0、前言
針對MFA 演算法中樣本點所選擇的同類近鄰點和異類近鄰點之間沒有必然的聯系,和LDSA演算法中樣本點的近鄰只有同類樣本的問題,邊界流行嵌入演算法MME被提出,
1、MME演算法原理
MME與MFA與LDSA類似,都需要確定每個樣本的同類近鄰和異類近鄰并分別構建本征圖和懲罰圖,他們的核心思想都是通過線性映射,讓原有資料集中的不同類別容易區分,區別在于同類近鄰和異類近鄰如何構建,以及目標函式如何表達,
MME同類邊界鄰域與異類邊界鄰域確定示意圖如下:(圖片來源于文獻,感謝作者的精美繪圖)
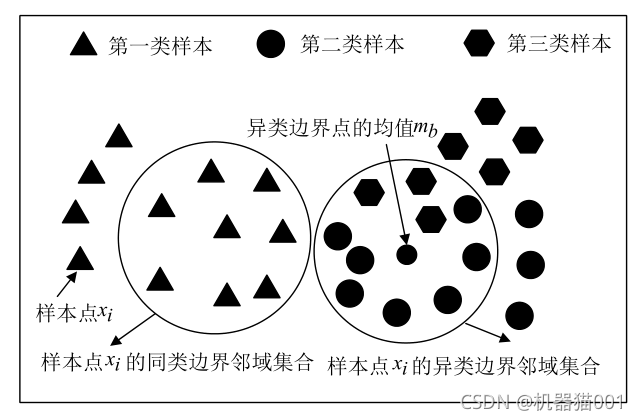
圖1 MME尋找邊界點示意圖
圖1決議:先確定樣本點的異類邊界鄰域集合,并計算異類邊界點的均值
,然后尋找與異類邊界均值
最近的且標簽與樣本點
系統的k個樣本構成其同類邊界鄰域集合,由此可見,每個樣本的同類近鄰點和異類近鄰點之間建立起必然的聯系,
圖2為MME邊界點分析圖:(圖片來源于文獻,感謝作者的精美繪圖)
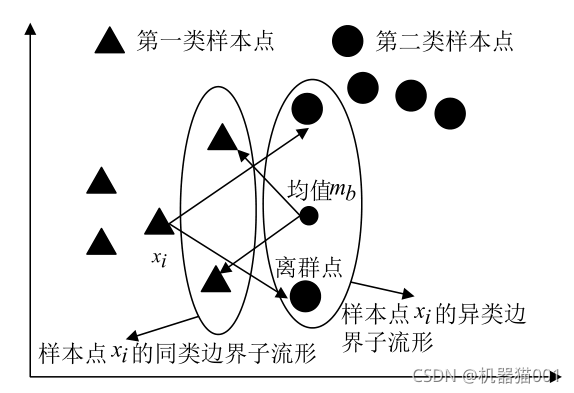
圖2 MME邊界點分析圖
圖3是MFA邊界點分析圖:(圖片來源于文獻,感謝作者的精美繪圖)
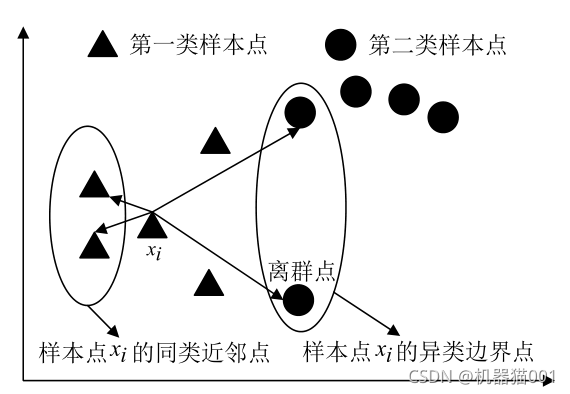
圖3 MFA邊界點分析圖
圖4是 LSDA邊界點分析圖:(圖片來源于文獻,感謝作者的精美繪圖)
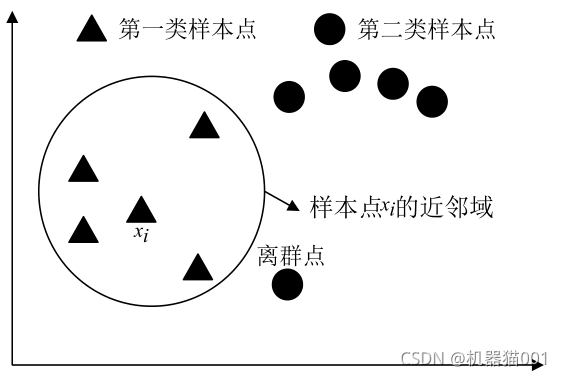
圖4 LSDA邊界點分析
對比圖2、3、4可以看出:MME演算法中,每個樣本點形成的同類邊界子流形和異類邊界子流形有著緊密的聯系;離群點通常位于樣本點的邊界,MME演算法在為每個樣本點構造同類邊界鄰域和異類邊界鄰域的時候,很容易將離群點收入到邊界鄰域內,這在一定程度上能夠減弱離群點給演算法帶來的負面影響,
2、 MME目標函式:
類內權重矩陣構建:![]()
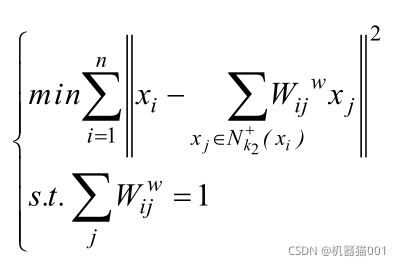
類間權重矩陣構建:![]()
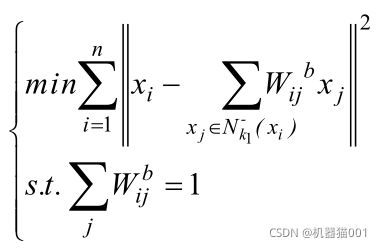
類內重構誤差:
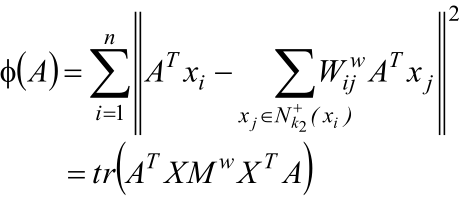
其中: ![]()
類間重構誤差:
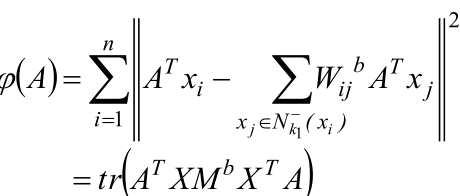
其中: ![]()
MME目標函式:
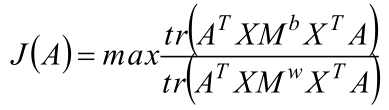
3、改進點分析
MME在分析MFA及LSDA等方法特點基礎上,針對存在的一些典型問題,進行改進突破,主要貢獻是 ①同類邊界子流形和異類邊界子流形有著緊密的聯系;②減弱離群點給演算法帶來的負面影響,
筆者認為在MME貢獻基礎上,還可以在以下方面進行改進:
①非線性化
②相似度量方式改進
③圖1圖2可以看出,樣本的同類邊界基本上都位于該類與其他類的分界處或者說在該類的邊緣,意味著同類樣本的同類邊界點重合可能性很高,基于目標函式要求,最小化同類重構誤差,意味著該類樣本整體要向該類的邊緣(同類邊界點在邊緣)靠近,其他類亦如此,這在類間重合度高的情況下不利于區分,所以可以將同類(非近鄰)間的聚集性納入考慮,并在目標函式中體現,
④與第③點類似,樣本的異類邊界點也基本上是該類與異類的交界處,即處于其他類面向該類的邊緣處(同樣重復度高),異類重構誤差僅僅考慮了與這有限個異類邊界點的距離最大化,但是并不能代表與異類剩余大部分樣本的距離最大化,所以可以將異類間的整體距離納入考慮,并在目標函式中體現,
說明:上述僅僅代表個人觀點,沒有十全十美的方法,也沒有最好的方法,只有各種各樣的解決問題的角度和思維,上述改進點僅僅適用于現有常規的圖嵌入降維演算法理論,并不代表最新觀點,當然各個演算法都有其獨特的優勢和使用場合,沒有最好的,只有更適合的,
4、MME效果分析
待下次統一驗證!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339013.html
標籤:AI