背景:在車載監控回傳的視頻里判斷該車里是否有豬
解決思路:在回傳視頻里做物體識別,如果有豬就框出來并且給出一個代表值
day1 2021-10-27
設想:物體識別,并且在圖中框出來豬
1.找正樣本
最開始對正樣本負樣本blabla沒有概念,所以瞎轉
在csdn里搜豬的資料包,找到了一個1447圖+標注檔案的資料包,因為以前沒做過CV類的東西,感覺牛逼,趕緊下載,

下載后就這個樣子,所有圖片都是裁好的,純度不錯,并在對應的xml檔案里生成了對該豬的描述
(后來發現沒雞兒用,因為我不會處理xml)
2.找負樣本
csdn搜了一堆貓狗資料,充當負樣本,該資料包自帶neg.txt
3.對正樣本進行灰度處理,并裁減
4.安裝opencv
pip install opencv_python5.樣本裁減+灰度處理
import cv2
path = 寫你的圖片地址比如 "D:/train/new/pos/"
for i in range(1, 1447): 有多少圖寫寫多大范圍
print(path+str(i)+'.jpg') 對應的圖片路徑
img = cv2.imread(path+str(i)+'.jpg', cv2.IMREAD_GRAYSCALE)
img5050 = cv2.resize(img, (100,100))
cv2.imshow("img",img5050)
cv2.waitKey(20)
cv2.imwrite('D:/train/new/pos/pos/'+str(i)+'.jpg', img5050) 給出處理好的圖片存盤地址
6.對正樣本進行描述處理,生成一個pos.txt檔案
import os
def create_pos_n_neg():
for img in os.listdir('D:/train/test2/pos'): 圖片的路徑,
line = 'pos' + '/' + img + ' 1 0 0 100 100\n' 生成對圖片的描述
print(line)
with open('D:/train/test2/pos.txt', 'a') as f: 寫入的檔案
f.write(line)
if __name__ == '__main__':
create_pos_n_neg()
7.此事檔案結構應該是這樣的,neg放負樣本圖片,pos放正樣本圖片,neg.txt描述負樣本,pos.txt描述正樣本
對應的5個opencv檔案是下載來的,https://pan.baidu.com/s/14plhrufj2hQR3Es3aYqoIg
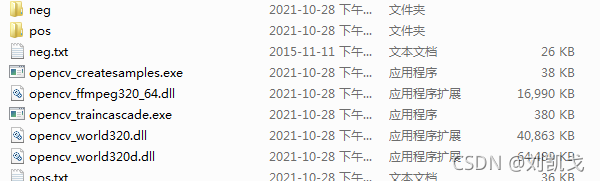
8.用createsample生成pos.vec
打開cmd,切到存放上邊這一堆的檔案夾下,輸入下邊的命令
-vec是生產的vec的名字,-info理解為指定vec從哪來的,-num是樣本數,-w -h 寬,高
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 1447 -w 100 -h 1009.出現這個小東西
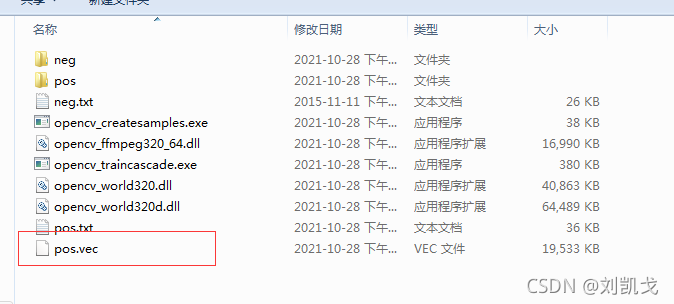
10.用traincascade進行分類器的訓練,首先創建xml檔案夾
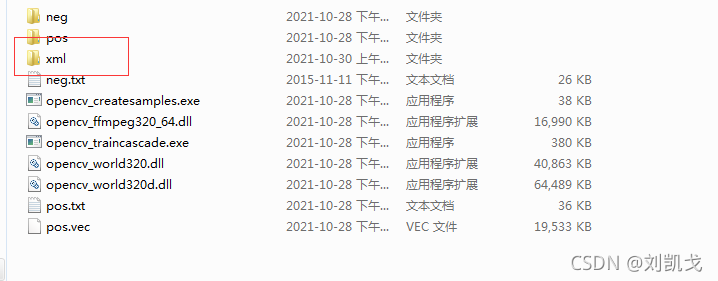
和上邊一樣,打開cmd,輸入下邊命令
-numPos正樣本數,-numNeg負樣本數,-vec正樣本,-bg負樣本,-data xml指生成xml檔案 -w -h 寬高,如果用LBP就把模型裁成24*24 -numStages層數,可任意
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 1447 -numNeg 2000 -numStages 20 -w 100 -h 100 -minHitRate 0.9999 -maxFalseAlarmRate 0.5 -mode ALL
此處記錄自己踩的坑
1.numPos沒有大寫P
2.樣本太大記憶體裝不下,一訓練就崩潰(解決方法,乖乖把圖片裁小點比如20*20)
3.層數太多記憶體裝不下
11.訓練完成
![]()
在xml檔案夾里出現這個東西就說明訓練ok
12.整一段代碼參考cascade來識別一下視頻里的豬
from PIL import Image, ImageDraw, ImageFont
import cv2
import numpy as np
import time
# 由于直接用opencv顯示中文會亂碼,所以先將圖片格式轉化為PIL庫的格式,用PIL的方法寫入中文,然后在轉化為CV的格式
def change_cv2_draw(image, strs, local, sizes, colour):
cv2img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
pilimg = Image.fromarray(cv2img)
draw = ImageDraw.Draw(pilimg)
font = ImageFont.truetype("SIMYOU.TTF", sizes, encoding="utf-8") # SIMYOU.TTF為字體檔案
draw.text(local, strs, colour, font=font)
image = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
return image
# src為輸入的影像
# classifier為對應識別物體的分類器
# strs為識別出的物體的中文說明
# colors表示框的顏色
# minSize為識別物體的最小尺寸,當識別的物體尺寸低于這個尺寸,則不檢測,就當沒識別到
# minSize為識別物體的最大尺寸,當大于該尺寸時不識別
def myClassifier(src, classifier, strs, colors, minSize, maxSize):
gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
# detectMultiScale()方法里面的引數在另一篇博客中有詳解:https://blog.csdn.net/GottaYiWanLiu/article/details/90442274
obj = classifier.detectMultiScale(gray, scaleFactor=1.15, minNeighbors=5, minSize=minSize, maxSize=maxSize)
for (x, y, w, h) in obj:
cv2.rectangle(src, (x, y), (x + w, y + w), colors, 2) # 畫框,(x,y)為識別物體的左上角頂點,(w,h)為寬和高
src = change_cv2_draw(src, strs, (x, y - 20), 20, colors) # 顯示中文
return src
# cap=cv2.VideoCapture(0)
cap = cv2.VideoCapture("C:/train/pigtest.mp4") #這里是對應的視頻檔案
pig = cv2.CascadeClassifier("C:/train/pig/xml/cascade.xml") 這里是對應的cascade
while True:
_, frame = cap.read()
frame = myClassifier(frame, pig, "pig", (0, 0, 255), (100, 100), (800, 800))
這里的pig是描述框的標題
cv2.imshow("frame", frame)
cv2.waitKey(30)
13. 看看效果

rnm退錢!垃圾垃圾垃圾垃圾
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342319.html
標籤:其他
上一篇:大津閾值法(OTSU)功能實作
下一篇:遇到的問題、秋招整理總結