最近導師讓我做并行多任務學習方面的作業,我開始著手閱讀這方面的論文并歸納一個大致的速覽,首先,我們看看什么是多任務學習,然后我們主要聚焦于基于正則化的多任務學習方法(這也是目前學術界主要的并行物件),并在此基礎上討論如何分布式并行,
1、多任務學習介紹
類似于遷移學習,多任務學習也運用了知識遷移的思想,即在不同任務間泛化知識,但二者的區別在于:
- 遷移學習可能有多個源域;而多任務學習沒有源域而只有多個目標域,
- 遷移學習注重提升目標任務性能,并不關心源任務的性能(知識由源任務\(\rightarrow\)目標任務;而多任務學習旨在提高所有任務的性能(知識在所有任務間相互傳遞),
下圖從知識遷移流的角度來說明遷移學習和多任務學習之間的區別所示:
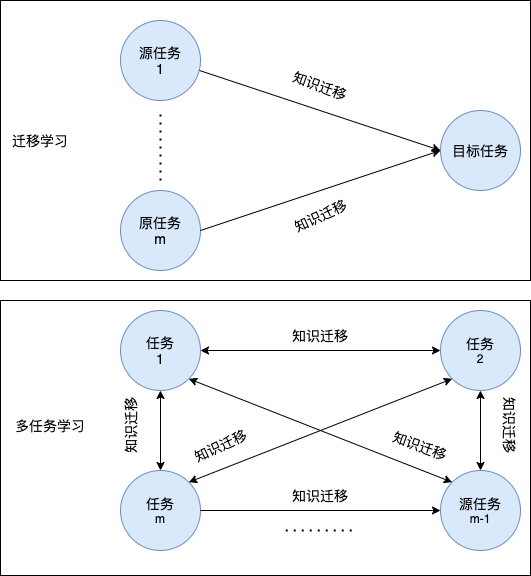
不嚴格地說,多任務學習的目標為利用多個彼此相關的學習任務中的有用資訊來共同對這些任務進行學習(一般會將各任務的損失函式加起來一起優化),
形式化地,多任務學習的定義如下:給定\(T\)個學習任務\(\{\mathcal{T}_t\}_{t=1}^{m}\),其中所有任務或者其中某些任務是相關的但不相同,多任務學習旨在利用這\(T\)個任務中的知識來提高所有\(\mathcal{T}_t\)的學習性能,
多任務學習按照學習任務性質不同可分為多任務監督學習、多任務無監督學習、多任務主動學習、多任務強化學習、多任務在線學習等,下面我們僅介紹最常見的多任務監督學習,
多任務監督學習每個任務都是監督學習,目的是學習樣本到標簽的的映射, 形式化地說,給定\(t\)個監督學習的任務\(\{\mathcal{T}_t\}_{t=1}^T\),每個任務各有一個訓練集\(\mathcal{D}_t = {\{(\bm{x}_{ti}, y_{ti})}_{i=1}^{m_t}\}\),其中\(\bm{x_{ti}} \in \mathbb{R}^{d}\),\(y_{ti} \in \mathbb{R}\),多任務學習的目標是根據\(T\)個任務的訓練集學習\(T\)個函式\(\{f_t(\bm{x})\}_{t=1}^{T}\),使得\(f_t(\bm{x}_{ti})\)可以很好的近似\(y_{ti}\),學習完成后,\(f_t(\cdot)\)將用于對第\(t\)個任務中的新資料樣本的標簽進行預測,
接下來我們描述多任務學習的目標函式,若第\(t\)個任務的經驗風險形式為\(\mathbb{E}_{(\bm{x_{ti}, y_{ti})\sim \mathcal{D}_t}}[L(y_{ti}, f(\bm{x}_{ti};\bm{w}_t))]\)(設\(\bm{w}_t\)為第\(t\)個模型的引數),則一般多任務學習的目標函式形式為
(此處\(\textbf{W}=(\bm{w}_1,\bm{w}_2,...,\bm{w}_T)\)為所有任務引數構成的矩陣)
不過,如果我們直接對各任務的損失函式和\(\sum_{t=1}^{T} [\frac{1}{m_t}\sum_{i=1}^{m_t}L(y_{ti}, f(\bm{x}_{ti}))]\)進行優化,我們發現不同任務的損失函式是解耦(decoupled)的,無法完成我們的多任務學習任務,在多任務學習中一種典型的方法為增加一個正則項[1][2][3]:
\[\begin{aligned} \underset{\textbf{W}}{\min} & \sum_{t=1}^{T} [\frac{1}{m_t}\sum_{i=1}^{m_t}L(y_{ti}, f(\bm{x}_{ti}; \bm{w}_t))]+\lambda g(\textbf{W})\\ & = f(\textbf{W}) + \lambda g(\textbf{W}) \end{aligned} \]這里\(g(\textbf{W})\)編碼了任務的相關性(多任務學習的假定)并結合了\(T\)個任務;\(\lambda\)是一個正則化引數,用于控制有多少知識在任務間共享,在許多論文中,都假設了損失函式\(f(\textbf{W})\)是凸的,且是\(L\text{-Lipschitz}\)可導的(對\(L>0\)),然而正則項\(g(\textbf{W})\)雖然常常不滿足凸性(比如采用矩陣的核范數),但是我們認為其實接近凸的,可以采用近端梯度演算法(proximal gradient methods)[4]來求解,
2、多任務監督學習
多任務監督學習的關鍵是找到任務之間的相關性,根據找到的任務相關性不同,可分為基于特征的多任務監督學習、基于模型的多任務監督學習和基于樣本的多任務監督學習,下面我們主要介紹基于特征和基于模型的這兩種,
(1)基于特征的多任務監督學習的分類
特征變換: 即通過線性/非線性變換由原始特征構建共享特征表示,這種方法最招可追溯到使用多層前饋網路(Caruana, 1997)[5],如下圖所示:
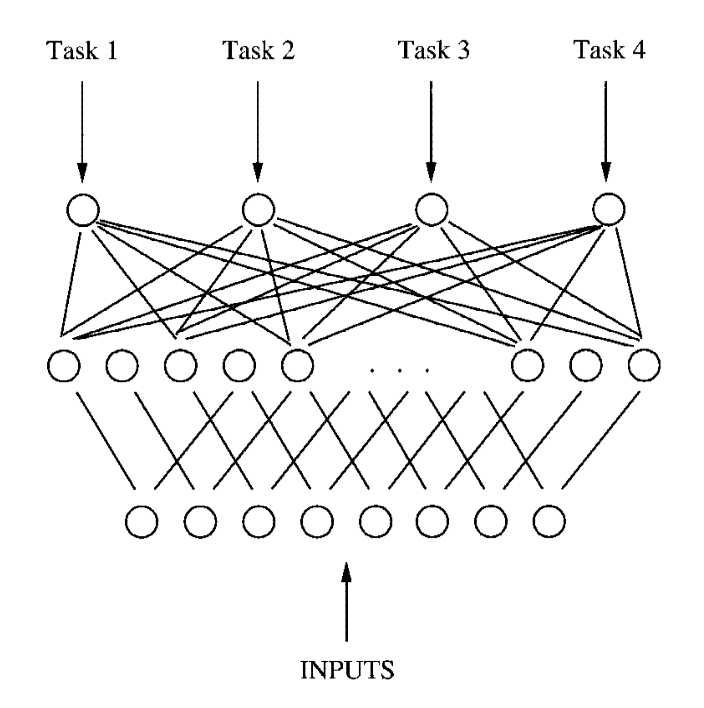
該示例中,假設所有任務的輸入相同,將多層前饋網路的隱藏層輸出視為所有任務共享的特征表示,將輸出層的輸出視為對\(T\)個任務的預測結果,
如果采用我們之前所提到的正則化框架,多任務特征學習(Multi-Task Feature Learning, MTFL)方法[6][7](Argyrious等人,2006、2008)和多任務稀疏編碼(Multi-Task Sparse Coding, MTSC)[8]方法(Maurer等, 2013)都通過酉變換\(\hat{\bm{x}}_{ti}= \textbf{U}^T\bm{x}_{ti}\)來為每個任務先構造共享特征表示, 再在此基礎上為每個任務學習線性函式\(f_t(\bm{x}_{ti})=\langle \bm{a}_t, \hat{\bm{x}}_{ti} \rangle\),設每個\(f_t(\bm{x}_{ti})\)的引數為\(\bm{a}_{t}\),設線性函式的引數矩陣為\(\textbf{A}=(\bm{a}_1,...,\bm{a}_T)\), 該方法定義的優化問題表示如下:
這里\(\mathbf{U} \in \mathbb{R}^{d \times d}\)是酉(正交)矩陣,
與MTFL不同, MTSC方法的目標函式定義為
此時\(\mathbf{U}^T \in \mathbb{R}^{d^{'}\times d}(d^{'}<d)\),除了學習共享特征表示之外,還會起到降維的作用,\(d^{'}\)為降維后的新特征維度,此外我們通過\(l_1\)約束使\(\mathbf{A}\)是稀疏的,
聯合特征學習(joint feature learning):通過特征選擇得到原始特征的共享子集(shared feature subset),以做為共享的特征表示,我們常采用的方法是將引數矩陣\(\textbf{W}=(\bm{w}_1,...,\bm{w}_T)\)正則化使其稱為行稀疏矩陣,從而去除特定特征對于線性模型預測的影響,只有對所有任務都有用的特征被保留,
所有正則化方法中,最廣泛使用的是\(l_{p, q}\)正則化(即采用\(l_{p, q}\)范數做為正則項),其目標函式為:
\(l_{p, q}\)正則化的特例是\(l_{2, 1}\)[9][10](Obozinski等人,2006、2010)和\(l_{\infin}\)無窮正則化[11](Liu等人,2009b),\(l_{2, 1}\)正則化中采用\(l_{2, 1}\)范數\(||\textbf{W}||_{2, 1} = \sum_{i=1}^{d}||\bm{w}^{i}||_2\)(此處\(d\)為特征維度,\(\bm{w}^i\)為\(\textbf{W}\)第\(i\)行),\(l_{\infin}\)正則化采用\(l_{\infin}\)范數\(||\mathbf{W}||_{\infin}=\underset{1\leqslant i\leqslant d}{\max}\sum_{j=1}^{T}|w_{ij}|\),即對所有行沿著行求和,然后求最大,為了獲得對所有特征都有用的更緊湊的子集,Gong等人[12](2013)提出了上限\(l_{p, 1}\)懲罰項\(\sum_{i=1}^{d}\min(||\bm{w}^i||_p, \theta)\),當\(\theta\)足夠大時它將退化為\(l_{p, 1}\)正則化,
(2)基于模型的多任務監督學習
共享子空間學習(shared subspace learning): 該方法的假設引數矩陣\(\textbf{W}\)為低秩矩陣,以使相似的任務擁有相似的引數向量(即\(\textbf{W}\)的\(T\)個列向量盡量線性相關),以使\(T\)個任務的模型引數\(\bm{w_t}\)都來自一個共享低秩子空間,Ando和Zhang(2005)[13]提出了一個對\(\bm{w}_t\)的引數化方式,即\(\bm{w}_t = \bm{p}_t + \mathbf{\Theta}^T \bm{q}_t\),其中線性變換\(\mathbf{\Theta}^T\in \mathbb{R}^{d^{'} \times d}(d^{'}<d)\)由于構建任務的共享子空間,\(\bm{p}_t\)是任務特定的引數向量,在正則項設計方面,我們在\(\mathbf{\Theta}\)上使用正交約束\(\mathbf{\Theta}{\Theta}^T = \mathbf{I}\)來消除冗余,此時相應的目標函式為:
\[\begin{aligned} & \underset{\textbf{P},\mathbf{Q},\mathbf{\Theta},\bm{b}}{\min} \sum_{t=1}^{T} [\frac{1}{m_t}\sum_{i=1}^{m_t}L(y_{ti}, \langle \bm{p}_t + \mathbf{\Theta}^T \bm{q}_t, \bm{x}_{ti} \rangle + b_{t}]+\lambda ||\textbf{P}||_{F}^2 \\ & \text{s. t. } \quad \mathbf{\Theta}\mathbf{\Theta}^T = \mathbf{I} \end{aligned} \]Chen等人(2009)[14]通過為\(\mathbf{W}\)增加平方Frobenius正則化推廣了這一模型,并采用松弛技術將問題轉換為了凸優化問題,
除此之外,根據優化理論,使用矩陣的核范數(nuclear norm, 有時也稱跡范數(trace norm))\(||\mathbf{W}||_{*}=\sum_{i=1}^{\min(d, T)}\sigma_i(\mathbf{W})\)來進行正則化會產生地址矩陣,所以核范數正則化(pong等人)也在多任務學習中應用廣泛,此時目標函式通常為:
核范數是一rank function[15](Fazel等人, 2001)的緊的凸松弛,可以用近端梯度下降法求解,
聚類方法: 該方法受聚類方法的啟發,基本思想為:將任務分為若個個簇,每個簇內部的任務在模型引數上更相似,
參考文獻
- [1] Evgeniou T, Pontil M. Regularized multi--task learning[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. 2004: 109-117.
- [2] Zhou J, Chen J, Ye J. Malsar: Multi-task learning via structural regularization[J]. Arizona State University, 2011, 21.
- [3] Zhou J, Chen J, Ye J. Clustered multi-task learning via alternating structure optimization[J]. Advances in neural information processing systems, 2011, 2011: 702.
- [4] Ji S, Ye J. An accelerated gradient method for trace norm minimization[C]//Proceedings of the 26th annual international conference on machine learning. 2009: 457-464.
- [5] Caruana R. Multitask learning[J]. Machine learning, 1997, 28(1): 41-75
- [6] Evgeniou A, Pontil M. Multi-task feature learning[J]. Advances in neural information processing systems, 2007, 19: 41.
- [7] Argyriou A, Evgeniou T, Pontil M. Convex multi-task feature learning[J]. Machine learning, 2008, 73(3): 243-272.
- [8] Maurer A, Pontil M, Romera-Paredes B. Sparse coding for multitask and transfer learning[C]//International conference on machine learning. PMLR, 2013: 343-351.
- [9] Obozinski G, Taskar B, Jordan M. Multi-task feature selection[J]. Statistics Department, UC Berkeley, Tech. Rep, 2006, 2(2.2): 2.
- [10] Obozinski G, Taskar B, Jordan M I. Joint covariate selection and joint subspace selection for multiple classification problems[J]. Statistics and Computing, 2010, 20(2): 231-252.
- [11] Liu H, Palatucci M, Zhang J. Blockwise coordinate descent procedures for the multi-task lasso, with applications to neural semantic basis discovery[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 649-656.
- [12] Gong P, Ye J, Zhang C. Multi-stage multi-task feature learning[J]. arXiv preprint arXiv:1210.5806, 2012.
- [13] Ando R K, Zhang T, Bartlett P. A framework for learning predictive structures from multiple tasks and unlabeled data[J]. Journal of Machine Learning Research, 2005, 6(11).
- [14] Chen J, Tang L, Liu J, et al. A convex formulation for learning shared structures from multiple tasks[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 137-144.
- [15] Fazel M, Hindi H, Boyd S P. A rank minimization heuristic with application to minimum order system approximation[C]//Proceedings of the 2001 American Control Conference.(Cat. No. 01CH37148). IEEE, 2001, 6: 4734-4739.
- [16] 楊強等. 遷移學習[M].機械工業出版社, 2020.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/341736.html
標籤:其他