最近想回顧一下資料結構,今天看到一篇內容是是關于 ‘二叉樹 ’的,突然感覺資料結構忘記了好多,今天來整理一下把,還曾記得當初準備考研的時候,資料結構還是學的不錯的,沒想到忘記的這么快~~~
一 基本概念
1、堆疊的特點是"LIFO,即后進先出(Last in, first out)",資料存盤時只能從頂部逐個存入,取出時也需從頂部逐個取出,(就像是一個杯子一樣,先放入的要想拿出來話,就得先拿出后放入得)
var arr = [1, 2, 3, 4, 5];
arr.push(6); // 存入資料 arr -> [1, 2, 3, 4, 5, 6]
arr.pop(); // 取出資料 arr -> [1, 2, 3, 4, 5]
2、堆的特點是"無序"的key-value"鍵值對"存盤方式,
我們想要在書架上找到想要的書,最直接的方式就是通過查找書名,書名就是我們的key,
堆是一種經過排序的樹形資料結構,每個節點都有一個值,通常我們所說的堆的資料結構是指二叉樹,所以堆在資料結構中通常可以被看做是一棵樹的陣列物件,而且堆需要滿足一下兩個性質:
(1)堆中某個節點的值總是不大于或不小于其父節點的值;
(2)堆總是一棵完全二叉樹,
在程式中,堆用于動態分配和釋放程式所使用的物件,在以下情況中呼叫堆操作:
1.事先不知道程式所需物件的數量和大小,
2.物件太大,不適合使用堆疊分配器,
3、佇列的特點是是"FIFO,即先進先出(First in, first out)" ,資料存取時"從隊尾插入,從隊頭取出",
“與堆疊的區別:堆疊的存入取出都在頂部一個出入口,而佇列分兩個,一個出口,一個入口”,
var arr = [1, 2, 3, 4, 5];
// 隊尾in
arr.push(6); // 存入 arr -> [1, 2, 3, 4, 5, 6]
// 隊頭out
arr.shift(); // 取出 arr -> [2, 3, 4, 5, 6]
JS參考
1、JavaScript中變數型別有兩種:
基礎型別(Undefined, Null, Boolean, Number, String, Symbol)一共6種
參考型別(Object)
1)JS中的基礎資料型別,這些值都有固定的大小,往往都保存在堆疊記憶體中(閉包除外),由系統自動分配存盤空間,我們可以直接操作保存在堆疊記憶體空間的值,因此基礎資料型別都是按值訪問 資料在堆疊記憶體中的存盤與使用方式類似于資料結構中的堆疊資料結構,遵循后進先出的原則,
2)JS的參考資料型別,比如陣列Array,它們值的大小是不固定的,參考資料型別的值是保存在堆記憶體中的物件,JS不允許直接訪問堆記憶體中的位置,因此我們不能直接操作物件的堆記憶體空間,在操作物件時,實際上是在操作物件的參考而不是實際的物件,因此,參考型別的值都是按參考訪問的,這里的參考,我們可以粗淺地理解為保存在堆疊記憶體中的一個地址,該地址與堆記憶體的實際值相關聯,
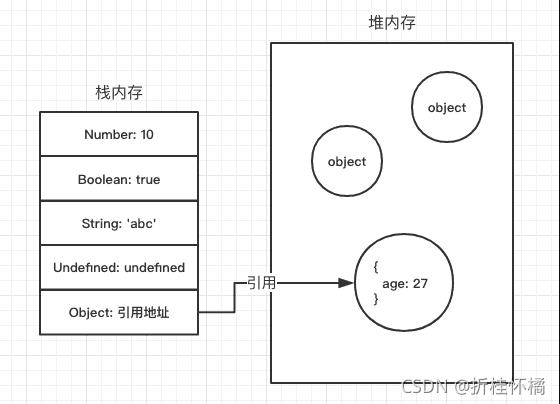
"淺拷貝:堆疊存盤拷貝"
"深拷貝:堆疊堆存盤拷貝"
垃圾回識訓制
JavaScript中有自動垃圾回識訓制,會通過標記清除的演算法識別哪些變數物件不再使用,對其進行銷毀,開發者也可在代碼中手動設定變數值為null(a = null)進行標記清除,讓其失去參考,以便下一次垃圾回收時進行有效回收,
區域環境中,函式執行完成后,函式區域環境宣告的變數不再需要時,就會被垃圾回收銷毀(理想的情況下,閉包會阻止這一程序),
全域環境只有頁面退出時才會出堆疊,解除變數參考,所以開發者應盡量避免在全域環境中創建全域變數,如需使用,也要在不需要時手動標記清除,將其記憶體釋放掉,
為什么會有堆疊記憶體和堆記憶體之分?
通常與垃圾回識訓制有關,為了使程式運行時占用的記憶體最小,
當一個方法執行時,每個方法都會建立自己的記憶體堆疊,在這個方法內定義的變數將會逐個放入這塊堆疊記憶體里,隨著方法的執行結束,這個方法的記憶體堆疊也將自然銷毀了,因此,所有在方法中定義的變數都是放在堆疊記憶體中的;
當我們在程式中創建一個物件時,這個物件將被保存到運行時資料區中,以便反復利用(因為物件的創建成本通常較大),這個運行時資料區就是堆記憶體,堆記憶體中的物件不會隨方法的結束而銷毀,即使方法結束后,這個物件還可能被另一個參考變數所參考(方法的引數傳遞時很常見),則這個物件依然不會被銷毀,只有當一個物件沒有任何參考變數參考它時,系統的垃圾回識訓制才會在核實的時候回收它,
JavaScript是單執行緒
堆疊頂的執行背景關系處于執行中,其它需要排隊
全域背景關系只有一個處于堆疊底,頁面關閉時出堆疊
函式執行背景關系可存在多個,但應避免遞回時堆疊溢位
函式呼叫時就會創建新的背景關系,即使呼叫自身,也會創建不同的執行背景關系
詳見event Loop
4)鏈表是由一組節點組成的集合,每個節點都使用一個物件的參考指向它的后繼,許多鏈表的實作都在鏈表最前面有一個特殊節點,叫做頭節點,
在這里我能聯想到作用域鏈
當代碼在一個環境中執行時,會創建變數物件的一個作用域鏈,
作用域鏈的用途:保證對執行環境有權訪問的所有變數和函式的有序訪問,
作用域鏈的前端,始終是當前執行的代碼所在環境的變數物件,若此環境是函式,則將其活動對象作為變數物件,
- 函式在執行的程序中,先從自己內部找變數,
- 如果找不到,再從創建當前函式所在的作用域去找, 以此往上,
- 注意找的是變數的當前的狀態,
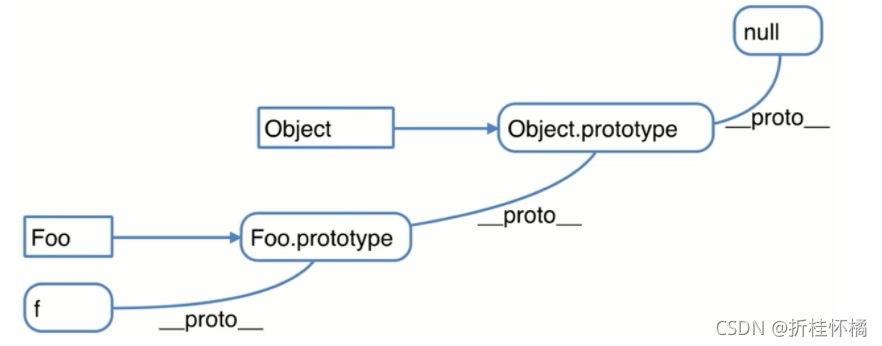
在這里我能聯想到原型鏈
當這個物件沒有這個屬性的時候,去它自身的隱式原型中找,它自身的隱式原型就是它建構式(Foo)的顯式原型(Foo.prototype)但顯式原型(Foo.prototype)中并沒有 toString ;但顯式原型(Foo.prototype)也是物件,也要在它的隱式原型中找,即在其建構式 (Object )的顯式原型中去找 toString. 故要在 f.proto(隱式原型)的.proto(隱式原型)中找,如圖所示,故輸出 null
5)二叉樹:樹是一種非線性的資料結構,以分層的方式存盤資料,特別是有序串列,樹可以分為幾個層次,根節點是第0層,沒有任何子節點的節點稱為葉子節點,
二叉樹是一種特殊的樹,二叉樹進行查找、添加、洗掉都非常快,二叉樹每個節點的子節點不允許超過兩個,相對較小的值保存在左節點中,較大的值保存在右節點中,
二、排序
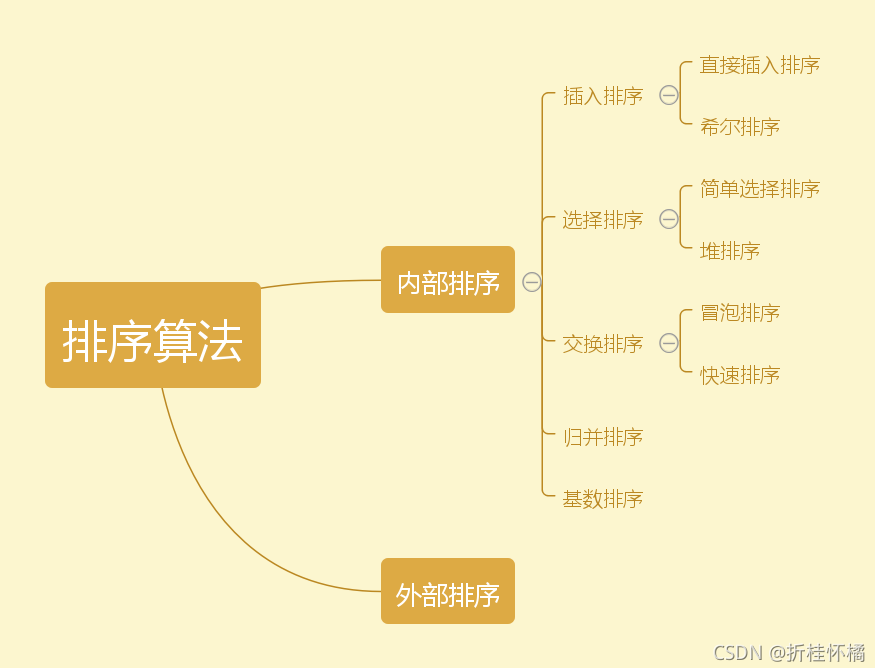
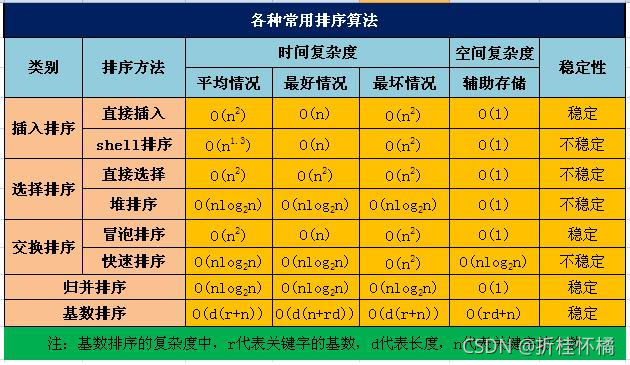
直接插入排序(Straight Insertion Sort)的基本思想是:把n個待排序的元素看成為一個有序表和一個無序表,開始時有序表中只包含1個元素,無序表中包含有n-1個元素,排序程序中每次從無序表中取出第一個元素,將它插入到有序表中的適當位置,使之成為新的有序表,重復n-1次可完成排序程序,
快速排序
冒泡排序
希爾排序
直接選擇排序
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337697.html
標籤:其他
上一篇:連接SQLserver資料庫發生錯誤,提示用戶sa登錄失敗解決方法(親試有用)
下一篇:發布自己的 Python 代碼給別人 “pip install”(linux和windows都有)。(Linux版)