目錄
基礎理論
一、 讀取檔案
二、神經網路初始化
1、搭建神經網路
2、GPU加速
三、打開攝像頭、按幀讀取影像
四、向神經網路輸入
五、獲取神經網路輸出
1、獲取各層名稱
2、獲取輸出層名稱
3、獲取輸出層影像(內容)
六、框出物體
1、獲取所有預測框情況
逐特征圖輸出
逐框輸出
單預測框結果
置信度過半時,把預測框認為可能的預測結果存入串列
2、保留一個預測框
3、畫出預測框
總代碼
基礎理論
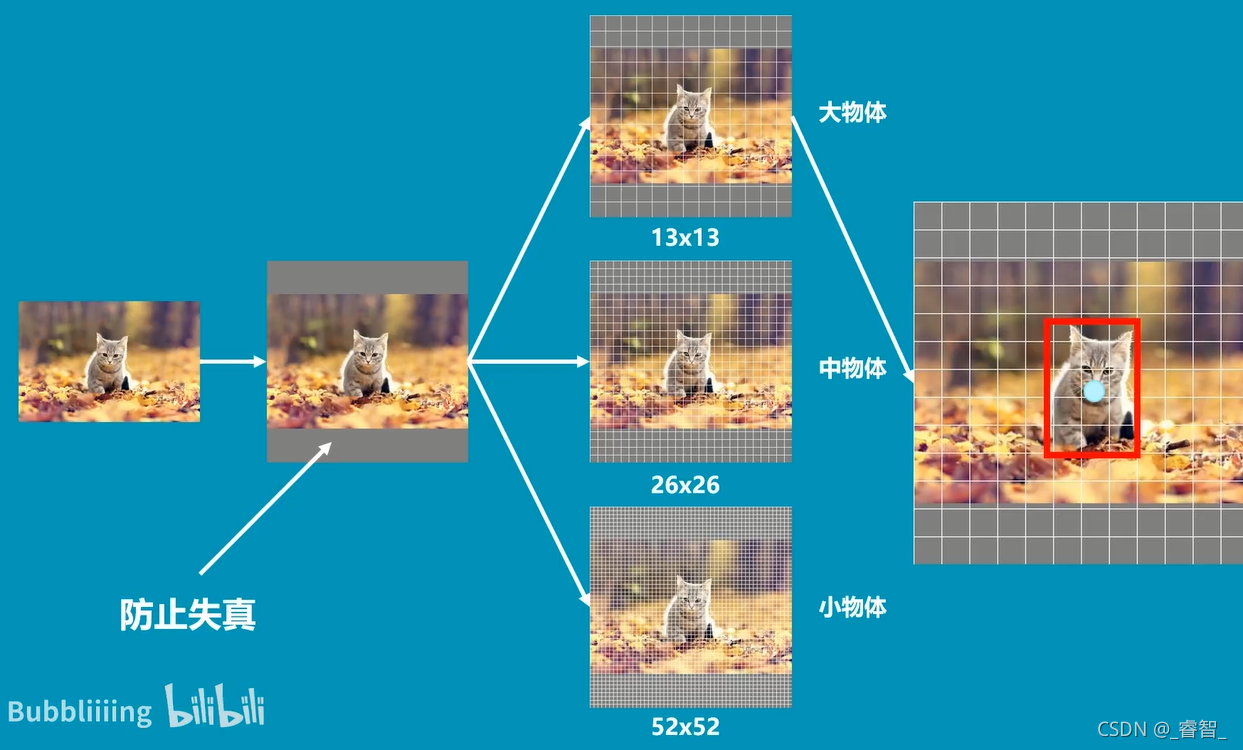
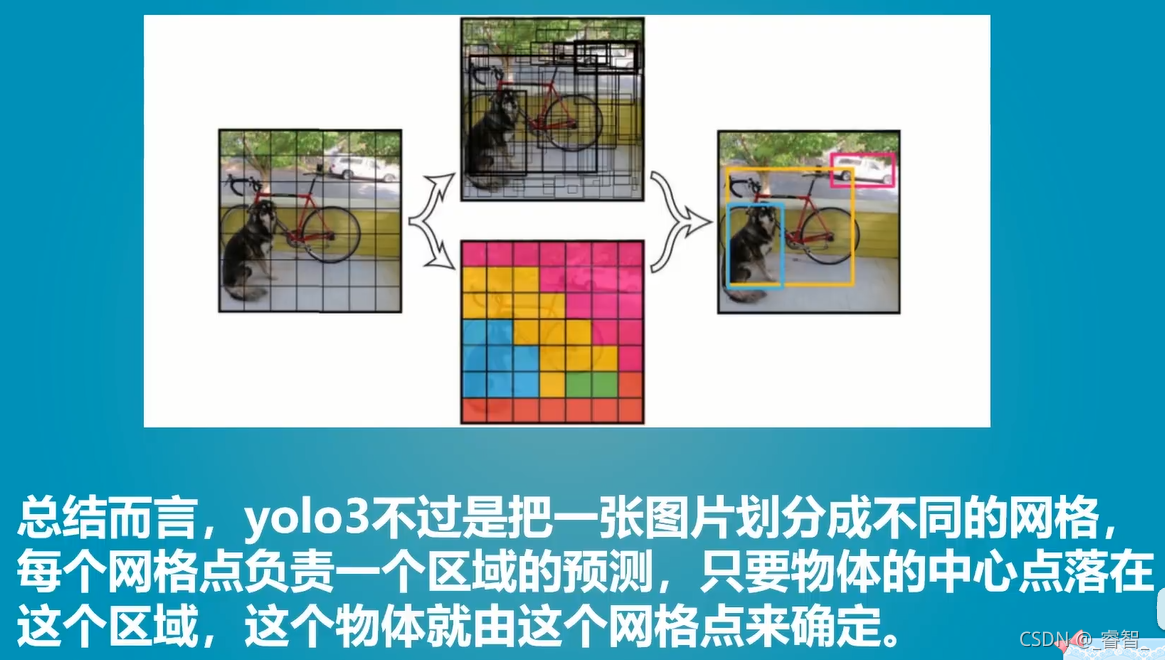
影像被劃分成3個影像:
影像在多次卷積壓縮后,小物體容易消失,所以我們分別用52*52、26*26、13*13的網格檢測小物體、中物體、大物體,
(貓是大物體,所以用13*13的網格檢測)

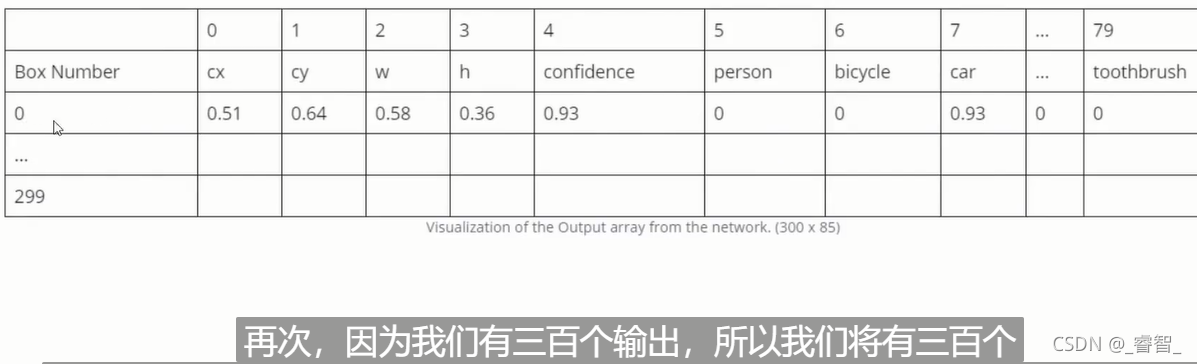
輸出層output:

一、 讀取檔案
需要三個檔案:
coco.names、yolov3.cfg、yolov3.weights,
下載地址:
https://download.csdn.net/download/great_yzl/34365174
(也可以去yolo官網下載,不過coco.names檔案不知道有沒有)
yolov3.cfg、yolov3.weights都是官方給定的模型(已經設定訓練好的,直接拿來用即可),
# 讀取檔案
def ReadFile():
global name_list
name_list = []
# 讀取檔案
with open('coco.names') as f:
name_list = f.read().split('\n')
print(name_list)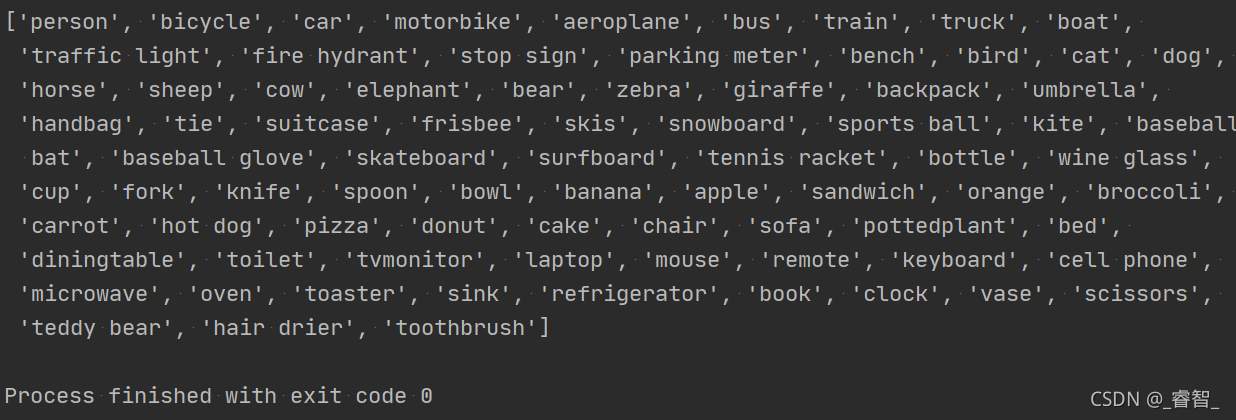
二、神經網路初始化
1、搭建神經網路
根據yolov3官方的設定和權重
global network
model_configuration = 'yolov3.cfg' # 配置模型
model_weights = 'yolov3.weights' # 權重
# 1、創建神經網路
network = cv2.dnn.readNetFromDarknet(model_configuration, model_weights)
# 配置模型 權重2、GPU加速
# 2、GPU加速
network.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) # 設定opencv作為后端
network.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)三、打開攝像頭、按幀讀取影像
def Capture_Init():
global capture, w, h
capture = cv2.VideoCapture(0)
w, h = 320, 320 while True:
global img
success, img = capture.read()
# img = cv2.imread("Resource/test4.jpg")
cv2.imshow('img', img)
# 設定每幀間隔時間(q鍵退出)
cv2.waitKey(1)
# if cv2.waitKey(1) & 0XFF == ord("q"):
# break
四、向神經網路輸入
# 向神經網路輸入
Input_to_Network(img)把img的資料變換一下,作為blob輸入到image中,
# 向神經網路輸入
def Input_to_Network(image):
# 把image轉換成blob資料型別(歸一化等一系列資料型別轉換)(這種方式網路可以理解)
blob = cv2.dnn.blobFromImage(image, 1 / 255, (w, h), [0, 0, 0], 1, crop=False)
# 影像 歸一化 寬,高 裁剪結果
# 設定神經網路輸入
network.setInput(blob)
print(blob)
五、獲取神經網路輸出
1、獲取各層名稱
# 神經網路各層名稱
layersNames = network.getLayerNames()
print(layersNames)
2、獲取輸出層名稱
# 2、獲取神經網路輸出層名稱
outputNames = [(layersNames[i[0] - 1]) for i in network.getUnconnectedOutLayers()]
print(outputNames)![]()
3、獲取輸出層影像(內容)
# 3、獲取輸出層影像(內容)
# outputs:3個特征圖:分別為小、中、大,(13*13、26*26、52*52)
# 每個特征圖又輸出85個類別
outputs = network.forward(outputNames)
# print(outputs[0].shape)
# print(outputs[1].shape)
# print(outputs[2].shape)
# print(outputs[0][0])
return outputs# 獲取神經網路輸出
def Network_Output():
# 神經網路各層名稱
layersNames = network.getLayerNames()
# 神經網路輸出層名稱
outputNames = [(layersNames[i[0] - 1]) for i in network.getUnconnectedOutLayers()]
# outputs:3個特征圖:分別為小、中、大,(13*13、26*26、52*52)
# 每個特征圖又輸出85個類別
outputs = network.forward(outputNames)
# print(outputs[0].shape)
# print(outputs[1].shape)
# print(outputs[2].shape)
# print(outputs[0][0])
return outputs得到圖中的一系列結果:
預測框坐標、長寬、置信度、各分類的預測分數,
[5.9418369e-02 7.4009120e-02 5.7651168e-01 1.6734526e-01 6.5560471e-07
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00]
六、框出物體
# 框出物體
def GetObject(outputs, image):
# 創建引數串列
h_p, w_p, c_p = image.shape # 影像的高、寬、通道數
bboxes = [] # 預測框
classIds = [] # 分類索引
confidences = [] # 置信度1、獲取所有預測框情況
逐特征圖輸出
# 逐特征圖輸出
for output in outputs:逐框輸出
# 逐框輸出
for one_class in output:單預測框結果
# 算出每個框的預測情況
# 先得到其85分類,每個分類的得分,再獲取最大得分的下標作為索引,最后得到其置信度
scores = one_class[5:] # 獲取所有得分
classId = np.argmax(scores) # 獲取分類索引
confidence = scores[classId] # 獲取置信度置信度過半時,把預測框認為可能的預測結果存入串列
# 加入預測到的物體(認為可能的物體)
if confidence > 0.5:
# 獲取預測框寬高、坐標
w_b, h_b = int(one_class[2] * w_p), int(one_class[3] * h_p)
x, y = int((one_class[0] * w_p) - w_b / 2), int((one_class[1] * h_p) - h_b / 2)
# (中心點x、y坐標)
bbox = [x, y, w_b, h_b]
# 把引數加入串列(預測框引數、分類索引、置信度)
bboxes.append(bbox) # 預測框引數
classIds.append(classId) # 分類索引
confidences.append(float(confidence)) # 置信度
print(confidences)2、保留一個預測框
根據置信度、NMS進行非極大值抑制, (前面對置信度已經有過一次過濾,這次可以不再設定置信度閾值),
# 保留一個預測框(從置信度閾值、NMS閾值進行設定)
indices = cv2.dnn.NMSBoxes(bboxes, confidences, 0.5, 0.1)
# 預測框 置信度 置信度閾值 NMS閾值(非極大值抑制)3、畫出預測框
# 輸出預測框
for i in indices:
i = i[0]
box = bboxes[i]
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 255), 2)
cv2.putText(image, f'{name_list[classIds[i]].upper()} {int(confidences[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
cv2.imshow('image', image) 
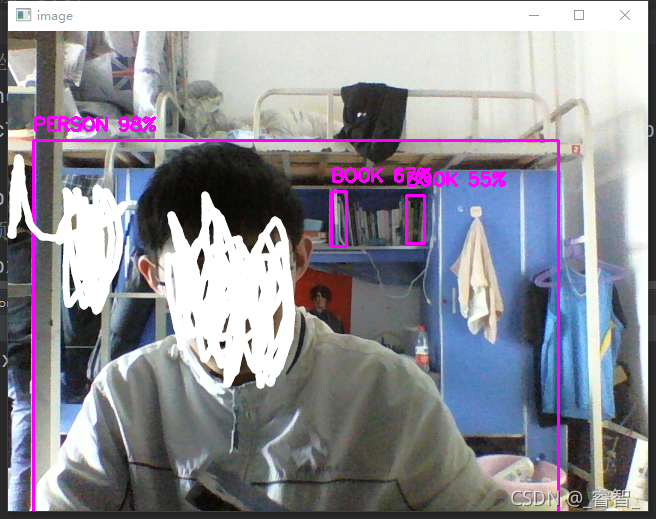
預測最大的問題就是比較慢,用tiny的話足夠快,但是不準確,還有很大的提升空間,
總代碼
import cv2
import numpy as np
# 讀取檔案
def ReadFile():
global name_list
name_list = []
# 讀取檔案
with open('yolo/coco.names') as f:
name_list = f.read().split('\n')
# print(name_list)
# 搭建神經網路
def Network_Init():
global network
model_configuration = 'yolo/yolov3.cfg' # 配置模型
model_weights = 'yolo/yolov3.weights' # 權重
# 1、創建神經網路
network = cv2.dnn.readNetFromDarknet(model_configuration, model_weights)
# 配置模型 權重
# 2、GPU加速
network.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV) # 設定opencv作為后端
network.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# print(network)
# 打開攝像頭
def Capture_Init():
global capture, w, h
capture = cv2.VideoCapture(0)
w, h = 320, 320
# 向神經網路輸入
def Input_to_Network(image):
# 把image轉換成blob資料型別(歸一化等一系列資料型別轉換)(這種方式網路可以理解)
blob = cv2.dnn.blobFromImage(image, 1 / 255, (w, h), [0, 0, 0], 1, crop=False)
# 影像 歸一化 寬,高 裁剪結果
# 設定神經網路輸入
network.setInput(blob)
# print(blob)
# 獲取神經網路輸出
def Network_Output():
# 1、獲取神經網路各層名稱
layersNames = network.getLayerNames()
# 2、獲取神經網路輸出層名稱
outputNames = [(layersNames[i[0] - 1]) for i in network.getUnconnectedOutLayers()]
# print(outputNames)
# 3、獲取輸出層影像(內容)
# outputs:3個特征圖:分別為小、中、大,(13*13、26*26、52*52)
# 每個特征圖又輸出85個類別
outputs = network.forward(outputNames)
# print(outputs[0].shape)
# print(outputs[1].shape)
# print(outputs[2].shape)
# print(outputs[0][0])
return outputs
# 框出物體
def GetObject(outputs, image):
# 創建引數串列
h_p, w_p, c_p = image.shape # 影像的高、寬、通道數
bboxes = [] # 預測框
classIds = [] # 分類索引
confidences = [] # 置信度
# 1、獲取所有預測框的情況
# outputs:小、中、大三個特征圖
# output:小、中、大單個特征圖
# oneclass:小、中、大每個分類
# 逐特征圖輸出
for output in outputs:
# 逐框輸出
for one_class in output:
# 算出每個框的預測結果
# 先得到其85分類,每個分類的得分,再獲取最大得分的下標作為索引,最后得到其置信度
scores = one_class[5:] # 獲取所有得分
classId = np.argmax(scores) # 獲取分類索引
confidence = scores[classId] # 獲取置信度
# 加入預測到的物體(認為可能的物體)
if confidence > 0.5:
# 獲取預測框寬高、坐標
w_b, h_b = int(one_class[2] * w_p), int(one_class[3] * h_p)
x, y = int((one_class[0] * w_p) - w_b / 2), int((one_class[1] * h_p) - h_b / 2)
# (中心點x、y坐標)
bbox = [x, y, w_b, h_b]
# 把引數加入串列(預測框引數、分類索引、置信度)
bboxes.append(bbox) # 預測框引數
classIds.append(classId) # 分類索引
confidences.append(float(confidence)) # 置信度
print(confidences)
# 保留一個預測框(從置信度閾值、NMS閾值進行設定)
indices = cv2.dnn.NMSBoxes(bboxes, confidences, 0.5, 0.1)
# 預測框 置信度 置信度閾值 NMS閾值(非極大值抑制)
# 輸出預測框
for i in indices:
i = i[0]
box = bboxes[i]
x, y, w, h = box[0], box[1], box[2], box[3]
# print(x,y,w,h)
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 255), 2)
cv2.putText(image, f'{name_list[classIds[i]].upper()} {int(confidences[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
cv2.imshow('image', image)
if __name__ == '__main__':
ReadFile() #讀取檔案
Network_Init() #神經網路初始化
Capture_Init() #攝像頭初始化
while True:
global img
# success, img = capture.read()
img = cv2.imread("Resource/test4.jpg")
# 向神經網路輸入
Input_to_Network(img)
# 獲取神經網路輸出
outputs = Network_Output()
# 框出物體
GetObject(outputs, img)
# 設定每幀間隔時間(q鍵退出)
cv2.waitKey(1)
# if cv2.waitKey(1) & 0XFF == ord("q"):
# break
cv2.waitKey(0)轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/336337.html
標籤:其他
上一篇:徒然學會了抗拒熱鬧,卻還來不及透悟真正的冷清;寫個聊天機器人治愈自己吧!
下一篇:ByteTrack實時多目標跟蹤