HDFS常用命令及基礎編程
JunLeon——go big or go home

目錄
HDFS常用命令及基礎編程
一、HDFS概述
1、什么是HDFS?
2、HDFS資料存盤模式——資料塊(block)
3、HDFS的副本存放策略及機架感知
(1)副本存放策略:
(2)機架感知:
4、HDFS的讀寫程序
(1)讀流程:
(2)寫流程:
二、HDFS常用命令
1、Hadoop命令
2、HDFS常用命令
3、安全模式
三、HDFS API 基礎編程
1、Eclipse的環境搭建(hadoop插件)
(1)環境準備
(2)環境配置
(3)環境測驗
2、HDFS API
創建專案:
(1)創建新檔案
(2)洗掉檔案
(3)上傳檔案到HDFS指定目錄中
(4)讀取檔案內容
(5)顯示檔案屬性
(6)顯示資料塊資訊
(7)查看DataNode節點資訊
前言:
? Hadoop 分布式檔案系統 (HDFS) 是一種分布式檔案系統,旨在運行在商品硬體上,它與現有的分布式檔案系統有很多相似之處,但是與其他分布式檔案系統的區別是顯著的,HDFS 具有高度容錯性,旨在部署在低成本硬體上,HDFS 提供對應用程式資料的高吞吐量訪問,適用具有大型資料集的應用程式,HDFS 放寬了一些 POSIX 要求,以啟用對檔案系統資料的流式訪問,HDFS 最初是作為 Apache Nutch 網路搜索引擎專案的基礎設施而構建的,HDFS 是 Apache Hadoop Core 專案的一部分,
一、HDFS概述
1、什么是HDFS?
HDFS(Hadoop Distributed File System)分布式檔案系統,是Hadoop平臺的資料存盤系統,大多用于存盤大型的離線資料,
HDFS 具有主/從架構,HDFS 集群由單個 NameNode 組成,NameNode 是一個主服務器,用于管理檔案系統命名空間并管理客戶端對檔案的訪問,此外,還有許多 DataNode,通常集群中的每個節點一個,用于管理連接到它們運行的??節點的存盤,HDFS 公開了一個檔案系統命名空間,并允許將用戶資料存盤在檔案中,在內部,檔案被分成一個或多個塊,這些塊存盤在一組 DataNode 中,NameNode 執行檔案系統命名空間操作,如打開、關閉和重命名檔案和目錄,它還確定塊到 DataNode 的映射,DataNode 負責處理來自檔案系統客戶端的讀寫請求,DataNode 還執行塊的創建、洗掉等操作,
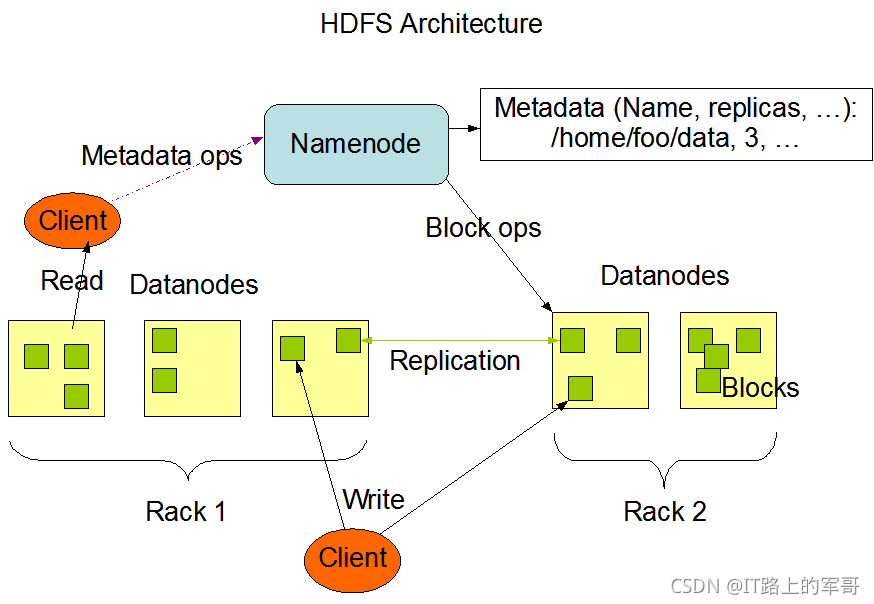
HDFS的Master/Slave架構主要由HDFS Client、NameNode、DataNode和Secondary NameNode四個部分組成,各組件介紹如下:
HDFS Clent:HDFS的客戶端,與NameNode互動的程式,職責或功能如下:
(1)檔案切分:在上傳檔案至HDFS的時候,Client會將檔案分切成一個個的Block上傳;
(2)與NameNode互動,可以獲取檔案的位置資訊(存在哪個節點上);
(3)Client可以通過一些命令來訪問HDFS,比如增刪改查操作;
(4)Client通過一些命令來管理HDFS,比如將NameNode格式化,
NameNode:就是master,負責管理DataNode和管理HDFS的相關資訊:
(1)管理HDFS的名稱空間;
(2)管理副本的策略;
(3)管理資料塊(Block)的映射資訊;
(4)處理客戶端的讀寫請求,
Secondary NameNode:并非是NameNode的熱備,當NameNode掛掉的時候,它并不會立即替換NameNode并提供服務,
(1)輔助NameNode,分擔其作業量,比如定期合并FsImage和Edits,并將合并后的FsImage.checkPoint推送給NameNode;
(2)在緊急情況下可以輔助恢復NameNode,
DataNode:就是slave,NameNode下達指令,DataNode執行實際的操作:
(1)存盤實際的資料塊;
(2)執行資料塊的讀/寫操作,
2、HDFS資料存盤模式——資料塊(block)
HDFS主要以資料塊(block)的模式對資料進行存盤,
在Hadoop2.0以前,默認資料塊大小為64Mb;Hadoop2.0以后版本默認資料塊大小為128Mb, block大小可以通過配置引數(dfs.blocksize)來設定,
采用資料塊的模式存盤資料的優點:
支持大規模檔案存盤:一個很大的檔案可以被拆分為若干檔案塊,不同的檔案塊可以被分發到不同的節點上,因此一個檔案的大小不會受單個節點的存盤容量的限制,
簡化系統設定:首先,簡化存盤管理,因為檔案大小是固定的,這樣就很容易算出一個節點可以存放多少檔案塊,其次,簡化元資料的管理,元資料不需要和檔案塊一起存盤,
適合資料備份:每個檔案塊都可以冗余地存盤到多個節點上
3、HDFS的副本存放策略及機架感知
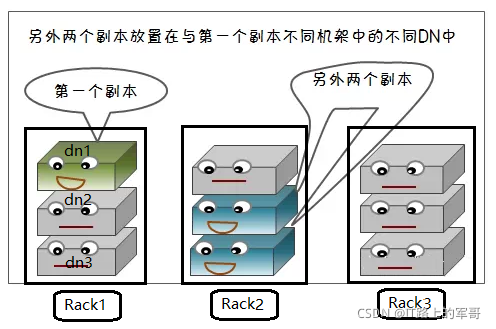
HDFS檔案系統中,默認的副本存放數量為3,在寫入資料是會自動的進行備份,副本數量可在hdfs-site.xml中(dfs.replication)來設定,
(1)副本存放策略:
1、第一個副本存盤在本機(本地節點),這里所說的本地節點是相對于客戶端來說的,也就是說某一個用戶正在用一個客戶端來向HDFS中寫資料,如果該客戶端上有資料節點,那么就應該最優先考慮把正在寫入的資料的一個副本保存在這個客戶端的資料節點上,它即被看做是本地節點,
2、第二個副本塊存跟本機不同機架內的任意服務器節點,
3、第三個副本塊存與第二個副本所在節點同一機架最近的另一個節點上,
作用:保證對該block所屬檔案的訪問能夠優先在本rack下找到,如果整個rack發生了例外,也可以在另外的rack上找到該block的副本,這樣足夠的高效,并且同時做到了資料的容錯,這種策略設定可以將副本均勻分布在集群中,有利于當組件失效的情況下的均勻負載,
(2)機架感知:
通常,大型Hadoop集群會分布在很多機架上,在這種情況下,
? ——希望不同節點之間的通信能夠盡量發生在同一個機架之內,而不是跨機架,
? ——為了提高容錯能力,名稱節點會盡可能把資料塊的副本放到多個機架上,
綜合考慮這兩點的基礎上Hadoop設計了機架感知功能
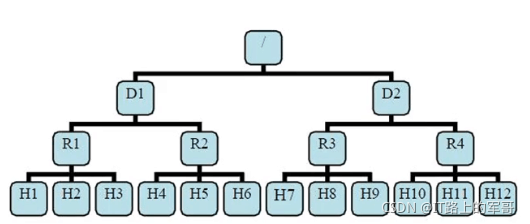
有了機架感知,NameNode就能夠畫出上圖所看到的的datanode網路拓撲圖,D1,R1都是交換機,最底層是datanode,
則H1的rackid=/D1/R1/H1,H1的parent是R1,R1的parent是D1,這些rackid資訊能夠通過topology.script.file.name配置,有了這些rackid資訊就能夠計算出隨意兩臺datanode之間的距離,
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode4、HDFS的讀寫程序
(1)讀流程:
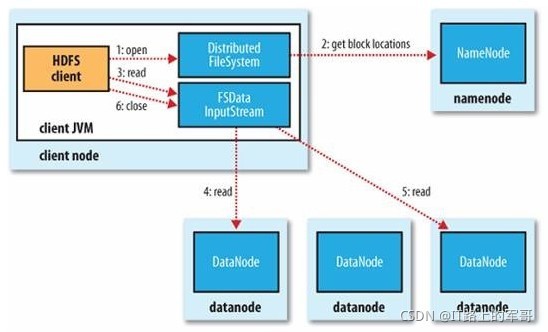
讀詳細步驟:
1、client訪問NameNode,查詢元資料資訊,獲得這個檔案的資料塊位置串列,回傳輸入流物件,
2、就近挑選一臺datanode服務器,請求建立輸入流 ,
3、DataNode向輸入流中中寫資料,以packet為單位來校驗,
4、關閉輸入流
(2)寫流程:

寫詳細步驟:
1、客戶端向NameNode發出寫檔案請求,
2、檢查是否已存在檔案、檢查權限,若通過檢查,直接先將操作寫入EditLog,并回傳輸出流物件,
(注:WAL,write ahead log,先寫Log,再寫記憶體,因為EditLog記錄的是最新的HDFS客戶端執行所有的寫操作,如果后續真實寫操作失敗了,由于在真實寫操作之前,操作就被寫入EditLog中了,故EditLog中仍會有記錄)
3、client端按128MB的塊切分檔案,
4、client將NameNode回傳的DataNode串列和Data資料一同發送給最近的第一個DataNode節點,此后client端和多個DataNode構成pipeline管道,
client向第一個DataNode寫入一個packet,這個packet便會在pipeline里傳給第二個、第三個…DataNode,
在pipeline反方向上,逐個發送ack(命令正確應答),最終由pipeline中第一個DataNode節點將ack發送給client,
5、寫完資料,關閉輸輸出流.
6、發送完成信號給NameNode,
二、HDFS常用命令
1、Hadoop命令
| 命令名稱 | 命令格式 | 作用 |
|---|---|---|
| -help | hadoop -help | 查看hadoop命令的使用資訊 |
| version | hadoop version | 查看hadoop的版本資訊 |
| jar | hadoop jar project.jar Class.main | 運行jar檔案 |
| fs | hadoop fs commond | 操作HDFS檔案系統 |
| namenode -format | hadoop namnode -format | 格式化NameNode |
示例:
hadoop -help # 幫助命令,查看hadoop命令詳情
hadoop version # 查看hadoop版本資訊
hadoop jar jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar #運行自帶的測驗包
hadoop namenode -format # 格式化NameNode,這個命令在啟動HDFS前已經執行過2、HDFS常用命令
HDFS操作命令也可用: hdfs dfs [-command]
| 命令名稱 | 命令格式 | 作用 |
|---|---|---|
| -cat | hadoop fs -cat <hdfs:pathFile> | 查看HDFS檔案系統里的檔案內容 |
| -ls | hadoop fs -ls <hdfs:path> | 查看HDFS檔案系系統的目錄 |
| -mkdir | hadoop fs -mkdir <hdfs:pathDir> | 創建HFDS的目錄 |
| -rm | hadoop fs -rm <hdfs:pathFile> | 洗掉HDFS中的檔案或目錄 |
| -cp | hadoop fs -cp <hdfs:pathFile> | 復制HDFS中的檔案或目錄 |
| -mv | hadoop fs -mv <hdfs:pathFile> | 移動HDFS中的檔案或目錄 |
| -put | hadoop fs -put <loacl:pathfile > <hdfs:pathFile> | 將本地檔案或目錄進行上傳到HDFS |
| -copyFormLocal | hadoop fs -copyFormLocal <loacl:pathfile > <hdfs:pathFile> | 同上,類似于put命令 |
| -get | hadoop fs -get <hdfs:pathFile> <loacl:pathfile > | 將HDFS的檔案下載到本地 |
| -copyToLocal | hadoop fs -copyToLocal <hdfs:pathFile> <loacl:pathfile > | 同上,類似于get命令 |
| -du | hadoop fs -du <hdfs:pathFile> | 顯示HDFS中的檔案或目錄的大小 |
| -dus | hadoop fs -dus <hdfs:pathFile> | 顯示HDFS中的指定目錄的大小 |
| -touchz | hadoop fs -touchz <hdfs:pathFile> | 創建一個0位元組的空檔案 |
| -text | hadoop fs -text <hdfs:pathFile> | 將源檔案輸出為文本格式,允許的格式是zip和TextRecordInputStream, |
部分命令示例:
hadoop fs -ls / # 查看HDFS的根目錄
hadoop fs -ls -R / #遞回查看HDFS的根目錄/
hadoop fs -mkdir /data # 在HDFS中創建一個data目錄
hadoop fs -touchz /data/a.txt # 在HDFS的/data目錄下創建一個0位元組的空檔案a.txt
hadoop fs -cp /data/a.txt /data/b.txt #將/data目錄下的a.txt復制一份在當前目錄重命名為b.txt
hadoop fs -mv /data/a.txt / # 將HDFS的/data目錄下的a.txt移動到HDFS的根目錄
hadoop fs -cat /a.txt # 查看HDFS根目錄下的a.txt,由于剛剛創建的是空檔案,顯示沒有內容,可查看其他檔案
hadoop fs -get /a.txt /~ # 將HDFS根目錄下的a.txt下載到本地/home目錄(本地指的是虛擬機)
hadoop fs -put /~/a.txt /data/ # 將家目錄下的a.txt上傳到HDFS中的data目錄下3、安全模式
NameNode在啟動時會自動進入安全模式,安全模式是NameNode的一種狀態,在這個階段,檔案系統不允許有任何修改,
系統顯示Name node in safe mode,說明系統正處于安全模式,這時只需要等待幾十秒即可,也可通過下面的命令退出安全模式:
hadoop dfsadmin -safemode leave也可以進入安裝模式:
hadoop dfsadmin -safemode enter三、HDFS API 基礎編程
1、Eclipse的環境搭建(hadoop插件)
(1)環境準備
java下載并安裝:(安裝程序略)
java版本: jdk-8u91-windows-x64
官網下載:Java Downloads | Oracle
百度云下載:鏈接:https://pan.baidu.com/s/1rCd7LHGyc3oMk0SFc95DEg 提取碼:8888
Eclipse下載并安裝:(安裝程序略)
官網下載:http://www.eclipse.org/downloads/packages/
Hadoop下載并解壓:
官網下載:Index of /dist/hadoop/common/hadoop-2.7.3
基于Eclipse的Hadoop插件下載:
百度云 鏈接:https://pan.baidu.com/s/1nCCNgzKvy70X3LUKEex_IA 提取碼:8888
(2)環境配置
配置java環境變數:
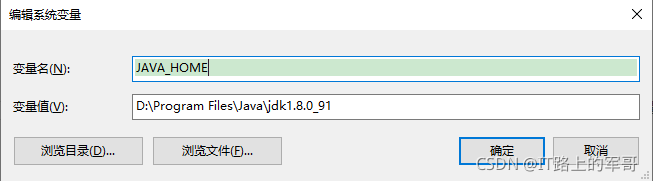
1、右鍵單擊桌面 我的電腦/此電腦-->屬性-->找到高級系統設定-->環境變數-->下面的系統變數-->新建變數
JAVA_HOME=D:\Program Files\Java\jdk1.8.0_91 (自己安裝的路徑)
新建變數,如圖:
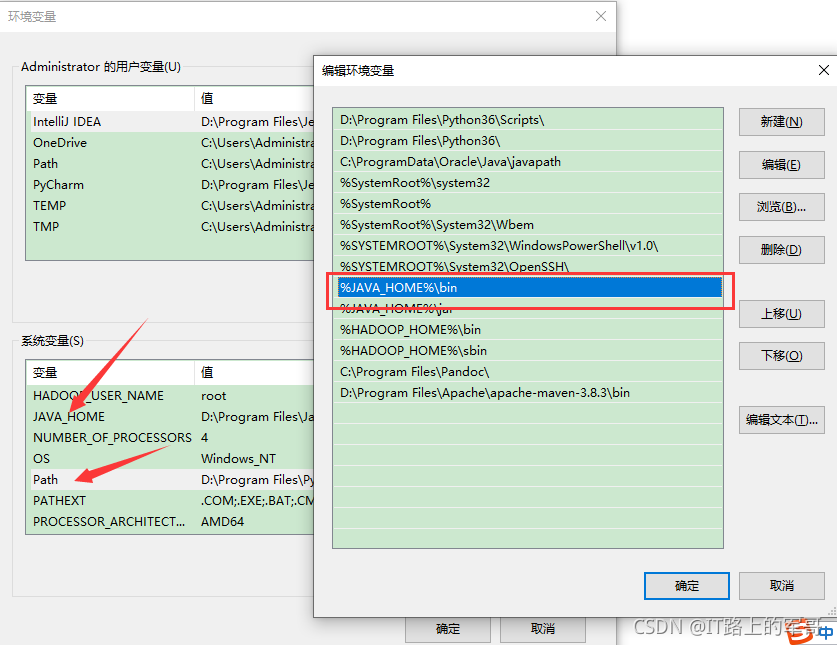
2、找到Path,添加 %JAVA_HOME%\bin
配置hadoop環境變數:
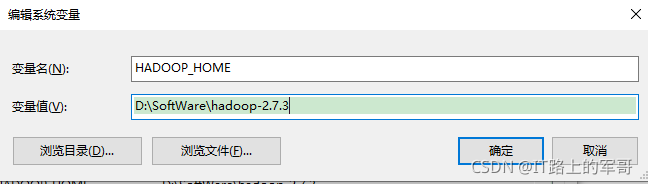
1、右鍵單擊桌面 我的電腦/此電腦-->屬性-->找到高級系統設定-->環境變數-->系統變數-->新建變數
HADOOP_HOME=D:\SoftWare\hadoop-2.7.3 (自己安裝的路徑)
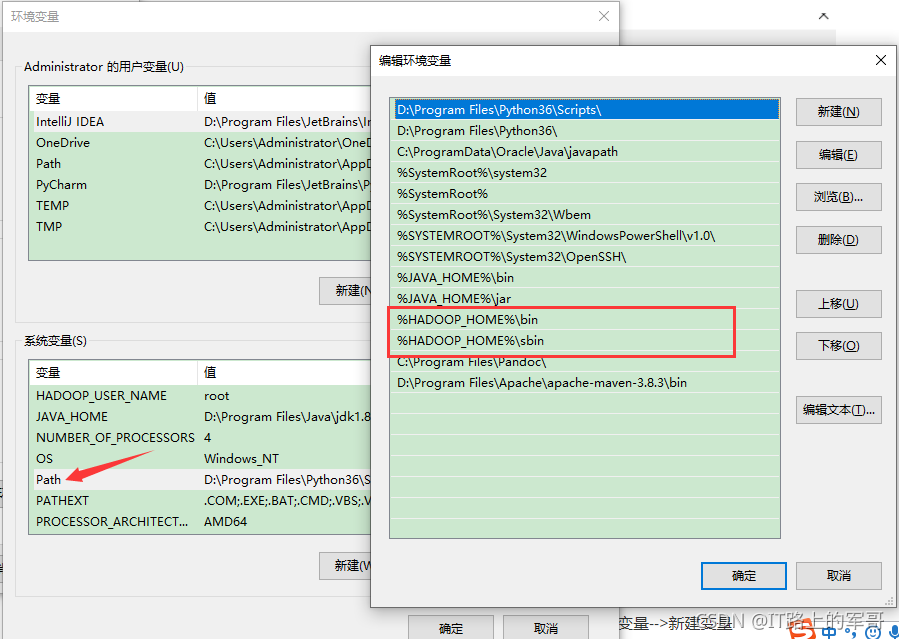
2、找到Path,添加 %HADOOP_HOME%\bin、%HADOOP_HOME%\sbin
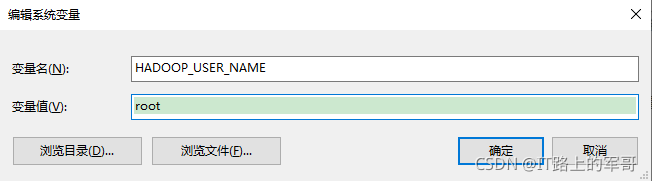
配置Hadoop用戶名:HADOOP_USER_NAME
右鍵單擊桌面 我的電腦/此電腦-->屬性-->找到高級系統設定-->環境變數-->系統變數-->新建變數
添加變數:HADOOP_USER_NAME=root
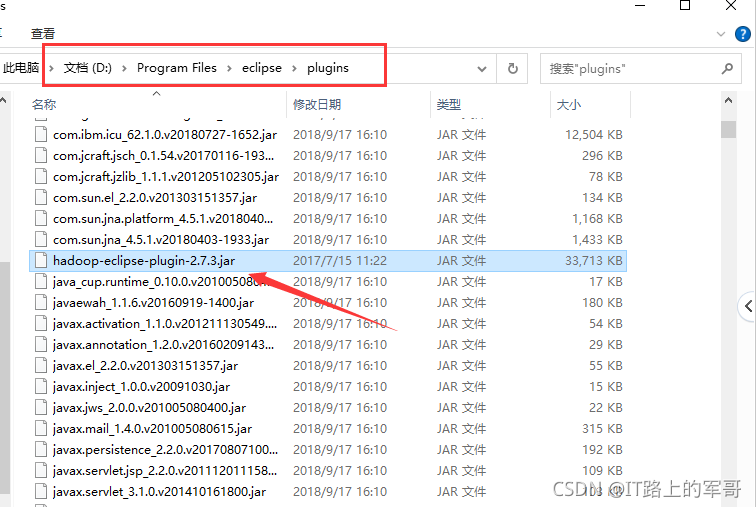
配置hadoop-eclipse插件:
1、將下載好的hadoop-eclipse-plugin-2.7.3.jar復制到eclipse的plugins目錄下
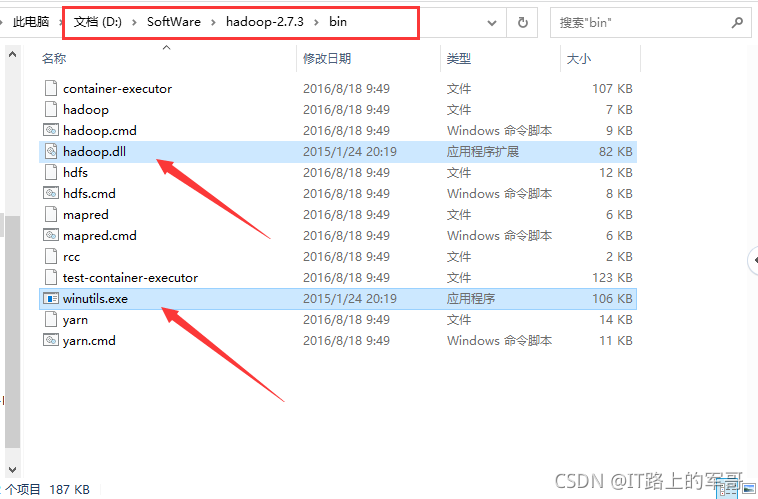
2、將下載好的hadoop.dll和winutils.exe復制到hadoop的bin目錄下
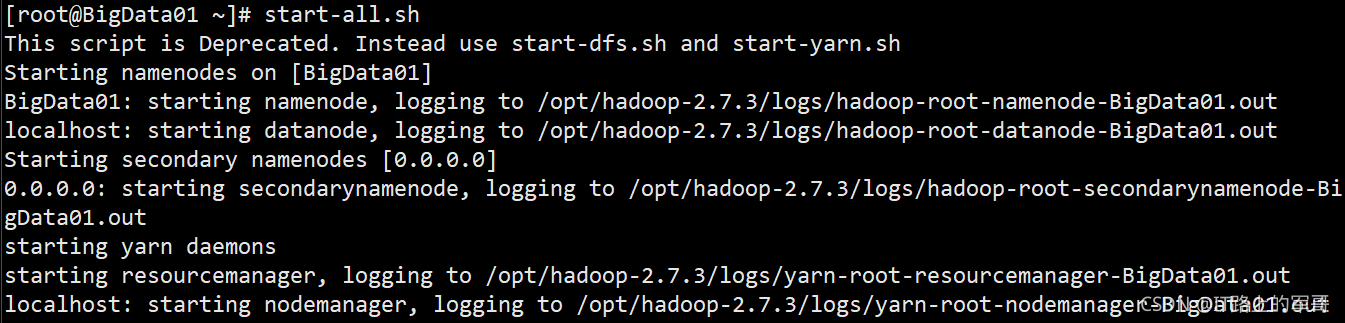
(3)環境測驗
1、在Hadoop偽分布式或者分布式上先開啟HDFS節點(可以先在Web端進行訪問)
開啟節點:(偽分布式)
Web端訪問:
在瀏覽器里輸入ip:50070即可訪問到DHFS主頁
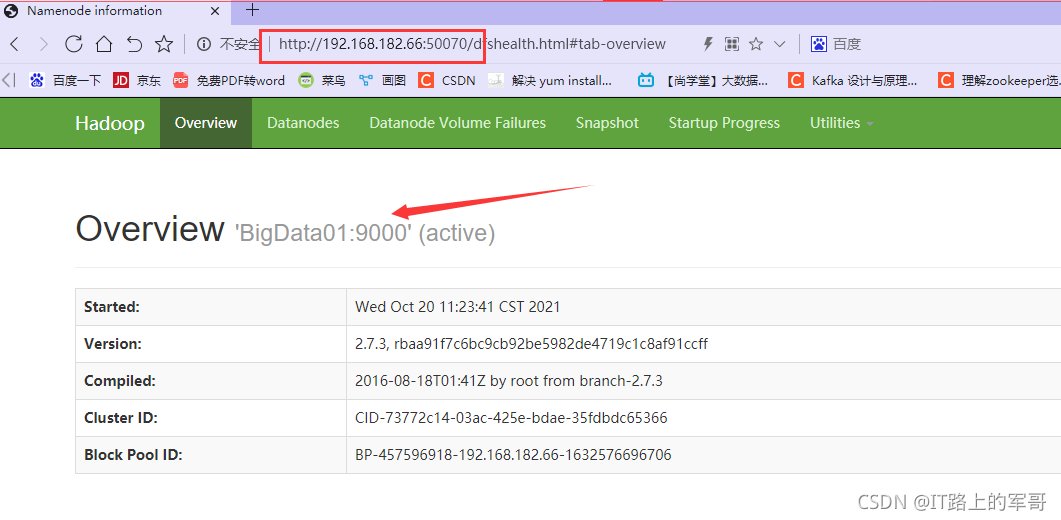
2、在Eclipse中連接到HDFS
啟動 Eclipse 后就可以在左側的Project Explorer中看到DFS Locations
注:如果沒有DFS Locations顯示項則直接創建MapReduce專案打開新的視圖后會出現

選擇 Window 選單下的 Preference
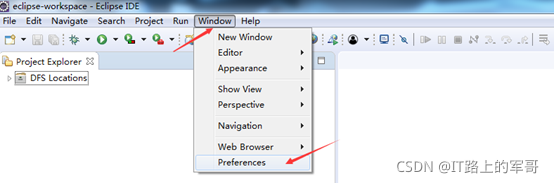
此時會彈出一個表單,點擊選擇 Hadoop Map/Reduce 選項,選擇 Hadoop 的安裝目錄(例如:D:\SoftWare\hadoop-2.7.3)
切換 Map/Reduce 開發視圖
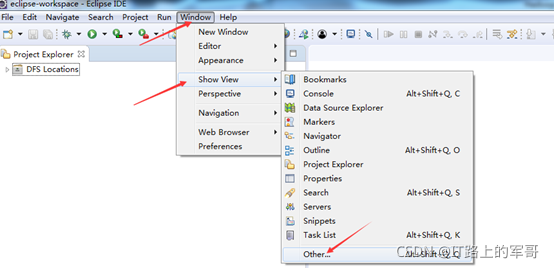
選擇Other中,找到MapReduce Tools-->MapReduce Location

在下面既可以看到 MapReduce Location ,開始連接HDFS:

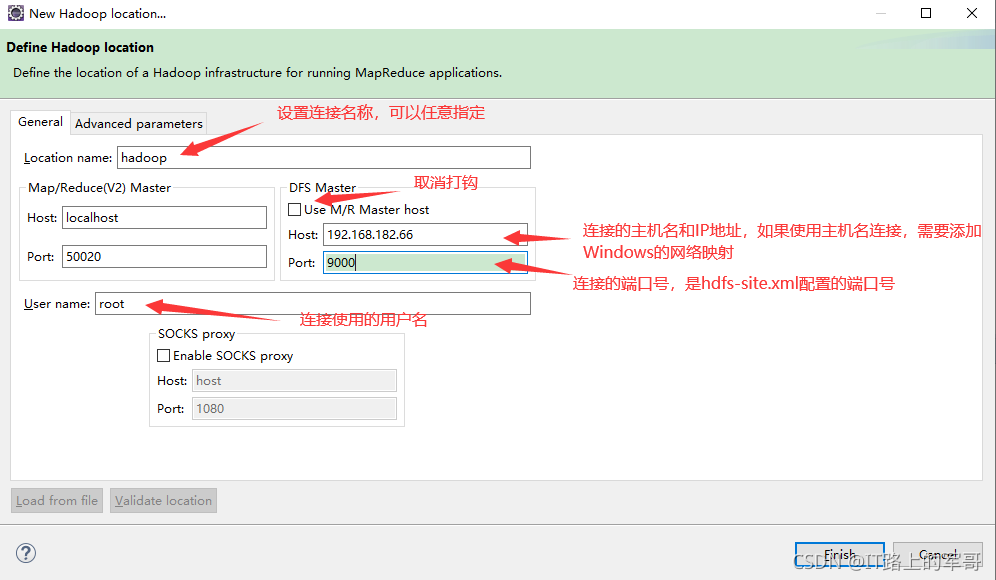
在彈出來的General選項面板中,General 的設定要與 Hadoop主機的配置一致,
Location Name:隨意填寫
DFS Master:
偽分布式:
Host:設定你的主機名,也可以為 IP地址(建議用IP,用主機名需要在Windows中配網路映射)
Port 改為 9000,(此埠和hadoop里core-site.xml中設定的埠號一致,有人配置為8020,則改為8020)
Map/Reduce(V2) Master: Host和Port 用默認的即可
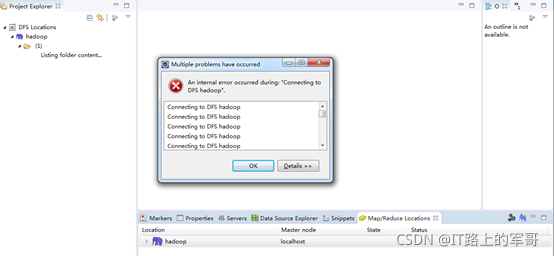
如果出現以下錯誤:是因為Windows下沒有給主機名hadoop配置網路映射
Windows中網路組態檔c:/windows/system32/drivers/etc/hosts
在hosts檔案末尾添加:192.168.182.66 hadoop
連接成功后:
2、HDFS API
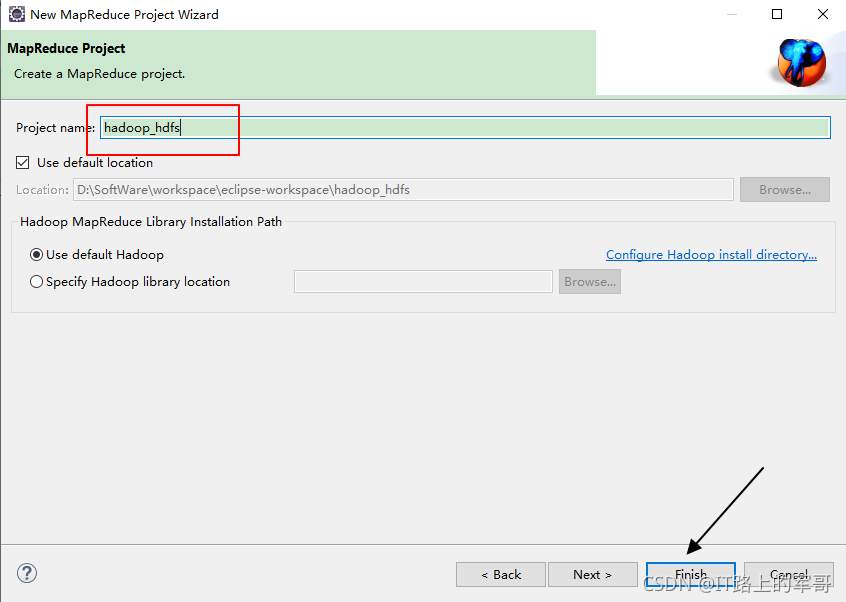
創建專案:
1.在eclipse中,File --> New --> Project 
找到Map/Reduce --> MapReduce Project
下一步:輸入專案名,完成
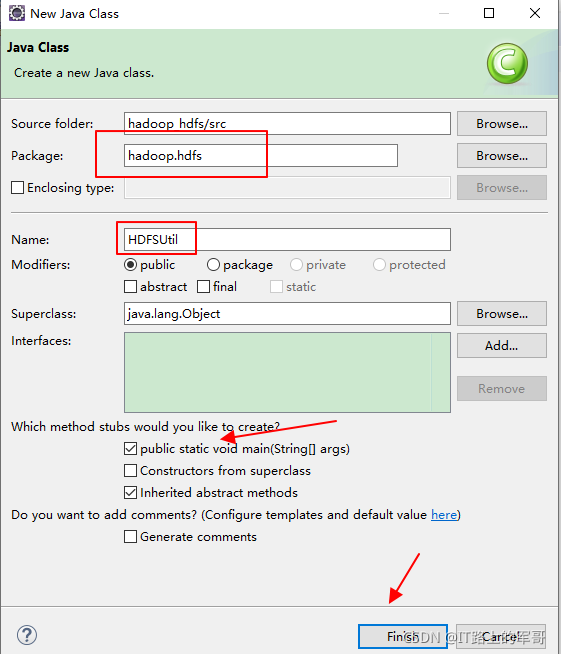
在專案中src下創建類并創建包:
HFDS API:
main函式中的呼叫:
public static void main(String[] args) throws IOException {
//在集群上創建新檔案,并寫入字符內容,如下:
//如果工程里沒有加入core-site.xml、hdfs-site.xml,則下面引數中的檔案名前必須指定 HDFS通信地址 (如:hdfs://IP:埠號/ )
//創建一個新檔案hello.txt
createFile("hdfs://192.168.182.66:9000/hello.txt", "Hello world! Welcome to learn Hadoop! HDFS, Mapreduce!\n");
//讀取hello.txt檔案內容
readFile("hdfs://192.168.182.66:9000/hello.txt");
//上傳檔案
//uploadFile("D:\\a.txt","hdfs://192.168.182.66:9000/a.txt");
//顯示檔案屬性詳情
showFile("hdfs://192.168.182.66:9000/hello.txt",true);
//查看資料塊資訊
showLocation("hdfs://192.168.182.66:9000/hello.txt/hello.txt");
//獲取集群上的節點資訊
showDataNodeName();
//洗掉指定檔案hello.txt
//deleteFile("hdfs://192.168.182.66:9000/hello.txt/hello.txt");
}注:單個呼叫方法時,請把其他方法注釋掉
(1)創建新檔案
public static void createFile(String dstPath, byte[] contents) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建一個檔案系統物件
Path dst = new Path(dstPath); //將傳入的dstPath轉換為path物件
FSDataOutputStream outputStream = fs.create(dst); //創建指定檔案
outputStream.write(contents); //將位元組陣列的內容寫入檔案
outputStream.close(); //關閉輸出流
fs.close(); //關閉檔案系統
System.out.println("檔案創建成功!");
}
public static void createFile(String dstPath,String contents) throws IOException {
byte[] buffer = contents.getBytes(); //檔案內容-->位元組陣列
createFile(dstPath,buffer);
}
以上代碼還可以優化成一個方法:(上下兩種代碼選擇一種即可)
public static void createFile(String dstPath, String contents) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建一個檔案系統物件
Path dst = new Path(dstPath); //將傳入的dstPath轉換為創建path物件
FSDataOutputStream outputStream = fs.create(dst); //創建指定檔案
byte[] buffer = content.getBytes(); //檔案內容--位元組陣列
outputStream.write(buffer,0,buffer.length); //將位元組寫入
outputStream.close(); //關閉輸出流
fs.close(); //關閉檔案系統
System.out.println("檔案創建成功!");
}(2)洗掉檔案
//HDFS中洗掉指定的檔案
public static void deleteFile(String filePath) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建檔案系統
Path path = new Path(filePath); //將傳入的filePath轉換為Path物件
boolean isOk = fs.deleteOnExit(path); //呼叫deleteOnExit方法洗掉檔案,并將回傳的狀態賦值給boolean變數
if(isOk) { //判斷檔案是否洗掉
System.out.println("檔案已被洗掉!");
}else {
System.out.println("洗掉檔案失敗!");
}
}(3)上傳檔案到HDFS指定目錄中
//從本地上傳檔案到HDFS
public static void uploadFile(String src,String dst) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建檔案系統
Path srcPath = new Path(src); //實體化本地檔案路徑
Path dstPath = new Path(dst); //實體化上傳后的HDFS路徑
fs.copyFromLocalFile(srcPath, dstPath); //呼叫copyFromLocalFile方法將本地檔案上傳
FileStatus[] fileStatus = fs.listStatus(dstPath); //創建一個FileStatus型別陣列接收指定檔案的屬性
for (FileStatus file : fileStatus) { //遍歷陣列
System.out.println("HDFS中目標檔案路徑" + file.getPath()); //列印輸出該檔案的路徑屬性
System.out.println("上傳檔案成功!");
}
}(4)讀取檔案內容
//讀取HDFS中指定檔案的內容
public static void readFile(String filePath) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建檔案系統
Path path = new Path(filePath); //實體化檔案路徑
FSDataInputStream inputStream = null;
try{
inputStream = fs.open(path);
IOUtils.copyBytes(inputStream, System.out, 4096, false);
} finally {
IOUtils.closeStream(inputStream);
}
}(5)顯示檔案屬性
public static void showFile(String filePath,boolean isDetail) throws IOException {
Configuration conf = new Configuration(); //獲取組態檔
FileSystem fs = FileSystem.get(conf); //創建檔案系統
Path path = new Path(filePath); //創建一個路徑地址
FileStatus dstStatus = fs.getFileStatus(path); //創建檔案屬性物件
if(dstStatus.isDirectory()) { //判斷是否是一個目錄
System.out.println("這是一個目錄,目錄下的檔案及子目錄有:");
for (FileStatus file : fs.listStatus(path)) { //遍歷屬性串列
if(isDetail) { //判斷是否列印輸出檔案的詳細資訊
System.out.println((file.isDirectory() ? "d" : "-") +
file.getPermission().toShort() + " " + //獲取指定檔案的權限
file.getOwner() + "\t" + //獲取指定檔案的所有者
file.getGroup() + "\t" + //獲取指定檔案的所屬組
file.getLen() + "\t" + //獲取指定檔案的長度
new TimeStamp(file.getModificationTime()).toString() + "\t" + //獲取指定檔案修改時間
file.getPath().toString() //獲取檔案的路徑
);
} else {
System.out.println(file.getPath().toString()); //只輸出檔案路徑屬性
}
}
}
}(6)顯示資料塊資訊
private static void showLocation(String path) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf); //獲取組態檔
Path dst = new Path(path);
FileStatus filestatus = fs.getFileStatus(dst);
BlockLocation[] locations = fs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
//可能存在多個節點
for(int i=0; i<locations.length; i++){
String[] host = locations[i].getHosts();
for(int j=0; j<host.length; j++){
System.out.println("block_"+i+": "+host[j]);
}
}
}(7)查看DataNode節點資訊
private static void showDataNodeName() throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf); //獲取組態檔
DistributedFileSystem hdfs = (DistributedFileSystem) fs; //創建分布式檔案系統物件
//獲取各資料節點資訊
DatanodeInfo[] dataNodeStatus = hdfs.getDataNodeStats();
for(int i=0; i<dataNodeStatus.length; i++){
System.out.println("DataNode_Name: "+dataNodeStatus[i].getHostName());
System.out.println("DataNode_IP: "+dataNodeStatus[i].getIpAddr());
System.out.println("DataNode_IpcPort: "+dataNodeStatus[i].getIpcPort());
}
}下一篇:MapReduce初級編程實踐(超詳細)
如果你喜歡、對你有幫助,點贊+收藏,跟著軍哥學知識……
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/340687.html
標籤:其他