HashMap在JDK7和JDK8是有了一些不同的,具體體現如下:
- JDK7HashMap底層是陣列+鏈表,而JDK8是陣列+鏈表+紅黑樹
- JDK7擴容采用頭插法,而JDK8采用尾插法
- JDK7的rehash是全部rehash,而JDK8是部分rehash,
- JDK8對于key的hash值計算相比于JDK7來說有所優化,
JDK7 HashMap
JDK7HashMap在多執行緒環境下會出現死回圈問題,
假如此時A、B執行緒同時對一個HashMap進行put操作,且HashMap剛號達到擴容條件需要進行擴容
那么這兩個執行緒都會取對HahsMap進行擴容(JDK7HashMap擴容呼叫 resize()方法,而resize()方法中需要呼叫transfer()方法將舊陣列元素全部rehash到新陣列中去重點:這里在多執行緒環境下就會出現問題)
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//對陣列的每一條鏈表遍歷rehash
for (Entry<K,V> e : table) {
while(null != e) {
//保留下一個節點
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//得到對應在新陣列中的索引位置
int i = indexFor(e.hash, newCapacity);
//尾插法
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
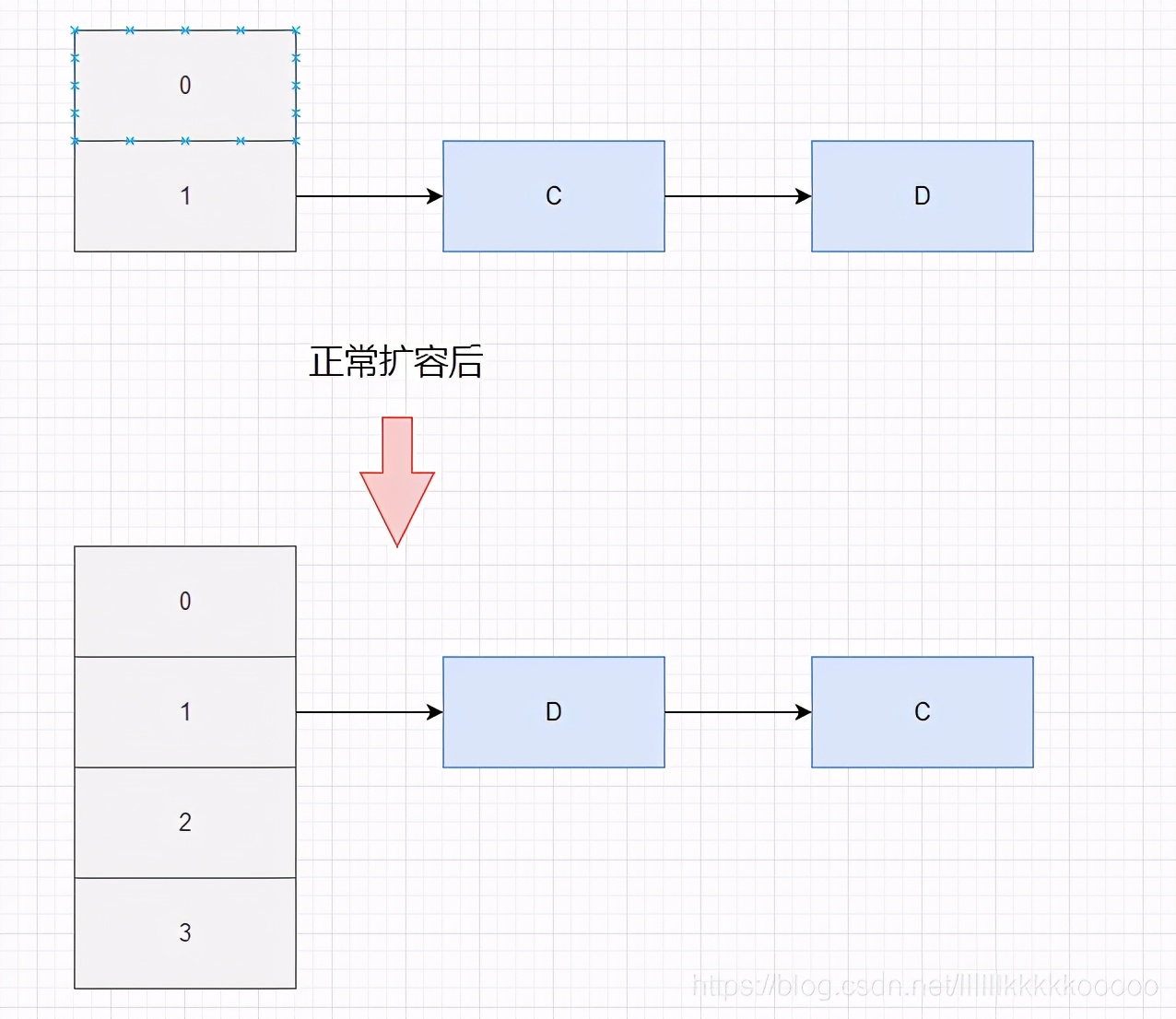
}我們假設現在有一個鏈表 C——>D,且C、D擴容后計算的索引位置依然不變,那他么還在同一鏈表中
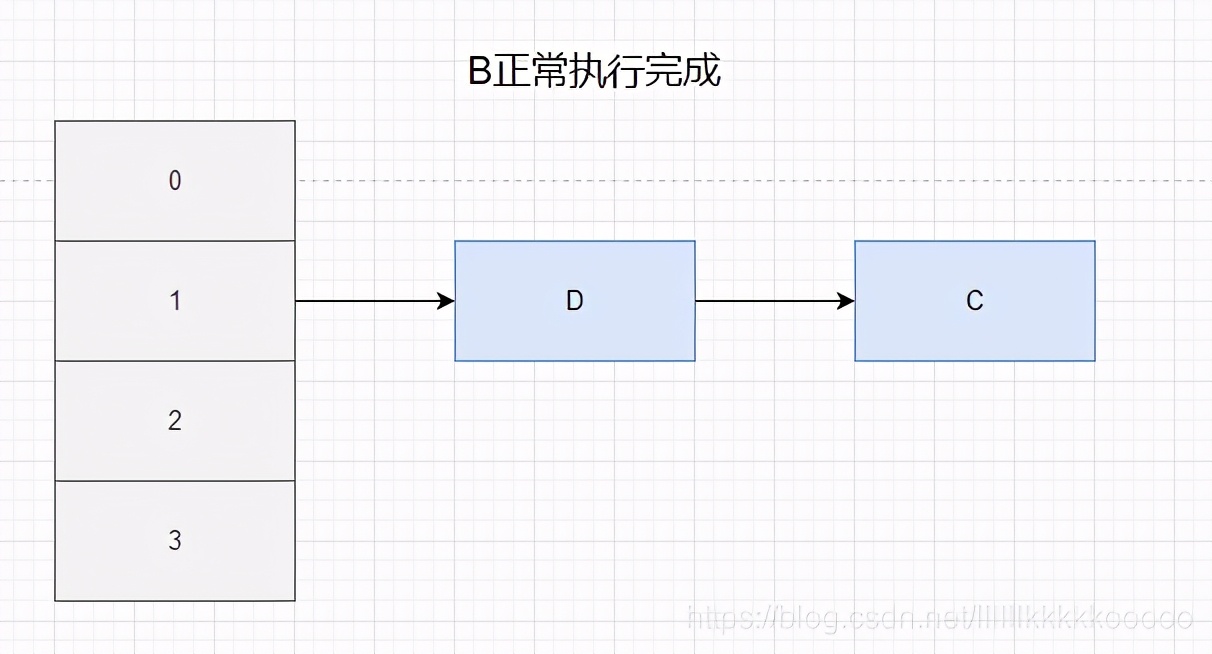
現在A執行緒進入到transfer方法拿到A和它的下一個節點B(Entry<K,V> next = e.next;)后,A執行緒被掛起,此時B執行緒正常走流程將A、Brehash到新的陣列中,那么根據頭插法在新的陣列中是D——>C
B執行完之后,A執行緒繼續去執行
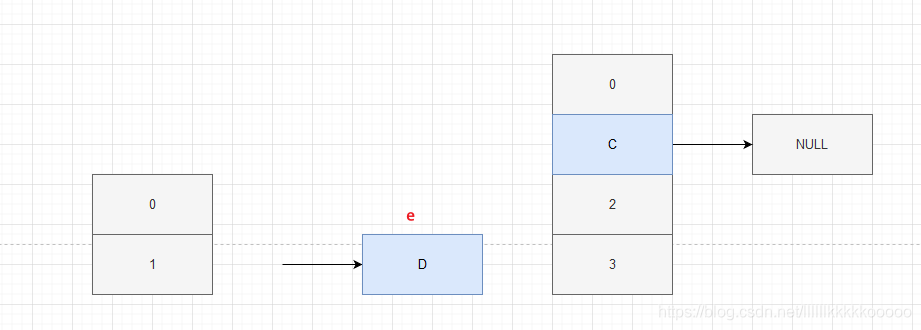
因為A獲取到了 e = C,next = D,所以C可以進行rehash,C進行完后拿到D,發現D.next = C,所以D也可以進行rehash,那么此時因為D——>C,此時會再拿到C,發現C.next = null,但C不是null,所以C再進行rehash,此時鏈表尾 C——> D ——>C,因為此時e = NULL,所以退出回圈,此時出現死回圈,C——>D——>C,
各位可以好好想想這些話或者自己在草稿紙上畫一畫再來看下面的圖!
B正常執行完成
A繼續執行
因為A獲取到了 e = C,next = D,所以C可以進行rehash
C進行完后拿到e = D,發現D.next = C,所以D也可以進行rehash
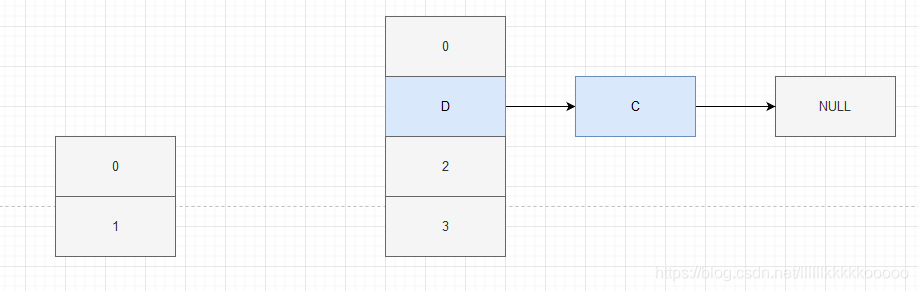
那么此時因為D——>C,此時會再拿到C,發現C.next = null,但C不是null,所以C再進行rehash
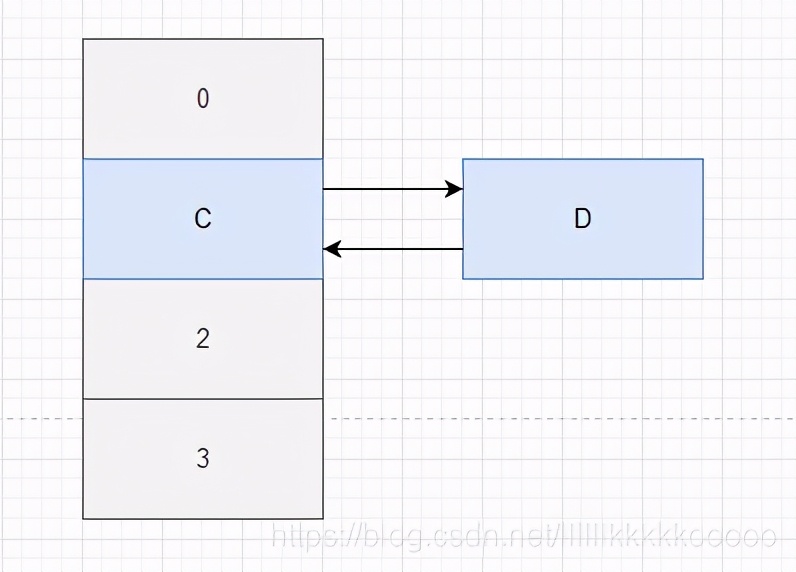
此時e = NULL,所以退出回圈,此時出現死回圈,C——>D——>C,
JDK8 HashMap
JDK1.8會出現資料覆寫的情況
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}第6行代碼:假設兩個執行緒A、B都在進行put操作,并且根據key計算出的hash值相同,那么得到得索引下標也相同,當執行緒A執行完第六行代碼后由于時間片耗盡導致被掛起,而執行緒B得到時間片后在該下標處插入了元素,完成了正常的插入,然后執行緒A獲得時間片,由于之前已經進行了hash碰撞的判斷,所有此時不會再進行判斷,而是直接進行插入,這就導致了執行緒B插入的資料被執行緒A覆寫了,從而執行緒不安全,
第38行代碼++size不安全,還是執行緒A、B,這兩個執行緒同時進行put操作時,假設當前HashMap的zise大小為10,當執行緒A執行到第38行代碼時,從主記憶體中獲得size的值為10后準備進行+1操作,但是由于時間片耗盡只好讓出CPU,執行緒B快樂的拿到CPU還是從主記憶體中拿到size的值10進行+1操作,完成了put操作并將size=11寫回主記憶體,然后執行緒A再次拿到CPU并繼續執行(此時size的值仍為10),當執行完put操作后,還是將size=11寫回記憶體,此時,執行緒A、B都執行了一次put操作,但是size的值只增加了1,所有說還是由于資料覆寫又導致了執行緒不安全,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336171.html
標籤:其他
上一篇:kali與永恒之藍