2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路 2021年中國高校大資料挑戰賽A題思路
CSDN:數模范訓園,提供,思路開源持續更新,允許售賣,鼓勵進行改進,歡迎加入學習群,這里有漂亮的小姐姐,小哥哥,可脫單,,,

A 智能運維中的例外檢測與趨勢預測
首先按題目要求整理好關鍵資料

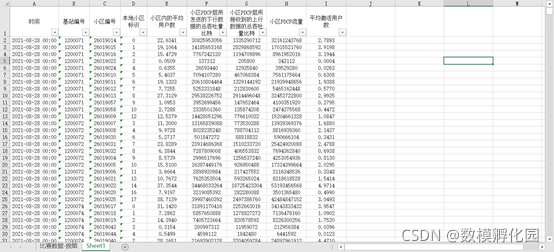
雖然題目只要求用到了幾個指標,但是其余指標也都可以用,可以用來描述設備的運行狀態,怎么用要看第一問檢測出的例外變動和其余哪些指標具有強相關性,如果有就可以作為后期預測的參考,沒有就不做,
雖然本題目告訴了資料具有周期性,也談到了例外,很明顯時間序列解題方向是沒錯,用例外檢測演算法檢測出例外資料,然后需要對例外資料進行修正,這里的修正我個人覺得不是簡單套一個演算法解決,資料例外只是設備的問題,而資料趨勢肯定不和設備有關,雖然這道題沒說輿情,但是自己想一下用戶的活躍,是否和娛樂圈、電影、新冠疫情、股市期貨、豬肉價格等等事件相關呢,這也并不是說要人人都去爬取微博、知乎、東方財富等網站的評論然后做熱詞分析,量太大時間也來不及,這里推薦百度指數、微指數、谷歌趨勢、360趨勢,
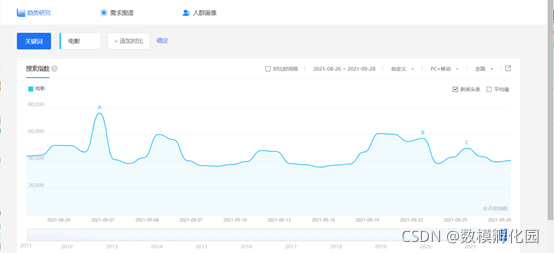
疫情資料國內外都可以,以及股市大盤的走向,或者比較關心的豬肉價格走勢等等,分別構建本題三個關鍵指標的指標體系,然后用這些指標資料作為訓練輸入,關鍵指標作為輸出,分別通過機器學習方法去修正檢測到的資料,如何給自己增加亮點自己考慮,隨便套用演算法誰都會
來看看第一問,一定是針對每個小區編號來做分析,做分析前一定是要對資料進行平滑處理,雖然說平滑后會導致資料失真,那肯定不能平滑的太厲害,平滑程度至少要把例外資料段凸顯出來,其實是有必要進行平滑的,只要趨勢一致就行,這樣主要利于后問的分析,接下來是先檢測例外資料,這三個關鍵指標理論上應當是相關性較強的,因此可以直接比對趨勢就可以比對出來,并不是單獨對每個關鍵指標用例外檢測演算法去做,就比如說下面這個小區的資料肯定沒有例外,例外檢測如果一定要寫個唬人的,就寫通過設立濾波矩陣去對趨勢例外進行檢測的,還有一個需要注意的是,人們睡覺期間肯定沒有太多的活躍資料,可以單獨對0點到7點進行檢測,用戶和基站資料肯定是比較低的

例外周期好算,如果有兩個以上例外點就可以算例外周期,然后進行例外值修正,如果不想用上面說到的修正方法,哪怕你直接其中一個關鍵指標的趨勢去等比計算也可以
時間周期推薦兩個方法,一個是傅里葉變化的平均時間周期,第二個是混沌理論中的時延(常見的有自相關法、互資訊法、平均位移法等,在matlab混沌時間序列工具箱中都有)
| function T_mean=period_mean_fft(data) %該函式使用快速傅里葉變換FFT計算序列平均周期 %data:時間序列 %T_mean:回傳快速傅里葉變換FFT計算出的序列平均周期 Y = fft(data); %快速FFT變換 N = length(Y); %FFT變換后資料長度 Y(1) = []; %去掉Y的第一個資料,它是data所有資料的和 power = abs(Y(1:N/2)).^2; %求功率譜 nyquist = 1/2; freq = (1:N/2)/(N/2)*nyquist; %求頻率 figure plot(freq,power); grid on %繪制功率譜圖 xlabel('頻率') ylabel('功率') title('功率譜圖') period = 1./freq; %計算周期 figure plot(period,power); grid on %繪制周期-功率譜曲線 ylabel('功率') xlabel('周期') title('周期—功率譜圖') [mp,index] = max(power); %求最高譜線所對應的下標 T_mean=period(index); %由下標求出平均周期 |
第一問也差不多就是確定周期引數和一場資料檢測和處理,來看第二問
注意是每個小區單獨分析,如果有例外就有例外,每例外就別故意增加例外
如果按前面說的找輿情資料,那這個問就比較好做,為什么前面要說如果能用上設備狀態的資料就用,設備的運行,主要有天氣和負載導致的,地理位置都沒給也沒辦法對標天氣資料,分析設備引數與三個關鍵指標的相關性后,如果沒發現相關性較高的設備狀態指標,這里也可以通過基站服務范圍所有用戶的活躍情況來反映,第二問首先是例外預測,在歷史資料中,三個關鍵指標以及一些輿情指標、小區所屬基站的整體三個關鍵指標值,例外點輸出1,正常輸出0,建立一個二分類的模型,為什么還要結合基站來分析,一個基站服務多個小區,就算一個小區看著資料正常,但是也不能保證會因為其他小區導致高過載引起的例外,就例如平時的網路波動,大家在做題目的時候一定是要結合生活實際去分析,在使用演算法算出比較好的結果的同時,也應當具有完善的邏輯
第三問是預測,先對例外處理后的三個關鍵指標資料進行預測,第一問的周期是需要用上的,在混沌時間序列中,時延和周期是其中演算法的輸入引數,也就剛好接上了第一問,這個問可以先用混沌時間序列方法進行預測(RBF神經網路一步預測、RBF神經網路多步預測、Volterra級數一步預測、Volterra級數多步預測等),預測之后再同樣的用第二問做法過一遍,如果預測出資料,接下來還需考慮例外變化量,例外變化量可通過第二問中的程序資料求一個關系式,這里加減就行,最后建議輸出無例外的趨勢和存在例外的趨勢
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340606.html
標籤:其他