生物神經元與人工神經元
在了解神經元網路之前,我們先簡單的看看生物學上的神經元是什么樣子的,下圖摘自維基百科:
(因為我不是專家,這里的解釋只用于理解人工神經元模擬了生物神經元的什么地方,不一定完全準確)
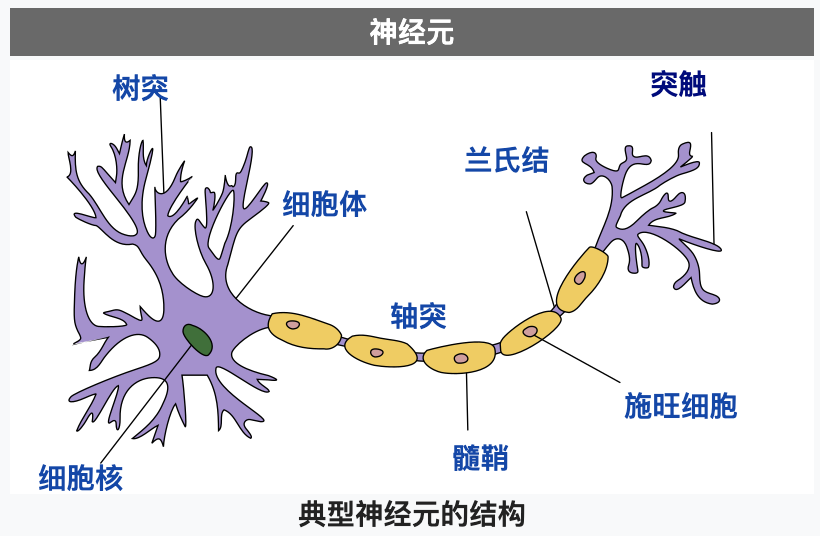
神經元主要由細胞體和細胞突組成,而細胞突分為樹突 (Dendrites) 和軸突 (Axon),樹突負責接收其他神經元輸入的電流,而軸突負責把電流輸出給其他神經元,一個神經元可以通過樹突從多個神經元接收電流,如果電流沒有達到某個閾值則神經元不會把電流輸出,如果電流達到了某個閾值則神經元會通過軸突的突觸把電流輸出給其他神經元,這樣的規則被稱為全有全無律,輸入電流達到閾值以后輸出電流的狀態又稱為到達動作電位,動作電位會持續 1 ~ 2 毫秒,之后會進入約 0.5 毫秒的絕對不應期,無論輸入多大的電流都不會輸出,然后再進入約 3.5 毫秒的相對不應期,需要電流達到更大的閾值才會輸出,最后回傳靜息電位,神經元之間連接起來的網路稱為神經元網路,人的大腦中大約有 860 億個神經元,因為 860 億個神經元可以同時作業,所以目前的計算機無法模擬這種作業方式 (除非開發專用的芯片),只能模擬一部分的作業方式和使用更小規模的網路,
計算機模擬神經元網路使用的是人工神經元,單個人工神經元可以用以下公式表達:
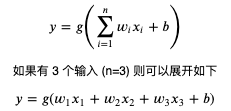
其中 n 代表輸入的個數,你可以把 n 看作這個神經元擁有的樹突個數,x 看作每個樹突輸入電流的值;而 w (weight) 代表各個輸入的權重,也就是各個樹突對電流大小的調整;而 b (bias) 用于調整各個輸入乘權重相加后的值,使得這個值可以配合某個閾值作業;而 g 則是激活函式,用于判斷值是否達到閾值并輸出和輸出多少,通常會使用非線性函式;而 y 則是輸出的值,可以把它看作軸突輸出的電流,連接這個 y 到其他神經元就可以組建神經元網路,
我們在前兩篇看到的其實就是只有一個輸入并且沒有激活函式的單個人工神經元,把同樣的輸入傳給多個神經元 (第一層),然后再傳給其他神經元 (第二層),然后再傳給其他神經元 (第三層) 就可以組建人工神經元網路了,同一層的神經元個數越多,神經元的層數越多,網路就越強大,但需要更多的運算時間并且更有可能發生第一篇文章講過的過擬合 (Overfitting) 現象,
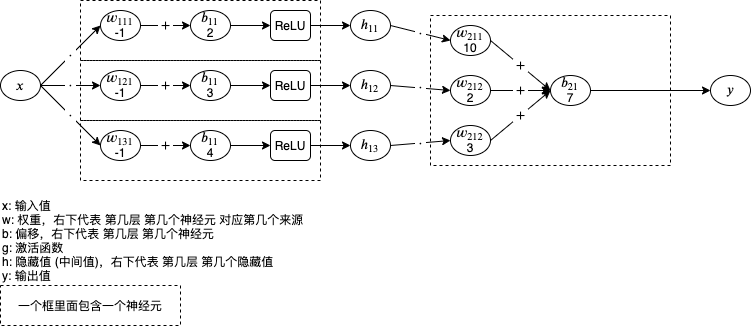
下圖是人工神經元網路的例子,有 3 輸入 1 個輸出,經過 3 層處理,第 1 層和第 2 層各有兩個神經元對應隱藏值 (中間值),第 3 層有一個神經元對應輸出值:
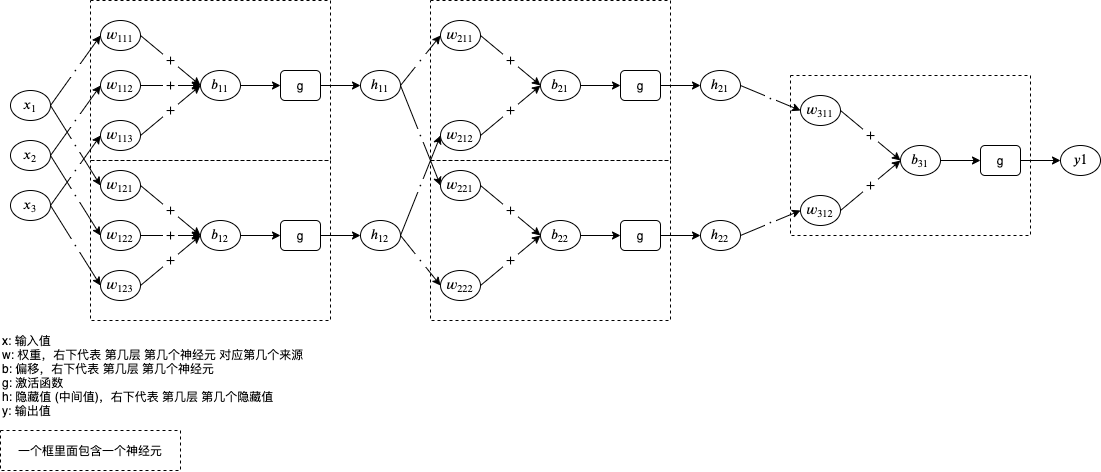
神經元中包含的 w 和 b 就是我們需要通過機器學習調整的引數值,
如果你覺得圖片有點難以理解,可以看轉換后的代碼:
h11 = g(x1 * w111 + x2 * w112 + x3 * w113 + b11)
h12 = g(x1 * w121 + x2 * w122 + x3 * w123 + b12)
h21 = g(h11 * w211 + h12 * w212 + b21)
h22 = g(h11 * w221 + h12 * w222 + b22)
y = g(h21 * w311 + h22 * w312 + b31)
很多癡迷人工神經元網路的學者聲稱人工神經元網路可以模擬人腦的作業方式,做到某些領域上超過人腦的判斷,但實際上這還有很大的爭議,我們可以看到人工神經元的連接方式只會按固定的模式,判斷是否達到閾值并輸出的邏輯也無法做到和生物神經元一樣(目前還沒有解明),并且也沒有生物神經元的不應期,所以也有學者聲稱人工神經元不過只是做了復雜的數學運算來模擬邏輯判斷,需要根據不同的場景切換不同的計算方法,使用這種方式并不能達到人腦的水平,
單層線性模型
在前一篇文章我們已經稍微了解過機器學習框架 pytorch,現在我們來看看怎么使用 pytorch 封裝的線性模型,以下代碼運行在 python 的 REPL 中:
# 匯入 pytorch 類別庫
>>> import torch
# 創建 pytorch 封裝的線性模型,設定輸入有 3 個輸出有 1 個
>>> model = torch.nn.Linear(in_features=3, out_features=1)
# 查看線性模型內部包含的引數串列
# 這里一共包含兩個引數,第一個引數是 1 行 3 列的矩陣分別表示 3 個輸入對應的 w 值 (權重),第二個引數表示 b 值 (偏移)
# 初始值會隨機生成 (使用 kaiming_uniform 生成正態分布)
>>> list(model.parameters())
[Parameter containing:
tensor([[0.0599, 0.1324, 0.0099]], requires_grad=True), Parameter containing:
tensor([-0.2772], requires_grad=True)]
# 定義輸入和輸出
>>> x = torch.tensor([1, 2, 3], dtype=torch.float)
>>> y = torch.tensor([6], dtype=torch.float)
# 把輸入傳給模型
>>> p = model(x)
# 查看預測輸出值
# 1 * 0.0599 + 2 * 0.1324 + 3 * 0.0099 - 0.2772 = 0.0772
>>> p
tensor([0.0772], grad_fn=<AddBackward0>)
# 計算誤差并自動微分
>>> l = (p - y).abs()
>>> l
tensor([5.9228], grad_fn=<AbsBackward>)
>>> l.backward()
# 查看各個引數對應的導函式值
>>> list(model.parameters())[0].grad
tensor([[-1., -2., -3.]])
>>> list(model.parameters())[1].grad
tensor([-1.])
以上可以看作 1 層 1 個神經元,很好理解吧?我們來看看 1 層 2 個神經元:
# 匯入 pytorch 類別庫
>>> import torch
# 創建 pytorch 封裝的線性模型,設定輸入有 3 個輸出有 2 個
>>> model = torch.nn.Linear(in_features=3, out_features=2)
# 查看線性模型內部包含的引數串列
# 這里一共包含兩個引數
# 第一個引數是 2 行 3 列的矩陣分別表示 2 個輸出和 3 個輸入對應的 w 值 (權重)
# 第二個引數表示 2 個輸出對應的 b 值 (偏移)
>>> list(model.parameters())
[Parameter containing:
tensor([[0.1393, 0.5165, 0.2910],
[0.2276, 0.1579, 0.1958]], requires_grad=True), Parameter containing:
tensor([0.2566, 0.1701], requires_grad=True)]
# 定義輸入和輸出
>>> x = torch.tensor([1, 2, 3], dtype=torch.float)
>>> y = torch.tensor([6, -6], dtype=torch.float)
# 把輸入傳給模型
>>> p = model(x)
# 查看預測輸出值
# 1 * 0.1393 + 2 * 0.5165 + 3 * 0.2910 + 0.2566 = 2.3019
# 1 * 0.2276 + 2 * 0.1579 + 3 * 0.1958 + 0.1701 = 1.3009
>>> p
tensor([2.3019, 1.3009], grad_fn=<AddBackward0>)
# 計算誤差并自動微分
# (abs(2.3019 - 6) + abs(1.3009 - -6)) / 2 = 5.4995
>>> l = (p - y).abs().mean()
>>> l
tensor(5.4995, grad_fn=<MeanBackward0>)
>>> l.backward()
# 查看各個引數對應的導函式值
# 因為誤差取了 2 個值的平均,所以求導函式值的時候會除以 2
>>> list(model.parameters())[0].grad
tensor([[-0.5000, -1.0000, -1.5000],
[ 0.5000, 1.0000, 1.5000]])
>>> list(model.parameters())[1].grad
tensor([-0.5000, 0.5000])
現在我們來試試用線性模型來學習符合 x_1 * 1 + x_2 * 2 + x_3 * 3 + 8 = y 的資料,輸入和輸出會使用矩陣定義:
# 參考 pytorch
import torch
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 創建線性模型,設定有 3 個輸入 1 個輸出
model = torch.nn.Linear(in_features=3, out_features=1)
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 隨機生成原始資料集,一共 20 組資料,每條資料有 3 個輸入
dataset_x = torch.randn((20, 3))
dataset_y = dataset_x.mm(torch.tensor([[1], [2], [3]], dtype=torch.float)) + 8
print(f"dataset_x: {dataset_x}")
print(f"dataset_y: {dataset_y}")
# 切分訓練集 (12 組),驗證集 (4 組) 和測驗集 (4 組)
random_indices = torch.randperm(dataset_x.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_x[traning_indices]
traning_set_y = dataset_y[traning_indices]
validating_set_x = dataset_x[validating_indices]
validating_set_y = dataset_y[validating_indices]
testing_set_x = dataset_x[testing_indices]
testing_set_y = dataset_y[testing_indices]
# 開始訓練程序
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
# 計算預測值
# 20 行 3 列的矩陣乘以 3 行 1 列的矩陣 (由 weight 轉置得到) 等于 20 行 1 列的矩陣
predicted = model(traning_set_x)
# 計算損失
loss = loss_function(predicted, traning_set_y)
# 列印除錯資訊
print(f"loss: {loss}, weight: {model.weight}, bias: {model.bias}")
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).abs().mean()
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
# 如果驗證集正確率大于 99 %,則停止訓練
print(f"validating accuracy: {validating_accuracy}")
if validating_accuracy > 0.99:
break
# 檢查測驗集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).abs().mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
輸出結果如下:
dataset_x: tensor([[ 0.8487, 0.6920, -0.3160],
[-2.1152, -0.3561, 0.4372],
[ 0.4913, -0.2041, 0.1198],
[ 1.2377, 1.1168, -0.2473],
[-1.0438, -1.3453, 0.7854],
[ 0.9928, 0.5988, -1.5551],
[-0.3414, 1.8530, 0.4681],
[-0.1577, 1.4437, 0.2660],
[ 1.3894, 1.5863, 0.9463],
[-0.8437, 0.9318, 1.2590],
[ 2.0050, 0.0537, 0.4397],
[ 0.1124, 0.6408, 0.4412],
[-0.2159, -0.7425, 0.5627],
[ 0.2596, 0.5229, 2.3022],
[-1.4689, -1.5867, -0.5692],
[ 0.9200, 1.1108, 1.2899],
[-1.4782, 2.5672, -0.4731],
[ 0.3356, -1.6293, -0.5497],
[-0.4798, -0.4997, -1.0670],
[ 1.1149, -0.1407, 0.8058]])
dataset_y: tensor([[ 9.2847],
[ 6.4842],
[ 8.4426],
[10.7294],
[ 6.6217],
[ 5.5252],
[12.7689],
[11.5278],
[15.4009],
[12.7970],
[11.4315],
[10.7175],
[ 7.9872],
[16.2120],
[ 1.6500],
[15.0112],
[10.2369],
[ 3.4277],
[ 3.3199],
[11.2509]])
epoch: 1
loss: 142.77590942382812, weight: Parameter containing:
tensor([[-0.0043, 0.3097, -0.4752]], requires_grad=True), bias: Parameter containing:
tensor([-0.4249], requires_grad=True)
validating x: tensor([[-0.4798, -0.4997, -1.0670],
[ 0.8487, 0.6920, -0.3160],
[ 0.1124, 0.6408, 0.4412],
[-1.0438, -1.3453, 0.7854]]), y: tensor([[ 3.3199],
[ 9.2847],
[10.7175],
[ 6.6217]]), predicted: tensor([[-0.1385],
[ 0.3020],
[-0.0126],
[-1.1801]], grad_fn=<AddmmBackward>)
validating accuracy: -0.04714548587799072
epoch: 2
loss: 131.40403747558594, weight: Parameter containing:
tensor([[ 0.0675, 0.4937, -0.3163]], requires_grad=True), bias: Parameter containing:
tensor([-0.1970], requires_grad=True)
validating x: tensor([[-0.4798, -0.4997, -1.0670],
[ 0.8487, 0.6920, -0.3160],
[ 0.1124, 0.6408, 0.4412],
[-1.0438, -1.3453, 0.7854]]), y: tensor([[ 3.3199],
[ 9.2847],
[10.7175],
[ 6.6217]]), predicted: tensor([[-0.2023],
[ 0.6518],
[ 0.3935],
[-1.1479]], grad_fn=<AddmmBackward>)
validating accuracy: -0.03184401988983154
epoch: 3
loss: 120.98343658447266, weight: Parameter containing:
tensor([[ 0.1357, 0.6687, -0.1639]], requires_grad=True), bias: Parameter containing:
tensor([0.0221], requires_grad=True)
validating x: tensor([[-0.4798, -0.4997, -1.0670],
[ 0.8487, 0.6920, -0.3160],
[ 0.1124, 0.6408, 0.4412],
[-1.0438, -1.3453, 0.7854]]), y: tensor([[ 3.3199],
[ 9.2847],
[10.7175],
[ 6.6217]]), predicted: tensor([[-0.2622],
[ 0.9860],
[ 0.7824],
[-1.1138]], grad_fn=<AddmmBackward>)
validating accuracy: -0.016991496086120605
省略途中輸出
epoch: 637
loss: 0.001102567883208394, weight: Parameter containing:
tensor([[1.0044, 2.0283, 3.0183]], requires_grad=True), bias: Parameter containing:
tensor([7.9550], requires_grad=True)
validating x: tensor([[-0.4798, -0.4997, -1.0670],
[ 0.8487, 0.6920, -0.3160],
[ 0.1124, 0.6408, 0.4412],
[-1.0438, -1.3453, 0.7854]]), y: tensor([[ 3.3199],
[ 9.2847],
[10.7175],
[ 6.6217]]), predicted: tensor([[ 3.2395],
[ 9.2574],
[10.6993],
[ 6.5488]], grad_fn=<AddmmBackward>)
validating accuracy: 0.9900396466255188
testing x: tensor([[-0.3414, 1.8530, 0.4681],
[-1.4689, -1.5867, -0.5692],
[ 1.1149, -0.1407, 0.8058],
[ 0.3356, -1.6293, -0.5497]]), y: tensor([[12.7689],
[ 1.6500],
[11.2509],
[ 3.4277]]), predicted: tensor([[12.7834],
[ 1.5438],
[11.2217],
[ 3.3285]], grad_fn=<AddmmBackward>)
testing accuracy: 0.9757462739944458
可以看到最終 weight 接近 1, 2, 3,bias 接近 8,和前一篇文章最后的例子比較還可以發現代碼除了定義模型的部分以外幾乎一模一樣 (后面的代碼基本上都是相同的結構,這個系列是先學套路在學細節??) ,
看到這里你可能會覺得,怎么我們一直都在學習一次方程式,不能做更復雜的事情嗎???
如我們看到的,線性模型只能計算一次方程式,如果我們給的資料不滿足任何一次方程式,這個模型將無法學習成功,那么疊加多層線性模型可以學習更復雜的資料嗎?
以下是一層和兩層人工神經元網路的公式例子:

因為我們還沒有學到激活函式,先去掉激活函式,然后展開沒有激活函式的兩層人工神經元網路看看是什么樣子:
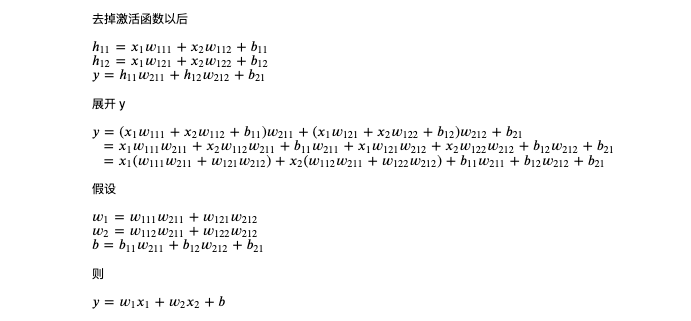
從上圖可以看出,如果沒有激活函式,兩層人工神經元網路和一層神經元網路效果是一樣的,實際上,如果沒有激活函式不管疊加多少層都和一層一樣??,所以如果我們要構建多層網路,必須添加激活函式,
激活函式
激活函式的作用是讓人工神經元網路支持學習非線性的資料,所謂非線性的資料就是不滿足任何一次方程式的資料,輸出和輸入之間不會按一定比例變化,舉個很簡單的例子,如果需要按碼農的數量計算某個專案所需的完工時間,一個碼農需要一個月,兩個碼農需要半個月,三個碼農需要十天,四個碼農需要一個星期,之后無論請多少個碼農都需要一個星期,多出來的碼農只會吃閑飯,使用圖表可以表現如下:
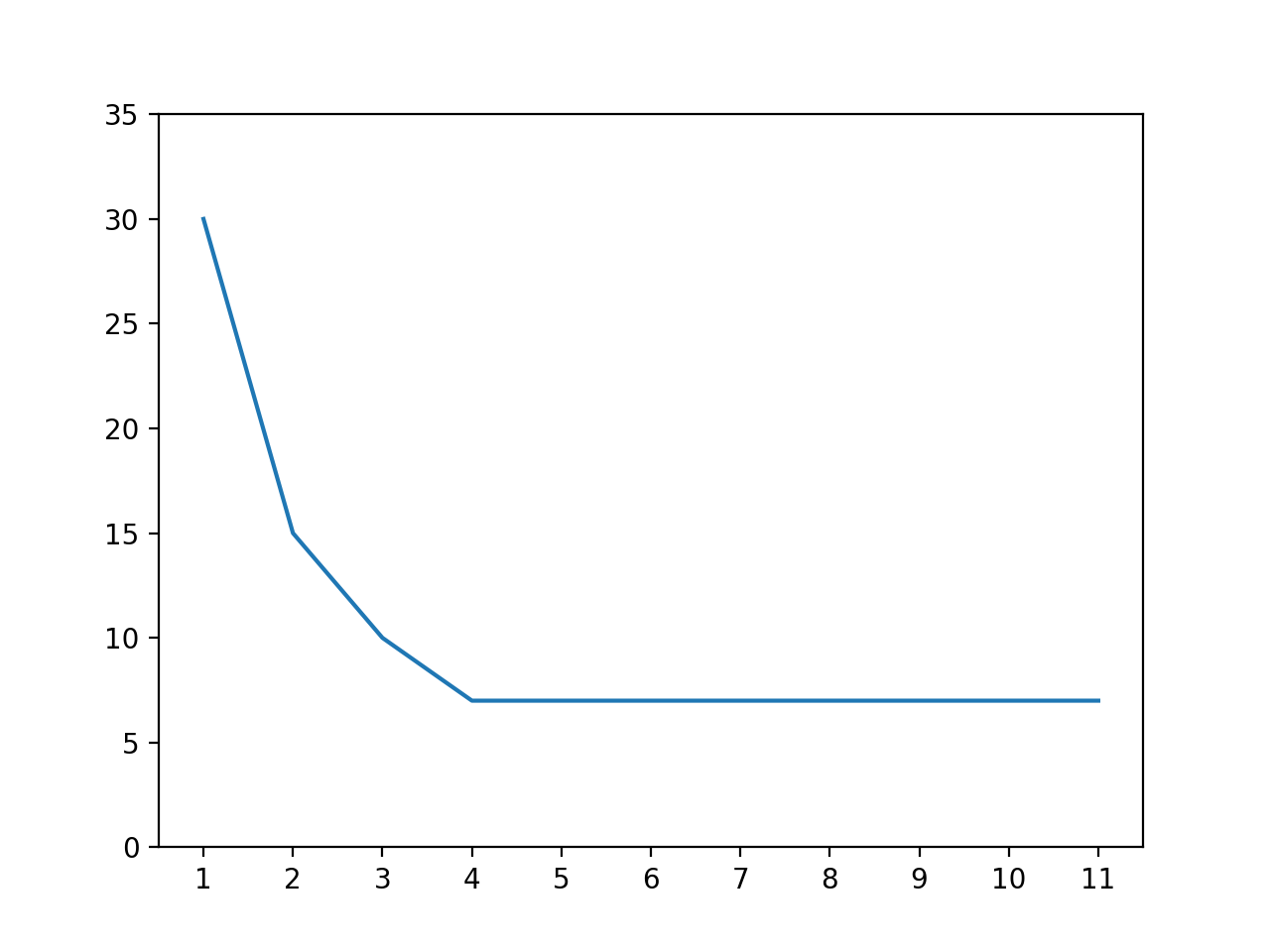
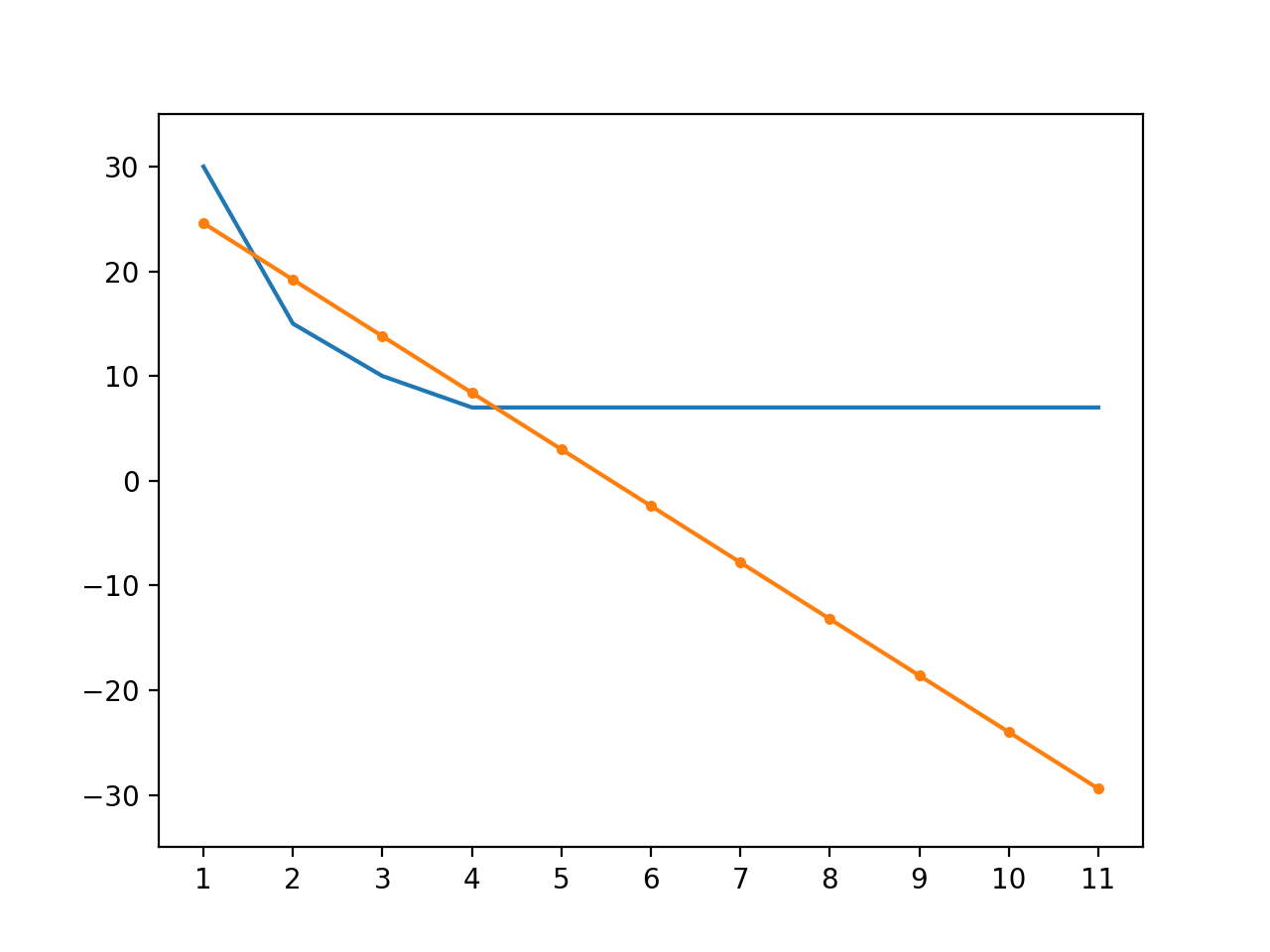
如果不用激活函式,只用線性模型可以調整 w 到 -5.4,b 到 30,使用圖表對比 -5.4 x + 30 和實際資料如下,我們可以看到不僅預測的誤差較大,隨著碼農數量的增長預測所需的完工時間會變為負數??:
那么使用激活函式會怎樣呢?我們以最簡單也是最流行的激活函式 ReLU (Rectified Linear Unit) 為例,ReLU 函式的定義如下:
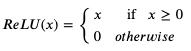
意思是傳入值大于 0 時回傳原值,否則回傳 0,用 python 代碼可以表現如下:
def relu(x):
if x > 0:
return x
return 0
再看看以下結合了 ReLU 激活函式的兩層人工神經元網路 (最后一層不使用激活函式):
試試計算上面的例子:
def relu(x):
if x > 0:
return x
return 0
for x in range(1, 11):
h1 = relu(x * -1 + 2)
h2 = relu(x * -1 + 3)
h3 = relu(x * -1 + 4)
y = h1 * 10 + h2 * 2 + h3 * 3 + 7
print(x, y)
輸入如下,可以看到添加激活函式后模型能夠支持計算上面的非線性資料??:
1 30
2 15
3 10
4 7
5 7
6 7
7 7
8 7
9 7
10 7
激活函式除了上述介紹的 ReLU 還有很多,以下是一些常用的激活函式:

如果你想看它們的曲線和導函式可以參考以下鏈接:
- https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
- https://ml-cheatsheet.readthedocs.io/en/latest/activation_functions.html
添加激活函式以后求導函式值同樣可以使用連鎖律,如果第一層回傳的是正數,那么就和沒有 ReLU 時的計算一樣 (導函式為 1):
>>> w1 = torch.tensor(5.0, requires_grad=True)
>>> b1 = torch.tensor(1.0, requires_grad=True)
>>> w2 = torch.tensor(6.0, requires_grad=True)
>>> b2 = torch.tensor(7.0, requires_grad=True)
>>> x = torch.tensor(2.0)
>>> y = torch.nn.functional.relu(x * w1 + b1) * w2 + b2
# 假設我們要調整 w1, b1, w2, b2 使得 y 接近 0
>>> y
tensor(73., grad_fn=<AddBackward0>)
>>> y.abs().backward()
# w1 的導函式值為 x * w2
>>> w1.grad
tensor(12.)
# b1 的導函式值為 w2
>>> b1.grad
tensor(6.)
# w2 的導函式值為 x * w1 + b1
>>> w2.grad
tensor(11.)
# b1 的導函式值為 1
>>> b2.grad
tensor(1.)
假設第一層回傳的是負數,那么 ReLU 會讓上一層的導函式值為 0 (導函式為 0):
>>> w1 = torch.tensor(5.0, requires_grad=True)
>>> b1 = torch.tensor(1.0, requires_grad=True)
>>> w2 = torch.tensor(6.0, requires_grad=True)
>>> b2 = torch.tensor(7.0, requires_grad=True)
>>> x = torch.tensor(-2.0)
>>> y = torch.nn.functional.relu(x * w1 + b1) * w2 + b2
>>> y
tensor(7., grad_fn=<AddBackward0>)
>>> y.backward()
>>> w1.grad
tensor(-0.)
>>> b1.grad
tensor(0.)
>>> w2.grad
tensor(0.)
>>> b2.grad
tensor(1.)
雖然 ReLU 可以適合大部分場景,但有時候我們還是需要選擇其他激活函式,選擇激活函式一般會考慮以下的因素:
- 計算量
- 是否存在梯度消失 (Vanishing Gradient) 問題
- 是否存在停止學習問題
從上圖我們可以看到 ReLU 的計算量是最少的,Sigmoid 和 Tanh 的計算量則很大,使用計算量大的激活函式會導致學習程序更慢,
而梯度消失 (Vanishing Gradient) 問題則是在人工神經元網路層數增多以后出現的問題,如果層數不斷增多,使用連鎖律求導函式的時候會不斷疊加激活函式的導函式,部分激活函式例如 Sigmoid 和 Tanh 的導函式會隨著疊加次數增多而不斷的減少導函式值,例如有 3 層的時候,第 3 層導函式值可能是 6, -2, 1,第 2 層的導函式值可能是 0.07, 0.68, -0.002,第 1 層的導函式值可能是 0.0004, -0.00016, -0.00003,也就是前面的層引數基本上不會調整,只有后面的層引數不斷變化,導致浪費計算資源和不能完全發揮模型的能力,激活函式 ReLU 則不會存在梯度消失問題,因為不管疊加多少層只要中間不存在負數則導函式值會一直傳遞上去,這也是 ReLU 流行的原因之一,
停止學習問題是模型達到某個狀態 (未學習成功) 以后不管怎么調整引數都不會變化的問題,一個簡單的例子是使用 ReLU 時,如果第一層的輸出剛好全部都是負數,那隱藏值則全部為 0,導函式值也為 0,不管再怎么訓練引數都不會變化,LeakyReLU 與 ELU 則是為了解決停止學習問題產生的,但因為增加計算量和允許負數可能會帶來其他影響,我們一般都會先使用 ReLU,出現停止學習問題再試試 ReLU 的派生函式,
Sigmoid 和 Tanh 雖然有梯度消失問題,但是它們可以用于在指定場景下轉換數值到 0 ~ 1 和 -1 ~ 1,例如 Sigmoid 可以用在最后一層表現可能性,100 表示非常有可能 (轉換到 1),50 也代表非常有可能 (轉換到 1),1 代表比較有可能 (轉換到 0.7311),0 代表不確定 (轉換到 0.5),-1 代表比較不可能 (轉換到 0.2689),-100 代表很不可能 (轉換到 0),而后面文章介紹的 LSTM 模型也會使用 Sigmoid 決定需要忘記哪些內部狀態,Tanh 決定應該怎樣更新內部狀態,此外還有 Softmax 等一般只用在最后一層的函式,Softmax 可以用于在分類的時候判斷哪個類別可能性最大,例如識別貓狗豬的時候最后一層給出 6, 5, 8,數值越大代表屬于該分類的可能性越高,經過 Softmax 轉換以后就是 0.1142, 0.0420, 0.8438,代表有 11.42% 的可能性是貓,4.2% 的可能性是狗,84.38% 的可能性是豬,
多層線性模型
接下來我們看看怎樣在 pytorch 里面定義多層線性模型,上一節已經介紹過 torch.nn.Linear 是 pytorch 中單層線性模型的封裝,組合多個 torch.nn.Linear 就可以實作多層線性模型,
組合 torch.nn.Linear 有兩種方法,一種創建一個自定義的模型類,關于模型類在上一篇已經介紹過:
# 參考 pytorch,nn 等同于 torch.nn
import torch
from torch import nn
# 定義模型
class MyModel(nn.Module):
def __init__(self):
# 初始化基類
super().__init__()
# 定義引數
# 這里一共定義了三層
# 第一層接收 2 個輸入,回傳 32 個隱藏值 (內部 weight 矩陣為 32 行 2 列)
# 第二層接收 32 個隱藏值,回傳 64 個隱藏值 (內部 weight 矩陣為 64 行 32 列)
# 第三層接收 64 個隱藏值,回傳 1 個輸出 (內部 weight 矩陣為 1 行 64 列)
self.layer1 = nn.Linear(in_features=2, out_features=32)
self.layer2 = nn.Linear(in_features=32, out_features=64)
self.layer3 = nn.Linear(in_features=64, out_features=1)
def forward(self, x):
# x 是一個矩陣,行數代表批次,列數代表輸入個數,例如有 50 個批次則為 50 行 2 列
# 計算第一層回傳的隱藏值,例如有 50 個批次則 hidden1 為 50 行 32 列
# 計算矩陣乘法時會轉置 layer1 內部的 weight 矩陣,50 行 2 列乘以 2 行 32 列等于 50 行 32 列
hidden1 = nn.functional.relu(self.layer1(x))
# 計算第二層回傳的隱藏值,例如有 50 個批次則 hidden2 為 50 行 64 列
hidden2 = nn.functional.relu(self.layer2(hidden1))
# 計算第三層回傳的輸出,例如有 50 個批次則 y 為 50 行 1 列
y = self.layer3(hidden2)
# 回傳輸出
return y
# 創建模型實體
model = MyModel()
我們可以定義任意數量的層,但每一層的接收值個數 (in_features) 必須等于上一層的回傳值個數 (out_features),第一層的接收值個數需要等于輸入個數,最后一層的回傳值個數需要等于輸出個數,
第二種方法是使用 torch.nn.Sequential,這種方法更簡便:
# 參考 pytorch,nn 等同于 torch.nn
import torch
from torch import nn
# 創建模型實體,效果等同于第一種方法
model = nn.Sequential(
nn.Linear(in_features=2, out_features=32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=64),
nn.ReLU(),
nn.Linear(in_features=64, out_features=1))
# 注:
# nn.functional.relu(x) 等于 nn.ReLU()(x)
如前面所說的,層數越多隱藏值數量越多模型就越強大,但需要更長的訓練時間并且更容易發生過擬合問題,實際操作時我們可以選擇一個比較小的模型,再按需要增加層數和隱藏值個數,
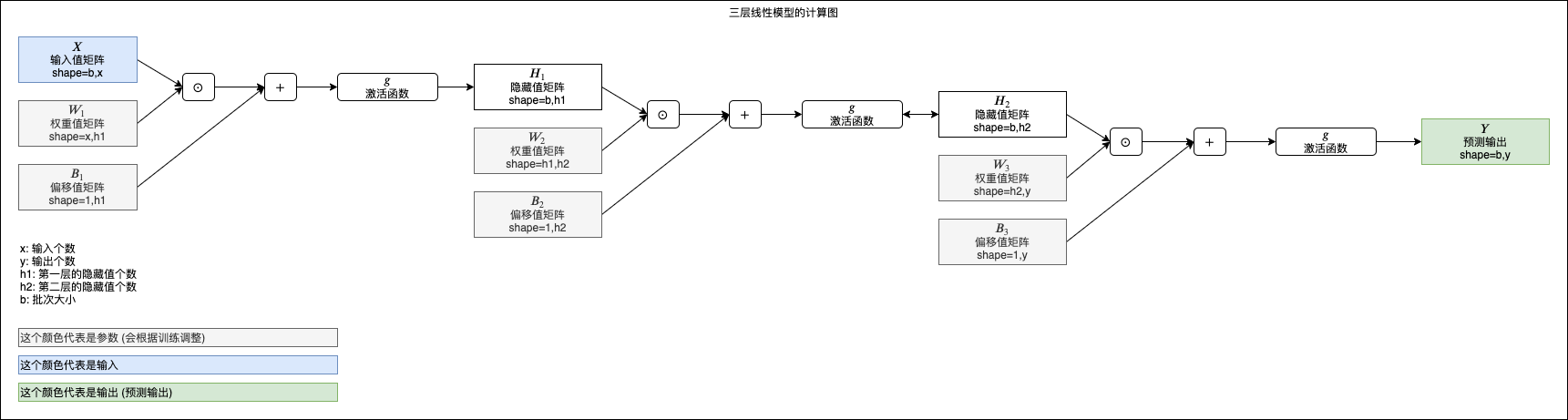
三層線性模型的計算圖可以表現如下,以后這個系列在講解其他模型的時候也會使用相同形式的圖表表示模型的計算路徑:
實體 - 根據碼農條件求工資
我們已經了解到如何創建多層線性模型,現在可以試試解決比較實際的問題了,對于大部分碼農來說最實際的問題就是每個月能拿多少工資??,那就來建立一個根據碼農的條件,預測可以拿到多少工資的模型吧,
以下是從某個地方秘密收集回來的碼農條件和工資資料(其實是按某種規律隨機生成出來的,不是實際資料??):
年齡,性別,作業經驗,Java,NET,JS,CSS,HTML,工資
29,0,0,1,2,2,1,4,12500
22,0,2,2,3,1,2,5,15500
24,0,4,1,2,1,1,2,16000
35,0,6,3,3,0,1,0,19500
45,0,18,0,5,2,0,5,17000
24,0,2,0,0,0,1,1,13500
23,1,2,2,3,1,1,0,10500
41,0,16,2,5,5,2,0,16500
50,0,18,0,5,0,5,2,16500
20,0,0,0,5,2,0,1,12500
26,0,6,1,5,5,1,1,27000
46,0,12,0,5,4,4,2,12500
26,0,6,1,5,3,1,1,23500
40,0,9,0,0,1,0,1,17500
41,0,20,3,5,3,3,5,20500
26,0,4,0,1,2,4,0,18500
42,0,18,5,0,0,2,5,18500
21,0,1,1,0,1,2,0,12000
26,0,1,0,0,0,0,2,12500
完整資料有 50000 條,可以從 https://github.com/303248153/BlogArchive/tree/master/ml-03/salary.csv 下載,
每個碼農有以下條件:
- 年齡
- 性別 (0: 男性, 1: 女性)
- 作業經驗年數 (僅限互聯網行業)
- Java 編碼熟練程度 (0 ~ 5)
- NET 編碼熟練程度 (0 ~ 5)
- JS 編碼熟練程度 (0 ~ 5)
- CSS 編碼熟練程度 (0 ~ 5)
- HTML 編碼熟練程度 (0 ~ 5)
也就是有 8 個輸入,1 個輸出 (工資),我們可以建立三層線性模型:
- 第一層接收 8 個輸入回傳 100 個隱藏值
- 第二層接收 100 個隱藏值回傳 50 個隱藏值
- 第三層接收 50 個隱藏值回傳 1 個輸出
寫成代碼如下 (這里使用了 pandas 類別庫讀取 csv,使用 pip3 install pandas 即可安裝):
# 參考 pytorch 和 pandas
import pandas
import torch
from torch import nn
# 定義模型
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=8, out_features=100)
self.layer2 = nn.Linear(in_features=100, out_features=50)
self.layer3 = nn.Linear(in_features=50, out_features=1)
def forward(self, x):
hidden1 = nn.functional.relu(self.layer1(x))
hidden2 = nn.functional.relu(self.layer2(hidden1))
y = self.layer3(hidden2)
return y
# 給亂數生成器分配一個初始值,使得每次運行都可以生成相同的亂數
# 這是為了讓訓練程序可重現,你也可以選擇不這樣做
torch.random.manual_seed(0)
# 創建模型實體
model = MyModel()
# 創建損失計算器
loss_function = torch.nn.MSELoss()
# 創建引數調整器
optimizer = torch.optim.SGD(model.parameters(), lr=0.0000001)
# 從 csv 讀取原始資料集
df = pandas.read_csv('salary.csv')
dataset_tensor = torch.tensor(df.values, dtype=torch.float)
# 切分訓練集 (60%),驗證集 (20%) 和測驗集 (20%)
random_indices = torch.randperm(dataset_tensor.shape[0])
traning_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
traning_set_x = dataset_tensor[traning_indices][:,:-1]
traning_set_y = dataset_tensor[traning_indices][:,-1:]
validating_set_x = dataset_tensor[validating_indices][:,:-1]
validating_set_y = dataset_tensor[validating_indices][:,-1:]
testing_set_x = dataset_tensor[testing_indices][:,:-1]
testing_set_y = dataset_tensor[testing_indices][:,-1:]
# 開始訓練程序
for epoch in range(1, 1000):
print(f"epoch: {epoch}")
# 根據訓練集訓練并修改引數
# 切換模型到訓練模式,將會啟用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.train()
for batch in range(0, traning_set_x.shape[0], 100):
# 切分批次,一次只計算 100 組資料
batch_x = traning_set_x[batch:batch+100]
batch_y = traning_set_y[batch:batch+100]
# 計算預測值
predicted = model(batch_x)
# 計算損失
loss = loss_function(predicted, batch_y)
# 從損失自動微分求導函式值
loss.backward()
# 使用引數調整器調整引數
optimizer.step()
# 清空導函式值
optimizer.zero_grad()
# 檢查驗證集
# 切換模型到驗證模式,將會禁用自動微分,批次正規化 (BatchNorm) 與 Dropout
model.eval()
predicted = model(validating_set_x)
validating_accuracy = 1 - ((validating_set_y - predicted).abs() / validating_set_y).mean()
print(f"validating x: {validating_set_x}, y: {validating_set_y}, predicted: {predicted}")
print(f"validating accuracy: {validating_accuracy}")
# 檢查測驗集
predicted = model(testing_set_x)
testing_accuracy = 1 - ((testing_set_y - predicted).abs() / testing_set_y).mean()
print(f"testing x: {testing_set_x}, y: {testing_set_y}, predicted: {predicted}")
print(f"testing accuracy: {testing_accuracy}")
# 手動輸入資料預測輸出
while True:
try:
print("enter input:")
r = list(map(float, input().split(",")))
x = torch.tensor(r).view(1, len(r))
print(model(x)[0,0].item())
except Exception as e:
print("error:", e)
輸出如下,可以看到最后沒有參與訓練的驗證集的正確度達到了 93.3% 測驗集的正確度達到了 93.1%,模型成功的摸索出了某種規律:
epoch: 1
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[27604.2578],
[15934.7607],
[14536.8984],
...,
[23678.5547],
[18189.6953],
[29968.8789]], grad_fn=<AddmmBackward>)
validating accuracy: 0.661293625831604
epoch: 2
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[29718.2441],
[15790.3799],
[15312.5791],
...,
[23395.9668],
[18672.0234],
[31012.4062]], grad_fn=<AddmmBackward>)
validating accuracy: 0.6694601774215698
省略途中輸出
epoch: 999
validating x: tensor([[42., 0., 16., ..., 5., 5., 5.],
[28., 0., 0., ..., 4., 0., 0.],
[23., 0., 3., ..., 0., 1., 1.],
...,
[44., 1., 15., ..., 2., 0., 2.],
[30., 0., 1., ..., 1., 1., 2.],
[50., 1., 18., ..., 5., 5., 2.]]), y: tensor([[24500.],
[12500.],
[17500.],
...,
[10500.],
[15000.],
[16000.]]), predicted: tensor([[22978.7656],
[13050.8018],
[18396.5176],
...,
[11449.5059],
[14791.2969],
[16635.2578]], grad_fn=<AddmmBackward>)
validating accuracy: 0.9311849474906921
testing x: tensor([[48., 1., 18., ..., 5., 0., 5.],
[22., 1., 2., ..., 2., 1., 2.],
[24., 0., 1., ..., 3., 2., 0.],
...,
[24., 0., 4., ..., 0., 1., 1.],
[39., 0., 0., ..., 0., 5., 5.],
[36., 0., 5., ..., 3., 0., 3.]]), y: tensor([[14000.],
[10500.],
[13000.],
...,
[15500.],
[12000.],
[19000.]]), predicted: tensor([[15481.9062],
[11011.7266],
[12192.7949],
...,
[16219.3027],
[11074.0420],
[20305.3516]], grad_fn=<AddmmBackward>)
testing accuracy: 0.9330180883407593
enter input:
最后我們手動輸入碼農條件可以得出預測輸出 (35 歲男 10 年經驗 Java 5 NET 2 JS 1 CSS 1 HTML 2 大約可拿 26k ??):
enter input:
35,0,10,5,2,1,1,2
26790.982421875
雖然訓練成功了,但以上代碼還有幾個問題:
- 學習比率設定的非常低 (0.0000001),這是因為我們沒有對資料進行正規化處理
- 總是會固定訓練 1000 次,不能像第一篇文章提到過的那樣自動檢測哪一次的正確度最高,沒有考慮過擬合問題
- 不能把訓練結果保存到硬碟,每次運行都需要從頭訓練
- 需要把所有資料一次性讀取到記憶體中,資料過多時記憶體可能不夠用
- 沒有提供一個使用訓練好的模型的介面
這些問題都會在下篇文章一個個解決,
寫在最后
在這一篇我們終于看到怎樣應用機器學習到更復雜的資料中,但路還有很長??,
下一篇我們會做個稍息,介紹一些訓練程序中使用的技巧 (本來打算寫到這篇里面的,但這篇已經足夠長了),再下一篇介紹可以處理不定長連續資料的遞回模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/33992.html
標籤:其他
上一篇:k8s創建一個service 型別NodePort 報錯 iptables-restore: exit status 1 (iptables-restore:
下一篇:網路基礎 資料的傳輸