Open3d對kitti資料集進行可視化
- 資料集工程結構
- kitti資料集決議
- Kitti_Dataset類
- Object3d類
- Calib類
- 單幀顯示kiiti的點云bin demo
- Opencv對img進行顯示demo
- 后續內容介紹
- 參考
資料集工程結構
資料集和kitti類決議檔案結構如下:
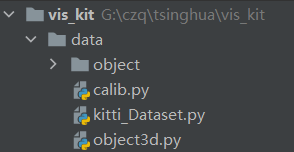
資料集的工程結構如下:
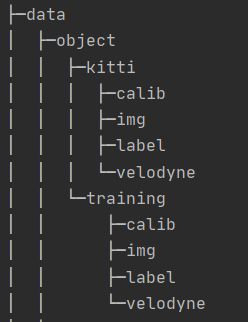
kitti檔案夾的部分直接將kitti資料集對應檔案放入其中,trainning檔案夾可以將我們訓練的資料集放入其中,
該結構很重要因為他涉及到下面對kiiti資料集進行決議,相對路徑的設定,
kitti資料集決議
kitti資料集的中含有bin,rgb,label,calib這四類檔案,其中中calib和label為txt檔案,
我們需要逐行讀入,然后存入到陣列中,然后按照陣列的索引獲取具體的值讀入到后續程式中,
Kitti_Dataset類
下面是kitti_Dataset.py檔案的代碼:
import os
import numpy as np
from data.calib import Calib
from data.object3d import Object3d
import cv2
class Kitti_Dataset:
def __init__(self, dir_path, split="training"):
super(Kitti_Dataset, self).__init__()
self.dir_path = os.path.join(dir_path, split)
# calib矯正引數檔案夾地址
self.calib = os.path.join(self.dir_path, "calib")
# RGB影像的檔案夾地址
self.images = os.path.join(self.dir_path, "img")
# 點云影像檔案夾地址
self.pcs = os.path.join(self.dir_path, "velodyne")
# 標簽檔案夾的地址
self.labels = os.path.join(self.dir_path, "label")
# 得到當前資料集的大小
def __len__(self):
file = []
for _, _, file in os.walk(self.images):
pass
# 回傳rgb圖片的數量
return len(file)
# 得到矯正引數的資訊
def get_calib(self, index):
# 得到矯正引數檔案
calib_path = os.path.join(self.calib, "{:06d}.txt".format(index))
with open(calib_path) as f:
lines = f.readlines()
lines = list(filter(lambda x: len(x) and x != '\n', lines))
dict_calib = {}
for line in lines:
key, value = line.split(":")
dict_calib[key] = np.array([float(x) for x in value.split()])
return Calib(dict_calib)
def get_rgb(self, index):
# 首先得到圖片的地址
img_path = os.path.join(self.images, "{:06d}.png".format(index))
return cv2.imread(img_path)
def get_pcs(self, index):
pcs_path = os.path.join(self.pcs, "{:06d}.bin".format(index))
# 點云的四個資料(x, y, z, r)
aaa = np.fromfile(pcs_path, dtype=np.float32, count=-1).reshape([-1, 4])
return aaa[:, :3]
def get_labels(self, index):
labels_path = os.path.join(self.labels, "{:06d}.txt".format(index))
with open(labels_path) as f:
lines = f.readlines()
lines = list(filter(lambda x: len(x) > 0 and x != '\n', lines))
return [Object3d(x) for x in lines]
Object3d類
下面是object3d.py檔案中的代碼:
import numpy as np
class Object3d:
def __init__(self, content):
super(Object3d, self).__init__()
# content 就是一個字串,根據空格分隔開來
lines = content.split()
# 去掉空字符
lines = list(filter(lambda x: len(x), lines))
self.name, self.truncated, self.occluded, self.alpha = lines[0], float(lines[1]), float(lines[2]), float(lines[3])
self.bbox = [lines[4], lines[5], lines[6], lines[7]]
self.bbox = np.array([float(x) for x in self.bbox])
self.dimensions = [lines[8], lines[9], lines[10]]
self.dimensions = np.array([float(x) for x in self.dimensions])
self.location = [lines[11], lines[12], lines[13]]
self.location = np.array([float(x) for x in self.location])
self.rotation_y = float(lines[14])
#這一行是模型訓練后的label通常最后一行是閾值,可以同個這個過濾掉概率低的object
#如果只要顯示kitti本身則不需要這一行
#self.ioc = float(lines[15])
Calib類
下面是calib.py檔案中的代碼:
class Calib:
def __init__(self, dict_calib):
super(Calib, self).__init__()
self.P0 = dict_calib['P0'].reshape(3, 4)
self.P1 = dict_calib['P1'].reshape(3, 4)
self.P2 = dict_calib['P2'].reshape(3, 4)
self.P3 = dict_calib['P3'].reshape(3, 4)
self.R0_rect = dict_calib['R0_rect'].reshape(3, 3)
self.P0 = dict_calib['P0'].reshape(3, 4)
self.Tr_velo_to_cam = dict_calib['Tr_velo_to_cam'].reshape(3, 4)
self.Tr_imu_to_velo = dict_calib['Tr_imu_to_velo'].reshape(3, 4)
單幀顯示kiiti的點云bin demo
注:demo的腳本都寫在和data同級目錄下*
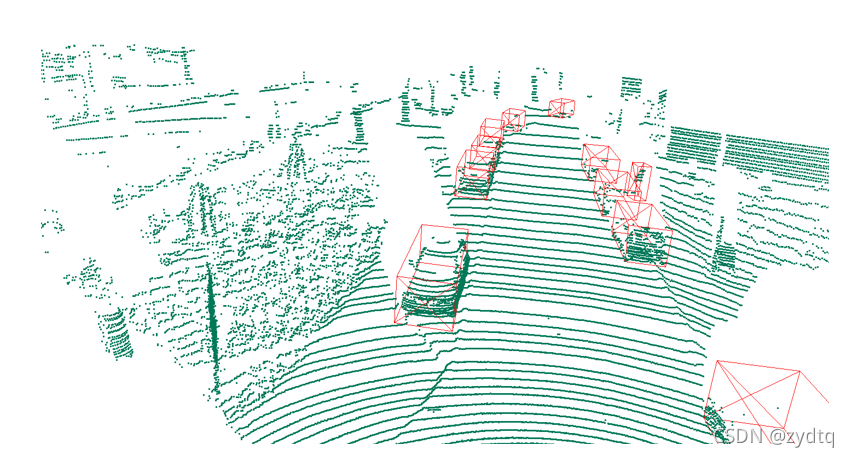
下面是點云俯視圖的顯示結果展示:

下面是對點云的主視圖進行展示:
下面是點云顯示的代碼展示:
該代碼不用直接運行,需要通過terminal中的命令列進行運行,運行的命令是:
python one_bin_show.py --index 10
其中 one_bin_show.py是代碼所在檔案, 10為想要顯示的點云的索引,
one_bin_show.py
import os
import cv2
import numpy as np
import time
import open3d as o3d
from data.kitti_Dataset import Kitti_Dataset
from pathlib import Path
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--index', type=str, default=None, help='index for the label data', required=True)
args = parser.parse_args()
# 根據偏航角計算旋轉矩陣(逆時針旋轉)
def rot_y(rotation_y):
cos = np.cos(rotation_y)
sin = np.sin(rotation_y)
R = np.array([[cos, 0, sin], [0, 1, 0], [-sin, 0, cos]])
return R
def draw_3dframeworks(vis,points):
position = points
points_box = np.transpose(position)
lines_box = np.array([[0, 1], [1, 2], [0, 3], [2, 3], [4, 5], [4, 7], [5, 6], [6, 7],
[0, 4], [1, 5], [2, 6], [3, 7], [0, 5], [1, 4]])
colors = np.array([[1., 0., 0.] for j in range(len(lines_box))])
line_set = o3d.geometry.LineSet()
line_set.points = o3d.utility.Vector3dVector(points_box)
line_set.lines = o3d.utility.Vector2iVector(lines_box)
line_set.colors = o3d.utility.Vector3dVector(colors)
render_option.line_width = 5.0
vis.update_geometry(line_set)
render_option.background_color = np.asarray([1, 1, 1])
# vis.get_render_option().load_from_json('renderoption_1.json')
render_option.point_size = 4
#param = o3d.io.read_pinhole_camera_parameters('BV.json')
print(render_option.line_width)
ctr = vis.get_view_control()
vis.add_geometry(line_set)
#ctr.convert_from_pinhole_camera_parameters(param)
vis.update_geometry(line_set)
vis.update_renderer()
if __name__ == "__main__":
dir_path ="data\\object"
# dir_path = Path(args.path_dataset)
index = args.index
index = int(index)
# split = "kitti"
split = "training"
dataset = Kitti_Dataset(dir_path, split=split)
vis = o3d.visualization.Visualizer()
vis.create_window(width=771, height=867)
obj = dataset.get_labels(index)
img3_d = dataset.get_rgb(index)
calib1 = dataset.get_calib(index)
pc = dataset.get_pcs(index)
print(img3_d.shape)
point_cloud = o3d.geometry.PointCloud()
point_cloud.points = o3d.utility.Vector3dVector(pc)
point_cloud.paint_uniform_color([0, 121/255, 89/255])
vis.add_geometry(point_cloud)
render_option = vis.get_render_option()
render_option.line_width = 4
for obj_index in range(len(obj)):
if obj[obj_index].name == "Car" or obj[obj_index].name == "Pedestrian" or obj[obj_index].name == "Cyclist":
# 閾值設定 ioc
# 如果需要顯示自己的trainninglabel結果,需要取消這樣的注釋,并取消object3d.py最后一行的注釋
#if (obj[obj_index].name == "Car" and obj[obj_index].ioc >= 0.7) or obj[obj_index].ioc > 0.5:
R = rot_y(obj[obj_index].rotation_y)
h, w, l = obj[obj_index].dimensions[0], obj[obj_index].dimensions[1], obj[obj_index].dimensions[2]
x = [l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2]
y = [0, 0, 0, 0, -h, -h, -h, -h]
# y = [h / 2, h / 2, h / 2, h / 2, -h / 2, -h / 2, -h / 2, -h / 2]
z = [w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2]
# 得到目標物體經過旋轉之后的實際尺寸(得到其在相機坐標系下的實際尺寸)
corner_3d = np.vstack([x, y, z])
corner_3d = np.dot(R, corner_3d)
# 將該物體移動到相機坐標系下的原點處(涉及到坐標的移動,直接相加就行)
corner_3d[0, :] += obj[obj_index].location[0]
corner_3d[1, :] += obj[obj_index].location[1]
corner_3d[2, :] += obj[obj_index].location[2]
corner_3d = np.vstack((corner_3d, np.zeros((1, corner_3d.shape[-1]))))
corner_3d[-1][-1] = 1
inv_Tr = np.zeros_like(calib1.Tr_velo_to_cam)
inv_Tr[0:3, 0:3] = np.transpose(calib1.Tr_velo_to_cam[0:3, 0:3])
inv_Tr[0:3, 3] = np.dot(-np.transpose(calib1.Tr_velo_to_cam[0:3, 0:3]), calib1.Tr_velo_to_cam[0:3, 3])
Y = np.dot(inv_Tr, corner_3d)
draw_3dframeworks(vis, Y)
vis.run()
你運行后的點云渲染和視角都不佳,那是因為你并沒有載入相應的renderoption.json和view.json.
如果有需要可以聯系我,或者等后續講解,
Opencv對img進行顯示demo
opencv顯示的效果如下,可以通過a,d按鍵控制索引切換圖片,q鍵退出,

下面是img_3dbox.py檔案,該檔案也需要通過命令列視窗運行,
python img_3dbox.py --path_dataset data\\object
img_3dbox.py為檔案面, data\\object為要顯示的資料檔案夾上級目錄相對位置,
import cv2
import numpy as np
from data.kitti_Dataset import Kitti_Dataset
from pathlib import Path
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--path_dataset', type=str, default=None, help='dir for the label data', required=True)
args = parser.parse_args()
# 根據偏航角計算旋轉矩陣(逆時針旋轉)
def rot_y(rotation_y):
cos = np.cos(rotation_y)
sin = np.sin(rotation_y)
R = np.array([[cos, 0, sin], [0, 1, 0], [-sin, 0, cos]])
return R
if __name__ == "__main__":
# 讀取的資料的檔案夾
# 檔案夾分為三級 dir_path\ training or test \ calib,label,bin,image
# G:\czq\tsinghua\label_test
# dir_path = 'G:\\czq\\tsinghua\\2_caozhenqiang'
# dir_path =Path(args.path_label)
dir_path = Path(args.path_dataset)
# 讀取訓練集檔案夾
split = "training"
dataset = Kitti_Dataset(dir_path, split=split)
k = 0
img3_d = dataset.get_rgb(k)
print(img3_d.shape)
max_num = 100
# 逐張讀入圖片
while True:
img3_d = dataset.get_rgb(k)
calib = dataset.get_calib(k)
# 獲取標簽資料
obj = dataset.get_labels(k)
# 逐個讀入一副圖片中的所有object的標簽
for num in range(len(obj)):
if obj[num].name == "Car" or obj[num].name == "Pedestrian" or obj[num].name == "Cyclist":
#這一行為閾值用來過濾訓練概率較低的object
#if (obj[num].name == "Car" and obj[num].ioc >= 0.7) or obj[num].ioc > 0.5:
# step1 得到rot_y旋轉矩陣 3*3
R = rot_y(obj[num].rotation_y)
# 讀取obect物體的高寬長資訊
h, w, l = obj[num].dimensions[0], obj[num].dimensions[1], obj[num].dimensions[2]
# step2
# 得到該物體的坐標以底面為原點中心所在的物體坐標系下各個點的坐標
# 7 -------- 4
# /| /|
# 6 -------- 5 .
# | | | |
# . 3 -------- 0
# |/ .- - -|/ - - -> (x)
# 2 ---|----- 1
# |
# | (y)
x = [l / 2, l / 2, -l / 2, -l / 2, l / 2, l / 2, -l / 2, -l / 2]
y = [0, 0, 0, 0, -h, -h, -h, -h]
z = [w / 2, -w / 2, -w / 2, w / 2, w / 2, -w / 2, -w / 2, w / 2]
# 將xyz轉化成3*8的矩陣
corner_3d = np.vstack([x, y, z])
# R * X
corner_3d = np.dot(R, corner_3d)
# 將該物體移動到相機坐標系下的原點處(涉及到坐標的移動,直接相加就行)
corner_3d[0, :] += obj[num].location[0]
corner_3d[1, :] += obj[num].location[1]
corner_3d[2, :] += obj[num].location[2]
# 將3d的bbox轉換到2d坐標系中(需要用到內參矩陣)
corner_3d = np.vstack((corner_3d, np.zeros((1, corner_3d.shape[-1]))))
corner_2d = np.dot(calib.P2, corner_3d)
# 在像素坐標系下,橫坐標x = corner_2d[0, :] /= corner_2d[2, :]
# 縱坐標的值以此類推
corner_2d[0, :] /= corner_2d[2, :]
corner_2d[1, :] /= corner_2d[2, :]
corner_2d = np.array(corner_2d, dtype=np.int)
# 繪制立方體邊界框
color = [0, 255, 0]
# 線寬
thickness = 2
#繪制3d框
for corner_i in range(0, 4):
i, j = corner_i, (corner_i + 1) % 4
cv2.line(img3_d, (corner_2d[0, i], corner_2d[1, i]), (corner_2d[0, j], corner_2d[1, j]), color, thickness)
i, j = corner_i + 4, (corner_i + 1) % 4 + 4
cv2.line(img3_d, (corner_2d[0, i], corner_2d[1, i]), (corner_2d[0, j], corner_2d[1, j]), color, thickness)
i, j = corner_i, corner_i + 4
cv2.line(img3_d, (corner_2d[0, i], corner_2d[1, i]), (corner_2d[0, j], corner_2d[1, j]), color, thickness)
cv2.line(img3_d,(corner_2d[0, 0],corner_2d[1, 0]), (corner_2d[0, 5], corner_2d[1, 5]),color, thickness)
cv2.line(img3_d, (corner_2d[0, 1], corner_2d[1, 1]), (corner_2d[0, 4], corner_2d[1, 4]), color, thickness)
cv2.imshow("{}".format(k), img3_d, )
cv2.moveWindow("{}", 300, 50)
key = cv2.waitKey(100) & 0xFF
if key == ord('d'):
k += 1
cv2.destroyAllWindows()
# if idx == 104:
# idx += 1
if key == ord('a'):
k -= 1
if key == ord('q'):
break
if k >= max_num:
k = max_num - 1
if k < 0:
k = 0
# 讀入圖片資訊
# cv2.destroyAllWindows()
后續內容介紹
- 上述代碼講解
- 點云渲染介紹
- 視角介紹
- open3d介紹
參考
Open3d官方檔案
各種open3d教程
kitti類決議
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/337841.html
標籤:其他
上一篇:Ubuntu opencv
下一篇:ubuntu 訓練darknet-yolov4遇到的問題合集。(bus error,Segmentation fault(core dumped))