Dictum:
?A man who is willing to be a slave, who does not know the power of freedom. -- Beck
??動態規劃(Dynamic Programming, DP)是基于模型的方法,即在給定一個利用MDP描述的完備的環境模型下可以計算出最優策略的優化演算法,
??DP的兩種性質:1.最優子結構:問題的最優解法可以被分為若干個子問題;2.重疊子問題:子問題之間存在遞回關系,解法是可以被重復利用的,在強化學習中,MDP滿足兩個性質,DP的關鍵思想就是利用價值函陣列織并結構化對好的策略的搜索,
策略評估
??策略評估(Policy Evaluation)也被稱為“預測問題”,就是計算任意一個隨機策略\(\pi\)的狀態價值函式\(v_\pi\)的問題,
??在MDP中,由公式\((2.11)\)最終得到了狀態價值函式的貝爾曼方程:\(v_ \pi(s)=\displaystyle \sum_a\pi(a|s) \sum_{s^\prime.r} p(s^\prime,r|s,a) [r+\gamma v_\pi(s^\prime)]\),該方程可以通過迭代法求解,方法如下:
??1.將狀態價值函式序列記為\(\left\{ v_0,v_1,...,v_k\right\}\)
??2.\(v_0\)作為初始狀態價值函式,任意取值(在終止狀態時,取值必須為0)
??3.通過下面的公式進行迭代$$v_{k+1}=\displaystyle \sum_a\pi(a|s) \sum_{s^\prime.r} p(s^\prime,r|s,a) [r+\gamma v_k(s^\prime)] \tag{3.1}$$
??序列\(\left\{v_k\right\}\)在\(k \rightarrow \infty\)時將收斂于\(v_\pi\),該方法需要兩個陣列:一個用于存盤舊的\(v_k(s)\),另一個用于存盤新的\(v_{k+1}(s)\),也可以每次直接用新狀態價值函式替換舊狀態價值函式,這就是"in-place"更新,
價值迭代
??上述的策略評估方法是一個多次遍歷狀態集合的迭代程序,因此,可以通過價值迭代(Value Iteration)來縮短策略評估的步驟,公式如下:
\[\begin{aligned} v_{k+1}(s) & \doteq \max_a \mathbb{E}[R_{t+1}+ \gamma v_k(S_{t+1}|S_t=s,A_t=a)] \\ &=\max_a \displaystyle \sum_{s^\prime,r}p(s^\prime,r|s,a)[r+\gamma v_k(s^\prime)] \end{aligned} \tag{3.2} \]
??通過公式\((3.2)\)可以在一次遍歷后立即停止策略評估,只需要對每個狀態更新一次,從而提升計算效率,
策略改進
??通過策略評估得出策略的狀態價值函式,可以根據策略改進定理(policy improvement theorem)選擇出貪心策略:
對于任意兩個確定策略\(\pi\)和\(\pi^\prime\),\(\forall s \in \mathcal{S},q_\pi(s,\pi^\prime(s)) \geq v_\pi(s)\),則策略\(\pi^\prime\)不劣于\(\pi\),
??在這種情況下,\(v_{\pi^\prime}(s) \geq v_\pi(s)\),證明程序如下
\[\begin{aligned} v_{\pi}(s) & \leq q_{\pi}\left(s, \pi^{\prime}(s)\right) \\ &=\mathbb{E}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) | S_{t}=s, A_{t}=\pi^{\prime}(a)\right] \\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) | S_{t}=s\right] \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma q_{\pi}\left(S_{t+1}, \pi^{\prime}\left(S_{t+1}\right)\right) | S_{t}=s\right] \\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma \mathbb{E}_{\pi^{\prime}}\left[R_{t+2}+\gamma v_{\pi}\left(S_{t+2}\right)\right] | S_{t}=s\right] \\ &=\mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} v_{\pi}\left(S_{t+2}\right) | S_{t}=s\right] \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} v_{\pi}\left(S_{t+3}\right) | S_{t}=s\right] \\ & \qquad \vdots \\ & \leq \mathbb{E}_{\pi^{\prime}}\left[R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\gamma^{3} R_{t+4}+\cdots | S_{t}=s\right] \\ &=v_{\pi^{\prime}}(s) \end{aligned} \tag{3.3} \]
??由此,可以推出貪心策略\(\pi^\prime\),滿足
\[\begin{aligned} \pi^{\prime}(s) & \doteq \underset{a}{\arg \max } q_{\pi}(s, a) \\ &=\underset{a}{\operatorname{argmax}} \mathbb{E}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) | S_{t}=s, A_{t}=a\right] \\ &=\underset{a}{\operatorname{argmax}} \sum_{s^{\prime}, r} p\left(s^{\prime}, r | s, a\right)\left[r+\gamma v_{\pi}\left(s^{\prime}\right)\right] \end{aligned} \tag{3.4} \]
??同時,可以寫出它的狀態價值函式:
\[\begin{aligned} v_{\pi^{\prime}}(s) &=\max _{a} \mathbb{E}\left[R_{t+1}+\gamma v_{\pi^{\prime}}\left(S_{t+1}\right) | S_{t}=s, A_{t}=a\right] \\ &=\max _{a} \sum_{s^{\prime}, r} p\left(s^{\prime}, r | s, a\right)\left[r+\gamma v_{\pi^{\prime}}\left(s^{\prime}\right)\right] \\ &=v_*(s) \end{aligned} \tag{3.5} \]
策略迭代
??通過下面的鏈式方法,可以得到一個不斷改進的策略和狀態價值函式的序列:
\[\pi_{0} \stackrel{E}{\longrightarrow} v_{\pi_{0}} \stackrel{I}{\longrightarrow} \pi_{1} \stackrel{E}{\longrightarrow} v_{\pi_{1}} \stackrel{I}{\longrightarrow} \pi_{2} \stackrel{E}{\longrightarrow} \cdots \stackrel{I}{\longrightarrow} \pi_{*} \stackrel{E}{\longrightarrow} v_{*} \]
??\(\stackrel{E}{\longrightarrow}\)表示策略評估,\(\stackrel{I}{\longrightarrow}\)表示策略改進,每一次的策略評估都是一個迭代計算的程序,需要基于前一個策略的狀態價值函式開始計算,
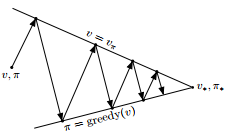 由上圖可知,策略迭代(Policy Iteration)是通過策略評估和策略改進不斷互動,使策略和狀態價值函式最終收斂為最優,
由上圖可知,策略迭代(Policy Iteration)是通過策略評估和策略改進不斷互動,使策略和狀態價值函式最終收斂為最優,
異步動態規劃
??上述的都是同步動態規劃(synchronous dynamic programming),它們的缺點是需要對MDP的整個狀態集進行遍歷,異步動態規劃(Asynchronous Dynamic Programming)使使用任意可用的狀態值,以任意規則進行更新,為了確保能夠正確收斂,異步動態規劃必須不斷更新所有狀態的值,
References
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction (Second Edition). Cambridge, Massachusetts London, England : The MIT Press, 2018.
Csaba Szepesvári, ‘Algorithms for Reinforcement Learning’, Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 4, no. 1, pp. 1–103, Jan. 2010, doi: 10.2200/S00268ED1V01Y201005AIM009.
UCL Reinforcement Learning Course by David Silver:https://www.bilibili.com/video/BV1b7411y7ax
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/33996.html
標籤:其他
下一篇:云速建站沒有備案授權碼