文章目錄
- 1 前言
- 2 用戶畫像分析概述
- 2.1 用戶畫像構建的相關技術
- 2.2 標簽體系
- 2.3 標簽優先級
- 3 實站 - 百貨商場用戶畫像描述與價值分析
- 3.1 資料格式
- 3.2 資料預處理
- 3.3 會員年齡構成
- 3.4 訂單占比 消費畫像
- 3.5 季度偏好畫像
- 3.6 會員用戶畫像與特征
- 3.6.1 構建會員用戶業務特征標簽
- 3.6.2 會員用戶詞云分析
- 4 最后-畢設幫助
1 前言
Hi,大家好,這里是丹成學長,今天做一個電商銷售預測分析,這只是一個demo,嘗試對電影資料進行分析,并可視化系統
畢設幫助,開題指導,技術解答
🇶746876041
2 用戶畫像分析概述
用戶畫像是指根據用戶的屬性、用戶偏好、生活習慣、用戶行為等資訊而抽象出來的標簽化用戶模型,通俗說就是給用戶打標簽,而標簽是通過對用戶資訊分析而來的高度精煉的特征標識,通過打標簽可以利用一些高度概括、容易理解的特征來描述用戶,可以讓人更容易理解用戶,并且可以方便計算機處理,

標簽化就是資料的抽象能力
- 互聯網下半場精細化運營將是長久的主題
- 用戶是根本,也是資料分析的出發點
2.1 用戶畫像構建的相關技術
我們對構建用戶畫像的方法進行總結歸納,發現用戶畫像的構建一般可以分為目標分析、體系構建、畫像建立三步,
畫像構建中用到的技術有資料統計、機器學習和自然語言處理技術(NLP)等,下如圖所示,具體的畫像構建方法學長會在后面的部分詳細介紹,
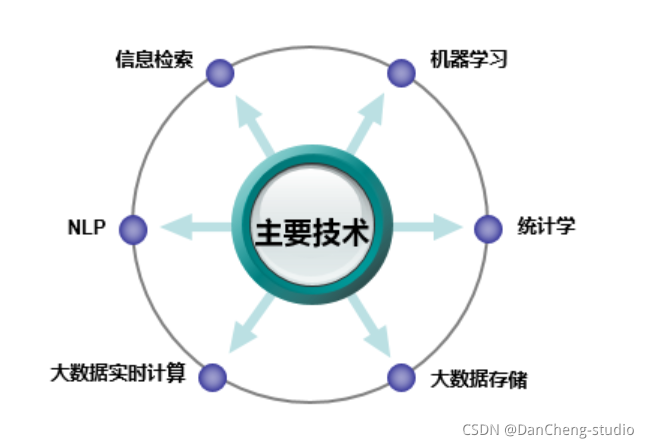
按照資料流處理階段劃分用戶畫像建模的程序,分為三個層,每一層次,都需要打上不同的標簽,
- 資料層:用戶消費行為的標簽,打上事實標簽,作為資料客觀的記錄
- 演算法層:透過行為算出的用戶建模,打上模型標簽,作為用戶畫像的分類
- 業務層:指的是獲客、粘客、留客的手段,打上預測標簽,作為業務關聯的結果
2.2 標簽體系
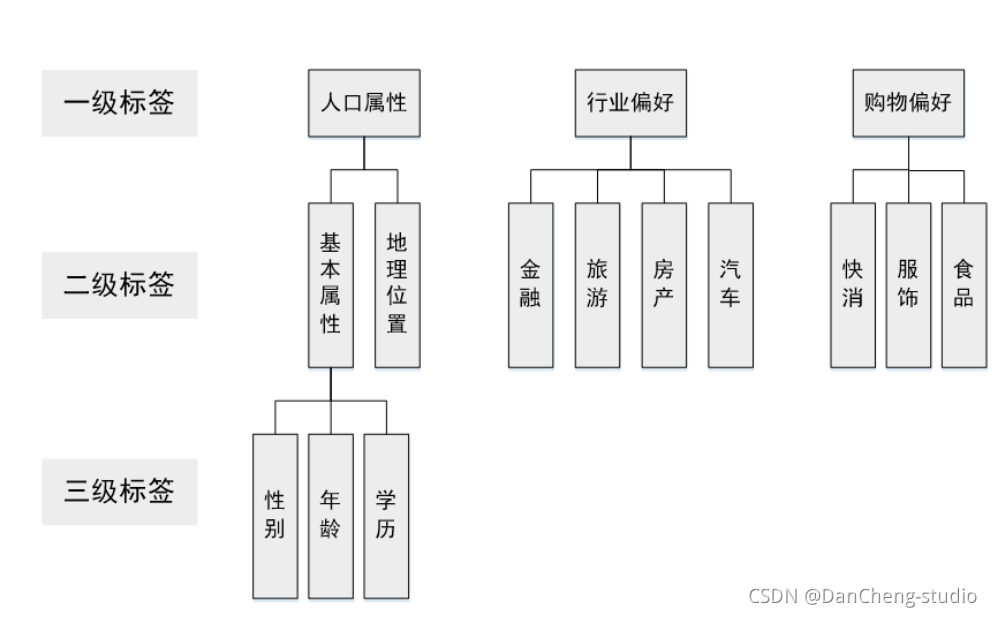
目前主流的標簽體系都是層次化的,如下圖所示,首先標簽分為幾個大類,每個大類下進行逐層細分,在構建標簽時,我們只需要構建最下層的標簽,就能夠映射到上面兩級標簽,
上層標簽都是抽象的標簽集合,一般沒有實用意義,只有統計意義,例如我們可以統計有人口屬性標簽的用戶比例,但用戶有人口屬性標簽本身對廣告投放沒有任何意義,
2.3 標簽優先級
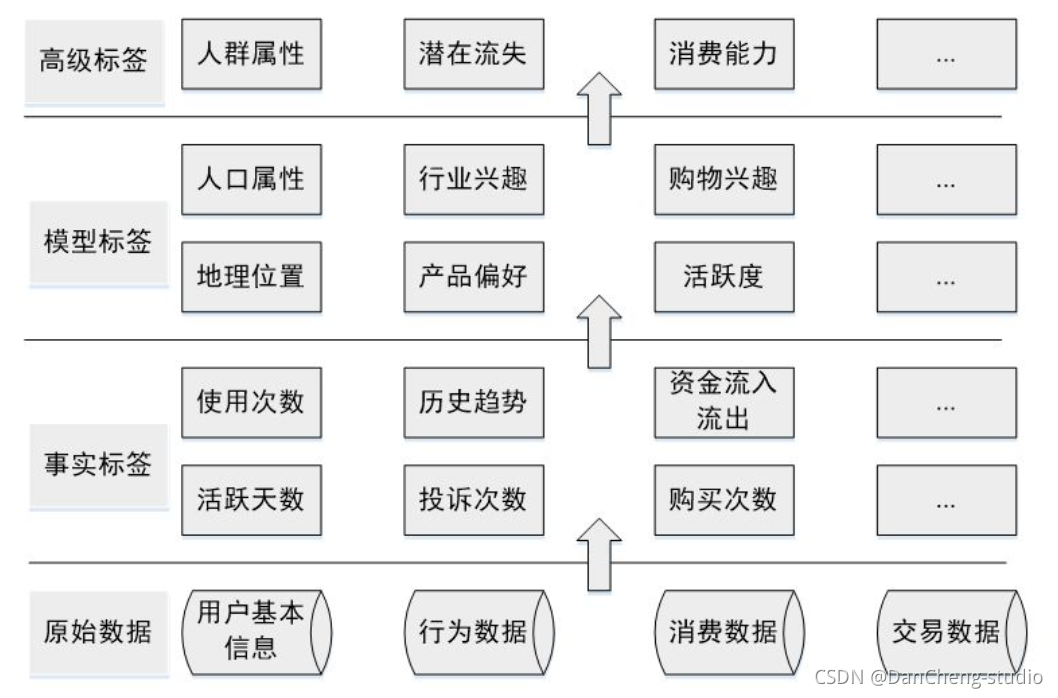
構建的優先級需要綜合考慮業務需求、構建難易程度等,業務需求各有不同,這里介紹的優先級排序方法主要依據構建的難易程度和各類標簽的依存關系,優先級如下圖所示:
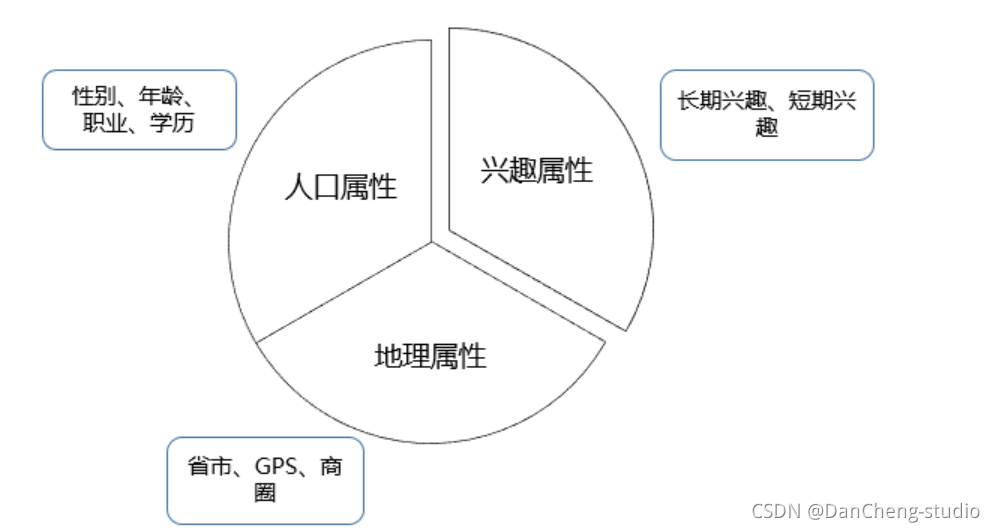
我們把標簽分為三類,這三類標簽有較大的差異,構建時用到的技術差別也很大,第一類是人口屬性,這一類標簽比較穩定,一旦建立很長一段時間基本不用更新,標簽體系也比較固定;第二類是興趣屬性,這類標簽隨時間變化很快,標簽有很強的時效性,標簽體系也不固定;第三類是地理屬性,這一類標簽的時效性跨度很大,如GPS軌跡標簽需要做到實時更新,而常住地標簽一般可以幾個月不用更新,挖掘的方法和前面兩類也大有不同,如圖所示:
3 實站 - 百貨商場用戶畫像描述與價值分析
3.1 資料格式
3.2 資料預處理
部分代碼
# 作者:丹成學長 Q746876041
import matplotlib
import warnings
import re
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler, MinMaxScaler
%matplotlib inline
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
matplotlib.rcParams.update({'font.size' : 16})
plt.style.use('ggplot')
warnings.filterwarnings('ignore')
df_cum = pd.read_excel('./cumcm2018c1.xlsx')
df_cum
# 先來對會員資訊表進行分析
print('會員資訊表一共有{}行記錄,{}列欄位'.format(df_cum.shape[0], df_cum.shape[1]))
print('資料缺失的情況為:\n{}'.format(df_cum.isnull().mean()))
print('會員卡號(不重復)有{}條記錄'.format(len(df_cum['會員卡號'].unique())))
# 會員資訊表去重
df_cum.drop_duplicates(subset = '會員卡號', inplace = True)
print('會員卡號(去重)有{}條記錄'.format(len(df_cum['會員卡號'].unique())))
# 去除登記時間的缺失值,不能直接dropna,因為我們需要保留一定的資料集進行后續的LRFM建模操作
df_cum.dropna(subset = ['登記時間'], inplace = True)
print('df_cum(去重和去缺失)有{}條記錄'.format(df_cum.shape[0]))
# 性別上缺失的比例較少,所以下面采用眾數填充的方法
df_cum['性別'].fillna(df_cum['性別'].mode().values[0], inplace = True)
df_cum.info()
# 由于出生日期這一列的缺失值過多,且存在較多的例外值,不能貿然洗掉
# 故下面另建一個資料集L來保存“出生日期”和“性別”資訊,方便下面對會員的性別和年齡資訊進行統計
L = pd.DataFrame(df_cum.loc[df_cum['出生日期'].notnull(), ['出生日期', '性別']])
L['年齡'] = L['出生日期'].astype(str).apply(lambda x: x[:3] + '0')
L.drop('出生日期', axis = 1, inplace = True)
L['年齡'].value_counts()
...(略)....
3.3 會員年齡構成
# 使用上述預處理后的資料集L,包含兩個欄位,分別是“年齡”和“性別”,先畫出年齡的條形圖
fig, axs = plt.subplots(1, 2, figsize = (16, 7), dpi = 100)
# 繪制條形圖
ax = sns.countplot(x = '年齡', data = L, ax = axs[0])
# 設定數字標簽
for p in ax.patches:
height = p.get_height()
ax.text(x = p.get_x() + (p.get_width() / 2), y = height + 500, s = '{:.0f}'.format(height), ha = 'center')
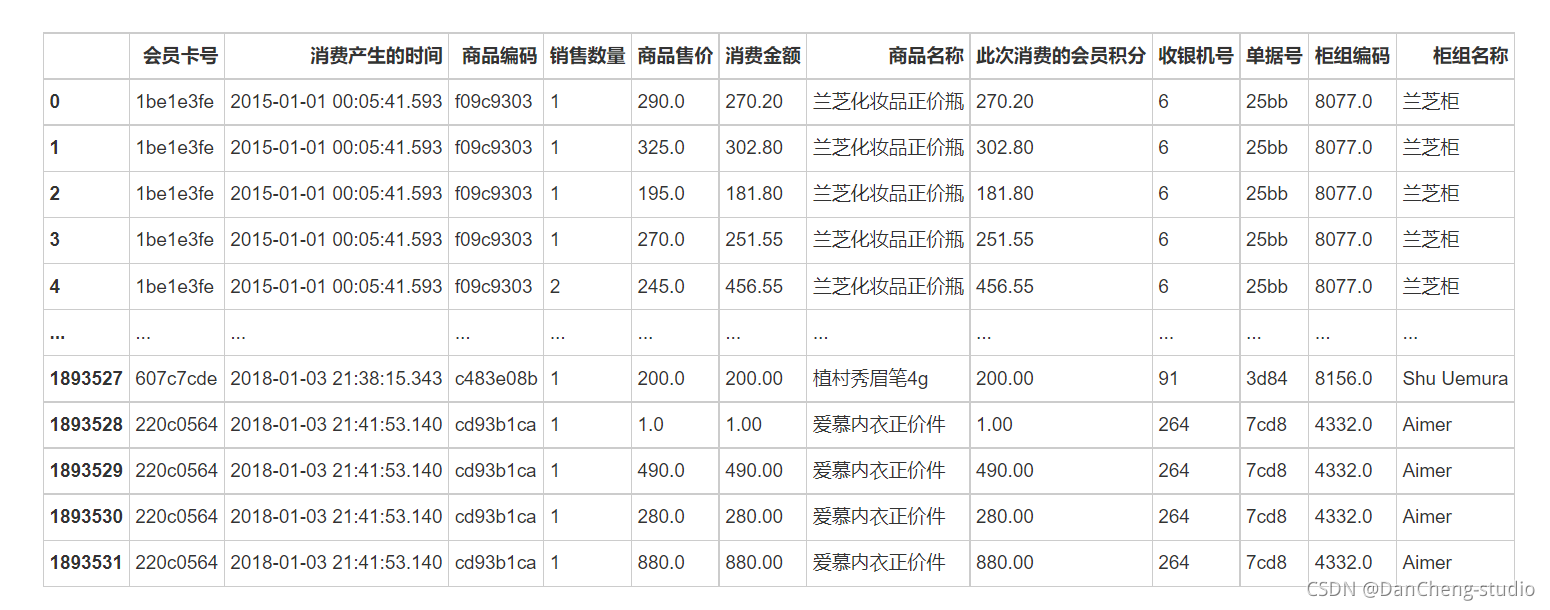
axs[0].set_title('會員的出生年代')
# 繪制餅圖
axs[1].pie(sex_sort, labels = sex_sort.index, wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[1].set_title('會員的男女比例')
plt.savefig('./會員出生年代及男女比例情況.png')
# 繪制各個年齡段的餅圖
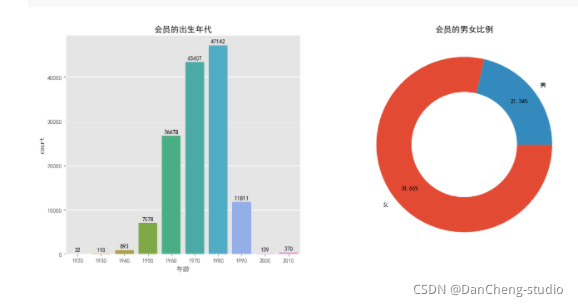
plt.figure(figsize = (8, 6), dpi = 100)
plt.pie(res.values, labels = ['中年', '青年', '老年'], autopct = '%.2f%%', pctdistance = 0.8,
counterclock = False, wedgeprops = {'width': 0.4})
plt.title('會員的年齡分布')
plt.savefig('./會員的年齡分布.png')
3.4 訂單占比 消費畫像
# 由于相同的單據號可能不是同一筆消費,以“消費產生的時間”為分組依據,我們可以知道有多少個不同的消費時間,即消費的訂單數
fig, axs = plt.subplots(1, 2, figsize = (12, 7), dpi = 100)
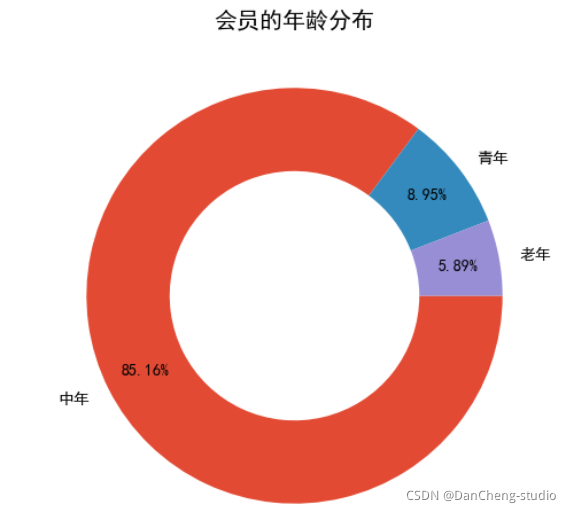
axs[0].pie([len(df1.loc[df1['會員'] == 1, '消費產生的時間'].unique()), len(df1.loc[df1['會員'] == 0, '消費產生的時間'].unique())],
labels = ['會員', '非會員'], wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[0].set_title('總訂單占比')
axs[1].pie([df1.loc[df1['會員'] == 1, '消費金額'].sum(), df1.loc[df1['會員'] == 0, '消費金額'].sum()],
labels = ['會員', '非會員'], wedgeprops = {'width': 0.4}, counterclock = False, autopct = '%.2f%%', pctdistance = 0.8)
axs[1].set_title('總消費金額占比')
plt.savefig('./總訂單和總消費占比情況.png')
消費偏好:
我覺得會稍微偏向與消費的頻次,相當于消費的訂單數,因為每筆消費訂單其中所包含的消費商品和金額都是不太一樣的,有的訂單所消費的商品很少,但金額卻很大,有的消費的商品很多,但金額卻特別少,如果單純以總金額來衡量的話,會員下次消費時間可能會很長,消費頻次估計也會相對變小(因為這次所購買的商品已經足夠用了),所以我會偏向于認為一個用戶消費頻次(訂單數)越多,就越能帶來更多的價值,從另一方面上來講,用戶也不可能一直都是消費低端產品,消費頻次越多用戶的粘性也會相對比較大
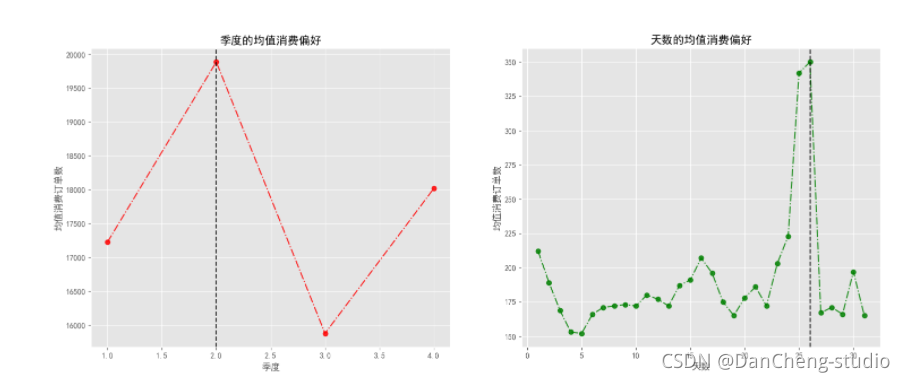
3.5 季度偏好畫像
# 前提假設:2015-2018年之間,消費者偏好在時間上不會發生太大的變化(均值),消費偏好——>以不同時間的訂單數來衡量
quarters_list, quarters_order = orders(df_vip, '季度', 3)
days_list, days_order = orders(df_vip, '天', 36)
time_list = [quarters_list, days_list]
order_list = [quarters_order, days_order]
maxindex_list = [quarters_order.index(max(quarters_order)), days_order.index(max(days_order))]
fig, axs = plt.subplots(1, 2, figsize = (18, 7), dpi = 100)
colors = np.random.choice(['r', 'g', 'b', 'orange', 'y'], replace = False, size = len(axs))
titles = ['季度的均值消費偏好', '天數的均值消費偏好']
labels = ['季度', '天數']
for i in range(len(axs)):
ax = axs[i]
ax.plot(time_list[i], order_list[i], linestyle = '-.', c = colors[i], marker = 'o', alpha = 0.85)
ax.axvline(x = time_list[i][maxindex_list[i]], linestyle = '--', c = 'k', alpha = 0.8)
ax.set_title(titles[i])
ax.set_xlabel(labels[i])
ax.set_ylabel('均值消費訂單數')
print(f'{titles[i]}最優的時間為: {time_list[i][maxindex_list[i]]}\t 對應的均值消費訂單數為: {order_list[i][maxindex_list[i]]}')
plt.savefig('./季度和天數的均值消費偏好情況.png')
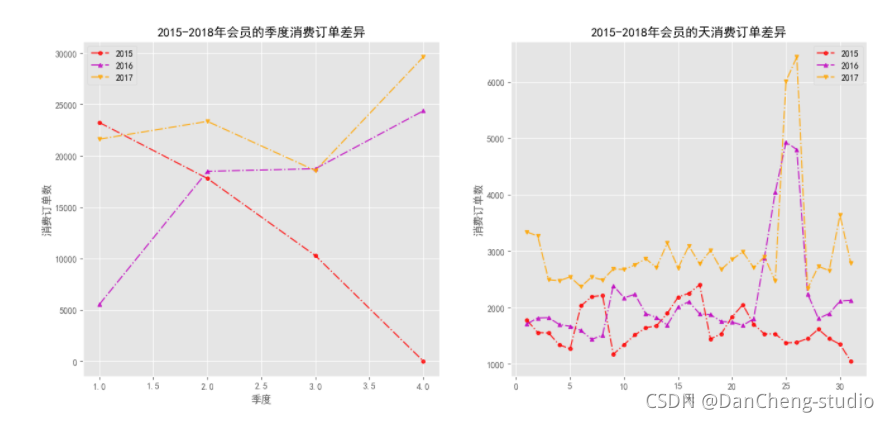
# 自定義函式來繪制不同年份之間的的季度或天數的消費訂單差異
def plot_qd(df, label_y, label_m, nrow, ncol):
"""
df: 為DataFrame的資料集
label_y: 為年份的欄位標簽
label_m: 為標簽的一個串列
n_row: 圖的行數
n_col: 圖的列數
"""
# 必須去掉最后一年的資料,只能對2015-2017之間的資料進行分析
y_list = np.sort(df[label_y].unique().tolist())[:-1]
colors = np.random.choice(['r', 'g', 'b', 'orange', 'y', 'k', 'c', 'm'], replace = False, size = len(y_list))
markers = ['o', '^', 'v']
plt.figure(figsize = (8, 6), dpi = 100)
fig, axs = plt.subplots(nrow, ncol, figsize = (16, 7), dpi = 100)
for k in range(len(label_m)):
m_list = np.sort(df[label_m[k]].unique().tolist())
for i in range(len(y_list)):
order_m = []
index1 = df[label_y] == y_list[i]
for j in range(len(m_list)):
index2 = df[label_m[k]] == m_list[j]
order_m.append(len(df.loc[index1 & index2, '消費產生的時間'].unique()))
axs[k].plot(m_list, order_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i], markersize = 4)
axs[k].set_xlabel(f'{label_m[k]}')
axs[k].set_ylabel('消費訂單數')
axs[k].set_title(f'2015-2018年會員的{label_m[k]}消費訂單差異')
axs[k].legend()
plt.savefig(f'./2015-2018年會員的{"和".join(label_m)}消費訂單差異.png')
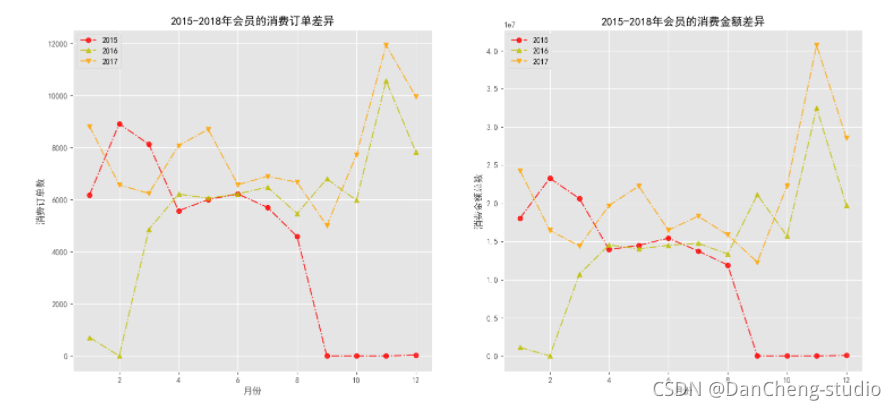
# 自定義函式來繪制不同年份之間的月份消費訂單差異
def plot_ym(df, label_y, label_m):
"""
df: 為DataFrame的資料集
label_y: 為年份的欄位標簽
label_m: 為月份的欄位標簽
"""
# 必須去掉最后一年的資料,只能對2015-2017之間的資料進行分析
y_list = np.sort(df[label_y].unique().tolist())[:-1]
m_list = np.sort(df[label_m].unique().tolist())
colors = np.random.choice(['r', 'g', 'b', 'orange', 'y'], replace = False, size = len(y_list))
markers = ['o', '^', 'v']
fig, axs = plt.subplots(1, 2, figsize = (18, 8), dpi = 100)
for i in range(len(y_list)):
order_m = []
money_m = []
index1 = df[label_y] == y_list[i]
for j in range(len(m_list)):
index2 = df[label_m] == m_list[j]
order_m.append(len(df.loc[index1 & index2, '消費產生的時間'].unique()))
money_m.append(df.loc[index1 & index2, '消費金額'].sum())
axs[0].plot(m_list, order_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i])
axs[1].plot(m_list, money_m, linestyle ='-.', c = colors[i], alpha = 0.8, marker = markers[i], label = y_list[i])
axs[0].set_xlabel('月份')
axs[0].set_ylabel('消費訂單數')
axs[0].set_title('2015-2018年會員的消費訂單差異')
axs[1].set_xlabel('月份')
axs[1].set_ylabel('消費金額總數')
axs[1].set_title('2015-2018年會員的消費金額差異')
axs[0].legend()
axs[1].legend()
plt.savefig('./2015-2018年會員的消費訂單和金額差異.png')
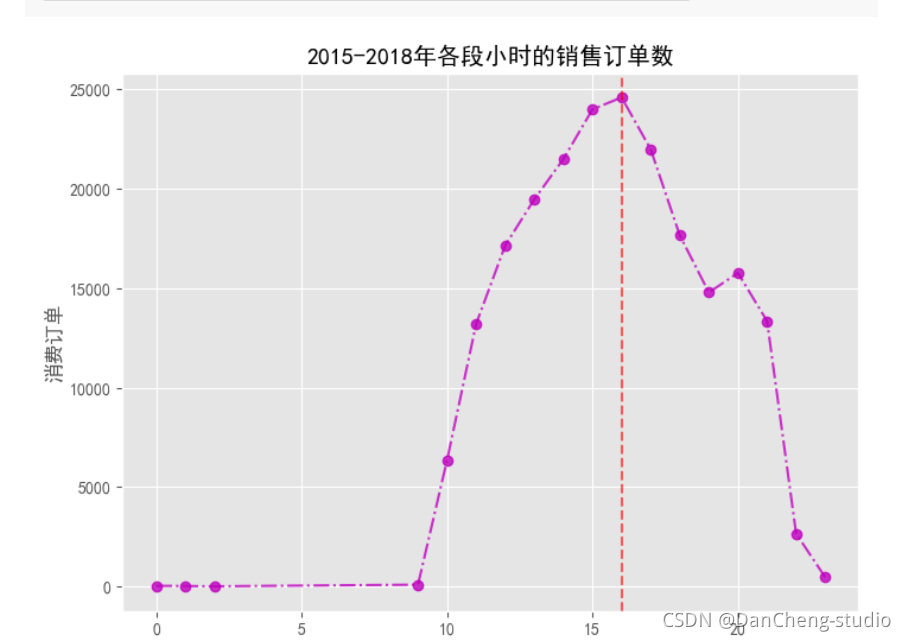
maxindex = order_nums.index(max(order_nums))
plt.figure(figsize = (8, 6), dpi = 100)
plt.plot(x_list, order_nums, linestyle = '-.', marker = 'o', c = 'm', alpha = 0.8)
plt.xlabel('小時')
plt.ylabel('消費訂單')
plt.axvline(x = x_list[maxindex], linestyle = '--', c = 'r', alpha = 0.6)
plt.title('2015-2018年各段小時的銷售訂單數')
plt.savefig('./2015-2018年各段小時的銷售訂單數.png')
3.6 會員用戶畫像與特征
3.6.1 構建會員用戶業務特征標簽
# 取DataFrame之后轉置取values得到一個串列,再繪制對應的詞云,可以自定義一個繪制詞云的函式,輸入引數為df和會員卡號
"""
L: 入會程度(新用戶、中等用戶、老用戶)
R: 最近購買的時間(月)
F: 消費頻數(低頻、中頻、高頻)
M: 消費總金額(高消費、中消費、低消費)
P: 積分(高、中、低)
S: 消費時間偏好(凌晨、上午、中午、下午、晚上)
X:性別
"""
# 開始對資料進行分組
"""
L(入會程度):3個月以下為新用戶,4-12個月為中等用戶,13個月以上為老用戶
R(最近購買的時間)
F(消費頻次):次數20次以上的為高頻消費,6-19次為中頻消費,5次以下為低頻消費
M(消費金額):10萬以上為高等消費,1萬-10萬為中等消費,1萬以下為低等消費
P(消費積分):10萬以上為高等積分用戶,1萬-10萬為中等積分用戶,1萬以下為低等積分用戶
"""
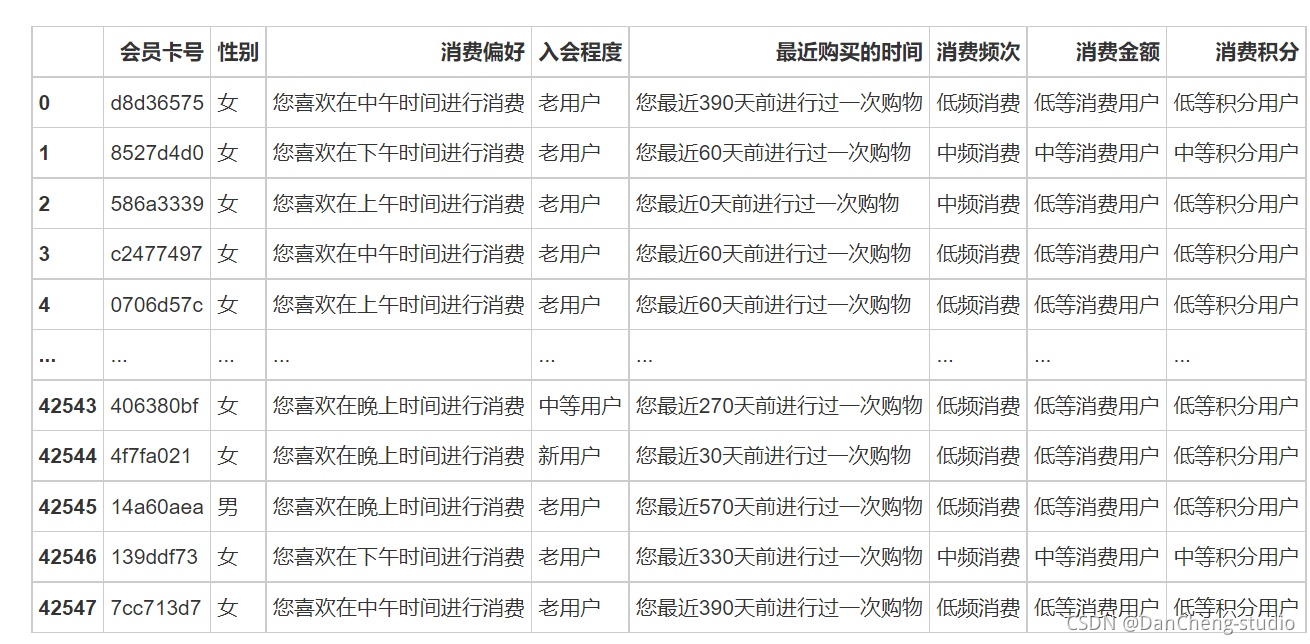
df_profile = pd.DataFrame()
df_profile['會員卡號'] = df['id']
df_profile['性別'] = df['X']
df_profile['消費偏好'] = df['S'].apply(lambda x: '您喜歡在' + str(x) + '時間進行消費')
df_profile['入會程度'] = df['L'].apply(lambda x: '老用戶' if int(x) >= 13 else '中等用戶' if int(x) >= 4 else '新用戶')
df_profile['最近購買的時間'] = df['R'].apply(lambda x: '您最近' + str(int(x) * 30) + '天前進行過一次購物')
df_profile['消費頻次'] = df['F'].apply(lambda x: '高頻消費' if x >= 20 else '中頻消費' if x >= 6 else '低頻消費')
df_profile['消費金額'] = df['M'].apply(lambda x: '高等消費用戶' if int(x) >= 1e+05 else '中等消費用戶' if int(x) >= 1e+04 else '低等消費用戶')
df_profile['消費積分'] = df['P'].apply(lambda x: '高等積分用戶' if int(x) >= 1e+05 else '中等積分用戶' if int(x) >= 1e+04 else '低等積分用戶')
df_profile
3.6.2 會員用戶詞云分析
# 開始繪制用戶詞云,封裝成一個函式來直接顯示詞云
def wc_plot(df, id_label = None):
"""
df: 為DataFrame的資料集
id_label: 為輸入用戶的會員卡號,默認為隨機取一個會員進行展示
"""
myfont = 'C:/Windows/Fonts/simkai.ttf'
if id_label == None:
id_label = df.loc[np.random.choice(range(df.shape[0])), '會員卡號']
text = df[df['會員卡號'] == id_label].T.iloc[:, 0].values.tolist()
plt.figure(dpi = 100)
wc = WordCloud(font_path = myfont, background_color = 'white', width = 500, height = 400).generate_from_text(' '.join(text))
plt.imshow(wc)
plt.axis('off')
plt.savefig(f'./會員卡號為{id_label}的用戶畫像.png')
plt.show()


4 最后-畢設幫助
畢設幫助,開題指導,技術解答
🇶746876041

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342045.html
標籤:其他
上一篇:9. spark源代碼分析(基于yarn cluster模式)- Task執行,Reduce端讀取shuffle資料檔案