上幾個章節我們講述了很多硬核的知識,那本章開始我們正式進入Sql實戰程序!!
1、熱身Case
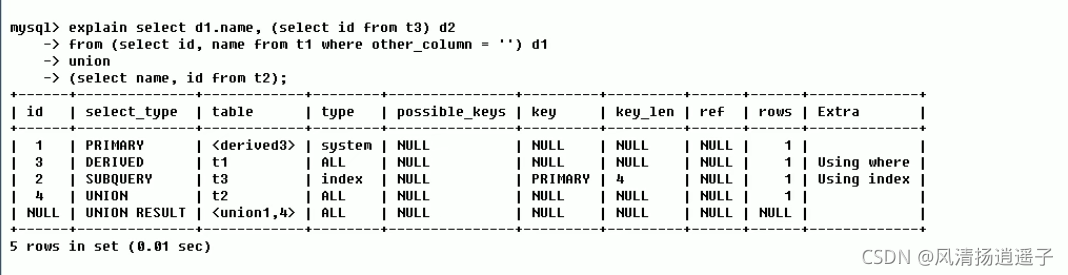
回顧上節講的Explain知識點,我們簡單做個回顧,來個熱身的Case:
看下面的Sql執行是如何的,請列出步驟!
很明顯先看id,id依次遞增,誰最大誰先執行:
所以先執行id=4,執行t2表:select name, id from t2
再執行id=3,t1表的查詢:select id, name from t1 where other column = ''
再執行id=2,t3表的查詢:select id from t3
再執行id=1,這個表是由id=3這個表衍生的表,查詢的結果來自id=3的結果,且table被標記為derived3,select_type為primary表示外層查詢,
最后執行id=NULL,代表從union的臨時表讀取行的階段,table為<union1,4>表示用id=1和id=4的select結果進行union操作!
2、索引單表優化案例剖析
表的結構在我之前的一篇文章里,附上鏈接可以自行去Copy:
Mysql高級調優篇表補充——建表SQLhttps://blog.csdn.net/qq_31821733/article/details/120886389?spm=1001.2014.3001.5501
新建article表:
2.1、查詢category_id為1且comments大于1的情況下,views最多的article_id
Sql:select id, author_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
執行計劃后,會發現多一個列filtered,這個是5.7版本后添加的,意思是:
指回傳結果的行占需要讀到的行(rows列的值)的百分比,比如我回傳了10行,但是我需要讀1000行,這個比例就是10%,filtered的數值其實越高,表示通過索引直接回傳的行很多,數值較低時,一般出現在type=ALL或者index的情況,
分析下這個執行計劃,type=ALL全表掃,而且產生了filesort,功能完成了,但是作為開發一定要考慮到你的sql性能,這個是你的談資!
看下索引:目前只有一個主鍵id默認主鍵索引,
因為我們sql的where條件后有三個欄位,首先想到加的復合索引:
我也不知道對不對,但是先這么嘗試,然后看看執行計劃:
發現走了索引了,但是發現走到了filesort,這樣還不行;
說明這個索引不起作用嗎?那假設我們把sql調整為comments = 1再看看執行計劃
很明顯,filesort沒有了,type一下從range變成了ref,這個情況是最好的,但是合不合理?業務都變了,
分析下:我們建立的索引是ccv,上面的sql是范圍查comments,而下面的是指定常量const,肯定是常量更精確,所以在Mysql中,索引中出現了范圍查找,后面就失效,comments出現了范圍,索引在找的時候,發現comments無法直接定位到,影響了order by views的索引排序,進而出現了filesort,不好意思,你讓我去2樓找進3口的入口,我一個一個找,這個時候我無法走到索引,自然找不到我就不能按照你的索引順序走到3樓了,Mysql做不到時,內部自己產生了個排序,出現了filesort,總結一句話:
范圍索引全失效
結論是:type變成了range,這是可以忍受的,但是Extra里出現了filesort是無法接受的,但是我們建立了索引為什么沒有用,這是因為按照Mysql的BTREE作業原理,先排序category_id,如果遇到相同的,再排序comments,如果遇到相同的,再排序views,當comments位置處于聯合(復合)索引的中間位置時,Mysql無法對范圍(range)后面的欄位進行索引排序,從而后面的欄位索引失效!
剛剛建立的索引對于當前的需求,并不是最合適,那么怎么優化呢?
我們先洗掉剛剛的索引:
既然范圍之后索引失效,那么我們能不能繞過去?直接新建category_id, views的復合索引,執行計劃告訴我們,這個索引加的很合適!
3、索引兩表優化案例剖析
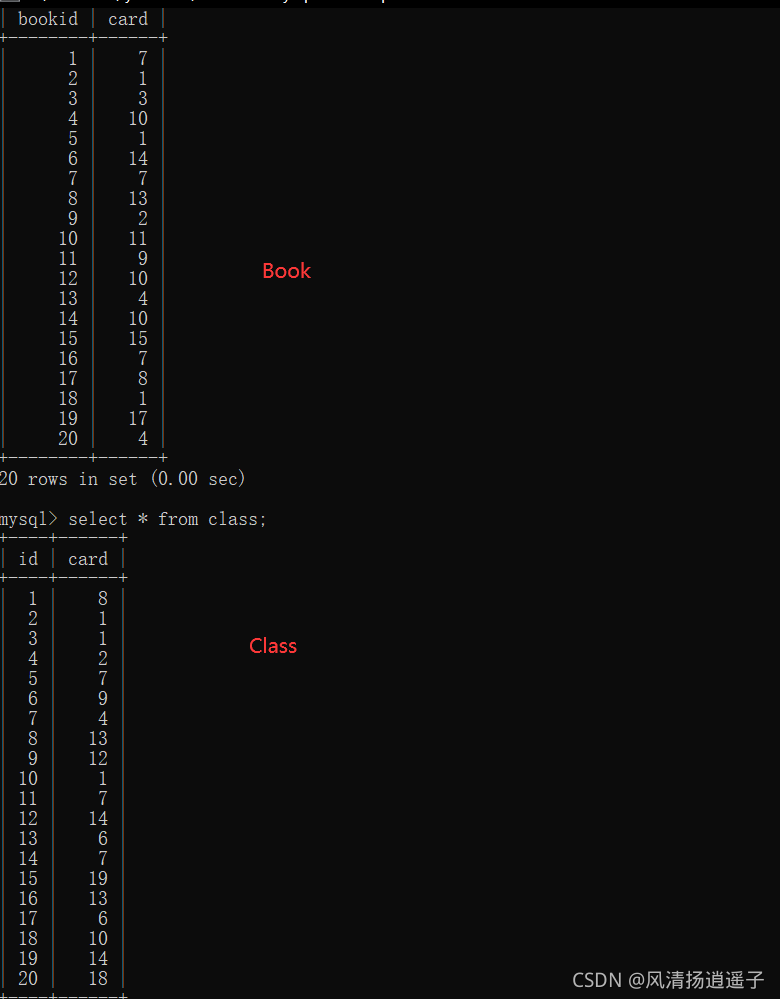
兩表的情況在開發中也很常見,這里我新建book表和class表:
這兩個表無需關心含義,我們看具體Sql:
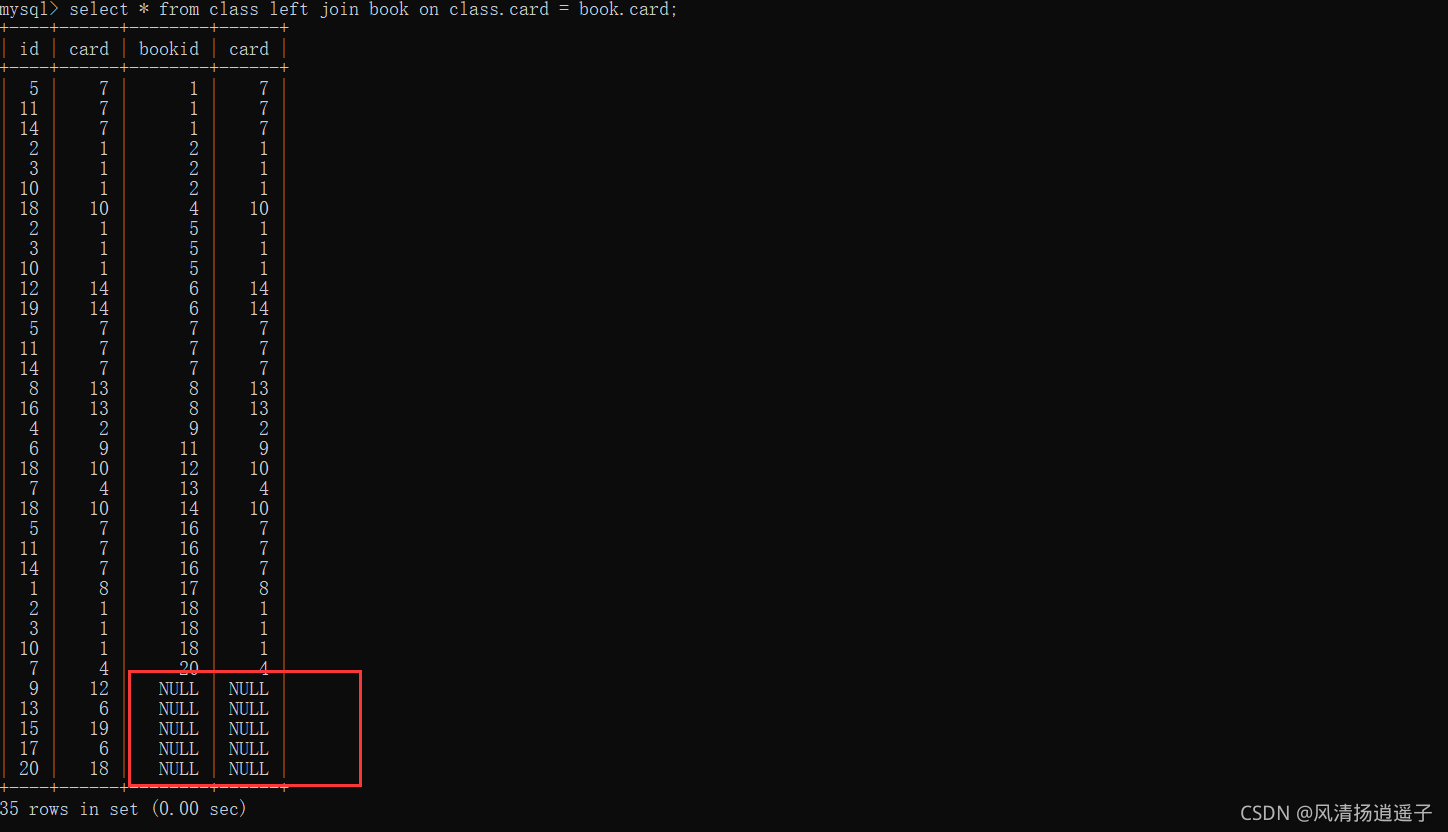
Sql1:select * from class left join book on class.card = book.card;
看到這個sql應該立馬想到我之前畫的圖,很明顯取的是class的全部,加上book不滿足的部分;
執行計劃跑下看:明顯這個type為ALL,索引也沒有加
問題來了,索引加哪邊?是加class.card還是book.card?
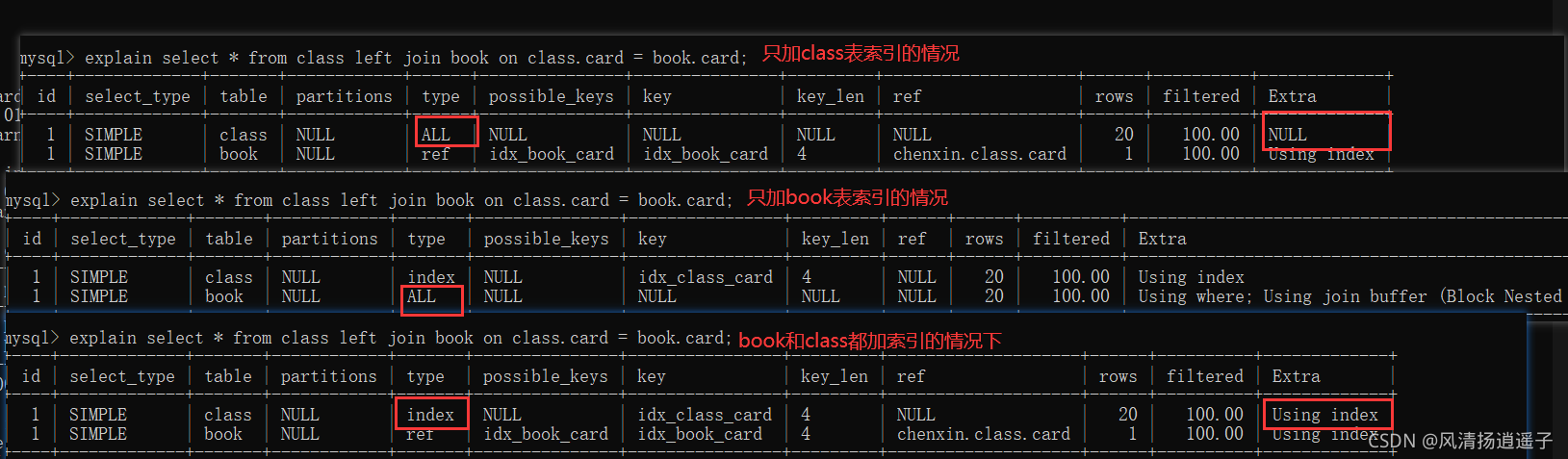
我們都試試,先添加右邊book表的索引:
執行計劃走下:book的很明顯的改變,type變成了ref
此時我把book表的索引刪掉,而建立class左表的索引看看執行計劃:明顯,加了class表的索引后,發現type是index,并且rows20行記錄,全索引掃描,性能不會有剛剛的好!
同樣的sql,同樣的索引列,左連接的時候,加的索引所在的表不同,效果不同;
總結一句話:左連接相反加!
結論:上面出現效果不同,這個是由左連接的特性決定的,left join 條件用于確定如何從右邊搜索行,而左邊一定是都有的; 左邊全有,確定核心的點在于確定如何從右表中搜索資料行,右邊是關鍵點,要加索引!所以左連接索引加在右表上,同理,右連接也是相反加!
有沒有人好奇,如果兩個索引都建呢會是什么樣?我們嘗試下加上看看:
現在book和class表上的card欄位都加了索引,效果比上面兩個都好!
在具體作業中我們還是要具體分析!
4、索引三表優化案例剖析
講完兩個表,我們講下三表怎么優化
在基于上面兩個表book和class的前提下,我們新增加一個表,叫做phone表,欄位也差不多:
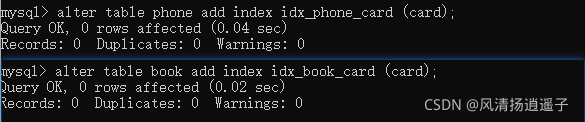
把book表和class表的索引都清除掉;
假設我有這么一個sql:
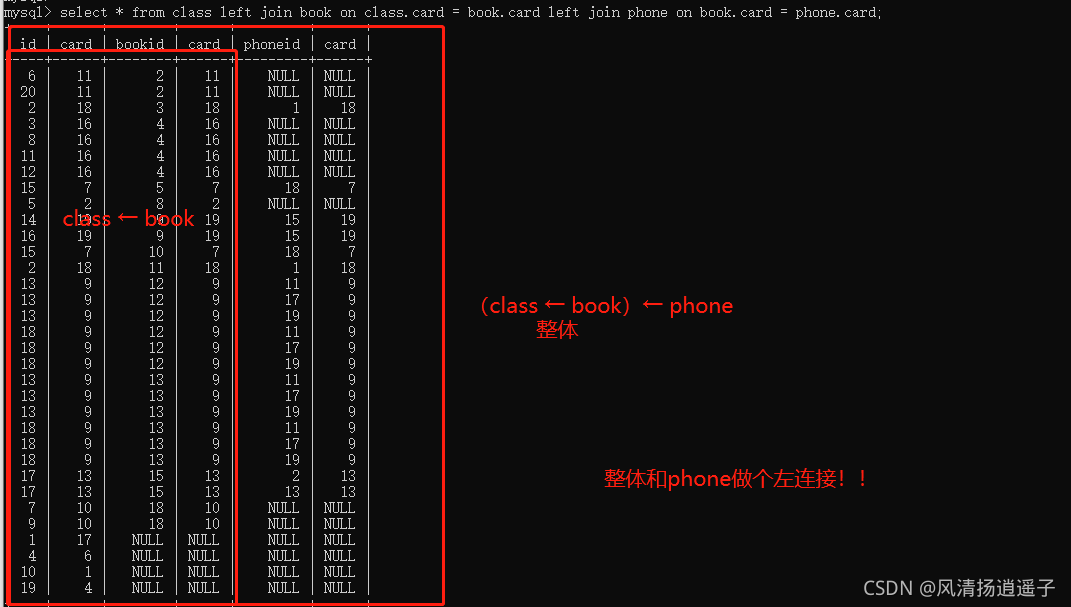
select * from class left join book on class.card = book.card left join phone on book.card = phone.card; 看下結果,兩表的連接基礎打牢固,其實三表的是一樣的,
此時三個表都沒有索引:我們走下執行計劃后發現,Extra欄位多了Using join buffer;首先join buffer意思是使用了連接快取,在5.7之后,Mysql對表和表之間的連接,做了優化快取,實際上在A left join B的程序,Mysql會更在意B的表往A中相同的部分,所以類似一個for回圈,最外層for A,內層是for B,找到B中的每一行滿足A行的記錄,因為是要A的全部,所以最外層一定是A,然后合并行,最后輸出;而在3表中,等于3個for回圈,
其中其實發現有個Block Nested-Loop Join——BNL演算法,這個演算法將外層回圈的行/結果集存入join buffer, 內層回圈的每一行與整個buffer中的記錄做比較,從而減少內層回圈的次數,所以最外層的表是class,先for整個class,然后放在join buffer里,接下來回圈內表的時候,直接取buffer的行去比對,減少對磁盤的IO,
但是整個type=ALL,rows都是20,全表掃,這是我們無法接受的,
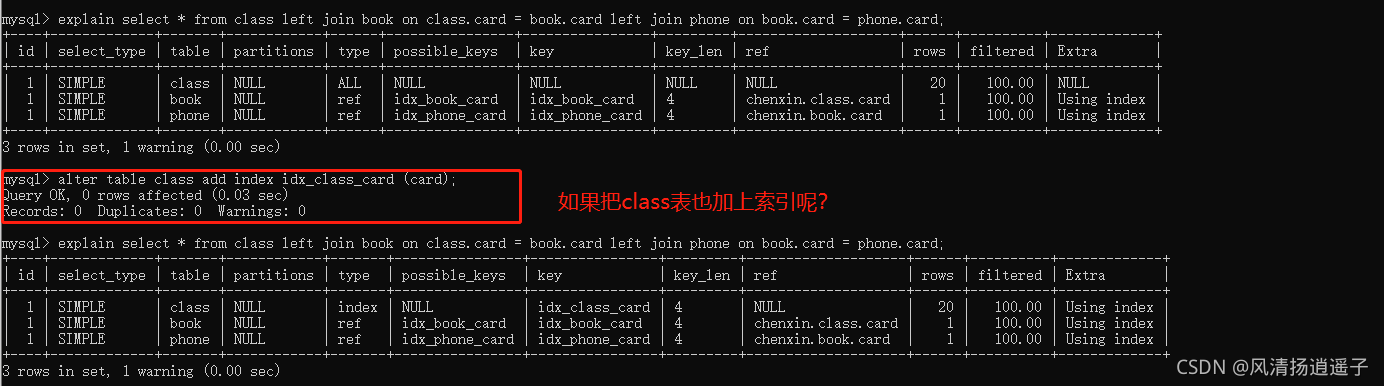
那么三張表怎么加索引呢?可以想想,左連接建右表上,那么這個是不是說class左表,建立索引在book和phone上?試試!
走下執行計劃看看:很明顯,改善很多!
那么很明顯這個原則也成立,總結下:
盡可能減少join陳述句中的NestedLoop回圈總次數,永遠用小結果集驅動大的結果集,這里的例子,就是左表盡量資料小于右表,外層for的次數就減少了,IO次數也會降低,
優先優化NestedLoop的內層回圈;
保證join陳述句中被驅動表上的欄位已經被索引;
當無法保證被驅動表的join欄位被索引且記憶體資源充足的前提下,不要吝嗇JoinBuffer的設定值,JoinBuffer在my.cnf中,由DBA運維著,
其實你可以試試,如果class表加了索引,效果會比右連接稍微好點,哈哈
但是這個不一定可行,具體資料場景具體分析!















本章講了優化索引實體,下一章節繼續索引其他場景實戰!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342135.html
標籤:其他
下一篇:優秀學弟的秋招經歷(嵌入式軟體)