樸素貝葉斯(Na?ve Bayes)屬于監督學習演算法,實作簡單,學習效率高;由于建立在貝葉斯理論之上,涉及到統計學方法,所以在大樣本量下會有較好的表現,當然樣本需要在一定程度上反映真實分布情況,
該演算法的一條假設為:輸入的特征向量的各分量之間兩兩條件獨立,因為這條假設比較嚴格,能夠完全符合該假設的應用場景并不多見,所以給這個演算法帶來了“樸素”的修飾,然兒這并不妨礙樸素貝葉斯作為一個概率分類器在文本分類方面的優異表現,特別是在垃圾郵件識別領域,樸素貝葉斯表現突出,
本文著重介紹樸素貝葉斯在分類任務上的應用(只考慮特征向量各分量均為離散值的情況,在實際應用中,遇到連續取值的變數通常也會將其離散化),
1 問題描述
假設我們獲得如下訓練資料(訓練集中樣本數為N):
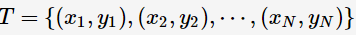
其中,x 表示特征向量(設定為n維,表示有n個離散屬性值),y 表示標簽變數,表征對應的特征向量代表的樣本所屬的類別,y 的取值范圍如下(類別數為K):
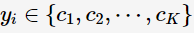
預測:當特征向量為X時,標簽y應取何值,
2 貝葉斯定理
貝葉斯定理是關于隨機事件A和B的條件概率的一則定理:
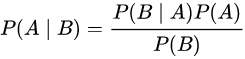
其中 A 以及 B 為隨機事件,且 P(B) 不為零,P(A|B) 是指在事件 B 發生的情況下事件 A 發生的概率,
在貝葉斯定理中,上式中的項有以下稱謂:
P(A|B) 由于得自 B 的取值而被稱作 A 的后驗概率,
P(A) 是 A 的先驗概率(或邊緣概率),稱為"先驗"是因為不考慮 B 的情況,
3 應用貝葉斯理論解決分類問題
貝葉斯理論解決分類問題的思路如下:
輸入待預測資料X,則預測類別 y 取使得 y 的后驗概率最大的類別值,即:

應用貝葉斯定理:
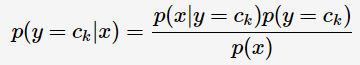
由于 y 的取值不會影響上式的分母,所以可以將上式轉化為:

進一步考慮屬性間的條件獨立性,對于n維特征向量:
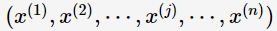
可以將它的后驗概率轉化為:
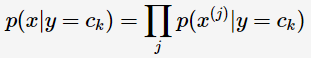
則(2)式可以轉為:
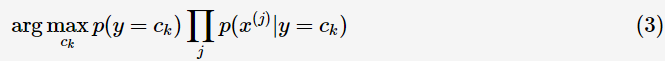
選擇后驗概率最大的類別作為預測類別,因為已經證明:后驗概率最大化可以使期望風險最小化,
到此為止,我們將類別預測問題轉為后驗概率的計算與比較問題;為了進一步計算,需要對(3)式中涉及的先驗概率與條件概率進行估計,
4 概率估計
4.1 極大似然估計
先驗概率的極大似然估計:
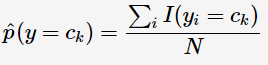
I 用于計數,用類別為Ck的樣本占總樣本的比例作為y取Ck值的先驗概率,
特征向量的第j個屬性變數的條件概率的極大似然估計:
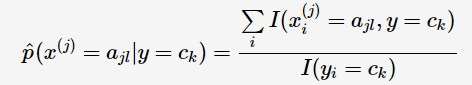
同樣是將樣本比例作為概率的思想,
4.2 貝葉斯估計(最大后驗概率估計)
極大似然估計先驗概率與條件概率時,可能出現有關樣本數為0的情況,由于后驗概率是多項連乘的結果,那么得到的后驗概率也為0,影響分類的效果,
因此,在估計時需要做平滑處理,這種方法被稱為貝葉斯估計,
先驗概率的貝葉斯估計:
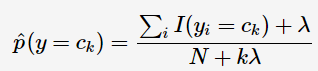
其中 K 為總的類別數,λ為可調引數,
特征向量的第j個屬性變數的條件概率的貝葉斯估計:
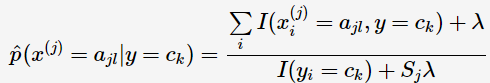
其中 Sj 為第 j 個屬性所取的不同的離散值的數量,λ為可調引數,
通常貝葉斯估計中的引數 λ=1 ,這時被稱為Laplace平滑,
通過概率估計得到先驗概率以及條件概率的概率值后,就可以計算得到各個類別的后驗概率,從而將具有最大后驗概率的類別作為樸素貝葉斯分類器的輸出類別,注意:最大后驗概率的思想不僅用于最后的類別輸出,在進行概率估計時也用到最大后驗概率估計(即前文所述的貝葉斯估計),只不過推匯出來的公式表現為拉普拉斯平滑的形式,
宣告:文中使用的圖片源自網路
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/33761.html
標籤:其他