統計學、深度學習、機器學習、資料挖掘
1、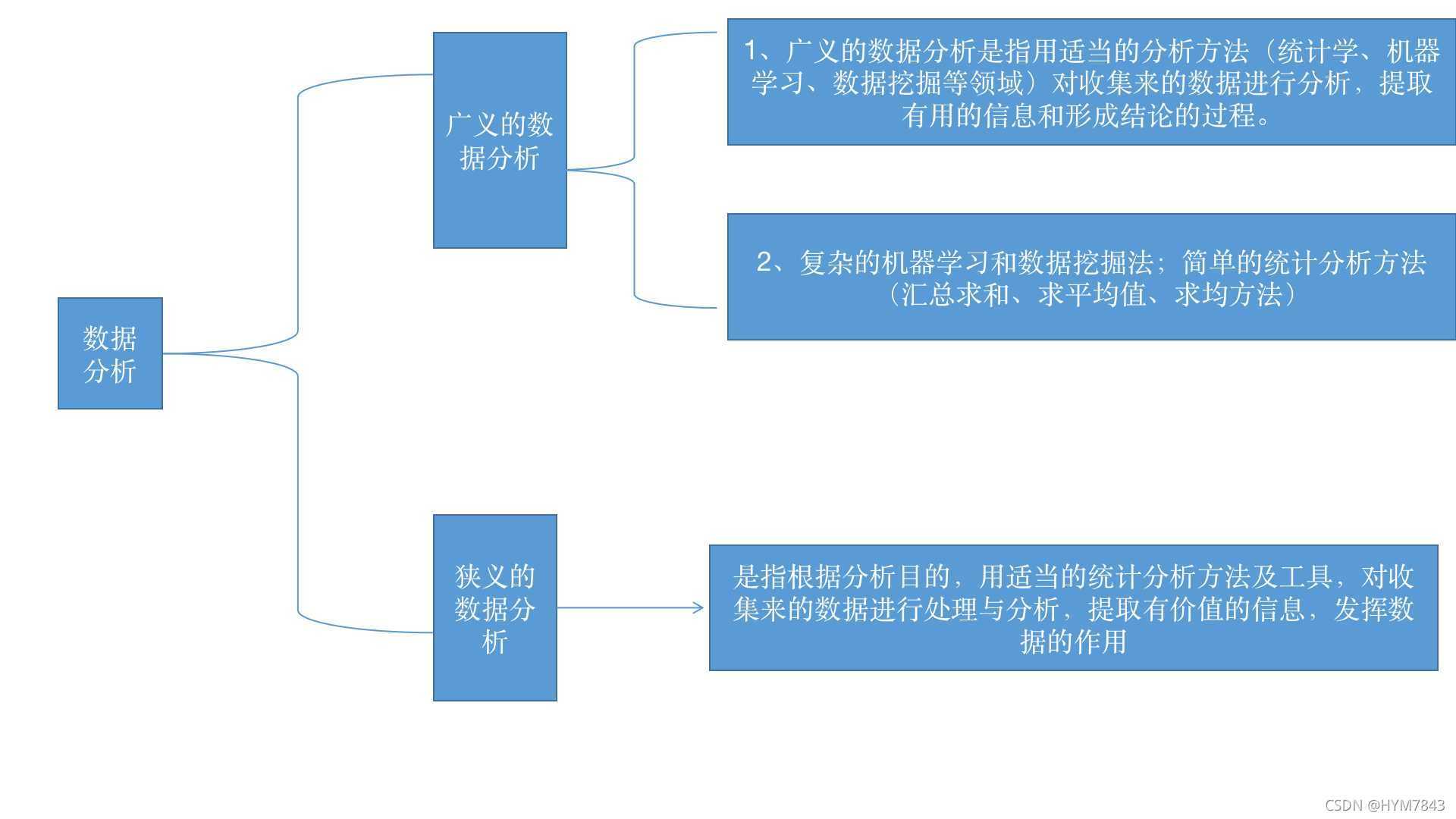
2、
3、資料挖掘:
(1)資料挖掘是在大型資料庫中,自動地發現有用資訊的程序,用來探查大型資料庫,發現先前未知的有用模式,預測未來觀測接結果,
(2)它是資料庫知識發現(Knowledge-Discovery in Databases,簡稱:KDD)中的一個步驟,
(3)資料挖掘的一般步驟:
資料準備到規律尋找到規律表示
4、統計學:
(1)統計學是資料的科學,它包括資料的收集、分類、概括、整理、分析以及解釋,
(2)統計學通常應用于兩種型別的問題:
1. 概括、描述以及探索資料,即描述性統計
2. 利用樣本資料推斷被選取樣本的資料集的性質,即推斷統計學
5、機器學習:
機器學習大致可分為兩類學習任務,分別為:監督學習(supervised learning)和非監督學習(unsupervised learning), 其中,監督學習又分為:回歸(regression)和分類(classification),
6、深度學習:
深度學習是學習樣本資料的內在規律和表示層次,這些學習程序中獲得的資訊對諸如文字,影像和聲音等資料的解釋有很大的幫助,它的最終目標是讓機器能夠像人一樣具有分析學習能力,能夠識別文字、影像和聲音等資料, 深度學習是一個復雜的機器學習演算法,在語音和影像識別方面取得的效果,遠遠超過先前相關技術,
深度學習在搜索技術,資料挖掘,機器學習,機器翻譯,自然語言處理,多媒體學習,語音,推薦和個性化技術,以及其他相關領域都取得了很多成果,深度學習使機器模仿視聽和思考等人類的活動,解決了很多復雜的模式識別難題,使得人工智能相關技術取得了很大進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342317.html
標籤:其他
上一篇:ffmpeg
下一篇:大津閾值法(OTSU)功能實作