版本:Flink 1.13.2 - 2021-08-02
Flink 運行時集群的基本結構及調度程序圖解
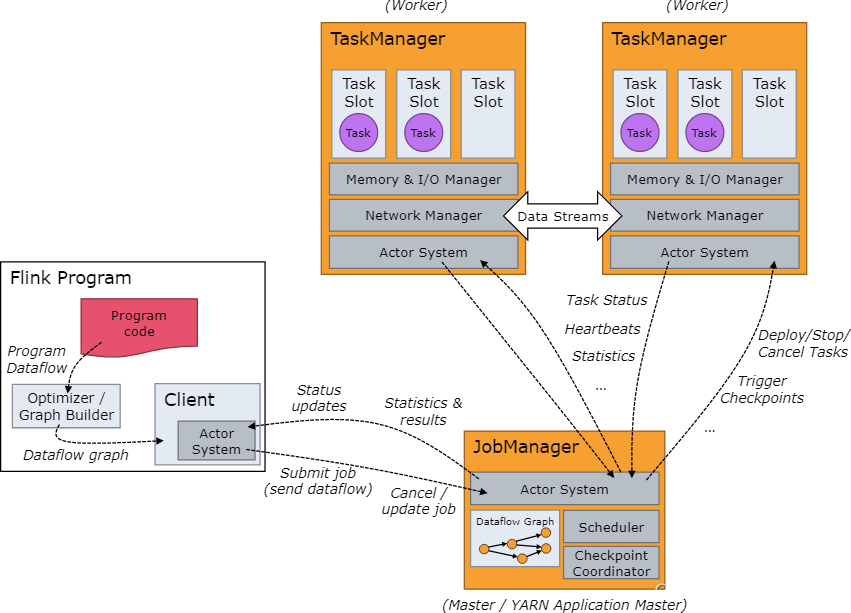
Flink 運行時集群的基本結構
針對不同集群環境(YARN,Mesos,Kubernetes,standalone等),結構會有略微不同,但是基本結構中包含了運行時的調度原理,
Flink Runtime 集群的基本結構,采用了標準 master-slave 的結構,中間 AM 中的部分表示 master,它負責管理整個集群中的資源和作業;而右側的兩個 TaskManager 則是 slave,負責提供具體的資源并實際執行作業任務,
途中 白色實線雙線箭頭表示資料互動,虛線表述調度程序,
AppMaster
-
Dispatcher
- 負責接收用戶提供的作業,并且負責為這個新提交的作業拉起一個新的 JobManager 組件 ResourceManager
- 負責資源的管理,在整個 Flink 集群中只有一個 ResourceManager JobManager
- 負責管理作業的執行,在一個 Flink 集群中可能有多個作業同時執行,每個作業都有自己的JobManager 組件
TaskManager
真正干活的組件,雖然他叫任務管理器,但是它并不管理任務,它是任務執行者,給他起名管理器大概是應為它并不是執行任務的最小單元,它里面還管理著插槽(Slot),Slot 是 Flink 集群中最小的資源單元,
調度大致流程
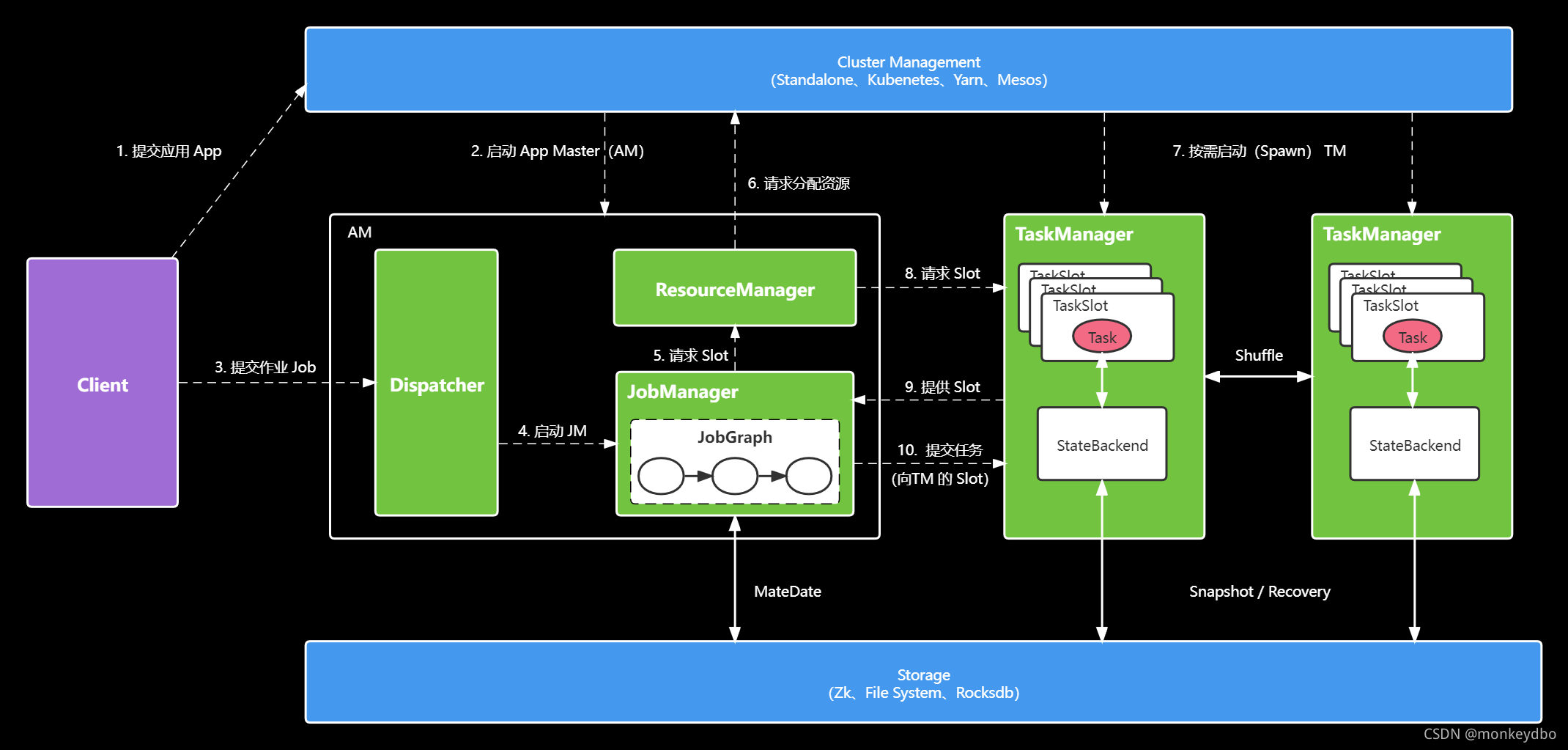
基于上述結構,當用戶提交作業的時候,提交腳本會首先啟動一個 Client 行程負責作業的編譯與提交,它首先將用戶撰寫的代碼編譯為一個 JobGraph,在這個程序,它還會進行一些檢查或優化等作業,例如判斷哪些 Operator 可以 Chain 到同一個 Task 中,然后,Client 將產生的 JobGraph 提交到集群中執行,
此時有兩種情況,一種是類似于 Standalone 這種 Session 模式,AM 會預先啟動,此時 Client直接與 Dispatcher 建立連接并提交作業即可,另一種是 Per-Job 模式,AM 不會預先啟動,此時 Client 將首先向資源管理系統 (如 Yarn、K8S)申請資源來啟動AM,然后再向 AM 中的Dispatcher 提交作業,
資源管理與作業調度
在 Flink 中,資源是通過 Slot 來表示的,每個 Slot 可以用來執行不同的 Task,調度的主要目的就是為了給 Task 找到匹配的 Slot,
邏輯上來說,每個 Slot 都應對外描述能提供多少資源,而每個 Task 也應說明它需要申請到多少資源,但是實際上在 1.9之前,Flink 是不支持細粒度的資源描述的,而是統一的認為每個 Slot 提供的資源和Task 需要的資源都是相同的,從 1.9 開始,Flink 開始增加對細粒度的資源匹配的支持的實作,但這部分功能目前仍在完善中,
Flink 中資源管理的實作
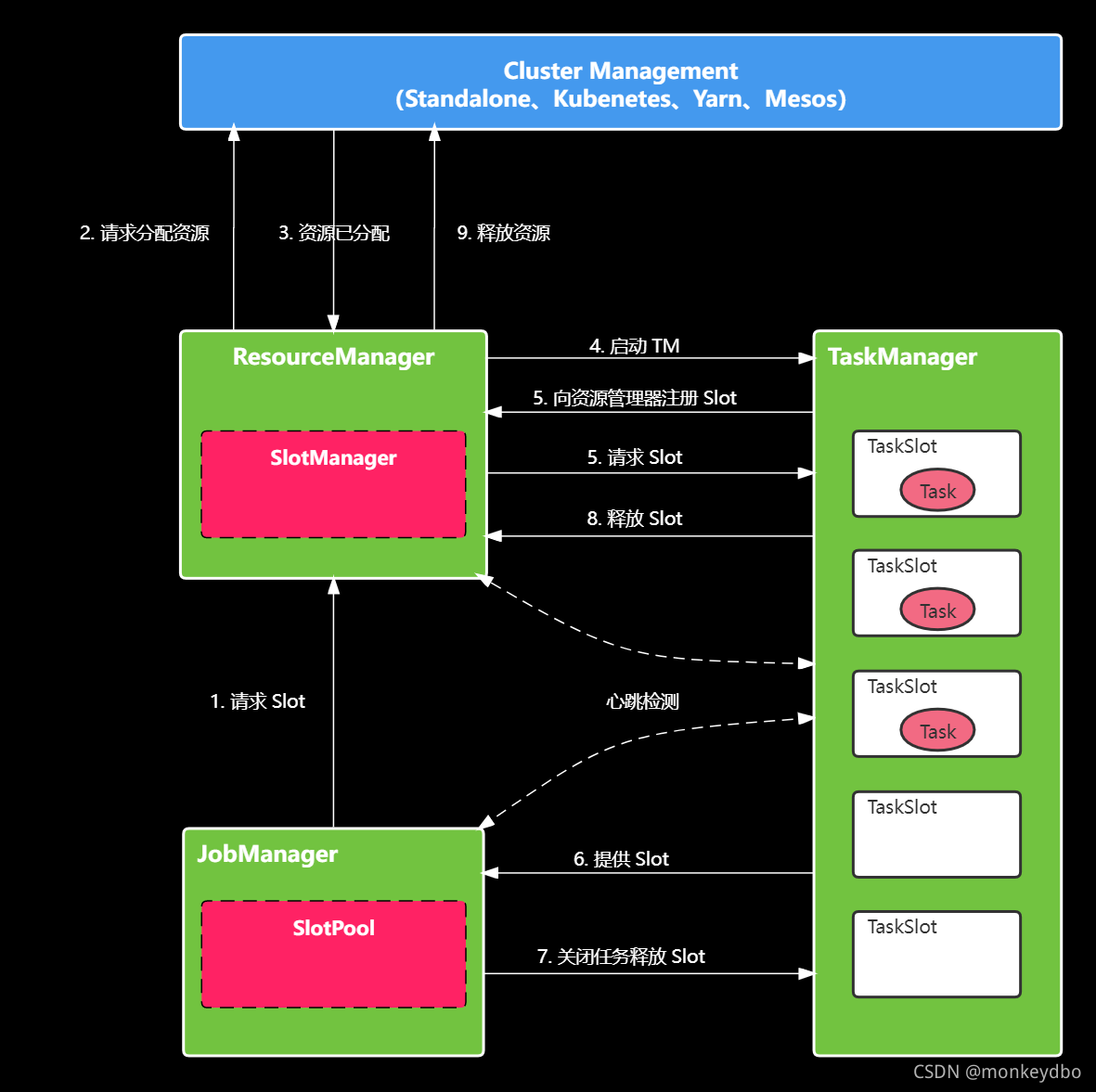
圖中:
ResourceManager 中,有一個子組件叫做 SlotManager,它維護了當前集群中所有 TaskExecutor 上的 Slot 的資訊與狀態,如該 Slot 在哪個TaskManager 中,該 Slot 當前是否空閑等,
JobManger 中,有一個 SlotPool 組件,它快取了所有的 Slot 資源請求,
-
JobManger 為特定 Task 申請 Slot 資源,并且會將發起的請求快取到 SlotPool 中
此時會根據當前是 Per-job 還是 Session 模式,ResourceManager 可能會去申請資源來啟動新的 TaskExecutor,(即后面的 2,3,4 步驟)
-
向資源提供者(如K8s等)申請資源
-
資源提供者已分配資源
-
根據資源提供者分配的資源,啟動 TM
-
如果有 2,3,4 步驟(即啟動新的 TM)則在啟動 TM 后會向 RM 注冊 Slot 資訊,RM 根據現有的 Slot 資訊向 TM 發起 Slot 請求
-
TM 向 JM 提供 Slot 資源,并且在 JM 獲取到資源后會取消 SlotPool 中相應的 Slot 請求
-
在 Task 結束后,無論是正常結束還是例外結束,都會通知 JobManager 相應的結束狀態,然后在 TaskManager 端將 Slot 標記為已占用但未執行任務的狀態,即:先將相應的 Slot 快取到 SlotPool 中,但不會立即釋放,通過延時釋放,Failover 的 Task 可以盡快調度回原來的 TaskManager,從而加快 Failover 的速度,
-
過一段時間后,如果延時釋放的 Slot 沒有在被使用,那么 TM 就會釋放相應的 Slot 資源并向 RM 報告,跟新 Slot 的狀態
-
如果是通過資源提供者創建的新的 TM 那么還需要報告資源提供者,釋放相應的 TM 資源,
另外:除了正常的通信邏輯外,在 ResourceManager 和 TaskManager 之間還存在定時的心跳訊息來同步 Slot 的狀態,
當 JobManger 來為特定 Task 申請資源的時候,根據當前是 Per-job 還是 Session 模式,ResourceManager 可能
會去申請資源來啟動新的 TaskExecutor,
Task調度
在 Slot 管理基礎上,Flink 可以將 Task 調度到相應的 Slot 當中,
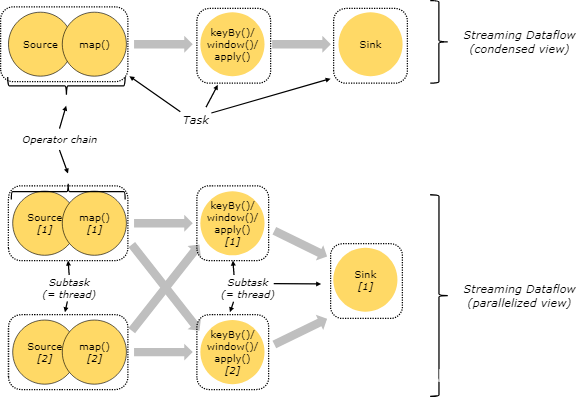
虛線框表示 Task ,里面的圓形表示子任務,圓形里面的文字表示一些操作
從圖中可以看出,有的任務會被合并到一個大任務中,即 Source 和 map 兩個可以是獨立的任務,
圖中上面的是一個單一并行度的數量處理流程,每個 Task 都只需要一個 Slot 資源;下面的是一個帶有并行度的資料處理流圖,其中 【Source 、map】 和 【keyBy/window/apply】 兩個任務的并行度都是 2 ,最后輸出 sink 任務的并行度是 1,
從這里可以看出,slot 其實就是一個執行緒,把一些任務合并成一個大的任務放到統一個 Slot 中是很有優勢的:可以降低執行緒切換帶來的消耗,提高整體的吞吐量,至于什么樣的 Task 會被合并到一個 Slot 中可以參考:chaining docs,
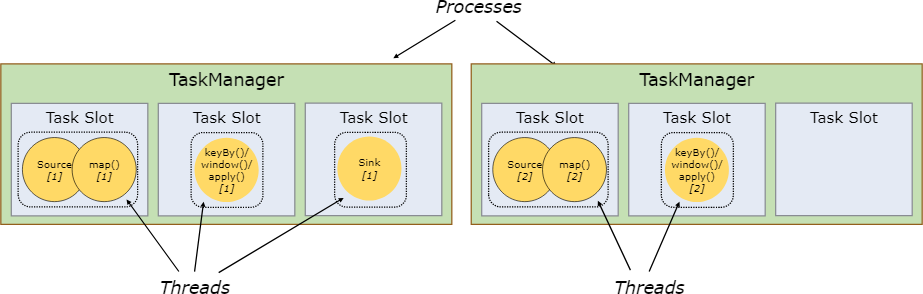
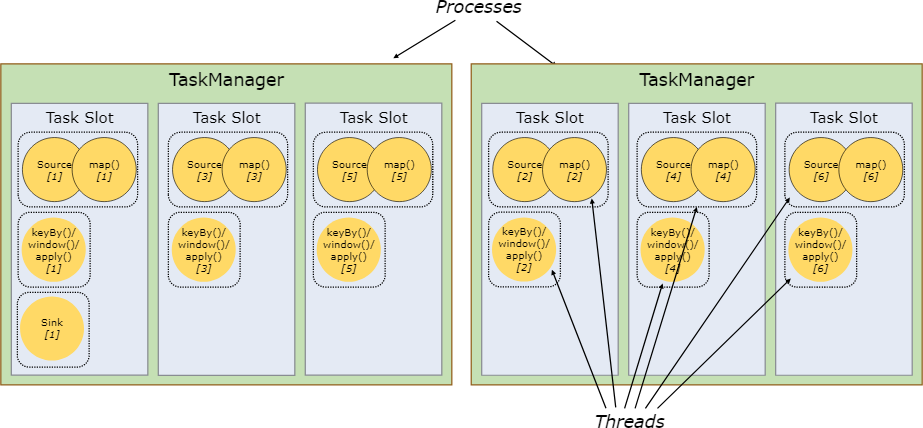
每個 TaskManager 都是一個 JVM 行程,它通過 Slot 數量來控制 TaskManager 能夠接受多少任務,一個 Slot 并不是只能執行一個任務,只要重疊的任務,都可以在一個 Slot 中,在啟動時,定義了 TM 的記憶體大小,這些記憶體會分到每一個 Slot 上,稱之為委托記憶體,Slot 只在委托記憶體上進行相互的隔離,在 CPU 層面并不做隔離,所以,一般的建議都是:TM 的 Slot 數量和機器的 CPU 數量一致,這樣可以降低計算資源的競爭,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342140.html
標籤:其他