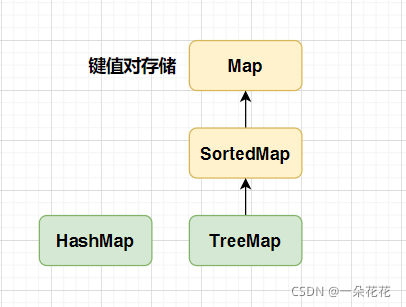
Map 和 Set
1.標準庫:TreeSet,TreeMap,HashSet,HashMap
2.二叉搜索樹:對應TreeSet TreeMap 底層實作
3.哈希表:對應 HashMap,HashTree 底層實作
搜索
Map 和 Set是一種專門用來進行搜索的容器或者資料結構,其搜索的效率與其具體的實體化子類有關
模型
一般把搜索的資料稱為關鍵字(Key),和關鍵字對應的稱為值(Value),將其稱之為 Key-value 的鍵值對,所以模型會有兩種
- 純 key 模型 :即,我們 Set 要解決的事情,只需要判斷關鍵字在不在集合中即可,沒有關聯的 Value —— 例:有一個英文詞典,快速查找一個單詞是否在詞典中
- Key-Value 模型 :即,我們 Map 要解決的事情,需要根據指定 Key 找到關聯的 Value
例:梁山好漢的江湖綽號:每個好漢都有自己的江湖綽號
Map 中存盤的就是 Key - Value 的鍵值對,Set 中只存盤了 Key
Map 的使用
Map.Entry<K, V>
Map.Entry<K, V> 是 Map 內部實作的用來存放 <key, value> 鍵值對映射關系的內部類,該內部類中主要提供了<key, value>的獲取,value的設定以及Key的比較方式
| 方法 | 說明 |
|---|---|
| K getKey( ) | 回傳 Entry 中的 key |
| V getValue( ) | 回傳 Entry 中的 value |
| V setValue(V value) | 將鍵值對中的 value 替換為指定 value |
常用方法
| 方法 | 說明 |
|---|---|
| V get (Object key) | 回傳 key 對應的 value |
| V getOrDefault (Object key,V defaultValue) | 回傳 key 對應的 value,key 不存在,回傳默認值 |
| V put (K key,V value) | 設定 key 對應的 value |
| V remove (Object key) | 洗掉 key 對應的映射關系 |
| Set keySet ( ) | 回傳所有 key 的不重復集合 |
| Collection values ( ) | 回傳所有 value 的可重復集合 |
| Set<Map.Entry <K, V> > entrySet( ) | 回傳所有的 key-value 映射關系 |
| boolean containsKey (Object key) (高效) | 判斷是否包含 key |
| boolean containsValue (Object value) (低效) | 判斷是否包含 value |
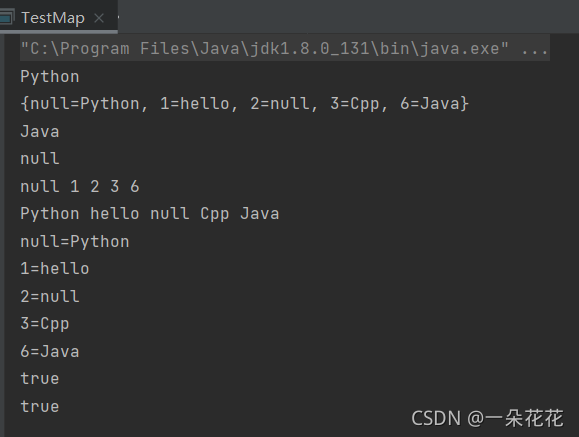
HashMap 使用示例:
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
// put(key, value):插入key-value的鍵值對
map.put(1,"hello~");
// key value 重復
map.put(1,"hello");
map.put(6,"Java");
map.put(3,"Cpp");
// put(key,value): key 為null
map.put(null,"Python");
// put(key,value): value 為null
map.put(2,null);
System.out.println(map.get(null));
System.out.println(map);
// 回傳 key 對應的 value
System.out.println(map.get(6));
// 找不到 回傳會null
System.out.println(map.get(10));
// 列印所有的 key
for (Integer key : map.keySet()) {
System.out.print(key + " ");
}
System.out.println();
// 列印所有的 value
for (String value : map.values()) {
System.out.print(value + " ");
}
System.out.println();
// 按照映射關系列印
for (Map.Entry<Integer,String> entry : map.entrySet()) {
System.out.println(entry);
}
// 是否包含 key
System.out.println(map.containsKey(6));
//是否包含 value
System.out.println(map.containsValue("Java"));
}
輸出結果:
TreeMap 使用示例:
1.插入鍵值對
public static void main(String[] args) {
Map<String,String> map = new TreeMap<>();
//插入鍵值對
map.put("西游記","吳承恩");
map.put("紅樓夢","曹雪芹");
map.put("狂人日記","魯迅");
// value 重復
map.put("阿Q正傳","魯迅");
// key 重復
map.put("阿Q正傳","key不能重復");
System.out.println(map.get("阿Q正傳"));
}
輸出結果:
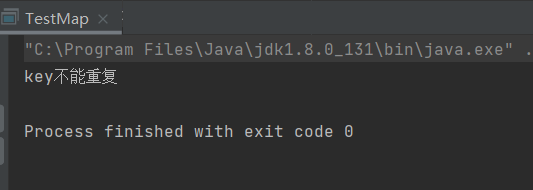
如果key存在,會使用 value 替換原來 key 所對應的 value,回傳舊 value
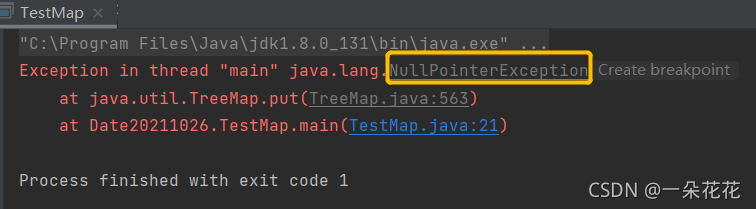
key 不能為null
key 為null,會拋出 NullPointerException 例外
public static void main(String[] args) {
Map<String,String> map = new TreeMap<>();
// key 不能為 null,否則拋出例外
map.put(null,"例外~");
}
輸出結果:
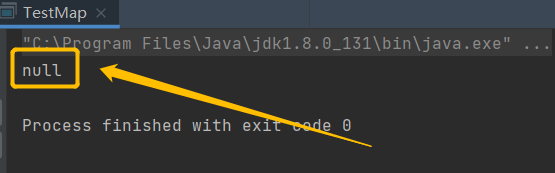
value 可以為null
public static void main(String[] args) {
Map<String,String> map = new TreeMap<>();
// value 可以為null
map.put("value為null",null);
System.out.println(map.get("value為null"));
}
輸出結果:
注意事項:
- Map 是一個介面,不能直接實體化物件,如果要實體化物件只能實體化其實作類 TreeMap 或者HashMap
- TreeMap 中存放鍵值對的 key 是唯一的,value 是可以重復的
- 在 TreeMap 中插入鍵值對時,key 不能為空,否則就會拋 NullPointerException 例外,但是 value 可以為空
- Map 中的 key 可以全部分離出來,存盤到 Set 中來進行訪問 (因為 key 不能重復)
- Map 中的 value 可以全部分離出來,存盤在 Collection 的任何一個子集合中 (value可能有重復)
- Map 中鍵值對的 key 不能直接修改,value 可以修改,如果要修改 key,只能先將該 key 洗掉掉,然后再進行重新插入
- HashMap 和 TreeMap 的區別
| Map底層結構 | TreeMap | HashMap |
|---|---|---|
| 底層結構 | 紅黑樹 | 哈希桶 |
| 插入 / 洗掉 / 查找時間復雜度 | O(logN) | O(1) |
| 是否有序 | 關于 key 有序 | 無序 |
| 執行緒是否安全 | 不安全 | 不安全 |
| 插入 / 洗掉 / 查找區別 | 需要進行元素比較 | 通過哈希函式計算哈希地址 |
| 比較與重寫 | key 必須能夠比較,否則會拋出 ClassCastException 例外 | 自定義型別需要重寫 equals 和 hashCode 方法 |
| 應用場景 | 需要 key 有序場景下 | key 是否有序不關心,需要更高的時間性能 |
Set 的使用
Set與Map主要的不同:
- Set 是繼承自 Collection 的介面類
- Set 中只存盤了 key
常見方法:
| 方法 | 說明 |
|---|---|
| boolean add(E e) | 添加元素,但重復元素不會被添加成功 |
| void clear( ) | 清空集合 |
| boolean contains(Object o) | 判斷 o 是否在集合中 |
| Iterator iterator( ) | 回傳迭代器 |
| boolean remove(Object o) | 洗掉集合中的 o |
| int size( ) | 回傳set中元素的個數 |
| boolean isEmpty( ) | 檢測 set 是否為空,慷訓傳 true,否則回傳 false |
| Object[] toArray( ) | 將 set 中的元素轉換為陣列回傳 |
| boolean containsAll(Collection<?> c) | 集合 c 中的元素是否在 set 中全部存在,是回傳 true,否則回傳 false |
| boolean addAll(Collection<? extends E> c) | 將集合 c 中的元素添加到 set 中,可以達到去重的效果 |
HashSet 代碼示例:
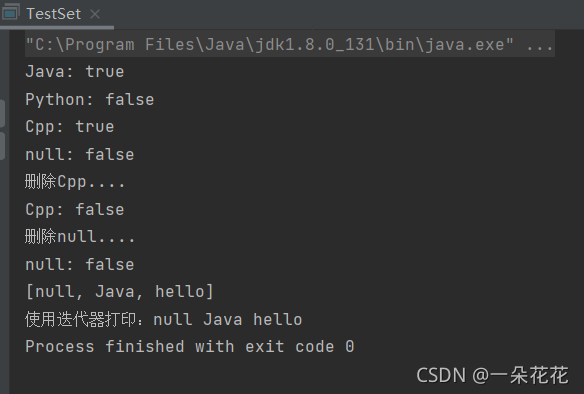
public static void main(String[] args) {
//1.實體化 Set
Set<String> set = new HashSet<>();
//2.插入元素 : add
set.add("hello");
set.add("Java");
set.add("Cpp");
// 插入null
set.add(null);
//3.判斷某個值是否存在
System.out.println("Java: " + set.contains("Java"));
System.out.println("Python: " + set.contains("Python"));
System.out.println("Cpp: " + set.contains("Cpp"));
System.out.println("null: " + set.contains("null"));
//4.洗掉某個值
System.out.println("洗掉Cpp....");
set.remove("Cpp");
System.out.println("Cpp: " + set.contains("Cpp"));
//洗掉null
System.out.println("洗掉null....");
System.out.println("null: " + set.contains(null));
//5.列印Set
// a) 直接列印
System.out.println(set);
// b) 回圈遍歷,使用迭代器
// 迭代器的泛型引數 要和 集合類中保存的元素引數型別一致
// 集合類內部自己實作自己版本的迭代器,不同的集合類 內部的迭代器型別不同,迭代方式也不同
System.out.print("使用迭代器列印:");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()){
String next = iterator.next();
System.out.print(next + " ");
}
}
輸出結果:
TreeSet 代碼示例:
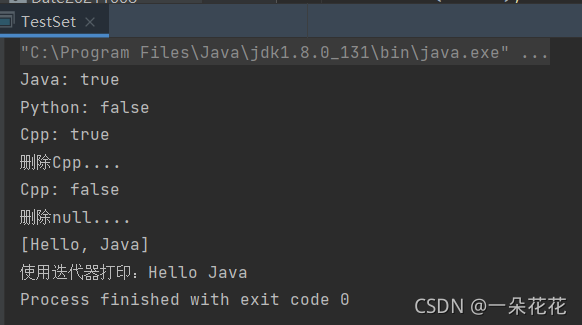
public static void main(String[] args) {
//1.實體化 Set
Set<String> set = new TreeSet<>();
//2.插入元素
set.add("Hello");
set.add("Java");
set.add("Cpp");
// 不能插入null,會拋出 空指標例外
// set.add(null);
//3.判斷某個值是否存在
System.out.println("Java: " + set.contains("Java"));
System.out.println("Python: " + set.contains("Python"));
System.out.println("Cpp: " + set.contains("Cpp"));
// contains(key): key為null,拋出空指標例外
// System.out.println("null: " + set.contains(null));
//4.洗掉某個值
System.out.println("洗掉Cpp....");
set.remove("Cpp");
System.out.println("Cpp: " + set.contains("Cpp"));
//洗掉null
System.out.println("洗掉null....");
// remove(key): key為null,拋出空指標例外
// set.remove(null);
// System.out.println("null: " + set.contains(null));
//5.列印 set
// a) 直接列印
System.out.println(set);
// b) 迭代器列印
System.out.print("使用迭代器列印:");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()){
String next = iterator.next();
System.out.print(next + " ");
}
}
輸出結果:
注意事項:
- Set 是繼承自 Collection 的一個介面類
- Set 中只存盤了 key,key 是唯一的,不能重復
- Set 最大的功能就是對集合中的元素進行去重
- Set 中的 Key 不能修改,如果要修改,先將原來的洗掉掉,然后再重新插入
- TreeSet 和 HashSet 的區別
| Set | TreeSet | HashSet |
|---|---|---|
| 底層結構 | 紅黑樹 | 哈希桶 |
| 插入 / 洗掉 / 查找時間復雜度 | O(logN) | O(1) |
| 是否有序 | 關于 key 有序 | 不一定有序 |
| 執行緒是否安全 | 不安全 | 不安全 |
| 插入 / 洗掉 / 查找區別 | 按照紅黑樹的特性來進行插入和洗掉 | 1. 先計算 key 哈希地址;2. 然后進行插入和洗掉 |
| 比較與重寫 | key 必須能夠比較,否則會拋出 ClassCastException 例外 | 自定義型別需要重寫 equals 和 hashCode 方法 |
| 應用場景 | 需要 key 有序場景下 | key是否有序不關心,需要更高的時間性能 |
題目練習
只出現 1 次的數字
題目: 在線OJ
思考:
方法一: 通過 Map 統計每個數字出現的次數,再遍歷 Map 找到那個只出現一次的數字
- 創建 Map<Integer,Integer>,key:當前出現的數字;value:該數字出現次數
- 遍歷統計次數即可~
方法二: 按位異或 A ^ B ^ A = B;A ^ 0 = A,異或規則,相同為0,相異為1
代碼實作:
- 方法1
public int singleNumber(int[] nums) {
// key : 當前數字
// value : 數字出現次數
Map<Integer,Integer> map = new HashMap<>();
for (int x : nums) {
Integer value = map.get(x);
// 當前數字在 map 中不存在,新增一個鍵值對
if(value == null){
map.put(x,1);
}
//這個數字已經存在了
else{
map.put(x,value + 1);
}
}
// 遍歷 map ,找到出現次數為1的數
for (Map.Entry<Integer,Integer> entry : map.entrySet()) {
// getValue 得到的是一個 Integer 包裝類
// 使用 equals,相當于對 1 自動裝箱
// 使用 == ,相當于對 Integer 自動拆箱
if(entry.getValue().equals(1)){
return entry.getKey();
}
}
//沒找到
return 0;
}
- 方法2
public int singleNumber(int[] nums) {
int result = 0;
for (int x : nums) {
result ^= x;
}
return result;
}
復制帶隨機指標的鏈表
題目: 在線OJ

思考:
- 創建一個 Map <Node,Node>,key:舊鏈表的節點;value:新鏈表的節點(舊鏈表對應節點的拷貝)
- Map 結構創建好了之后,遍歷舊鏈表,取出節點在 Map 中找到對應的 value
例:新node1.next = map.get (舊node1.next);
新node1.random = map.get (舊node1.random);
代碼實作:
public Node copyRandomList(Node head) {
//1.創建 map
Map<Node,Node> map = new HashMap<>();
//2.遍歷舊鏈表,把舊鏈表的每個節點 依次插入到map中
// key: 舊鏈表節點
// value: 新鏈表節點
for (Node cur = head;cur != null;cur = cur.next){
map.put(cur,new Node(cur.val));
}
// 再次遍歷鏈表,修改新鏈表節點中的 next 和 random
for (Node cur = head;cur != null;cur = cur.next){
// 先從 map 中找到 該 cur對應的新鏈表對應的節點
Node newCur = map.get(cur);
newCur.next = map.get(cur.next);
newCur.random = map.get(cur.random);
}
// 回傳新鏈表的頭節點
return map.get(head);
}
寶石和石頭
題目: 在線OJ
思考:
- 遍歷 J,把所有寶石放到一個 set 里
- 遍歷 S,和 set 中元素比較即可
代碼實作:
public int numJewelsInStones(String jewels, String stones) {
// 先遍歷J,把所有寶石型別加到一個 set 里
Set<Character> set = new HashSet<>();
for (char c : jewels.toCharArray()) {
set.add(c);
}
// 遍歷 S,和set 中元素比較
int ret = 0;
for (char c : stones.toCharArray()) {
if(set.contains(c)){
ret++;
}
}
return ret;
}
寶石和石頭
題目: 在線OJ
舊鍵盤上壞了幾個鍵,于是在敲一段文字的時候,對應的字符就不會出現,現在給出應該輸入的一段文字、以及實際被輸入的文字,請你列出肯定壞掉的那些鍵
輸入描述:
輸入在2行中分別給出應該輸入的文字、以及實際被輸入的文字,每段文字是不超過80個字符的串,由字母A-Z(包括大、小寫)、數字0-9、
以及下劃線“_”(代表空格)組成,題目保證2個字串均非空
輸出描述:
按照發現順序,在一行中輸出壞掉的鍵,其中英文字母只輸出大寫,每個壞鍵只輸出一次,題目保證至少有1個壞鍵
思考:
壞掉的鍵,即:按下鍵,沒有輸出
給出一個預期輸出的字串,再給出一個實際輸出的字串
找到那些預期要輸出,但實際沒輸出的字符,這樣的字符就是壞掉的鍵
鍵盤上某個鍵壞了,則其大小寫字母均不會輸出,需要把 A 和 a當成同一種情況
代碼實作:
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
//回圈讀取兩個字串
// 字串1: 預期輸出內容; 字串2: 實際輸出內容
while (scan.hasNext()){
String expected = scan.next();
String actual = scan.next();
// 把輸入的字串全部轉換成大寫字母
expected = expected.toUpperCase();
actual = actual.toUpperCase();
// 創建一個set, 存盤實際輸出的每個字符
Set<Character> actualSet = new HashSet<>();
for (int i = 0; i < actual.length(); i++) {
// set中的元素 不能重復,若add時,發現這個元素已經存在,add操作就會失敗,
// 但不會有任何影響,不會拋出例外,也不會影響元素原來的內容
actualSet.add(actual.charAt(i));
}
// 存放壞的鍵的set
Set<Character> brokenKeySet = new HashSet<>();
// 遍歷預期輸出內容,看是否匹配即可
for (int i = 0;i < expected.length();i++){
char c = expected.charAt(i);
//當前字符被輸出,該鍵沒壞
if(actualSet.contains(c)){
continue;
}
//沒被輸出,就是壞的鍵
// [壞的鍵],預期字串中可能多次出現壞的鍵,但最后輸出結果 只輸出一次
// 需要去重操作
if(brokenKeySet.contains(c)){
continue;
}
System.out.print(c);
brokenKeySet.add(c);
}
}
}
前 K 個高頻單詞
題目: 在線OJ
思考:
- 先統計陣列中每個單詞出現的次數,使用 Map
- 把鍵值對組織到一個 ArrayList 中
- 按照題目要求降序排序(出現次數 + 字典序)
- 取前 K 個元素即可
代碼實作:
//比較器
static class MyComparator implements Comparator<String>{
private Map<String,Integer> map;
public MyComparator(Map<String, Integer> map) {
this.map = map;
}
@Override
public int compare(String o1, String o2) {
int count1 = map.get(o1);
int count2 = map.get(o2);
if(count1 == count2) {
// String 自身的 compareTo
return o1.compareTo(o2);
}
return count2 - count1;
}
}
public List<String> topKFrequent(String[] words, int k) {
//1.統計每個單詞出現的次數
Map<String,Integer> map = new HashMap<>();
for (String s : words) {
Integer count = map.getOrDefault(s,0);
map.put(s,count + 1);
}
//2.把剛才統計的字串內容放到ArrayList 中
ArrayList<String> arrayList = new ArrayList<>(map.keySet());
//3.排序
// sort 默認按照元素的自身大小升序排序(字典序)
// 自己寫一個比較器
// Collections.sort(arrayList,new MyComparator(map));
//匿名內部類 這個類只需要用一次,用完就丟了~~
// Collections.sort(arrayList, new Comparator<String>() {
// @Override
// public int compare(String o1, String o2) {
// int count1 = map.get(o1);
// int count2 = map.get(o2);
// if(count1 == count2) {
// // String 自身的 compareTo
// return o1.compareTo(o2);
// }
// return count2 - count1;
// }
// });\
// lambda 運算式 本質上就是一個匿名方法,也可以認為是一個物件
Collections.sort(arrayList, (o1, o2) -> {
int count1 = map.get(o1);
int count2 = map.get(o2);
if(count1 == count2) {
// String 自身的 compareTo
return o1.compareTo(o2);
}
return count2 - count1;
});
//取前 K 個元素
return arrayList.subList(0,k);
}

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/339146.html
標籤:其他
上一篇:少兒編程教培管理系統