CIPS 2016 筆記整理
《中文資訊處理發展報告(2016)》是中國中文資訊學會召集專家對本領域學科方 向和前沿技術的一次梳理,官方定位是深度科普,旨在向政府、企業、媒體等對中文 資訊處理感興趣的人士簡要介紹相關領域的基本概念和應用方向,向高校、科研院所和 高技術企業中從事相關作業的專業人士介紹相關領域的前沿技術和發展趨勢,
本專欄主要是針對《中文資訊處理發展報告(2016)》做的筆記知識整理,方便日后查看,
注意:本筆記不涉及任何代碼以及原理分析研究探討,主要是對NLP的研究進展、現狀以及發展趨勢有一個清晰的了解,方便以后更加深入的研究,
ps:我已將思維導圖以及Markdown版本、pdf版本上傳到我的GitHub中,有需要的可以自行查看:
https://github.com/changliang5811/CIPS-2016.git
傳送門:
CIPS 2016(1-3章)——詞法、句法、語意、語篇分析研究進展&發展趨勢
文章目錄
- CIPS 2016 筆記整理
- 前言
- Chapter 4. 語言認知模型
- 任務定義、目標&研究意義
- 認知語言學
- 語言認知計算模型
- 意義
- 研究內容&關鍵科學問題
- 人腦處理語言的認知機理
- 類腦語言資訊處理方法
- 研究進展和現狀
- 腦科學、認知神經科學與語言認知計算
- 大腦語意整合的理論
- 語言認知計算模型
- 深度神經網路與自然語言處理
- 研究現狀
- 總結&展望
- Chapter 5 語言表示與深度學習
- 任務定義、目標&研究意義
- 表示方法
- 關鍵科學問題和研究內容
- 研究內容
- 關鍵科學問題
- 技術方法和研究現狀
- 語言表示方法
- 技術展望&發展趨勢
- 關注問題
- 總結
- 彩蛋
前言
認知語言學(cognitive linguistics)是認知科學(cognitive science)與語言學交 叉的一個研究分支,是研究人腦的思維、心智、智能、推理和認識等認知機理及其對語言進行分析和理解程序的一門學問,隨著計算機硬體和醫學設備性能的提升,技術手段日漸強大,機器學習等大資料處理算 法日臻成熟,更加深入地研究腦、了解腦和揭示腦的條件已經具備,近年來人工智能領域的 一些突破性進展,如 IBM Watson 問答系統在“危險邊緣”挑戰賽中擊敗人類對手、谷歌公司利用深度學習和增強學習演算法實作的 AlphaGo 系統在圍棋專案上打敗人類對手;微軟小冰 機器人以情感語料為基礎,利用大資料知識搜索和深度神經網路機器學習方法等,建立了滿 足人的情感和心理需求的人機對話系統,這些成果讓我們看到了未來智能資訊處理的曙光, 我們完全有理由相信,語言認知計算模型研究的春天已經到來,其研究成果必將在自然語言 處理等相關領域中發揮重要的作用,
語言表示是對人類語言的一種描述或約定,是認知科學、人工智能等多個領域共同存在 的問題,隨著深度學習、無監督學習、以及增強學習等技術的快速發展以及大量文本資料的涌現, 語言表示作為自然語言處理中最基礎的問題將會得到相當程度的解決,從而為下游的各種自 然語言處理任務,諸如機器翻譯、自動文摘、文本分類、自動問答等,提供有效的表示基礎,
Chapter 4. 語言認知模型
(研究進展、現狀&趨勢)
任務定義、目標&研究意義
認知語言學
- 認知科學(cognitive science)與語言學交 叉的一個研究分支,是研究人腦的思維、心智、智能、推理和認識等認知機理及其對語言進 行分析和理解程序的一門學問
語言認知計算模型
- 刻畫人腦語言認知和理解程序的形式化模型
- 目的:建立可計算的、復雜度可控的數學模型,以便在計算機系 統上實作對人腦語言理解程序的模擬
- 實作所謂的“類腦語言資訊處理”
意義
- 從本質上揭示人腦進行語言學習、思維和推理的機理,探索大腦實作語意、概念 和知識計算的奧秘
- 了解人類某些與語言能力相關的疾病形成的原因,對于改善人 類的健康,提高計算機資訊處理的能力,促進社會的發展,都具有非常重要的意義,
研究內容&關鍵科學問題
人腦處理語言的認知機理
-
對人腦的結構和語言進化的程序進行研究
-
通過采集分析在某種語言環境下人腦的生理資料,研究人腦對語音、詞匯、句法 和語意的理解機理
-
關鍵科學問題
- 人腦進行語言理解的認知程序和機理是什么?
- 什么生理因素或外部原因影響著人腦的語言認知能力和進化程序?
類腦語言資訊處理方法
-
通過研究人腦在某些任務上(如歧義消解、選擇性限制、記憶容量等)的語言認知能力和表現,來建立語言資訊處理和計算模型
-
關鍵科學問題
- 是否可以對人腦執行語言理 建模?換句話說,語意和概念是否是可計算的?
研究進展和現狀
腦科學、認知神經科學與語言認知計算
- 基于對正常的和腦損傷群體的 行為和腦的研究證據
- 語意記憶在大腦中是沿著特定的維度進行組織和 表征的
大腦語意整合的理論
-
語言處理程序至少涉及兩種并行的程序
-
語意記憶
- 負責檢索單詞間 的語意特征、關聯和語意關系
-
語意組合
- 至少有一個通路 負責將單詞整合形成更高級的含義
-
語言認知計算模型
-
腦成像技術
(用不同的 方式來測量大腦活動)- 好處:這些從人腦中直接采集 的生理信號是最接近人腦活動的資料
-
焦點:如何將生理信號用于語言認知計算模型的研究
深度神經網路與自然語言處理
- 在神經網路模型中融合記憶模塊和注意力機制成為了研究的趨勢
研究現狀
- 目前人們對大腦處理語言的機理研究只 是揭開了冰山一角,離真正認識大腦的語言處理機理并通過形式化數學方法準確地描述出來, 還有非常遙遠的道路要走
總結&展望
-
從微觀層面進一步研究人腦的結構,發現和揭示人腦理解語言的機理
如何打通宏觀、介觀和微觀 層面的聯系并給出清晰的解釋,恐怕是未來必須解決的問題
-
建立完整的語言認知 計算的理論體系和復雜度可控的形式化數學模型
-
建立有效的、魯棒、可解釋的語言計算模型
任務大多解決的是“處理”層面的問題,如 邊界的切分、語音信號到文字的轉換等,而上升到“語意理解”的層面還有太多的 問題,如正確理解一幅影像所包含的語意和情感等,仍是極具有挑戰性的問題,
Chapter 5 語言表示與深度學習
(研究進展、現狀&趨勢)
任務定義、目標&研究意義
對人類語言的一種描述或約定
-
在認知科學里,語言表示是語言在人腦中的表現形式,關系到人類如何理解和產生 語言
-
在人工智能里,語言表示主要指用于語言的形式化或數學的描述,以便在計算機中表示語言,并能讓計算機程式自動處理,
- 設計一種計算機內部的資料結構來表示語言,以及語言和此資料結構之間的相互轉換機制
挑戰:人類語言需結合一 定的背景關系和知識才能理解
語言表示是自然語言處理以及語意計算的基礎
語言具有一定的層次結構,具體表現為 詞、短語、句子、段落以及篇章等不同的語言粒度,為了讓計算機可以理解語言,需要將不 同粒度的語言都轉換成計算機可以處理的資料結構,
表示方法
- 語言表示模型劃分
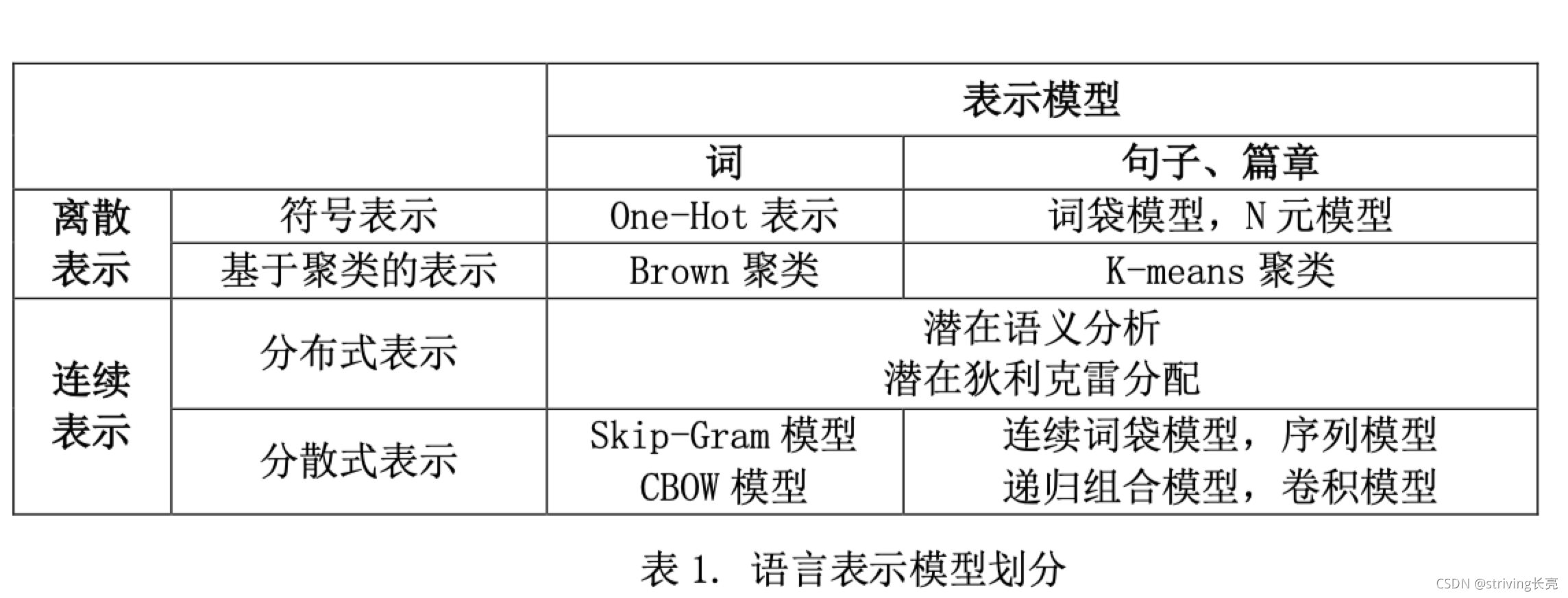
CBOW:根據中心詞的背景關系預測中心詞的概率
Skip-Gram:用中心詞最大化預測輸出層為背景關系詞匯的概率
-
早期:符號化的離散表示
-
詞:One-Hot向量
-
句/篇:詞袋模型、TF-IDF 模型、N 元模型等方法進行轉換
-
缺點
-
詞與詞之間沒有距離的概念
-
需要引入人工知識庫,比如同義詞詞 典、上下位詞典等,才能有效地進行后續的語意計算
-
改進方法
- 基于聚類的詞表示
-
-
無法解決”多詞一義“問題
-
-
-
連續表示
-
為了解決離散表示所無法解決的““一詞多義”和“一義多詞”問題
-
將語言單位表示為連續語意空間中的一個點,這樣的表示方法稱之為連續表示
-
基于連續表示,詞與詞之間 就可以通過歐式距離或余弦距離等方式來計算相似度
-
常用方法
-
分布式表示
- 基于 Harris 的分布式假設,即如果兩個詞的背景關系相似,那么這兩個詞也是相似的,
-
分散式表示(主流方法)
-
將語言的潛在語法或語意特征分散式地存盤在一組神經元中,可以用稠密、低維、連續的向量來表示,也叫嵌入(Embeddings),
-
一個好的詞嵌入模型應該是:對于 相似的詞,它們對應的詞嵌入也相近
-
根據所表示文本的顆粒度的不同,可以分為詞、句子、篇章的表示
-
詞表示
- Word embeddings
- 詞嵌 入的質量非常依賴于背景關系視窗大小的選擇
- 有研究者關注如何利用已有的知識庫來改進詞嵌入模型,結合知識圖譜 和未標注語料在同一語意空間中來聯合學習知識和詞的向量表示,這樣可以更有效地實作詞 的嵌入
-
句子表示
-
很多任務的輸入是變長的文本序列,需要將變長的文本序串列示成固定長度的向量
-
句子編碼主要研究如何有效地從詞嵌入通過不同 方式的組合得到句子表示
-
神經詞袋模型
-
簡單對文本序列中每個詞嵌入進行平均,作為整個序列的表示
-
缺點
- 丟失了詞序資訊
- 對于長文本,神經詞袋模型比較有效,但是對于短文本, 神經詞袋模型很難捕獲語意組合資訊
-
-
遞回神經網路(Recursive Neural Network)
- 按照一個給定的外部拓撲 結構(比如成分句法樹),不斷遞回得到整個序列的表示
- 缺點:需要 給定一個拓撲結構來確定詞和詞之間的依賴關系,因此限制其使用范圍
-
回圈神經網路(Recurrent Neural Network)
- 將文本序列看作時間序列,不 斷更新,最后得到整個序列的表示
-
卷積神經網路(Convolutional Neural Network)
- 通過多個卷積層和子采樣 層,最終得到一個固定長度的向量,
-
改進
- 綜合這些方法的優點,結合具體的任務,已 經 提出了一些更復雜的組合模型, 例如 雙向回圈神經 網路 ( Bi-directional Recurrent Neural Network)、長短時記憶模型(Long-Short Term Memory)等,
- 比如近幾年大熱的Attention機制、Transformer以及Bert模型
-
-
-
篇章表示
-
思想:層次化的方法,先得到句子編碼,然后以句子編碼為輸入,進一步得到篇章的表示
-
層次化CNN
- 用卷積神經網路對每個句子進行建模,然后以 句子為單位再進行一次卷積和池化操作,得到篇章表示
-
層次化RNN
- 用回圈神經網路對每個句子進行建模,然后再用一個回圈神經網路建模以句子為單位的序列,得到篇章表示
-
混合模型
- 先用回圈神經網路對每個句子進行建模,然后以句子為單位再進行 一次卷積和池化操作,得到篇章表示
-
回圈神經網路因為非常適合處理文本 序列,因此被廣泛應用在很多自然語言處理任務上,
-
-
-
-
區別:分散式表示是指一種語意分散存盤的表示形式,而分布式 表示是通過分布式假設獲得的表示
-
聯系:兩者并不對立,比如 Skip-Gram、CBOW 和 glove 等模型得到詞向量,即是分散式表示,又是分布式表示,
-
-
關鍵科學問題和研究內容
研究內容
- 如何針對不同的語言單位,設計表示語言的資料結構以及和語言的轉換機制,即如何將語言轉換成計算機內部的資料結構(理解)以及由計算機內部表示轉換成語言(生成),
關鍵科學問題
-
語言表示的認知機理
- 一個高效的語言表示模型需要借鑒人類的認知機理
- 人們對語言的理解需要大量的背景知識
- 語言表示和知識表示應該是相輔相成的
- 關鍵問題:如何構建語言表示和知識表示的聯系,從人工知識庫或大規模未 標記語料來自動學習語言的表示
-
跨語種的統一語言表示
- 不同語種的語言表示也具有一定的相似性,即可以用同一種表示方式來刻畫 不同語言
- 關鍵問題:如何為不同語種構建一種統一的語言表示模型,利用不同語言之間的共性, 從而提高各個語言的表示能力
-
不同粒度單位的語言表示
- 字、詞、句子、篇章等不同粒度或層次的語 下文進行理解,如“一詞多義”問題
- 關鍵問題:結合語言本身的層次結構以及不同粒度文本之間的制約關 系,構建一個多粒度文本的聯合語意表示模型
-
基于少量觀察樣本的新詞、低頻詞表示學習
- 目前,詞的表示是通過大量的語料庫學習得到的
- 語言中低頻詞往 含有價值的資訊,丟棄這些詞也往往降低了語言表示的能力
- 人們學習新詞和低頻詞的方 式并不是通過大量語料進行學習的,而是通過字典或少量觀察樣本進行學習
- 關鍵問題:對于新 詞或低頻詞,需要研究如何通過少量觀察樣本來學習新詞和低頻詞的表示
技術方法和研究現狀
語言表示方法
-
按不同粒度進行劃分,語言 具有一定的層次結構,語言表示可以分為字、詞、句子、篇章等不同粒度的表示
-
按表示形式進行劃分,可以分為離散表示和連續表示兩類
(具體見任務定義、目標&研究意義——表示方法)- 離散表示是將語言看成離散 的符號
- 連續表示將語言表示為連續空間中的一個點,包括分布式表示和分散式表示
技術展望&發展趨勢
目前,基于深度學習的方法在自然語言處理中取得了很大的進展,因此,分散式表示也 成為語言表示中最熱門的方法
關注問題
- 語言中出現所有符號是否都需要使用統一的表示模型?比如,無意義 數字等
- 新詞以及低頻詞的表示學習方法,目前的表示學習方法很難對這些詞進行很好的建 模,而這些詞都是極具資訊量的,不能簡單忽略
- 篇章的語言表示,目前對篇章級別的文本進行建模方法比較簡單,不足以表示篇章 中的復雜語意
- 語言表示的基礎資料結構,除了目前的基于向量的資料結構 結構,比如矩陣、佇列、堆疊等
隨著深度學習、無監督學習、以及增強學習等技術的快速發展以及大量文本資料的涌現, 語言表示作為自然語言處理中最基礎的問題將會得到相當程度的解決,從而為下游的各種自 然語言處理任務,諸如機器翻譯、自動文摘、文本分類、自動問答等,提供有效的表示基礎,
總結
本篇文章主要對CIPS中4-5章的內容做了一個大概的匯總,
語言認知模型任務大多解決的是“處理”層面的問題,如 邊界的切分、語音信號到文字的轉換等,而上升到“語意理解”的層面還有太多的 問題,如正確理解一幅影像所包含的語意和情感等,仍是極具有挑戰性的問題,并且隨著深度學習、無監督學習、以及增強學習等技術的快速發展以及大量文本資料的涌現, 語言表示作為自然語言處理中最基礎的問題將會得到相當程度的解決,從而為下游的各種自 然語言處理任務,諸如機器翻譯、自動文摘、文本分類、自動問答等,提供有效的表示基礎,
彩蛋
Next blog:知識圖譜(Chapter 6)&文本分類與聚類(Chapter 7)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342078.html
標籤:AI
上一篇:完虐鏈表(一)之反轉鏈表Ⅰ