知識圖譜概述
文章目錄
- 知識圖譜概述
- 1.1 知識圖譜的基本概念
- 1.1.1 知識圖譜的狹義概念
- 1.1.2 知識圖譜的廣義概念
- 1.2 知識圖譜的歷史沿革
- 1.2.1 知識圖譜溯源
- 1.2.2 大資料知識工程
- 1.3 知識圖譜的研究意義
- 1.3.1 知識圖譜的認知智能的基石
- 1.3.2 知識引導成為解決問題的重要方式之一
- 1.4 知識圖譜的應用價值
- 1.4.1 資料分析
- 1.4.2 智慧搜索
- 1.4.3 智能推薦
- 1.4.4 自然人機互動
- 1.4.5 決策支持
- 1.5 知識圖譜的分類
- 1.5.1 知識圖譜中的知識分類
- 1.5.2 知識圖譜的領域特性
- 1.5.3 典型知識圖譜
1.1 知識圖譜的基本概念
狹義: 特指一類知識表示,本質上是大規模語意網路
廣義:大資料時代知識工程一系列技術的總稱,在一定程度程度上指代大資料知識工程這一新興學科,
1.1.1 知識圖譜的狹義概念
-
知識圖譜作為語意網路的內涵
作為一種知識表示形式,知識圖譜是一種大規模語意網路,包括物體(Entity)、概念(Concept)及其之間的各種語意關系,
知識圖譜本質是語意網路:
語意網路是一種以圖形化的(Graphic)形式通過點和邊表示知識的方式,其基本組成元素是點和邊,
點可以是物體(又稱物件、實體)、概念(又稱類別、類)和值(Value),
邊可以分為屬性(Property)和關系(Relation)兩類,當物體的某個屬性值也是一個物體時,這個屬性實質上就是關系,
語意網路中的邊按照其兩端節點的型別可以分為概念之間的子類(subclassof)關系、物體與概念之間的實體(instanceOf)關系,以及物體之間的各種屬性與關系,
-
知識圖譜與傳統語意網路的區別
根本區別:知識圖譜規模大
(1)規模巨大,知識圖譜點、邊數量巨大原因在于需要覆寫物體,是大知識的代表,
(2)語意豐富,兩方面:富含各類語意關系;語意關系建模多樣,
(3)質量精良,大資料多源特性使得我們可以通過多個來源驗證簡單事實;眾包平臺有助于實作大規模知識驗證,
(4)結構友好,知識圖譜通常可以表示為三元組,通過圖結構和RDF(Resource Description Framework)進行表示,知識圖譜構建與應用的獨特挑戰:
(1)高質量模式缺失,放寬要求,允許模式(Schema)定義不完善甚至缺失,對資料語意理解以及資料質量控制提出挑戰,
(2)封閉世界假設(Closed World Assumption)不再成立,CWA假定資料庫/知識庫中不存在的事實為不成立的事實,
(3)大規模自動化知識獲取成為前提, -
知識圖譜與本體的區別
本體源于哲學的本體論,側重對存在進行規定和刻畫,本體刻畫人們認知一個領域的基本框架,而知識圖譜富含的是實體以及關系實體,模式定義實際上在完成本體定義的任務,
1.1.2 知識圖譜的廣義概念
知識圖譜是大資料時代知識工程(Big Data Knowledge Engineering, BigKE)的代表性進展,知識工程的核心內容是建設專家系統,旨在讓機器能夠利用專家知識以及推理能力解決實際問題,知識表示是發展知識工程最關鍵的問題之一,知識表示的一個重要方式是知識圖譜,側重用關聯方式表達物體與概念之間的語意關系,
1.2 知識圖譜的歷史沿革
以知識圖譜為代表的大資料知識工程的產生有歷史必然性,
1.2.1 知識圖譜溯源
-
傳統知識工程
知識工程屬于符號主義,符號主義認為知識是智能的基礎,傳統人工智能專家認為人工智能的核心問題是知識表示、推理和應用,成功解決的問題普遍具有規則明確、應用封閉的特點,根本局限在于嚴重依賴人的干預(領域專家、知識工程師、用戶反饋),
-
傳統知識工程的局限性
傳統知識工程難以適用開放性應用,實際應用不是絕對封閉,則容易超出預先設定的知識庫邊界,機器理解常識的水平有限,
(1)隱形知識與程序知識等難以表達,
(2)知識表達的主觀性與不一致性,專家認知有差異、沖突是常態,人類認知存在模糊性,如物體歸類,
(3)知識難以完備,
(4)知識更新困難,
1.2.2 大資料知識工程
-
互聯網與大資料應用催生了知識圖譜
應用特點:規模巨大(如搜索引擎);精度要求相對不高;知識推理簡單
-
大資料時代給知識圖譜的發展帶來了新機遇
(1)資料、算力和模型的飛速發展使得大規模自動化知識獲取成為可能,
(2)眾包技術使得知識的規模化驗證成為可能,
(3)高質量的用戶生成內容(UGC)提供了高質量知識庫來源,包括百科、社區、論壇、問答平臺,
1.3 知識圖譜的研究意義
1.3.1 知識圖譜的認知智能的基石
認知智能是指讓機器具備人類認知世界的能力,機器認知智能的兩個核心能力是“理解”、“解釋”,理解是指從資料到知識圖譜中的知識要素(包括物體、概念和關系)的映射,解釋是將知識圖譜中的知識與問題或者資料相關聯,
(1)知識圖譜使能機器語言認知,
實作機器對自然語言的理解所需要的背景知識的條件如下,知識圖譜滿足所有條件:
- 規模必須足夠巨大才能理解不同的物體和概念
- 語意關系必須足夠豐富才能理解不同的關系
- 結構必須足夠友好才能為機器所處理
- 質量必須足夠精良才能讓機器對現實世界產生正確的理解
(2)知識圖譜賦能可解釋人工智能:可解釋性的缺失問題,
人類傾向于利用概念、屬性、關系這些認知的基本元素去解釋現象和事實,可以通過知識圖譜表達,
(3)知識圖譜有助于增強機器學習的能力,
讓機器學習模型利用大量累積的符號知識,降低機器學習模型對大樣本的依賴,提高學習的經濟性,提高對先驗知識的利用率,
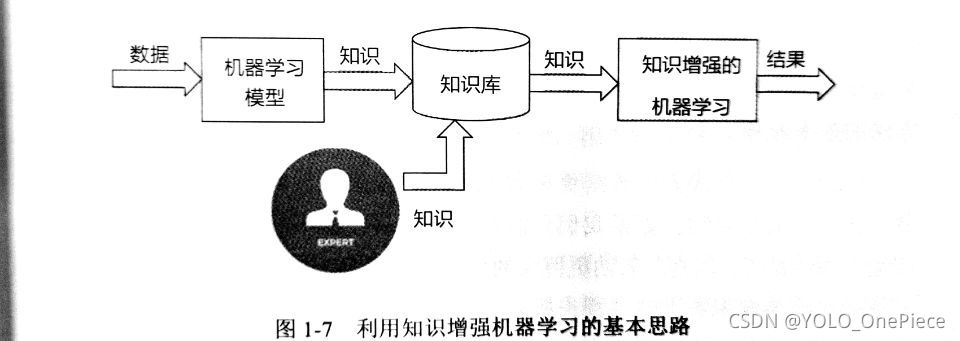
1.3.2 知識引導成為解決問題的重要方式之一
實際應用越來越要求將資料驅動和知識引導相結合,以突破基于統計學習的純資料驅動的效果瓶頸,
1.4 知識圖譜的應用價值
1.4.1 資料分析
大資料的精準分析(輿情分析、互聯網商業洞察、軍事情報分析、商業情報分析)和精細分析(個性化制造、搜集評價與反饋)需要知識圖譜,
1.4.2 智慧搜索
- 精準的搜索意圖理解
精準分類、語意理解、個性化推薦 - 搜索物件復雜化、多元化
文本、圖片、代碼、聲音、視頻、文案、素材 - 搜索粒度多元化
篇章級、段落級、陳述句級、詞匯級 - 跨媒體協同搜索
不同媒體資料聯合完成搜索、多模態搜索
1.4.3 智能推薦
- 場景化推薦,建立場景圖譜,實作基于場景圖譜的精準推薦,
- 冷啟動下的推薦,利用來自知識圖譜的外部知識,特別是關于用戶與物品的知識,增強用戶與物品的描述,提升匹配精度,是讓系統盡快度過冷啟動階段的重要思路,
- 跨領域推薦,
- 知識型內容的推薦,
1.4.4 自然人機互動
對話式互動、問答式互動,
1.4.5 決策支持
建立包含各種語意關聯的知識圖譜,挖掘物體之間的深層關系,成為決策分析的重要輔助手段,
1.5 知識圖譜的分類
1.5.1 知識圖譜中的知識分類
- 事實知識,是關于某個特定物體的基本事實,最常見的知識型別,
- 概念知識,分為兩類,一類是物體與概念之間的類屬關系(isA關系),一類是子概念與父概念之間的子類關系(subclassOf),
- 詞匯知識,主要包括物體與詞匯之間的關系以及詞匯之間的關系,已取得較好應用效果,
- 常識知識,常識是人類通過身體與世界互動而積累的經驗與知識,使人們不言自明的知識,常識知識的獲取是構建知識圖譜的一大難點,
1.5.2 知識圖譜的領域特性
通用到領域/行業
DKG與GKG之間區別體現在知識表示、知識獲取、知識應用三個層面:
- 在知識表示層面的區別可以從廣度、深度、粒度這三個維度來考察,
- 在知識獲取層面,DKG對質量要求更高,
- 在知識應用層面,DKG的推理鏈條相對較長,應用相對復雜,
聯系:
- 領域知識是通過隱喻或者類比從通用知識發展而來,
- GKG與DKG相互支撐,GKG給DKG提供高質量種子事實和領域模式,DKG反哺GKG,
1.5.3 典型知識圖譜
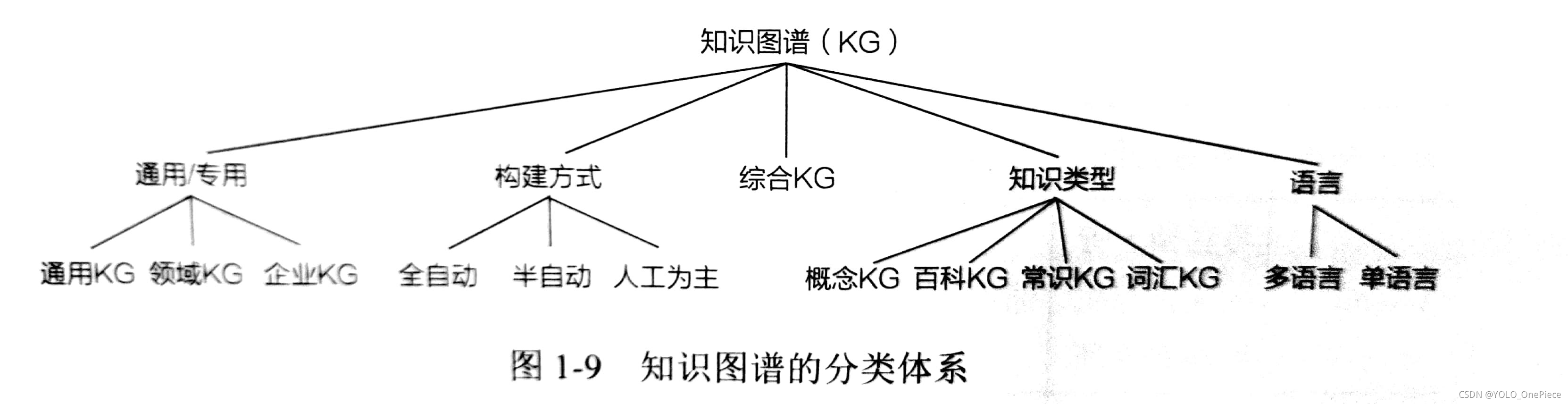
常見知識圖譜
| 知識圖譜 | 領域 | 特點 | 構建方式、規模 | 語言 | 型別 |
|---|---|---|---|---|---|
| Cycorp公司的Cyc | 通用 | 通過人工方法將上百萬條人類常識編碼成機器可用的形式,用于智能推斷 | 人工,700萬條斷言,63萬個概念,3.8萬條關系 | 英語 | 常識圖譜 |
| 普林斯頓大學的WordNet | 通用 | 以同義詞集合作為一個基本單元 | 人工,15萬個詞,11萬組同義詞集合,20萬條關系 | 英語 | 詞匯圖譜 |
| 麻省理工學院的ConceptNet | 通用 | 多語言常識知識庫 | 自動,800萬個物體,2100萬條關系 | 多語言 | 常識圖譜 |
| Meta Web公司的Freebase | 通用 | 眾包編輯 | 半自動,4400萬個概念,24億個事實 | 英語 | 百科圖譜 |
| Geonames.org的Geonames | 領域 | 多語言地理位置資訊 | 半自動,2500萬個物體 | 多語言 | 地理圖譜 |
| DBpedia | 通用 | 百科圖譜多語言自動構建 | 半自動,2800萬個物體 | 多語言 | 百科圖譜 |
| YAGO | 通用 | 人工校驗,時空維度,多語言 | 自動,1000萬個物體,1.2億條關系 | 多語言 | 百科圖譜 |
| 華盛頓大學的OpenIE | 通用 | 開放性關系抽取,Never-ending | 自動,50億條關系 | 英語 | 文本圖譜 |
| BabelNet | 通用 | 271種語言,自動融合 | 自動,1400萬個物體 | 多語言 | 詞匯圖譜 |
| WikiData | 通用 | 眾包編輯 | 半自動,540萬個物體 | 多語言 | 百科圖譜 |
| Google知識圖譜 | 通用 | 規模最大 | 自動,未知 | 多語言 | 綜合知識圖譜 |
| 微軟亞洲研究院的Probase | 通用 | 概念規模最大 | 自動,270萬個概念 | 英語 | 概念圖譜 |
| 搜狗知立方 | 通用 | 側重于娛樂領域 | 自動,未知 | 漢語 | 百科圖譜 |
| 百度知心 | 通用 | 支持百度搜索 | 自動,未知 | 漢語 | 百科圖譜 |
| 復旦大學的CN-DBpedia | 通用 | 實時更新,完整的資料/服務介面 | 自動,1600萬個物體,2.2億條關系 | 漢語 | 百科圖譜 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337625.html
標籤:其他
上一篇:聊聊Java泛型
下一篇:BI與報表的區別