前言
本篇文章介紹KafKa的核心概念,其中包含了topic、生產者、消費者、leader選舉的機制、訊息如何進行分片選擇,以及流式持久化存盤原理,以及驚群效應產生及解決辦法等
核心API
在java客戶端要使用Kafka,我們最簡單,也是最常用的,使用springboot提供的start,自動給我們管理,還有直接使用jar包的方式,當然最后還有一種是使用maven依賴去下載,其實總的來說都是為我們下載 kafka-clients
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.0</version>
</dependency>而客戶端中使用方式采用的 創建 洗掉 修改 topic 都是采用 AdminClient
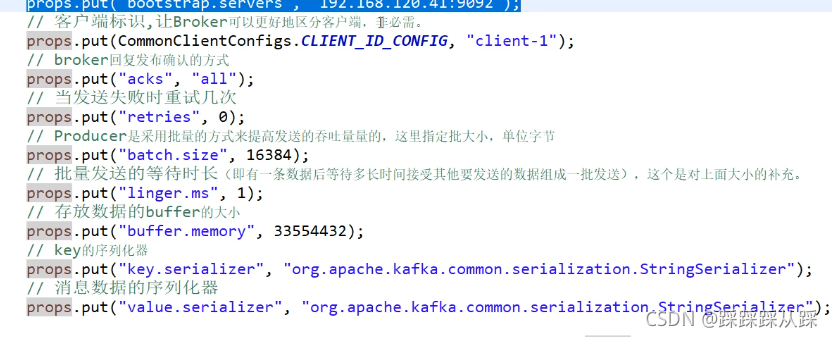
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.120.41:9092");
try (AdminClient admin = AdminClient.create(props);) {
admin.createTopics(Collections.singletonList(new NewTopic("test", 1, (short) 1)));
}核心的創建完topic就能進行生產和消費
然后配置這些 可配可不配,都有默認值的,
如果是生產者 則使用 KafkaProducer 進行發送 ,需要立即回傳的,ProducerRecord
producer采用異步批量的方式來發送訊息,send方法會立即回傳,
try (Producer<String, String> producer = new KafkaProducer<>(props);) {Future<RecordMetadata> resultFuture = producer.send(new ProducerRecord<String, String>("test", Integer.toString(i), message));
// 如果你想要同步阻塞等待結果
RecordMetadata rm = resultFuture.get();
如果是生產者 則是KafkaConsumer 采用拉的模式進行拉資料,默認就是異步的,
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);) { // kafka中是拉模式,poll的時間引數是告訴Kafka:如果當前沒有資料,等待多久再回應
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1L));對于消費者或者提供者的引數配置 可以按照下面官網中配置引數進行查找
阿帕奇·卡夫卡 (apache.org)
包括訊息資料的序列化器 value.serializer 等等需要自定義則設定,
// 訊息資料的序列化器
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");以及提供者 中存放資料的大小一定是比批量發送大小大很多的,原理也是來自我們可以多執行緒發送的資料,與總的未發送資料記憶體之間的區別
// 存放資料的buffer的大小
props.put("buffer.memory", 33554432);
// Producer是采用批量的方式來提高發送的吞吐量量的,這里指定批大小,單位位元組
props.put("batch.size", 16384);訂閱topic 并且拉資料 ,kafka中是拉模式,poll的時間引數是告訴Kafka:如果當前沒有資料,等待多久再回應 設定
consumer.poll(Duration.ofSeconds(1L));- KafkaProducer
- ProducerRecord
- ProducerConfifig
- Serializer
對于上面的一些常見的配置,都是默認的,可以不用配置
- KafkaConsumer
- ConsumerConfifig
- ConsumerRecord
- Deserializer
序列化和反序列化
序列化器

反序列化器

核心概念
topic
在kafka中有 topic的概念,類似與 rabbitmq中通道的概念,但還是不一樣的,也包含了型別的區分
[root@node4 latest]# bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic my-33-topic
[root@node4 latest]# bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-33-topic Topic:my-33-topic PartitionCount:3 ReplicationFactor:3 Configs:segment.bytes=1073741824
Topic: my-33-topic Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: my-33-topic Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: my-33-topic Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2- Topic :主題 ,一類訊息(資料)
- partition:一個Topic可以分成多個分片來分布式存放資料,分片以順序號來編號,
- Replicas:為保證資料存盤的可靠性,一個分片可以存盤多個副本(一般3個),副本被自動均衡 分布在集群節點上
- Leader:一個分片的多個副本中自動選舉一個作為Leader,通過Leader操作資料,Leader同步 給其他副本,以此來保證一致性,當Leader掛了時,自動選擇一個做Leader,
- Topic的這些元資訊存盤在Zookeeper上,
- Replicas: 0,2,1 副本在哪些broker上
- Isr: 0,2,1 副本 存活且同步的broker
都是內部進行操作的,
Leader選舉
每個分片的leader如何產生,在kafka中,基于zk ,進行臨時節點 +watch ;因為驚群效應以及依賴性太大,節點一旦多了驚群效應影響性能,Kafka沒有直接使用zk來進行分片的Leader選舉,
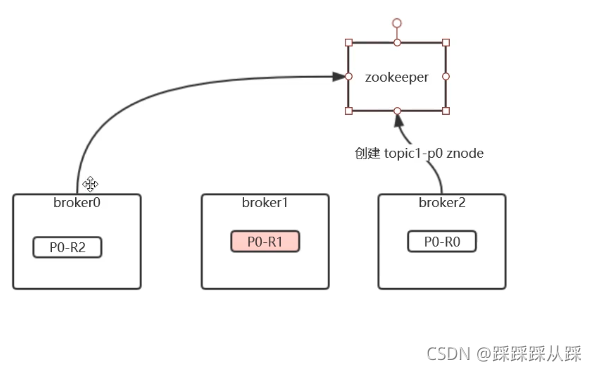
選擇是采用Kafka中增加一個角色: Controller , 由集群的一個broker來擔任這個角色;這個controller會連接到任何節點上去
這里就是真正用的zk 來進行 Controller的選舉, 然后所有的 主題的分片的副本的分布、leader的選定都由Controller來完成,
控制源資料的變更
訊息的分片選擇
訊息過來,一定需要去選擇集群 到底該選擇那個分片,這是Kafka中訊息分片的選擇,這我最開始的想法是利用redis中hash槽, 相似的原理,利用重定向也好都可以使用的,
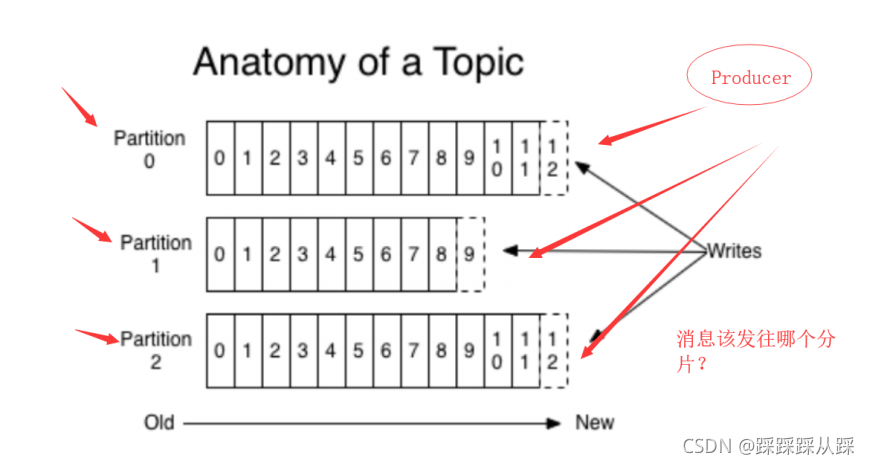
在kafka中選擇的是Producer客戶端負責訊息的分發
- kafka集群中的任何一個broker都可以向producer提供metadata資訊,這些metadata中包含”集群 中存活的servers串列”/”partitions leader串列”等資訊;
- 當producer獲取到metadata資訊之后, producer將會和Topic下所有partition leader保持socket 連接;
- 訊息由producer直接通過socket發送到broker,中間不會經過任何”路由層”,事實上,訊息被路 由到哪個partition上由producer客戶端決定;比如可以采用”random”“key-hash”“輪詢”等,如果一個topic中有多個partitions,那么在producer端實作”訊息均衡分發”是必要的,
選擇實作達到均衡分布,
- 用戶給定了分片號且正確有效,則發到給定分片;
- 未指定分片,指定了Key,則對Key取Hash 求余決定目標分片
- 未指定分片,也未提供key,則采用輪詢
ProducerRecord<K, V>
可以選擇,帶整數進行分片的,
只要能均勻將訊息均勻的分布到分片上去,每個topic 可以有多個分片,
客戶端直接發訊息都發給leader ,在進行同步
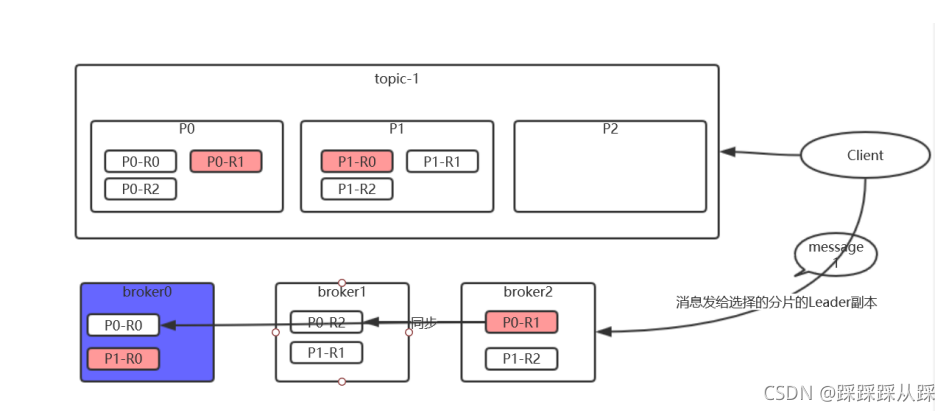
分片資料持久化存盤原理
首先Kafka 是采用檔案來存盤資料 ,資料量大 ;這是它存盤的方式;
磁盤檔案組織方式
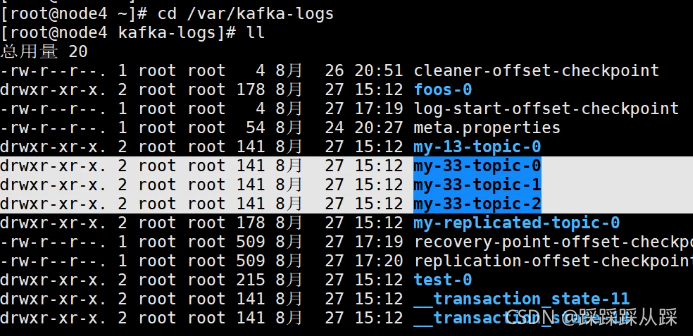
[root@node4 kafka-logs]# ll my-33-topic-0 總用量 4
-rw-r--r--. 1 root root 10485760 8月 25 15:41 00000000000000000000.index
-rw-r--r--. 1 root root 0 8月 25 15:41 00000000000000000000.log
-rw-r--r--. 1 root root 10485756 8月 25 15:41 00000000000000000000.timeindex
-rw-r--r--. 1 root root 8 8月 25 15:41 leader-epoch-checkpoint- 日志檔案名 這串 00000000000000000000 表示什么
- 在這個日志檔案中怎么存盤資料,怎么知道一條訊息的結尾,
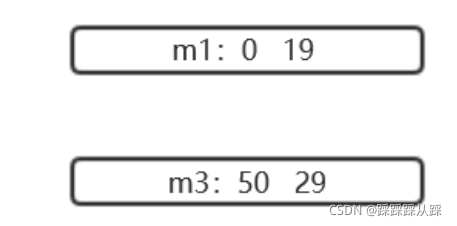
日志檔案資料存盤格式

從那個檔案開始讀,這里記錄第幾條資料,并且長度也記錄著,偏移量相對于整個分片的,

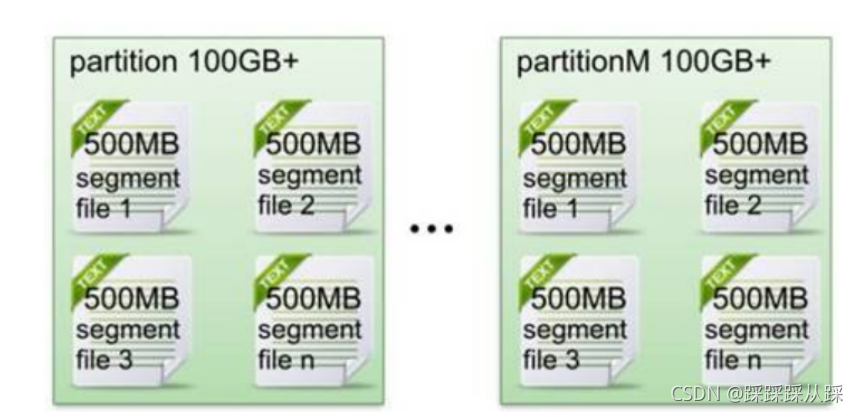
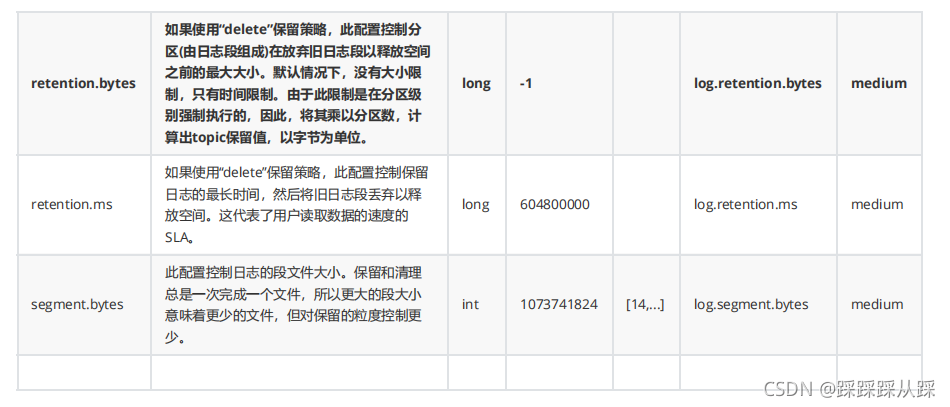
- 通過在server.properties檔案中配置全域默認的日志保留策略來控制:
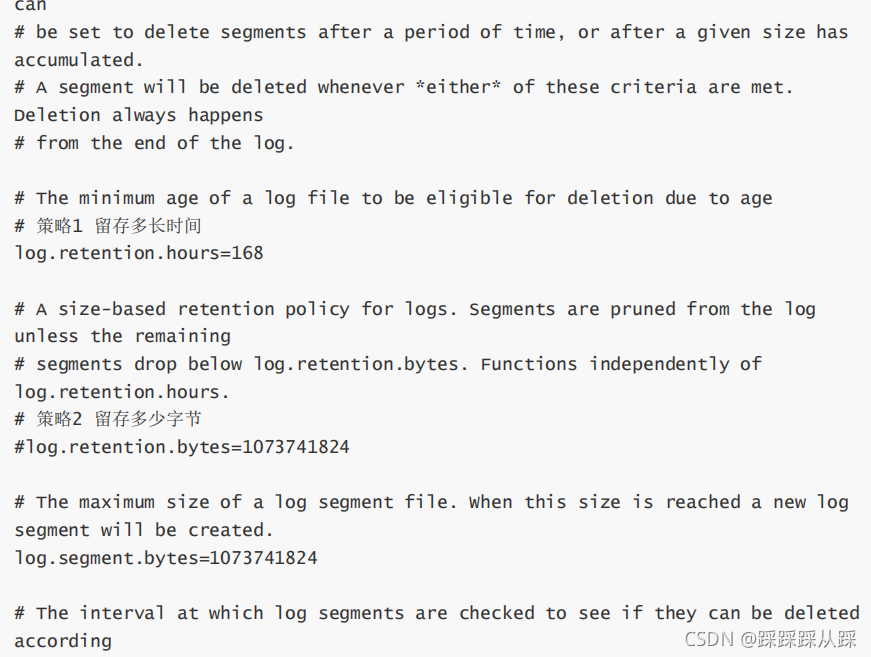
全域默認的方式
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342137.html
標籤:其他
上一篇:優秀學弟的秋招經歷(嵌入式軟體)
下一篇:聊一聊hive檔案存盤格式