代碼倉庫: https://github.com/brandonlyg/cute-dl
(轉載請注明出處!)
目標
- 增加學習率優化器, 加快模型在小學習率下模型的訓練速度,
- 使用MNIST資料集比較同一個模型使用不同學習率優化器的表現,
常見的學習率優化演算法
在上個階段,我們使用固定學習率優化器訓練識別MNIST手寫數字模型,在后面的示例中將會看到: 如果學習習設定太大,模型將無法收斂; 如果設定學習率太小模型大概率會收斂速度會非常緩慢,因此必須要要給學習率設定一個合適的值,這個合適的值到底是什么需要反復試驗,
訓練模型的本質是,在由損失函式定義的高緯超平面中盡可能地找到最低點,由于高緯超平面十分復雜,找到全域最低點往往不現實,因此找到一個盡量接近全域最低點的區域最低點也是可以的,
由于模型引數是隨機初始化的,在訓練的初始階段, 可能遠離最低點,也可能距最低點較較近,為了使模型能夠收斂,較小的學習率比較大的學習率更有可能達到目地, 至少不會使模型發散,
理想的狀態下,我們希望,學習率是動態的: 在遠離最低點的時候有較大的學習率,在靠近最低點的時候有較小的學習率,
學習率演算法在訓練程序中動態調整學習率,試圖使學習率接近理想狀態,常見的學習率優化演算法有:
- 動量演算法,
- Adagrad演算法,
- RMSProp演算法,
- Adadelta演算法,
- Adam演算法,
目前沒有一種理論能夠給出定量的結論斷言一種演算法比另一種更好,具體選用哪種演算法視具體情況而定,
接下來將會詳細討論每種演算法的數學性質及實作,為了方便討論,先給出一些統一的定義:
- 模型經歷一次向前傳播和一次反向傳播稱訓練稱為一次迭代,用t表示模型當前的迭代次數,t=0,1,2,..., 當t=0是表示模型處于初始狀態,
- g表示反向傳播的梯度, \(g_t\)是第t次迭的梯度,其他量的表示方式和g相同,
- w表示模型學習的引數,α表示學習率超引數,
- 符號a ⊙ v如果a和v都是向量, a, v必須有相同的維度a ⊙ v表示他們相同位置上的元素相乘,結果是和a,v具有相同維度的向量. 如果a是標量v是向量a ⊙ v表示向量的標量乘法等價于av,
動量演算法
數學原理
\[\begin{matrix} v_t = v_{t-1}γ + αg_t \\ w = w - v_t\\ \end{matrix} \]
其中v是動量\(v_0=0\), γ是動量的衰減率\(γ∈(0,1)\). 現在把\(v_t\)展開看一下\(g_i, i=1,2,...t\)對v_t的影響.
\[v_t = α(γ^{t-1}g_1 + γ^{t-2}g_2 + ... + γg_{t-1} + g_t) \]
個項系數之和的極限情況:
\[\lim_{t \to ∞} \sum_{i=1}^t γ^{t-i} = \frac{1}{1-γ} \]
令\(t=\frac{1}{1-γ}\)則有\(\frac{1}{t}=1-γ\), \(g_i\)的指數加權平均值可用下式表示:
\[\bar v_t = \frac{1}{t}(γ^{t-1}g_1 + γ^{t-2}g_2 + ... + γg_{t-1} + g_t) = (1-γ)(γ^{t-1}g_1 + γ^{t-2}g_2 + ... + γg_{t-1} + g_t) \]
如果把學習率α表示為:\(α=\frac{α}{1-γ}(1-γ)\),因此\(v_t\)可以看成是最近的\(1-γ\)次迭代梯度的指數加權平均乘以一個縮放量\(\frac{α}{1-γ}\), 這里的縮放量\(\frac{α}{1-γ}\)才是真正的學習率引數,
設\(\frac{1}{1-γ}=n\), 最近n次迭代梯度的權重占總權重的比例為:
\[(\sum_{i=1}^{n} γ^i) / \frac{1}{1-γ} = \frac{\frac{1-γ^n}{1-γ}}{\frac{1}{1-γ}} = 1-γ^n = 1 - γ^{\frac{1}{1-γ}} \]
當γ=0.9時, \(1 - γ^{10}≈0.651\), 就是說, 這個時候, 最近的10次迭代占總權重的比例約為65.1%, 換言之\(v_t\)的值的數量級由最近10次迭代權重值決定,
當我們設定超引數γ,α時, 可以認為取了最近\(\frac{1}{1-γ}\)次迭代梯度的指數加權平均值為動量積累量,然后對這個積累量作\(\frac{α}{1-γ}\)倍的縮放, 例如: γ=0.9, α=0.01, 表示取最近10次的加權平均值,然后將這個值縮小到原來的0.1倍,
動量演算法能夠有效地緩解\(g_t \to 0\)時引數更新緩慢的問題和當\(g_t\)很大時引數更新幅度過大的問題,
比較原始的梯度下降演算法和使用動量的梯度下降演算法更新引數的情況:
\[\begin{matrix} w = w - αg_t & (1) & 原始梯度下降演算法 \\ w = w - v_t & (2) & 動量演算法 \end{matrix} \]
\(g_t \to 0\)時, 有3種可能:
- 當前位置是超平面的一個全域最低點,是期望的理想收斂位置,(1)式會停止更新引數, (2)式會使引數在這個位置周圍以越來越小的幅度震蕩, 最終收斂到這個位置,
- 當前位置是超平面的一個區域最低點,(1)式會停留在這個位置, 最終學習到一個不理想的引數,(2)式中\(v_t\)由于積累了最近n步的勢能, 會沖過這個區域, 繼續尋找更優解,
- 當前位置是超平面的一個鞍點, (1)式會停留在這個位置, 最終學習到一個不可用的引數,(2)式中\(v_t\)由于記錄了最近n步的勢能, 會沖過這個區域, 繼續尋找更優解
當\(g_t\)很大時(1)式導致引數大幅度的更新, 會大概率導致模型發散,(2)式當γ=0.9時, \(g_t\)對\(v_t\)的影響權重是0.1; 式當γ=0.99時,\(g_t\)對\(v_t\)的影響權重是0.01, 相比于\(g_{t-1}\)到\(g_t\)的增加幅度, \(v_{t-1}\)到\(v_t\)增加幅度要小的多, 引數更新也會平滑許多,
實作
檔案: cutedl/optimizers.py, 類名:Momentum.
def update_param(self, param):
#pdb.set_trace()
if not hasattr(param, 'momentum'):
#為引數添加動量屬性
param.momentum = np.zeros(param.value.shape)
param.momentum = param.momentum * self.__dpr + param.gradient * self.__lr
param.value -= param.momentum
Adagrad演算法
數學原理
\[\begin{matrix} s_t = s_{t-1} + g_t ⊙ g_t \\ Δw_t = \frac{α}{\sqrt{s_t} + ε} ⊙ g_t \\ w = w - Δw_t \end{matrix} \]
其中\(s_t\)是梯度平方的積累量, \(ε=10^{-6}\)用來保持數值的穩定, Δw_t是引數的變化量,\(s_t\)的每個元素都是正數, 隨著迭代次數增加, 數值會越來越大,相應地\(\frac{α}{\sqrt{s_t} + ε}\)的值會越來越小,\(\frac{α}{\sqrt{s_t} + ε}\)相當于為\(g_t\)中的每個元素計算獨立的的學習率, 使\(Δw_t\)中的每個元素位于(-1, 1)區間內,隨著訓練次數的增加會向0收斂,這意味著\(||Δw_t||\)會越來越小, 迭代次數比較大時, \(||Δw_t|| \to 0\), 引數w將不會有更新,相比于動量演算法, Adagrad演算法調整學習率的方向比較單一, 只會往更小的方向上調整,α不能設定較大的值, 因為在訓練初期\(s_t\)的值會很小, \(\frac{α}{\sqrt{s_t} + ε}\)會放大α的值, 導致較大的學習率,從而導致模型發散,
實作
檔案: cutedl/optimizers.py, 類名:Adagrad.
def update_param(self, param):
#pdb.set_trace()
if not hasattr(param, 'adagrad'):
#添加積累量屬性
param.adagrad = np.zeros(param.value.shape)
a = 1e-6
param.adagrad += param.gradient ** 2
grad = self.__lr/(np.sqrt(param.adagrad) + a) * param.gradient
param.value -= grad
RMSProp演算法
數學原理
為了克服Adagrad積累量不斷增加導致學習率會趨近于0的缺陷, RMSProp演算法的設計在Adagrad的基礎上引入了動量思想,
\[\begin{matrix} s_t = s_{t-1}γ + g_t ⊙ g_t(1-γ) \\ Δw_t = \frac{α}{\sqrt{s_t} + ε} ⊙ g_t \\ w = w - Δw_t \end{matrix} \]
演算法設計者給出的推薦引數是γ=0.99, 即\(s_t\)是最近100次迭代梯度平方的積累量, 由于計算變化量時使用的是\(\sqrt{s_t}\), 對變化量的影響只相當于最近10次的梯度積累量,
的Adagrad類似, \(s_t\)對\(g_t\)的方向影響較小, 但對\(||g_t||\)大小影響較大,會把它縮小到(-1, 1)區間內, 不同的是不會單調地把\(||g_t||\)收斂到0, 從而克服了Adagrad的缺陷,
實作
檔案: cutedl/optimizers.py, 類名:RMSProp.
def update_param(self, param):
#pdb.set_trace()
if not hasattr(param, 'rmsprop_storeup'):
#添加積累量屬性
param.rmsprop_storeup = np.zeros(param.value.shape)
a = 1e-6
param.rmsprop_storeup = param.rmsprop_storeup * self.__sdpr + (param.gradient**2) * (1-self.__sdpr)
grad = self.__lr/(np.sqrt(param.rmsprop_storeup) + a) * param.gradient
param.value -= grad
Adadelta演算法
數學原理
這個演算法的最大特點是不需要全域學習率超引數, 它也引入了動量思想,使用變化量平方的積累量和梯度平方的積累量共同為\(g_t\)的每個元素計算獨立的學習率,
\[\begin{matrix} s_t = s_{t-1}γ + g_t ⊙ g_t(1-γ) \\ Δw_t = \frac{\sqrt{d_{t-1}} + ε}{\sqrt{s_t} + ε} ⊙ g_t \\ d_t = d_{t-1}γ + Δw_t ⊙ Δw_t(1-γ)\\ w = w - Δw_t \end{matrix} \]
這個演算法引入了新的量\(d_t\), 是變化量平方的積累量, 表示最近n次迭代的引數變化量平方的加權平均. \(ε=10^{-6}\). 推薦的超引數值是γ=0.99,這個演算法和RMSProp類似, 只是用\(\sqrt{d_{t-1}}\)代替了學習率超引數α,
實作
檔案: cutedl/optimizers.py, 類名:Adadelta.
def update_param(self, param):
#pdb.set_trace()
if not hasattr(param, 'adadelta_storeup'):
#添加積累量屬性
param.adadelta_storeup = np.zeros(param.value.shape)
if not hasattr(param, "adadelta_predelta"):
#添加上步的變化量屬性
param.adadelta_predelta = np.zeros(param.value.shape)
a = 1e-6
param.adadelta_storeup = param.adadelta_storeup * self.__dpr + (param.gradient**2)*(1-self.__dpr)
grad = (np.sqrt(param.adadelta_predelta)+a)/(np.sqrt(param.adadelta_storeup)+a) * param.gradient
param.adadelta_predelta = param.adadelta_predelta * self.__dpr + (grad**2)*(1-self.__dpr)
param.value -= grad
Adam演算法
數學原理
前面討論的Adagrad, RMSProp和Adadetal演算法, 他們使用的加權平均積累量對\(g_t\)的范數影響較大, 對\(g_t\)的方向影響較小, 另外它們也不能緩解\(g_t \to 0\)的情況,Adam演算法同時引入梯度動量和梯度平方動量,理論上可以克服前面三種演算法共有的缺陷的缺陷,
\[\begin{matrix} v_t = v_{t-1}γ_1 + g_t(1-γ_1) \\ s_t = s_{t-1}γ_2 + g_t ⊙ g_t(1-γ_2) \\ \hat{v_t} = \frac{v_t}{1 - γ_1^t} \\ \hat{s_t} = \frac{s_t}{1 - γ_2^t} \\ Δw_t = \frac{α\hat{v_t}}{\sqrt{s_t} + ε} \\ w = w - Δw_t \end{matrix} \]
其中\(v_t\)和動量演算法中的\(v_t\)含義一樣,\(s_t\)和RMSProp演算法的\(s_t\)含義一樣, 對應的超引數也有一樣的推薦值\(γ_1=0.9\), \(γ_2=0.99\),用于穩定數值的\(ε=10^{-8}\). 比較特別的是\(\hat{v_t}\)和\(\hat{s_t}\), 他們是對\(v_t\)和\(s_t\)的一個修正,以\(\hat{v_t}\)為例, 當t比較小的時候, \(\hat{v_t}\)近似于最近\(\frac{1}{1-γ}\)次迭代梯度的加權和而不是加權平均, 當t比較大時, \(1-γ^t \to 1\), 從而使\(\hat{v_t} \to v_t\),也就是所\(\hat{v_t}\)時對對迭代次數較少時\(v_t\)值的修正, 防止在模型訓練的開始階段產生太小的學習率,\(\hat{s_t}\)的作用和\(\hat{v_t}\)是類似的,
實作
檔案: cutedl/optimizers.py, 類名:Adam.
def update_param(self, param):
#pdb.set_trace()
if not hasattr(param, 'adam_momentum'):
#添加動量屬性
param.adam_momentum = np.zeros(param.value.shape)
if not hasattr(param, 'adam_mdpr_t'):
#mdpr的t次方
param.adam_mdpr_t = 1
if not hasattr(param, 'adam_storeup'):
#添加積累量屬性
param.adam_storeup = np.zeros(param.value.shape)
if not hasattr(param, 'adam_sdpr_t'):
#動量sdpr的t次方
param.adam_sdpr_t = 1
a = 1e-8
#計算動量
param.adam_momentum = param.adam_momentum * self.__mdpr + param.gradient * (1-self.__mdpr)
#偏差修正
param.adam_mdpr_t *= self.__mdpr
momentum = param.adam_momentum/(1-param.adam_mdpr_t)
#計算積累量
param.adam_storeup = param.adam_storeup * self.__sdpr + (param.gradient**2) * (1-self.__sdpr)
#偏差修正
param.adam_sdpr_t *= self.__sdpr
storeup = param.adam_storeup/(1-param.adam_sdpr_t)
grad = self.__lr * momentum/(np.sqrt(storeup)+a)
param.value -= grad
不同學習率對訓練模型的影響
接下來我們仍然使用上個階段的模型做為示例, 使用不同的優化演算法訓練模型,對比差別,代碼在examples/mlp/mnist-recognize.py中
代碼中有兩個結束訓練的條件:
- 連續20次驗證沒有得到更小的驗證誤差,表示模型模型已經無法進一步優化或者已經開始發散了,結束訓練,
- 連續20次驗證模型驗證正確率都在91%以上,表示模型性能已經達到預期目標且是收斂的,結束訓練,
不使用優化演算法的情況
使用較小的學習率
def fit0():
lr = 0.0001
print("fit1 lr:", lr)
fit('0.png', optimizers.Fixed(lr))
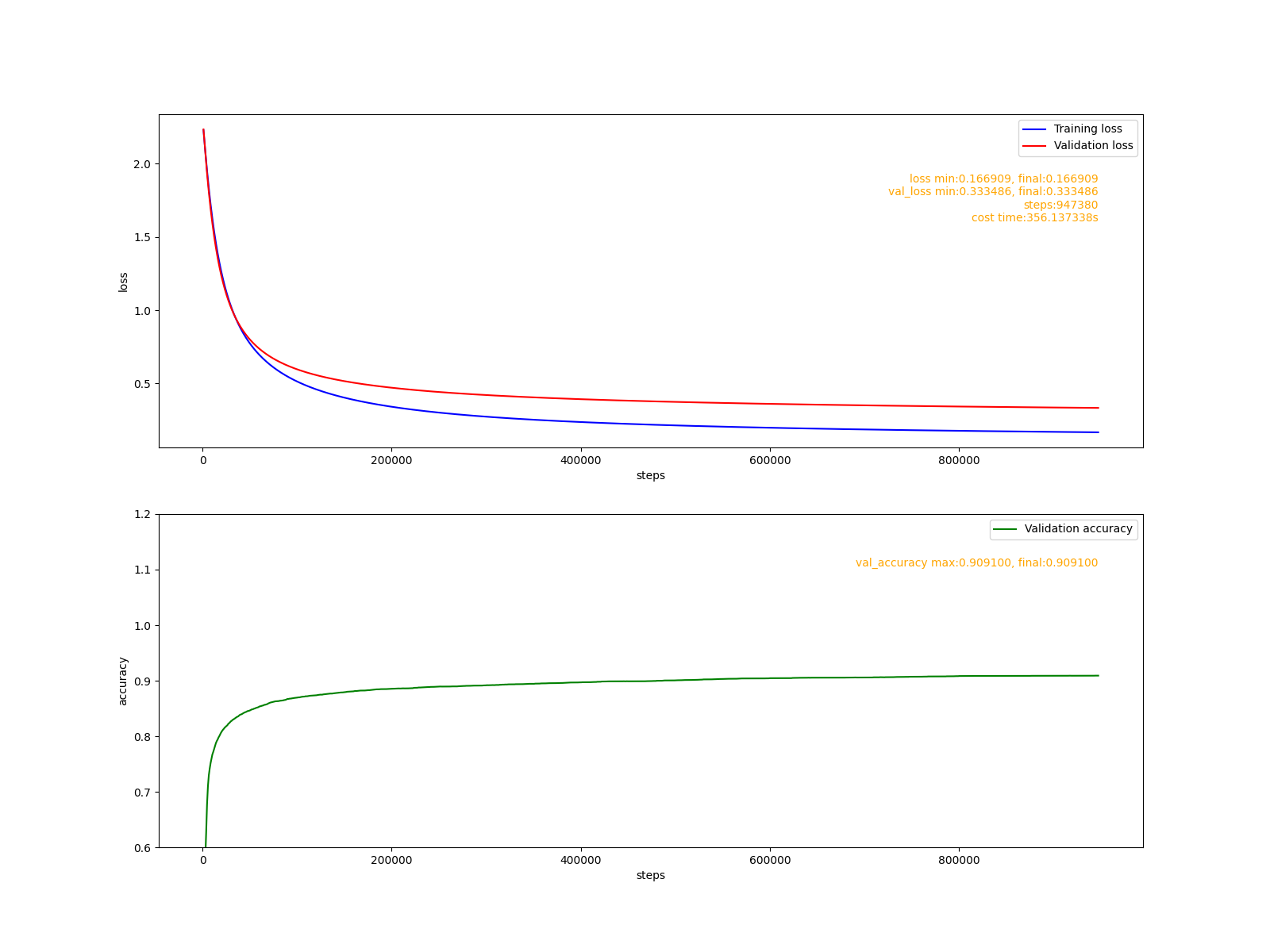
較小的固定學習率0.0001可以使模型穩定地收斂,但收斂速度很慢, 訓練接近100萬步, 最后由于收斂速度太慢而停止訓練,
使用較大的學習率
def fit1():
lr = 0.2
print("fit0 lr:", lr)
fit('1.png', optimizers.Fixed(lr))
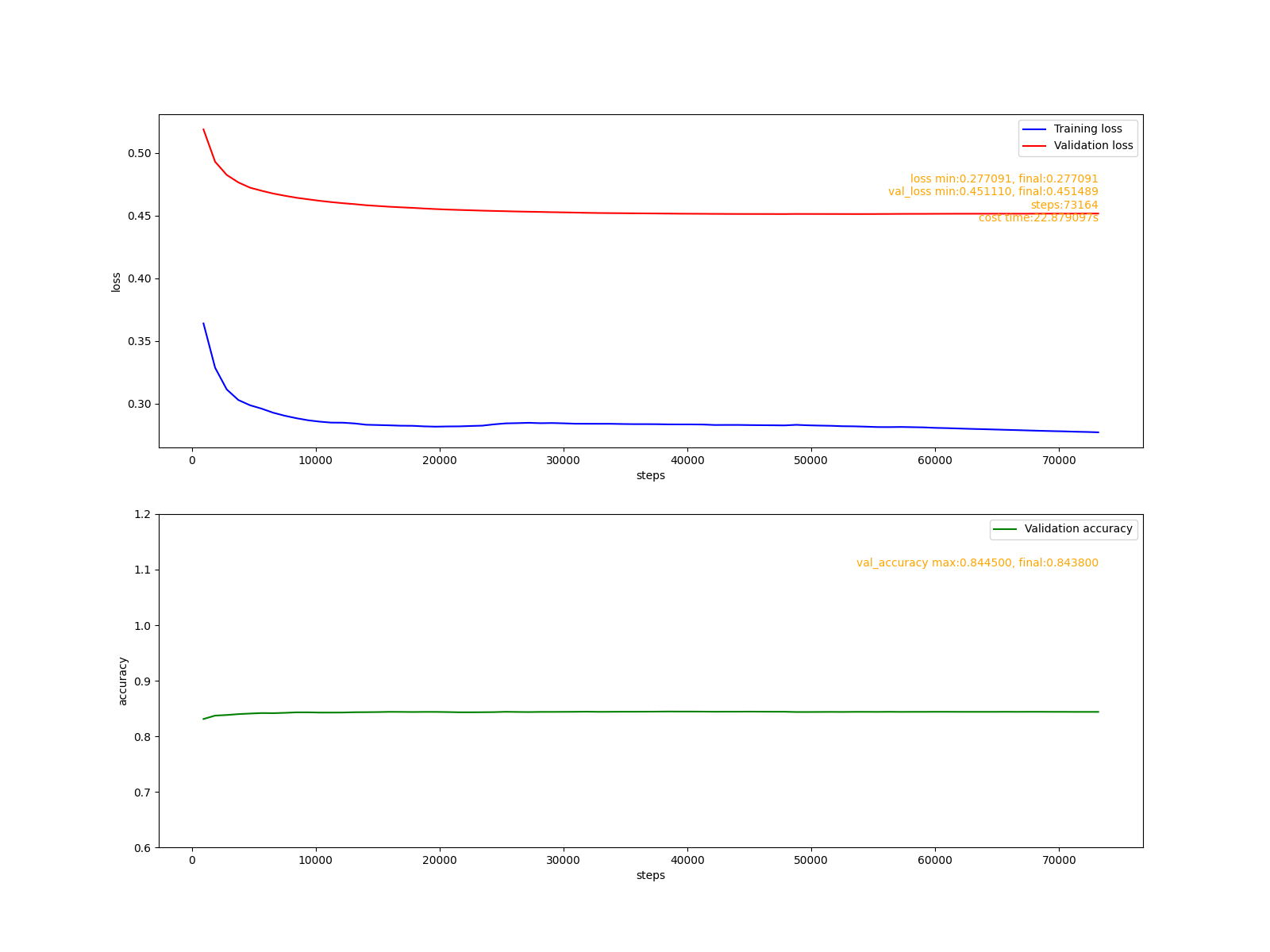
較大的固定學習率0.2, 模型在訓練7萬步左右的時候因發散而停止訓練,模型進度開始降低: 最大驗證正確率為:0.8445, 結束時的驗證正確率為:0.8438.
適當的學習率
def fit2():
lr = 0.01
print("fit2 lr:", lr)
fit('2.png', optimizers.Fixed(lr))
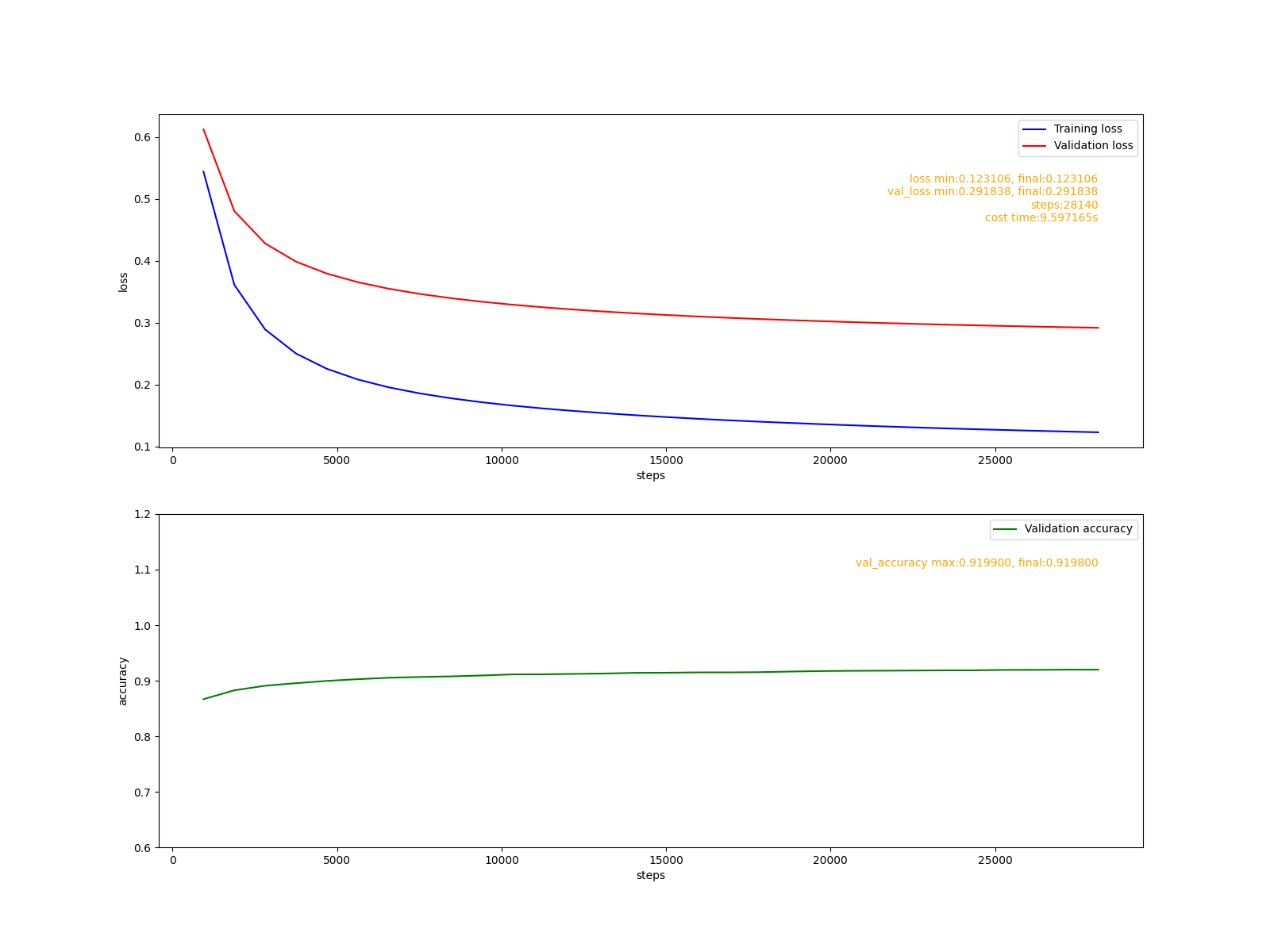
通過多次試驗, 找到了一個合適的學習率0.01, 這時模型只需訓練28000步左右即可達到期望性能,
動量演算法優化器
def fit_use_momentum():
lr = 0.002
dpr = 0.9
print("fit_use_momentum lr=%f, dpr:%f"%(lr, dpr))
fit('momentum.png', optimizers.Momentum(lr, dpr))
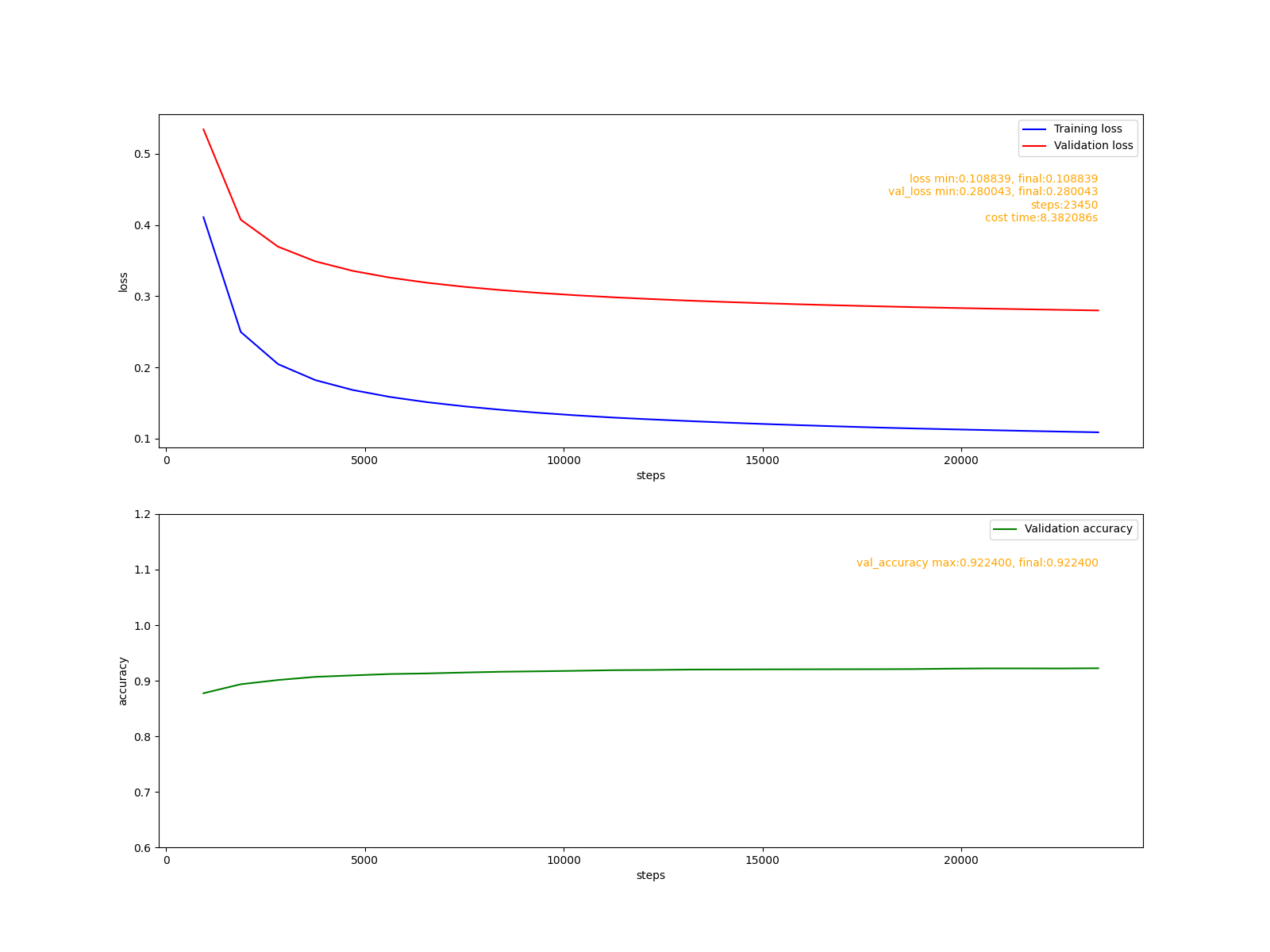
這里的真實學習率為\(\frac{0.002}{1-0.9} = 0.02\),模型訓練23000步左右即可達到期望性能,這里的學習率稍大,證明動量演算法可以適應稍大學習率的數學性質,
Adagrad演算法優化器
def fit_use_adagrad():
lr = 0.001
print("fit_use_adagrad lr=%f"%lr)
fit('adagrad.png', optimizers.Adagrad(lr))
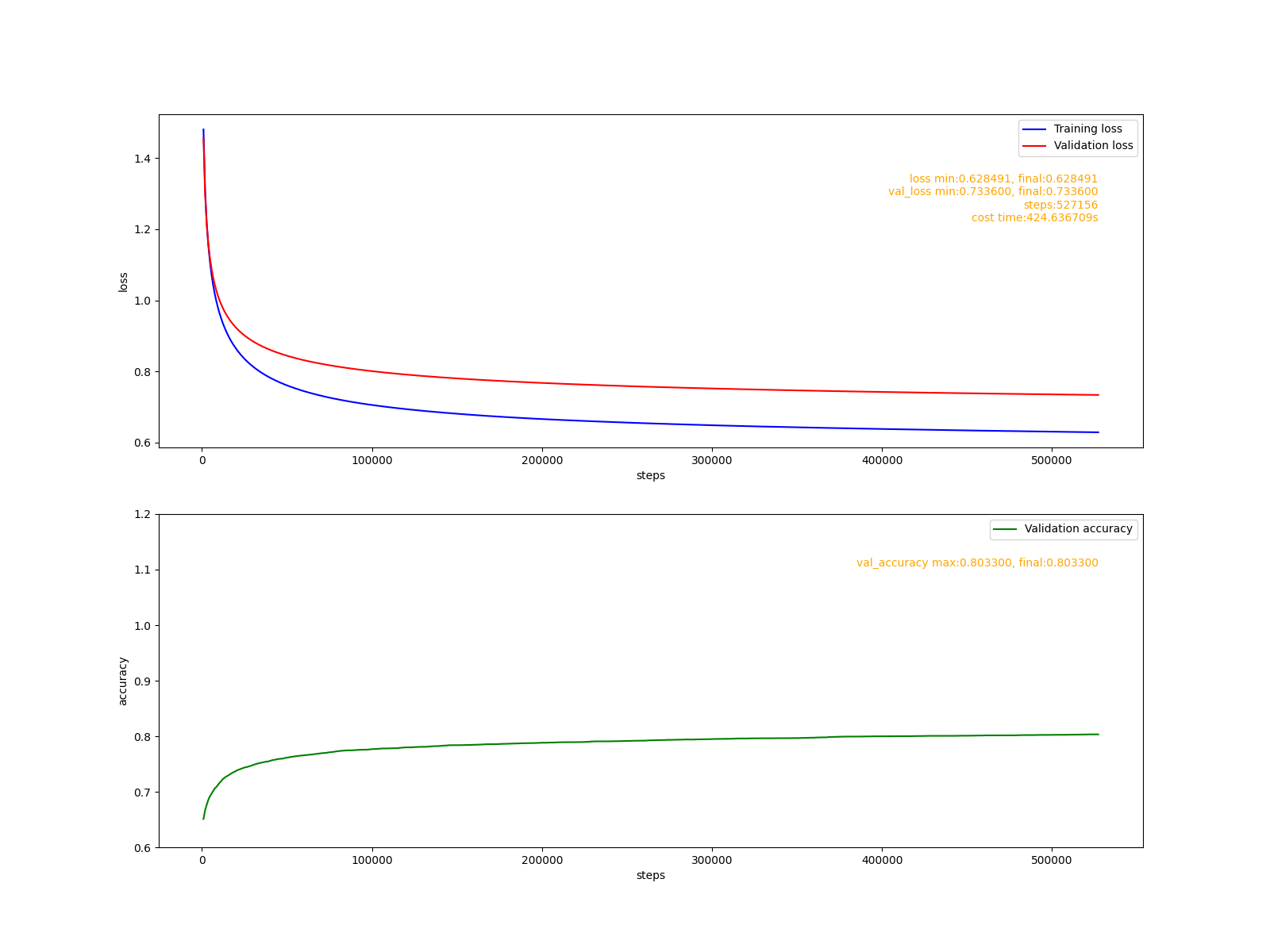
多次試驗表明,Adagrad演算法的引數最不好調,由于這個演算法的學習率會一直單調遞減, 它只能對模型進行小幅度的優化, 故而這個演算法并不適合從頭開始訓練模型,比較適合對預訓練的模型引數進行微調,
RMSProp演算法優化器
def fit_use_rmsprop():
sdpr = 0.99
lr=0.0001
print("fit_use_rmsprop lr=%f sdpr=%f"%(lr, sdpr))
fit('rmsprop.png', optimizers.RMSProp(lr, sdpr))
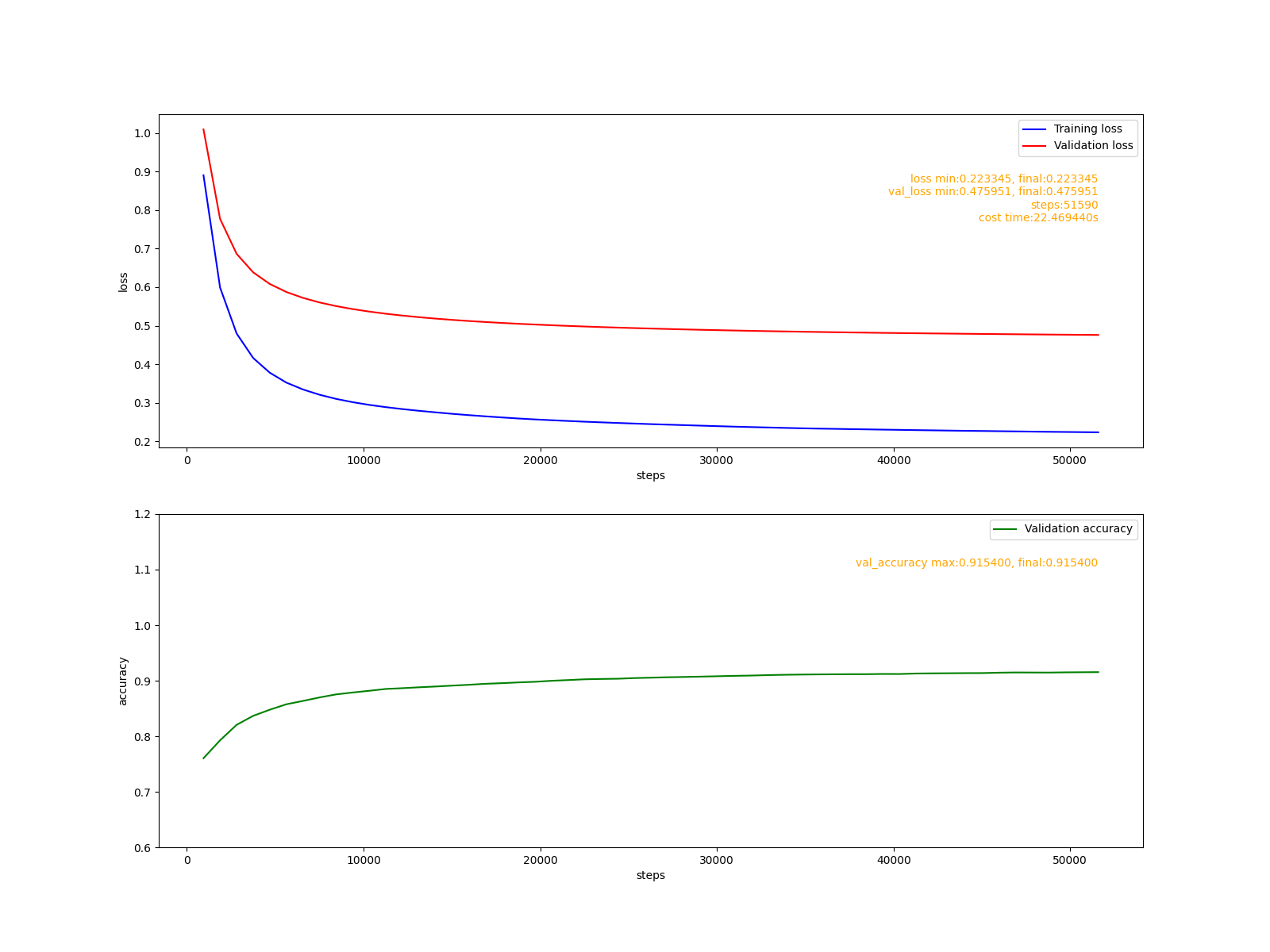
這里給出的是較小的學習率0.0001,多次試驗表明, RMSProp在較大學習率下很容易發散,而在較小學習率下通常會有穩定的良好表現,
Adadelta演算法優化器
def fit_use_adadelta():
dpr = 0.99
print("fit_use_adadelta dpr=%f"%dpr)
fit('adadelta.png', optimizers.Adadelta(dpr))
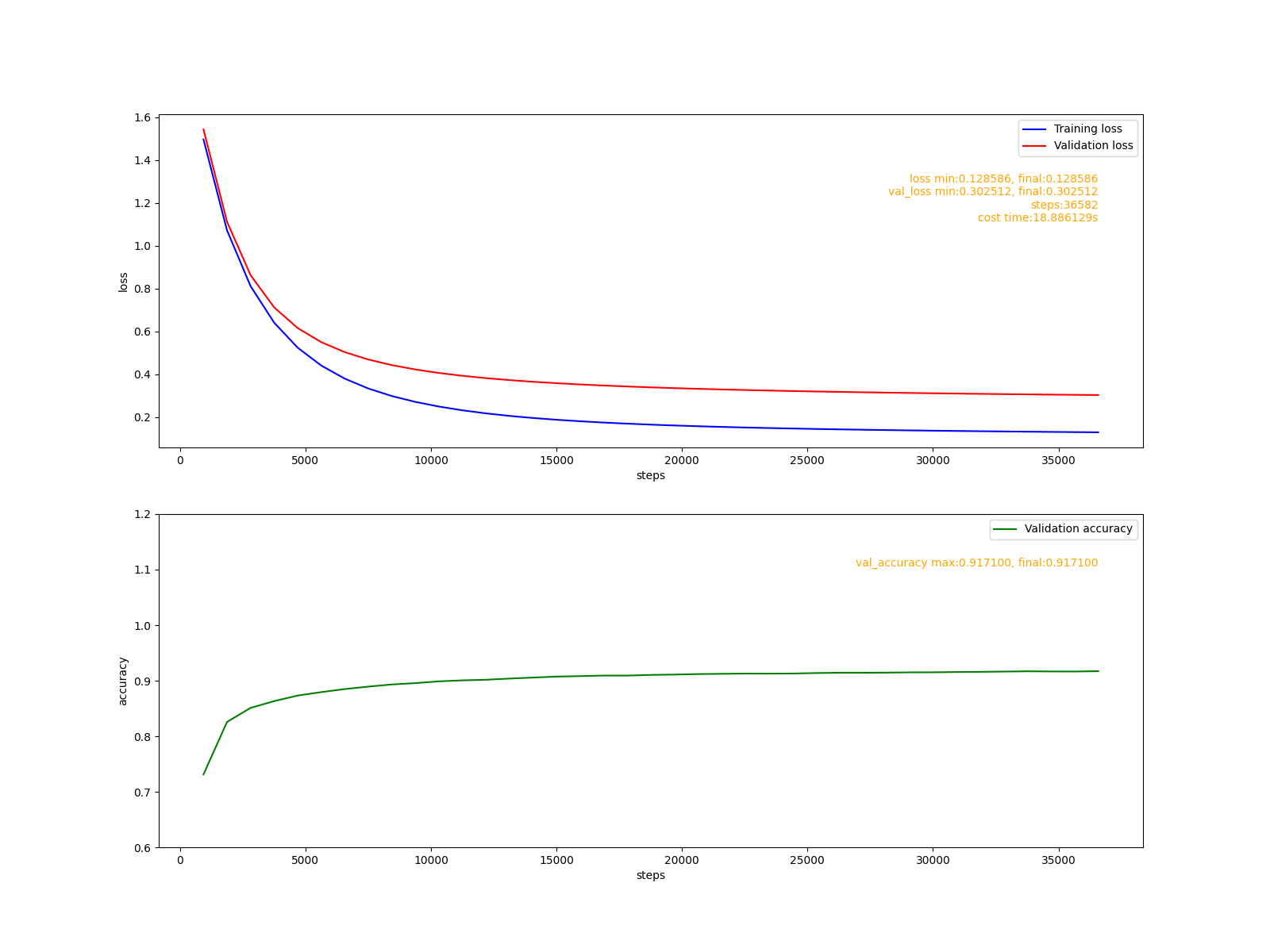
這個演算法不需要給出學習率引數,多次試驗顯示, 在這個簡單模型上, Adadelta演算法表現得非常穩定,
Adam演算法優化器
def fit_use_adam():
lr = 0.0001
mdpr = 0.9
sdpr = 0.99
print("fit_use_adam lr=%f, mdpr=%f, sdpr=%f"%(lr, mdpr, sdpr))
fit('adam.png', optimizers.Adam(lr, mdpr, sdpr))
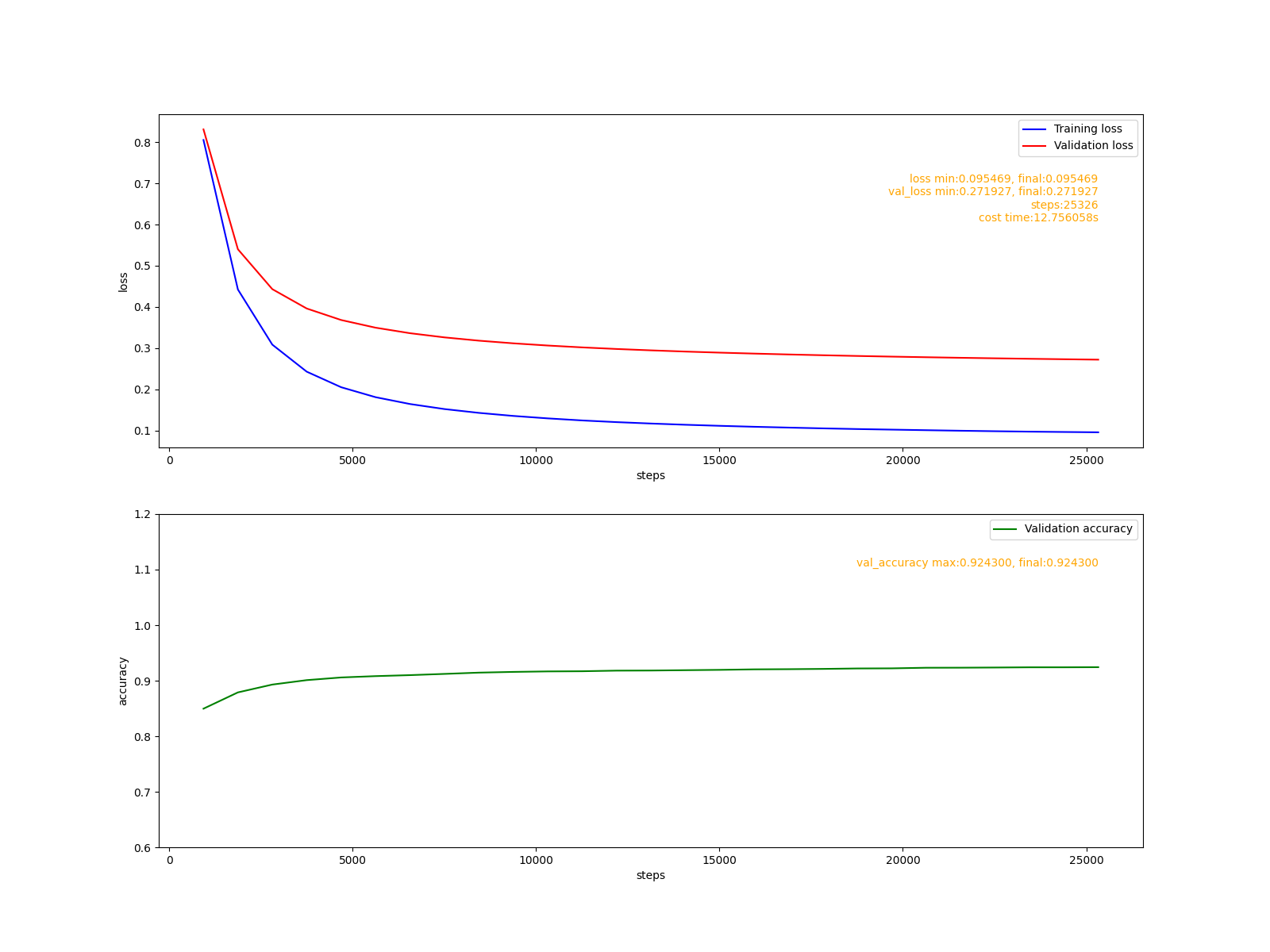
只用這個演算法在較小學習率0.0001的情況下20000步左右即可完成訓練且最終達到了92.4%的驗證準確率,
總結
這個階段為框架添加了常見的學習率優化演算法,并在同一個模型上進行驗證,對比,我發現即使不使用優化演算法,用固定的學習率, 只要給出“合適”的學習率引數,仍然能夠得到理想的訓練速度, 但很難確定怎樣才算“適合”, 學習率演算法給出了引數調整的大致方向,一般來說較小的學習率都不會有問題,至少不會使模型發散,然后可以通過調整衰減率來加快訓練速度,而衰減率有比較簡單數學性質可以讓我們在調整它的時知道這樣調整意味著什么,
目前為止cute-dl框架已經實作了對簡單MLP模型的全面支持,接下來將會為框架添一些層,讓它能夠支持卷積神經網路模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34007.html
標籤:其他
上一篇:spark寫入phoenix