文章目錄
- 專案目錄
- 提取人臉
- 特征提取
- PCA
- LDA
- LBPH+直方圖特征
- 訓練分類器
- SVC
- 可視化
- 利用分類器進行視頻人像分類
有空的時候把專案部署到github上
專案目錄
提取人臉
首先撰寫一個人臉檢測的演算法
import cv2 as cv
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw
import traceback
def face_detection_(image,scaleFactor_,minNeighbors_):
'''
輸入影像,回傳人臉圖片
'''
# 轉成灰度影像
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# 創建一個級聯分類器 加載一個.xml分類器檔案 它既可以是Haar特征也可以是LBP特征的分類器
face_detecter = cv.CascadeClassifier('haarcascade_frontalface_default.xml')
# 多個尺度空間進行人臉檢測 回傳檢測到的人臉區域坐標資訊
faces = face_detecter.detectMultiScale(image=gray, scaleFactor=scaleFactor_, minNeighbors=minNeighbors_)
# print('檢測人臉資訊如下:\n', faces)
image=cv.cvtColor(image, cv.COLOR_BGR2RGB)
# for x, y, w, h in faces:
# # 在原影像上繪制矩形標識
# cv.rectangle(img=image, pt1=(x, y), pt2=(x+w, y+h), color=(0, 0, 255), thickness=2)
# plt.imshow(image)
# assert faces.shape[0]==1
try:
(x,y,w,h)=faces[0]
face_=image[y:y+h,x:x+w,:]
except Exception as e:
# print('faces: ',faces)
# print('it may be cause by scaleFactor or minNeighbors, that the face is not be recognize')
# print('so i would just return null')
# traceback.print_exc()
return None
return face_# 回傳單張人臉
'''這是多張人臉的提取,以后再搞'''
# image_list=[]
# try:
# # 提取多張人臉傳入list
# for (x, y, w, h) in faces:
# image_list.append(image[y:y+h,x:x+w,:])
# except Exception as e:
# print('faces: ',faces)
# print('it may be cause by scaleFactor or minNeighbors, that the face is not be recognize')
# print('so i would just return null')
# traceback.print_exc()
# return None
# # 回傳人臉影像list
# return image_list
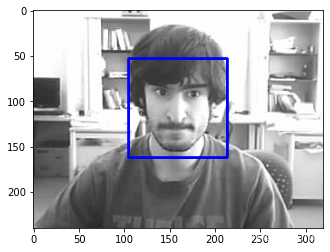
測驗的效果
filepath=r'..\data\db\6_FaceOcc2\train\0003.jpg'
src=cv.imread(filepath)
face_detecter = cv.CascadeClassifier('haarcascade_frontalface_default.xml')
# 多個尺度空間進行人臉檢測 回傳檢測到的人臉區域坐標資訊
faces = face_detecter.detectMultiScale(image=src, scaleFactor=1.03, minNeighbors=20)
for x, y, w, h in faces:
# 在原影像上繪制矩形標識
cv.rectangle(img=src, pt1=(x, y), pt2=(x+w, y+h), color=(0, 0, 255), thickness=2)
plt.imshow(src)
faces
下一步,我們要將這個演算法自動化,即自動對影像資料集進行人臉檢測與分割,并將分割好的人臉影像保存在人臉資料集目錄
首先創建這個人臉資料集目錄
import os
def mkdir(path):
folder = os.path.exists(path)
if not folder :
os.makedirs(path)
else:
print('dir is existed')
file_path=r'data\db_face\\'
dir_list=os.listdir(r'..\data\db')
for dir in dir_list:
filePath=file_path+dir
mkdir(filePath)
mkdir(filePath+'\\train')
mkdir(filePath+'\\test')
然后寫了一個全自動的人臉提取器,可以對所有類別的人的影像進行人臉提取
data_path=r'..\data\db\\'
for db_name in os.listdir(data_path):
tt_path=os.path.join(data_path,db_name)
for data_set in os.listdir(tt_path):
data_set_path=os.path.join(tt_path,data_set)
for img_name in os.listdir(data_set_path):
img_path=os.path.join(data_set_path,img_name)
# ok 終于得到了這個圖片的路徑
save_path=os.path.join('data\db_face',db_name,data_set,img_name)
src=cv.imread(img_path)
roi=face_detection_(src,scaleFactor_=1.01,minNeighbors_=100)# 提取人臉
if roi is None:
print('can not detect faces')
continue
print(save_path)
if os.path.exists(save_path):
continue# 已經有圖片了
else:
plt.imsave(save_path,roi)
# 這是roi_list 多張人臉檢測 以后再搞
# for roi in roi_list:
# if os.path.exists(save_path):
# continue# 已經有圖片了
# else:
# plt.imsave(save_path,roi)
還寫了一個半自動的人臉提取,只對一個人的人臉影像進行提取,這是為了方便調整人臉檢測器的引數,畢竟不同的人的影像資料集干凈程度不一樣
def auto_draw_face(data_path,db_name,scaleFactor_=1.03,minNeighbors_=3):
for data_set in os.listdir(data_path):
data_set_path=os.path.join(data_path,data_set)
for img_name in os.listdir(data_set_path):
img_path=os.path.join(data_set_path,img_name)
# ok 終于得到了這個圖片的路徑
save_path=os.path.join('data\db_face\\'+db_name+'\\',data_set,img_name)
print(save_path)
src=cv.imread(img_path)
roi=face_detection_(src,scaleFactor_,minNeighbors_)# 提取人臉
if roi is None:
print('can not detect faces')
continue
if os.path.exists(save_path):
continue
else:
print(save_path)
plt.imsave(save_path,roi)
# 這是roi_list 多張人臉檢測 以后再搞
# for roi in roi_list:
# if os.path.exists(save_path):
# continue# 已經有圖片了
# else:
# plt.imsave(save_path,roi)
測驗以下在8_Girl這個人的資料集中提取情況如何
data_path=r'..\data\db\\8_Girl'
auto_draw_face(data_path,'8_Girl',scaleFactor_=1.01,minNeighbors_=5)
全部人都提取完了之后看看都提取了多少人臉
file_path='data/db_face//'
db_name=os.listdir('data/db_face')
for db in db_name:
filePath=os.path.join(file_path,db)
print(db,':')
print('train',len(os.listdir(filePath+'//train')))
print('test',len(os.listdir(filePath+'//test')))
10_Mhyang :
train 200
test 1290
1_BlurFace :
train 200
test 286
2_ClifBar :
train 150
test 175
3_David :
train 258
test 272
4_Dudek :
train 271
test 765
5_FaceOcc1 :
train 242
test 254
6_FaceOcc2 :
train 110
test 113
7_FleetFace :
train 272
test 211
8_Girl :
train 124
test 187
9_Jumping :
train 138
test 153
,,,資料有點不平衡,有的人多有的人少,不過沒關系,我們到時候都只取100張人臉就行了
接下來要處理以下影像,都轉換為單通道灰度圖且大小都調整為100x100
data_path='data/db_face'
re_shape=(100,100)
for db_name in os.listdir(data_path):
tt_path=os.path.join(data_path,db_name)
for data_set in os.listdir(tt_path):
data_set_path=os.path.join(tt_path,data_set)
for img_name in os.listdir(data_set_path):
img_path=os.path.join(data_set_path,img_name)
# ok 終于得到了這個圖片的路徑
save_path=os.path.join(data_path,db_name,data_set,img_name)
print(save_path)
# 處理影像
files=cv.imread(img_path,0)
tmp_img=cv.resize(files,re_shape,cv.INTER_LINEAR)
cv.imwrite(save_path,tmp_img)
最后,我們把影像資料集轉化為X(nums,high,weight)這樣的ndarrary,然后把每張影像的類別也整理為y(nums,1)
data_path='data/db_face'
img_list=[]
label_list=[]
for types,db_name in enumerate(os.listdir(data_path)):
tt_path=os.path.join(data_path,db_name)
# for data_set in os.listdir(tt_path):
data_set_path=os.path.join(tt_path,'train')
for img_name in os.listdir(data_set_path)[:100]:
img_path=os.path.join(data_set_path,img_name)
print(img_path)
print(types)
img=cv.imread(img_path,0)
img_list.append(img)
label_list.append(types)
X=np.array(img_list)
y=np.array(label_list)[:,np.newaxis]
np.save('train_X.npy',X)
np.save('train_y.npy',y)
上邊是處理訓練集的,我們對測驗集也同樣處理
data_path='data/db_face'
img_list=[]
label_list=[]
for types,db_name in enumerate(os.listdir(data_path)):
tt_path=os.path.join(data_path,db_name)
# for data_set in os.listdir(tt_path):
data_set_path=os.path.join(tt_path,'test')
for img_name in os.listdir(data_set_path)[:110]:
img_path=os.path.join(data_set_path,img_name)
print(img_path)
print(types)
img=cv.imread(img_path,0)
img_list.append(img)
label_list.append(types)
X=np.array(img_list)
y=np.array(label_list)[:,np.newaxis]
np.save('test_X.npy',X)
np.save('test_y.npy',y)
特征提取
這里我煩了,直接把train和test的資料混成一堆算了
import cv2 as cv
import os
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import numpy as np
from sklearn import utils
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
X=np.load('train_X.npy')
y=np.load('train_y.npy')
X_t=np.load('test_X.npy')
y_t=np.load('test_y.npy')
X=np.concatenate((X,X_t))
y=np.concatenate((y,y_t))
np.save('total_X',X)
np.save('total_y',y)
好的,現在X,y就是我們的人臉資料集和label了
可視化一下
#傳入一張圖片(10000,1)numpy陣列,轉化為(100,100)的影像
def getDatumImg(row):
width, height = 100,100
square = row.reshape(width,height)
return square
#可視化資料
def displayData(myX, mynrows = 40, myncols = 40):
width, height = 100,100
nrows, ncols = mynrows, myncols
#大圖片
big_picture = np.zeros((height*nrows,width*ncols))
irow, icol = 0, 0
for idx in range(nrows*ncols):#每10張圖片換行一次,遍歷100張圖片
if icol == ncols:
irow += 1
icol = 0
# iimg = getDatumImg(myX[idx])#讀取圖片的numpy陣列(32,32)
iimg=myX[idx,:,:]
big_picture[irow*height:irow*height+iimg.shape[0],icol*width:icol*width+iimg.shape[1]] = iimg
icol += 1
fig = plt.figure(figsize=(15,15))
plt.imshow(big_picture,cmap ='gray')
X,y=utils.shuffle(X,y)
displayData(X)

上面的一堆人臉就是我們的資料
下面我們要構建一下人臉向量,把資料集X由(nums,high,weight)的影像序列變為(nums,hegh*weight)的二維表(標準的X)
# X_vec=np.array([X[i,:,:].ravel()[:,np.newaxis] for i in range(X.shape[0])])
X_vec=np.array([X[i,:,:].ravel() for i in range(X.shape[0])])
隨便可視化一張人臉看看
img=getDatumImg(X_vec[1424,:])
plt.imshow(img,cmap='gray')

下面開始降維
PCA
PCA可以看我這篇
分割一下訓練集和測驗集
X_train, X_test, y_train, y_test = train_test_split(
X_vec, y, test_size=0.3, random_state=42
)
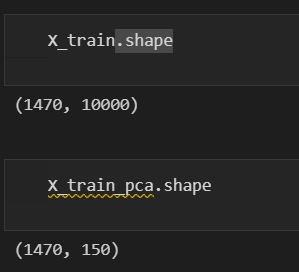
n_components = 150
print(
"Extracting the top %d eigenfaces from %d faces" % (n_components, X.shape[0])
)
pca = PCA(n_components=n_components, whiten=True).fit(X_train)
# 得到前150個特征向量,每個特征向量10000維(協方差矩陣10000x10000)
eigenfaces = pca.components_.reshape((n_components, 100, 100))
無腦調包,結果長這樣,X的維度由10000降維到了150
看看提取出來的特征臉
其實就是把PCA搞出來的幾個特征向量(
10000x1)搞成了臉的形狀(100x100)
displayData(eigenfaces,mynrows = 10, myncols = 10)

然后把訓練集和測驗集降維一下
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
LDA
LDA可以看我這篇
太懶了,之后搞
LBPH+直方圖特征
LBP可以看我這篇
太懶了,之后搞
訓練分類器
SVC
太懶了,就先只用svm分類了
import warnings
warnings.filterwarnings('ignore')
param_grid = {
"C": [1e3, 5e3, 1e4, 5e4, 1e5],
"gamma": [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1],
}
clf = GridSearchCV(SVC(kernel="rbf", class_weight="balanced"), param_grid)
clf = clf.fit(X_train_pca, y_train)
print(clf.best_estimator_)
輸出
SVC(C=1000.0, class_weight='balanced', gamma=0.0001)
列印看看準確率如何
print('test score: ',clf.score(X_test_pca,y_test))
輸出
test score: 1.0
有點小高,怕怕
可視化
可視化看看樣本在低維空間的分布情況
pca = PCA(n_components=3, whiten=True).fit(X_vec)
X_vec_pca=pca.transform(X_vec)
X_list=[]
label_set=set(y.ravel())
for label in label_set:
tmp_list=[X_vec_pca[i] for i in range(X_vec_pca.shape[0]) if y[i][0]==label]
X_list.append(tmp_list)
X_list=np.array(X_list)
X_list.shape
輸出
(10, 210, 3)
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
# %matplotlib auto
fig = plt.figure(figsize=[10,15])
ax = Axes3D(fig)
#ax.legend(loc='best')
ax.set_zlabel('Z', fontdict={'size': 15, 'color': 'red'})
ax.set_ylabel('Y', fontdict={'size': 15, 'color': 'red'})
ax.set_xlabel('X', fontdict={'size': 15, 'color': 'red'})
for i in range(X_list.shape[0]):
ax.scatter(X_list[i,:,0],X_list[i,:,1],X_list[i,:,2])
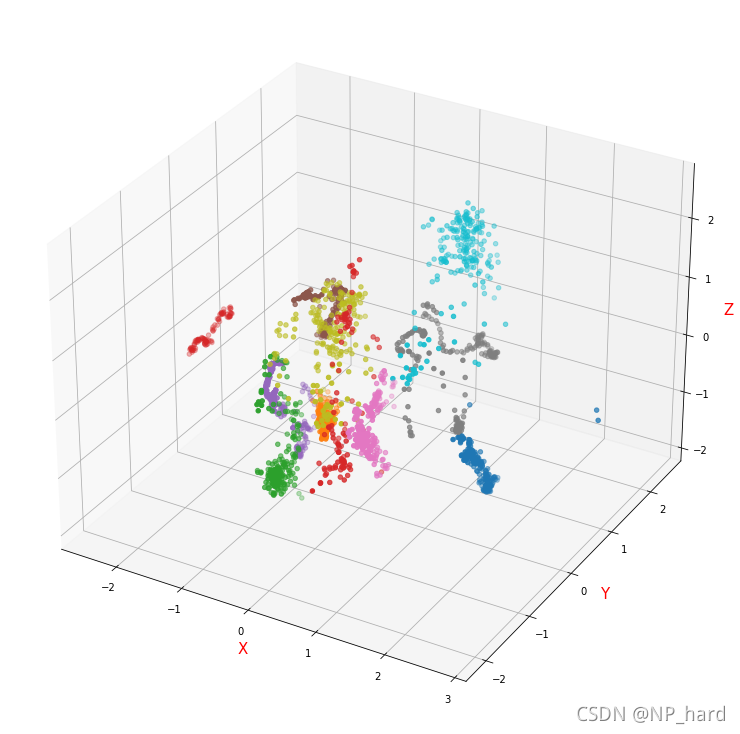
還不錯,可分性很好
利用分類器進行視頻人像分類
懶了,以后再搞s
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/341884.html
標籤:其他
上一篇:完虐鏈表之反轉鏈表(一)
下一篇:初階資料結構——堆疊