前文我們介紹過一種基于TPS薄板樣條與梯度下降法的非剛性配準方法:
基于TPS薄板樣條變換與梯度下降法的一種非剛性配準方法
我們知道,梯度下降法是一種單線優化演算法,也即它只優化目標函式的一組解,這樣是很容易陷入區域極值的,而PSO粒子群演算法則不一樣,它是多線優化演算法,也即同時優化目標函式的多組解,最后從多組解中再選擇最優的一組解作為最終解,因此相比梯度下降法,PSO演算法更不容易陷入區域極值,
本文我們來實作一種基于薄板樣條變換與PSO優化演算法的非剛性配準方法,該方法使用薄板樣條變換作為形變模型,并使用PSO粒子群演算法作為優化演算法對薄板樣條變換的輸入引數進行優化,
01
—
目標函式介紹
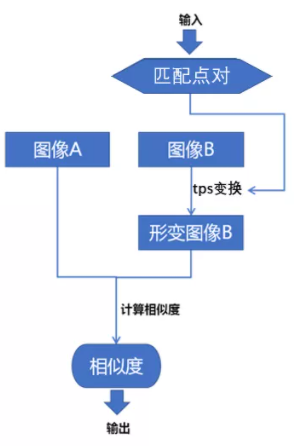
目標函式示意圖
目標函式如下圖所示,輸入引數為參考影像A與浮動影像B的多組匹配點對,然后使用匹配點對計算TPS變換的坐標偏移,接著使用坐標偏移對影像B進行像素重采樣,得到TPS形變之后的影像B,最后計算影像A與形變之后影像B的相似度,作為目標函式的輸出值,
輸入引數的初始化
配準開始之前,需要在參考影像A與浮動影像B上面初始化一系列等間距的點,假設兩圖中相同位置的點為匹配點對,然后將這些匹配點對作為以上目標函式的初始輸入引數,接著使用PSO演算法求解目標函式取得最小值(也即影像A與形變影像B最相似)時的輸入引數作為最終解,如下圖所示:
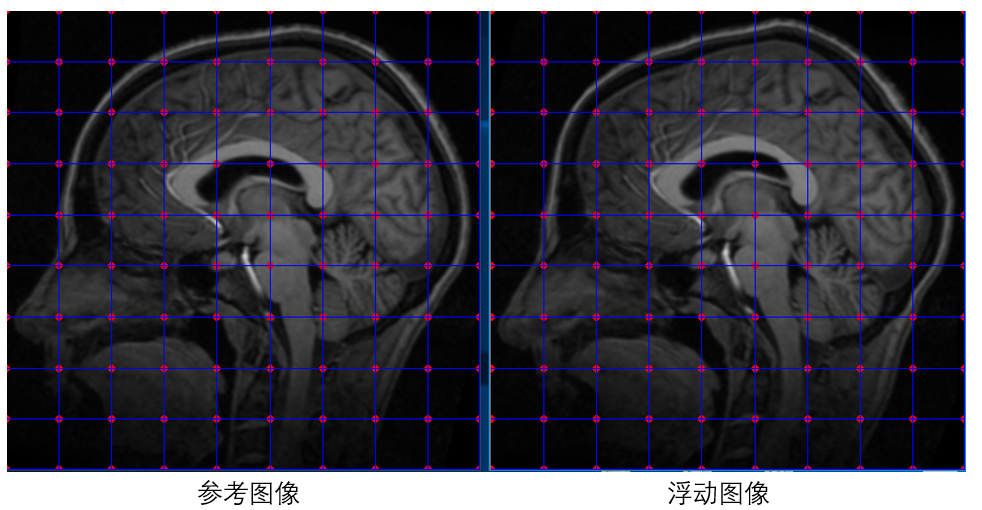
目標函式的輸入為影像A與影像B的多組匹配點對,但實際上并不需要優化影像A上點的位置,只需要固定影像A上點的位置,然后優化影像B上點的位置,使其與影像A上點的位置匹配即可,假設影像A與影像B上初始化的等間距的點個數都是N個,每個點包含x坐標和y坐標,那么我們需要優化的引數為影像B上所有初始化點的x、y坐標組成的2*N個引數,
TPS薄板樣條變換原理與實作
TPS變換是一種非剛性形變模型,其輸入引數為兩影像的一系列匹配點對,所有匹配點對共同決定了一張影像到另一張影像的形變坐標偏移,一般通過特征點匹配、光流追蹤等方法獲取兩圖的匹配點對,不過本文中我們使用PSO優化演算法來獲取,
前文我們介紹過TPS變換的原理與C++實作:
TPS薄板樣條變換計算原理及C++實作
由于TPS變換的計算程序很耗時,后來我們又使用GPU CUDA來并行加速其計算程序:
基于TPS薄板樣條變換與梯度下降法的一種非剛性配準方法
相似度衡量
本文我們使用兩影像的差值圖均值作為相似度,也即相似度越小,表示兩影像越相似,假設影像A與影像B的尺寸都是m行n列,對于影像上任意坐標點(x,y),影像A、影像B上該點的像素值分別為A(x,y)、B(x,y),那么A和B的相似度計算如下式:
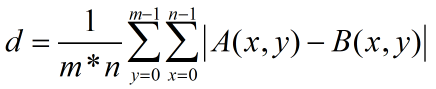
02
—
PSO粒子群演算法的基本原理與改進
基本原理
前文我們已經講過PSO演算法的基本原理,此處再簡單介紹一下:
粒子群(PSO)演算法的理解與應用
簡單地理解粒子群演算法就是:
(1) 有多個粒子;
(2) 每個粒子就是目標函式的一組解;
(3) 每個粒子具有記憶功能,它在移動程序中,每到達一個位置都計算目標函式值,如果發現目標函式值相對上一個位置有所下降,則把當前位置記住,這個記住的位置也稱為區域最優位置pbest(每個粒子都有一個自己的pbest);
(4) 不同粒子之間互相通信,把各自記住的區域最優位置互相告知,并在所有粒子的區域最優位置當中,選擇一個目標函式值最小的位置,作為全域最優位置gbest(所有粒子共享一個gbest),
(5) 當前位置X、區域最優位置pbest、全域最優位置gbest共同決定粒子移動的下一個位置(也即更新粒子引數),假設目標函式f輸入N個引數,那么每個粒子的X、pbest以及所有粒子共享的gbest都可看作長度為N的一維向量:
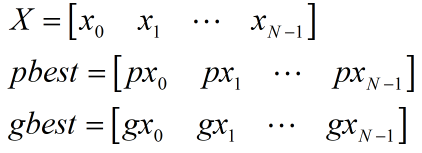
對于X中的任意分量xi(0≤i≤N-1),其下一個位置的值可按下式計算,其中c1和c2為取值范圍在1.5~2.5之間的固定值,通常都取1.8,rand(0,1)為0~1的亂數,pxi為pbest中對應xi的分量,gxi為gbest中對應xi的分量,
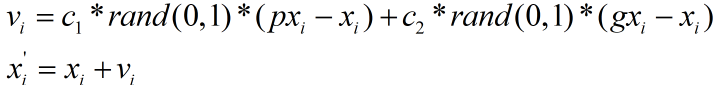
演算法改進
增加慣性權重
上式的v相當于粒子移動的速度,根據加速度原理,當前位置的速度與上個位置的速度具有一定關系,因此后來人們又提出了改進演算法,改進之后可加速收斂速度,如下式所示,
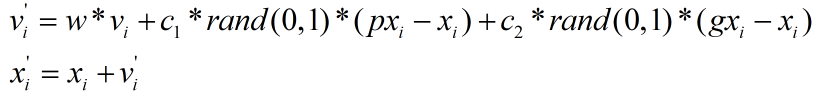
上式中v'為粒子在當前位置的速度,v為粒子在上個位置的速度,w為0~1之間的慣性權重值,w通常取固定值或遞減:
(1) 取0~1之間的一個固定值,
(2) 設定最大、最小值,隨著迭代次數的增加,由最大值線性遞減到最小值,如下式,i為當前迭代次數(0≤i≤num-1),num為總迭代次數,
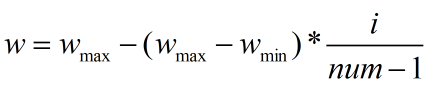
增加壓縮系數
增加壓縮系數φ來限制速度的大小,這樣也可加速迭代收斂,如下式所示,不過需要注意c1和c2之和必須大于4:
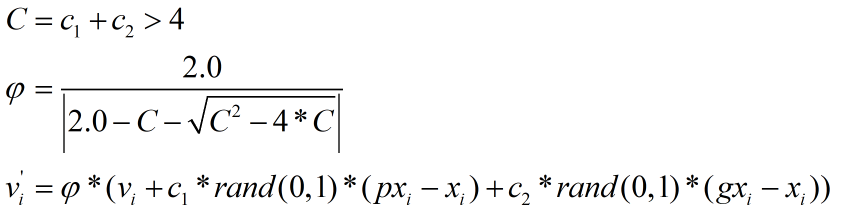
增加粒子的老化處理
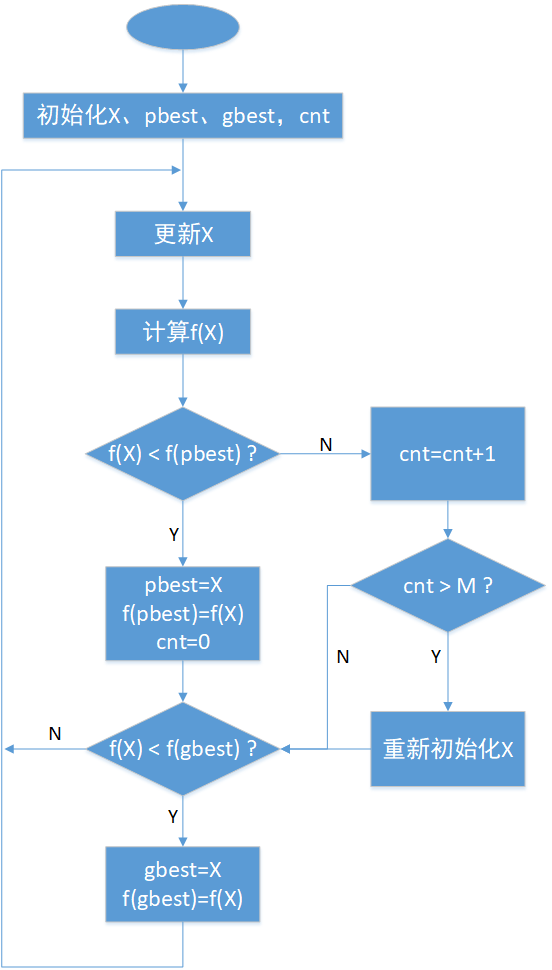
當某一個粒子連續移動M次(M通常設定為5~15之間的一個值)但目標函式值一次都沒有下降,則認為該粒子老化了,此時可對該粒子的位置X重新初始化,使其重新煥發活力,這樣可以有效避免優化陷入區域極值,如下圖所示:
使用所有粒子的pbest的質心位置代替各自的pbest
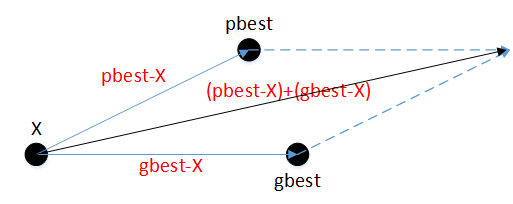
由上述速度計算公式可知,粒子的移動速度主要由其pbest與X的差值向量,以及gbest與其X的差值向量決定,也就是說,粒子的移動方向由兩個差值向量的向量之和決定,這么一來粒子大概率往目標函式值更低的位置移動,如下圖所示:
根據統計學原理,多個值的平均值通常比單個值的準確度更高,因此我們計算所有粒子的pbest的質心點,使用質心點代替各個粒子的pbest計算速度,使粒子朝著更加準確的方向移動,所以可加快收斂速度,
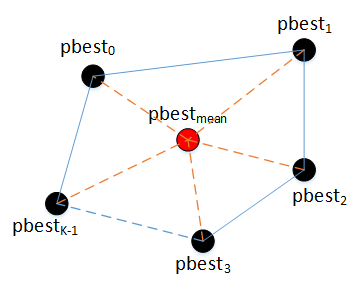
假設有K個粒子,每個粒子都有一個pbest,那么總共有K個pbest,如上圖對K個pbest求平均,得到質心位置pbestmean,然后使用pbestmean來代替原來各自的pbest計算速度:
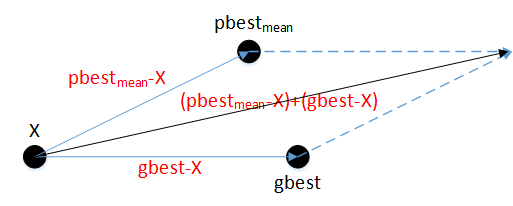
pbestmean的計算如下式:
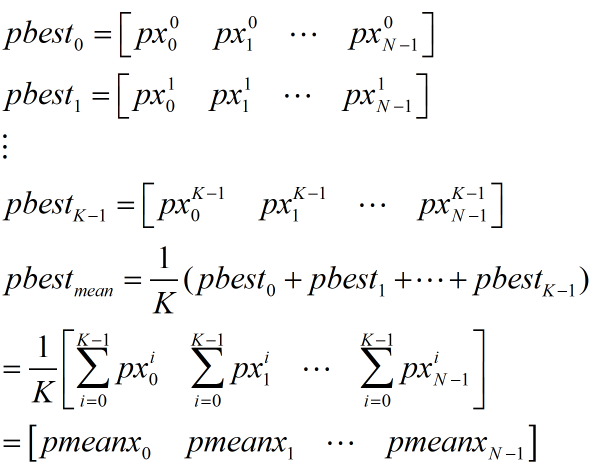
從而速度計算公式修改為:
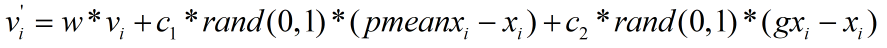
修改后的速度計算公式還有一個優點:我們知道當粒子運行到位置X時,如果f(X)<f(pbest),那么會將X賦值給pbest、將f(x)賦值給f(pbest),此時pxi-xi的值為0;如果f(X)<f(gbest),那么會將X賦值給gbest、將f(x)賦值給f(gbest),此時gxi-xi的值為0,這兩種情況下如果按照原速度公式計算,粒子的移動速度將很大程度減小,導致收斂速度變慢,但是修改后的公式則沒有這個問題,不管是f(X)<f(pbest)還是f(X)<f(gbest)的情況,pmeanxi-xi都不會為0,這就確保了粒子的移動速度保持在一定水平,
03
—
各部分代碼實作
TPS薄板樣條變換代碼
TPS變換的代碼,以及CUDA并行加速代碼,我們在前文都已列出,此處不再重復:
TPS薄板樣條變換計算原理及C++實作
基于TPS薄板樣條變換與梯度下降法的一種非剛性配準方法
值得一提的是,Opencv也有現成的TPS模塊可以呼叫,不過相比自己使用CUDA加速實作的TPS就慢了很多了:
//定義一個tps變換的物件
auto tps = cv::createThinPlateSplineShapeTransformer();
//定義一個DMatch引數,p1為影像A上的點集,p2為影像B上的點集
//p1與p2中對應位置的點互相匹配
vector<cv::DMatch> matches;
for (int i = 0; i < p1.size(); i++)
{
matches.push_back(cv::DMatch(i, i, 0));
}
//計算tps形變坐標偏移
tps->estimateTransformation(p1, p2, matches);
Mat out;
//對影像B進行像素重采樣
tps->warpImage(Si, out);相似度計算代碼
double cal_diff_gradient(Mat S1, Mat Si)
{
Mat diff = abs(S1 - Si); //計算兩圖的差值絕對值圖
double m = mean(diff)[0]; //求差值絕對值圖的均值
return m;
}目標函式代碼
float F_fun_tps(Mat S1, Mat Si, vector<Point2f> p1, vector<Point2f> p2)
{
double result;
Mat Si_tmp;
#if 1 //CUDA加速TPS
Mat Tx, Ty;
Tps_warpImage_cuda(Si, Si_tmp, Tx, Ty, p1, p2, 1);
result = cal_diff_gradient(S1, Si_tmp);
#else //Opencv實作的TPS
auto tps = cv::createThinPlateSplineShapeTransformer();
vector<cv::DMatch> matches;
for (int i = 0; i < p1.size(); i++)
{
matches.push_back(cv::DMatch(i, i, 0));
}
tps->estimateTransformation(p1, p2, matches);
Mat out;
tps->warpImage(Si, out);
result = cal_diff_gradient(S1, out);
#endif
return result;
}輸入引數初始化代碼
在參考影像A與浮動影像B上面初始化一系列等間距的點,假設兩圖中相同位置的點為匹配點對,然后將這些匹配點對作為目標函式的初始輸入引數,
void init_points(Mat src, int row_block_num, int col_block_num, vector<Point2f> &p1, vector<Point2f> &p2)
{
float row_block_size = src.rows * 1.0 / (row_block_num-1);
float col_block_size = src.cols * 1.0 / (col_block_num-1);
p1.clear();
p2.clear();
for (int i = 0; i < row_block_num; i++)
{
for (int j = 0; j < col_block_num; j++)
{
float x = j*col_block_size;
float y = i*row_block_size;
x = x > src.cols - 1 ? src.cols - 1 : x;
y = y > src.rows - 1 ? src.rows - 1 : y;
Point2f p(x, y);
p1.push_back(p);
p2.push_back(p);
}
}
}PSO優化代碼
首先是一些全域變數的定義:
const int NUM_tps = 50; //粒子數
const float c1_tps = 1.88; //粒子群引數1
const float c2_tps = 1.88; //粒子群引數2
float xmin_tps = -1.5; //控制引數被初始化為-1.5到1.5之間的亂數
float xmax_tps = 1.5;
const float vmin_tps = -6.5; //粒子的移動速度被鉗制在為-6.5到6.5之間,這是經驗值,合適的鉗制范圍可以加快收斂速度
const float vmax_tps = 6.5;
//定義粒子群,粒子個數為NUM_tps,每個粒子為一個結構體
struct particle_tps
{
vector<Point2f> x; //粒子的當前位置
vector<Point2f> bestx; //粒子的區域最優位置
float f; //當前位置對應的目標函式值
float bestf; //區域最優位置對應的目標函式值
}swarm_tps[NUM_tps];其次是原PSO演算法代碼:
void tps_PSO_0(Mat S0_u8, Mat Si_u8, Mat &out_u8, vector<Point2f> p1, vector<Point2f> &p2, Mat &Tx, Mat &Ty, int iter_num)
{
vector<float> cc_list;
float v_min = vmin_tps;
float v_max = vmax_tps;
float c1 = c1_tps;
float c2 = c2_tps;
srand((unsigned)time(NULL) + rand());
float gbestf = 999999999999.9;
const int len = p1.size();
for (int i = 0; i < NUM_tps; i++) //初始化粒子群
{
particle_tps *p = &swarm_tps[i];
for (int j = 0; j < len; j++)
{
p->x.push_back(p1[j] + Point2f(randf(xmin_tps, xmax_tps), randf(xmin_tps, xmax_tps)));
p->bestx.push_back(p1[j] + Point2f(randf(xmin_tps, xmax_tps), randf(xmin_tps, xmax_tps)));
}
p->f = F_fun_tps(S0_u8, Si_u8, p1, p->x);
p->bestf = p->f;
}
for (int t = 0; t < iter_num; t++) //iter_num次迭代
{
for (int i = 0; i < NUM_tps; i++) //NUM_tps個粒子
{
particle_tps *p = &swarm_tps[i];
for (int j = 0; j < len; j++) //計算速度
{
float Vx = c1*randf(0, 1)*(p->bestx[j].x - p->x[j].x) + c2*randf(0, 1)*(p2[j].x - p->x[j].x);
float Vy = c1*randf(0, 1)*(p->bestx[j].y - p->x[j].y) + c2*randf(0, 1)*(p2[j].y - p->x[j].y);
//鉗制速度大小
Vx = (Vx < v_min) ? v_min : ((Vx > v_max) ? v_max : Vx);
Vy = (Vy < v_min) ? v_min : ((Vy > v_max) ? v_max : Vy);
p->x[j].x = p->x[j].x + Vx; //更新粒子位置
p->x[j].y = p->x[j].y + Vy;
}
p->f = F_fun_tps(S0_u8, Si_u8, p1, p->x); //計算當前粒子的當前位置對應的目標函式值
//如果當前粒子的當前位置目標函式值小于其區域最優位置對應的目標函式值,則替換該粒子的區域最優位置
if (p->f < p->bestf)
{
for (int j = 0; j < len; j++)
{
p->bestx[j] = p->x[j];
}
p->bestf = p->f;
}
//如果當前粒子的區域最優位置對應的目標函式值小于全域最優位置對應的目標函式值,則替換全域最優位置
if (p->bestf < gbestf)
{
for (int j = 0; j < len; j++)
{
p2[j] = p->bestx[j];
}
gbestf = p->bestf;
printf("t = %d, gbestf = %lf\n", t, gbestf);
}
}
//速度鉗制范圍逐漸縮小,6.5->5.5
v_min = vmin_tps - (vmin_tps + 5.5) * t / (iter_num - 1);
v_max = vmax_tps - (vmax_tps - 5.5) * t / (iter_num - 1);
}
Tps_warpImage_cuda(Si_u8, out_u8, Tx, Ty, p1, p2, 1);
}接著是改進的PSO演算法代碼:
void tps_PSO_1(Mat S0_u8, Mat Si_u8, Mat &out_u8, vector<Point2f> p1, vector<Point2f> &p2, Mat &Tx, Mat &Ty, int iter_num)
{
vector<float> cc_list;
float v_min = vmin_tps;
float v_max = vmax_tps;
float c1 = c1_tps;
float c2 = c2_tps;
srand((unsigned)time(NULL) + rand());
float gbestf = 999999999999.9;
const int len = p1.size();
for (int i = 0; i < NUM_tps; i++) //初始化粒子群
{
particle_tps *p = &swarm_tps[i];
for (int j = 0; j < len; j++)
{
p->x.push_back(p1[j] + Point2f(randf(xmin_tps, xmax_tps), randf(xmin_tps, xmax_tps)));
p->bestx.push_back(p1[j] + Point2f(randf(xmin_tps, xmax_tps), randf(xmin_tps, xmax_tps)));
}
p->f = F_fun_tps(S0_u8, Si_u8, p1, p->x);
p->bestf = p->f;
}
vector<vector<float>> Vx_pre(NUM_tps, vector<float>(len, 0));
vector<vector<float>> Vy_pre(NUM_tps, vector<float>(len, 0));
float Vx, Vy;
float w = 0.25;
vector<int> update_cnt(NUM_tps, 0);
//計算所有粒子的pbest的均值
vector<Point2f> mean_bestx(len, Point2f(0, 0));
for (int t = 0; t < len; t++)
{
for (int k = 0; k < NUM_tps; k++) //NUM個粒子
{
mean_bestx[t] = mean_bestx[t] + swarm_tps[k].bestx[t];
}
mean_bestx[t] = mean_bestx[t] / NUM_tps;
}
for (int t = 0; t < iter_num; t++) //iter_num次迭代
{
//權重線性遞減
w = 0.25 - (0.25 - 0.1) * t / (iter_num - 1);
for (int i = 0; i < NUM_tps; i++) //NUM_tps個粒子
{
particle_tps *p = &swarm_tps[i];
for (int j = 0; j < len; j++) //計算速度,并更新位置
{
//改進,使用質心點替代原來的區域最優位置
Vx = Vx_pre[i][j] * w + c1*randf(0, 1)*(mean_bestx[j].x - p->x[j].x) + c2*randf(0, 1)*(p2[j].x - p->x[j].x);
Vy = Vy_pre[i][j] * w + c1*randf(0, 1)*(mean_bestx[j].y - p->x[j].y) + c2*randf(0, 1)*(p2[j].y - p->x[j].y);
Vx = (Vx < v_min) ? v_min : ((Vx > v_max) ? v_max : Vx);
Vy = (Vy < v_min) ? v_min : ((Vy > v_max) ? v_max : Vy);
p->x[j].x = p->x[j].x + Vx; //更新位置
p->x[j].y = p->x[j].y + Vy;
Vx_pre[i][j] = Vx; //將當位置的速度保存到上個位置的速度
Vy_pre[i][j] = Vy;
}
//計算當前粒子的當前位置的目標函式值
p->f = F_fun_tps(S0_u8, Si_u8, p1, p->x);
//如果當前粒子的當前位置目標函式值小于其區域最優位置目標函式值,則替換該粒子的區域最優位置
if (p->f < p->bestf)
{
//因為當前粒子的區域最優位置改變,質心點也將改變,所以重新計算質心點
//這里為了加快計算速度,沒有重新計算所有pbest的均值,而是原來的和減去舊值再加上新值,然后再除以粒子數
for (int t = 0; t < len; t++)
{
mean_bestx[t] = mean_bestx[t] * NUM_tps - p->bestx[t] + p->x[t];
mean_bestx[t] = mean_bestx[t] / NUM_tps;
}
for (int j = 0; j < len; j++)
{
p->bestx[j] = p->x[j];
}
p->bestf = p->f;
update_cnt[i] = 0; //計數器清零
}
else
{
//如果目標函式值沒有下降,計數器加1,且如果連續10次沒有下降,則重新初始化該粒子
update_cnt[i]++;
if (update_cnt[i] >= 10)
{
update_cnt[i] = 0; //計數器清零
//重新初始化該粒子
for (int j = 0; j < len; j++)
{
p->x[j] = p1[j] + Point2f(randf(xmin_tps, xmax_tps), randf(xmin_tps, xmax_tps));
}
}
}
if (p->bestf < gbestf) //如果當前粒子的歷史最優值小于全域最優值,則替換全域最優值
{
for (int j = 0; j < len; j++)
{
p2[j] = p->bestx[j];
}
gbestf = p->bestf;
printf("t = %d, gbestf = %lf\n", t, gbestf);
}
}
v_min = vmin_tps - (vmin_tps + 5.5) * t / (iter_num - 1);
v_max = vmax_tps - (vmax_tps - 5.5) * t / (iter_num - 1);
}
Tps_warpImage_cuda(Si_u8, out_u8, Tx, Ty, p1, p2, 1);
}測驗代碼
分別使用原PSO演算法、改進PSO演算法來優化TPS模型,對兩張腦部MRI進行配準,
void tps_pso_test(void)
{
Mat img1 = imread("brain3.png", CV_LOAD_IMAGE_GRAYSCALE);
Mat img2 = imread("brain4.png", CV_LOAD_IMAGE_GRAYSCALE);
imshow("image before", img1);
imshow("image2 before", img2);
vector<Point2f> p1, p2;
int row_block_num = 8;
int col_block_num = 8;
//初始化輸入引數
init_points(img1, row_block_num, col_block_num, p1, p2);
Mat out, Tx, Ty;
//tps_PSO_0(img1, img2, out, p1, p2, Tx, Ty, 300);
tps_PSO_1(img1, img2, out, p1, p2, Tx, Ty, 300);
//畫出配準前后的網格
Mat img1_grid = img1.clone();
Mat img2_grid = img2.clone();
Mat img3_grid = img2.clone();
cvtColor(img1_grid, img1_grid, CV_GRAY2BGR);
cvtColor(img2_grid, img2_grid, CV_GRAY2BGR);
cvtColor(img3_grid, img3_grid, CV_GRAY2BGR);
for (int i = 0; i < row_block_num; i++)
{
for (int j = 0; j < col_block_num; j++)
{
int idx = i*col_block_num + j;
circle(img1_grid, p1[idx], 2, Scalar(0, 0, 255), 2);
circle(img2_grid, p1[idx], 2, Scalar(0, 0, 255), 2);
circle(img3_grid, p2[idx], 2, Scalar(0, 0, 255), 2);
if (i > 0 && j > 0)
{
line(img1_grid, p1[idx], p1[i*(col_block_num)+j - 1], Scalar(255, 255, 255), 1);
line(img1_grid, p1[idx], p1[(i - 1)*(col_block_num)+j], Scalar(255, 255, 255), 1);
line(img2_grid, p1[idx], p1[i*(col_block_num)+j - 1], Scalar(255, 255, 255), 1);
line(img2_grid, p1[idx], p1[(i - 1)*(col_block_num)+j], Scalar(255, 255, 255), 1);
line(img3_grid, p2[idx], p2[i*(col_block_num)+j - 1], Scalar(255, 255, 255), 1);
line(img3_grid, p2[idx], p2[(i - 1)*(col_block_num)+j], Scalar(255, 255, 255), 1);
}
}
}
imshow("img1_grid", img1_grid);
imshow("img2_grid", img2_grid);
imshow("img3_grid", img3_grid);
imshow("img2-img1", abs(img2 - img1));
imshow("tps_out-img1", abs(out - img1));
imshow("tps_out", out);
waitKey();
}04
—
測驗結果
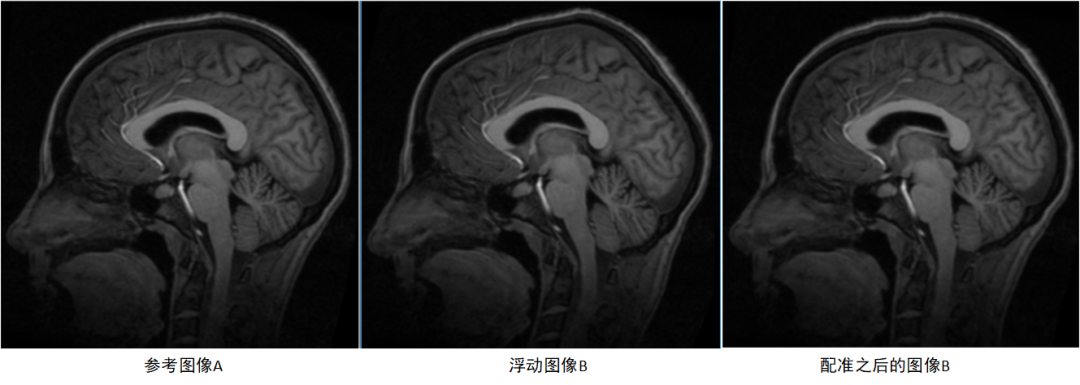
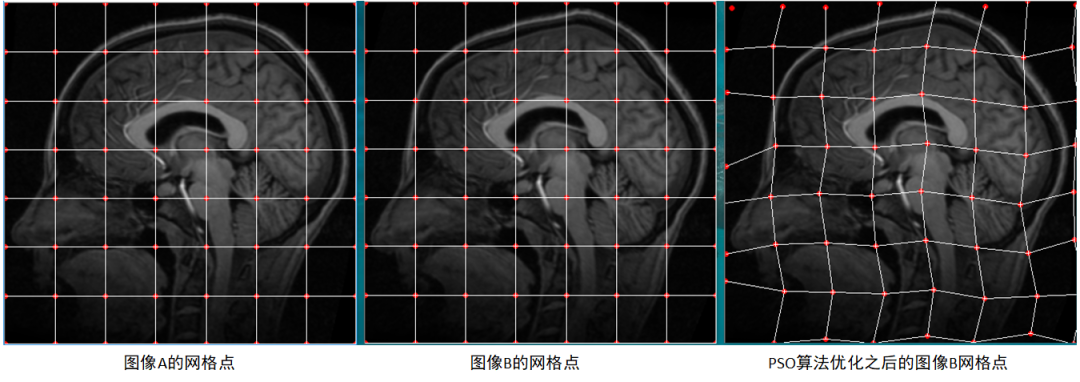
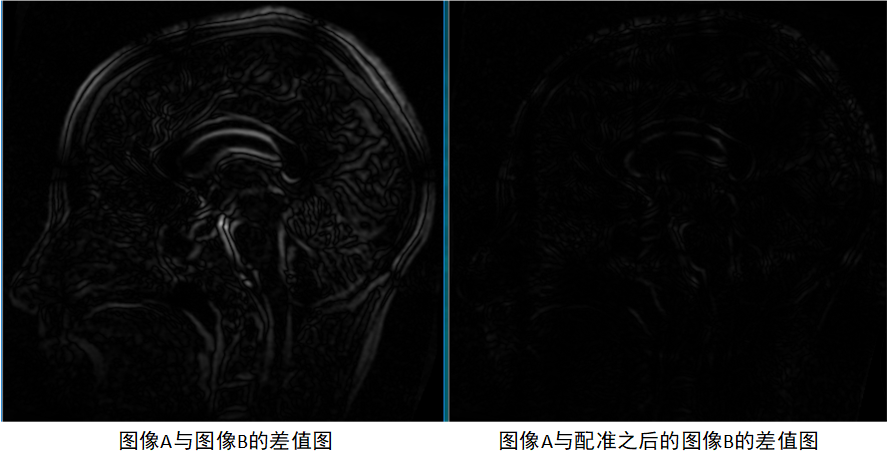
改進PSO演算法的配準結果如下圖,可以看到經過優化之后影像B上的網格點位置發生了改變,且由差值圖可知配準之后影像B的形狀達到與影像A相匹配,
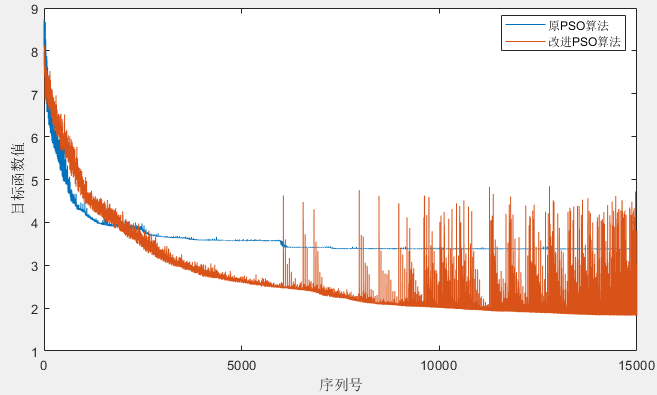
為了對比原PSO演算法和改進的PSO演算法,記錄所有粒子每輪迭代程序中的目標函式值,得到下圖,可以看到,原PSO演算法迭代到了一定程度之后目標函式值沒有明顯的下降,但改進演算法則持續下降,而且我們注意到,到了中后期改進演算法的目標函式值出現較多毛刺波動,這是因為對粒子做了重新初始化的老化處理,重新初始化之后目標函式值難免有波動,但總比原演算法陷入區域極值無法自拔好,
歡迎掃碼關注以下微信公眾號,接下來會不定時更新更加精彩的內容噢~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340569.html
標籤:其他
上一篇:libavdevice.so.58: cannot open shared object file: No such file or directory