Kafaka基本入門
文章目錄
- Kafaka基本入門
- 一 基本認識
- 1.1 訊息中間件(訊息佇列)
- 1.2 常用訊息中間件
- 1.3 通信協議
- 1.4 基本術語
- 二 kafaka的基本介紹
- 2.1 概述
- 2.2 訊息系統介紹
- 2.3 點對點訊息傳遞模式
- 2.4 發布-訂閱訊息傳遞模式
- 三 Kafka中的術語解釋
- 3.1 概述
- 3.2 broker
- 3.3 Topic
- 3.4 Partition
- 3.5 Producer
- 3.6 Consumer
- 3.7 Consumer Group
- 3.8 Leader
- 3.9 Follower
- 四 Kafaka的安裝
- 4.1 Zookeeper的安裝
- 4.2 Kafka的安裝
- 4.3 基本命令
- 4.3.1 創建topic
- 4.3.2 查看創建的topic
- 4.3.3 洗掉某個topic
- 4.3.4 查看某個topic的資訊
- 4.3.5 發送訊息
- 4.3.6 接受訊息
- 4.3.7 訊息的有序性
- 4.4 消費者組
- 4.4.1 單播消費
- 4.4.2 多播消費
- 4.4.3 查看消費組的資訊
- 五 Kafka中主題和磁區的概念
- 5.1 主題
- 5.2 磁區
- 5.3 日志資訊
- 六 Kafka集群的搭建
- 6.1 Zookeeper集群的搭建
- 6.2 Kafka集群的搭建
- 6.3 副本的概念
- 6.4 集群消費
- 6.5 集群中的controller
- 6.6 rebalance機制
- 6.8 HW和LEO
- 七 代碼中的實作
- 7.1 訊息提供者
- 7.1 .1 Java訊息提供者代碼中的實作
- 7.1.2 ?產者中的ack的配置
- 7.1.3 訊息緩沖區
- 7.2 訊息消費者
- 7.2.1 java客服端基本實作
- 7.2.1 自動提交與手動提交
- 7.2.3 ?輪詢poll訊息
- 7.2.4 心跳檢查
- 7.2.5 指定磁區和偏移量、時間消費
- 7.6 SpringBoot中代碼的實作
一 基本認識
1.1 訊息中間件(訊息佇列)
-
訊息(Message):是在兩臺計算機間傳送的資料單位,訊息可以非常簡單,例如只包含文本字串;也可以更復雜,可能包含嵌入物件,
-
佇列(Queue):訊息佇列,用來保存訊息直到發送給消費者,是一種資料結構,先進進出,
-
訊息佇列的主要特點是異步處理,主要目的是減少請求回應時間和解耦,所以主要的使用場景就是將比較耗時而且不需要即時(同步)回傳結果的操作作為訊息放入訊息佇列,同時由于使用了訊息佇列,只要保證訊息格式不變,訊息的發送方和接收方并不需要彼此聯系,也不需要受對方的影響,即解耦和,這也是訊息中間件的意義所在,
1.2 常用訊息中間件
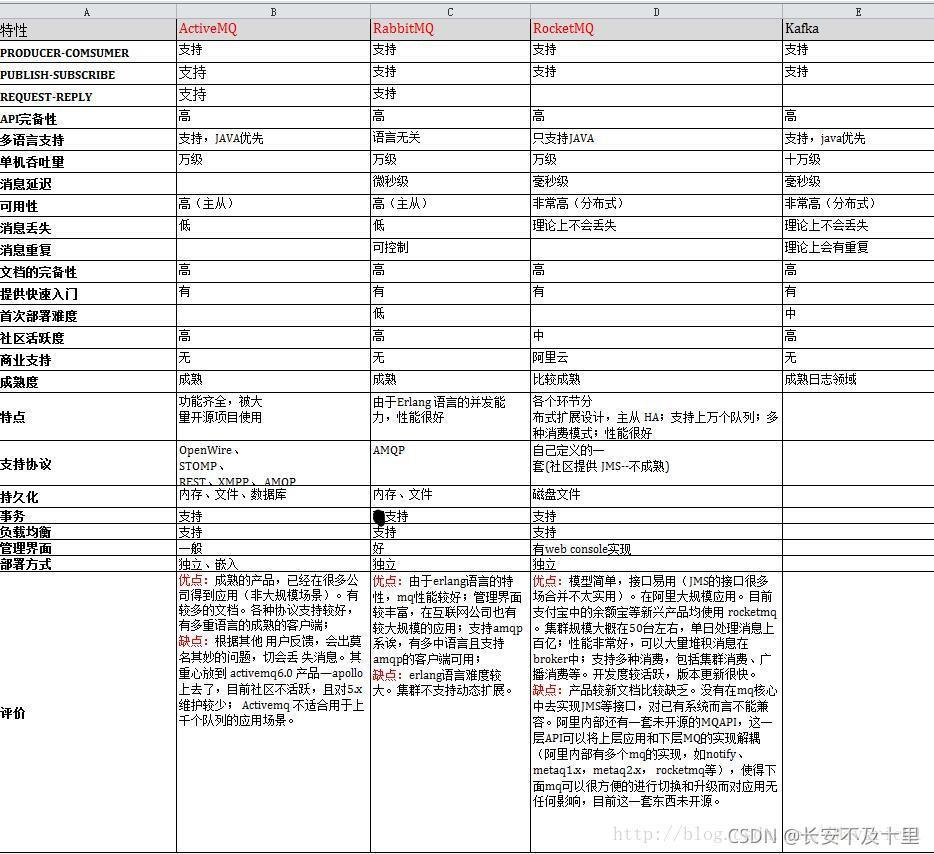
ActiveMQ:是 Apache開源產品,完全支持 J M S 規范的訊息中間件,是一個純Java程式,因此只需要作業系統支持Java虛擬機,ActiveMQ便可執行,ActiveMQ可以很容易內嵌到使用Spring的系統里面去通過了常見J2EE服務器的測驗,JMS即Java訊息服務(Java Message Service)應用程式介面,是一個Java平臺中關于面向訊息中間件(MOM)的API,用于在兩個應用程式之間,或分布式系統中發送訊息,進行異步通信,其豐富的API、多種集群構建模式使得他成為業界老牌訊息中間件,在中小型企業中應用廣泛!Kafka: 是由Linkedin公司開發的,它是一個分布式的,支持多磁區、多副本,基于Zookeeper的分布式訊息流平臺,它同時也是一款開源的基于發布訂閱模式的訊息引擎系統,KAFKA基于TCP協議,RocketMQ:阿里系下開源的一款分布式、佇列模型的訊息中間件,原名Metaq,3.0版本名稱改為RocketMQ,是阿里參照kafka設計思想使用java實作的一套mq,同時將阿里系內部多款mq產品(Notify、metaq)進行整合,只維護核心功能,去除了所有其他運行時依賴,保證核心功能最簡化,在此基礎上配合阿里上述其他開源產品實作不同場景下mq的架構,目前主要多用于訂單交易系統,RabbitMQ:使用Erlang撰寫的一個開源的訊息佇列,本身支持很多的協議:AMQP,XMPP, SMTP,STOMP,也正是如此,使的它變的非常重量級,更適合于企業級的開發,同時實作了Broker架構,核心思想是生產者不會將訊息直接發送給佇列,訊息在發送給客戶端時先在中心佇列排隊,對路由(Routing),負載均衡(Load balance)、資料持久化都有很好的支持,多用于進行企業級的ESB整合,ZeroMQ:號稱最快的訊息佇列系統,專門為高吞吐量/低延遲的場景開發,在金融界的應用中經常使用,偏重于實時資料通信場景,ZMQ能夠實作RabbitMQ不擅長的高級/復雜的佇列,但是開發人員需要自己組合多種技術框架,開發成本高,
1.3 通信協議
-
AMQP:Advanced Message Queuing Protocol一個提供統一訊息服務的應用層標準高級訊息佇列協議,是應用層協議的一個開放標準,為面向訊息的中間件設計,基于此協議的客戶端與訊息中間件可傳遞訊息,并不受客戶端/中間件不同產品,不同開發語言等條件的限制, -
MQTT:(Message Queuing Telemetry Transport,訊息佇列遙測傳輸)是IBM開發的一個即時通訊協議,有可能成為物聯網的重要組成部分,該協議支持所有平臺,幾乎可以把所有聯網物品和外部連接起來,被用來當做傳感器和致動器(比如通過Twitter讓房屋聯網)的通信協議, -
STOMP:(Streaming Text Orientated Message Protocol)是流文本定向訊息協議,是一種為MOM(Message Oriented Middleware,面向訊息的中間件)設計的簡單文本協議,STOMP提供一個可互操作的連接格式,允許客戶端與任意STOMP訊息代理(Broker)進行互動, -
XMPP:(可擴展訊息處理現場協議,Extensible Messaging and Presence Protocol)是基于可擴展標記語言(XML)的協議,多用于即時訊息(IM)以及在線現場探測,適用于服務器之間的準即時操作,核心是基于XML流傳輸,這個協議可能最終允許因特網用戶向因特網上的其他任何人發送即時訊息,即使其作業系統和瀏覽器不同, -
其他:有些特殊框架(如:
redis、kafka、zeroMq等)根據自身需要未嚴格遵循MQ規范,而是基于TCP\IP自行封裝了一套協議,通過網路socket介面進行傳輸,實作了MQ的功能,
1.4 基本術語
Broker
訊息服務器,作為server提供訊息核心服務
Producer
訊息生產者,業務的發起方,負責生產訊息傳輸給broker,
Consumer
訊息消費者,業務的處理方,負責從broker獲取訊息并進行業務邏輯處理
Topic
主題,發布訂閱模式下的訊息統一匯集地,不同生產者向topic發送訊息,由MQ服務器分發到不同的訂閱者,實作訊息的 廣播
Queue
佇列,PTP模式下,特定生產者向特定queue發送訊息,消費者訂閱特定的queue完成指定訊息的接收
Message
訊息體,根據不同通信協議定義的固定格式進行編碼的資料包,來封裝業務資料,實作訊息的傳輸
二 kafaka的基本介紹
2.1 概述
Kafka是最初由Linkedin公司開發,是一個分布式、磁區的、多副本的、多訂閱者,基于zookeeper協調的分布式日志系統(也可以當做MQ系統),常見可以用于web/nginx日志、訪問日志,訊息服務等等,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源專案,
主要應用場景是:日志收集系統和訊息系統,
Kafka主要設計目標如下:
- 以時間復雜度為O(1)的方式提供訊息持久化能力,即使對TB級以上資料也能保證常數時間的訪問性能,
- 高吞吐率,即使在非常廉價的商用機器上也能做到單機支持每秒100K條訊息的傳輸,
- 支持Kafka Server間的訊息磁區,及分布式消費,同時保證每個partition內的訊息順序傳輸,
- 同時支持離線資料處理和實時資料處理,
- Scale out:支持在線水平擴展
2.2 訊息系統介紹
一個訊息系統負責將資料從一個應用傳遞到另外一個應用,應用只需關注于資料,無需關注資料在兩個或多個應用間是如何傳遞的,分布式訊息傳遞基于可靠的訊息佇列,在客戶端應用和訊息系統之間異步傳遞訊息,有兩種主要的訊息傳遞模式:點對點傳遞模式、發布-訂閱模式,大部分的訊息系統選用發布-訂閱模式,Kafka就是一種發布-訂閱模式,
2.3 點對點訊息傳遞模式
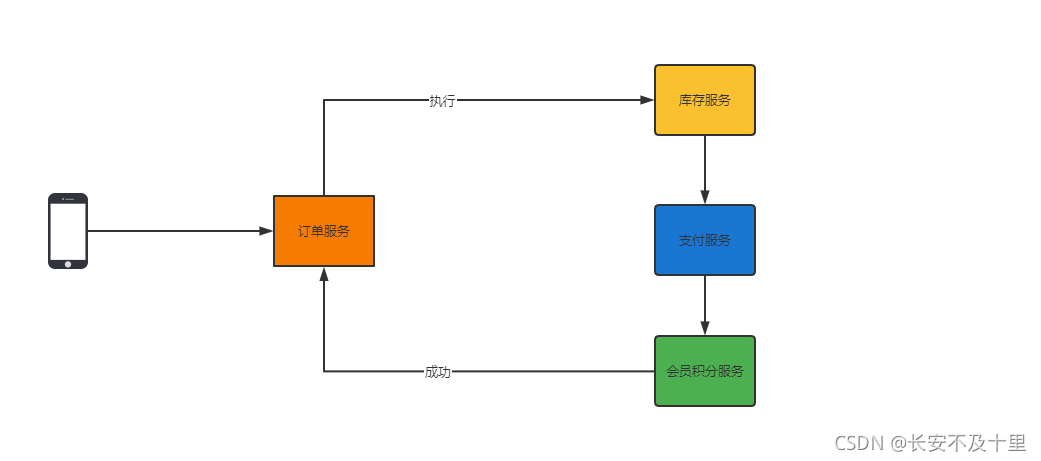
在點對點訊息系統中,訊息持久化到一個佇列中,此時,將有一個或多個消費者消費佇列中的資料,但是一條訊息只能被消費一次,當一個消費者消費了佇列中的某條資料之后,該條資料則從訊息佇列中洗掉,該模式即使有多個消費者同時消費資料,也能保證資料處理的順序,這種架構描述示意圖如下:
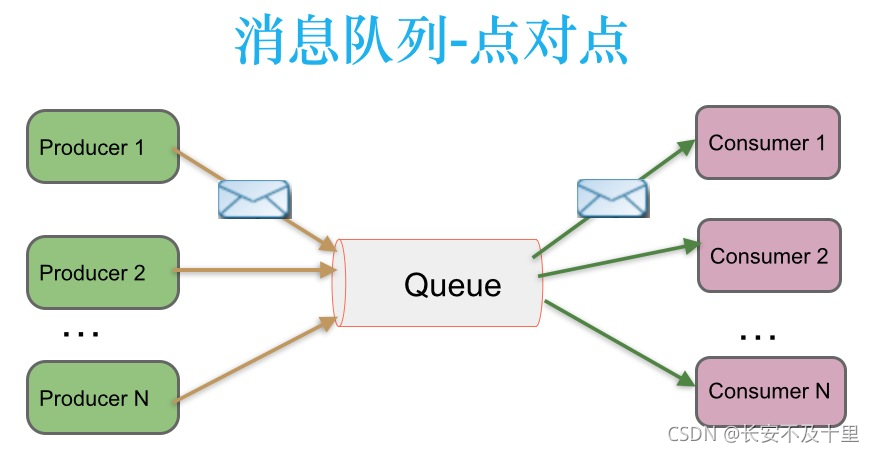
生產者發送一條訊息到queue,只有一個消費者能收到,
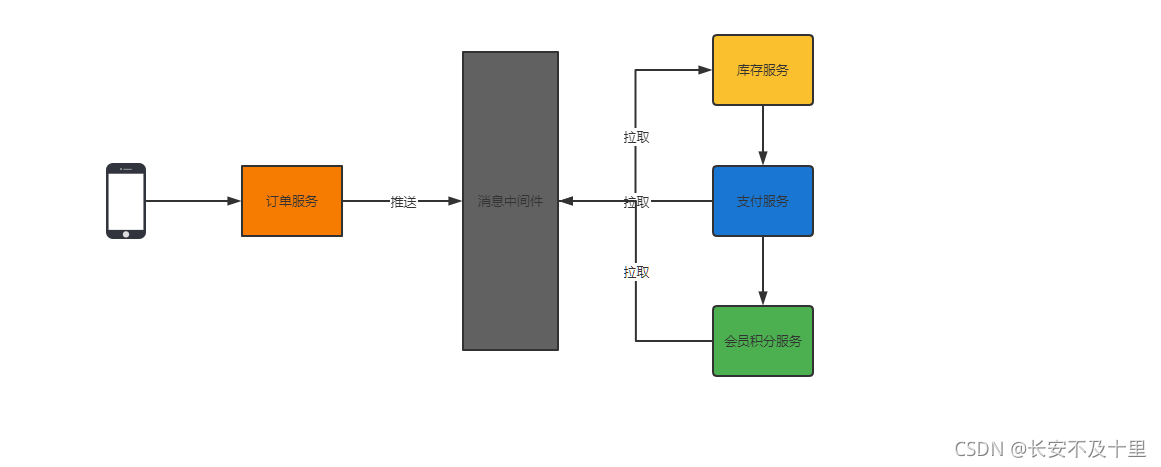
2.4 發布-訂閱訊息傳遞模式
在發布-訂閱訊息系統中,訊息被持久化到一個topic中,與點對點訊息系統不同的是,消費者可以訂閱一個或多個topic,消費者可以消費該topic中所有的資料,同一條資料可以被多個消費者消費,資料被消費后不會立馬洗掉,在發布-訂閱訊息系統中,訊息的生產者稱為發布者,消費者稱為訂閱者,該模式的示例圖如下:
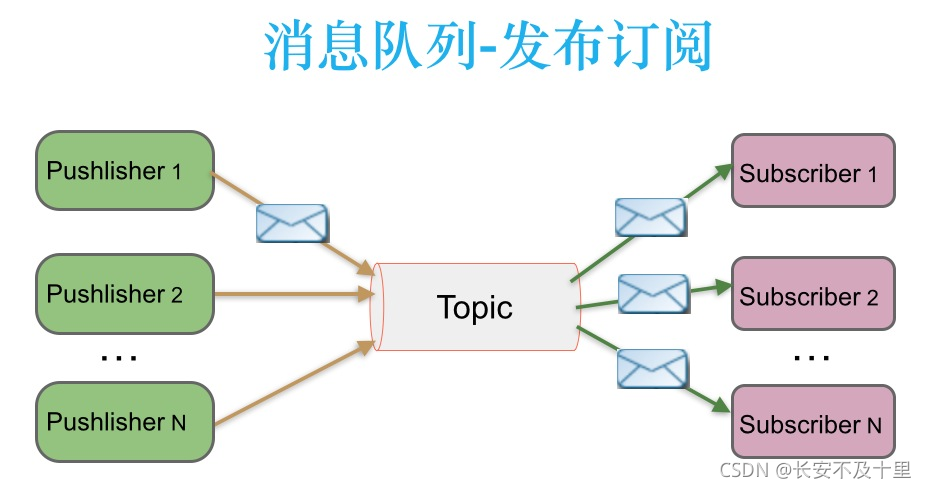
發布者發送到topic的訊息,只有訂閱了topic的訂閱者才會收到訊息,
三 Kafka中的術語解釋
3.1 概述
在深入理解Kafka之前,先介紹一下Kafka中的術語,下圖展示了Kafka的相關術語以及之間的關系:
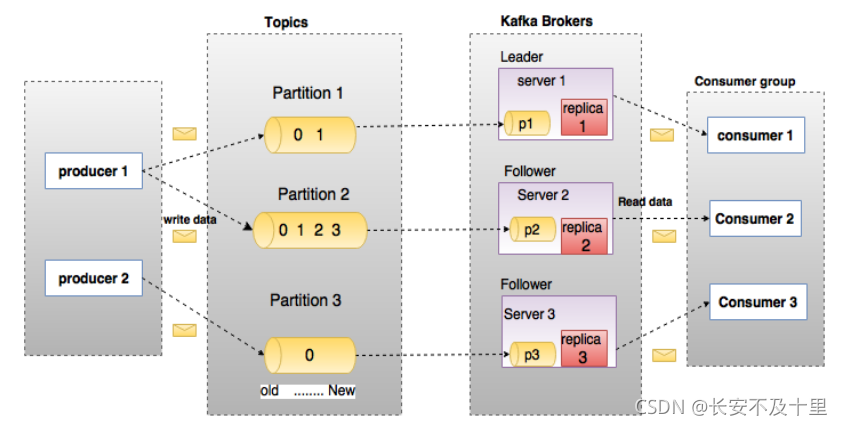
3.2 broker
Kafka 集群包含一個或多個服務器,服務器節點稱為broker,
3.3 Topic
每條發布到Kafka集群的訊息都有一個類別,這個類別被稱為Topic,類似于資料庫的表名,
3.4 Partition
topic中的資料分割為一個或多個partition,每個topic至少有一個partition,每個partition中的資料使用多個segment檔案存盤,partition中的資料是有序的,不同partition間的資料丟失了資料的順序,如果topic有多個partition,消費資料時就不能保證資料的順序,在需要嚴格保證訊息的消費順序的場景下,需要將partition數目設為1,
3.5 Producer
生產者即資料的發布者,該角色將訊息發布到Kafka的topic中,broker接收到生產者發送的訊息后,broker將該訊息追加到當前用于追加資料的segment檔案中,生產者發送的訊息,存盤到一個partition中,生產者也可以指定資料存盤的partition,
3.6 Consumer
消費者可以從broker中讀取資料,消費者可以消費多個topic中的資料,
3.7 Consumer Group
每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于默認的group),
3.8 Leader
每個partition有多個副本,其中有且僅有一個作為Leader,Leader是當前負責資料的讀寫的partition,
3.9 Follower
Follower跟隨Leader,所有寫請求都通過Leader路由,資料變更會廣播給所有Follower,Follower與Leader保持資料同步,如果Leader失效,則從Follower中選舉出一個新的Leader,
四 Kafaka的安裝
4.1 Zookeeper的安裝
- 首頁:Apache ZooKeeper
- 安裝
# 解壓
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
# 修改組態檔
cd conf
cp coo_sample.cfg zoo.cfg
vim zoo.cfg
#啟動
bin/zkServer.sh start
#查看
jps
#狀態查看
bin/zkServer.sh status
#停止
bin/zkServer.sh stop
#啟動客戶端
bin/zkCli.sh
#退出
quit
tickTime = 2000:通信心跳時間,Zookeeper服務器與客戶端心跳時間,單位毫秒initLimit = 10:LF初始通信時限,Leader和Follower初始連接時能容忍的最多心跳數(tickTime的數量)syncLimit = 5:LF同步通信時限,Leader和Follower之間通信時間如果超過syncLimit * tickTime,Leader認為Follwer死 掉,從服務器串列中洗掉Follwer,dataDir:保存Zookeeper中的資料,注意:默認的tmp目錄,容易被Linux系統定期洗掉,所以一般不用默認的tmp目錄,clientPort = 2181:客戶端連接埠,通常不做修改,
4.2 Kafka的安裝
- 官網:Apache Kafka
#解壓
tar -zxvf kafka_2.11-2.4.0.tgz
#修改組態檔
cd config
vim server.properties
# 修改以下配置
#broker.id屬性在kafka集群中必須要是唯?
broker.id=0
#kafka部署的機器ip和提供服務的端?號(內網)
#listeners=PLAINTEXT://服務器地址:9092
#阿里云外網
advertised.listeners=PLAINTEXT://阿里云地址:9092
#kafka的訊息存盤?件
log.dir=/usr/local/data/kafka-logs
#kafka連接zookeeper的地址
zookeeper.connect=192.168.65.60:2181
#是否可以洗掉
delete.topic.enable=true
# 啟動
cd bin
./kafka-server-start.sh -daemon ../config/server.properties
# 檢查是否啟動
jps
#查看埠問題
netstat -an | grep 9092
#或者
lsof -i:9092
# 防火墻開發埠
firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --reload
#停止kafka
./kafka-server-stop.sh ../config/server.properties
4.3 基本命令
注:這些命令我們不需要記,因為我們是在代碼中完成這些命令
4.3.1 創建topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic my
4.3.2 查看創建的topic
./kafka-topics.sh --list --zookeeper localhost:2181
4.3.3 洗掉某個topic
洗掉topic的前提是需要將kafka的消費者和生產者停止
./kafka-topics.sh --delete --zookeeper localhost:2181 --topic my
4.3.4 查看某個topic的資訊
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
4.3.5 發送訊息
./kafka-console-producer.sh --broker-list 服務器地址:9092 --topic my
4.3.6 接受訊息
# 重頭消費
./kafka-console-consumer.sh --bootstrap-server 服務器地址:9092 --topic my --from-beginning
# :從當前主題中的最后?條訊息的offset(偏移量位置)+1開始消費
./kafka-console-consumer.sh --bootstrap-server 服務器地址:9092 --topic my
4.3.7 訊息的有序性
- ?產者將訊息發送給broker,broker會將訊息保存在本地的?志?件中
- 訊息的保存是有序的,通過offset偏移量來描述訊息的有序性
- 消費者消費訊息時也是通過offset來描述當前要消費的那條訊息的位置

4.4 消費者組
4.4.1 單播消費
在?個kafka的topic中,啟動兩個消費者,?個?產者,問:?產者發送訊息,這條訊息是否 同時會被兩個消費者消費? 如果多個消費者在同?個消費組,那么只有?個消費者可以收到訂閱的topic中的訊息,換? 之,同?個消費組中只能有?個消費者收到?個topic中的訊息,
./kafka-console-consumer.sh --bootstrap-server 服務器地址:9092 --consumer-property group.id=testGroup --topic my --from-beginning
4.4.2 多播消費
不同的消費組訂閱同?個topic,那么不同的消費組中只有?個消費者能收到訊息,實際上也 是多個消費組中的多個消費者收到了同?個訊息,
./kafka-console-consumer.sh --bootstrap-server 服務器地址:9092 --consumer-property group.id=testGroup01 --topic my --from-beginning
./kafka-console-consumer.sh --bootstrap-server 服務器地址:9092 --consumer-property group.id=testGroup02 --topic my --from-beginning
4.4.3 查看消費組的資訊
./kafka-consumer-groups.sh --bootstrap-server 服務器地海:9092 --describe --group testGroup

重點關注以下?個資訊:
- current-offset: 最后被消費的訊息的偏移量
- Log-end-offset: 訊息總量(最后?條訊息的偏移量)
- Lag:積壓了多少條訊息
五 Kafka中主題和磁區的概念
5.1 主題
主題-topic在kafka中是?個邏輯的概念,kafka通過topic將訊息進?分類,不同的topic會被 訂閱該topic的消費者消費, 但是有?個問題,如果說這個topic中的訊息?常?常多,多到需要?T來存,因為訊息是會被 保存到log?志?件中的,為了解決這個?件過?的問題,kafka提出了Partition磁區的概念
5.2 磁區
通過partition將?個topic中的訊息磁區來存盤,這樣的好處有多個:
-
磁區存盤,可以解決統?存盤?件過?的問題
-
提供了讀寫的吞吐量:讀和寫可以同時在多個磁區中進?
./kafka-topics.sh --create --zookeeper localhost:2181 --replicationfactor 1 --partitions 2 --topic test
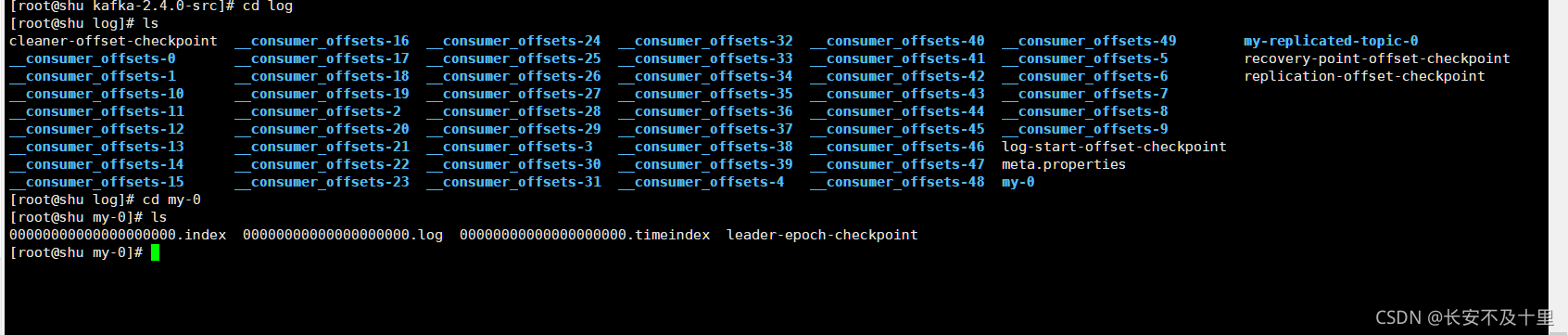
5.3 日志資訊
- 00000.log: 這個?件中保存的就是訊息
- __consumer_offsets-49: kafka內部??創建了__consumer_offsets主題包含了50個磁區,這個主題?來存放消費 者消費某個主題的偏移量,因為每個消費者都會??維護著消費的主題的偏移量,也就是 說每個消費者會把消費的主題的偏移量?主上報給kafka中的默認主題: consumer_offsets,
- 因此kafka為了提升這個主題的并發性,默認設定了50個磁區, 提交到哪個磁區:通過hash函式:hash(consumerGroupId) % __consumer_offsets 主題的磁區數 提交到該主題中的內容是:key是consumerGroupId+topic+磁區號,value就是當前 offset的值 ?件中保存的訊息,默認保存7天,
- 七天到后訊息會被洗掉,
六 Kafka集群的搭建
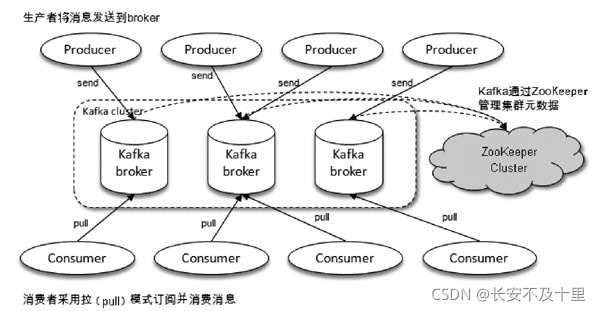
6.1 Zookeeper集群的搭建
-
注意開放埠,以及關閉防火墻
-
ip:2181,ip:2182,ip:2183
-
修改組態檔
cd conf
#修改組態檔
vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/environment/zookeeper/apache-zookeeper-3.6.3-bin/data_log
# the port at which the clients will connect
clientPort=2182
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.1=ip1:2888:3888
server.2=ip2:2888:3888
server.3=ip3:2888:3888
quorumListenOnAllIPs=true
#啟動zookeeper,修改其他機器的組態檔
bin/zkServer.sh start、
# 等待一下,查看選舉狀態
bin/zkServer.sh status
[root@shu apache-zookeeper-3.6.3-bin]# bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /environment/zookeeper/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost. Client SSL: false.
Mode: leader
[root@shu apache-zookeeper-3.6.3-bin]#
# 問題:埠開發問題,防火墻問題
# 防火墻開發埠
firewall-cmd --zone=public --add-port=2182/tcp --permanent
firewall-cmd --reload
#關閉防火墻
systemctl stop firewalld
6.2 Kafka集群的搭建
-
注意開放埠,以及關閉防火墻
-
ip:9092,ip:9093,ip:9094
-
修改組態檔
cd config
#修改組態檔
vim server.properties
#修改zookeeper連接
zookeeper.connect=ip:2181,ip:2182,ip:2183
# 分布修改三臺的機器的組態檔,并啟動
#broker.id屬性在kafka集群中必須要是唯?
broker.id=0
./kafka-server-start.sh -daemon ../config/server.properties
# 檢查是否啟動
jps
#查看埠問題
netstat -an | grep 9092
#或者
lsof -i:9092
# 防火墻開發埠
firewall-cmd --zone=public --add-port=9092/tcp --permanent
firewall-cmd --reload
#停止kafka
./kafka-server-stop.sh ../config/server.properties
# 驗證,我們在lead機器上面創建一個topic
./kafka-topics.sh --create --zookeeper localhost:2182 --replication-factor 1 --partitions 1 --topic my
#查看其余機器上的topic
[root@xlc bin]# ./kafka-topics.sh --list --zookeeper localhost:2183
my
[root@shu bin]# ./kafka-topics.sh --list --zookeeper localhost:2181
my
6.3 副本的概念
副本是為了為主題中的磁區創建多個備份,多個副本在kafka集群的多個broker中,會有?個 副本作為leader,其他是follower(就是備份)
# 創建topic
./kafka-topics.sh --create --zookeeper localhost:2182 --replication-factor 3 --partitions 2 --topic my-replicated-topic
# 查看topic詳細資訊
./kafka-topics.sh --describe --zookeeper localhost:2182 --topic my-replicated-topic
[root@shu bin]# ./kafka-topics.sh --create --zookeeper localhost:2182 --replication-factor 3 --partitions 2 --topic my-replicated-topic
Created topic my-replicated-topic.
[root@shu bin]# ./kafka-topics.sh --describe --zookeeper localhost:2182 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: my-replicated-topic Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
-
leader: kafka的寫和讀的操作,都發?在leader上,
-
leader負責把資料同步給follower,當leader掛 了,經過主從選舉,從多個follower中選舉產??個新的leader follower 接收leader的同步的資料
-
isr:可以同步和已同步的節點會被存?到isr集合中,這?有?個細節:如果isr中的節點性能較差,會被提出isr集合,
-
集群中有多個broker,創建主題時可以指明主題有多個磁區(把訊息拆分到不同的磁區中存 儲),可以為磁區創建多個副本,不同的副本存放在不同的broker?,
6.4 集群消費
- 我們在領導服務器中,創建主體,發送訊息
# 創建topic
./kafka-topics.sh --create --zookeeper localhost:2182 --replication-factor 3 --partitions 2 --topic my-replicated-topic
# 查看topic資訊
./kafka-topics.sh --describe --zookeeper localhost:2182 --topic my-replicated-topic
# 創建訊息
./kafka-console-producer.sh --broker-list ip:9093 --topic my-replicated-topic
>nihao
- 其余機器接受訊息
./kafka-console-consumer.sh --bootstrap-server ip:9092 --topic my-replicated-topic
./kafka-console-consumer.sh --bootstrap-server ip:9093 --topic my-replicated-topic
- 集群消費組命令,參考前面的消費者組命令
- ?個partition只能被?個消費組中的?個消費者消費,?的是為了保證消費的順序性,但 是多個partion的多個消費者消費的總的順序性是得不到保證的,那怎么做到消費的總順 序性呢?
- partition的數量決定了消費組中消費者的數量,建議同?個消費組中消費者的數量不要超 過partition的數量,否則多的消費者消費不到訊息
6.5 集群中的controller
- 集群中誰來充當controller 每個broker啟動時會向zk創建?個臨時序號節點,獲得的序號最?的那個broker將會作為集 群中的controller,
- 負責這么?件事: 當集群中有?個副本的leader掛掉,需要在集群中選舉出?個新的leader,選舉的規則是 從isr集合中最左邊獲得,
- 當集群中有broker新增或減少,controller會同步資訊給其他broker 當集群中有磁區新增或減少,controller會同步資訊給其他broker
6.6 rebalance機制
- 前提:消費組中的消費者沒有指明磁區來消費 觸發的條件:當消費組中的消費者和磁區的關系發?變化的時候
- 磁區分配的策略:在rebalance之前,磁區怎么分配會有這么三種策略
- range:根據公示計算得到每個消費消費哪?個磁區:前?的消費者是磁區總數/消費 者數量+1,之后的消費者是磁區總數/消費者數量
- 輪詢:?家輪著來
- sticky:粘合策略,如果需要rebalance,會在之前已分配的基礎上調整,不會改變之 前的分配情況,如果這個策略沒有開,那么就要進?全部的重新分配,建議開啟,
6.8 HW和LEO
- LEO是某個副本最后訊息的訊息位置(log-end-offset)
- HW是已完成同步的位置,訊息在寫?broker時,且每個broker完成這條訊息的同步后,hw 才會變化,在這之前消費者是消費不到這條訊息的,
- 在同步完成之后,HW更新之后,消費者 才能消費到這條訊息,這樣的?的是防?訊息的丟失,
七 代碼中的實作
7.1 訊息提供者
7.1 .1 Java訊息提供者代碼中的實作
- 依賴
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
- 代碼
/**
* @Author shu
* @Date: 2021/10/22/ 16:25
* @Description
**/
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class MySimpleProducer {
private final static String TOPIC_NAME = "my-replicated-topic";
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1.設定引數
Properties props = new Properties();
//領導者主機
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9093");
//把發送的key從字串序列化為位元組陣列
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//把發送訊息value從字串序列化為位元組陣列
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//2.創建?產訊息的客戶端,傳?引數
Producer<String,String> producer = new KafkaProducer<String, String>(props);
//3.創建訊息
//key:作?是決定了往哪個磁區上發,value:具體要發送的訊息內容
ProducerRecord<String,String> producerRecord = new ProducerRecord<>(TOPIC_NAME,"value","hello-kafka-ok");
//4.發送訊息,得到訊息發送的元資料并輸出
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println( "topic-" + metadata.topic() + "|partition-" + metadata.partition() + "|offset-" + metadata.offset());
}
}
- 查看結果
可以發現我們的消費者已經收到了訊息
7.1.2 ?產者中的ack的配置
同步
-
ack = 0 kafka-cluster:不需要任何的broker收到訊息,就?即回傳ack給?產者,最容易 丟訊息的,效率是最?的 -
ack=1(默認): 多副本之間的leader已經收到訊息,并把訊息寫?到本地的log中,才 會回傳ack給?產者,性能和安全性是最均衡的 -
ack=-1/all:??有默認的配置min.insync.replicas=2(默認為1,推薦配置?于等于2), 此時就需要leader和?個follower同步完后,才會回傳ack給?產者(此時集群中有2個 broker已完成資料的接收),這種?式最安全,但性能最差,
props.put(ProducerConfig.ACKS_CONFIG, "1");
/*
發送失敗會重試,默認重試間隔100ms,重試能保證訊息發送的可靠性,但是也可能造
成訊息重復發送,?如?絡抖動,所以需要在
接收者那邊做好訊息接收的冪等性處理
*/
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//重試間隔設定
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
-
producer 先從 zookeeper 的 “/brokers/…/state” 節點找到該 partition 的 leader
-
producer 將訊息發送給該 leader
-
leader 將訊息寫入本地 log
-
followers 從 leader pull 訊息,寫入本地 log 后 leader 發送 ACK
-
leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 發送 ACK
異步
異步發送,?產者發送完訊息后就可以執?之后的業務,broker在收到訊息后異步調??產 者提供的callback回呼?法,但是容易造成訊息丟失,
//異步發送訊息
producer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception
exception) {
if (exception != null) {
System.err.println("發送訊息失敗:" +
exception.getStackTrace());
}
if (metadata != null) {
System.out.println("異步?式發送訊息結果:" + "topic-" +
metadata.topic() + "|partition-"
+ metadata.partition() + "|offset-" + metadata.offset());
}
}
});
7.1.3 訊息緩沖區
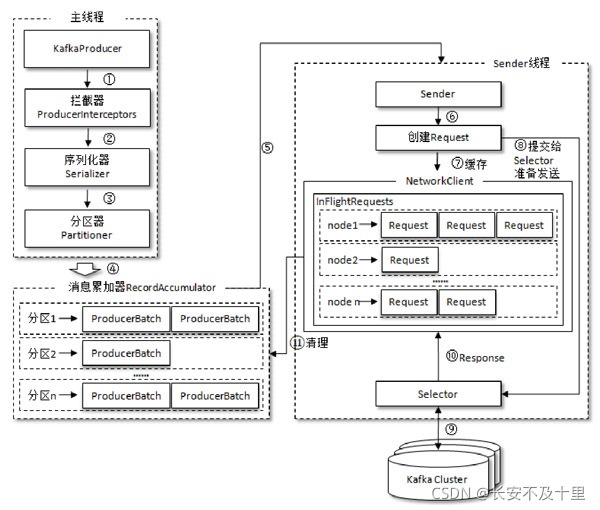
- kafka默認會創建?個訊息緩沖區,?來存放要發送的訊息,緩沖區是32m
- kafka本地執行緒會去緩沖區中?次拉16k的資料,發送到broker
- 如果執行緒拉不到16k的資料,間隔10ms也會將已拉到的資料發到broker 七、Java客戶端消費者的實作細節
//快取區默認大小
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//拉取資料默認大小
props.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
//如果數據未滿16k,也提交
props.put(ProducerConfig.LINGER_MS_CONFIG,10);
7.2 訊息消費者
7.2.1 java客服端基本實作
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @Author shu
* @Date: 2021/10/25/ 15:09
* @Description 消費者
**/
public class MySimpleConsumer {
//主題名
private final static String TOPIC_NAME = "my-replicated-topic";
//分組
private final static String CONSUMER_GROUP_NAME = "testGroup";
public static void main(String[] args) {
Properties props =new Properties();
//訊息地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "47.104.223.187:9093");
//分組
props.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);
//序列化
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//自動提交,拉取到資訊之后,立馬提交偏移量給consumer_offset,保證順序消費,但是會造成訊息丟失問題
// // 是否?動提交offset,默認就是true
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// // ?動提交offset的間隔時間
// props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//手動提交,當消費者消費訊息完畢之后,回傳偏移量
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
//?次poll最?拉取訊息的條數,可以根據消費速度的快慢來設定
// props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
//props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
//1.創建?個消費者的客戶端
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
//2. 消費者訂閱主題串列
consumer.subscribe(Arrays.asList(TOPIC_NAME));
while (true) {
/*
* 3.poll() API 是拉取訊息的?輪詢
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
//4.列印訊息
System.out.printf("收到訊息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),
record.offset(), record.key(), record.value());
}
//所有的訊息已消費完
if (records.count() > 0) {//有訊息
// ?動同步提交offset,當前執行緒會阻塞直到offset提交成功
// ?般使?同步提交,因為提交之后?般也沒有什么邏輯代碼了
consumer.commitSync();//=======阻塞=== 提交成功
}
}
}
}
7.2.1 自動提交與手動提交
- 消費者?論是?動提交還是?動提交,都需要把所屬的消費組+消費的某個主題+消費的某個 磁區及消費的偏移量,這樣的資訊提交到集群的
_consumer_offsets主題??,保證順序, - 自動提交:消費者poll訊息下來以后就會?動提交offset,但是會造成消失丟失,
//自動提交,拉取到資訊之后,立馬提交偏移量給consumer_offset,保證順序消費,但是會造成訊息丟失問題
// // 是否?動提交offset,默認就是true
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// // ?動提交offset的間隔時間
// props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
- 手動提交:當消費者消費完畢之后,提交偏移量給
_consumer_offsets
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
//?次poll最?拉取訊息的條數,可以根據消費速度的快慢來設定
// props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
//props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
while (true) {
/*
* 3.poll() API 是拉取訊息的?輪詢
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
//4.列印訊息
System.out.printf("收到訊息:partition = %d,offset = %d, key = %s, value = %s%n", record.partition(),
record.offset(), record.key(), record.value());
}
//所有的訊息已消費完
if (records.count() > 0) {//有訊息
// ?動同步提交offset,當前執行緒會阻塞直到offset提交成功
// ?般使?同步提交,因為提交之后?般也沒有什么邏輯代碼了
consumer.commitSync();//=======阻塞=== 提交成功
}
}
7.2.3 ?輪詢poll訊息
- 默認情況下,消費者?次會poll500條訊息,
//?次poll最?拉取訊息的條數,可以根據消費速度的快慢來設定
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
//?次poll最?拉取訊息的條數,可以根據消費速度的快慢來設定
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
//如果兩次poll的時間如果超出了30s的時間間隔,kafka會認為其消費能?過弱,將其踢
出消費組,將磁區分配給其他消費者,-rebalance
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
while (true) {
/*
* poll() API 是拉取訊息的?輪詢
*/
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("收到訊息:partition = %d,offset = %d, key = %s,
value = %s%n", record.partition(),
record.offset(), record.key(), record.value());
}
- 如果?次poll到500條,就直接執?for回圈 如果這?次沒有poll到500條,
- 且時間在1秒內,那么?輪詢繼續poll,要么到500 條,要么到1s 如果多次poll都沒達到500條,且1秒時間到了,那么直接執?for回圈
- 如果兩次poll的間隔超過30s,集群會認為該消費者的消費能?過弱,該消費者被踢出消 費組,觸發rebalance機制,rebalance機制會造成性能開銷,可以通過設定這個引數, 讓?次poll的訊息條數少?點
7.2.4 心跳檢查
消費者每隔1s向kafka集群發送?跳,集群發現如果有超過10s沒有續約的消費者,將被踢出 消費組,觸發該消費組的rebalance機制,將該磁區交給消費組?的其他消費者進?消費,
//consumer給broker發送?跳的間隔時間
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
//kafka如果超過10秒沒有收到消費者的?跳,則會把消費者踢出消費組,進?
rebalance,把磁區分配給其他消費者,
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
7.2.5 指定磁區和偏移量、時間消費
- 磁區消費
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
- 從頭消費
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(TOPIC_NAME,
0)));
- 指定offset消費
consumer.assign(Arrays.asList(new TopicPartition(TOPIC_NAME, 0)));
consumer.seek(new TopicPartition(TOPIC_NAME, 0), 10);
- 指定時間消費,根據時間,去所有的partition中確定該時間對應的offset,然后去所有的partition中找到該 offset之后的訊息開始消費,
List<PartitionInfo> topicPartitions =
consumer.partitionsFor(TOPIC_NAME);
//從1?時前開始消費
long fetchDataTime = new Date().getTime() - 1000 * 60 * 60;
Map<TopicPartition, Long> map = new HashMap<>();
for (PartitionInfo par : topicPartitions) {
map.put(new TopicPartition(TOPIC_NAME, par.partition()),
fetchDataTime);
}
Map<TopicPartition, OffsetAndTimestamp> parMap =
consumer.offsetsForTimes(map);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> entry :
parMap.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndTimestamp value = entry.getValue();
if (key == null || value == null) continue;
Long offset = value.offset();
System.out.println("partition-" + key.partition() +
"|offset-" + offset);
System.out.println();
//根據消費?的timestamp確定offset
if (value != null) {
consumer.assign(Arrays.asList(key));
consumer.seek(key, offset);
}
}
7.6 SpringBoot中代碼的實作
- 依賴匯入
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 組態檔撰寫
server.port=8080
#########kafka配置#############
# lead機器
spring.kafka.bootstrap-servers=ip:9093
#########producer############
# ack
spring.kafka.producer.acks=1
# 拉取大小
spring.kafka.producer.batch-size=16384
# 重試次數
spring.kafka.producer.retries=10
# 緩沖區大小
spring.kafka.producer.buffer-memory=33554432
# 序列化
spring.kafka.producer.key-serializer= org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#########consumer############
# 關閉自動提交
spring.kafka.consumer.enable-auto-commit=false
# 消費組
spring.kafka.consumer.group-id=default-group
#
spring.kafka.consumer.auto-offset-reset=earliest
# 反序列化
spring.kafka.consumer.key-deserializer= org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer= org.apache.kafka.common.serialization.StringDeserializer
# 最大訊息
spring.kafka.consumer.max-poll-records=500
spring.kafka.listener.ack-mode=manual_immediate
# redis
spring.redis.host=ip
- 服務端
package com.demo.demo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author shu
* @Date: 2021/10/27/ 16:45
* @Description
**/
@RestController
public class KafkaProvide {
private final static String TOPIC_NAME = "my-replicated-topic";
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@RequestMapping("/send")
public String sendMessage(){
kafkaTemplate.send(TOPIC_NAME,0,"key","this is a message!");
return "send success!";
}
}
- 消費端
package com.demo.demo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.PartitionOffset;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
/**
* @Author shu
* @Date: 2021/10/27/ 16:46
* @Description
**/
@Component
public class KafkaConsumer {
/**
* 單條訊息消費
* @param record
* @param ack
*/
@KafkaListener(topics = "my-replicated-topic",groupId = "MyGroup1")
public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//?動提交offset
ack.acknowledge();
}
/**
* 其他磁區消費配置
* @param record
* @param ack
*/
@KafkaListener(groupId = "testGroup", topicPartitions = {
@TopicPartition(topic = "topic1", partitions = {"0", "1"}),
@TopicPartition(topic = "topic2", partitions = "0",
partitionOffsets = @PartitionOffset(partition = "1",
initialOffset = "100"))
},concurrency = "3")//concurrency就是同組下的消費者個數,就是并發消費數,建議?于等于磁區總數
public void listenGroupPro(ConsumerRecord<String, String> record,
Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//?動提交offset
ack.acknowledge();
}
}
package com.demo.demo.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.Date;
/**
* @Author shu
* @Date: 2021/10/29/ 9:49
* @Description 訊息物體類
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class MsgInfo implements Serializable {
private Long id;
private String name;
private Long msg;
private Date time;
}
package com.demo.demo.kafka;
import com.demo.demo.pojo.MsgInfo;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.concurrent.atomic.AtomicLong;
/**
* @Author shu
* @Date: 2021/10/28/ 19:55
* @Description
**/
@Component
public class KafkaTest {
//topic
private final static String TOPIC_NAME = "my-replicated-topic";
//程式執行的初始時間,只會保留一份
private static final AtomicLong lastRecieveMessage = new AtomicLong(System.currentTimeMillis());
//時間轉換
private static final SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//前綴
private static final String KEY_PREFIX = "test";
//快取
private final List<ConsumerRecord<String,String>> DataList = new ArrayList<>();
//json
private final Gson gson = new GsonBuilder().create();
//kafka
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 訊息接受者(每隔1分鐘執行)
*/
@Scheduled(cron = "0 */1 * * * ?")
public void Consumer() {
long last = lastRecieveMessage.get();
long current = System.currentTimeMillis();
if ((current - last) > (60 * 1000)){
System.out.println(DataList);
for (ConsumerRecord<String, String> consumerRecord : DataList) {
MsgInfo info = gson.fromJson(consumerRecord.value(), MsgInfo.class);
System.out.println("訊息:"+info);
}
DataList.clear();
}
}
/**
* 訊息發送者(30s執行一次)
*/
@Scheduled(cron = "0/30 * * * * ? ")
public void Provide(){
long last = lastRecieveMessage.get();
long current = System.currentTimeMillis();
if ((current - last) > (30 * 1000) ){
MsgInfo msgInfo=new MsgInfo(current-last,"測驗",last,new Date());
kafkaTemplate.send(TOPIC_NAME,"test",gson.toJson(msgInfo));
}
}
/**
* 單條消費
* @param record
* @param ack
*/
@KafkaListener(topics = TOPIC_NAME,groupId = "MyGroup1")
public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) {
DataList.add(record);
//?動提交offset
ack.acknowledge();
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342150.html
標籤:其他
上一篇:【Hadoop 3】HDFS 高可用環境搭建(詳細圖文教程)
下一篇:Kafka問題優化之消費重復問題