06:59 2017
@author: lql0716
"""
import cv2
img = cv2.imread('D:/photo/01.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
fast = cv2.FeatureDetector_create('FAST')
kp = fast.detect(gray, None)
img2 = cv2.drawKeypoints(img, kp, (0, 0, 255))
cv2.namedWindow('img', cv2.WINDOW_NORMAL)
cv2.imshow('img', img2)
cv2.imwrite('D:/photo/01_1.jpg', img2)
cv2.waitKey(0)
SIFT演算法
1、SIFT綜述
尺度不變特征轉換(Scale-invariant feature transform或SIFT)是一種電腦視覺的演算法用來偵測與描述影像中的區域性特征,它在空間尺度中尋找極值點,并提取出其位置、尺度、旋轉不變數,此演算法由 David Lowe在1999年所發表,2004年完善總結,
其應用范圍包含物體辨識、機器人地圖感知與導航、影像縫合、3D模型建立、手勢辨識、影像追蹤和動作比對,
此演算法有其專利,專利擁有者為英屬哥倫比亞大學,
區域影像特征的描述與偵測可以幫助辨識物體,SIFT 特征是基于物體上的一些區域外觀的興趣點而與影像的大小和旋轉無關,對于光線、噪聲、些微視角改變的容忍度也相當高,基于這些特性,它們是高度顯著而且相對容易擷取,在母數龐大的特征資料庫中,很容易辨識物體而且鮮有誤認,使用 SIFT特征描述對于部分物體遮蔽的偵測率也相當高,甚至只需要3個以上的SIFT物體特征就足以計算出位置與方位,在現今的電腦硬體速度下和小型的特征資料庫條件下,辨識速度可接近即時運算,SIFT特征的資訊量大,適合在海量資料庫中快速準確匹配,
SIFT演算法的特點有:
1. SIFT特征是影像的區域特征,其對旋轉、尺度縮放、亮度變化保持不變性,對視角變化、仿射變換、噪聲也保持一定程度的穩定性;
2. 獨特性(Distinctiveness)好,資訊量豐富,適用于在海量特征資料庫中進行快速、準確的匹配;
3. 多量性,即使少數的幾個物體也可以產生大量的SIFT特征向量;
4. 高速性,經優化的SIFT匹配演算法甚至可以達到實時的要求;
5. 可擴展性,可以很方便的與其他形式的特征向量進行聯合,
SIFT演算法可以解決的問題:
目標的自身狀態、場景所處的環境和成像器材的成像特性等因素影響影像配準/目標識別跟蹤的性能,而SIFT演算法在一定程度上可解決:
1. 目標的旋轉、縮放、平移(RST)
2. 影像仿射/投影變換(視點viewpoint)
3. 光照影響(illumination)
4. 目標遮擋(occlusion)
5. 雜物場景(clutter)
6. 噪聲
SIFT演算法的實質是在不同的尺度空間上查找關鍵點(特征點),并計算出關鍵點的方向,SIFT所查找到的關鍵點是一些十分突出,不會因光照,仿射變換和噪音等因素而變化的點,如角點、邊緣點、暗區的亮點及亮區的暗點等,
Lowe將SIFT演算法分解為如下四步:
1. 尺度空間極值檢測:搜索所有尺度上的影像位置,通過高斯微分函式來識別潛在的對于尺度和旋轉不變的興趣點,
2. 關鍵點定位:在每個候選的位置上,通過一個擬合精細的模型來確定位置和尺度,關鍵點的選擇依據于它們的穩定程度,
3. 方向確定:基于影像區域的梯度方向,分配給每個關鍵點位置一個或多個方向,所有后面的對影像資料的操作都相對于關鍵點的方向、尺度和位置進行變換,從而提供對于這些變換的不變性,
4. 關鍵點描述:在每個關鍵點周圍的鄰域內,在選定的尺度上測量影像區域的梯度,這些梯度被變換成一種表示,這種表示允許比較大的區域形狀的變形和光照變化,
本文沿著Lowe的步驟,參考Rob Hess及Andrea Vedaldi原始碼,詳解SIFT演算法的實作程序,
2. 尺度空間
在一定的范圍內,無論物體是大還是小,人眼都可以分辨出來,然而計算機要有相同的能力卻不是那么的容易,在未知的場景中,計算機視覺并不能提供物體的尺度大小,其中的一種方法是把物體不同尺度下的影像都提供給機器,讓機器能夠對物體在不同的尺度下有一個統一的認知,在建立統一認知的程序中,要考慮的就是在影像在不同的尺度下都存在的特征點,
2.1 多解析度影像金字塔
在早期影像的多尺度通常使用影像金字塔表示形式,影像金字塔是同一影像在不同的解析度下得到的一組結果,其生成程序一般包括兩個步驟:
- 對原始影像進行平滑
- 對處理后的影像進行降采樣(通常是水平、垂直方向的1/2)
降采樣后得到一系列不斷尺寸縮小的影像,顯然,一個傳統的金字塔中,每一層的影像是其上一層影像長、高的各一半,多解析度的影像金字塔雖然生成簡單,但其本質是降采樣,影像的區域特征則難以保持,也就是無法保持特征的尺度不變性,
2.2 高斯尺度空間
我們還可以通過影像的模糊程度來模擬人在距離物體由遠到近時物體在視網膜上成像程序,距離物體越近其尺寸越大影像也越模糊,這就是高斯尺度空間,使用不同的引數模糊影像(解析度不變),是尺度空間的另一種表現形式,
我們知道影像和高斯函式進行卷積運算能夠對影像進行模糊,使用不同的“高斯核”可得到不同模糊程度的影像,一副影像其高斯尺度空間可由其和不同的高斯卷積得到:
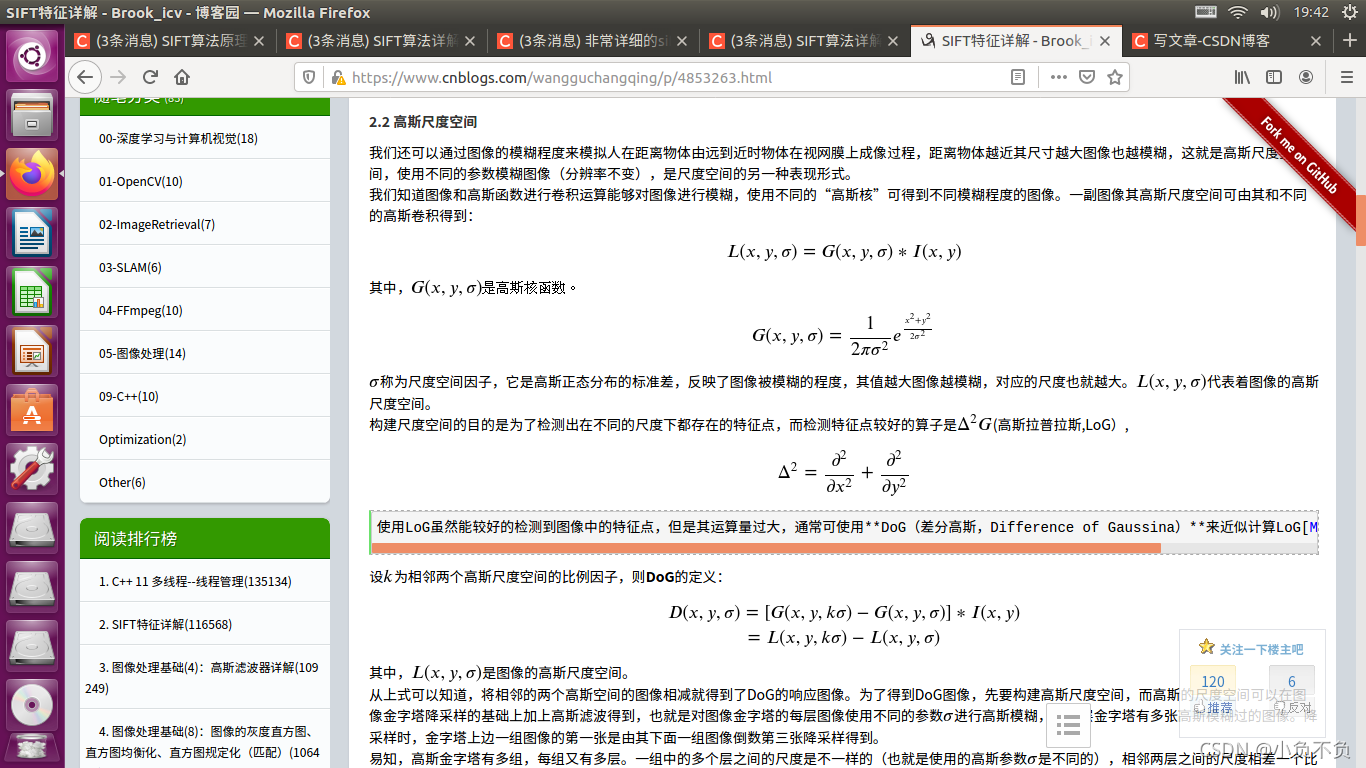
其中,𝐿(𝑥,𝑦,𝜎)是影像的高斯尺度空間,
從上式可以知道,將相鄰的兩個高斯空間的影像相減就得到了DoG的回應影像,為了得到DoG影像,先要構建高斯尺度空間,而高斯的尺度空間可以在影像金字塔降采樣的基礎上加上高斯濾波得到,也就是對影像金字塔的每層影像使用不同的引數𝜎進行高斯模糊,使每層金字塔有多張高斯模糊過的影像,降采樣時,金字塔上邊一組影像的第一張是由其下面一組影像倒數第三張降采樣得到,
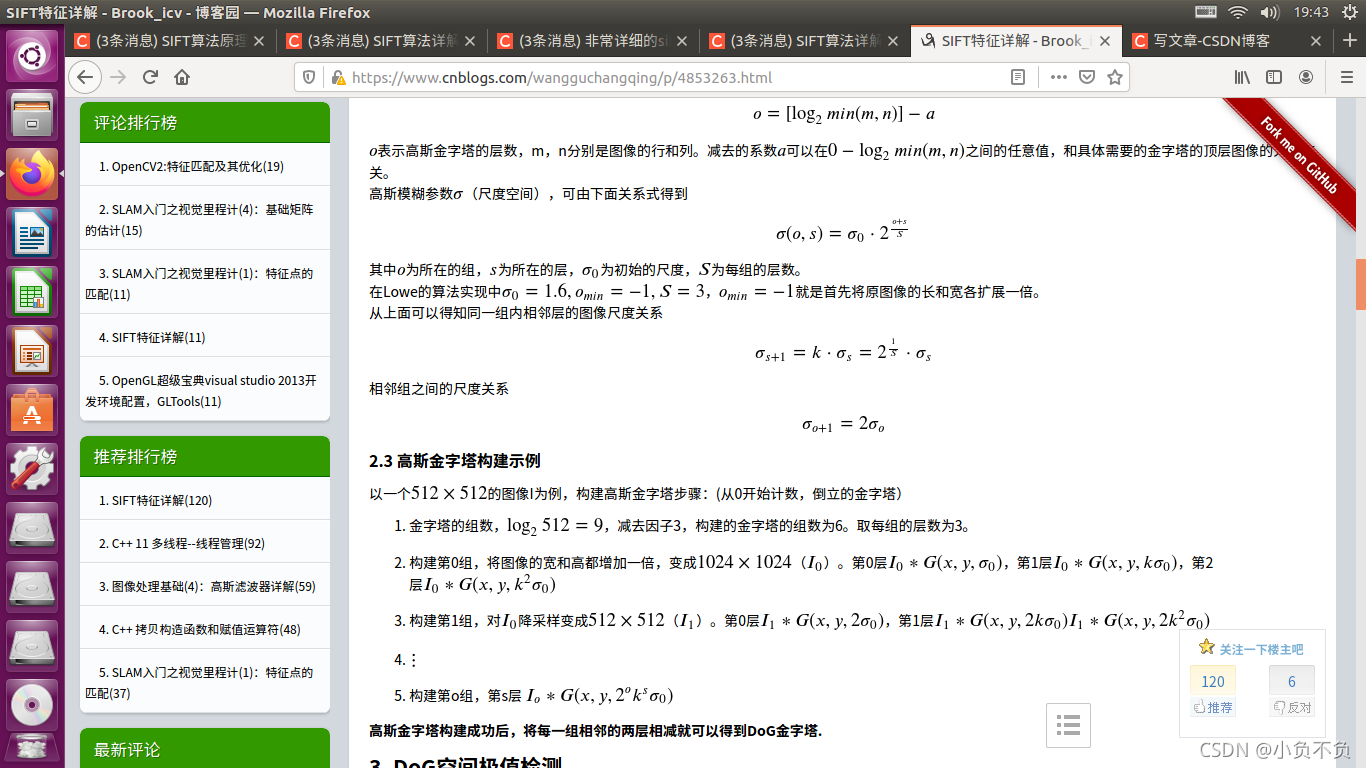
易知,高斯金字塔有多組,每組又有多層,一組中的多個層之間的尺度是不一樣的(也就是使用的高斯引數𝜎是不同的),相鄰兩層之間的尺度相差一個比例因子𝑘,如果每組有𝑆層,則𝑘=21𝑆,上一組影像的最底層影像是由下一組中尺度為2𝜎的影像進行因子為2的降采樣得到的(高斯金字塔先從底層建立),高斯金字塔構建完成后,將相鄰的高斯金字塔相減就得到了DoG金字塔,
高斯金字塔的組數一般是
3. DoG空間極值檢測
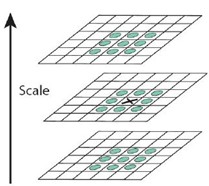
為了尋找尺度空間的極值點,每個像素點要和其影像域(同一尺度空間)和尺度域(相鄰的尺度空間)的所有相鄰點進行比較,當其大于(或者小于)所有相鄰點時,改點就是極值點,如圖所示,中間的檢測點要和其所在影像的3×3
鄰域8個像素點,以及其相鄰的上下兩層的3×3領域18個像素點,共26個像素點進行比較,
從上面的描述中可以知道,每組影像的第一層和最后一層是無法進行比較取得極值的,為了滿足尺度變換的連續性,在每一組影像的頂層繼續使用高斯模糊生成3幅影像,高斯金字塔每組有𝑆+3層影像,DoG金字塔的每組有𝑆+2組影像,
3.1 尺度變化的連續性
設𝑆=3
,也就是每組有3層,則𝑘=21𝑆=213,也就是有高斯金字塔每組有(𝑆?1)3層影像,𝐷𝑜𝐺金字塔每組有(S-2)2層影像,在DoG金字塔的第一組有兩層尺度分別是𝜎,𝑘𝜎,第二組有兩層的尺度分別是2𝜎,2𝑘𝜎,由于只有兩項是無法比較取得極值的(只有左右兩邊都有值才能有極值),由于無法比較取得極值,那么我們就需要繼續對每組的影像進行高斯模糊,使得尺度形成𝜎,𝑘𝜎,𝑘2𝜎,𝑘3𝜎,𝑘4𝜎,這樣就可以選擇中間的三項𝑘𝜎,𝑘2𝜎,𝑘3𝜎,對應的下一組由上一組降采樣得到的三項是2𝑘𝜎,2𝑘2𝜎,2𝑘3𝜎,其首項2𝑘𝜎=2?213𝜎=243𝜎,剛好與上一組的最后一項𝑘3𝜎=233𝜎的尺度連續起來,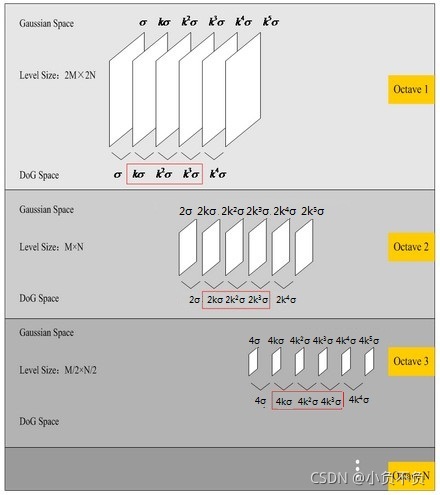
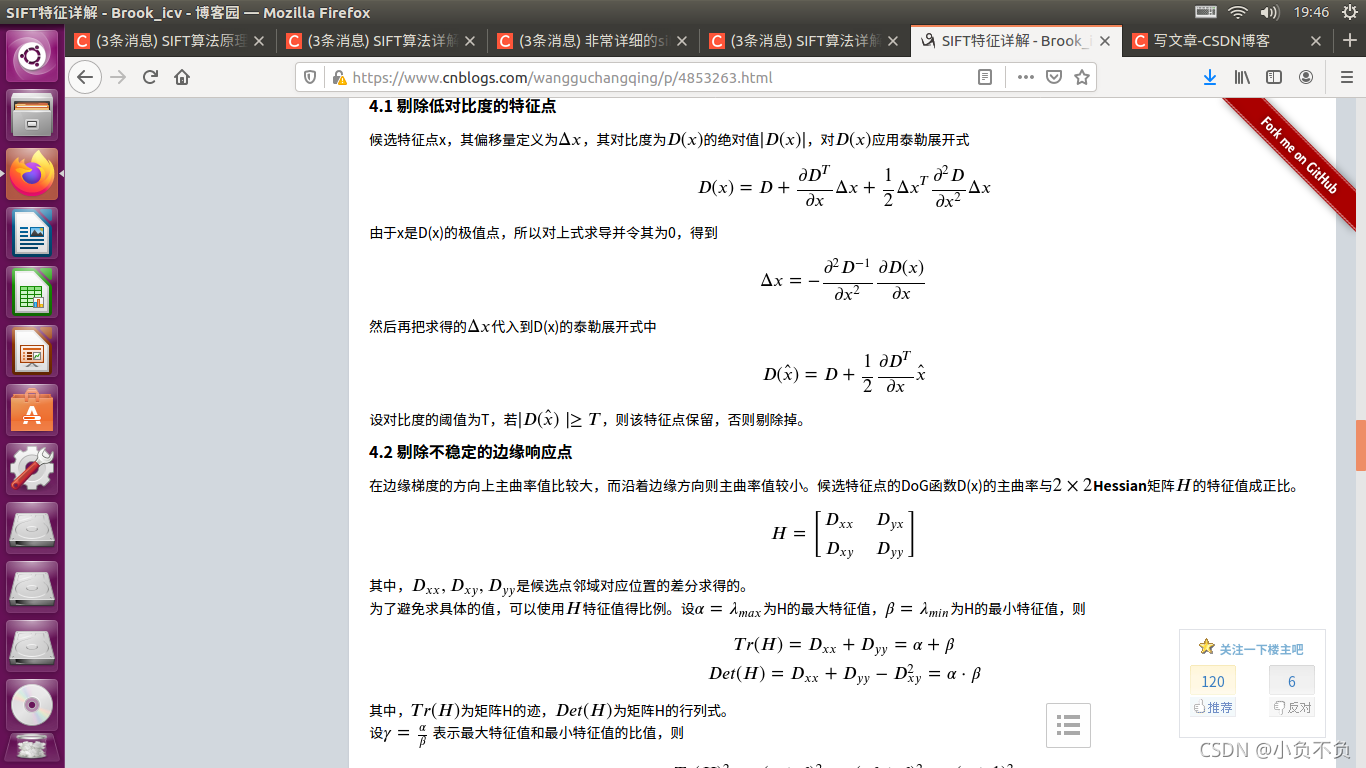
4. 洗掉不好的極值點(特征點)
通過比較檢測得到的DoG的區域極值點實在離散的空間搜索得到的,由于離散空間是對連續空間采樣得到的結果,因此在離散空間找到的極值點不一定是真正意義上的極值點,因此要設法將不滿足條件的點剔除掉,可以通過尺度空間DoG函式進行曲線擬合尋找極值點,這一步的本質是去掉DoG區域曲率非常不對稱的點,
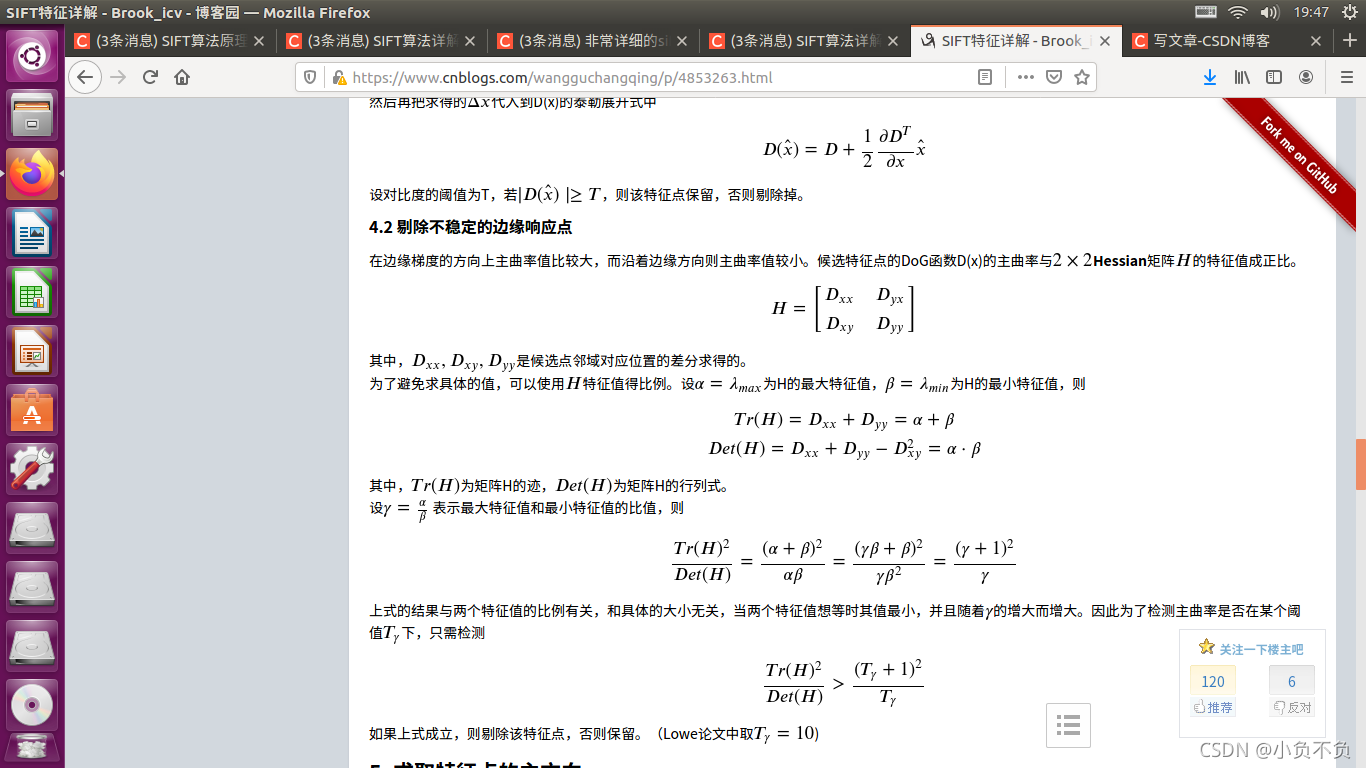
要剔除掉的不符合要求的點主要有兩種:
- 低對比度的特征點
- 不穩定的邊緣回應點

6. 生成特征描述
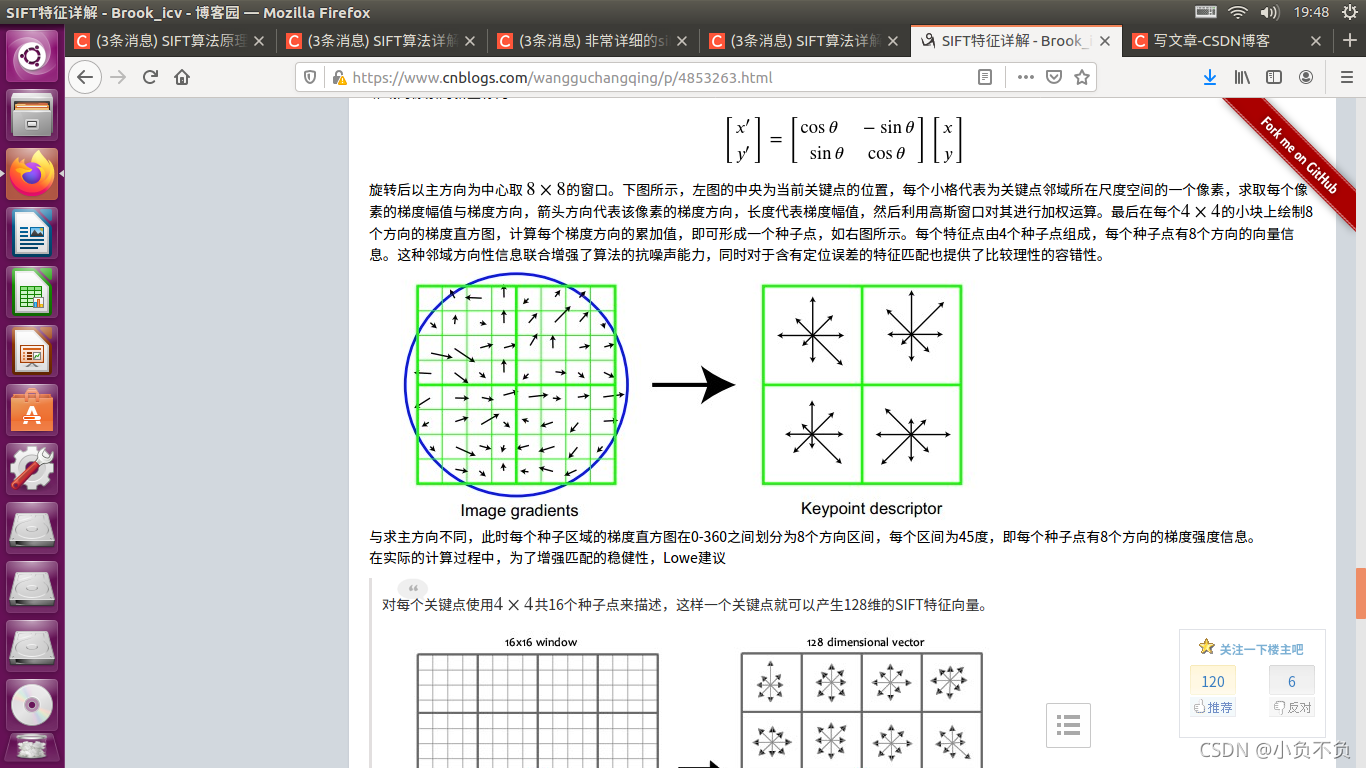
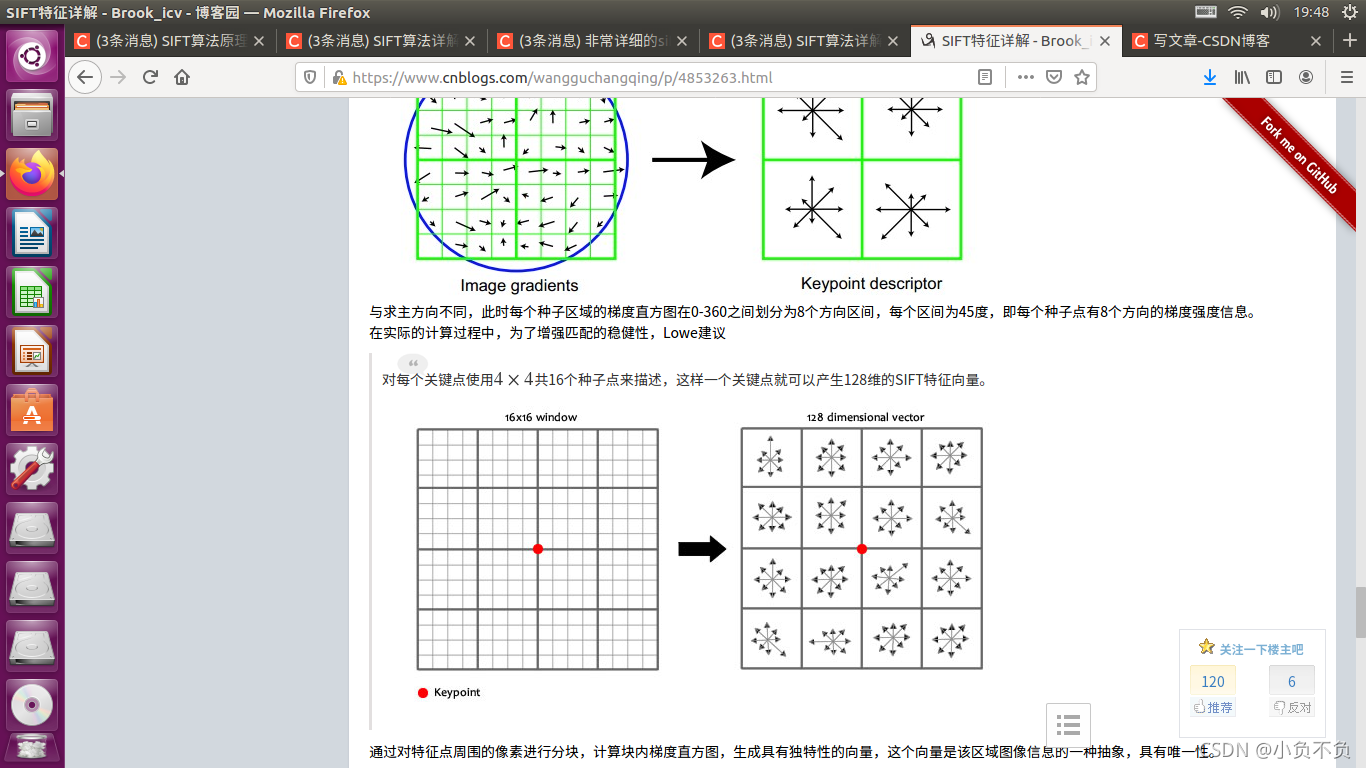
通過以上的步驟已經找到了SIFT特征點位置、尺度和方向資訊,下面就需要使用一組向量來描述關鍵點也就是生成特征點描述子,這個描述符不只包含特征點,也含有特征點周圍對其有貢獻的像素點,描述子應具有較高的獨立性,以保證匹配率,
特征描述符的生成大致有三個步驟:
- 校正旋轉主方向,確保旋轉不變性,
- 生成描述子,最終形成一個128維的特征向量
- 歸一化處理,將特征向量長度進行歸一化處理,進一步去除光照的影響,
為了保證特征矢量的旋轉不變性,要以特征點為中心,在附近鄰域內將坐標軸旋轉𝜃
(特征點的主方向)角度,即將坐標軸旋轉為特征點的主方向,旋轉后鄰域內像素的新坐標為:
7. 總結
SIFT特征以其對旋轉、尺度縮放、亮度等保持不變性,是一種非常穩定的區域特征,在影像處理和計算機視覺領域有著很重要的作用,其本身也是非常復雜的,下面對其計算程序做一個粗略總結,
- DoG尺度空間的極值檢測, 首先是構造DoG尺度空間,在SIFT中使用不同引數的高斯模糊來表示不同的尺度空間,而構造尺度空間是為了檢測在不同尺度下都存在的特征點,特征點的檢測比較常用的方法是Δ2𝐺
- (高斯拉普拉斯LoG),但是LoG的運算量是比較大的,Marr和Hidreth曾指出,可以使用DoG(差分高斯)來近似計算LoG,所以在DoG的尺度空間下檢測極值點,
- 洗掉不穩定的極值點,主要洗掉兩類:低對比度的極值點以及不穩定的邊緣回應點,
- ** 確定特征點的主方向**,以特征點的為中心、以3×1.5𝜎
- 為半徑的領域內計算各個像素點的梯度的幅角和幅值,然后使用直方圖對梯度的幅角進行統計,直方圖的橫軸是梯度的方向,縱軸為梯度方向對應梯度幅值的累加值,直方圖中最高峰所對應的方向即為特征點的方向,
- 生成特征點的描述子, 首先將坐標軸旋轉為特征點的方向,以特征點為中心的16×16
- 的視窗的像素的梯度幅值和方向,將視窗內的像素分成16塊,每塊是其像素內8個方向的直方圖統計,共可形成128維的特征向量,



原文鏈接:https://blog.csdn.net/zddblog/article/details/7521424
SIFT特征詳解 - Brook_icv - 博客園
SIFT python代碼實作
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('test30.jpg')
img1 = img.copy()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
cv2.drawKeypoints(gray, kp, img)
cv2.drawKeypoints(gray, kp, img1, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
plt.subplot(121), plt.imshow(img),
plt.title('Dstination'), plt.axis('off')
plt.subplot(122), plt.imshow(img1),
plt.title('Dstination'), plt.axis('off')
plt.show()轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336162.html
標籤:AI
下一篇:RCE全覆寫