學習總結
(1)業界主流的模型服務方法有 4 種,分別是預存推薦結果或 Embeding 結果、預訓練 Embeding+ 輕量級線上模型、利用 PMML 轉換和部署模型以及 TensorFlow Serving,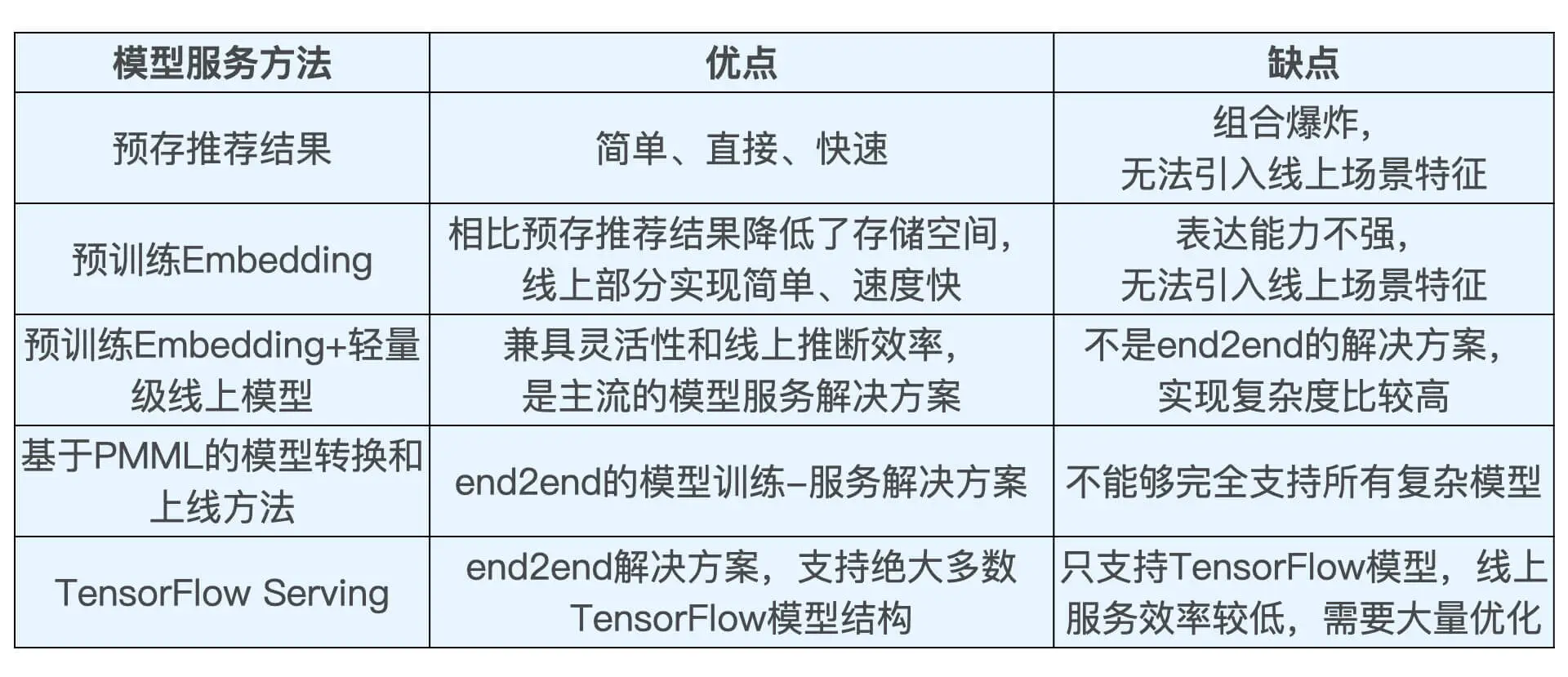
(2)重點使用基于Docker的 TensorFlow Serving 服務,它是 End2End 的解決方案,使用起來非常方便、高效,而且它支持絕大多數 TensorFlow 的模型結構,對于深度學習推薦系統來說,是一個非常好的選擇,
(3)但 TensorFlow Serving 只支持 TensorFlow 模型,而且針對線上服務的性能問題,需要進行大量的優化,TensorFlow serving本身在高并發下有一定的性能問題,有一些坑,各一線團隊都在進行一些魔改,
文章目錄
- 學習總結
- 一、業界的主流模型服務方法
- 二、預存推薦結果或Embedding
- 三、預訓練Embedding+輕量級線上模型
- 四、利用PMML轉換和部署模型
- 五、實戰搭建 TensorFlow Serving 模型服務
- 5.1 安裝 Docker
- 5.2 建立 TensorFlow Serving 服務
- 5.3 請求 TensorFlow Serving 獲得預估結果
- 六、作業
- 七、課后答疑
- Reference
一、業界的主流模型服務方法
在實驗室的環境下,我們經常使用 Spark MLlib、TensorFlow、PyTorch 這些流行的機器學習庫來訓練模型,因為不用直接服務用戶,所以往往得到一些離線的訓練結果就覺得大功告成了,但在業界的生產環境中,模型需要在線上運行,實時地根據用戶請求生成模型的預估值,這個把模型部署在線上環境,并實時進行模型推斷(Inference)的程序就是模型服務,
業界主流的模型服務方法有 4 種,分別是預存推薦結果或 Embedding 結果、預訓練 Embedding+ 輕量級線上模型、PMML 模型以及 TensorFlow Serving,
二、預存推薦結果或Embedding
對于推薦系統線上服務來說,最簡單直接的模型服務方法就是在離線環境下生成對每個用戶的推薦結果,然后將結果預存到以 Redis 為代表的線上資料庫中,這樣,我們在線上環境直接取出預存資料推薦給用戶即可,
適用場景:只適用于用戶規模較小,或者一些冷啟動、熱門榜單等特殊的應用場景中,

用戶規模大時,為了減少模型存盤所需空間,可以通過存盤embedding來替代直接存盤推薦結果,而在線上則利用embedding計算相似度得到推薦結果,在【特征工程篇】就通過 Item2vec、Graph Embedding 等方法生成物品 Embedding,再存入 Redis 供線上使用的程序,這就是預存 Embedding 的模型服務方法的典型應用,
缺點:由于完全基于線下計算出 Embedding,這樣的方式無法支持線上場景特征的引入,并且無法進行復雜模型結構的線上推斷,表達能力受限,因此對于復雜模型,我們還需要從模型實時線上推斷的角度入手,來改進模型服務的方法,
三、預訓練Embedding+輕量級線上模型
上一個方法不太行的原因:僅僅采用了“相似度計算”這樣非常簡單的方式去得到最終的推薦分數,
所以想到在線上實作一個比較復雜的操作,甚至是用神經網路來生成最終的預估值——預訓練 Embedding+ 輕量級線上模型,
具體:用復雜深度學習網路離線訓練生成 Embedding,存入記憶體資料庫,再在線上實作邏輯回歸或淺層神經網路等輕量級模型來擬合優化目標,
【栗子】阿里的推薦模型 MIMN(Multi-channel user Interest Memory Network,多通道用戶興趣記憶網路)的結構,神經網路,才是真正在線上服務的部分,
不需要糾結于復雜模型的結構細節,你只要知道左邊的部分不管多復雜,它們其實是在線下訓練生成的,而右邊的部分是一個經典的多層神經網路,它才是真正在線上服務的部分,
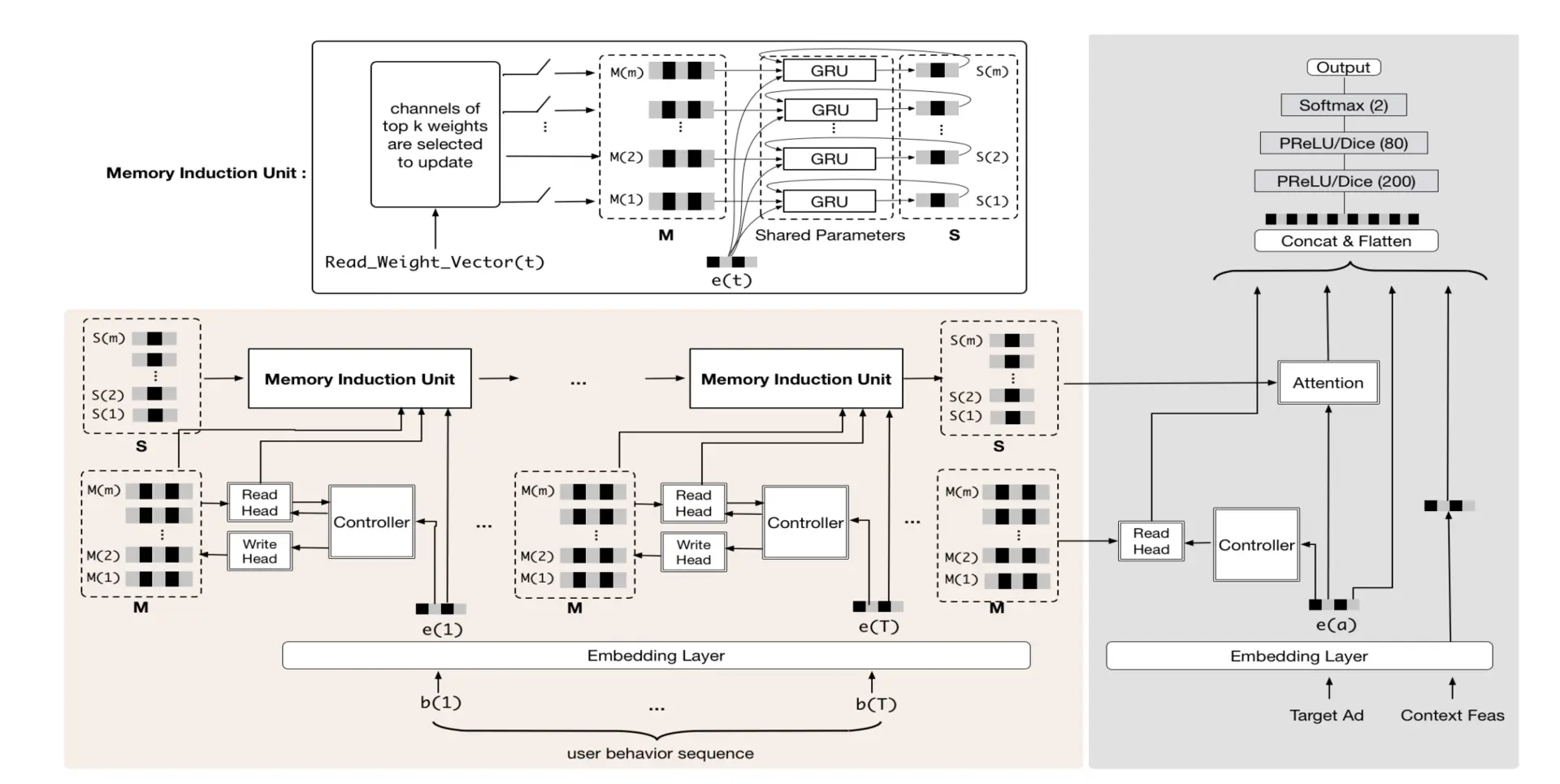
(1)有兩個被虛線框框住的資料結構,分別是 S(1)-S(m) 和 M(1)-M(m)——其實就是在離線生成的 Embedding 向量,在 MIMN 模型中,它們被稱為“多通道用戶興趣向量”,這些 Embedding 向量就是連接離線模型和線上模型部分的介面,
(2)線上部分從redis資料庫拿到這些embedding后,和其他特征的embedding向量組合,扔給一個標準的多層神經網路進行預估,
優點:隔離了離線模型的復雜性和線上推斷的效率要求,
四、利用PMML轉換和部署模型
上一個方法不完全是 End2End(端到端)訓練 +End2End 部署這種最“完美”的方式,
還有一種方法是脫離于平臺的通用模型部署方式,PMML,
“預測模型標記語言”(Predictive Model Markup Language, PMML),它是一種通用的以 XML 的形式表示不同模型結構引數的標記語言,在模型上線的程序中,PMML 經常作為中間媒介連接離線訓練平臺和線上預測平臺,
以 Spark MLlib 模型的訓練和上執行緒序為例:
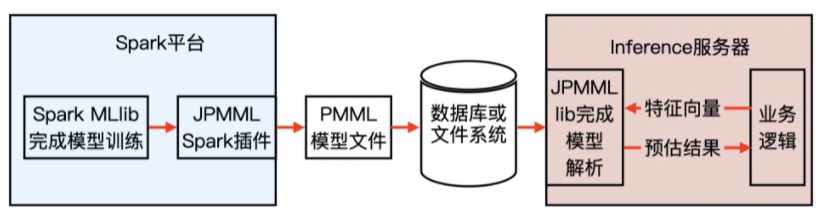
PMML 在整個機器學習模型訓練及上線流程中扮演的角色:
例子使用了 JPMML 作為序列化和決議 PMML 檔案的 library(庫),JPMML 專案分為 Spark 和 Java Server 兩部分,Spark 部分的 library 完成 Spark MLlib 模型的序列化,生成 PMML 檔案,并且把它保存到線上服務器能夠觸達的資料庫或檔案系統中,而 Java Server 部分則完成 PMML 模型的決議,生成預估模型,完成了與業務邏輯的整合,
JPMML 在 Java Server 部分只進行推斷,不考慮模型訓練、分布式部署等一系列問題,因此 library 比較輕,能夠高效地完成推斷程序,與 JPMML 相似的開源專案還有 MLeap,同樣采用了 PMML 作為模型轉換和上線的媒介,
PS:JPMML 和 MLeap 也具備 Scikit-learn、TensorFlow 等簡單模型的轉換和上線能力,
JPMML :https://github.com/jpmml
MLeap:https://github.com/combust/mleap
五、實戰搭建 TensorFlow Serving 模型服務
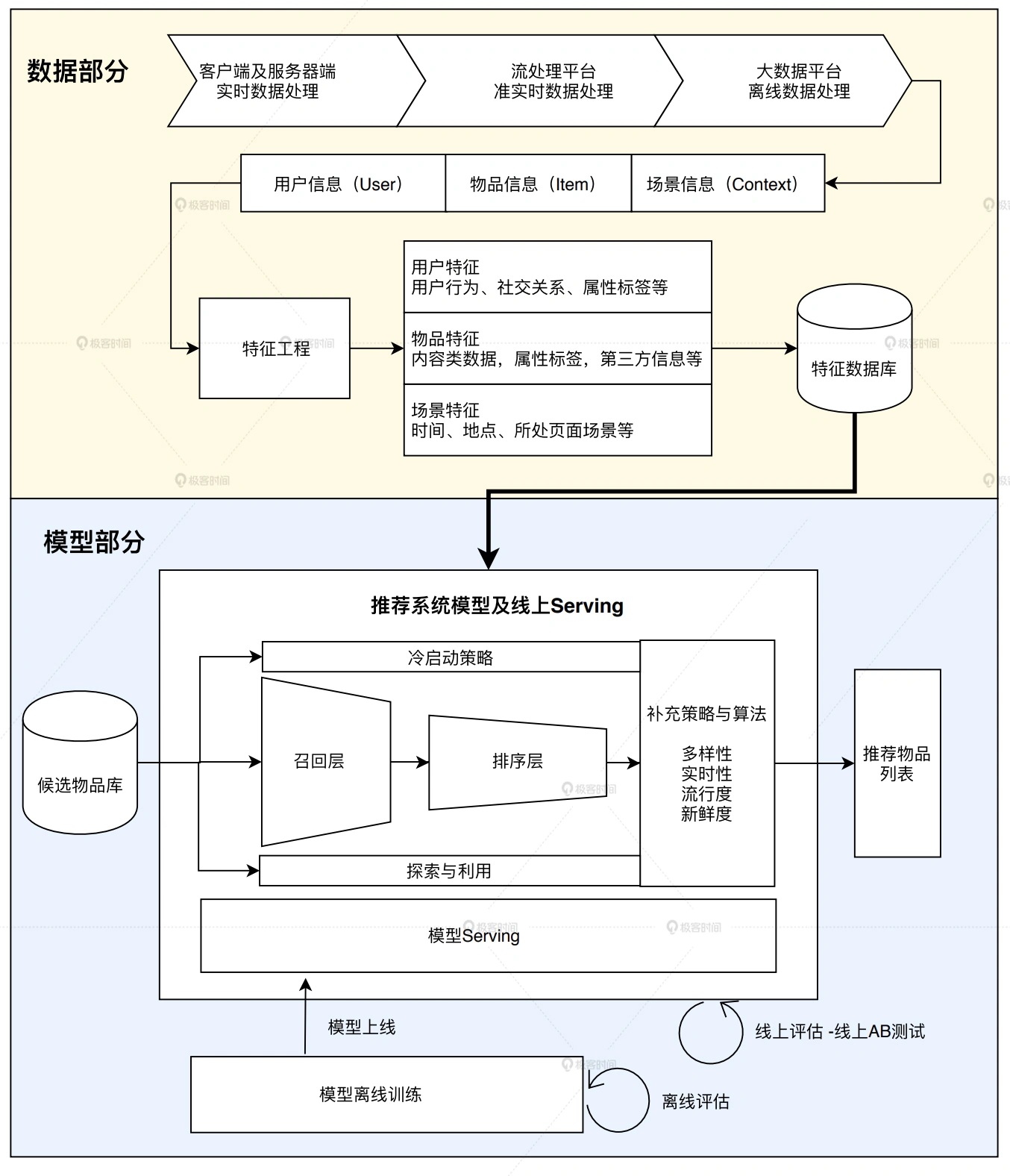
PMML 語言的表示能力還是比較有限的,還不足以支持復雜的深度學習模型結構,想要上線 TensorFlow 模型,我們就需要借助 TensorFlow 的原生模型服務模塊,也就是 TensorFlow Serving 的支持,
TensorFlow Serving 和 PMML 類工具的流程一致,它們都經歷了模型存盤、模型載入還原以及提供服務的程序,
在具體細節上:TensorFlow 在離線把模型序列化,存盤到檔案系統,TensorFlow Serving 把模型檔案載入到模型服務器,還原模型推斷程序,對外以 HTTP 介面或 gRPC 介面的方式提供模型服務,
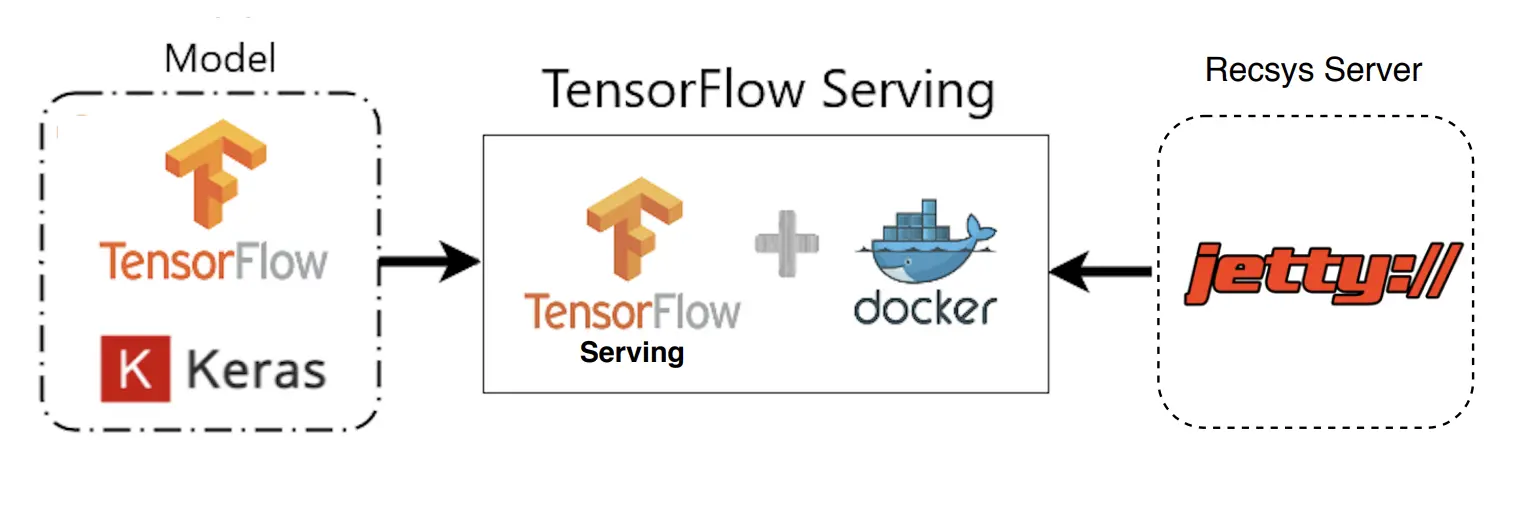
具體到 Sparrow Recsys 專案中(上圖):我們會在離線使用 TensorFlow 的 Keras 介面完成模型構建和訓練,再利用 TensorFlow Serving 載入模型,用 Docker 作為服務容器,然后在 Jetty 推薦服務器中發出 HTTP 請求到 TensorFlow Serving,獲得模型推斷結果,最后推薦服務器利用這一結果完成推薦排序,
5.1 安裝 Docker
本次學習選用了 TensorFlow Serving 作為模型服務的技術方案,它們可以說是整個推薦系統的核心了,
TensorFlow Serving 最普遍、最便捷的服務方式就是使用 Docker 建立模型服務 API,
Docker介紹:(官網:https://www.docker.com/get-started)
Docker 是一個開源的應用容器引擎,你可以把它當作一個輕量級的虛擬機,它可以讓開發者打包他們的應用以及依賴包到一個輕量級、可移植的容器中,然后發布到任何流行的作業系統,比如 Linux/Windows/Mac 的機器上,Docker 容器相互之間不會有任何介面,而且容器本身的開銷極低,這就讓 Docker 成為了非常靈活、安全、伸縮性極強的計算資源平臺,
因為 TensorFlow Serving 對外提供的是模型服務介面,所以使用 Docker 作為容器的好處主要有兩點:
一是可以非常方便的安裝(上面官網鏈接);
二是在模型服務的壓力變化時,可以靈活地增加或減少 Docker 容器的數量,做到彈性計算,彈性資源分配,
不僅可以通過圖形界面打開并運行 Docker,而且可以通過命令列來進行 Docker 相關的操作,
驗證你是否安裝成功:打開命令列輸入 docker --version 命令,它能顯示出類似“Docker version 19.03.13, build 4484c46d9d”這樣的版本號,就說明你的 Docker 環境已經準備好了,
【安裝docker的坑】
(1)官網下載docker:
https://www.docker.com/get-started
(2)菜鳥教程:
https://www.runoob.com/docker/ubuntu-docker-install.html
我參考這個教程,直接在ubuntu上curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun就ok了,這里會使用官方的腳本自動安裝好(出現一排sudo就慢慢等好了hh),
然后輸入docker --version,顯示如下版本號說明安裝成功:
Docker version 20.10.10, build b485636
(3)Docker容器啟動失敗 Failed to start Docker Application Container Engine的解決辦法:
https://www.cnblogs.com/huhyoung/p/9495956.html
或者參考:docker正常安裝成功,但是啟動服務報錯Failed to startDocker……Engine
或者參考Stack Overflow:
https://stackoverflow.com/questions/66091744/docker-failed-to-start
(4)卸載docker:在window10上徹底卸載docker
安裝也可以參考docker 入坑(win10和Ubuntu 安裝)
5.2 建立 TensorFlow Serving 服務
PS:搞tensorflow serving服務中遇到的困難可以參考官網,
首先,我們要利用 Docker 命令拉取 TensorFlow Serving 的鏡像(如果不行就加上sudo):
# 從docker倉庫中下載tensorflow/serving鏡像
docker pull tensorflow/serving
再從 TenSorflow 的官方 GitHub 地址下載 TensorFlow Serving 相關的測驗模型檔案:
# 把tensorflow/serving的測驗代碼clone到本地
git clone https://github.com/tensorflow/serving
# 指定測驗資料的地址
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
最后,我們在 Docker 中啟動一個包含 TensorFlow Serving 的模型服務容器,并載入我們剛才下載的測驗模型檔案 half_plus_two:
# 啟動TensorFlow Serving容器,在8501埠運行模型服務API
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
我的ubuntu設定的路徑后的命令應該是(不過好像有點問題,回頭看這個):
# 啟動TensorFlow Serving容器,在8501埠運行模型服務API
docker run -t --rm -p 8501:8501 \
-v "/Desktop/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
在命令執行完成后,如果你在 Docker 的管理界面(window版本)中看到了 TenSorflow Serving 容器,如下圖所示,就證明 TensorFlow Serving 服務被你成功建立起來了,而如果是用ubuntu的linux系統,則可以使用docker的圖形化Portainer容器,
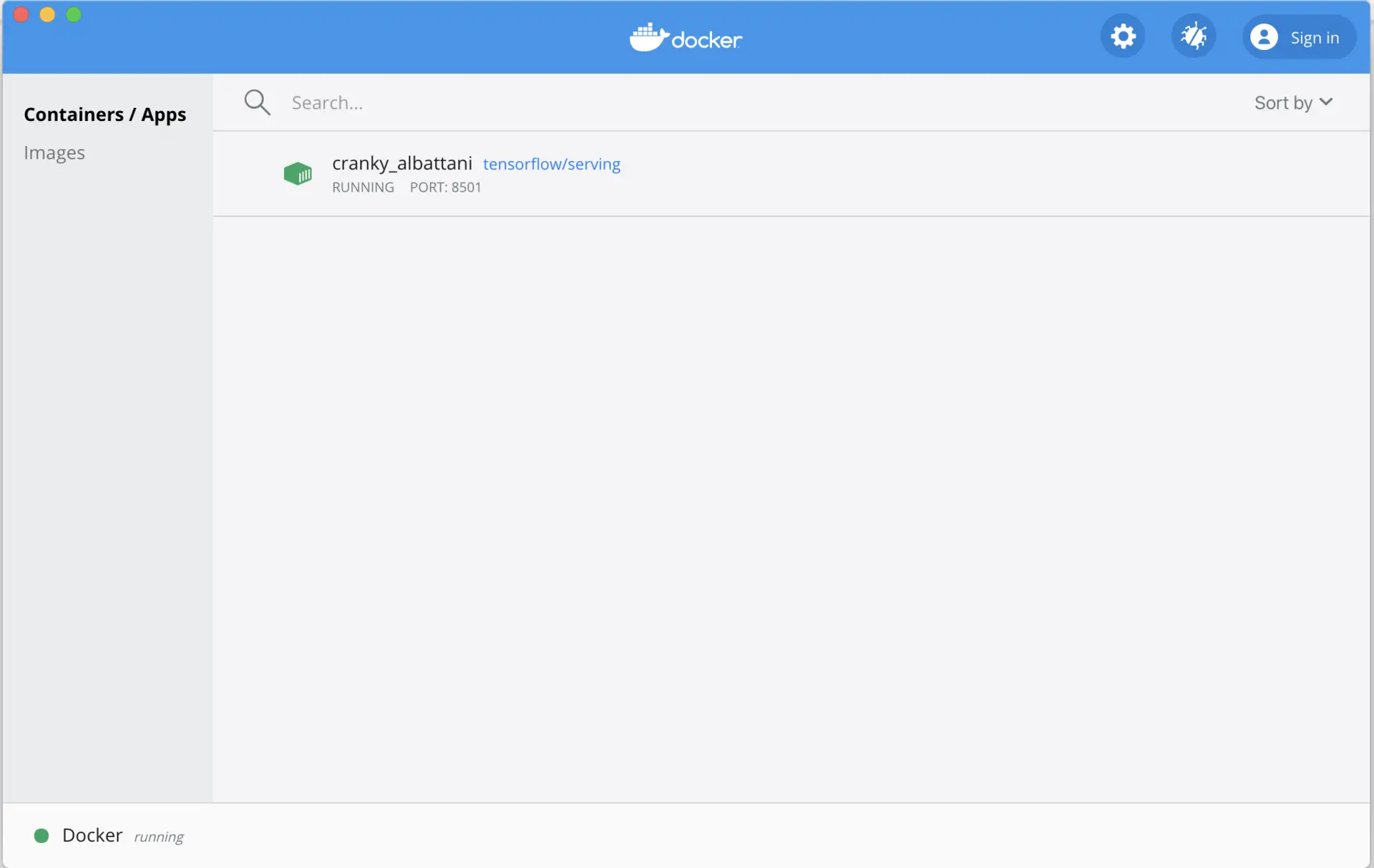
注意關閉docker服務是:service docker stop,其他常用的docker命令總結,
5.3 請求 TensorFlow Serving 獲得預估結果
驗證一下是否能夠通過 HTTP 請求從 TensorFlow Serving API 中獲得模型的預估結果:
(1)可以通過 curl 命令來發送 HTTP POST 請求到 TensorFlow Serving 的地址;
(2)或者利用 Postman 等軟體來組裝 POST 請求進行驗證,
# 請求模型服務API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
回傳結果如下,就說明 TensorFlow Serving 服務已經成功建立起來了,
# 回傳模型推斷結果如下
# Returns => { "predictions": [2.5, 3.0, 4.5] }
PS:上面只是使用了 TensorFlow Serving 官方自帶的一個測驗模型,來將怎么準備環境,在推薦模型實戰的時候,還會基于 TensorFlow 構建多種不同的深度學習模型,到時候 TensorFlow Serving 就會派上關鍵的用場了,
六、作業
你是如何在自己的專案中進行模型服務的嗎?你還用過哪些模型服務的方法?
七、課后答疑
(1)在window7上面通過docker toolbox安裝好了docker,然后在docker toolbox上pull tensorflow serving鏡像,再把tensorflow測驗模型檔案下載到本地,并配置TESTDATA地址,然后docker run服務,最后報錯了:error response form daemon: invalid mode: /models/half_plus_two,
【答】估計還是TESTDATA的路徑問題,參考這篇文章https://stackoverflow.com/questions/50540721/docker-toolbox-error-response-from-daemon-invalid-mode-root-docker,
(2)建議:第一步初次安裝的國內小伙伴,添加Docker 引擎源加快拉取資料:
{
"experimental": true,
"debug": true,
"registry-mirrors": [
"http://hub-mirror.c.163.com"
]
}
(3)請問tf serving怎么解決預訓練embedding+輕量級預估的問題呢,如果用tf serving方案,MIMN不還是割裂的兩部分嗎,并不是端到端的啊,
【答】tf serving并不是說不能做MIMN的end2end serving,而是因為MIMN做e2e serving太慢了,所以把它割裂成兩部分,這是一個優化的程序,
這塊沒必要鉆牛角尖,我們這里說的是tf serving有e2e serving的能力,真正的工業級環境,當然是要做各種優化的,
(4)git clone tf-serving不可用,failed,網上找的以下這個可以:
git clone --recurse-submodules https://github.com/tensorflow/serving
(5)下面這個TESTDATA這句命令也是直接在command Prompt里直接打么,我試了,得到錯誤資訊“TESTDATA is not recognized as an internal or external command…” 是不是應該在別的地方打這句啊?
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
【答】這句是配置一個變數,如果不打的話,你把serving/tensorflow_serving/servables/tensorflow/testdata 的完整絕對路徑替換后面命令的TESTDATA也可以
(6)在Windows下的Git命令列里照著輸入這些指令碰到了下面的問題,運行docker run那個指令報錯:
E tensorflow_serving/sources/storage_path/file_system_storage_path_source.cc:364] FileSystemStoragePathSource encountered a filesystem access error: Could not find base path /models/half_plus_two for servable half_plus_two
報錯說找不到模型檔案,
原因:$TESTDATA這里的路徑前面是"/c:/xxx/"這種,識別不了
解決方法:手動輸入路徑,把c盤前面的’/'符號去掉,就本來是‘/c:/xxx/xxx’改成‘c:/xxx/xxx’就可以了
【另外】curl就本文中提到的命令中,windows下引號需要轉義,
curl -d ‘{“instances”: [1.0, 2.0, 5.0]}’
變成curl -d “{“instances”: [1.0, 2.0, 5.0]}” ,后面不變,
Windows 下curl轉義可以參考https://stackoverflow.com/questions/58788793/curl-query-to-tensorflow-serving-model-to-predict-api-breaks
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度學習推薦系統實戰》,王喆
(3)docker圖形化Portainer
(4)基礎服務系列-安裝TensorFlow Serving
(5)Tensorflow Serving: no versions of servable half_plus_two found under base path /models
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/342349.html
標籤:其他
上一篇:計算機入門知識點(簡)
下一篇:從表中提取記錄值的SQL查詢?