摘要:
本文由以資料之名分享,正所謂“問君能有幾多愁,恰似一江春水向東流”,
不知不覺中,“以資料之名”Kettle解憂消愁系列專題已更新了五篇知識庫文章“三十而立、四十不惑、五十而耳知天命、六十而耳順、七十古稀”,敘述了使用Kettle作為ETL開發的常見組件使用說明、業務場景實作邏輯、例外分析及組件性能優化相關內容,
今天,我們跟著小編的節奏,繼續探討第六篇Kettle知識庫問答系列之八零年代,做到理念和實踐的生動統一,
1.例外分析篇
第073問:
Host '127.0.0.1' is blocked
because of many connection errors;
unblock with 'mysqladmin flush-hosts'Connection
closed by foreign host?
第073答:
由例外提示可以看出原因:同一個ip在短時間內產生太多(超過mysql資料庫max_connect_errors的最大值)中斷的資料庫連接而導致的阻塞,
- 首先,我們先查詢資料庫服務端的引數max_connect_errors配置
show variables like 'max_connect_errors';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_connect_errors | 10 |
+--------------------+-------+
max_connect_errors是一個MySQL中與安全有關的計數器值,它負責阻止過多嘗試失敗的客戶端以防止暴力破解密碼的情況,
- max_connect_errors的值與性能并無太大關系,默認是10,意味著如果某一客戶端嘗試連接此MySQL服務器,但是失敗(如密碼錯誤等等)10次 ,則MySQL會無條件強制阻止此客戶端連接,
- 如果希望重置此計數器的值,則必須重啟MySQL服務器或者執行mysql> flush hosts; 命令,當這一客戶端成功連接一次MySQL服務器后,針對此客戶端的max_connect_errors會清零,如果max_connect_errors設定過小,則網頁可能提示無法連接資料庫服務器,
- 解決方法1:修改max_connect_errors的值
(1)進入Mysql資料庫查看max_connect_errors:
show variables like '%max_connect_errors%';
(2)修改max_connect_errors的值:
set global max_connect_errors = 80;
(3)查看是否修改成功
show variables like '%max_connect_errors%';
- 解決方法2:使用mysqladmin flush-hosts 命令清理一下hosts檔案
,
(1)在查找到的目錄下使用命令修改:
> mysqladmin -u xxx -p flush-hosts
或者
> flush hosts;
- 解決方法3:重啟mysqld,
也可以在重啟之前,在組態檔中將該引數調大,
> vi /etc/my.cnf
max_connect_errors = 80
第074問:
Kettle發送郵件附件中文亂碼,如何解決呢?
第074答:
修改spoon啟動腳本配置,在set OPT=%OPT% %PENTAHO_DI_JAVA_OPTIONS% 這一行末尾,添加如下配置:
"-Dmail.mime.encodefilename=true"
"-Dmail.mime.charset=utf-8"
"-Dfile.encoding=utf-8"
第075問:
Kettle ES Bulk Insert批量資料寫入,Kibana查詢有延遲?
第075答:
- 首先,很可能短時間寫入資料量和并發量過大,es的master處理不過來了,segment合并是一個很是耗時的操作,
- 其次也可能有以下幾點原因:
- 1、分片數過多,建議單節點的分片數不要超過1000個;shard越少,寫入開銷越小;
- 2、經過寫入資料自動建立索引最容易出現這種狀況;
- 3、大批量寫入資料refresh時間間隔過短;
- 4、索引的欄位數量太多(幾十上百個)
性能分析篇
第076問:
你理解count(*)、count(1)、count(column)的區別嘛?
第076答:
我們可以從以下兩個角度來分別看待:
-
執行效果上 :
- 1、count(*)包括了所有的列,相當于行數,在統計結果的時候, 不會忽略列值為NULL
- 2、count(1)包括了忽略所有列,用1代表代碼行,在統計結果的時候, 不會忽略列值為NULL
- 3、count(column)只包括列名那一列,在統計結果的時候,會忽略列值為空(這里的空不是只空字串或者0,而是表示null)的計數, 即某個欄位值為NULL時,不統計,
-
執行效率上:
- 1、列名為主鍵,count(column)會比count(1)快
- 2、列名不為主鍵,count(1)會比count(column)快
- 3、如果表多個列并且沒有主鍵,則 count(1) 的執行效率優于 count(*)
- 4、如果有主鍵,則 select count(主鍵)的執行效率是最優的
- 5、如果表只有一個欄位,則 select count(*)最優,
第077問:
怎么我的Kettle轉換或者作業運行耗時那么長?
第077答:
無論使用什么組件,首先要看任務運行表象:
- 1、任務執行慢?(思考為什么慢,怎么找出那個環節慢)
- 2、找出哪個環節接慢?
- 2.1、看各環節執行耗時,做初步觀察;
- 2.2、啟動探測,觀察metrics步驟度量資訊,
- 3、找出了那個環節耗時最長,思考什么原因可能導致慢邏輯?
- 3.1、表輸入慢,思考是否存在查詢badsql,如索引未生效;
Kettle知識庫問答系列之六十而耳順 - 3.2、資料庫查詢或資料庫連接,反查操作慢,是否存在索引未生效的情況,如上一步驟資料流,資料型別和查詢條件資料型別不匹配,導致badsql
- 3.3、表輸出慢或插入更新慢,參考我的文章:
Kettle知識庫問答系列之三十而立
Kettle知識庫問答系列之四十不惑
Kettle知識庫問答系列之六十而耳順
- 3.1、表輸入慢,思考是否存在查詢badsql,如索引未生效;
- 4、也可能跟源資料庫服務器、etl服務器、目標資料庫服務器等系統資源或資料庫存在性能瓶頸,
- 4.1、需要做服務器底層引數優化(如檔案句柄數等)
- 4.2、資料庫層面(如server實體啟動分配記憶體等)
- 4.3、找DBA配合做性能分析
- 5、抑或是組件使用問題,再或者是組件本身存在性能瓶頸
實戰開發篇
第078問:
如何一次性掌握json決議真諦?
第078答:
對于Json欄位的決議有兩種標準的處理方式:

- 1.使用自帶的JsonInput輸入組件決議
- 1.1 決議單層資料
決議思路:JsonInput的使用規范是,決議單層資料,可以一次性搞定;
這里我們直接決議第4層,itemCode的路徑配置,JsonArray用key[*]獲取,JsonObject用key直接獲取:- $..extendList[*]..itemCode(此處有省略路徑資訊)
- 或 $..extendList[*].itemCode(此處有省略路徑資訊)
- 或 $.result.paySuiteDataList[*].extendList[*].itemCode

決議結果,具體如下:
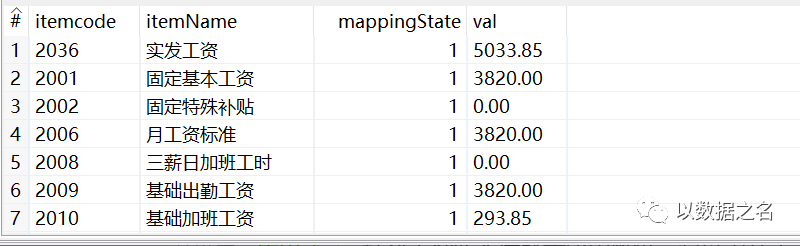
- 1.2 決議多層資料,需要分層次決議,還有一點,需要保證每層決議的元資料欄位必須一致,否則JsonInput組件就會跑例外啦,
- 這里我們需要決議第3層和第4層資料,實作資料流欄位組合,先決議第3層,extendList的路徑為$.result.paySuiteDataList[*].extendList,其他同層key獲取路徑前綴一致
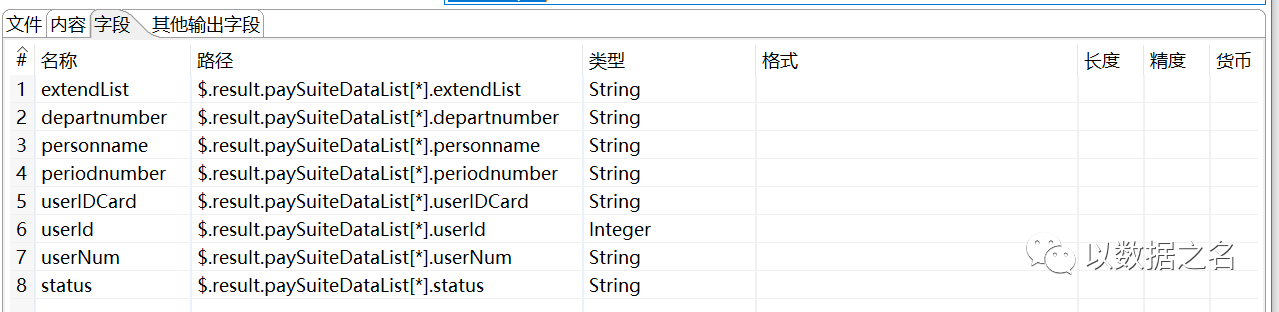
決議結果,具體如下:

- 再在第三層extendList的路徑基礎上,決議第4層JsonArray資料,itemCode的路徑配置為$..itemCode
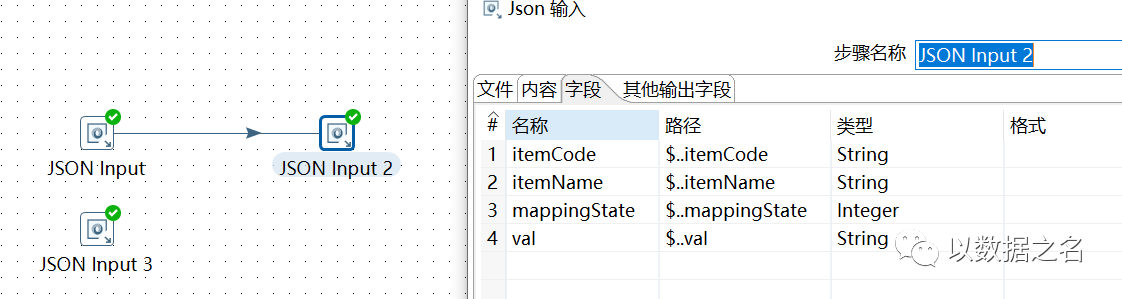
決議結果,具體如下:

- 這里我們需要決議第3層和第4層資料,實作資料流欄位組合,先決議第3層,extendList的路徑為$.result.paySuiteDataList[*].extendList,其他同層key獲取路徑前綴一致
- 1.1 決議單層資料
- 2.使用Java腳本組件決議(引入FastJson或Jackson等Json序列化和反序列化包),此處以FastJson為例
- 1、import 匯入FastJson包;
- 2、Json反序列化成JsonArray或JsonObject,依據Json體層次結構的物件屬性來具體呼叫JSONObject.parseObject或JSONArray.parseArray等API方法
- 3、獲取當層次key欄位資料getString或getObject等API方法
后臺回復json,獲取json決議示例檔案和示例轉換
第079問:
怎么玩轉xml決議?
第079答:
針對于XML檔案或欄位串決議,有以下幾個關鍵步驟:
以如下xml結構為示例,做具體步驟決議分析,供參考,
<session_header code="xmltest">
<infosession>
<infosessiondata user="Username1">
<data>Data1</data>
</infosessiondata>
</infosession>
<infosession>
<infosessiondata user="Username2">
<data>Data2</data>
</infosessiondata>
</infosession>
<infosession>
<infosessiondata user="Username3">
<data>Data3</data>
</infosessiondata>
</infosession>
<session>
<sessiondata>
<parameter>
<user>Username1</user>
<password>password123</password>
</parameter>
<outputdata>
<step>
<error_message>Please have transaction ID and related information ready. Timestamp : 20070731 01:50:06 Session : 0201</error_message>
</step>
</outputdata>
</sessiondata>
<sessiondata>
<parameter>
<user>Username2</user>
<password>password345</password>
</parameter>
<outputdata>
<step>
<error_message>error occurred Timestamp : 20070731 01:53:25</error_message>
</step>
</outputdata>
</sessiondata>
<sessiondata>
<parameter>
<user>Username3</user>
<password>password567</password>
</parameter>
<outputdata>
<step>
<error_message>Transaction Id :361163328</error_message>
<status>Processed according to contract/plan provisions</status>
</step>
</outputdata>
</sessiondata>
</session>
</session_header>
- 1、指定xml資料流來源,是檔案?還是資料流欄位?還是介面回傳報文?
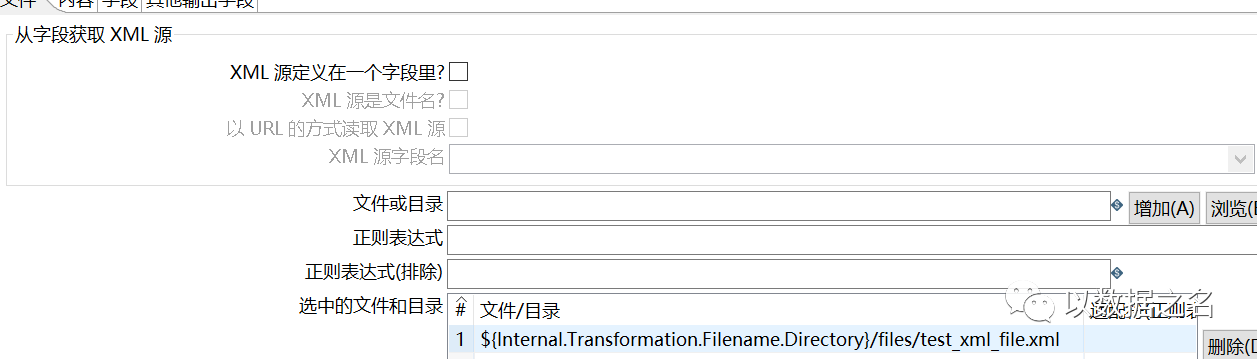
- 2、查看xml資料標簽結構,確定回圈目錄Session_header/Session/SessionData;

- 3、明確待決議欄位資訊,是標簽屬性值?還是標簽值?

- Code:為Session_header的標簽屬性值,而回圈讀取路徑為Session_header/Session/SessionData,所以需要往上找兩層../../,加上此處獲取的是標簽屬性值,故配置為@Code,所以整體Code欄位的XML路徑為“../../@Code”

- User:此處xml結構第5層的
的標簽值,而回圈讀取路徑為Session_header/Session/SessionData,所以需要往下找兩層,此處采用具體路徑Parameter/User,Password、Status、Error_Message標簽值的XML路徑配置同上邏輯
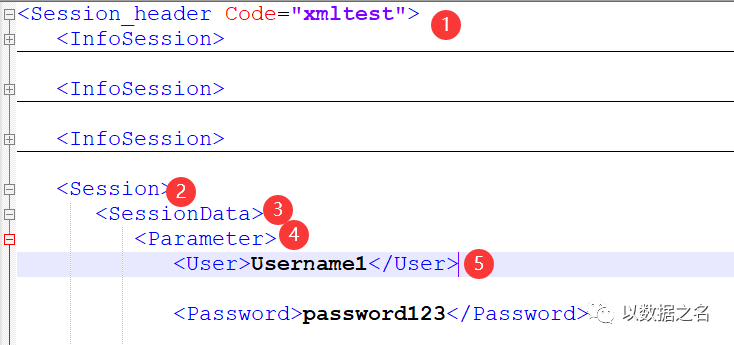
- Data:此處xml結構第4層的的標簽值,而回圈讀取路徑為Session_header/Session/SessionData,所以需要先往上找兩層../../,再往下找兩層InfoSession/InfoSessionData,而這里的Data標簽值要根據上層InfoSessionData的標簽屬性User對應值,與Session_header/Session/SessionData/Parameter/User的標簽值一一匹配上,這里的InfoSessionData路徑要調整為InfoSessionData[@User=@_User-],最后再取第4層的的標簽值,最后Data對應的標簽值的XML路徑配置為../../InfoSession/InfoSessionData[@User=@_User-]/Data
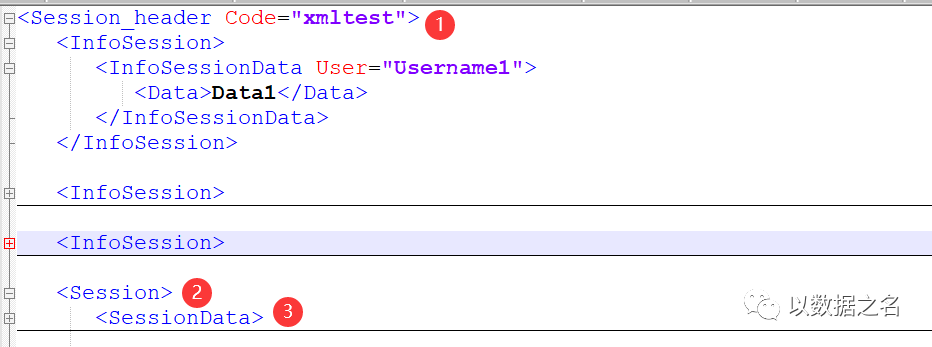
- Code:為Session_header的標簽屬性值,而回圈讀取路徑為Session_header/Session/SessionData,所以需要往上找兩層../../,加上此處獲取的是標簽屬性值,故配置為@Code,所以整體Code欄位的XML路徑為“../../@Code”
- 4、最后我們來具體看下,示例運行輸出結果,來檢查配置邏輯是否正確,

后臺回復xml,獲取xml決議示例檔案和示例轉換
第080問:
我有200+表,需要做全量資料同步,Kettle 有沒有通用的解決方案?
第080答:
如果你的ETL邏輯沒有特別個性化,理論上是可以搞一套通用配置,要什么欄位取什么欄位,目標不配置映射關系,就可以讓資料流和目標資料庫按照順序自動匹配,
- 1個入口程式Job A,負責呼叫查詢通用配置表查詢轉換 Trans A,和回圈呼叫執行Job B;
- 1個執行Job B ,負責呼叫初始化通用引數轉換Trans B,和呼叫核心執行轉換Trans C;
- 1個轉換Trans A負責讀取配置表資訊,復制到結果集;
- 1個轉換Trans B負責從結果集讀取配置行資訊,賦值給設定變數;
- 1個轉換Trans C負責執行核心ETL操作,表輸入(根據配置源資料庫表引數資訊,獲取動態SQL
${S_SQL}
或動態拼接SQL
select ${s_column} from ${s_tb} where ${s_where})
+個性化處理(非必須)+表輸出(動態目標表【${t_tb}】),

KETTLE專題
Kettle插件開發之Splunk篇
Kettle插件開發之Elasticsearch篇
Kettle插件開發之KafkaConsumerAssignPartition篇
Kettle插件開發之KafkaProducer篇
Kettle插件開發之KafkaConsumer篇
Kettle插件開發之KafkaConsumerAssignPartition篇
Kettle插件開發之MQToSQL篇
Kettle插件開發之Redis篇
Kettle快速構建基礎資料倉庫平臺
Kettle知識庫問答系列之三十而立
Kettle知識庫問答系列之四十不惑
Kettle知識庫問答系列之五十而知天命
Kettle知識庫問答系列之六十而耳順
Kettle知識庫問答系列之七十古稀
Kettle實戰系列之Carte集群應用
Kettle實戰系列之動態郵件
Kettle實戰系列之基于Carte構建微服務

雖小編一己之力微弱,但讀者眾星之光璀璨,小編敞開心扉之門,還望傾囊賜教原創之文,期待之心滿于胸懷,感激之情溢于言表,一句話,歡迎聯系小編投稿您的原創文章!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340370.html
標籤:其他