糖尿病資料挖掘
- 一理:機器學習量化分析糖尿病致病因子
- 下載:臨床資料
- 線性回歸預測糖尿病
- LightGBM 預測糖尿病
- 糖尿病因子分析
- 變數相關性分析
- 一文:當前科學理解慢病之王的解決方案
- 是什么
- 怎么治療
- 怎么預防
一理:機器學習量化分析糖尿病致病因子
下載:臨床資料
這是一所大學統計系提供的資料:https://statistics.sciences.ncsu.edu/
資料集在審核中,也可以在官網下載,
資料下載:https://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
點擊 the original data set 獲取原資料:
全選,把這些資料復制下來,保存到本地 .txt 檔案,
再從 .txt 檔案中全選,復制到 .excel 檔案,
線性回歸預測糖尿病
最小回歸預測糖尿病論文:https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score,mean_absolute_error, median_absolute_error
from sklearn.model_selection import train_test_split
readFileName="original_data.xlsx" # 原始資料
# readFileName="processed_data.xlsx" # 處理過的資料(提供資料的機構修剪了原始資料,方差不會太大)
# 讀取excel
data=pd.read_excel(readFileName)
X=data.loc[:,"AGE":"S6"]
y=data["y"]
# 劃分訓練集和測驗集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 創建線性回歸物件
regr = linear_model.LinearRegression()
# 使用訓練集訓練模型
regr.fit(X_train,y_train)
# 使用測驗集進行預測
y_pred = regr.predict(X_test)
# 平均絕對誤差:真實值 - 預測值的絕對值,累加,除以樣本量
MAE = mean_absolute_error(y_test,y_pred)
# 中值絕對誤差:倆隊數相減得到差值,求中位數
MedianAE = median_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
dict1 = {"y_predict": y_pred, "y_test": y_test}
df1 = pd.DataFrame(dict1)
df1.to_excel("MAE.xlsx")
print("MAE", MAE)
print("median_absolute_error", MedianAE)
# 解釋方差得分:1 是完美預測
print('r2: %.4f' % r2)
輸出:
original_data
MAE 41.54836328325207
r2: 0.4
LightGBM 預測糖尿病
import lightgbm as lgb
import pandas as pd
from sklearn import model_selection
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error,median_absolute_error
readFileName = "original_data.xlsx" # 原始資料
# readFileName = "processed_data.xlsx" # 處理過的資料(提供資料的機構修剪了原始資料,方差不會太大)
# 讀取excel
data = pd.read_excel(readFileName)
X = data.loc[:, "AGE": "S6"]
y = data["y"]
# 劃分訓練集和測驗集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=42)
# lightgbm
model = lgb.LGBMRegressor()
model.fit(X, y)
y_pred = model.predict(X_test)
MAE = mean_absolute_error(y_test, y_pred)
# 中值絕對誤差
MedianAE = median_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
輸出:
original_data
MAE 14.273899805021866
r2: 0.9
模型提升了 2 倍,
糖尿病因子分析
糖尿病因子分析,如性別,根據統計,男性患病率 9.6%,女性患病率 9.0%,性別差異不大,
反倒是年齡,年齡越大,患病概率越高:
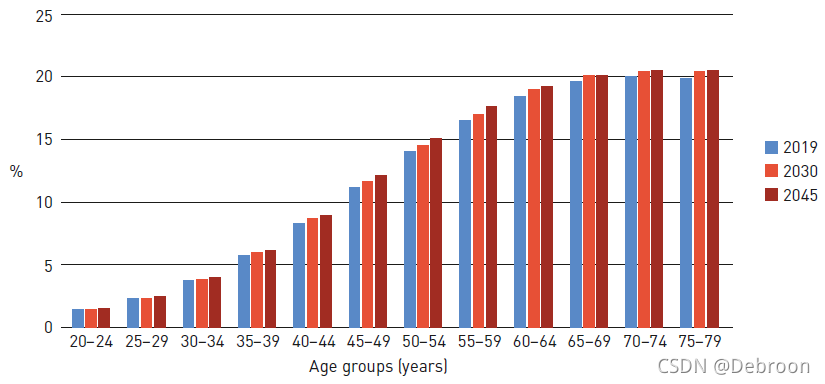
所以,年齡越大,飲食越要控制,減少糖分攝入,
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn import model_selection
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
# readFileName="original_data.xlsx"
readFileName="processed_data.xlsx"
# 讀取excel
data=pd.read_excel(readFileName)
X=data.loc[:,"AGE":"S6"]
y=data["y"]
# 劃分訓練集和測驗集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=42)
# lightgbm
model=lgb.LGBMRegressor(max_depth=13)
# model=lgb.LGBMRegressor()
model.fit(X, y)
y_pred = model.predict(X_test)
# rms = (np.mean((y - y_pred)**2))**0.5
MAE=sum(abs(y_test - y_pred))/len(y_test)
score=1/(1+MAE)
# print ("RF RMS", rms)
print("MAE",MAE)
print("score:",score)
# Explained variance score: 1 is perfect prediction
print('r2: %.4f' % r2_score(y_test,y_pred))
feature_importances=model.feature_importances_
names=X.columns
list_feature_importances=list(zip(feature_importances,names))
df_feature_importances=pd.DataFrame(list_feature_importances)
# df_feature_importances.to_excel("catboost_110變數重要性.xlsx")
df_feature_importances.to_excel("lightgbm變數重要性.xlsx")
n_features=X.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),X.columns)
plt.title("lightgbm feature importance")
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
# plt.savefig("featureImportance_original_data.png")
plt.savefig("featureImportance_processed_data.png")
輸出:
MAE 13.823899600226756
score: 0.06745863281377751
r2: 0.9388
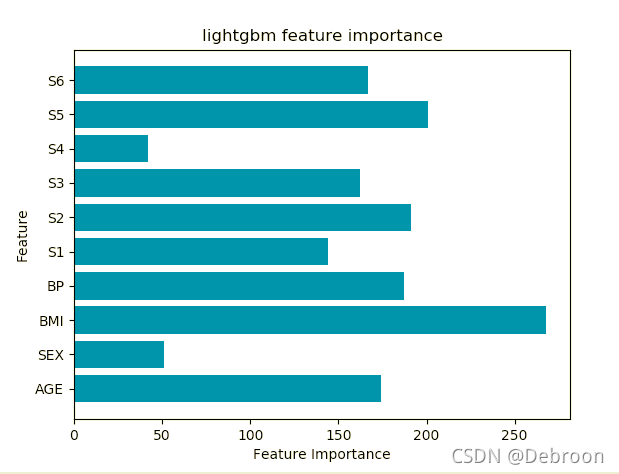
Age(年齡)、性別(Sex)、Body mass index(體質指數)、Average Blood Pressure(平均血壓)、S1~S6一年后疾病級數指標,
影響糖尿病的致病因素,主要是 BMI、S5(血壓)、AGE(年齡),BMI 指數高(肥胖)是導致糖尿病最重要的風險因素,
變數相關性分析
# 變數相關性
def Relation(df1,method,fileName):
# 共線性分析
cor=df1.corr(method)
cor.to_excel("correlation_table.xlsx")
cor.loc[:,:]=np.tril(cor,k=-1)
cor=cor.stack()
# 僅僅列出高相關系數,資料呈現結構化
high_cor=cor[(cor>0.6)|(cor<-0.6)]
# 轉換為dataframe結構
df_high_cor=pd.DataFrame(high_cor)
# 保存到Excel
df_high_cor.to_excel(fileName)
Relation(data,'pearson',"high_correlation_pearson.xlsx") # 資料正態分布
Relation(data,'spearman',"high_correlation_spearman.xlsx") # 資料不是正態分布
完整代碼:
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn import model_selection
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
# readFileName="original_data.xlsx"
readFileName="processed_data.xlsx"
# 讀取excel
data=pd.read_excel(readFileName)
X=data.loc[:,"AGE":"S6"]
y=data["y"]
# 劃分訓練集和測驗集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=42)
# lightgbm
model=lgb.LGBMRegressor(max_depth=13)
# model=lgb.LGBMRegressor()
model.fit(X, y)
y_pred = model.predict(X_test)
# rms = (np.mean((y - y_pred)**2))**0.5
MAE=sum(abs(y_test - y_pred))/len(y_test)
score=1/(1+MAE)
# print ("RF RMS", rms)
print("MAE",MAE)
print("score:",score)
# Explained variance score: 1 is perfect prediction
print('r2: %.4f' % r2_score(y_test,y_pred))
feature_importances=model.feature_importances_
names=X.columns
list_feature_importances=list(zip(feature_importances,names))
df_feature_importances=pd.DataFrame(list_feature_importances)
# df_feature_importances.to_excel("catboost_110變數重要性.xlsx")
df_feature_importances.to_excel("lightgbm變數重要性.xlsx")
n_features=X.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),X.columns)
plt.title("lightgbm feature importance")
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
# plt.savefig("featureImportance_original_data.png")
plt.savefig("featureImportance_processed_data.png")
def Relation(df1,method,fileName):
cor=df1.corr(method)
cor.to_excel("correlation_table.xlsx")
cor.loc[:,:]=np.tril(cor,k=-1)
cor=cor.stack()
# 僅僅列出高相關系數,資料呈現結構化
high_cor=cor[(cor>0.6)|(cor<-0.6)]
df_high_cor=pd.DataFrame(high_cor)
df_high_cor.to_excel(fileName)
Relation(data,'pearson',"high_correlation_pearson.xlsx")
Relation(data,'spearman',"high_correlation_spearman.xlsx")
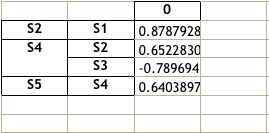
相關性最高的是 S1、S2,
一文:當前科學理解慢病之王的解決方案
中國是重大的慢病市場,糖尿病是慢病之王,
資料來自真實的臨床機構,畢竟機器學習受資料影響,資料不夠量、不夠均衡就會產生偏差,
-
國際糖尿病聯合會:https://idf.org/
-
英國糖尿病組織官網:http://www.diabetes.org.uk/
科學是一個社會行為,所謂科學知識,其實是當前這一代科學家的集體共識,僅此而已,
當前科學理解,是一線科學家窮盡人類目前所有的知識,對一個事物最好的判斷,對科學家來說,它是新研究的出發點和討論的基本線;對一般公眾來說,它可能是認知的天花板,
一般人得病后都喜歡吃貴的補品,鹿茸、虎骨、熊掌、人參、阿膠、海參、魚翅、蟲草,
比如蟲草,而現在整個學術界的共識就是,蟲草不僅沒用,而且可能有害,
如果冬蟲夏草真的沒用,為什么還有那么多人趨之若鶩呢?
如果用博弈論來看,現在的市場就是一個兩因素市場,
要想打破這個均衡,只對少數人科普是不夠的,
第一,互聯網并不是一個是非不分、黑白不明的地方,事實上很多的網站會列舉了冬蟲夏草的種種功效,包括補腎益精、止血化痰、補虛……一直到抑癌抗癌、美容養顏等等一共12 項功能,簡直就是神藥;再加上價格貴,大家都信了,
冬蟲夏草,你知道它沒用,這只是一個因素,這還不足以讓你徹底不買它,
還有一個因素是 “很多人認為它很值錢”,
所以,買冬蟲夏草并不是為了自己吃,而是作為一個貴重禮品送人,人們不一定認同它的功效,但是人們認同它的價格,
除非哪天,社會習俗把 “冬蟲夏草沒用” 變成一個公共知識,以至于送冬蟲夏草就等于是對智商的侮辱才行,
嗨,冬蟲夏草和燕窩等各類補品,就是一個“中國式”大騙局,
每年的九月到第二年四月是金絲燕的繁殖期,這期間,它們用來建巢的唾液很豐富,雌燕和雄燕會一起建巢,就是用唾液和其他東西混合在一起,形成一個杯子狀的窩,
古代人的判斷標準就是物以稀為貴,稀有的吃了就對身體有好處,
于是,懸崖上的燕窩比屋檐下的燕窩吃了更長壽,金絲燕嘔血做出來的血燕窩更是稀奇,于是它就能賣出天價,
中國是印尼燕窩出口的最大目的地,但是印尼當地采燕窩的農民說,根本沒有血燕窩這種東西,
當地有從內地來的黑心商人收購來燕窩后,把燕窩用燕子的糞便再熏蒸五天,這時候,燕窩有些部分會變紅,而后就被當作血燕窩來賣,價格會貴很多,
這些人就是摸準了有相當多的人對什么是健康、什么是營養這方面的認識,還停留在1000年前的水平,才敢這樣下狠手的,
燕窩有什么神奇功效嗎?一個也沒有,
普通功效呢?多吃的話可以解飽、治餓,除此之外就沒有其他特別的了,
其實這個道理也一樣適用于鹿茸、虎骨、熊掌、人參、阿膠、海參、魚翅、蟲草等傳統上認為的滋補品,
因為它們都不是提純過的物質,所以物質結構和大部分生物體差異并不大,
如果要體現出特別的功效,就要把那一點點微不足道的差異放大再放大,放大到和生物體的組成成分截然不同的時候,就有可能不一樣了,
比如,有的人發燒時,啃柳樹皮能退燒,但必須啃春天的,啃秋天的就沒用,
為什么呢?因為水楊酸在春天的柳樹皮中的含量是秋天的幾百倍,也就是說,功效不在柳樹皮,而在水楊酸,你能不能把水楊酸從柳樹皮中提純出來才是關鍵,
你不提純,怎么能期待一種微量物質有什么功效呢?
我們再來看鹿茸、虎骨、熊掌、人參、阿膠、海參、魚翅,它們根本沒有希望成為成功的商品(真的有功效、暢銷全球),
它們之所以依然常見于市場,主要就是生產者利用消費者的無知進行詐騙,
有名人故事做背景,再把功效用古代醫學解釋一番,燕窩自然是很受歡迎的,
中國幾乎沒有燕窩生產,全部依靠進口燕窩,據統計,燕窩總進口量是 80 噸左右,而中國每年燕窩產品的消費是 600 多噸,多出的 520 噸都是什么呢?
燕窩風味飲品,這個道理就像,番茄醬里沒有番茄但也叫番茄醬,椰汁里沒有椰子但也叫椰汁是一樣的,
吃補品對身體可能不僅沒有好處,還有壞處,對身體好的反而是最基礎的規律作息、飲食均衡、合理運動,
是什么
即使是在醫學如此發達的今天,糖尿病仍然是一種幾乎無法根治、無法逆轉的疾病,絕大多數時候,人們能夠期待的最好結果,也無非是“控制”,盡量延緩病情惡化的程度,
最后,糖尿病本身并不致死,但是會引發各種致命的疾病,
這就是所謂的“糖尿病并發癥”,一個糖尿病患者如果得不到很好的治療,幾乎一定會在10年內患上各種各樣的并發癥,這些并發癥不僅可能發生在全身各處,眼睛、雙腳、腎臟、血管、心臟、大腦都有可能;而且非常痛苦難治,甚至連患者的壽命都會受到很大影響,
怎么治療
型糖尿病,本質上都是負責降低血糖的胰島素系統失靈的結果,因此自然而然的,提到糖尿病,人們首先想到的就是胰島素,
在糖尿病治療的市場上,銷售額最大的品類也確實是胰島素,
除此之外,幾乎在全世界所有醫院,任何一個患者被確診 2型糖尿病(分1型、2型,2型居多)后,醫生都會立刻為他開出一張二甲雙胍的處方,每天全世界有超過1億人,使用這種藥物控制血糖,
至少截至目前,二甲雙胍還是一種治療糖尿病的處方藥物,它也有不少副作用需要警惕,比如說,可能會導致腹痛腹瀉、惡心嘔吐等胃腸道反應;再比如說,可能會導致腎功能有問題的人的腎病加重,所以不建議你隨便就去吃,
針對1型糖尿病,我們有各種胰島素藥物,未來還可能擁有升級版的生物胰腺;針對2型糖尿病,我們擁有“神藥”二甲雙胍,也有基于病理研發出來的各類“格列汀”、“格列凈”藥物,
怎么預防
糖尿病的復雜癥狀,其實歸根結底都是血糖上升導致的,
人,就是喜歡甜的;大腦對糖上癮,抵擋不住不是自控力低,而是無法克服人性的本能,
下面幾個方法,既可以不那么痛苦的自律,也不會得糖尿病,
1、一頓飯吃了,土豆、白薯、山藥、蓮藕等,就不要吃米飯,
2、喝飲料時選擇無糖的,
3、吃完整的水果,不要喝果汁,
吃完飯,走路溜達30分鐘,消化一下,正常人稍微控制下,一般不會得糖尿病,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340644.html
標籤:AI
上一篇:814. 二叉樹剪枝