目錄
- 1 相似度演算法
- 1.1 歐幾里德距離演算法
- 1.2 基于夾角余弦相似度演算法
- 2 最近鄰域
- 3 交替最小二乘法
- 3.1 最小二乘法
- 3.2 交替最小二乘法
- 3.3 ALS演算法流程
- 3.4 ALS演算法實戰
- 3.4.1 資料說明
- 3.4.2 資料建模
- 3.4.3 實戰
- 3.4.4 優化改進
1 相似度演算法
無論是基于用戶還是基于商品的推薦,都是需要找到相似的用戶或者商品,才能做推薦,所以,相似度演算法就變得非常重要了,
常見的相似度演算法有:
- 歐幾里德距離演算法(Euclidean Distance)
- 皮爾遜相似度演算法(Pearson Correlation Coefficient)
- 基于夾角余弦相似度演算法(Consine Similarity)
- 基于Tanimoto系數相似度(Tanimoto Coefficient)
1.1 歐幾里德距離演算法

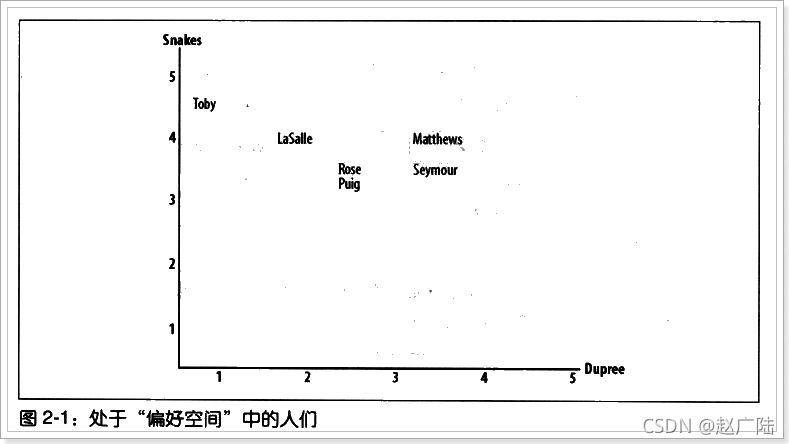
上圖即二維空間中6位用戶對Snakes 和 Dupree 這兩Item評價的直觀體現,
根據兩用戶之間共同評價的Item為維度,建立一個多維的空間,那么通過用戶對單一維度上的評價Score組成的坐標系X(s1,s2,s3……,si)即可定位該用戶在這個多維度空間中的位置,那么任意兩個位置之間的距離Distance(X,Y)(即:歐式距離)就能在一定程度上反應了兩用戶興趣的相似程度,
就其意義而言,歐氏距離越小,兩個用戶相似度就越大,歐氏距離越大,兩個用戶相似度就越小,
1.2 基于夾角余弦相似度演算法
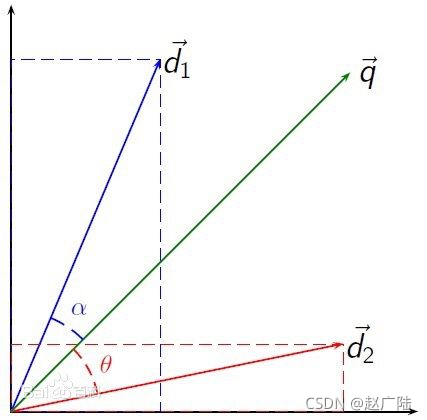
計算夾角,并得出夾角對應的余弦值,此余弦值就可以用來表征,這兩個向量的相似性,夾角越小,余弦值越接近于1,它們的方向更加吻合,則越相似,
計算公式:
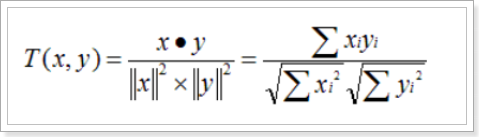
2 最近鄰域
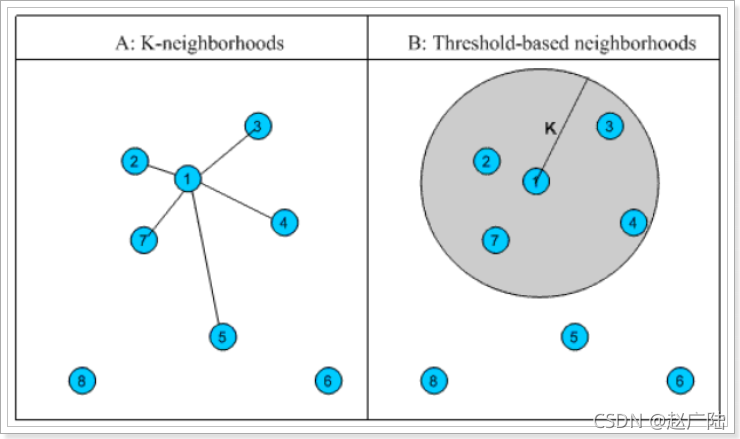
通過相似度計算,可以計算出鄰居,問題來了,我們如果選取出幾個鄰居作為參考,進行推薦呢?
通常有2種方式:
- 固定數量的鄰居:K-neighborhoods
- 基于相似度門檻的鄰居:Threshold-based neighborhoods
3 交替最小二乘法
交替最小二乘法(ALS)是統計分析中最常用的逼近計算的一種演算法,其交替計算結果使得最終結果盡可能地逼近真實結果,而ALS的基礎是最小二乘法(LS演算法),LS演算法是一種常用的機器學習演算法,它通過最小化誤差的平方和尋找資料的最佳函式匹配,利用最小二乘法可以簡便的求得未知的資料,并使得這些求得的資料與實際資料之間誤差的平法和為最小,也就是評分未知,稀疏矩陣預測評分.由于ALS演算法的目標函式不是凸的,而且變數互相耦合在一起,所以它并不容易求解,但如果把用戶特征矩陣U和物品特征矩陣V固定其一,其目標函式就立刻變成了一個凸的而且是可拆分的,
3.1 最小二乘法
以一個變數為例,在二維空間中最小二乘法的原理圖如下:
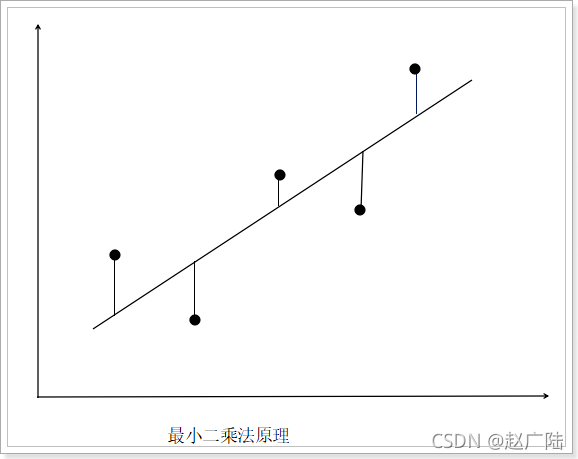
若干個點依次分布在向量空間中,如果希望找出一條直線和這些點達到最佳匹配,那么最簡單的一個方法就是希望這些點到直線的距離最小,則可得出最小二乘法的公式如下:
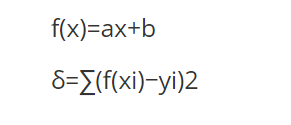
2是開方
這里的f(x)是直接的擬合公式,也是所求的目標函式,在這里希望各個點到直接的值最小,因此第二個公式就是求所有點到該直接的距離,我們可以微分求得其最小值,

3.2 交替最小二乘法
以用戶,商品為例說明,一個基于用戶名,物品表的用戶評分矩陣可以被分解成2個較為小型化的矩陣,即M=U的轉置矩陣*V,
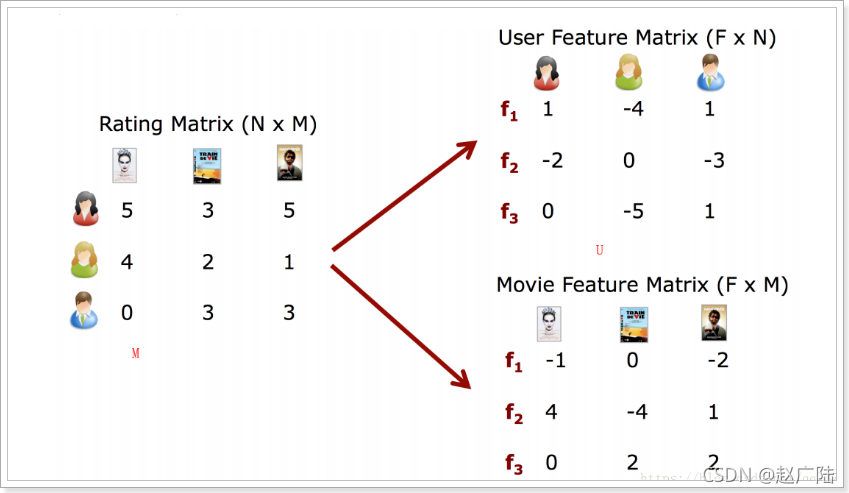
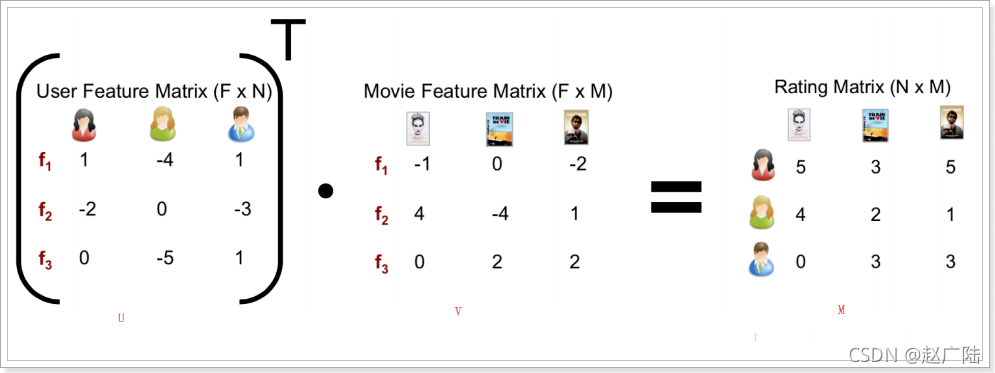
在這里U和V分別表示 用戶和物品的矩陣,在MLlib的ALS演算法中,首先會對U或者V矩陣隨機生成,之后固定某一個特定的物件,去求取另一個未隨機化的矩陣物件,
之后利用求取的矩陣物件去求隨機化矩陣物件,最后兩個物件相互迭代計算,求取與實際矩陣差異達到程式設定的最小閥值位置,
通俗的說就是先固定U矩陣,求取V,然后再固定V矩陣再求取U矩陣,一直這樣交替迭代計算直到誤差達到一定的閥值條件或者達到迭代次數的上限,例如,固定U求V,這個問題就是經典的最小二乘問題,所謂交替,就是指先隨機生成U(0),然后固定它,去 求 解V ( 0 ) ;再 固 定V ( 0 ) ,然 后 求 解U ( 1 ) ,這 樣 交 替 進 行 下 去 , 因 為 每一次迭代都會降低重構誤差,并且誤差是有下界的,所以ALS演算法一定會收斂,但由于目標函式是非凸的,所以ALS演算法并不保證會收斂到全域最優解,然而在實際應用中,ALS演算法對初始
點不是很敏感,且是不是全域最優解也不會有大的影響,
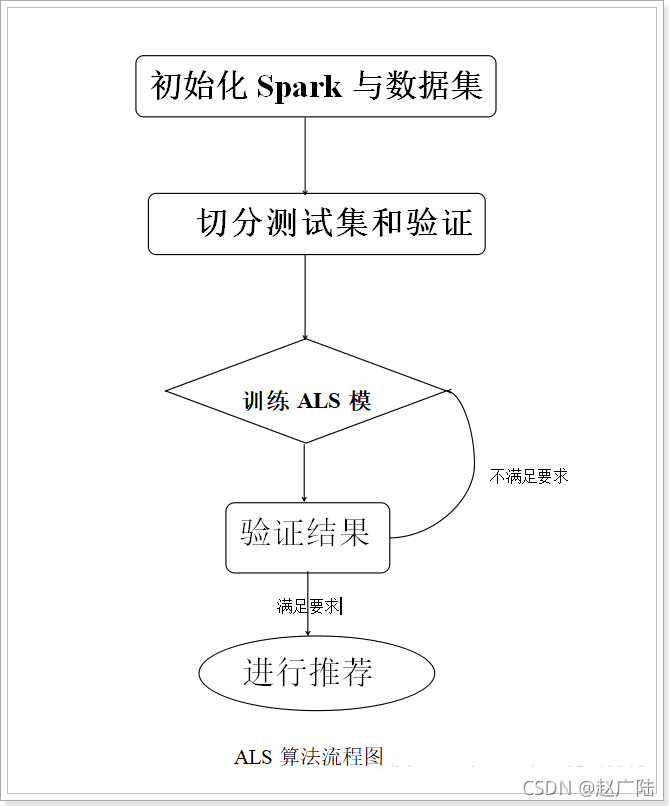
3.3 ALS演算法流程
通常,產品的用戶評分矩陣是龐大且稀疏的,因此在非常稀疏的資料集上采用簡單的用戶(或物品)相似度比較進行推薦,直觀上給人的感覺是這樣做缺少依據,理論上分析一下我們也能理解,基于記憶的協同過濾推薦實際上并沒有充分挖掘資料集中的潛在因素,本節介紹的交替最小二乘法(AlternatingLeastSquares,ALS)演算法,其核心思想就是要進一步挖掘通過觀察得到的所有用戶給產品的評分,并通過引入用戶特征矩陣(UserFeaturesMatrix)和物品特征矩陣(ItemFeaturesMatrix)來建立一個機器學習模型,然后利用采集的資料對這個模型進行訓練(反復迭代),最后得到用于推薦計算的用戶特征矩陣和物品特征矩陣,從而來推斷(也就是預測)每個用戶的喜好并向用戶推薦適合的物品,
ALS演算法解決了用戶評分矩陣中的缺失因子問題,實作了用預測得到的缺失因子進行推薦,
ALS 演算法的思路就不同了, ALS 演算法基于下面這個假設:評分矩陣是近似低秩 (Low?Rank) 矩陣;換句話說,評分矩陣 A(mxn) 可以用兩個小矩陣 U(mxk) 和 V(nxk) 來近似表示,即:
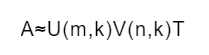
式中, k 遠小于 m 和 n, 這樣就把整個系統的自由度從 O(mn) 降到了 O((m+n)k) ,其實,
ALS 演算法的低秩假設是建立在客觀存在的合理性基礎上的,例如,用戶特征有很多,如年齡、性別、職業、身高、學歷、婚姻、地區、存款等,可以說不勝列舉,但我們沒有必要把用戶的所有特征都用起來,因為并不是所有特征都起同樣的作用,例如,在后面展示的電影推薦示例中,用戶特征矩陣僅僅包含了用戶編號、性別、年齡、職業、郵編5 個欄位,同樣,物品的屬性也有很多,以電影為例,可以有主演、導演、特效、劇情、型別等,但實際應用中我們只需要描述少數關鍵屬性即可,因此我們僅僅考慮了三個屬性,即電影編號、電影名和電影類別(當然這只是示例,到底 k 取什么值,可以采用系統自適應調節方法,通過應用逐步找到最佳的 k 值),
總之, ALS 演算法的巧妙之處就在于,引入了兩個特征矩陣,一個是用戶特征矩陣,用 U表示,另一個是物品特征矩陣,用 V 表示,這兩個矩陣的秩都比較低,接下來的問題是怎樣得到這兩個抽象的低秩序陣,既然已經假設評分矩陣 A 可以通過UVT 來近似,那么一個最直接的可以量化的東西就是通過 U 和 V 重構 A 時產生的誤差,在ALS 演算法中,使用式給出的 Frobenius 范數(又稱為 Euclid 范數)
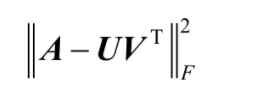
來表示重構誤差,也就是每個元素的重構誤差的平方和,如式所示,
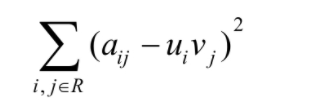
這里存在一個問題,由于只觀察到部分評分,A中有大量的未知元素是需要推斷的,所以這個重構誤差包含了未知數,解決方案很簡單,就是只計算對已知評分的重構誤差,
當然,也可以先用一個簡單的方法把評分矩陣填滿,再進行重構誤差計算,但是這樣做似乎也沒有太多道理,總之,ALS演算法就是求解下面的優化問題:
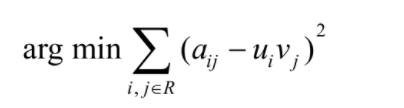
經過上面的處理,一個協同推薦問題就通過低秩假設被成功地轉換成了一個優化問題,
但是,這個優化問題怎么解呢?不要忘記,我們的目標是求出U和V這兩個矩陣,
ALS 演算法可以大體描述如下,
第一步,用小于 1 的數隨機初始化 V ,
第二步,在訓練資料集上反復迭代、交替計算 U 和 V, 直到 RMSE (均方根誤差,一種常用的離散性度量方法)值收斂或迭代次數足夠多,
第三步,回傳 UVT, 進行預測推薦,之所以說上述演算法是一個大體描述,是因為第二步中還包含了如何計算 U 和 V 的運算式,它們是通過求偏導推出的,
3.4 ALS演算法實戰
3.4.1 資料說明
ALS 演算法對 GroupLens Research ( http://grouplens.org/datasets/movielens/) 提供的資料進行學習并推薦,該資料為一組從 20 世紀 90 年代末到 21 世紀初由 MovieLens 用戶提供的電影評價資料,包括評分、電影元資料(如風格型別和年代),以及關于用戶的人口統計學資料(如年齡、郵編、性別和職業等),根據不同需求, GroupLens Research 提供了不同大小的樣本資料,包含了評分、用戶資訊和電影資訊三種資料,下面先來看看待處理的電影評價資料,再給出應用程式并進行分析,
示例資料是用戶、電影、評分的資料,其中用戶有943人,電影有1682部,評價有100000條,檔案在資料中,
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013
62 257 2 879372434
286 1014 5 879781125
200 222 5 876042340
210 40 3 891035994
................
3.4.2 資料建模
ALS演算法的第二步就是資料建模,其實在MLlib演算法庫中有可以直接使用的訓練演算法,ALS.tran方法原始碼如下:
def train(
ratings: RDD[Rating], //需要訓練的資料集
rank: Int, //模型中隱藏因子數,rank一般選在8到20之間
iterations: Int, //演算法中迭代次數,一般10次即可
lambda: Double, //ALS中的正則化引數,一般設定0.01
blocks: Int, //并行計算的block數(-1為自動配置)
alpha: Double, //ALS隱式反饋變化率用于控制每次擬合修正的幅度
seed: Long //加載矩陣的亂數
): MatrixFactorizationModel = {
new ALS(blocks, blocks, rank, iterations, lambda, true, alpha, seed).run(ratings)
}
3.4.3 實戰
package cn.oldlu.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.recommendation.ALS;
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel;
import org.apache.spark.mllib.recommendation.Rating;
public class MyRecommend {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("MyRecommend")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
jsc.setLogLevel("WARN"); //設定日志級別
JavaRDD<String> rawData = jsc.textFile("F://ml-100k//u.data");//設定資料集檔案
JavaRDD<String[]> rawRatings = rawData.map(v1 -> v1.split("\t"));//將資料按照\t分割
//轉化為Rating結構,引數分別為:用戶id,商品id,評分
JavaRDD<Rating> ratings = rawRatings.map(v1 -> new Rating(Integer.valueOf(v1[0]), Integer.valueOf(v1[1]), Double.valueOf(v1[2])));
//設定訓練模型
MatrixFactorizationModel model = ALS.train(ratings.rdd(), 8, 10, 0.01);
//為789用戶推薦10個商品
Rating[] recommendProducts = model.recommendProducts(789, 10);
//列印推薦結果
for (Rating rating : recommendProducts) {
System.out.println(rating.user() + "->" + rating.product()+": " + rating.rating());
}
}
}
3.4.4 優化改進
在上面的實戰中,rank、iterations、lambda引數都是寫死的,根據不同環境和資料集需要作出調整,所以我們需要計算中最佳的引數,才能得到最佳的訓練集,
package cn.oldlu.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.recommendation.ALS;
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel;
import org.apache.spark.mllib.recommendation.Rating;
import scala.Tuple2;
import java.util.List;
public class MyRecommend2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf()
.setAppName("MyRecommend")
.setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
jsc.setLogLevel("WARN"); //設定日志級別
JavaRDD<String> rawData = jsc.textFile("F://ml-100k//u.data");//設定資料集檔案
JavaRDD<String[]> rawRatings = rawData.map(v1 -> v1.split("\t"));//將資料按照\t分割
//裝載樣本評分資料,其中最后一列Timestamp取除10的余數作為key,Rating為值,即(Int,Rating)
JavaPairRDD<Long, Rating> ratings = rawRatings.mapToPair(v1 -> {
Rating rating = new Rating(Integer.valueOf(v1[0]), Integer.valueOf(v1[1]), Double.valueOf(v1[2]));
return new Tuple2<>(Long.valueOf(v1[3]) % 10, rating);
});
//裝載電影目錄對照表(電影ID->電影標題)
List<Tuple2> movies = jsc.textFile("F://ml-100k//u.item").map(v1 -> {
String[] ss = v1.split("\\|");
return new Tuple2(ss[0], ss[1]);
}).collect();
//統計有用戶數量和電影數量以及用戶對電影的評分數目
Long numRatings = ratings.count();
Long numUsers = ratings.map(v1 -> ((Rating) v1._2()).user()).distinct().count();
Long numMovies = ratings.map(v1 -> ((Rating) v1._2()).product()).distinct().count();
System.out.println("用戶:" + numUsers + "電影:" + numMovies + "評論:" + numRatings);
//將樣本評分表以key值切分成3個部分,分別用于訓練 (60%,并加入用戶評分), 校驗 (20%), and 測驗 (20%)
//該資料在計算程序中要多次應用到,所以cache到記憶體
Integer numPartitions = 4; // 磁區數
// 訓練集
JavaRDD<Rating> training = ratings
.filter(v -> v._1() < 6)
.values()
.repartition(numPartitions)
.cache();
// 校驗集
JavaRDD<Rating> validation = ratings
.filter(v -> v._1() >= 6 && v._1() < 8)
.values()
.repartition(numPartitions).cache();
// 測驗集
JavaRDD<Rating> test = ratings
.filter(v -> v._1() >= 8)
.values()
.cache();
Long numTraining = training.count();
Long numValidation = validation.count();
Long numTest = test.count();
System.out.println("訓練集:" + numTraining + " 校驗集:" + numValidation + " 測驗集:" + numTest);
//訓練不同引數下的模型,并在校驗集中驗證,獲取最佳引數下的模
int[] ranks = new int[]{10, 11, 12};
// double[] lambdas = new double[]{0.01, 0.03, 0.1, 0.3, 1, 3};
double[] lambdas = new double[]{0.01};
// int[] numIters = new int[]{8, 9, 10, 11, 12, 13, 14, 15};
int[] numIters = new int[]{8, 9, 10};
MatrixFactorizationModel bestModel = null;
double bestValidationRmse = Double.MAX_VALUE;
int bestRank = 0;
double bestLambda = -0.01;
int bestNumIter = 0;
for (int rank : ranks) {
for (int numIter : numIters) {
for (double lambda : lambdas) {
MatrixFactorizationModel model = ALS.train(training.rdd(), rank, numIter, lambda);
Double validationRmse = computeRmse(model, validation, numValidation);
System.out.println("RMSE(校驗集) = " + validationRmse + ", rank = " + rank + ", lambda = " + lambda + ", numIter = " + numIter);
if (validationRmse < bestValidationRmse) {
bestModel = model;
bestValidationRmse = validationRmse;
bestRank = rank;
bestLambda = lambda;
bestNumIter = numIter;
}
}
}
}
double testRmse = computeRmse(bestModel, test, numTest);
System.out.println("測驗資料集在 最佳訓練模型 rank = " + bestRank + ", lambda = " + bestLambda + ", numIter = " + bestNumIter + ", RMSE = " + testRmse);
// 計算均值
Double meanRating = training.union(validation).mapToDouble(v -> v.rating()).mean();
// 計算標準誤差值
Double baselineRmse = Math.sqrt(test.map(v -> (meanRating - v.rating()) * (meanRating - v.rating())).reduce((v1, v2) -> (v1 + v2) / numTest));
// 計算準確率提升了多少
double improvement = (baselineRmse - testRmse) / baselineRmse * 100;
System.out.println("最佳訓練模型的準確率提升了:" + String.format("%.2f", improvement) + "%.");
// 構建最佳訓練模型
bestModel = ALS.train(ratings.values().rdd(), bestRank, bestNumIter, bestLambda);
Rating[] recommendProducts = bestModel.recommendProducts(789, 10);
//列印推薦結果
for (Rating rating : recommendProducts) {
System.out.println(rating.user() + "->" + rating.product()+": " + rating.rating());
}
}
/**
* 校驗集預測資料和實際資料之間的均方根誤差
**/
public static Double computeRmse(MatrixFactorizationModel model, JavaRDD<Rating> data, Long n) {
// 進行預測
JavaRDD<Rating> predictions = model.predict(data.mapToPair(v -> new Tuple2<>(v.user(), v.product())));
JavaRDD<Tuple2<Double, Double>> predictionsAndRatings = predictions
.mapToPair(v -> new Tuple2<>(new Tuple2<>(v.user(), v.product()), v.rating()))
.join(data.mapToPair(v -> new Tuple2<>(new Tuple2<>(v.user(), v.product()), v.rating()))).values();
Double reduce = predictionsAndRatings.map(v -> (v._1 - v._2) * (v._1 - v._2))
.reduce((v1, v2) -> (v1 + v2) / n);
//正平方根
return Math.sqrt(reduce);
}
}
運行結果:
用戶:943電影:1682評論:100000
訓練集:60024 校驗集:20435 測驗集:19541
RMSE(校驗集) = 1.9042189155615398E-5, rank = 10, lambda = 0.01, numIter = 8
RMSE(校驗集) = 4.241470253244084E-5, rank = 10, lambda = 0.01, numIter = 9
RMSE(校驗集) = 1.4449138813397543E-5, rank = 10, lambda = 0.01, numIter = 10
RMSE(校驗集) = 6.082115231352825E-5, rank = 11, lambda = 0.01, numIter = 8
RMSE(校驗集) = 7.053700942035736E-5, rank = 11, lambda = 0.01, numIter = 9
RMSE(校驗集) = 2.6551033361283012E-5, rank = 11, lambda = 0.01, numIter = 10
RMSE(校驗集) = 3.31869548209156E-5, rank = 12, lambda = 0.01, numIter = 8
RMSE(校驗集) = 7.16881674580905E-5, rank = 12, lambda = 0.01, numIter = 9
RMSE(校驗集) = 4.8896811754448735E-5, rank = 12, lambda = 0.01, numIter = 10
測驗資料集在 最佳訓練模型 rank = 10, lambda = 0.01, numIter = 10, RMSE = 1.4925418704176325E-5
最佳訓練模型的準確率提升了:81.34%.
789->1598: 9.396627380043618
789->1368: 8.14482648449507
789->1466: 7.38882286732828
789->1462: 6.81871292883074
789->1059: 6.795506701087147
789->337: 6.780524189917936
789->267: 6.772379061916583
789->1184: 6.688179558303117
789->906: 6.528331428606722
789->854: 6.466069010345999
從運行效果來看:
- 總共有943個用戶,1682個電影(已經去重),100000條評分資料;
- 如程式,我們把所有資料分為三部分:
- 60%用于訓練、20%用于校驗、20%用于測驗模型;
- 模型在不同引數下的均方根誤差(RMSE)值,以及對應的引數,最優的引數選擇均方根誤差(RMSE)最小的引數值—即最優引數模型建立;
- 使用20%的測驗模型資料來測驗模型的好壞,也就是均方根誤差(RMSE),在最優引數模型基礎上提升了81.34%的準確率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336187.html
標籤:其他
上一篇:三、區分存盤物件的不同版本