1.ES核心概念
- 索引
- 欄位型別(mapping)
- 檔案(document)
elasticsearch是面向檔案,關系行資料庫和elasticsearch客觀對比!
| Relational DB | Elasticsearch |
|---|---|
| 資料庫(database) | 索引(indices)(就和資料庫一樣) |
| 表(tables) | types |
| 行(rows) | documents(檔案) |
| 欄位(columns) | fields |
elasticsearch(集群)中可以包含多個索引(資料庫),每個索引中可以包含多個型別(表),每個型別下又包含多個檔案(行),每個檔案中又包含多個欄位(列),
物理設計:
elasticsearch在后臺把每個索引劃分成多個片段,每分分片可以在集群中的不同服務器間遷移
一個人就是一個集群
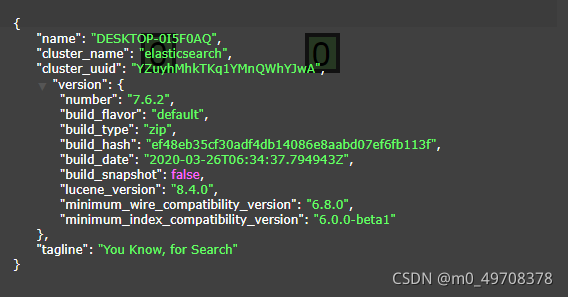
邏輯設計:
一個索引型別中,包含多個檔案,比如說檔案1,檔案2,I當我們索引一篇檔案時,可以通過這樣的一各順序找到它:索引》型別檔案ID,通過這個組合我們就能索引到某個具體的檔案,注意:ID不必是整數,實際上它是個字串,
檔案
就是一條條資料
user
1 zhangsan 19
2 lisi 3
之前說elasticsearch是面向檔案的,那么就意味著索引和搜索資料的最小單位是檔案,elasticsearch中,檔案有幾個重要屬性:·
- 自我包含,一篇檔案同時包含欄位和對應的值,也就是同時包含key:value !
- 可以是層次型的,一個檔案中包含自檔案,復雜的邏輯物體就是這么來的!(就是一個json物件!fastjsoin進行自動轉換!)
- 靈活的結構,檔案不依賴預先定義的模式,我們知道關系型資料庫中,要提前定義欄位才能使用,在elasticsearch中,對于欄位是非常靈活的,有時候,我們可以忽略該欄位,或者動態的添加一個新的欄位,
盡管我們可以隨意的新增或者忽略某個欄位,但是,每個欄位的型別非常重要,比如一個年齡欄位型別,可以是字串也可以是整形,因為elasticsearch會保存欄位和型別之間的映射及其他的設定,這種映射具體到每個映射的每種型別,這也是為什么在elasticsearch中,型別有時候也稱為映射型別,
型別
型別是檔案的邏輯容器,就像關系型資料庫一樣,表格是行的容器,型別中對于欄位的定義稱為映射,比如 name映射為字串型別,我們說檔案是無模式的,它們不需要擁有映射中所定義的所有欄位,比如新增一個欄位,那么elasticsearch是怎么做的呢?elasticsearch會自動的將新欄位加入映射,但是這個欄位的不確定它是什么型別,elasticsearch就開始猜,如果這個值是18,那么elasticsearch會認為它是整形,但是elasticsearch也可能猜不對,所以最安全的方式就是提前定義好所需要的映射,這點跟關系’型資料庫殊途同歸了,先定義好欄位,然后再使用,別整什么么蛾子,
索引
就是資料庫!
索引是映射型別的容器,elasticsearche中的索引是一個非常強大的檔案集合,索引存盤了映射型別的欄位和其他設定,然后他們被存盤在各個分片上了,我們來研究下分片是如何作業的,
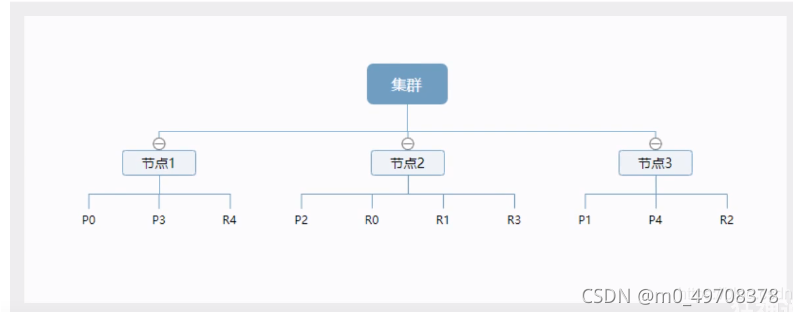
物理設計:節點和分片 如何作業
一個集群至少有一個節點,而一個節點就是一個elasricsearch行程,節點可以有多個索引默認的,如果你創建索引,那么索引將會有個5個分片( primary shard ,又稱主分片)構成的,每一個主分片會有一個副本( replica shard ,又稱復制分片)
倒排索引
elasticsearch使用的是一種稱為倒排索引的結構,采用Lucene倒排索作為底層,這種結構活用于快速的全文搜索,一個索引由檔案中所有不重復的串列構成,對于每一個詞,都有一個包含它的檔案串列,例如,現在有兩個檔案,每個檔案包含如下內容:
study every day,good good up to forever#檔案1包含的內容
To forever,study every day,good good up #檔案2包含的內容
為了創建倒排索引,我們首先要將每個檔案拆分成獨立的詞(或稱為詞潭訓者tokens),然后創建一個包含所有不重復的詞條的排序串列,然后列出每個詞條出現在哪個檔案:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | × |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
現在,我們試圖搜索to forever,只需要查看包含每個詞條的檔案
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
兩個檔案都匹配,但都是第一個檔案比第二個匹配程度更高,然后沒有別的條件,現在,這兩個包含關鍵字的檔案都將回傳,
再來看一個示例,比如我們通過博客標簽來搜索博客文章,那么倒排索引串列就是這樣的一個結構;
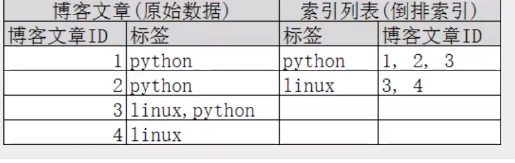
如果要搜索含有python標簽的文章,那相對于查找所有原始資料而言,查找倒排索引后的資料將會快的多,只需要查看標簽這-欄,然后獲取相關的文章ID即可,完全過濾掉無關的所有資料,提高效率!
elasticsearch的索引和Lucene的索引對比
在elasticsearch中,索引(庫)這個詞被頻繁使用,這就是術語的使用,在elasticsearch中,索引被分為多個分片,每份分片是一個Lucene的索引,所以一個elasticsearch索引是由多個Licene索引組成的,別問為什么,誰讓elasticsearch使用Lucene作為底層呢!如無特指,說起索引都是指elasticsearch的索引,
接下來的一切操作都在kibana中Dev Tools下的Console里完成,基礎操作!
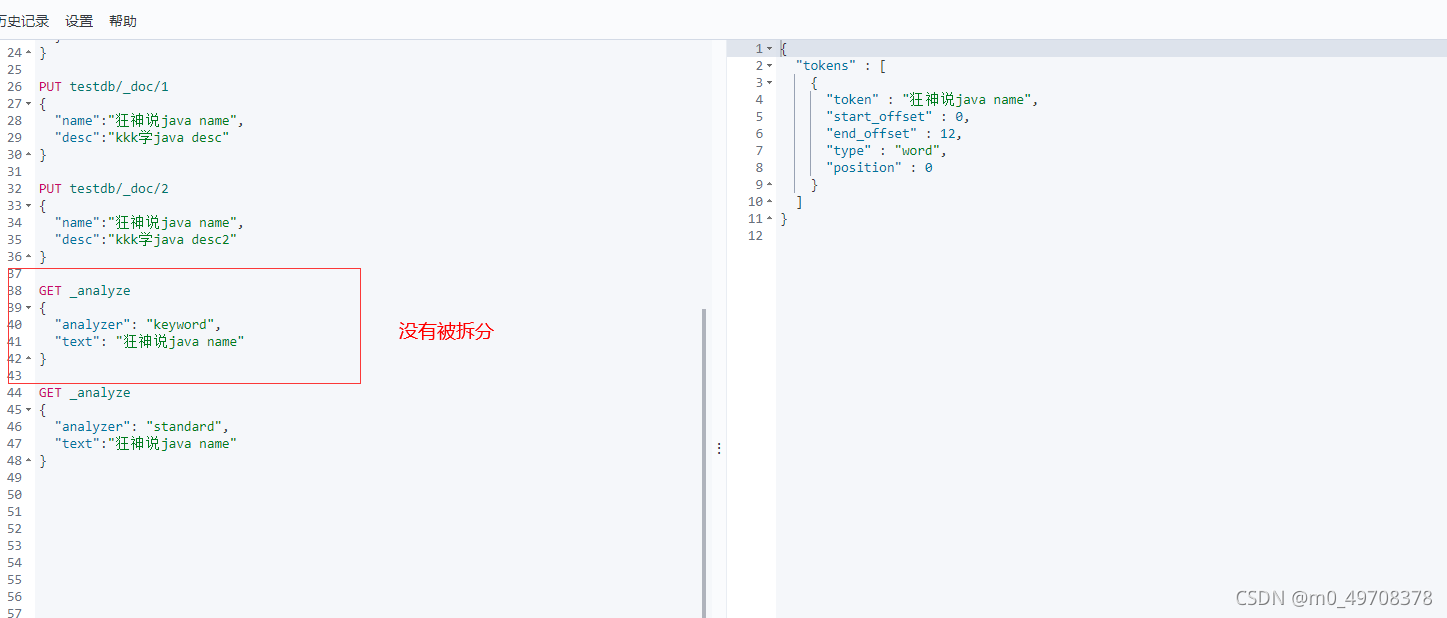
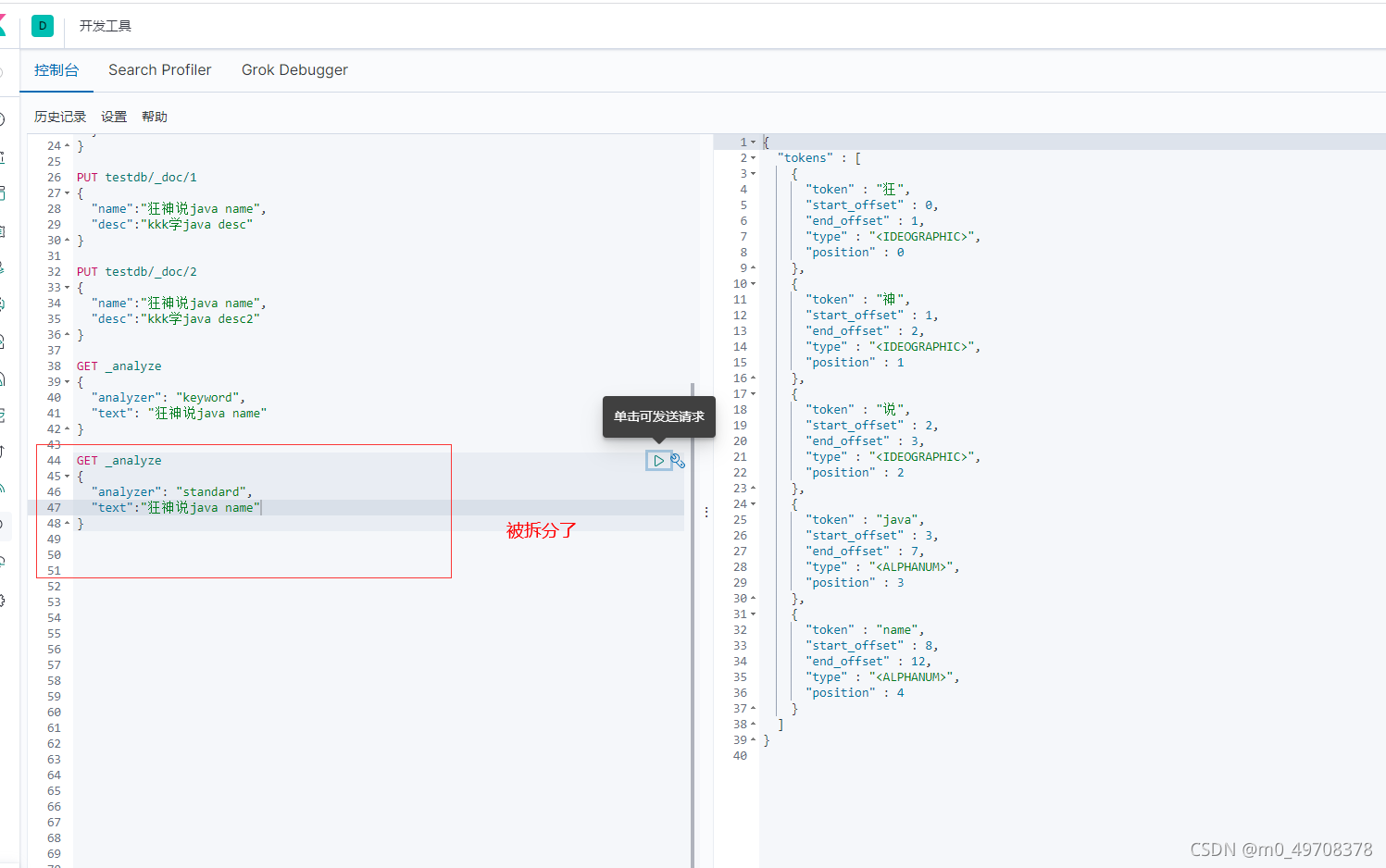
2.IK分詞器插件
解壓到plugins下面
查看ik分詞器被加載

使用kibana測驗
查看不同分詞器效果
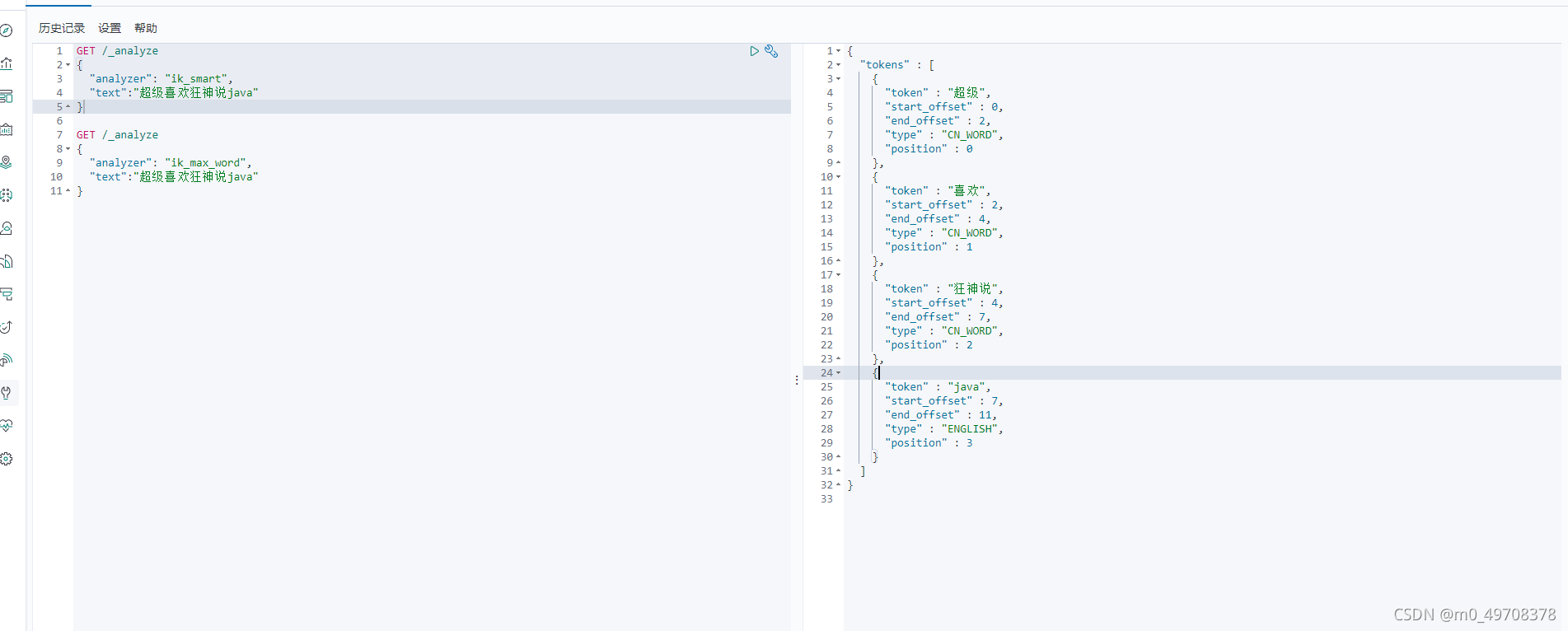
ik——smart為最小切分
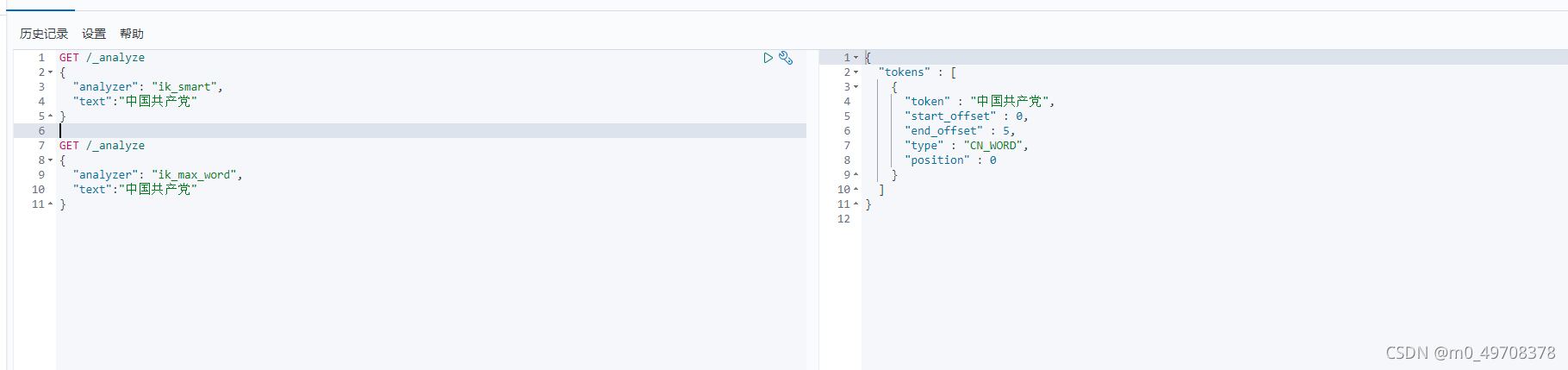
ik_max_word為最細粒度劃分,窮盡詞庫的可能!字典!
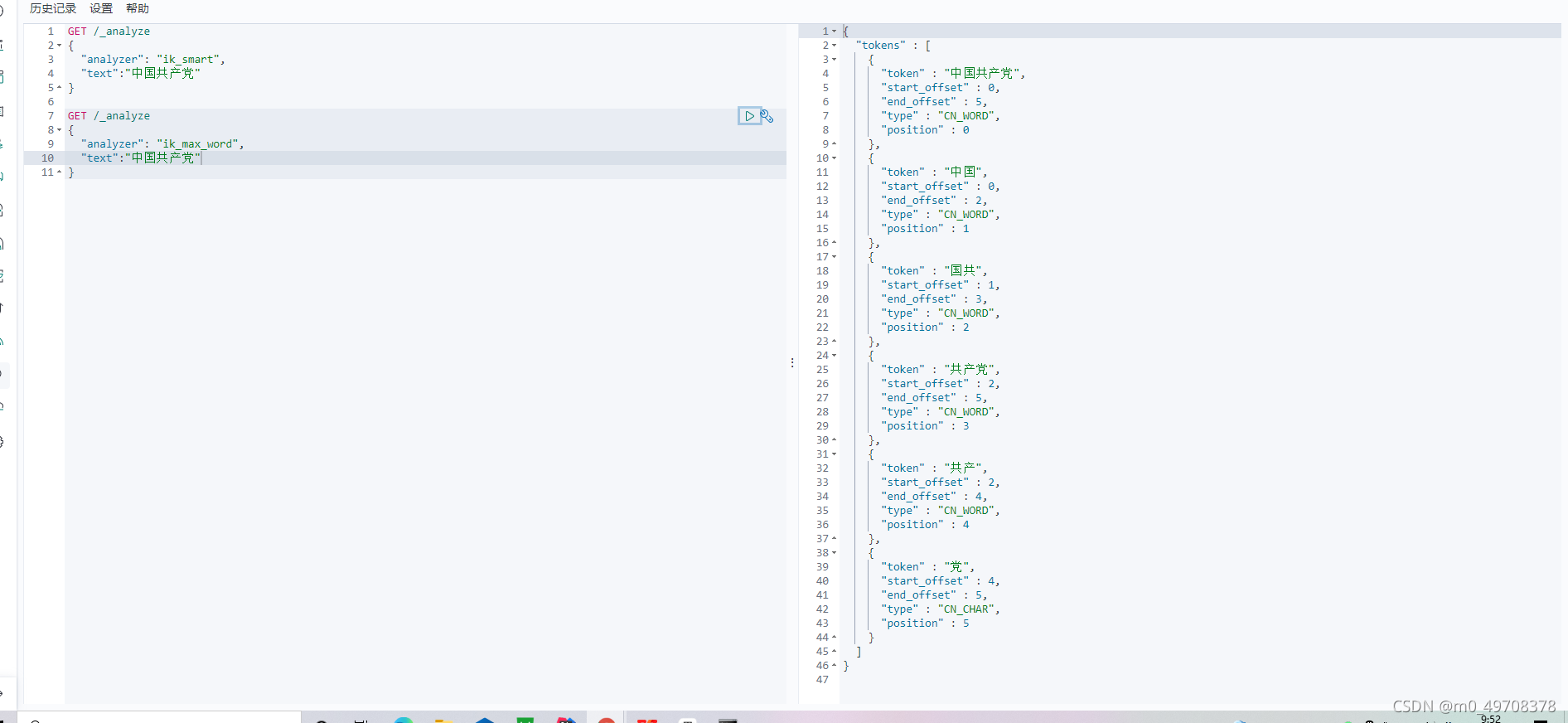
我們輸入超級喜歡狂神說java
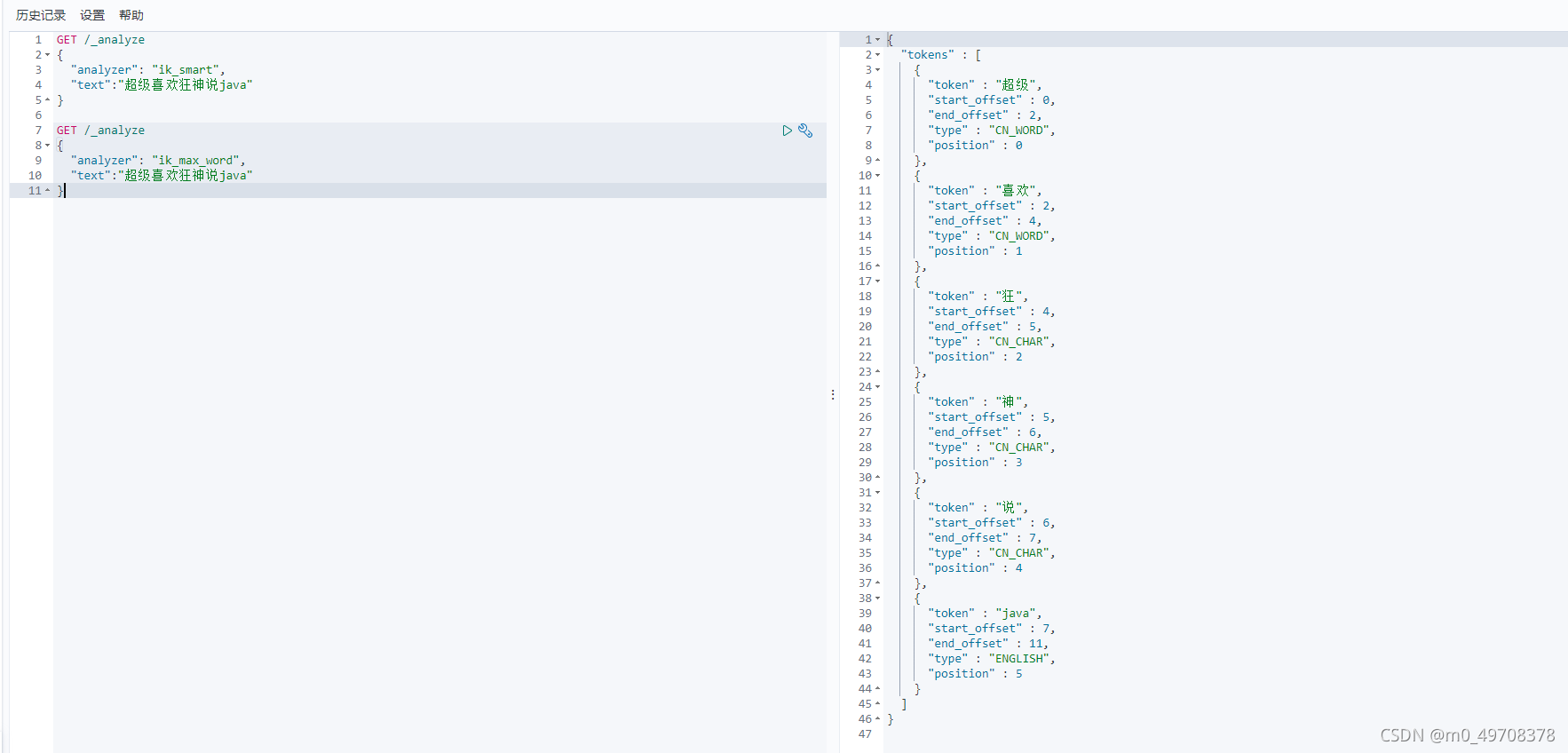
發現檔案狂說說被拆開
這種自己需要的詞,需要自己加到我們的分詞器的字典中!
ik分詞器增加自己的配置
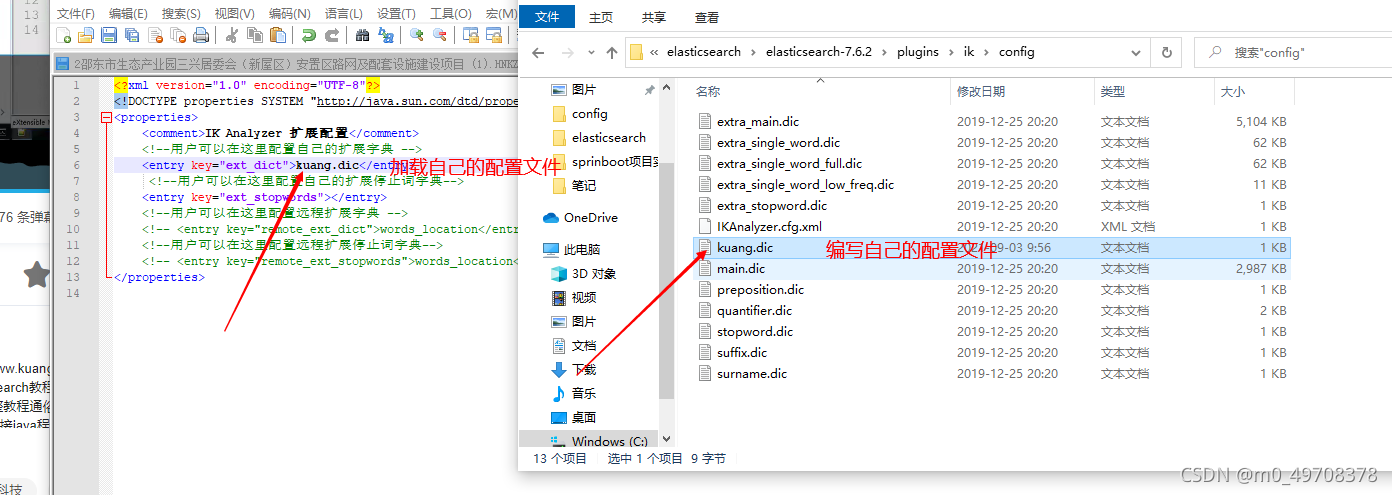
重啟es
以后的話,我們需要自己的配置,分詞就在自己定義的dic檔案中進行配置
3.Rest風格說明
一種軟體架構風格,而不是標準,更易于實作快取等機制
基本rest命令說明:
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名稱/型別名稱/檔案id | 創建檔案(指定檔案id) |
| POST | localhost:9200/索引名稱/型別名稱 | 創建檔案(隨機檔案id) |
| POST | localhost:9200/索引名稱/型別名稱/檔案id/_update | 修改檔案 |
| DELETE | localhost:9200/索引名稱/型別名稱/檔案id | 洗掉檔案 |
| GET | localhost:9200/索引名稱/型別名稱/檔案id | 通過檔案id查詢 |
| POST | localhost:9200/索引名稱/型別名稱/_search | 查詢所有資料 |
關于索引的基本操作
基礎測驗
1.創建一個索引
PUT /索引名/~型別名~ /檔案id
{請求體}
完成了自動添加索引!資料也成功添加了
3.那么name這個欄位用不用指定型別呢

4.指定欄位型別
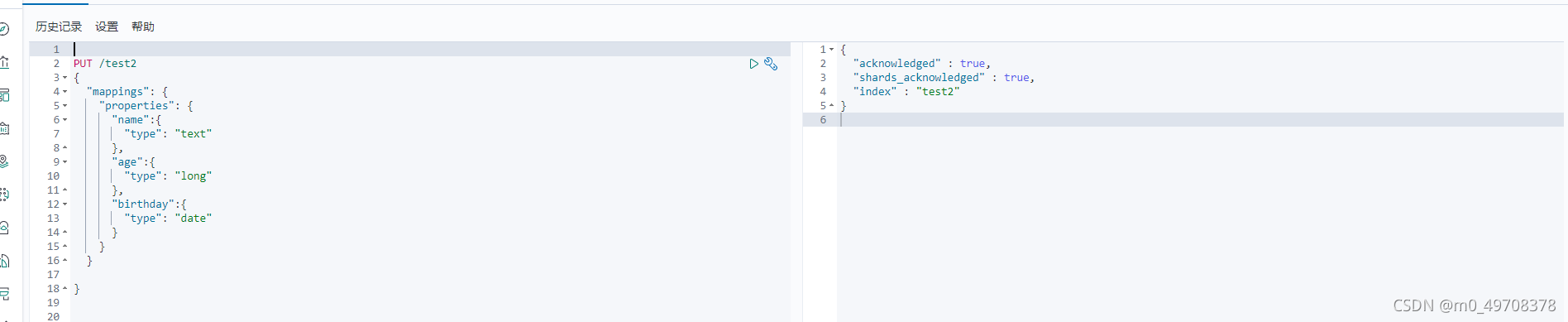
獲得規則,可以通過get獲得具體的資訊
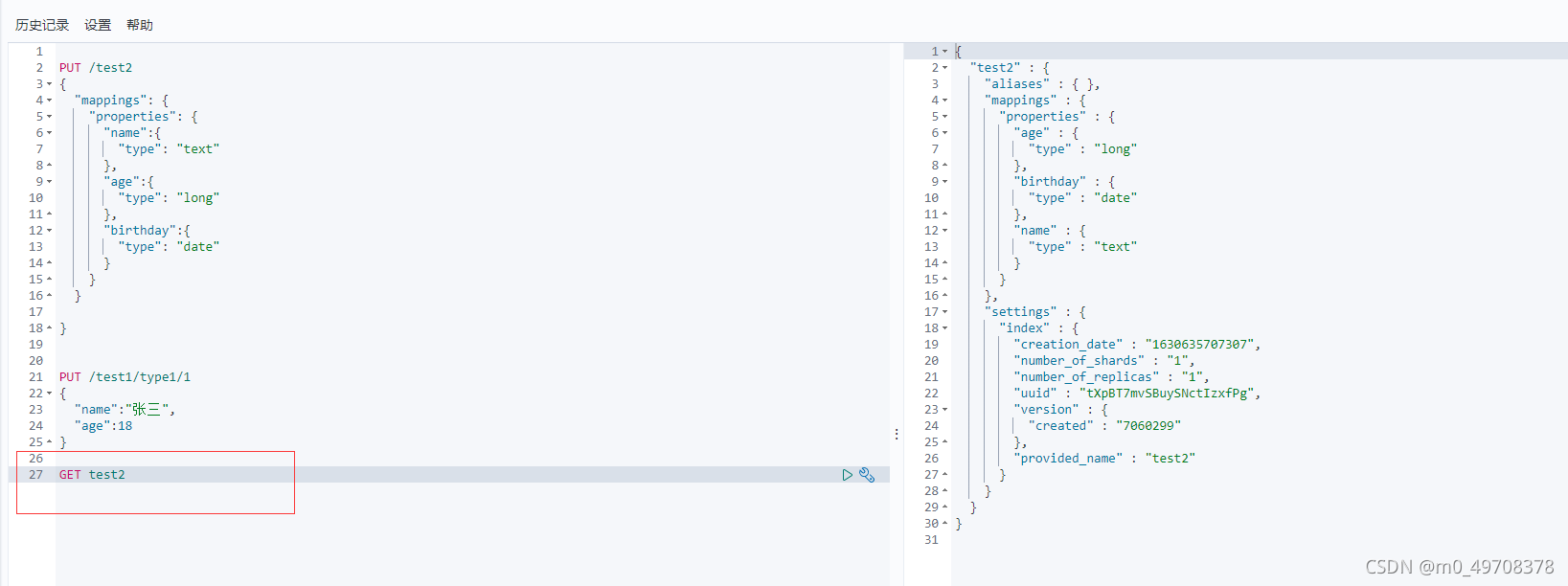
5.查看默認的資訊
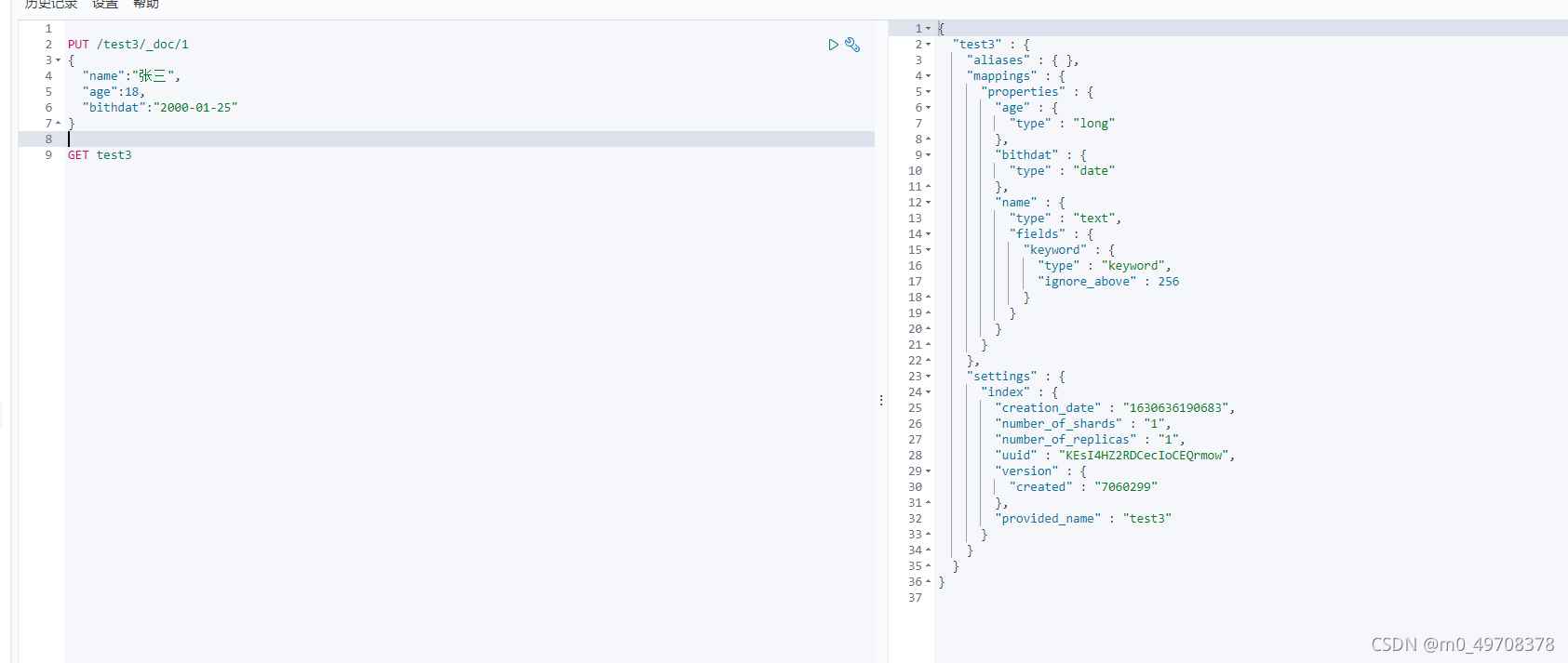
如果自己檔案型別沒有指定,那么es就是會默認配置欄位型別!
擴展: 通過get _cat/可以獲得當前es很多資訊
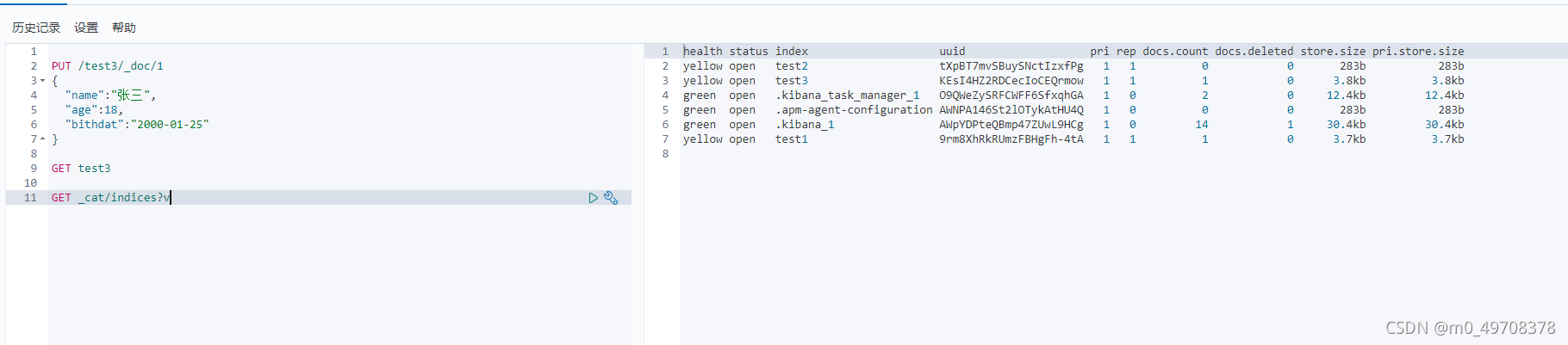
修改索引 還是PUT!
曾經
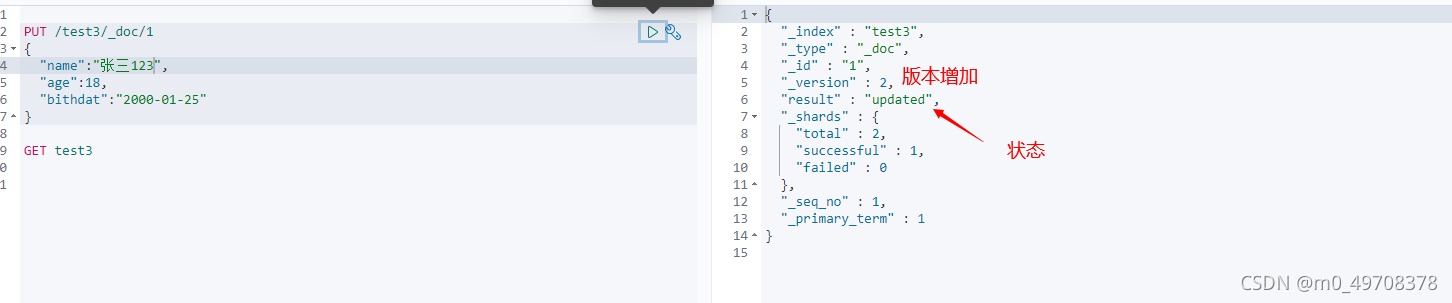
現在的方法!

洗掉索引
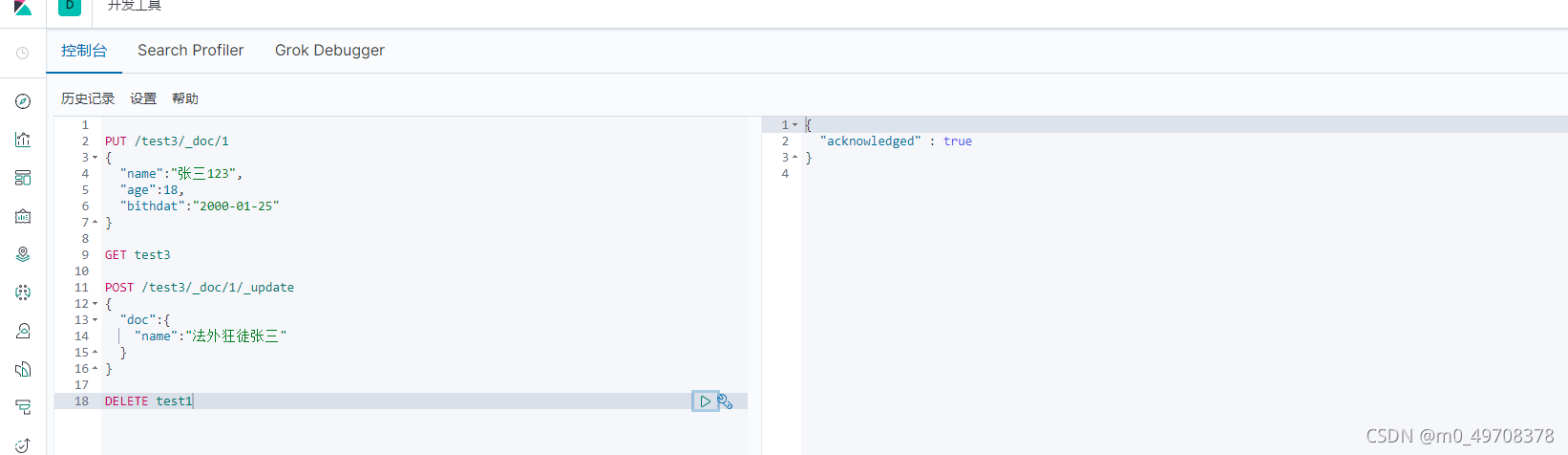
通過delete實作洗掉,根據請求來判斷來洗掉索引還是索引記錄!
使用rest風格是es推薦使用的
關于檔案的基本操作(重點)
基本操作
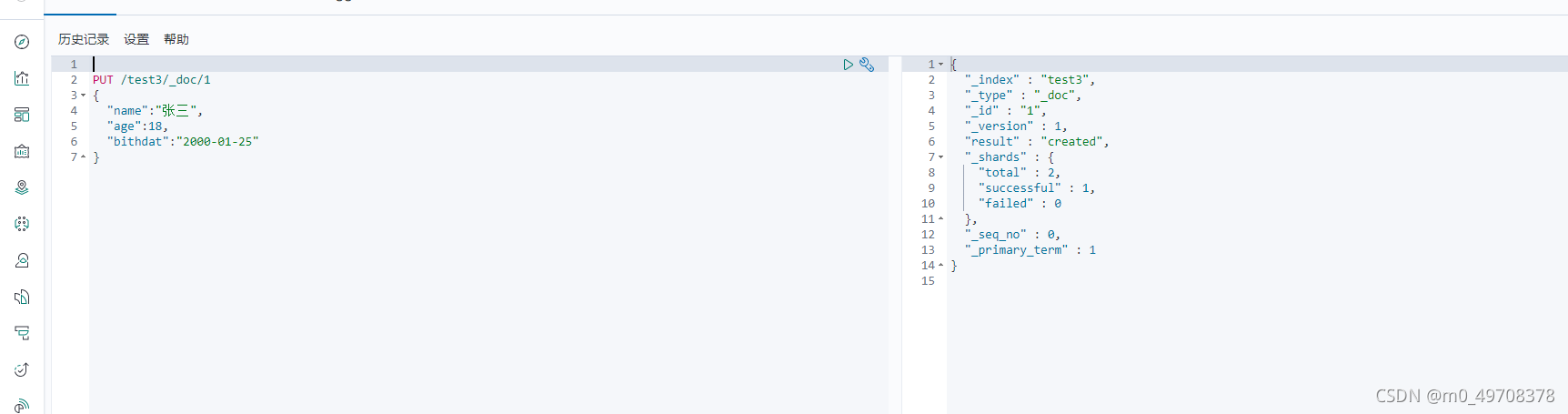
1、添加資料
PUT /kuang/user/1
{
"name":"張三",
"age":23,
"desc":"高級java開放",
"tags":["技術","籃球","飛賊"]
}
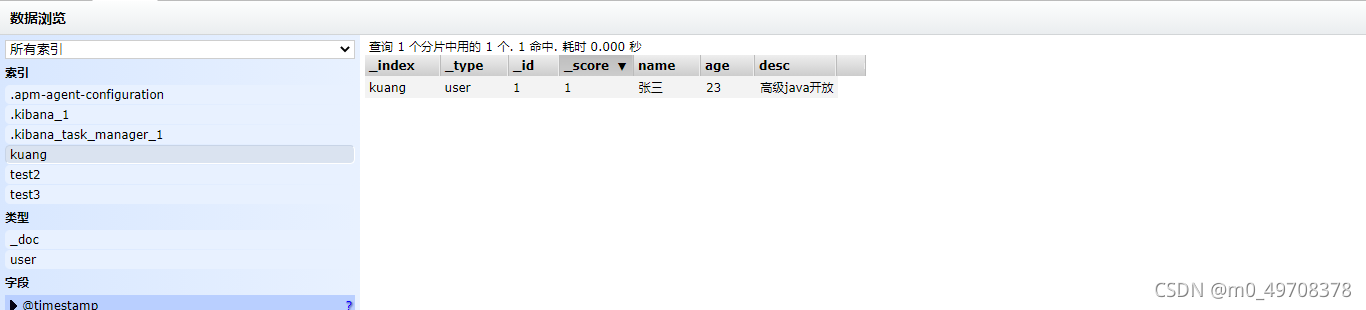
2.獲取資料
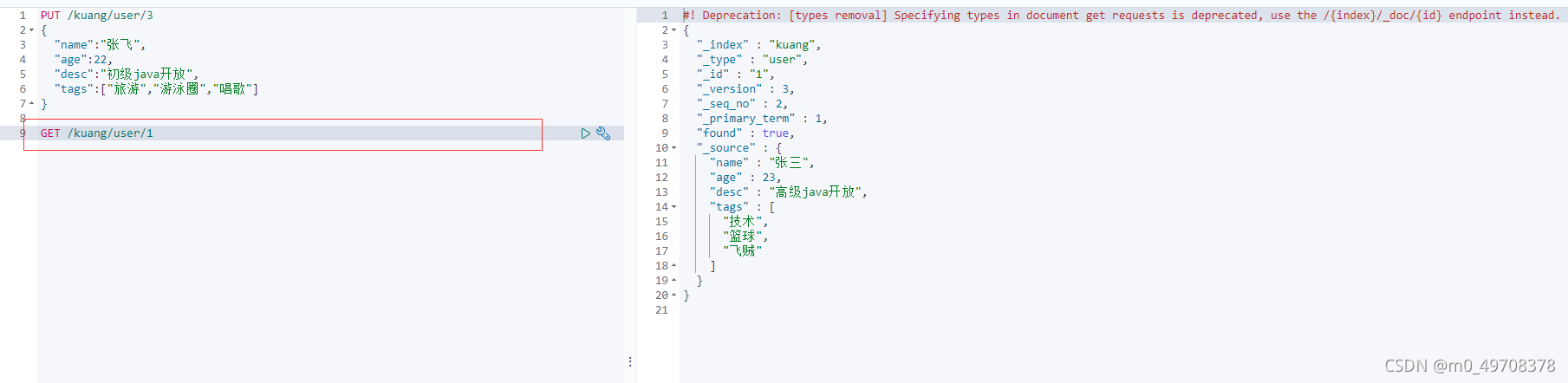
3.更新資料
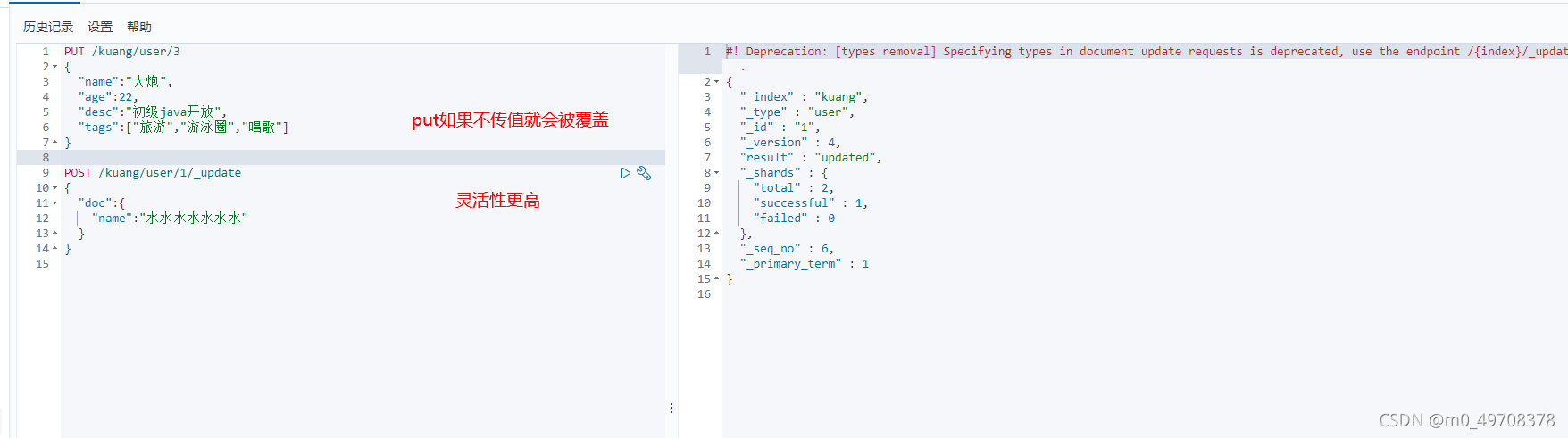
簡單搜索
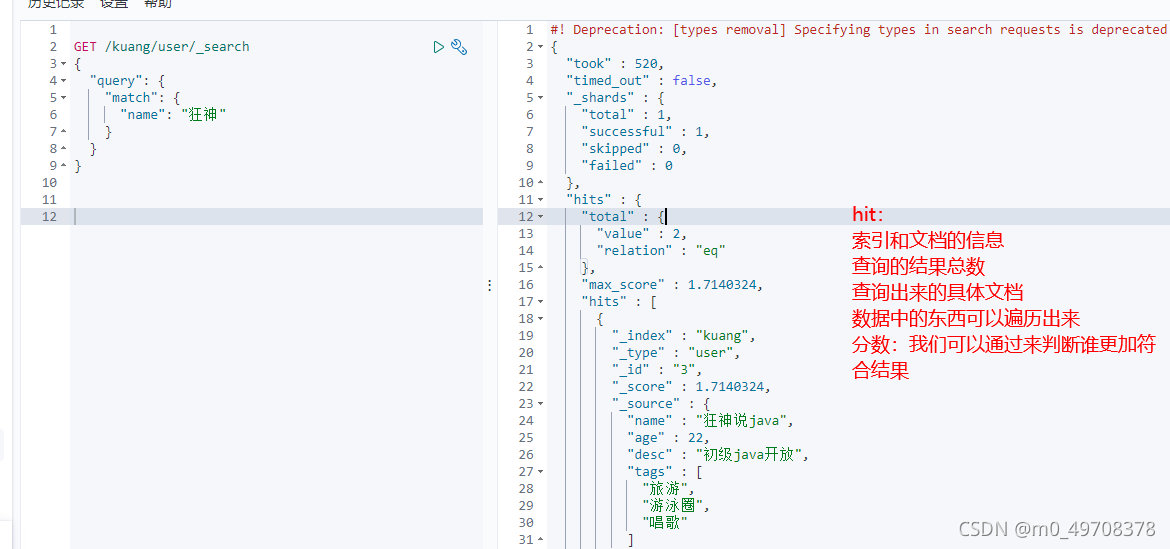
GET /kuang/user/1
簡單條件查詢,可以根據默認的映射規則,產生基本查詢
GET /kuang/user/_search?q=name:"狂神說"
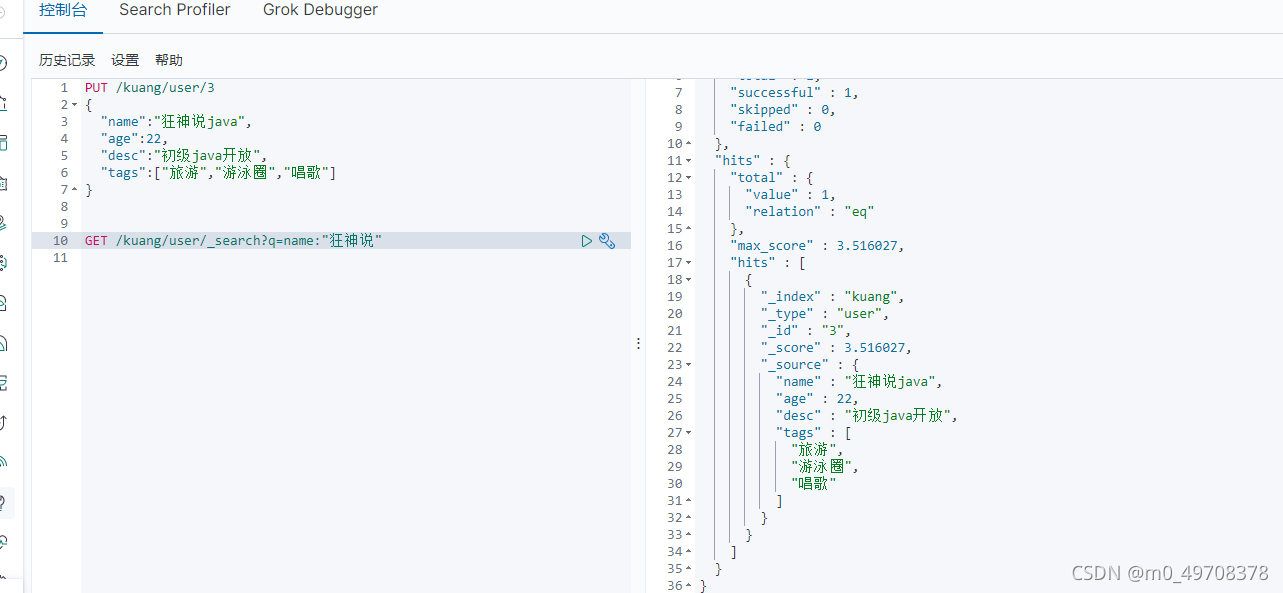
score匹配度
復雜操作搜索select(排序,分頁,模糊查詢,精準查詢,高亮,)
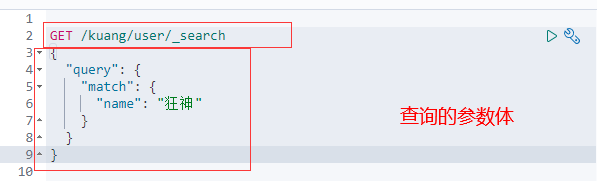
輸出結果,不想要那么多!
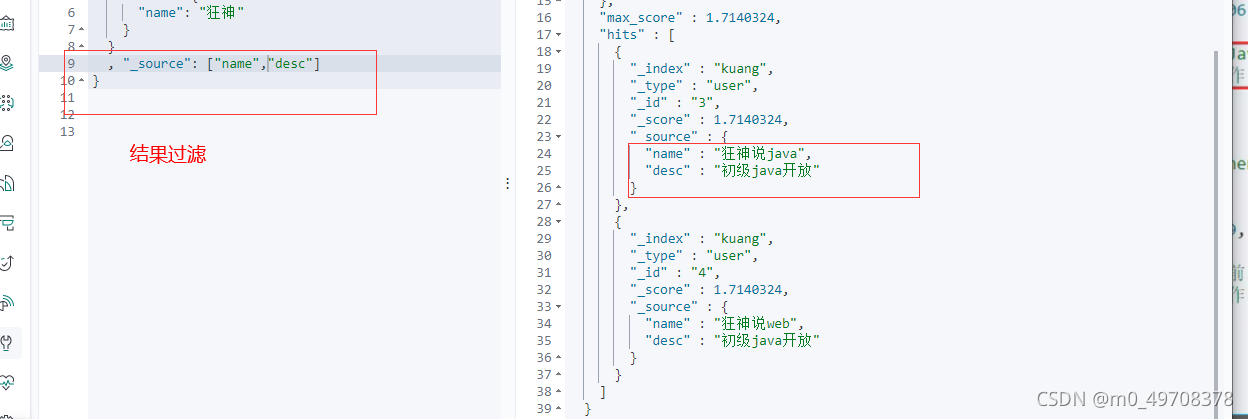
我們之后使用java操作es所有的方法和物件就是這里面的key
排序
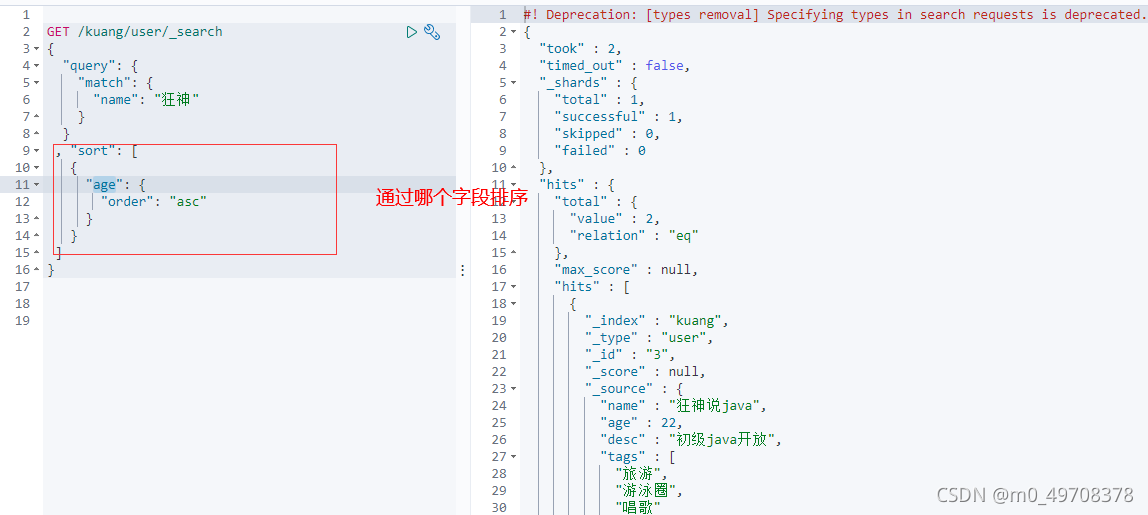
分頁
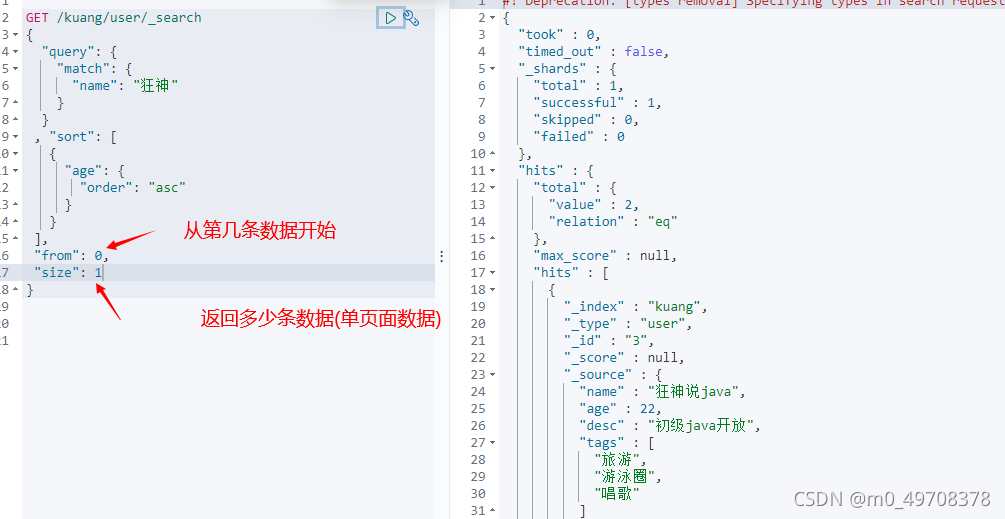
資料下表還是從0開始的
/search/{current}/{pagesize}
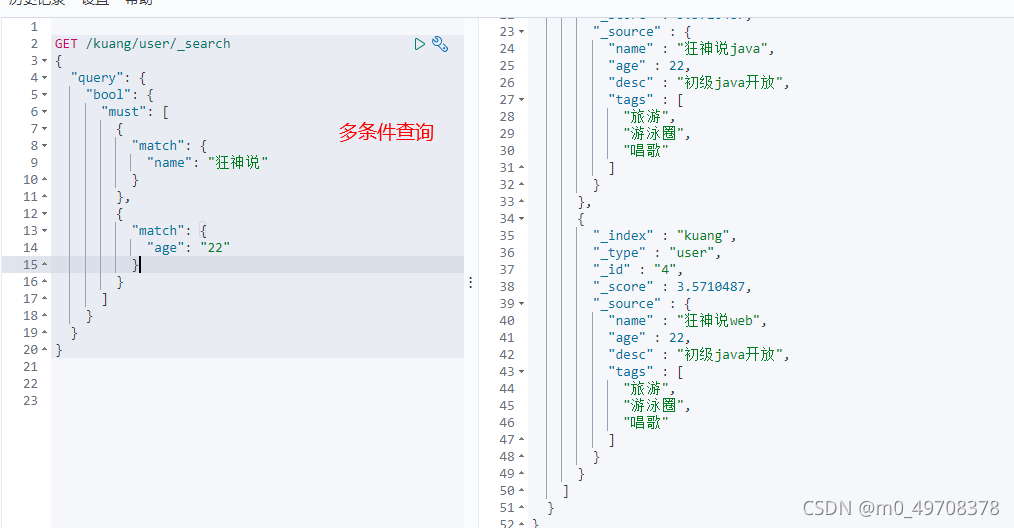
布林值查詢
must(and) ,所有的條件都要符合
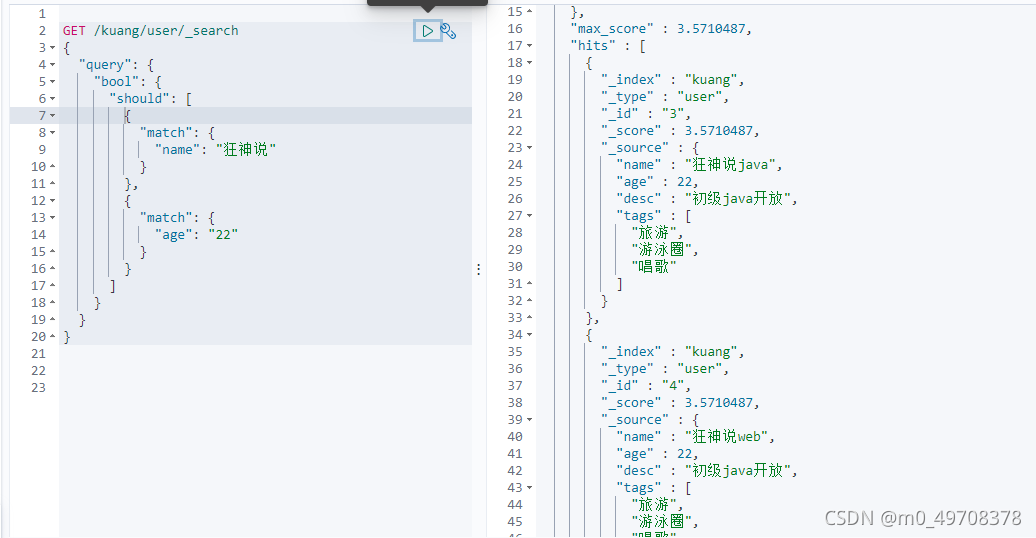
should (or),兩個條件滿足其一就可以了
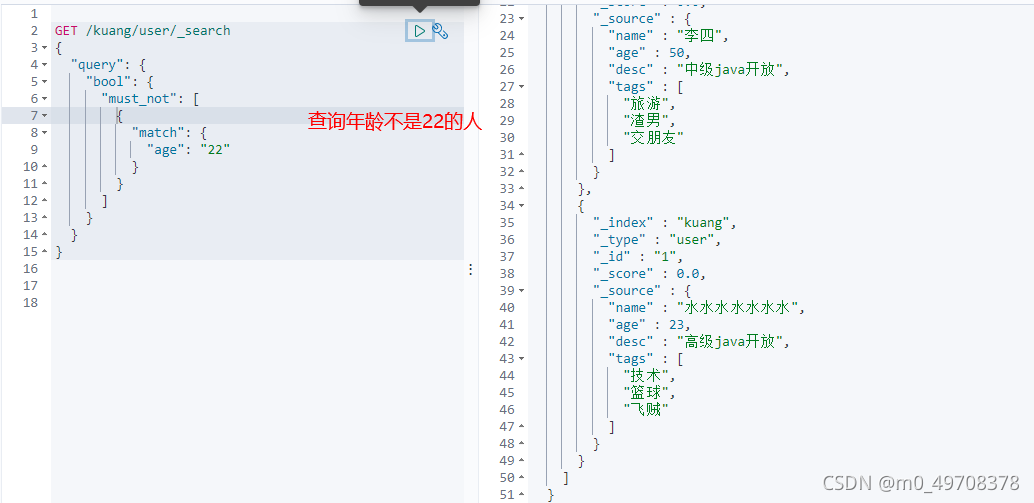
muse_not(not)
條件區間
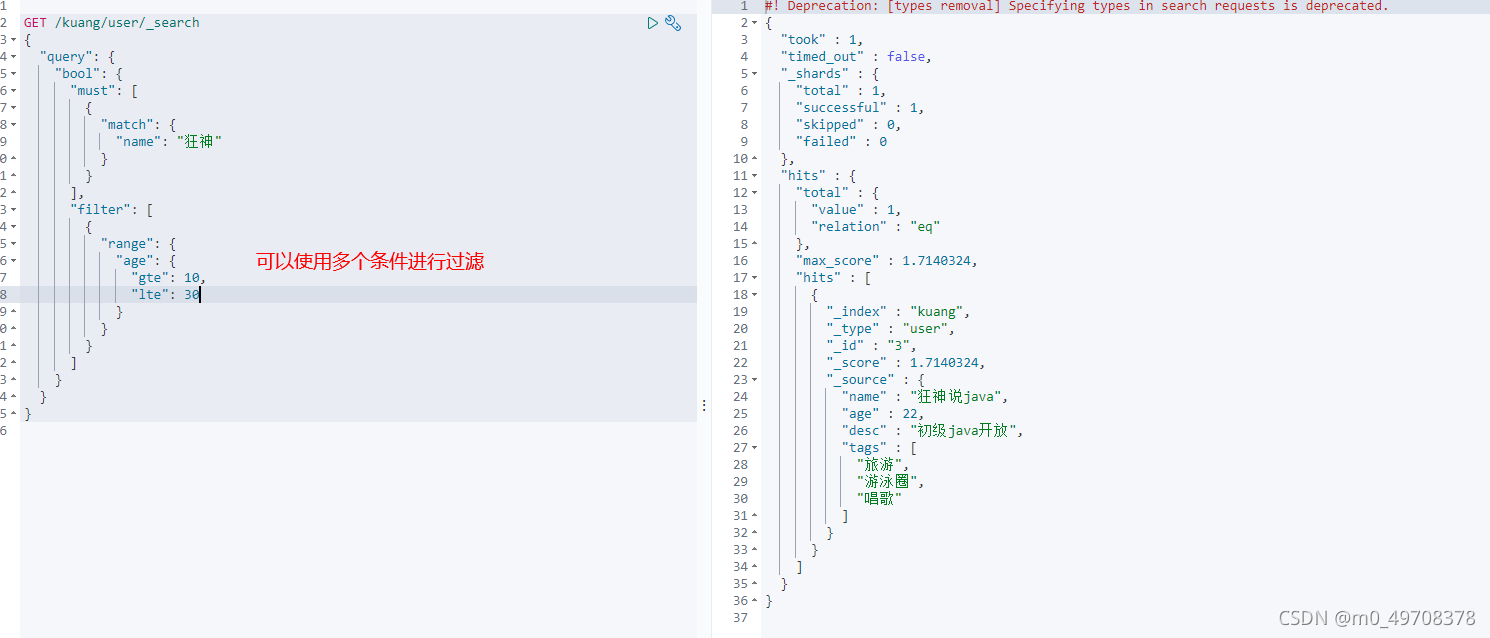
- gt大于
- gte大于等于
- lte小于
- lte小于等于
匹配多個條件
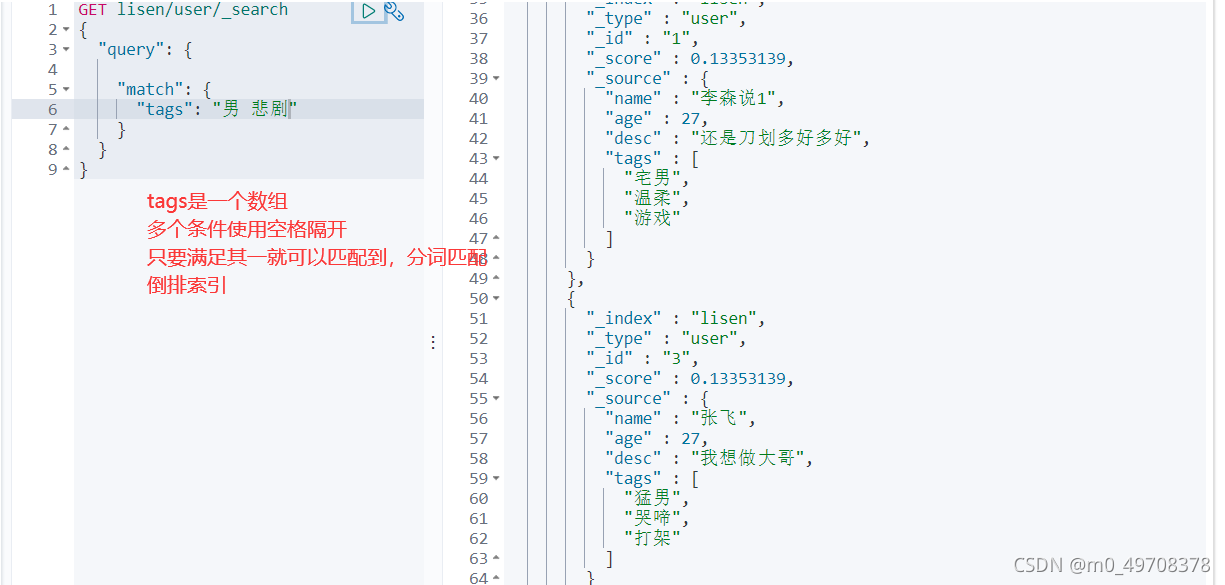
精確查詢!
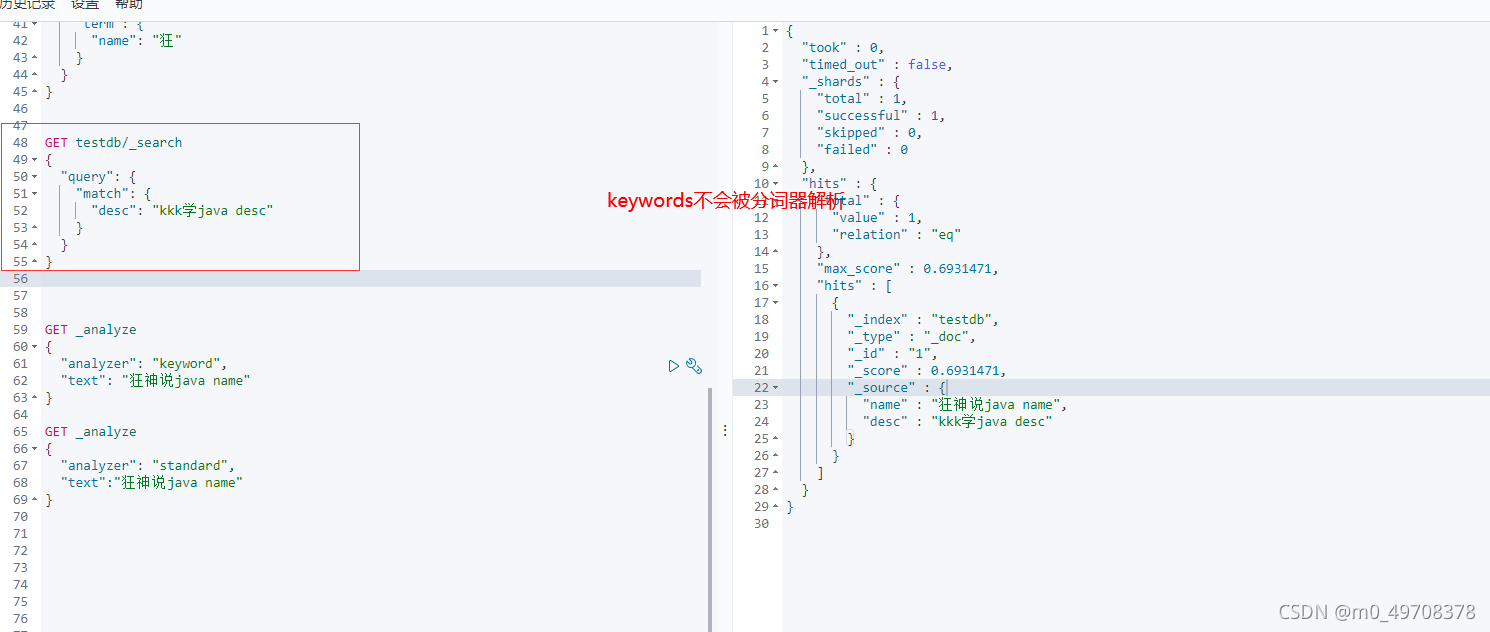
- term,直接查詢精確的
- match,會使用分詞器決議!(先分析檔案,然后通過分析的檔案進行查詢)
兩個型別 text keyword
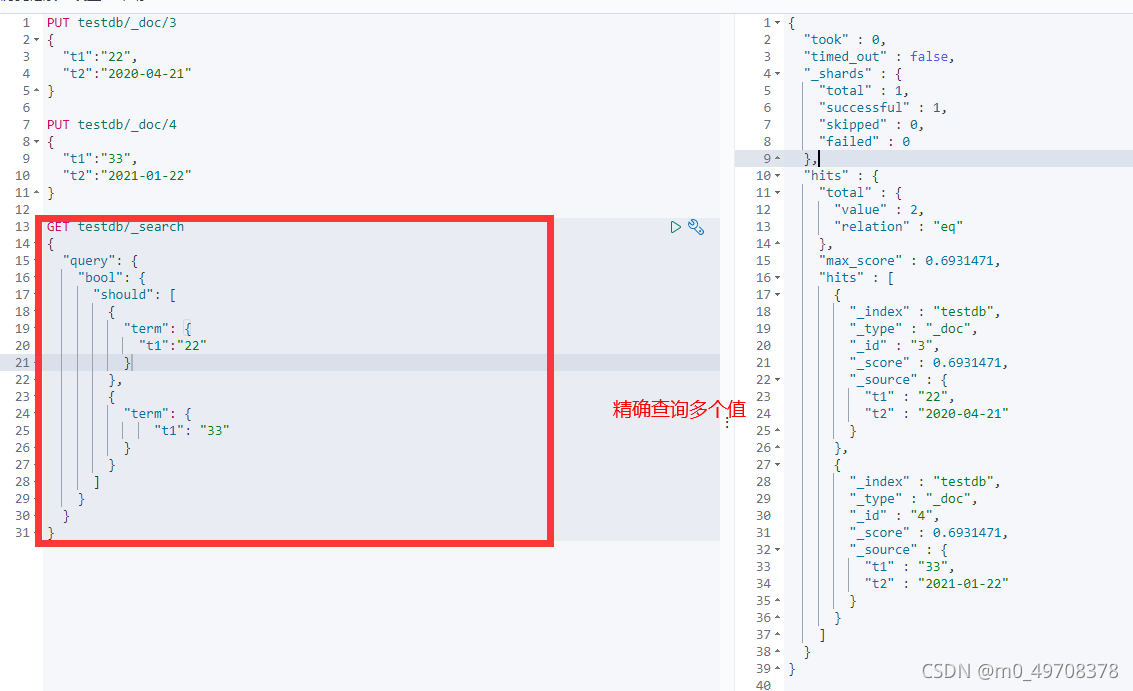
多個值匹配的精確查詢
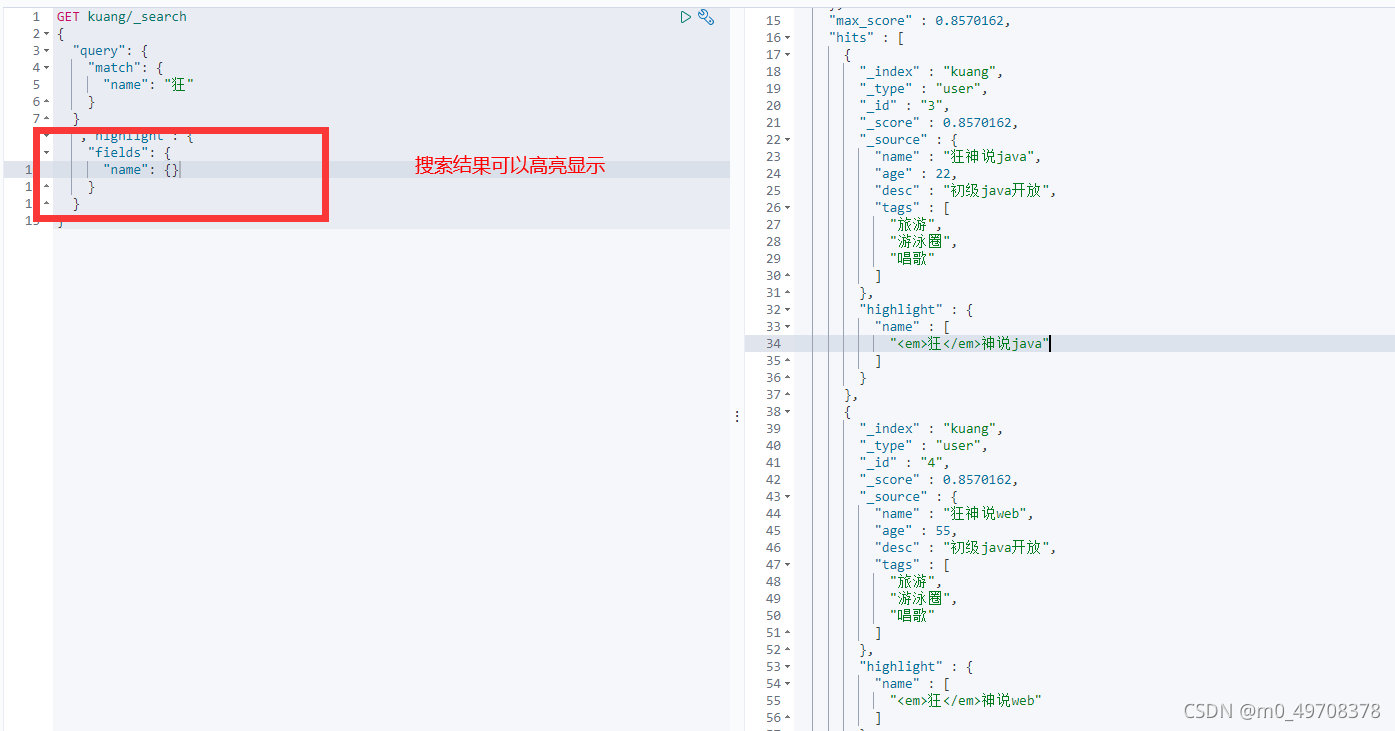
高亮
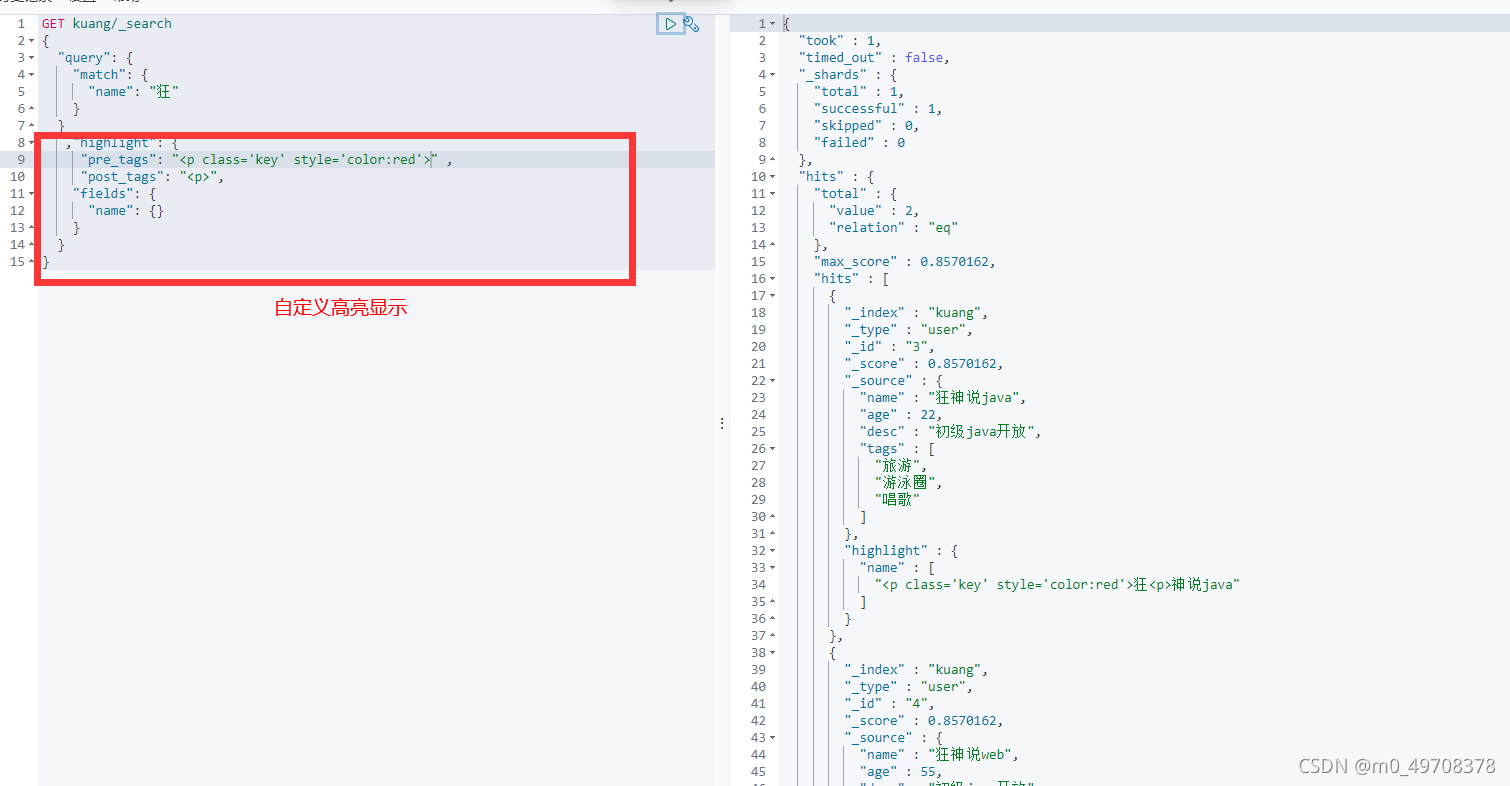
還能自定義高亮的樣式
- 匹配
- 按照條件匹配
- 精確匹配
- 區間范圍匹配
- 匹配過濾欄位
- 多條件查詢
- 高亮查詢
集成springboot
匯入依賴
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
爬蟲
資料問題?資料庫獲取,訊息佇列中獲取,都可以成為資料源
爬取資料:獲取請求頭回傳的頁面資訊,篩選出我們自己想要的資料
jsoup包!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342050.html
標籤:其他
下一篇:Kafka的高性能原理