這篇文章介紹下這個 Lucene,下篇寫寫 ElasticSearch , 然后再繼續填 Spring 的坑 🕳
內容的話就很基礎啦🐖,希望能幫你快速入門,了解下它
目錄
為啥要介紹這個 Lucene 呢?畢竟它是搜索引擎核心中的核心
其實是因為我想體驗下這個工具包,試著感受下 ElasticSearch 為啥要封裝它?以及他們之間的聯系~ 等🐖
Lucene
Lucene 是一個開源的,全文索引工具包,有 索引,搜索,分詞 等功能
是 ElasticSearch 和 Apache Solr 的核心,
在 MySQL 中,Innodb 和 MyISAM 的索引結構都是 B+樹, 而到了 Lucene , 就不得不說下這個倒排索引了,
倒排索引
這個就是通過 value ——> Key ,感覺有點像 MySQL 的回表操作🐖,但是這里還有 分詞,檔案 等概念,
比如我們平時在 百度,Google ,電商平臺等中進行搜索時,就是通過這個 關鍵字 找到相應的 檔案 內容出來
概念
下面會介紹下這些概念 👇
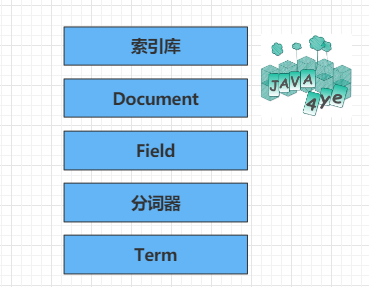
他們之間的關系就用這個來表示啦,這個也是本文的重點🐖
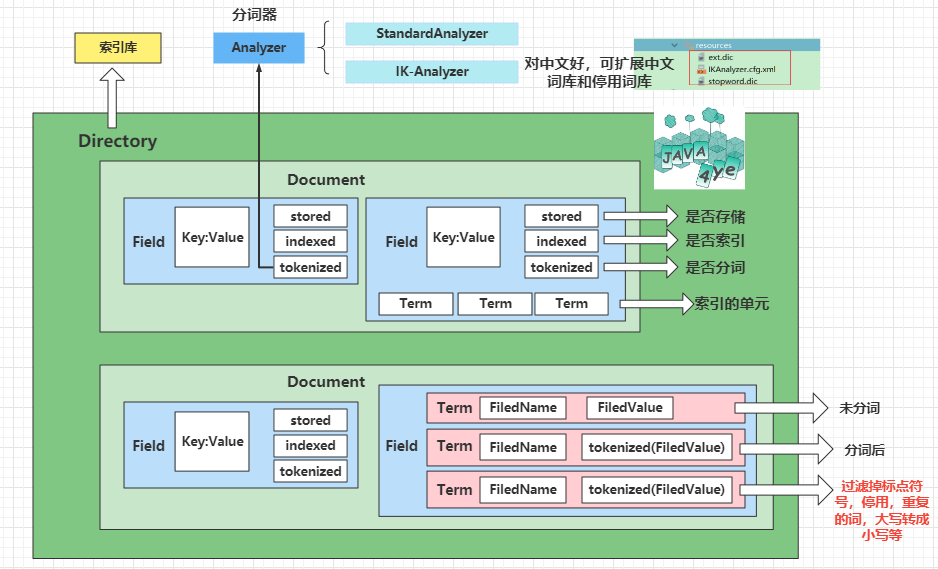
下面開始一一介紹啦😄
檔案
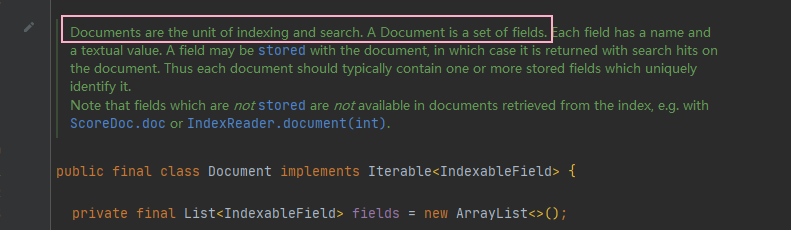
對應 Document 物件 👇
檔案 是 Lucene 內部的資料結構,索引檔案時,會按照一定規則去創建索引,生成倒排索引檔案,
查詢時就直接搜索到對應的索引檔案,獲取資料,效率非常高!
它是搜索和索引的單位,也是欄位的集合,
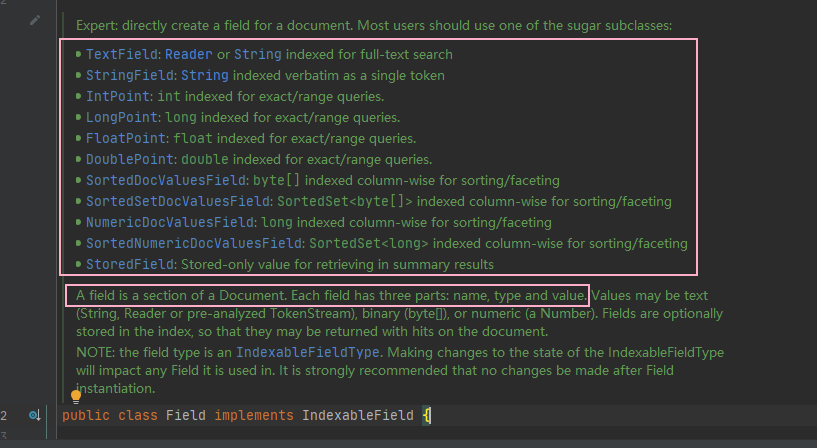
欄位
對應 Field 物件 👇 ,由三部分組成 :name,type,value
- name :欄位域名, 可以看作我們創建的 Model 的屬性名稱,如 name,age,id 等等,在同個索引庫中是唯一的
- value : 欄位值, 存盤檔案的部分內容,如
name:Java4ye這個 Field 中的值 Java4ye - type : 欄位型別,如 是否分詞,索引,存盤 等
詞匯
對應 Term 物件 👇 ,由兩部分組成 :name,value
- name :Field 的名稱 ,即 欄位域名
- value : Field 中檔案的部分內容 ,即 欄位值
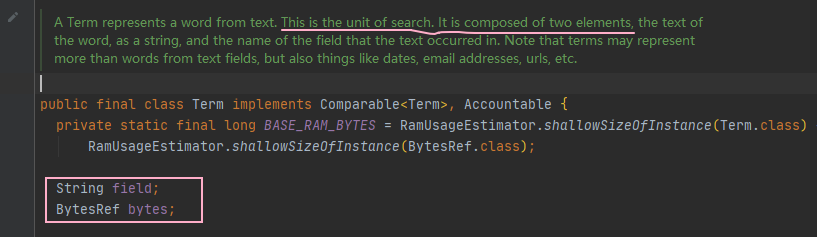
如果還不清楚,那么再看看下面這里你就懂啦~
分詞
這個是超級核心! 🐖
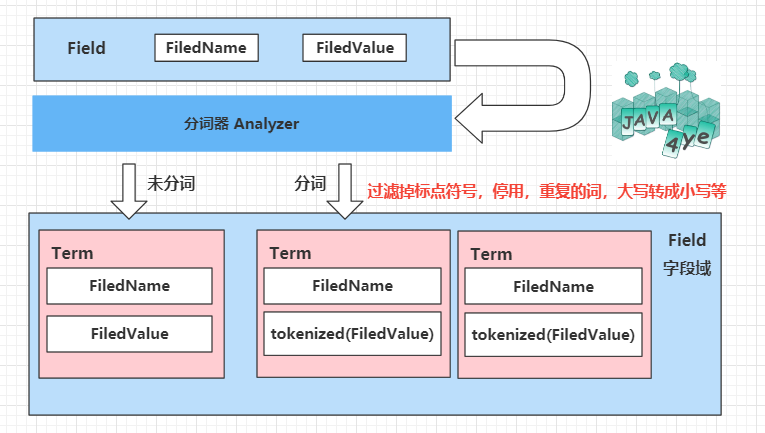
分詞的目的是為了索引,索引的目的是為了搜索,就像查字典一樣🐖
分詞的程序是先分詞,再過濾(過濾掉標點符號,停用,重復的詞,大寫轉成小寫等)
比如這個標準分詞器 : StandardAnalyzer 👇
通過注釋可以發現它會進行 停用詞,大寫轉成小寫 的過濾操作,

中文分詞器推薦 IK-Analyzer
小結
那么到了這里,咱們再把上面的知識點串一串~ 😄
通過咱們這個分詞器,會對欄位域中的 value 進行分詞,當然你也可以根據需求選擇不分詞,
不分詞就一個 Term ,分詞后會產生很多 Term,Term 的 name 就是這個 欄位域的名稱, Value 就是分出來的詞,
比如 對 desc:nice to meet you 的欄位域進行過分詞,會出現這四個單詞:nice,to,meet,you
索引庫
差點漏了這個~
可以看到里面有 段的概念 Segment 和 鎖🔒 等
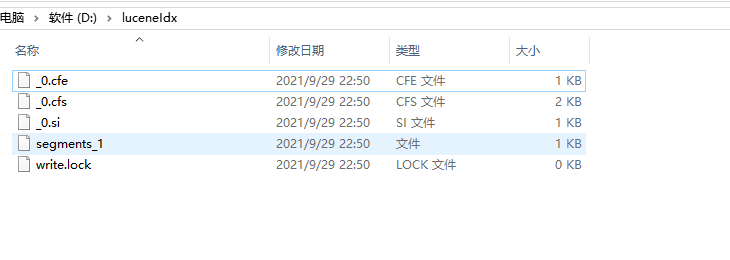
把整個檔案夾看到一個 Index,Segment 就是里面的 sub-index,
當創建索引時,不是立刻就刷到磁盤的,需要先寫入緩沖區,然后等滿了,或者關閉了,手動 flush 等操作才一起寫入磁盤,這也是它為什么是 近實時而非實時查詢 的原因 🐖
查詢時其實就是在 Segment 中查找,需要對多個 Segment 進行合并,搜索,找到相應的 docID ,再去存放資料的檔案中獲取并回傳,
Luke
下載地址:
https://github.com/DmitryKey/luke
這里用這個 Luke 工具演示下 👇
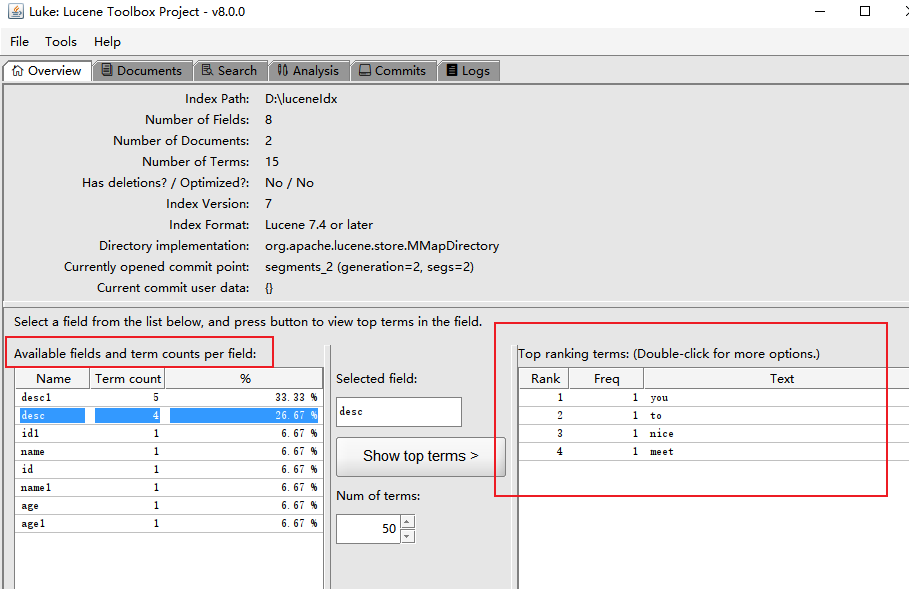
可以看到 desc 欄位域分詞后有四個 Term ,
上面介紹完了這些概念,這里就來開始實踐啦,將這些概念串聯起來,代碼同樣可以在 Github 上獲取 👇
https://github.com/Java4ye/springboot-demo-4ye
全文檢索流程
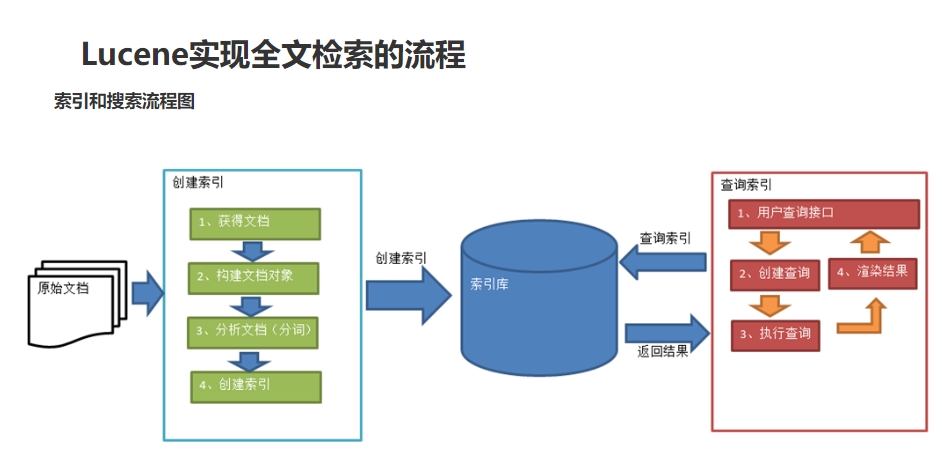
這里就兩個操作👉 創建索引 和 查詢索引 ,操作步驟寫代碼里啦,就不多說了🐖
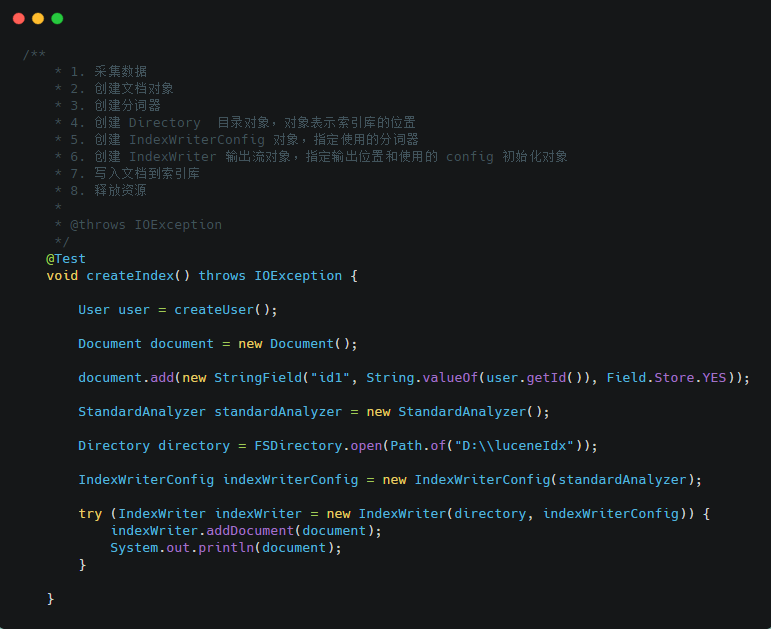
創建索引
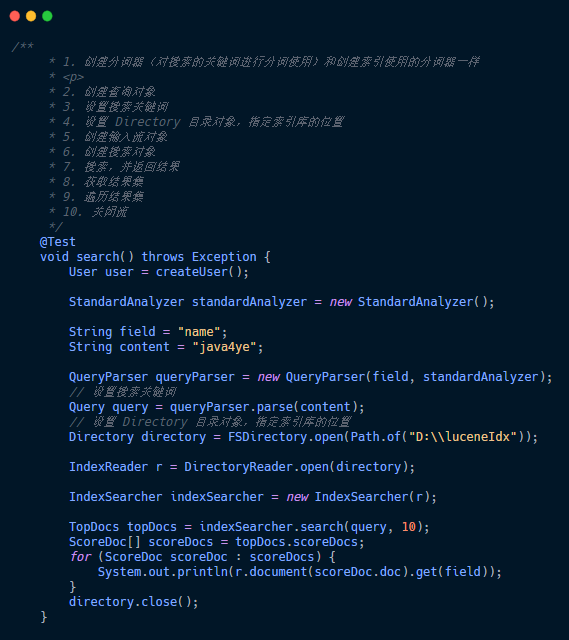
查詢索引
奇怪的識訓
由于專案中引入了 ElasticSearch , 它的底層核心又是 Lucene ,所以這里我沒有再去引入 Lucene , 而是直接使用,結果卻成了踩坑的開始🐖
這里可以看到 Lucene 是8.5.1 版本的,這樣 Lulke 工具是運行不了的 ,會報錯,但是 Lucene8.0 版本可以運行,所以得重新引包,
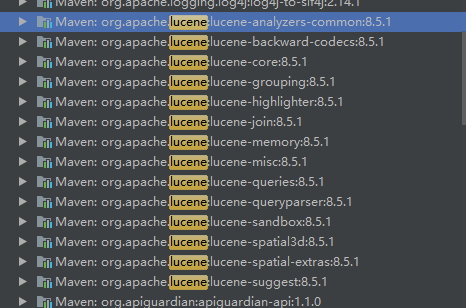
為啥報錯呢?
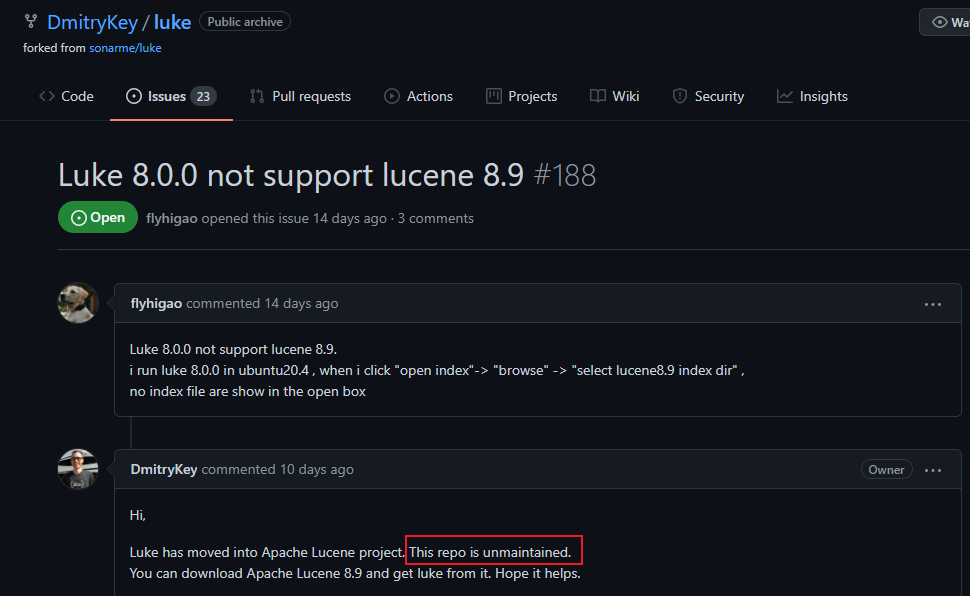
可以看到作者在說這個工具不維護了🐖
而 Lucene 也早就捐獻給 Apache 了
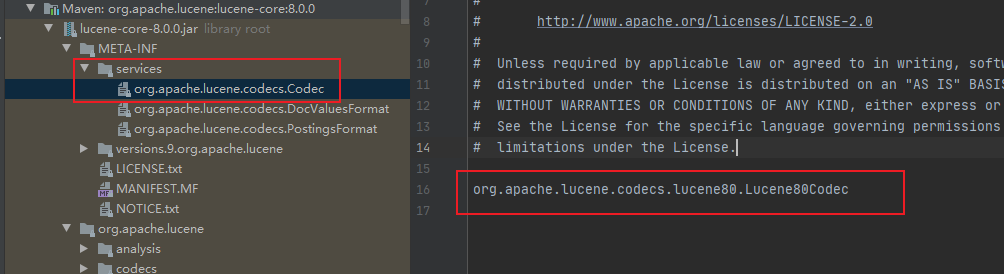
同時我還發現了 Luke 工具使用到這個 JavaSPI 機制,
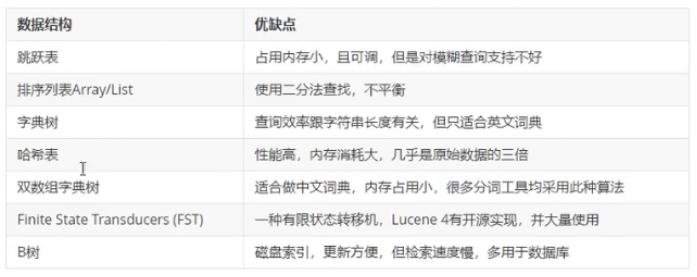
還有 Lucene 底層關鍵字的資料結構是 跳躍表 ( Redis 也用到了), FST 狀態機,
FST, 全稱Finite State Transducer, 中文翻譯: 有限狀態轉換器或有限狀態傳感器,
FST 最重要的功能是可以實作 Key 到 Value 的映射,相當于 HashMap<Key,Value>,FST 的記憶體消耗要比HashMap 少很多,但 FST 的查詢速度比 HashMap 要慢,FST 在 Lucene 中被大量使用,例如:倒排索引的存盤,同義詞詞典的存盤,搜索關鍵字建議等
跳躍表 不支持模糊查詢 ,FST 支持模糊查詢
搜過程序
大概就是這樣,通過這個詞,去找到對應的檔案id,再獲取檔案出來,依據權重啥的排序,
詞典資料結構有這么多種👇
最后
本文就分享到這里啦🐖
往細了看,可以發現這里涉及到很多 IO原理,以及底層資料結構的知識,編碼上目前就粗略認識到這個 JavaSPI 的使用,
快去敲下代碼,了解這些概念吧,這樣是不是也能有個基礎版的搜索引擎了 哈哈😝
👉 https://github.com/Java4ye/springboot-demo-4ye
喜歡的話可以 點贊 & 關注 并 星標 下公眾號 Java4ye 支持下 4ye 呀😝,這樣就可以第一時間收到更文訊息啦🐷
我是4ye 咱們下期應該……很快再見!! 😆
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336189.html
標籤:其他