文章目錄
- 結巴分詞簡介
- 分詞
- 基于前綴詞典實作高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖
- 構造前綴詞典
- 構造有向無環圖
- 動態規劃查找最大概率路徑, 找出基于詞頻的最大切分組合
- HMM識別未登陸詞
- 關鍵詞提取
- TF-IDF
- TextRank
- 詞性標注
- 參考
在我的上一篇博客 概率圖模型中,有介紹一些常見的概率圖模型,而在日常作業中,結巴分詞也是常用的中文分詞包,且其中使用了HMM模型,結合 概率圖模型中的理論知識,可以幫助我們進一步了解HMM演算法(當然不僅限于此),
結巴分詞簡介
首先,我們通過readme看看結巴分詞能夠做什么:
分詞:
官方給出了使用的分詞演算法:
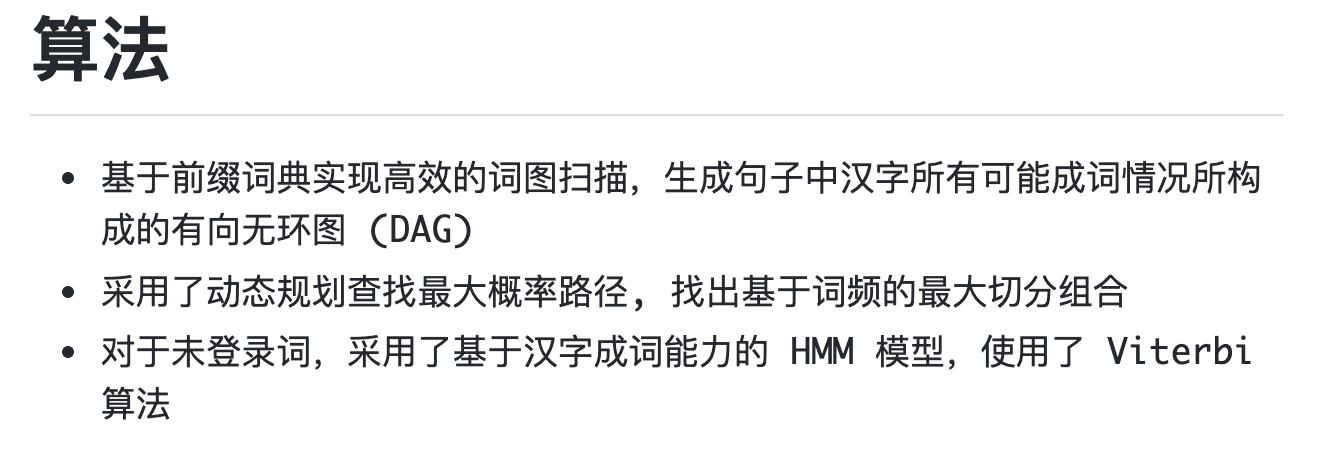
關鍵詞抽取:


詞性標注:
接下來,我們分三個小節分別介紹他們,
分詞
為了能夠更好的理解,用一個實體舉例:
去北京大學玩
基于前綴詞典實作高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖
構造前綴詞典
我們知道,結巴分詞含有自帶的詞典,也可以支持用戶自己添加詞典,利用該詞典構造前綴詞典,該前綴詞典被用于構造DAG,詞典的形式如下:
詞典格式和 dict.txt 一樣,一個詞占一行;每一行分三部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒,
根據詞典,我們可以構造前綴詞典,對示例“去北京大學玩”,其前綴詞典的形式如下:
北京大學 2053
北京大 0 # 不存在前綴詞,詞頻為0
北京 34488
北 17860
京 6583
大學 20025
大 144099
學 17482
去 123402
玩 4207
原始碼如下:
# f是離線統計的詞典檔案句柄
def gen_pfdict(self, f):
# 初始化前綴詞典
lfreq = {}
ltotal = 0
f_name = resolve_filename(f)
for lineno, line in enumerate(f, 1):
try:
# 決議離線詞典文本檔案
line = line.strip().decode('utf-8')
# 詞和對應的詞頻
word, freq = line.split(' ')[:2]
freq = int(freq)
lfreq[word] = freq
ltotal += freq
# 獲取該詞所有的前綴詞
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
# 如果某前綴詞不在前綴詞典中,則將對應詞頻設定為0
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
return lfreq, ltotal
構造有向無環圖
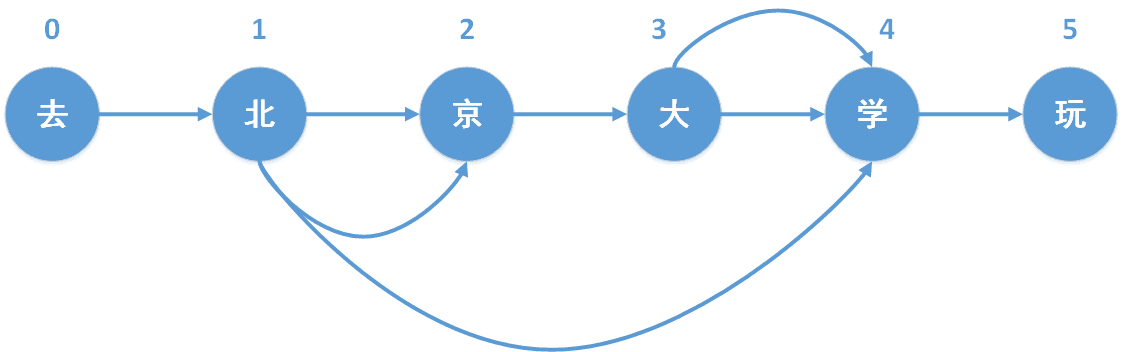
對jieba分詞中,每個字都以其在句子中的位置去標記,其最侄訓生成一個dict,key代表每個詞的開頭,value代表著每個詞的結尾(可能有多個),對示例“去北京大學玩”而言,其DAG結果如下:
{
0: [0] # key=0,value=[0]代表 這個詞為[0:0]即【去】
1: [1,2,4] # key=1,value=[1,2,4]代表有三個詞,分別為[1:1],[1:2],[1:4],即北、北京、北京大學
2: [2]
3: [3,4]
4: [4]
5: [5]
}
實作方式如下(采用偽代碼的形式講述,有興趣的朋友可以去GitHub看他的原始碼):
def get_DAG(self, sentence):
dag = {} # 最終生成的dag
for k in range(len(sentense)):
end_lst = [] # 結尾的position list
# 對每個position構造以該position開頭的子串
for j in range(k+1,len(sentence)):
term = sentence[k:j]
if term 在前綴詞典,且詞頻>0:
end_lst.append(j-1)
elif term 在前綴詞典,且詞頻=0:
continue
elif term 不在前綴詞典中:
# 說明有未登錄詞
break
dag[k] = end_lst
return dag
動態規劃查找最大概率路徑, 找出基于詞頻的最大切分組合
在得到所有可能的切分方式構成的有向無環圖后,我們發現從起點到終點存在多條路徑,多條路徑也就意味著存在多種分詞結果,比如:
# 路徑1
0 -> 1 -> 2 -> 3 -> 4 -> 5
# 分詞結果1
去 / 北 / 京 / 大 / 學 / 玩
# 路徑2
0 -> 1 , 2 -> 3 -> 4 -> 5
# 分詞結果2
去 / 北京 / 大 / 學 / 玩
# 路徑3
0 -> 1 , 2 -> 3 , 4 -> 5
# 分詞結果3
去 / 北京 / 大學 / 玩
# 路徑4
0 -> 1 , 2 , 3 , 4 -> 5
# 分詞結果4
去 / 北京大學 / 玩
...
上一節構造的DAG是帶權的,其權重為該詞在前綴詞典中的詞頻,我們的目標是,求得一個路徑,使得其權重最大,
從原始碼可以看出,采用動態規劃的方式對其進行求解(原始碼位置):

其中,logtotal為構建前綴詞頻時所有的詞頻之和的對數值,目的是為了防止下溢問題,route含義為:(最大概率對數,最大概率對數對應的詞語的最后一個位置),
其狀態轉移方程為:
r
i
=
m
a
x
(
l
o
g
w
i
→
j
Z
+
r
j
)
,
i
→
j
∈
D
A
G
r_i = max(log \frac {w_{i \rightarrow j}}{Z}+r_j),i \rightarrow j \in DAG
ri?=max(logZwi→j??+rj?),i→j∈DAG
其中,
Z
Z
Z是歸一化函式,
i
→
j
i \rightarrow j
i→j表示位置i到位置j的詞,
w
w
w表示該詞的詞頻,
HMM識別未登陸詞
關于HMM的原理,詳見我的博客:概率圖模型,
假設“去北京大學玩”中包含未登陸詞,那么我們其實是試圖構造如下的序列標注:
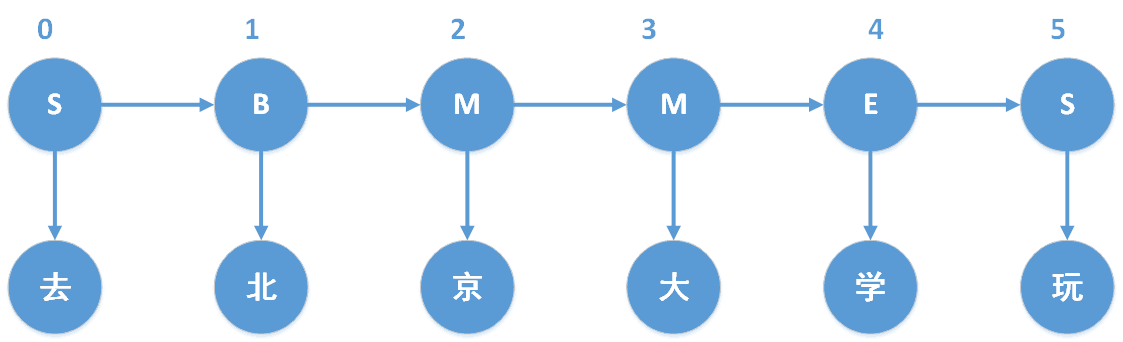
其中,B、M、E、S,分別表示Begin(這個字處于詞的開始位置)、Middle(這個字處于詞的中間位置)、End(這個字處于詞的結束位置)、Single(這個字是單字成詞),
既然我們的目標是獲取序列標注,那么自然是采用維特比演算法求解,
已知觀測序列 O O O和 λ = ( π , A , B ) \lambda=(\pi,A,B) λ=(π,A,B),求得最有可能出現的狀態序列,
- 這里的觀測序列自然是"去北京大學玩"
- 模型引數早已通過語料訓練完成,存盤于jieba/finalseg/下,
prob_start.py 存盤了已經訓練好的HMM模型的狀態初始概率表;
prob_trans.py 存盤了已經訓練好的HMM模型的狀態轉移概率表;
prob_emit.py 存盤了已經訓練好的HMM模型的狀態發射概率表;
在概率圖模型中已經列出維特比演算法的原理:

其原始碼如下:
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] # tabular
path = {}
# 時刻t = 0,初始狀態
for y in states: # init
V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT)
path[y] = [y]
# 時刻t = 1,...,len(obs) - 1
for t in xrange(1, len(obs)):
V.append({})
newpath = {}
# 當前時刻所處的各種可能的狀態
for y in states:
# 獲取發射概率
em_p = emit_p[y].get(obs[t], MIN_FLOAT)
# 分別獲取上一時刻的狀態的概率,該狀態到本時刻的狀態的轉移概率,本時刻的狀態的發射概率
# 其中,PrevStatus[y]是當前時刻的狀態所對應上一時刻可能的狀態
(prob, state) = max(
[(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]])
V[t][y] = prob
# 將上一時刻最優的狀態 + 這一時刻的狀態
newpath[y] = path[state] + [y]
path = newpath
# 最后一個時刻
(prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES')
# 回傳最大概率對數和最優路徑
return (prob, path[state])
關鍵詞提取
采用tfidf和textrank進行關鍵詞提取,
TF-IDF
TF-IDF(term frequency–inverse document frequency,詞頻-逆向檔案頻率)是一種用于資訊檢索(information retrieval)與文本挖掘(text mining)的常用加權技術,其字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降,
它的主要思想是: 如果一個詞在某篇文章中出現的詞頻很高,但是在其他文章中很少出現,則可以認為該詞具有很好的區分能力,可以用作關鍵詞,
tf(term frequency, 詞頻):
t
f
i
,
j
=
n
i
,
j
∑
k
n
k
,
j
tf_{i,j}=\frac{n_{i,j}}{\sum_k n_{k,j}}
tfi,j?=∑k?nk,j?ni,j??
其中,
n
i
,
j
n_{i,j}
ni,j?表示在
d
j
d_j
dj?檔案中,詞
i
i
i出現的次數,
∑
k
n
k
,
j
\sum_k n_{k,j}
∑k?nk,j?表示檔案
d
j
d_j
dj?中詞的總數,
idf(inverse document frequency,逆檔案頻率):
i
d
f
i
=
l
o
g
∣
D
∣
∣
{
j
:
n
i
∈
d
j
}
∣
+
1
idf_i = log \frac{|D|}{|\{j:n_i\in d_j\}|+1}
idfi?=log∣{j:ni?∈dj?}∣+1∣D∣?
其中,分子表示檔案的總數(有多少篇檔案),分母表示包含詞
n
i
n_i
ni?的檔案的數目,分母加1主要為了防止分母為0的情況,
tf-idf:
t
f
i
d
f
=
t
f
?
i
d
f
tfidf=tf*idf
tfidf=tf?idf
TextRank
TextRank演算法是一種基于圖的用于關鍵詞抽取和檔案摘要的排序演算法,由谷歌的網頁重要性排序演算法PageRank演算法改進而來,它利用一篇檔案內部的詞語間的共現資訊(語意)便可以抽取關鍵詞,它能夠從一個給定的文本中抽取出該文本的關鍵詞、關鍵詞組,并使用抽取式的自動文摘方法抽取出該文本的關鍵句,
pagerank:
(1)鏈接數量:如果一個網頁被越多的其他網頁鏈接,說明這個網頁越重要,即該網頁的PR值(PageRank值)會相對較高;
(2)鏈接質量:如果一個網頁被一個越高權值的網頁鏈接,也能表明這個網頁越重要,即一個PR值很高的網頁鏈接到一個其他網頁,那么被鏈接到的網頁的PR值會相應地因此而提高,
其計算公式如下:
s
(
v
i
)
=
(
1
?
d
)
+
d
×
∑
j
∈
i
n
(
v
i
)
1
∣
o
u
t
(
v
j
)
∣
s
(
v
j
)
s(v_i)=(1-d)+d\times \sum_{j\in in(v_i)} \frac{1}{|out(v_j)|} s(v_j)
s(vi?)=(1?d)+d×j∈in(vi?)∑?∣out(vj?)∣1?s(vj?)
s
(
v
)
s(v)
s(v)表示網頁的重要性,即pr值,d是阻尼系數,一般是0.85,
i
n
(
v
)
in(v)
in(v)是網頁的入度,表示對所有指向該網頁的網頁;
o
u
t
(
v
)
out(v)
out(v)表示網頁的出度,
1
∣
o
u
t
(
v
j
)
∣
s
(
v
j
)
\frac{1}{|out(v_j)|} s(v_j)
∣out(vj?)∣1?s(vj?)說明,傳入
v
i
v_i
vi?的pr值,被所有的出度分攤,
同樣的,我們可以寫出textrank的公式:
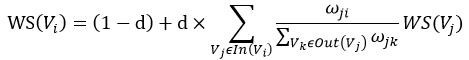
與pagerank不同的是,pagerank之間的邊是有向無權邊,而textrank之間的邊是無向有權邊,
ω
j
i
\omega_{ji}
ωji?即表示邊權,
textrank提取關鍵詞與關鍵詞組的步驟如下:
(1)給定文本進行整句分割,得到
T
=
[
S
1
,
S
2
,
?
?
,
S
m
]
T=[S_1,S_2,\cdots,S_m]
T=[S1?,S2?,?,Sm?]
(2)對于每個句子,對其進行分詞和詞性標注,然后剔除停用詞,只保留指定詞性的詞,如名詞、動詞、形容詞等,
(3)構建詞圖
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),其中V為節點集合,由以上步驟生成的詞組成,然后采用共現關系構造任意兩個節點之間的邊:兩個節點之間存在邊僅當它們對應的詞在長度為K的視窗中共現,K表示視窗大小,即最多共現K個單詞,一般K取2;
(4)根據上面的公式,迭代計算各節點的權重,直至收斂;
(5)對節點的權重進行倒序排序,從中得到最重要的t個單詞,作為top-t關鍵詞;
(6)對于得到的top-t關鍵詞,在原始文本中進行標記,若它們之間形成了相鄰詞組,則作為關鍵詞組提取出來,
詞性標注
其程序與分詞程序類似:
1)如果是漢字,則會基于前綴詞典構建有向無環圖,然后基于有向圖計算最大概率路徑,同時在前綴詞典中查找所分出的詞的詞性,如果沒有找到,則將其詞性標注為“x”(非語素字 非語素字只是一個符號,字母x通常用于代表未知數、符號);如果HMM標志位置位,并且該詞為未登錄詞,則通過隱馬爾科夫模型對其進行詞性標注;
2)如果是其它,則根據正則運算式判斷其型別,分別賦予“x”,“m”(數詞 取英語numeral的第3個字母,n,u已有他用),“eng”(英文),
具體就不贅述,
參考
結巴分詞原始碼
結巴分詞介紹,作者:zhbzz2007
TF-IDF
TextRank
TextRank演算法的基本原理及textrank4zh使用實體
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339023.html
標籤:AI
上一篇:聚類演算法之DBSCAN