XGBoost
極端梯度提升(Extreme Gradient Boosting,XGBoost,有時候也直接叫做XGB)和GBDT類似,也會定義一個損失函式,不同于GBDT的是只會用到一階導數資訊,XGBoost會利用泰勒展開式把損失函式展開到二階之后求導,利用了二階導數資訊,這樣在訓練集上的收斂就會更快
引數介紹
| 主要引數 | 解釋 |
|---|---|
| max_depth | 數的最大深度,一般值為【3,4,5】 |
| gamma | 學習速率,決定收斂速率以及正確率 |
| subsample | 訓練每棵樹時所選樣本占總訓練集比例 |
| colsample_bytree | 訓練每棵樹時所選特征占據總體特征比例 |
| n_estimators | 迭代次數(樹的數量) |
| min_child_weight | 最小葉子節點樣本權重和,值越大泛化能力越強 |
專案實戰(股票風險走勢預測)
方法討論
其實針對這個問題我知道的最好辦法就是用LSTM回圈神經網路去處理(但是畢竟我們在講XGBoost,所以不要在意這些細節【狗頭】)
利用XGBoost處理這類時間序列問題我能想到的有兩種方法
將前幾天的資料作為特征集,今天的股票close列作為標簽,這種方法的優點就是準確率高,但是缺點也很明顯,
他只能預測未來一天,,,,,,
用當天的股票資料作為特征,當天的close列作為標簽,用來訓練模型(就像咱們普通的回歸預測一樣),然后將所有選取的特征各自建立時間序列模型,預測他們未來幾天的資料,然后將該資料作為特征集,用訓練好的模型predict,得到的就是咱們要預測的未來幾天的資料 ,這個方法的優點就是能夠預測未來幾天的資料嘿嘿,缺點就是正確率不如前者,往后預測的天數越多,誤差越大,而且非常麻煩!(這里有一段非常凄慘的故事)
因為時間有限(其實是懶【狗頭】),咱們今天用第一種方法來預測(其實是因為懶【狗頭保命】)
利用tushare模塊匯入股票資料
import tushare as ts
#選取股票代碼為600000的股票從2020年1月1日到2021年10月28日的資料
data=ts.get_k_data('600000',start='2020-01-01',end='2021-10-28')
#將資料保存到指定路徑(不建議像我這樣路徑含有中文,血的教訓嗚嗚嗚)
#這種帶有日期的資料建議儲存到csv格式而不是excel格式,因為會亂碼
data.to_csv(r'C:\Users\74581\OneDrive - xmu\桌面\600000.csv')-
得到以下部分資料
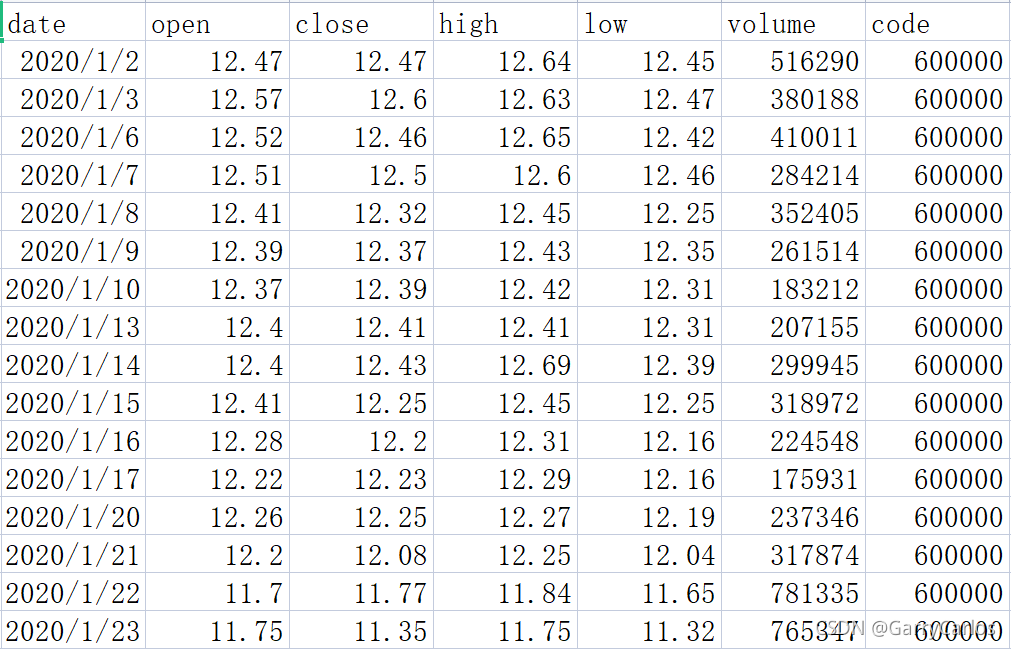
-
咱們先把資料讀取回來
import pandas as pd
#將日期設定為index,并且轉化為datatime格式(時間序列里一定要轉換!!!!)
data=pd.read_csv(r'C:\Users\74581\OneDrive - xmu\桌面\600000.csv',index_col='date',parse_dates=['date'])
-
匯入資料之后我們會發現有一列沒有必要的資料,就是code(不要問我為什么* _*),所以在這里我們先把他刪掉
data=data.drop(columns='code')排除例外值
-
處理完資料的基本操作之后,我們得檢查例外值,看看資料方面是否出了一些問題,如果出現了1000一股的資料我們還fit進了模型里,那可就糟糕了(血的教訓嚶嚶嚶)
-
我們可以先用describe函式直接構造
排除例外值
-
處理完資料的基本操作之后,我們得檢查例外值,看看資料方面是否出了一些問題,如果出現了1000一股的資料我們還fit進了模型里,那可就糟糕了(血的教訓嚶嚶嚶)
-
我們可以先用describe函式直接構造
-
print(data.describe().loc[['min','max','mean'],:])#其實大概檢測只要看這三個資料就行啦(菜雞看法) -

-
得到了以上的資料,最大值和最小值好像都沒有差均值太多,也沒有出現負值,說明這個資料還是沒有什么問題的
資料特征處理
#資料特征處理
base1=data['close']
base2=data.shift(1)
base2.columns=[f'v{j}-1' for j in range(len(data.columns))]
base3=pd.concat([base1,base2],axis=1)
for i in range(2,7):
base4=data.shift(i)
base4.columns=[f'v{j}-{i}' for j in range(len(data.columns))]
base3=pd.concat([base3,base4],axis=1)
base3.dropna(inplace=True)
x=base3.drop(columns=['close'])
y=base3['close']測驗集,訓練集的分割
from sklearn.preprocessing import StandardScaler‘
#資料分割
x_train,x_test=x.iloc[:int(len(x)*0.8),:],x.iloc[int(len(x)*0.8):,:]
y_train,y_test=y[:int(len(x)*0.8)],y[int(len(x)*0.8):]特征選擇
#資料特征處理
model1=XGBRegressor()
rfa=RFECV(model1,cv=5,scoring='neg_mean_absolute_error')
rfa.fit(x_train,y_train)
#特征權重資料可視化
plt.bar(x_train.columns,rfa.grid_scores_)
plt.show()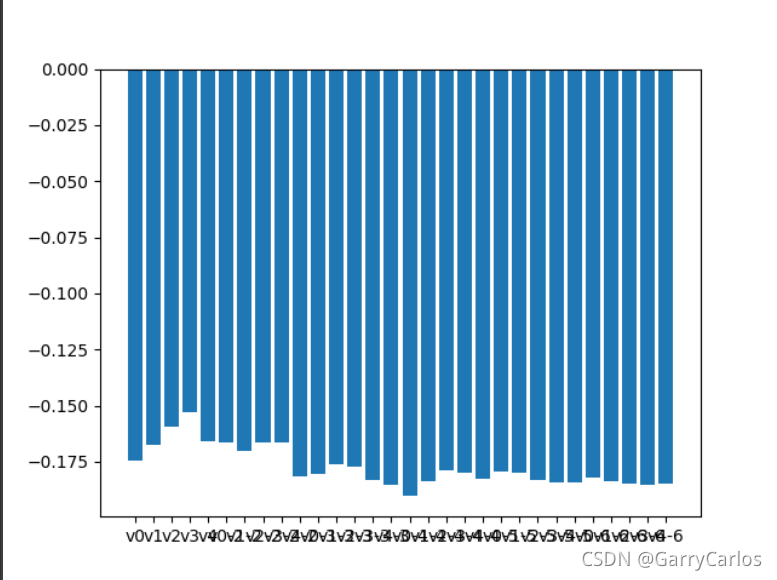
-
沒有出現過擬合的現象,完美!
-
接下來選取最優特征就行啦!!
#特征選擇 col_select=x_train.columns[rfa.support_] x_train,x_test=x_train.loc[:,col_select],x_test.loc[:,col_select]
資料標準化
#資料標準化
from sklearn.preprocessing import StandardScaler
std=StandardScaler()
std.fit(x_train)
x_train_std,x_test_std=std.transform(x_train),std.transform(x_test)模型調參
#模型調參
from sklearn.model_selection import GridSearchCV
params=dict(gamma=[0.1,0.5,0.7,0.05],min_child_weight=[1,3,5],subsample=[0.2,0.4,0.7],colsample_bytree=[0.2,0.4,0.7],n_estimators=[100,200,300],max_depth=[3,4,5])
model=GridSearchCV(XGBRegressor(),params,scoring='neg_mean_squared_error',n_jobs=5,cv=5)模型擬合
#模型擬合
model.fit(x_train_std,y_train)
print(model.best_params_)結果預測
#結果預測
from sklearn.metrics import mean_absolute_error
plt.plot(y_test.index,y_test,label='True')
y_pred=(model.predict(x_test_std)*0.7+model_.predict(x_test_std)*0.3)
plt.plot(y_test.index,y_pred,label='pred')
plt.title('mae:%.2f'%(mean_absolute_error(y_test,y_pred)))
gca=plt.gca()
mul=plt.MultipleLocator(45)
gca.xaxis.set_major_locator(mul)
plt.legend()
plt.show()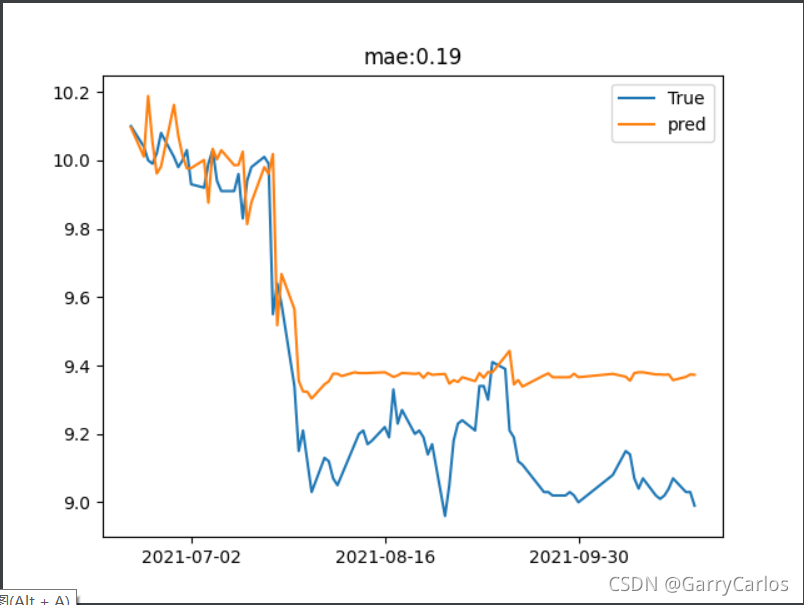
可以看到,在2021年7月2號左右的時候,股票資料比較平穩,模型預測情況也很理想,但是過了一段時間之后股市出現波動(我查閱了相關資料,據說是那段時間頒布了相關政策打擊到了白酒行業,導致股票下跌,所以投資還是有風險呀),出現劇烈波動之后的資料預測情況就沒有那么理想了,所以時間序列分析最理想的情況就是穩定的資料,像這種股票之類不太穩定的資料,就得用到我們的LSTM模型(個人覺得ARIMA有點過時,畢竟資料準備的時間成本太高了嗚嗚嗚),mae大概是0.19左右,對于股票預測分析來說,已經很好了,但是,能不能再降低一點呢,我們這里用Stacking聚合一下,看看能不能把mae再降低一點
#匯入模型
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,StackingRegressor
model1=RandomForestRegressor()
model2=GradientBoostingRegressor()
model3=XGBRegressor()
model4=StackingRegressor([('m1',model1),('m2',model3)],cv=5,n_jobs=10)
model4.fit(x_train_std,y_train)
#結果預測
from sklearn.metrics import mean_absolute_error
plt.plot(y_test.index,y_test,label='True')
y_pred=model4.predict(x_test_std)
plt.plot(y_test.index,y_pred,label='pred')
plt.title('mae:%.2f'%(mean_absolute_error(y_test,y_pred)))
gca=plt.gca()
mul=plt.MultipleLocator(45)
gca.xaxis.set_major_locator(mul)
plt.legend()
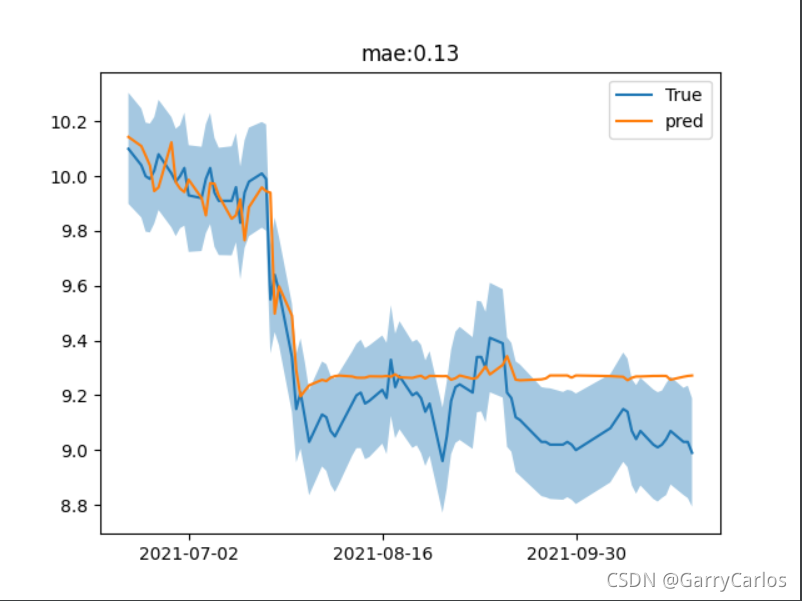
#置信區間
import scipy.stats as st
num=np.random.normal(loc=y_test.values,scale=np.ones(len(y_test))*0.1,size=(1000,len(y_test)))
l,u=st.t.interval(0.95,len(y_test)-1,loc=np.mean(num,axis=0),scale=np.std(num,axis=0))
plt.fill_between(y_test.index,l,u,alpha=0.4,color='r')
plt.show()可以看到,我們這里mae下降了6個百分點,說明Stacking在這里還是挺有效的,其實事實上,我們還可以通過GridSearchCV對各個進行Stacking聚合的模型進行進一步調參,但是今天時間不太夠【其實是我太懶,畢竟好麻煩qwq
模型的維護和預測
因為時間序列模型需要與時俱進不斷迭代資料,所以建議建立好模型之后每隔一段時間再重新給模型擬合一批資料,這個時間根據自己直覺決定(我一般是半個月重新訓練一次)
再者,我們一定要保留建立模型時所選擇的特征資料以及標準化資料,當我們需要呼叫建立的模型去預測的時候,需要先用這些資料去處理(千萬不要直接上來就直接fit進模型)
這個模型只適合預測未來一天的資料,所以想多預測幾天的話,咱們就要用到第二種方法(有時間我也會分享出來嘿嘿)
股市有風險,投資需謹慎,
結束
股票虧了千萬不要來找我嗚嗚嗚
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342019.html
標籤:AI