文章目錄
- HDFS Shell命令使用
- 1. mkdir:創建檔案夾
- 示例1:在分布式主目錄下新建檔案夾test
- 示例2:在根目錄下新建檔案夾/test/dir0/dir1,如果上一級目錄不存在,需要使用到-p引數,
- 2. touchz:新建檔案
- 示例:在/test/下新建檔案file1
- 3. ls 列指定目錄檔案和目錄
- 表一ls命令選項和功能
- 示例1:列出/test目錄下的所有檔案和目錄資訊
- 示例2:列出/test目錄資訊
- 示例3:列出目錄和檔案的大小
- 示例4:回圈列出目錄、子目錄及檔案資訊
- 4. rm洗掉目錄和檔案
- 表二rm命令的選項和功能
- 示例1:洗掉檔案
- 示例2:洗掉目錄及目錄下的目錄和檔案
- 5. put/get:上傳/下載
- 示例1:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,保存名為hfile;
- 示例2:把分布式檔案系統目錄下的檔案復制到本地
- 示例3:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,覆寫原來的檔案
- 示例4:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,保持源檔案屬性
- 6. cat、text、tail:查看檔案內容
- 示例1:查看檔案的內容
- 7. appendToFile:追寫檔案
- 示例1:把本地檔案系統檔案追加到分布式檔案系統中
- 8. du:顯示占用磁盤空間大小
- 示例1:顯示分布式主目錄下檔案和目錄大小
- 9. cp復制檔案
- 示例1:
- 10. chmod修改檔案權限
- 示例1:
- 示例2:
- 11. chown修改檔案屬主和組
- 示例1:
- 示例2:
- 12. chgrp修改檔案屬組
- 示例1:
- 示例2:
- 13. dfsadmin顯示HDFS運行狀態和管理HDFS
- 表三 dfsadmin命令選項和功能
- 示例1:顯示檔案系統的基本資訊和統計資訊
- 示例2:獲取安全模式
- 示例3:進入安全模式
- 示例3:可以強制創建檢查點
- 示例4:
- 14. Namenode 格式化升級回滾
- 15. fsck檢查實用程式
- 示例1:檢查目錄中檔案完整性
- 示例2:移動找到已損壞的檔案
- 示例3:洗掉已損壞的檔案
- 示例4:檢查HDFS系統上/test目錄下的塊資訊和檔案名
HDFS Shell命令使用
hadoop fs與hdfs dfs的命令的使用是相似的,本實驗使用的是hdfs dfs命令,所有命令的操作都是在hadoop用戶下進行,
1. mkdir:創建檔案夾
使用方法:hdfs fs -mkdir [-p]
接受路徑指定的uri作為引數,創建這些目錄,其行為類似于Unix的mkdir -p,它會創建路徑中的各級父目錄,
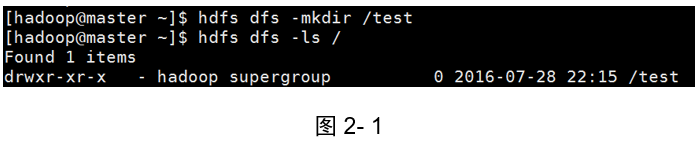
示例1:在分布式主目錄下新建檔案夾test
[hadoop@master ~]$ hdfs dfs -mkdir /test
[hadoop@master ~]$hdfs dfs -ls /
結果(如圖2-1所示):
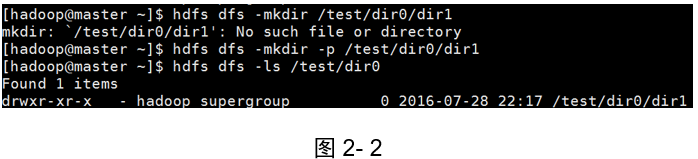
示例2:在根目錄下新建檔案夾/test/dir0/dir1,如果上一級目錄不存在,需要使用到-p引數,
[hadoop@master ~]$ hdfs dfs -mkdir -p /test/dir0/dir1
[hadoop@master ~]$ hdfs dfs -ls /test/dir0
結果(如圖2-2所示):
2. touchz:新建檔案
使用方法:hdfs fs -touchz URI [URI …]
當前時間下創建大小為0的空檔案,若大小不為0,回傳錯誤資訊,
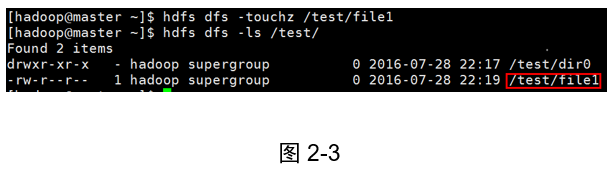
示例:在/test/下新建檔案file1
[hadoop@master ~]$ hdfs dfs -touchz /test/file1
[hadoop@master ~]$ hdfs dfs -ls /test/
結果(如圖2-3所示):
3. ls 列指定目錄檔案和目錄
使用方法:hdfs dfs -ls [-d][-h][-R]
表一ls命令選項和功能
| 選項 | 功能說明 |
|---|---|
| -d | 回傳paths |
| -h | 按照KMG資料大小單位顯示檔案大小,如果沒有單位,默認認為B |
| -R | 級聯顯示paths下檔案,這里paths是個多級目錄 |
示例1:列出/test目錄下的所有檔案和目錄資訊
[hadoop@master ~]$ hdfs dfs -ls /test
結果(如圖2-4所示):

示例2:列出/test目錄資訊
[hadoop@master ~]$ hdfs dfs -ls -d /test
結果(如圖2-5所示):

示例3:列出目錄和檔案的大小
[hadoop@master ~]$ hdfs dfs -ls -h /test
結果(如圖2-6所示):
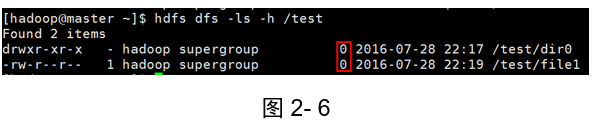
因為這些檔案和目錄都是新建的,所以檔案和目錄的大小為零,
示例4:回圈列出目錄、子目錄及檔案資訊
[hadoop@master ~]$ hdfs dfs -ls -R /test
結果(如圖2-7所示):

4. rm洗掉目錄和檔案
使用方法:hdfs dfs -rm [-f] [-r|-R] [-skip Trash]
表二rm命令的選項和功能
| 選項 | 說明 |
|---|---|
| -f | 如果要洗掉的檔案不存在,不顯示提示和錯誤資訊 |
| -r l R | 級聯洗掉目錄下的所有檔案和子目錄檔案 |
| -skipTrash | 直接洗掉,不進入垃圾回車站 |
示例1:洗掉檔案
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
[hadoop@master ~]$ hdfs dfs -rm /test/dir0/file3
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
結果:
洗掉前(如圖2-8所示)

洗掉后(如圖2-9所示)

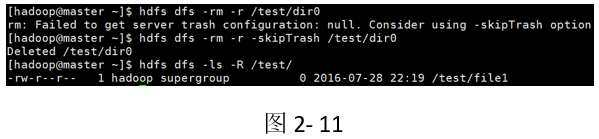
示例2:洗掉目錄及目錄下的目錄和檔案
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0
[hadoop@master ~]$ hdfs dfs -rm -r /test/dir0
[hadoop@master ~]$ hdfs dfs -ls -R /test/
結果:
洗掉前(如圖2-10所示):

洗掉后(如圖2-11所示):
5. put/get:上傳/下載
使用方法: hdfs dfs -put [-f] [-p] …
hdfs dfs -get [-p] [-ignoreCrc] [-crc] …
put將本地檔案系統的復制到HDFS檔案系統的目錄下
get 將HDFS中的檔案復制到本地檔案系統中,與-put命令相反
-f如果檔案在分布式檔案系統上已經存在,則覆寫存盤,若不加則會報錯;-p保持源檔案的屬性(組、擁有者、創建時間、權限等);-ignoreCrc同上,
示例1:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,保存名為hfile;
(如圖2-12所示)
[hadoop@master ~]$ touch /tmp/test.txt
[hadoop@master ~]$ ls -l /tmp/test.txt
[hadoop@master ~]$ hdfs dfs -put /tmp/test.txt /test/hfile
[hadoop@master ~]$ hdfs dfs -ls /test/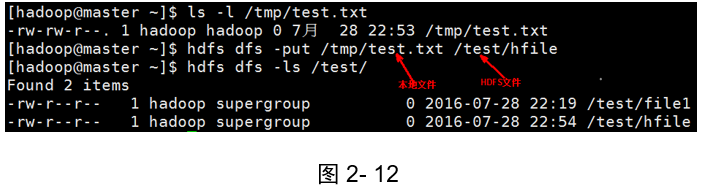
示例2:把分布式檔案系統目錄下的檔案復制到本地
[hadoop@master3 hadoop]$ hdfs dfs -get /test/hfile /home/hadoop/hfile
[hadoop@master ~]$ ls -l /home/hadoop/hfile
結果(如圖2-13所示):

示例3:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,覆寫原來的檔案
(如圖2-14和2-15所示)
[hadoop@master ~]$ hdfs dfs -ls /test/hfile

[hadoop@master ~]$ hdfs dfs -put -f /home/hadoop/hfile /test/hfile
[hadoop@master ~]$ hdfs dfs -ls /test/hfile

示例4:把本地新建的檔案test.txt放到分布式檔案系統主目錄下,保持源檔案屬性
[hadoop@master ~]$ ls -l /home/hadoop/file
結果(如圖2-16和2-17所示):

[hadoop@master ~]$ hdfs dfs -put -p /home/hadoop/file /test/
[hadoop@master ~]$ hdfs dfs -ls /test/file

6. cat、text、tail:查看檔案內容
使用方法:hdfs dfs -cat/text [-ignoreCrc]
Hdfs dfs -tail [-f]
其中:-ignoreCrc忽回圈檢驗失敗的檔案;-f動態更新顯示資料,如查看某個不斷增長的檔案的日志檔案,
3個命令都是在命令列視窗查看指定檔案內容,區別是text不僅可以查看文本檔案,還可以查看壓縮檔案和Avro序列化的檔案,其他兩個不可以;tail查看的是最后1KB的檔案(Linux上的tail默認查看最后10行記錄),
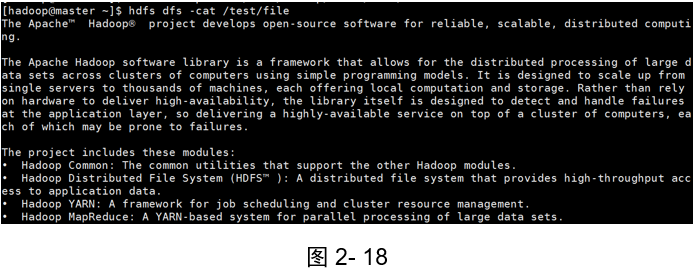
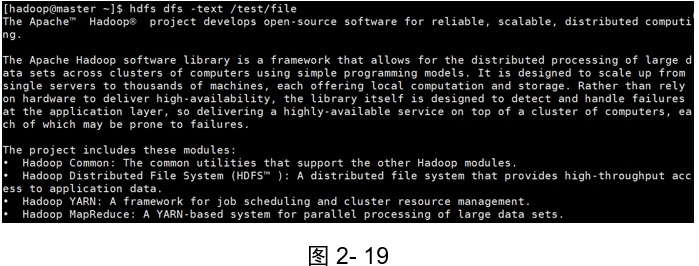
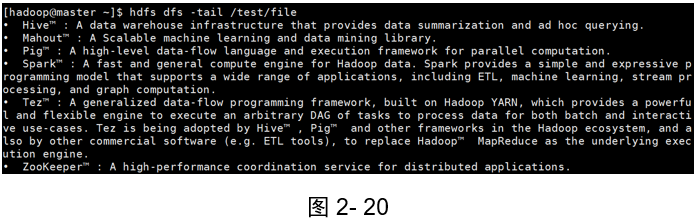
示例1:查看檔案的內容
(如圖2-18、2-19和2-20)
[hadoop@master ~]$ hdfs dfs -cat /test/file
[hadoop@master ~]$ hdfs dfs -text /test/file
[hadoop@master ~]$ hdfs dfs -tail /test/file
7. appendToFile:追寫檔案
使用方法:hdfs dfs -appendToFile …
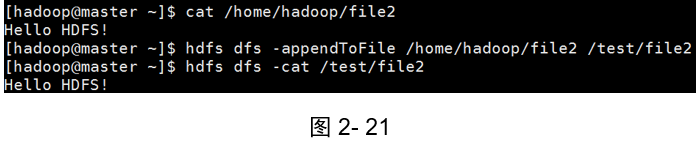
示例1:把本地檔案系統檔案追加到分布式檔案系統中
(如圖2-21所示)
[hadoop@master ~]$ cat /home/hadoop/file2
[hadoop@master ~]$ hdfs dfs -appendToFile /home/hadoop/file2 /test/file2
[hadoop@master ~]$ hdfs dfs -cat /test/file2
8. du:顯示占用磁盤空間大小
使用方法: hdfs dfs -du [-s] [-h]
默認按位元組顯示指定目錄所占空間大小,其中,-s顯示指定目錄下檔案總大小;-h按照KMG資料大小單位顯示檔案大小,如果沒有單位,默認為B,
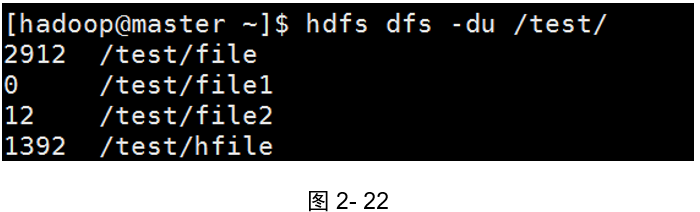
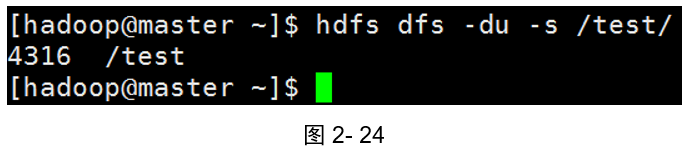
示例1:顯示分布式主目錄下檔案和目錄大小
(如圖2-22所示)
[hadoop@master ~]$ hdfs dfs -du /test/
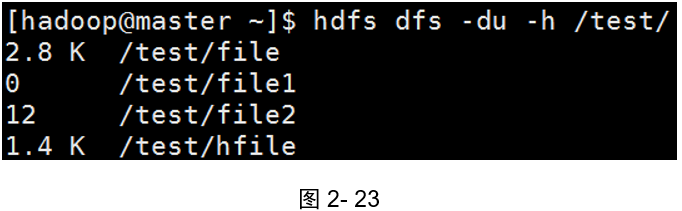
[hadoop@master ~]$ hdfs dfs -du -h /test/(如圖2-23所示)
[hadoop@master ~]$ hdfs dfs -du -s /test/(如圖2-24所示)
9. cp復制檔案
將檔案從SRC復制到DST,如果指定了多個SRC,則DST必須為一個目錄
使用方法:hdfs fs –cp SRC [SRC …] DST
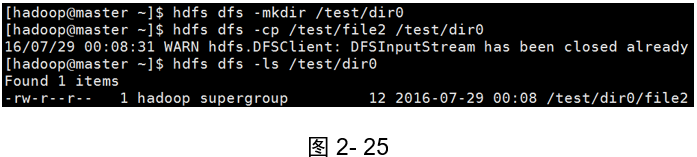
示例1:
(如圖2-25所示)
[hadoop@master ~]$ hdfs dfs -mkdir /test/dir0
[hadoop@master ~]$ hdfs dfs -cp /test/file2 /test/dir0
[hadoop@master ~]$ hdfs dfs -ls /test/dir0
10. chmod修改檔案權限
使用方法:hdfs fs -chmod [-R] <MODE[,MODE]… | OCTALMODE> URI [URI …]
改變檔案的權限,使用-R將使改變在目錄結構下遞回進行,命令的使用者必須是檔案的所有者或者超級用戶,更多的資訊請參見HDFS權限用戶指南,
示例1:
(如圖2-26所示)
[hadoop@master ~]$ hdfs dfs -chmod 777 /test/file2
[hadoop@master ~]$ hdfs dfs -ls /test/file2

示例2:
(如圖2-27所示)
[hadoop@master ~]$ hdfs dfs -chmod -R 777 /test/dir0/
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0

11. chown修改檔案屬主和組
使用方法:hdfs dfs -chmod [-R] <MODE[,MODE]… | OCTALMODE> URI [URI …]
改變檔案的權限,使用-R將使改變在目錄結構下遞回進行,命令的使用者必須是檔案的所有者或者超級用戶,更多的資訊請參見HDFS權限用戶指南,
示例1:
(如圖2-28所示)
[hadoop@master ~]$ hdfs dfs -chown hadoop:hadoop /test/file2
[hadoop@master ~]$ hdfs dfs -ls /test/file2

示例2:
(如圖2-29所示)
[hadoop@master ~]$ hdfs dfs -chown -R hadoop:hadoop /test/dir0
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir0

12. chgrp修改檔案屬組
使用方法:hdfs fs -chgrp [-R] GROUP URI [URI …]
改變檔案所屬的組,使用-R將使改變在目錄結構下遞回進行,命令的使用者必須是檔案的所有者或者超級用戶,更多的資訊請參見HDFS權限用戶指南,
示例1:
(如圖2-30所示)
[hadoop@master ~]$ hdfs dfs -ls /test/file5
[hadoop@master ~]$ hdfs dfs -chgrp hadoop /test/file5
[hadoop@master ~]$ hdfs dfs -ls /test/file5

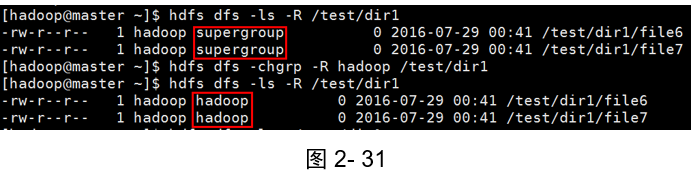
示例2:
(如圖2-31所示)
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir1
[hadoop@master ~]$ hdfs dfs -chgrp -R hadoop /test/dir1
[hadoop@master ~]$ hdfs dfs -ls -R /test/dir1
13. dfsadmin顯示HDFS運行狀態和管理HDFS
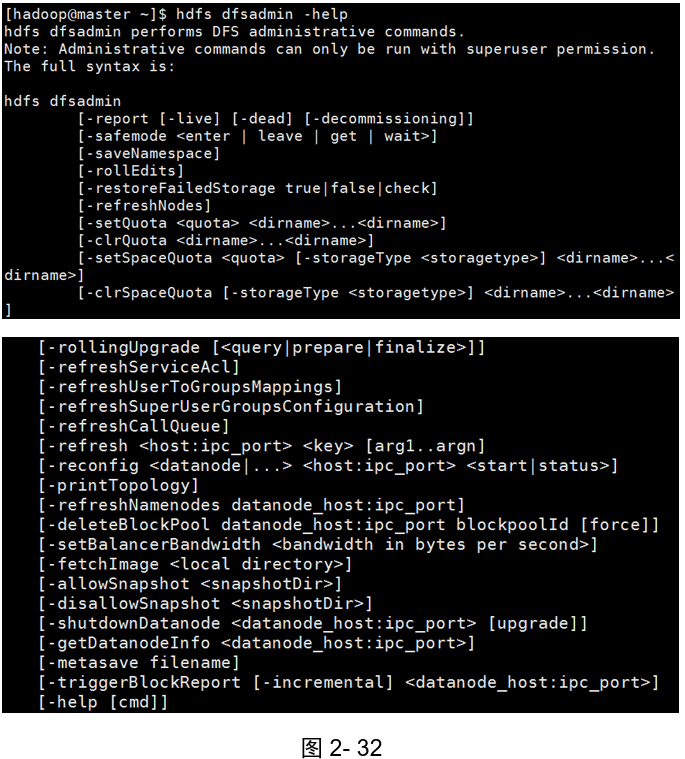
dfsadmin是一個多任務客服端工具,用來顯示HDFS運行狀態和管理HDFS,檔案的命令(如圖2-32所示):
[hadoop@master ~]$ hdfs dfsadmin -help
表三 dfsadmin命令選項和功能
| 命令選項 | 功能描述 |
|---|---|
| -report | 查看檔案系統的基本資訊和統計資訊 |
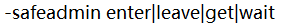 | 安全模式命令, |
| -saveNamespace | 可以強制創建檢查點,僅僅在安全模式下面運行 |
| -refreshNodes | 重新讀取hosts和exclude檔案,使新的節點或需要退出集群的節點能夠被NameNode重新識別,這個命令在新增節點或注銷節點時用到, |
| -finalizeUpgrade | 終結HDFS的升級操作,DataNode洗掉前一個版本的作業目錄,之后NameNode也這樣做, |
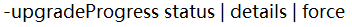 | 請求當前系統的升級狀態 l 升級狀態的細節 l 強制升級操作 |
| -metasave filename | 保存NameNode的主要資料結構到hadoop.log.dir屬性指定的目錄下的 < filename>檔案中, |
| -setQuota < quota>< dirname>……: | 為每個目錄< dirname>設定配額< quota>,目錄配額是一個長整形整數,強制設定目錄樹下的名字個數, |
| -clrQuota < dirname>……< dirname> | 為每個目錄< dirname>清除配額設定 |
| -fetchImage < local directory> | 把最新的檔案系統鏡像檔案從元資料節點上下載到本地指定目錄 |
| -clrQuota , < dirname> , < dirname> | 清除每個目錄dirname的配額,以下情況會報錯:(1)這個目錄不存在或者是一個檔案(2)用戶不是管理員 |
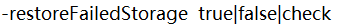 | 此選項將關閉自動嘗試恢復故障的存盤副本,如果故障的存盤可用,再次嘗試還原檢查點期間的日志編輯檔案或檔案系統鏡像檔案,“check”選項將回傳當前設定 |
| -help | 查看幫助 |
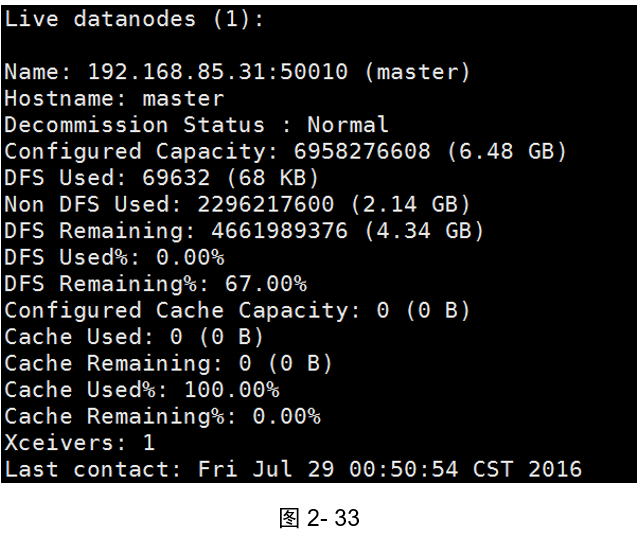
示例1:顯示檔案系統的基本資訊和統計資訊
(如圖2-33所示)
[hadoop@master ~]$ hdfs dfsadmin -report
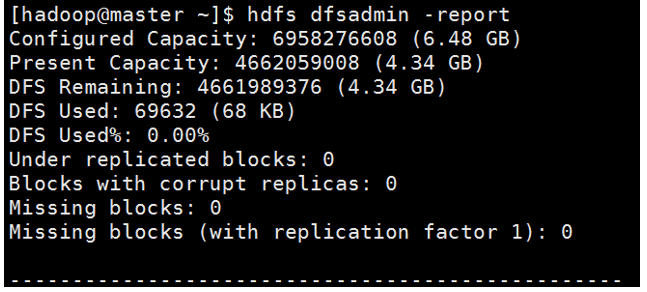
示例2:獲取安全模式
(如圖2-34所示)
[hadoop@master ~]$ hdfs dfsadmin -safemode get

示例3:進入安全模式
(如圖2-35所示)
[hadoop@master ~]$ hdfs dfsadmin -safemode enter

示例3:可以強制創建檢查點
(如圖2-36所示)
[hadoop@master ~]$ hdfs dfsadmin -saveNamespace

示例4:
(如圖2-37所示)
[hadoop@master ~]$ hdfs dfsadmin -refreshNodes

14. Namenode 格式化升級回滾
運行namenode進行格式化、升級回滾等操作
表四namenode選項和功能
| 命令選項 | 功能描述 |
|---|---|
| -format | 格式化元資料節點,先啟動元資料節點,然后格式化,最后關閉 |
| -upgrade | 元資料節點版本更新后,應該以upgrade方式啟動 |
| -rollback | 回滾到前一個版本,必須先停止集群,并且分發舊版本才可用 |
| -importCheckpoint | 從檢查點目錄加載鏡像,目錄由fs.checkpoint.dir指定 |
| -finalize | 持久化最近的升級,并把前一系統狀態洗掉,這個時候再使用rollback |
15. fsck檢查實用程式
fsck命令運行HDFS檔案系統檢查實用程式,用于和MapReduce作業互動,
表五fsck選項和功能
| 命令選項 | 功能描述 |
|---|---|
| -path | 檢查這個目錄中的檔案是否完整 |
| -move | 移動找到的已損壞的檔案到/lost+found |
| -rollback | 回滾到前一個版本,必須先停止集群,并且分發舊版本才可用 |
| -delete | 洗掉已損壞的檔案 |
| -openforwrite | 列印正在打開寫操作的檔案 |
| -files | 列印正在檢查的檔案名 |
| -blocks | 列印block報告(需要和-files引數一起使用) |
| -locations | 列印每個block的位置資訊(需要和-files引數一起使用) |
| -racks | 列印位置資訊的網路拓撲圖(需要和-files引數一起使用) |
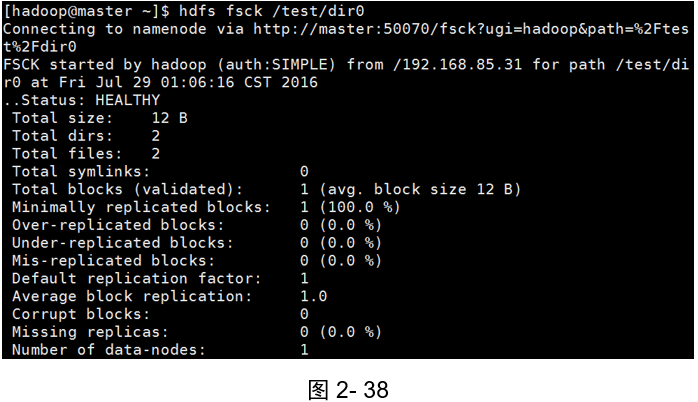
示例1:檢查目錄中檔案完整性
(如圖2-38所示)
[hadoop@master ~]$ hdfs fsck /test/dir0
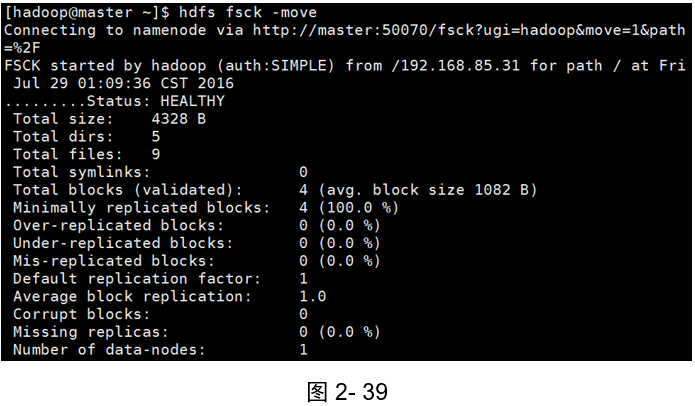
示例2:移動找到已損壞的檔案
(如圖2-39所示)
[hadoop@master ~]$ hdfs fsck -move
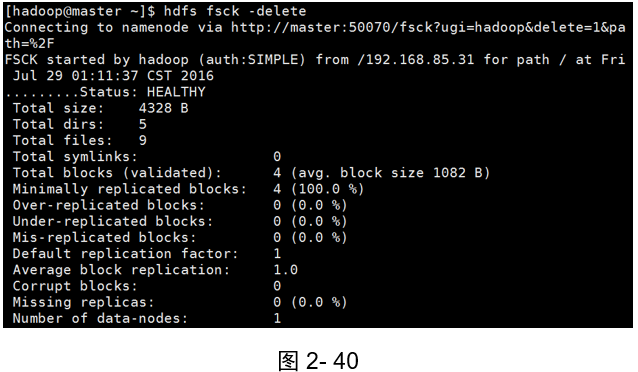
示例3:洗掉已損壞的檔案
(如圖2-40所示)
[hadoop@master ~]$ hdfs fsck -delete
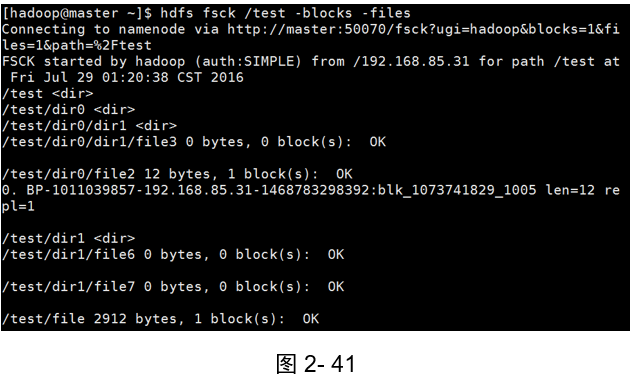
示例4:檢查HDFS系統上/test目錄下的塊資訊和檔案名
(如圖2-41所示)
[hadoop@master ~]$ hdfs fsck /test -blocks -files
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342052.html
標籤:其他
上一篇:Kafka的高性能原理