目錄
- 一、前置條件
- 二、安裝Centos系統
- 三、配置Centos系統靜態IP(很重要!)
- 三、解壓jdk壓縮包,配置環境變數
- 四、配置免密鑰登錄
- 修改主機名
- 增加ip映射關系
- 關閉防火墻
- **==我們繼續來配置免密碼登錄!==**
- 驗證免密碼登錄
- 五、Hadoop配置
- 六、集群啟動并測驗集群
一、前置條件
| 需要安裝 | 下載方法 |
|---|---|
| Vmware Workstation | 官網下載鏈接 |
| Centos7系統 | 百度網盤下載 , 提取碼:t6va |
| jdk1.8 | 官網下載鏈接 |
| MobaXterm | 百度網盤下載,提取碼:f64v |
| hadoop(2.7.3版本) | 百度網盤下載,提取碼:963t |
二、安裝Centos系統
為了減少篇幅,我就把安裝步驟放到另一篇博客,大家動動手指吧:安裝教程
三、配置Centos系統靜態IP(很重要!)
這里我之前的文章有寫過,這里也不詳細講了,有需要的可以看看我這篇文章:配置教程
注意:不配置的話Centos系統無法連網!!!
三、解壓jdk壓縮包,配置環境變數
這一步每個主機節點都需要配置!!我這里只演示一臺主機怎么配!!
1、我們第一步需要先用MobaXterm連接linux主機↓
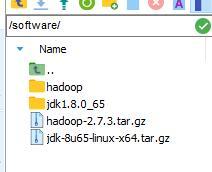
2、為了統一管理,我們把所有的jdk包都放在~/software目錄下
3、我們把從官網下載的jdk壓縮包拖到這目錄下
4、首先cd到/software目錄下,命令:cd/software,然后解壓縮jdk包,命令:tar -xzvf jdk-8u65-linux-x64.tar.gz
5、然后我們來配置環境變數,命令:vi /etc/profile,在末尾加上↓
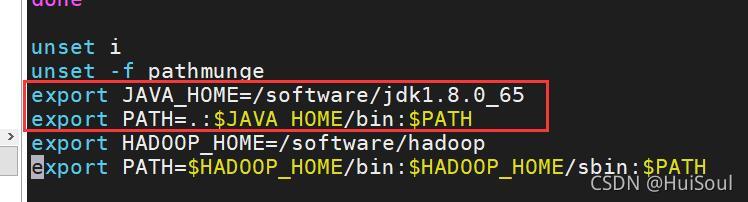
按下鍵盤 “i” 進入插入模式,緊接著在末尾加上:命令↓
export JAVA_HOME=/software/jdk1.8.0_65
export PATH=.:$JAVA_HOME/bin : $PATH
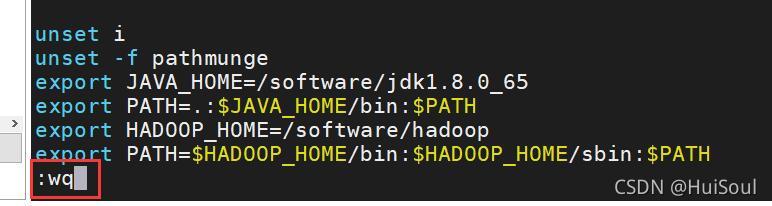
然后按 esc退出插入模式,再輸入:wq(注意有冒號!!)保存退出
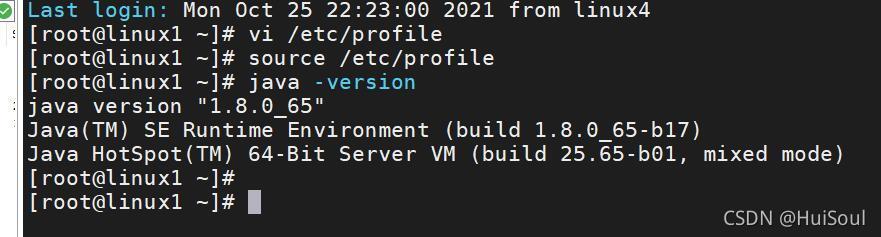
6、讓系統重繪組態檔,并找到JAVA環境變數,命令:source /etc/profile,查看JAVA版本資訊,命令:java -version
四、配置免密鑰登錄
配置免密鑰登錄,需要namenode和datanode結點一起配置才能生效,下面我演示一下如何配置一個datanode結點,大家根據這個規則給namenode結點和其他datanode結點配置就好了
我這里設定了三個結點,其中.110是主節點,其余為從節點
修改主機名
根據哪個是主節點,哪個是從結點給予名字,如:namenode、datanodeA、datanodeB等等
命令↓
vi /etc/hostname
更改后利用命令查看是否更改成功,命令↓
hostname
增加ip映射關系
利用MobaXterm打開需要配置免密鑰登錄的結點,cd 到 /etc目錄,命令↓
cd /etc
然后輸入 vi hosts,修改host組態檔,添加映射關系:命令↓
vi hosts
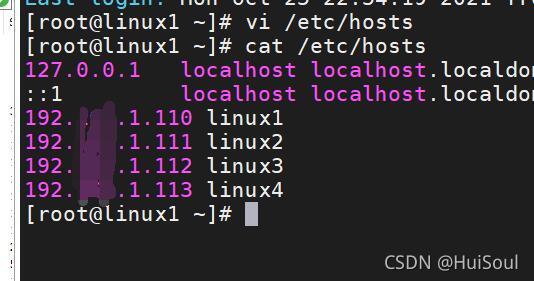
按 i 進入插入模式,增加結點的ip地址
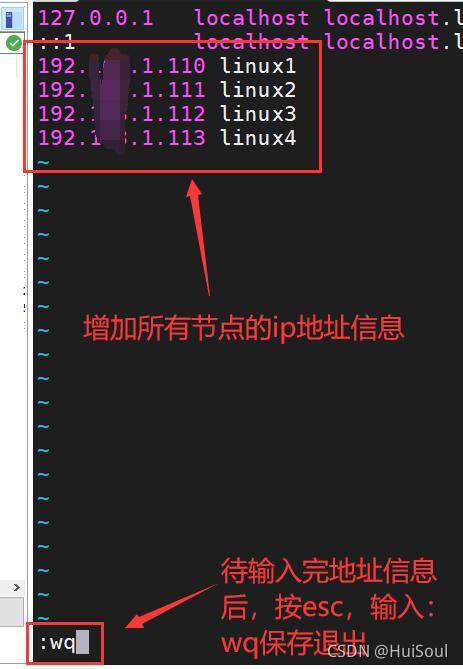
檢查是否添加成功,命令:cat hosts
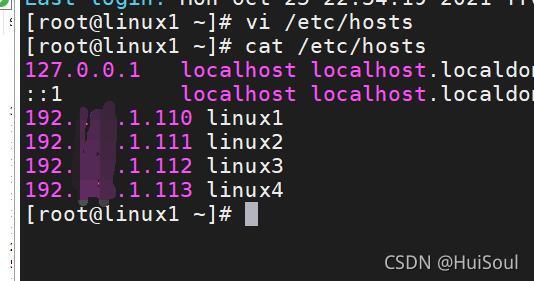
將組態檔“hosts”發送給集群中所有的主機,發送目標用戶為結點ip地址或者節點主機名用戶,發送目標路徑為“/etc”,我這里只演示發送一個結點,如果要發送多個結點,只用復制命令,更改ip地址就好啦,接著輸入要發送的結點的登錄密碼就完成發送了,
命令↓
scp -r /etc/hosts root@結點ip地址或者節點主機名:/etc
我這里因為配置好了免密登錄所以就不需要輸入密碼了

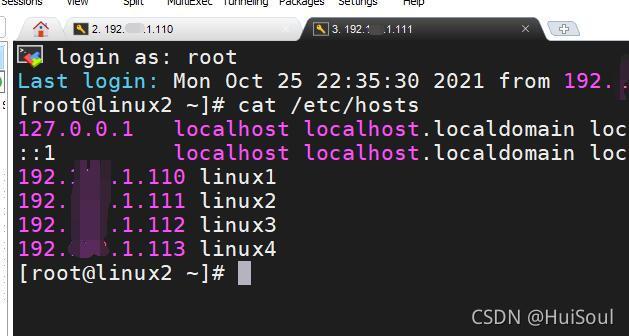
然后我們在接收結點的/etc/hosts檔案里就可以看到原本的檔案已經被覆寫成新檔案了!
關閉防火墻
永久關閉防火墻命令↓
systemctl stop firewalld.service
禁止防火墻重啟后自動啟動命令↓
systemctl status firewalld
關閉防火墻后,看看防火墻狀態是否關閉成功,命令↓
firewall-cmd --state
我們繼續來配置免密碼登錄!
步驟↓
①cd到.ssh目錄,命令↓
cd .ssh
有些同學在這一步可能找不到.ssh檔案夾,我們可以使用命令:ssh localhost ,進入root用戶,再cd .ssh就能找到這個檔案夾了!
②利用 ls 命令查看目前目錄存在的檔案
③洗掉當前目錄所有檔案,命令:rm *,在提示是否洗掉后輸入 y
④生成公鑰私鑰檔案,命令↓
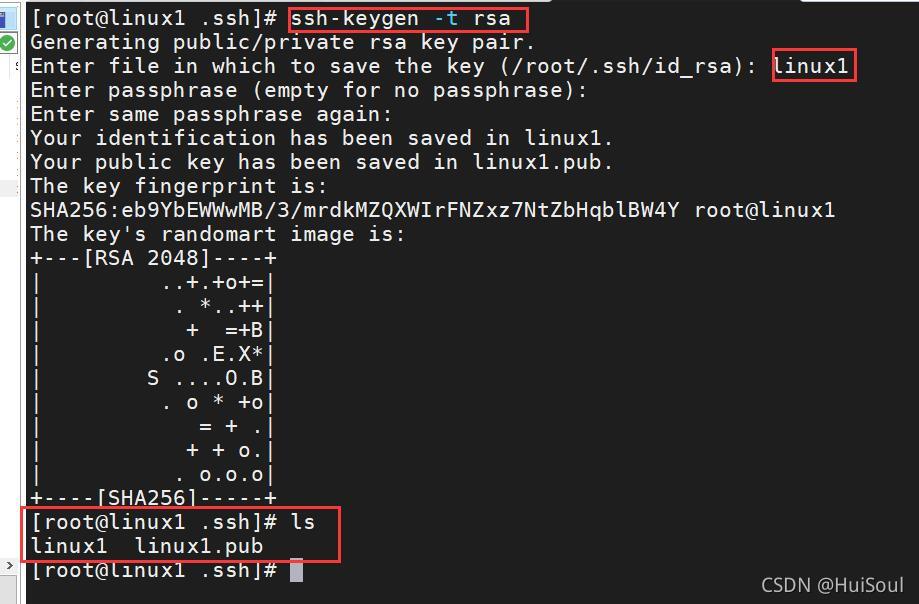
ssh-keygen -t rsa
注意:這里不要一直回車!在第一次詢問時,末尾加上能代表本結點的名字!
為了后面方便配置,我改變了一下公鑰檔案的名字↓

再次注意!!
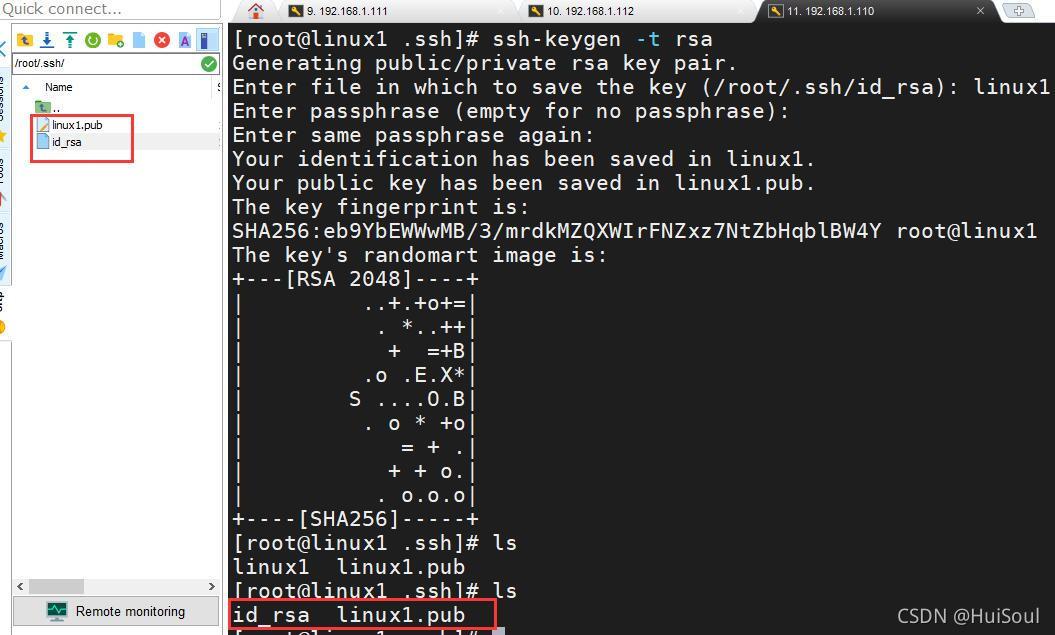
我們改完公鑰檔案名字之后需要把生成的私鑰名字改回id_rsa,因為系統只能識別id_rsa為本機私鑰,若沒有改回來免密登錄不會成功的!!
方法:只要在MobaXterm左邊目錄對著私鑰檔案右鍵Rename就可以了↓
⑤將公鑰檔案加入認證檔案authorized_keys中,命令↓
cat id_rsa.pub >> authorized_keys;
一定要注意認證檔案的名字要對,錯誤了系統是識別不到認證檔案的

----------------------------一定要三個節點都完成上述步驟后才能進行下面的步驟---------------------------------------------
然后我們把該結點的公鑰檔案 傳送給另外兩個節點的.ssh目錄下,命令↓
scp 公鑰檔案名.pub root@節點主機名:~/.ssh/
從linux1節點往其他linux2和linux3節點傳送公鑰檔案↓
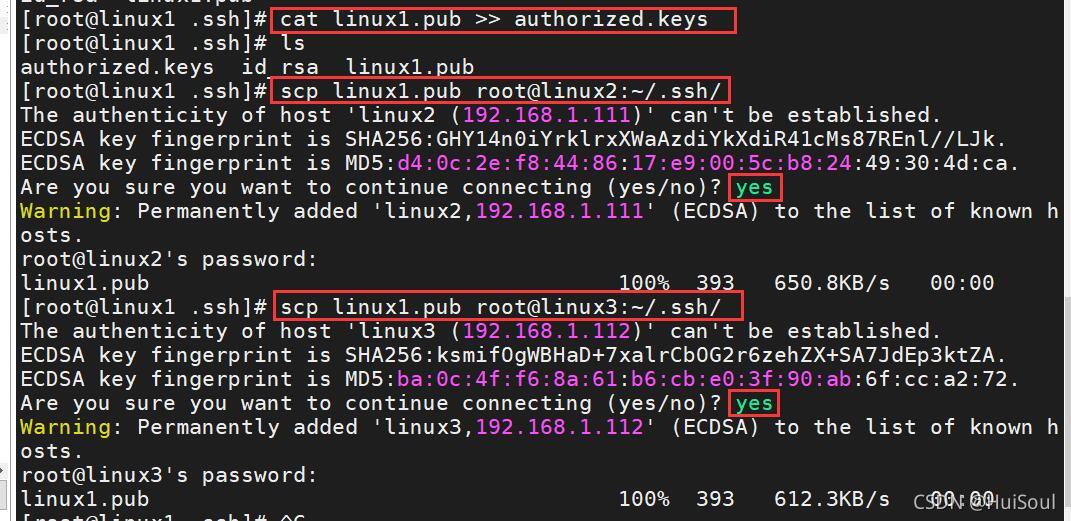
三個節點都要進行上面互相傳送公鑰檔案的操作!
互相傳送后的結果截圖↓

往每臺主機的認證檔案中加上另外兩個節點的公鑰

查看認證檔案中是否有三個節點的公鑰檔案
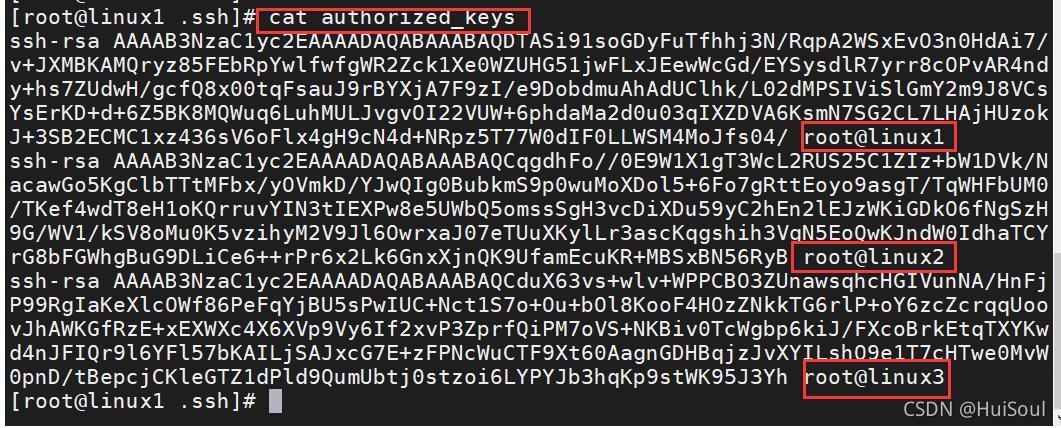
驗證免密碼登錄
剛剛我們在每個結點的認證檔案中都加上了公鑰檔案,也就是現在開始從任何結點都可以免密碼登錄至其他結點了,我們來試試看↓
因為我們之前增加了ip映射關系,我們這里測驗直接使用ssh+主機名就能進行登錄了
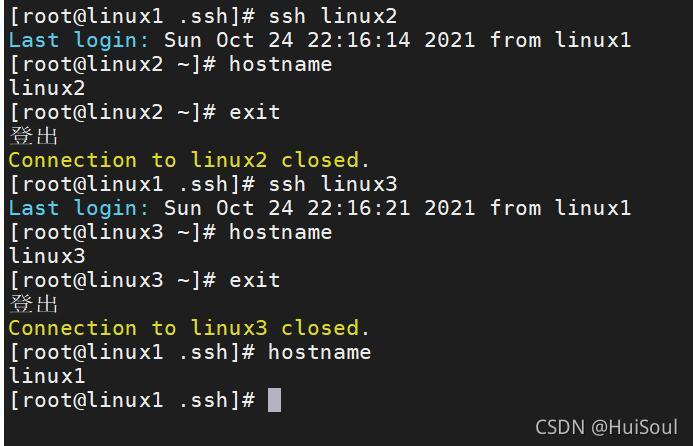
免密登錄已經配置成功了!
五、Hadoop配置
①將下載的hadoop壓縮包放到 /software 目錄下
②進行解壓hadoop壓縮包,命令:tar -xzvf hadoop-2.7.3.tar.gz
③將解壓后的hadoop檔案名修改成hadoop,方便后續操作
注意:這里有一個小技巧!我們這里只用將壓縮包解壓在主節點下就好了,因為我們可以在配置完后用 scp 命令將hadoop整個檔案傳送到其余節點下
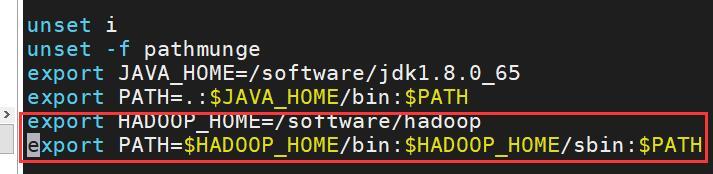
修改全域組態檔路徑,命令:vi /etc/profile,在末尾加上:
export HADOOP_HOME=/software/hadoop
export PATH=$HADOOP_HOME/bin: $HADOOP_HOME/sbin: $PATH
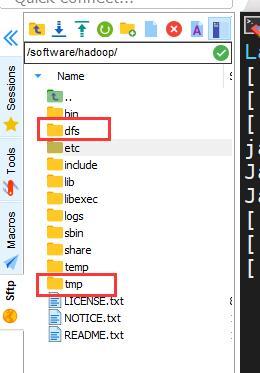
進入/software/hadoop 目錄下,創建dfs和tmp兩個空白檔案夾,用于后續運行檔案存盤
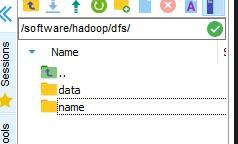
進入/software/hadoop/dfs 目錄下,創建data和name兩個空白檔案夾,用于后續運行檔案存盤
進入/software/hadoop/目錄下
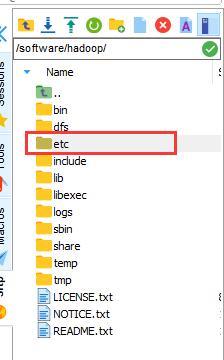
再進入 /software/hadoop/etc/hadoop目錄下,接下來配置/software/hadoop/etc/hadoop/目錄下的七個檔案↓
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
yarn-env.sh
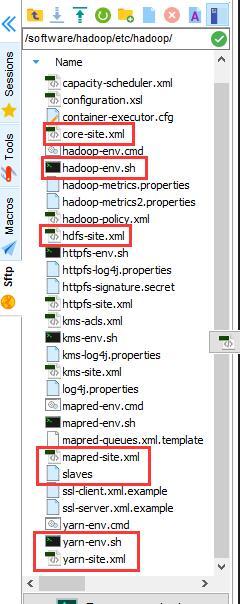
注意:Hadoop版本2和3此目錄下的檔案會有所不同!!建議大家使用Hadoop2.7.3版本!!
(最上面我已經更新了hadoop2.7.3版本的下載方法!)
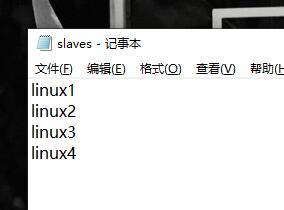
slaves檔案↓將原本的localhost刪掉,加上所有結點的主機名
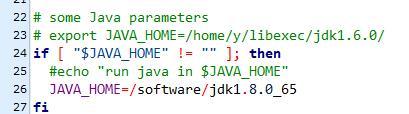
hadoop-env.sh↓,第25行加上java的jdk路徑↓

yarn-env.sh↓,第26行加上java的jdk路徑↓
--------------------------------------------以下均在組態檔中的configuration標簽內添加-------------------------------------------
core-site.xml↓
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://主節點名:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/software/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml↓
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/software/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/software/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<!-- 從結點數 -->
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>主節點名:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>主節點名:50090</value>
</property>
</configuration>
mapred-site.xml↓
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>主節點名:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主節點名:19888</value>
</property>
</configuration>
yarn-site↓
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>主節點名:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>主節點名:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>主節點名:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>主節點名:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>主節點名:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
用 scp 命令將主節點下已經配置好的hadoop檔案整個傳送至其余結點的~/software目錄下↓
scp -r /software/hadoop root@linux2:~/software/
scp -r /software/hadoop root@linux3:~/software/
六、集群啟動并測驗集群
以下操作均需所有節點主機在開啟狀態中
在主節點主機操作:cd /software/hadoop
格式化NameNode,命令:bin/hdfs namenode -format
后續若要重新格式化步驟:
(1)停止所有節點上的NameNode和DataNode行程,命令:stop-all.sh(任何目錄下都能運行)
(2)洗掉所有節點的data和logs檔案夾(hadoop.tmp.dir)
(3)格式化NameNode
啟動集群,命令:start-all.sh(任何目錄下都能運行)
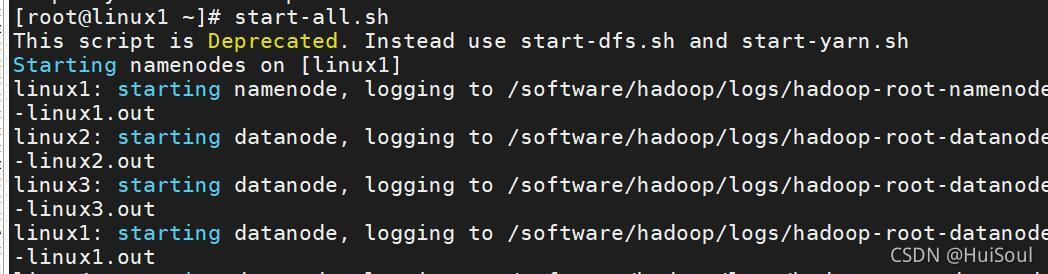
在主從節點中輸入命令:jps,就能看到節點資訊
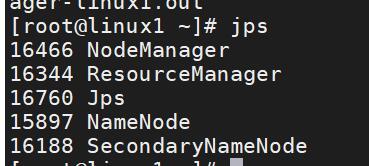
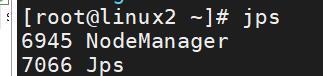
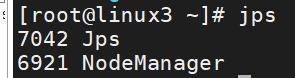
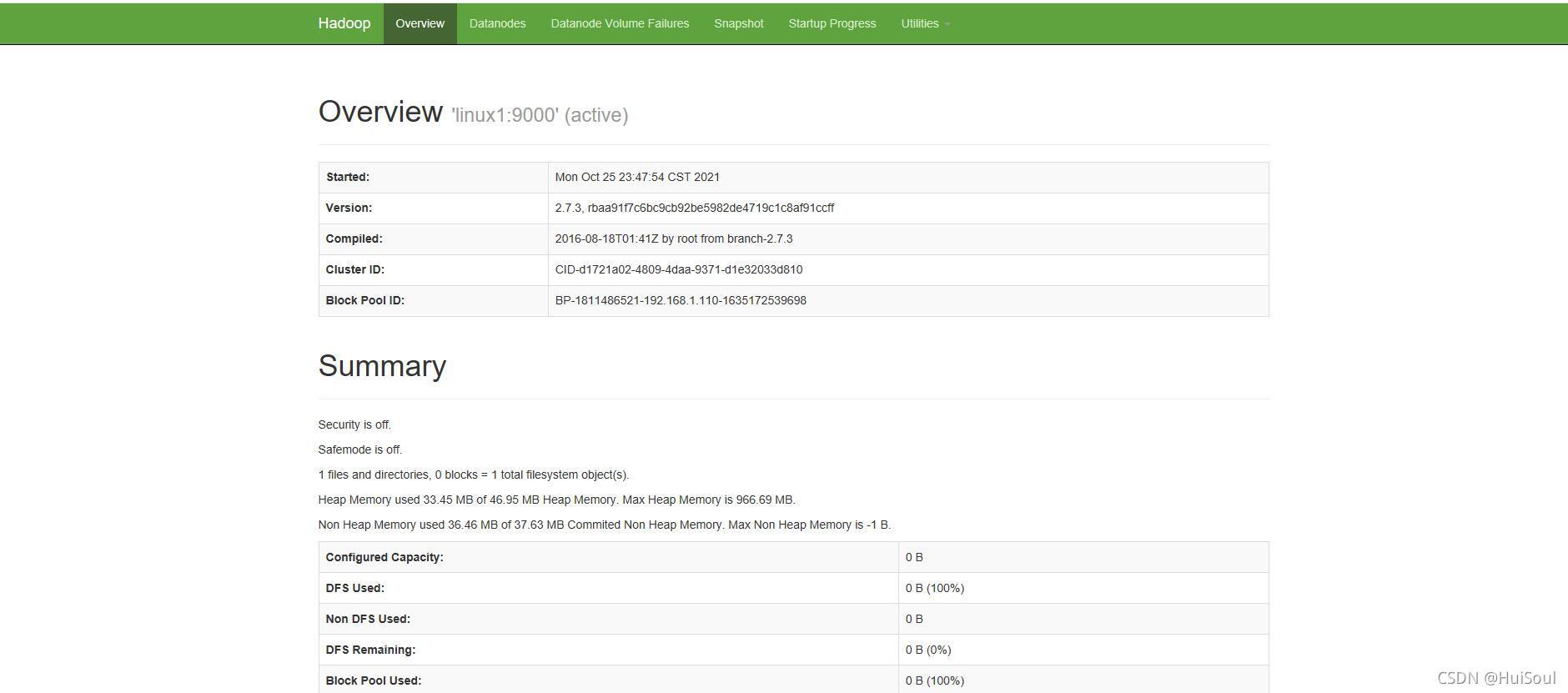
在windows瀏覽器輸入:http://主節點ip:50070/
就能訪問HDFS頁面啦!↓
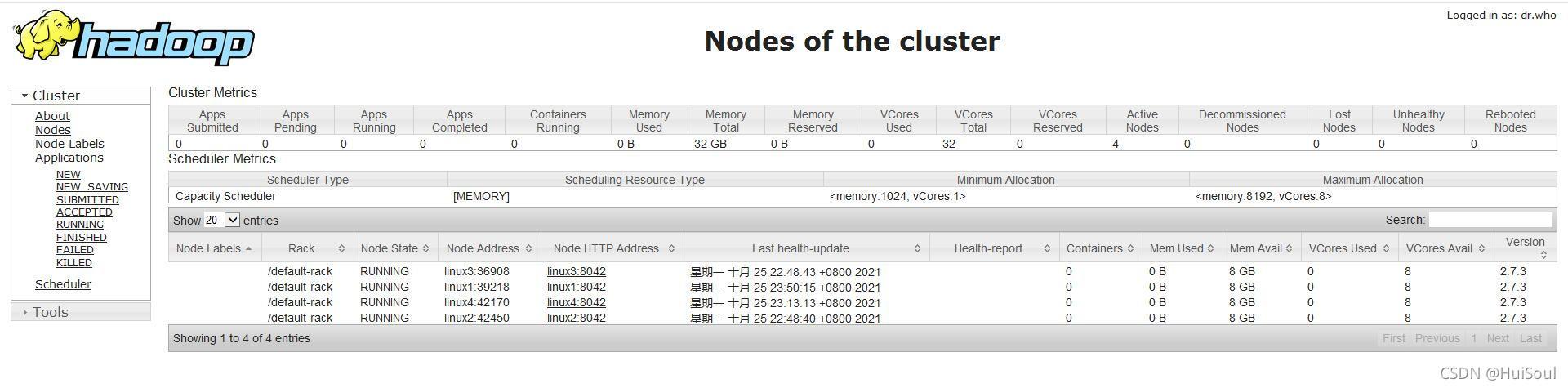
在windows瀏覽器輸入:http://主節點ip:8088/
就能看到yarn頁面啦!↓
本次分享到此結束,謝謝大家閱讀!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337649.html
標籤:其他
下一篇:10.25軟體測驗學習總結