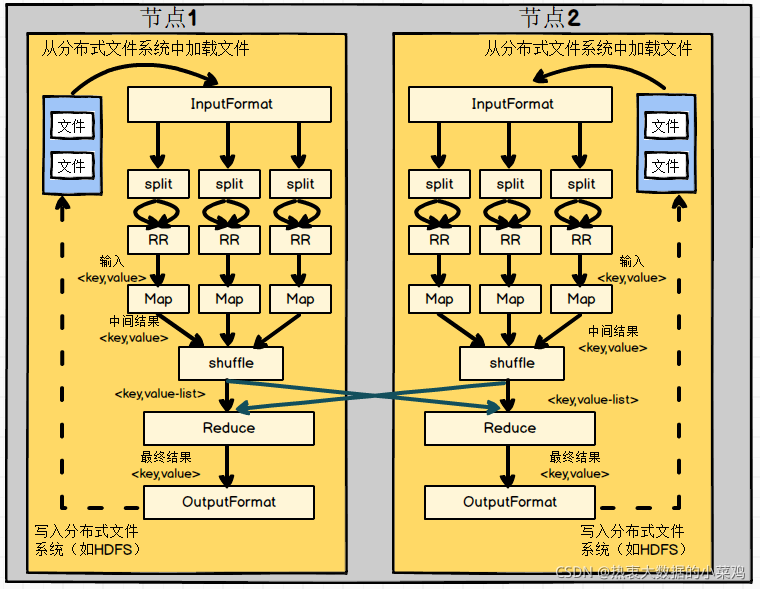
MapReduce演算法執行程序 核心思想:“分而治之”
(1)MapReduce框架使用InputFormat模塊做Map前的預處理,比如驗證輸入的格式是否符合輸入定義;然后,將輸入的檔案切分為邏輯上的多個InputSplit,InputSplit是MapReduce對檔案進行處理和運算的實際單位(邏輯概念),每個InputSplit沒有對檔案進行實際切割,只是記錄了要處理的資料的位置和長度,
(2)InputSplit是邏輯切分,所以需要通過RecordReader(RR)根據InputSplit的資訊來處理InputSplit中的具體記錄,加載資料并轉換為合適Map任務讀取的鍵值對,輸入給Map任務,
(3)Map任務根據用戶自定義的映射規則,輸出一系列的<key,value>作為中間結果,
(4)對Map的輸出進行磁區、排序、合并、歸并等操作,得到<key,value-list>形式的中間結果,再交給Reduce,此程序稱為Shuffle,(Shuffle詳解看下面)
(5)Reduce端以<key,value-list>作為輸入,執行用戶定義的邏輯,輸出結果給OutputFormat模塊,
(6)OutputFormat會驗證輸出目錄是否已經存在以及輸出結果型別是否符合組態檔中的配置型別,如果都滿足,就輸出Reduce的結果到分布式檔案系統中,
此圖是MapReduce執行流程:
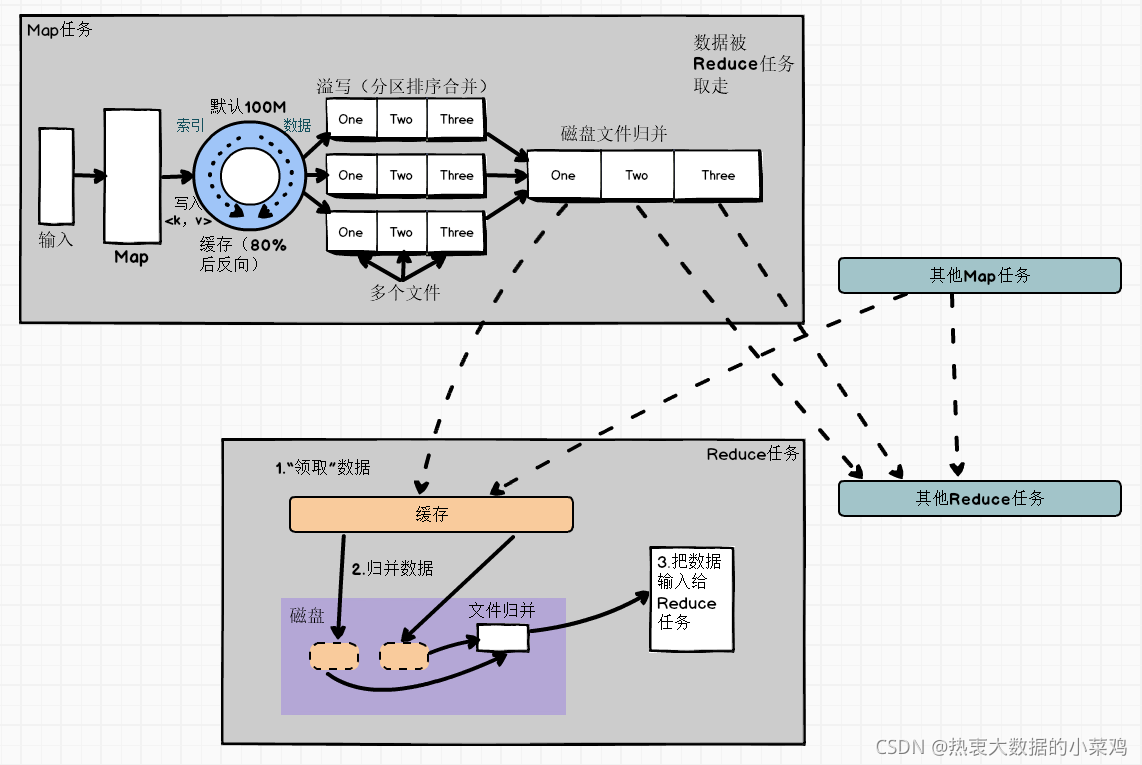
Shuffle詳解
1、在Map端的Shuffle程序
(1)寫入快取
??每一個Map任務會被分配一個快取,在快取中積累一定數量的Map輸出結果后,再批量寫入磁盤,可減少磁盤的I/O影響,
理解:磁盤包含機械部件,它時通過磁頭移動和盤片的轉動來尋址定位資料的,每次尋址的開銷很大,如果每個Map輸出結果都寫入磁盤,會引入很多次尋址開銷,而一次性批量寫入,就只需要一次尋址,連續寫入,大大降低了開銷,注意:在寫入快取之前,key與value值會被序列化成位元組陣列
(2)溢寫(磁區、排序和合并)
?? 1)磁區
?? 快取中的資料先磁區,快取中的資料是<key,value>鍵值對,通過Partitioner介面對這些鍵值對進行磁區,默認的磁區方式:采用hash函式對key進行哈希后再用Reduce任務的數量進行取模,表示為hash(key)mod R,這樣就可以把Map的輸出結果均勻的分配給Reduce任務區并行處理,也允許用戶通過多載Partitioner介面來定義磁區方式,
?? 2)排序(默認)
??每個磁區內的鍵值對,后臺執行緒會根據key,進行記憶體排序(Sort)
?? 3)合并(可選)
?? 如用戶事先沒有定義Combiner函式,就不用進行合并操作,如果定義了,會執行合并操作,從而減少了需要溢寫到磁盤的資料量,
?? “合并”是指具有相同key的<key,value>的value加起來,如:<a,1> , <a,1> => <a,2> 發生在Map端,有別與Reduce,Combiner的輸出是Reduce的輸入,Combiner不能改變Reduce任務最終的計算結果,
?? 3)溢寫
?? -MapReduce快取的容量默認是100MB,隨著Map任務不斷增加,很快占滿整個快取,這時,就必須啟動溢寫(spill)把快取的內容一次性寫入磁盤,并清空快取,
??默認溢寫比例是80%,也就是說,當100MB的快取被填滿80%MB資料時,就啟動溢寫程序,把寫入的80MB寫入磁盤,剩余20MB供Map結果繼續寫入,
?? 每次溢寫操作都會生成一個新的溢寫檔案,寫入溢寫檔案中的所有鍵值對都是經過磁區和排序的,
(3)檔案歸并
?? Map任務全部結束前,系統會對所有溢寫檔案進行歸并(Merge),生成一個大的溢寫檔案(鍵值對都經過磁區和排序)
?? “歸并”指對于具有相同key的鍵值對歸并成一個新的鍵值對,如<a,1> , <a,1> => <a, <1,1>>,
?? 了解:進行歸并時,如磁盤生成的溢寫檔案數量超過引數min.num.spills.for.combine的值時(默認是3,用戶可以修改這個值),就可再次運行Combiner,對資料進行合并,減少磁盤的資料量,如果寫磁盤中只有一兩個溢寫檔案,就不會運行Combiner,因為執行合并操作本身也有代價,
2、在Reduce端的Shuffle程序
(1)”領取“資料
?? Map端的Shuffle結束后,所有Map的輸出結果都保存在Map機器的本地磁盤上,檔案都是被磁區的,不同的磁區會被發送到不同的Reduce任務進行并行處理,
??每個Reduce任務會不斷地通過RPC向JobTracker詢問Map任務是否已經完成;JobTracker檢測到一個Map任務完成后,就會通知相關的Reduce任務來"領取"資料;Reduce收到通知,就會從Map任務所在機器把屬于自己的磁區資料領取到本地磁盤,一般是Reduce任務使用多個執行緒通過是多個Map機器領回資料,
(2)歸并資料
?? Map端領取的資料會被存放在Reduce端的快取中,如果快取被占滿,就會溢寫到磁盤,快取資料來自不同Map機器,會存在很多合并(Combiner)的鍵值對,當溢寫啟動時,相同key的鍵值對會被歸并,如用戶定義Combiner,則歸并后的資料可以執行合并操作,減少寫入磁盤資料量,一次溢寫,生成一個溢寫檔案,溢寫結束,磁盤上存在多個溢寫檔案,
?? Map端資料都被領回時,多個溢寫檔案會被歸并成一個大檔案,歸并時會進行排序,如果資料量很少就不需要進行溢寫,直接在記憶體中執行歸并操作,
?? 了解:把磁盤多個溢寫檔案歸并成一個大檔案可能需要執行多輪歸并操作,每輪歸并操作可以歸并檔案數量是由引數io.sort.factor的值來控制的(默認是10,可以修改),假設磁盤中生成50個溢寫檔案,每輪可以歸并10個溢寫檔案,則需要經過5輪歸并,得到5個歸并后的大檔案,
(3)把資料輸入給Reduce任務
?? Reduce任務會執行Reduce函式中定義的各種映射,輸出最終結果,保存在分布式檔案系統中(比如GFS或HDFS)
?? 了解:磁盤多輪歸并后得到若干個大檔案,不會歸并成一個新的大檔案,而是直接輸入給Reduce任務,可減少磁盤讀寫開銷
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337638.html
標籤:其他