Come on,傻狗
- Map
- 概述
- 常用方法
- 底層結構
- 應用
- Set
- 概述
- 常用方法
- 底層結構
- 作用
- 哈希表
- 哈希沖突
- 避免哈希沖突
- 解決哈希沖突
HashMap和HashSet資料型別 增刪改查 的時間復雜度都是 O(1)
Map
概述
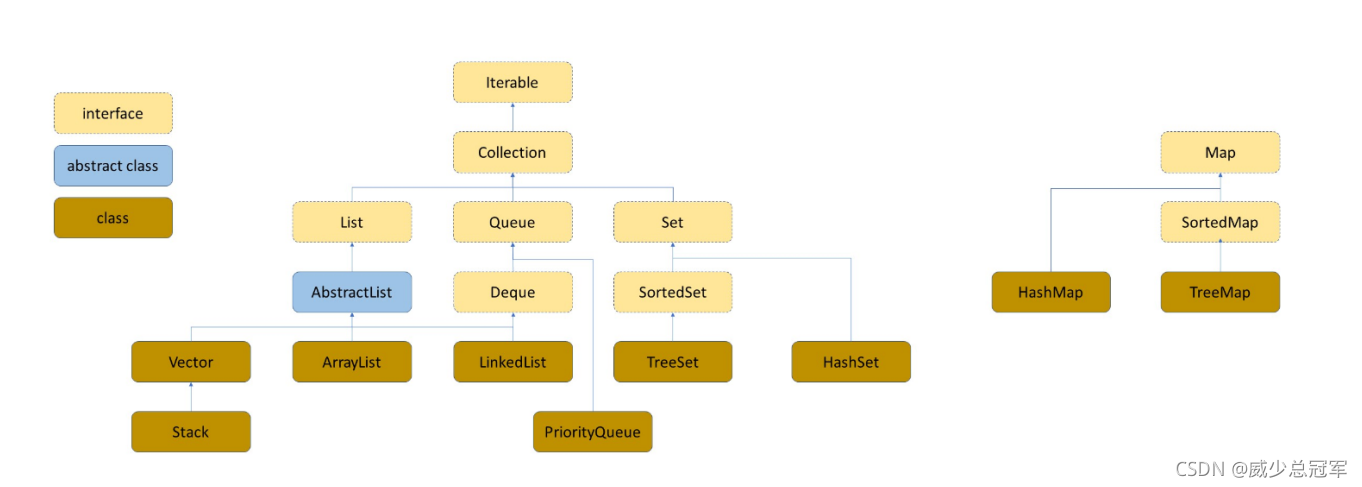
- Map是一個介面,如果要實體化一個物件,只能實體化其實作類HashMap或TreeMap
- 由圖可知,Map介面沒有繼承Iterable介面,所以Map實體的物件不能使用迭代器來列印(Map中也沒有iterator()方法)
- Map屬于Key-Value型別 key值是唯一的,不能重復,但是value 是可重復的
常用方法
| HashMap常用方法 | 解釋 |
|---|---|
| V get(Object key) | 回傳value對應的key;key不存在,回傳null |
| V getOrDefault(Object key , V defaultValue) | 回傳value對應的key;key不存在,回傳defaultValue |
| V put(K key, V value) | 設定key-value;如果原來有相同的key,value更新;key和value都可以是null |
| V remove(Object key) | 洗掉key-value;key存在,回傳value;key不存在,回傳null |
| Collection< V > values() | 回傳value的不重復集合 |
| Set< K > keySet() | 回傳所有key值的Set集合 |
| Set< Map.Entry< K , V> > entrySet() | 回傳所有key-value(集合中key-value是一個整體,型別是Map.Entry )的Set集合 |
| Boolean containsKey(Object key) | 判斷是否包含key |
| Boolean containsValue(Object value) | 判斷是否包含value |
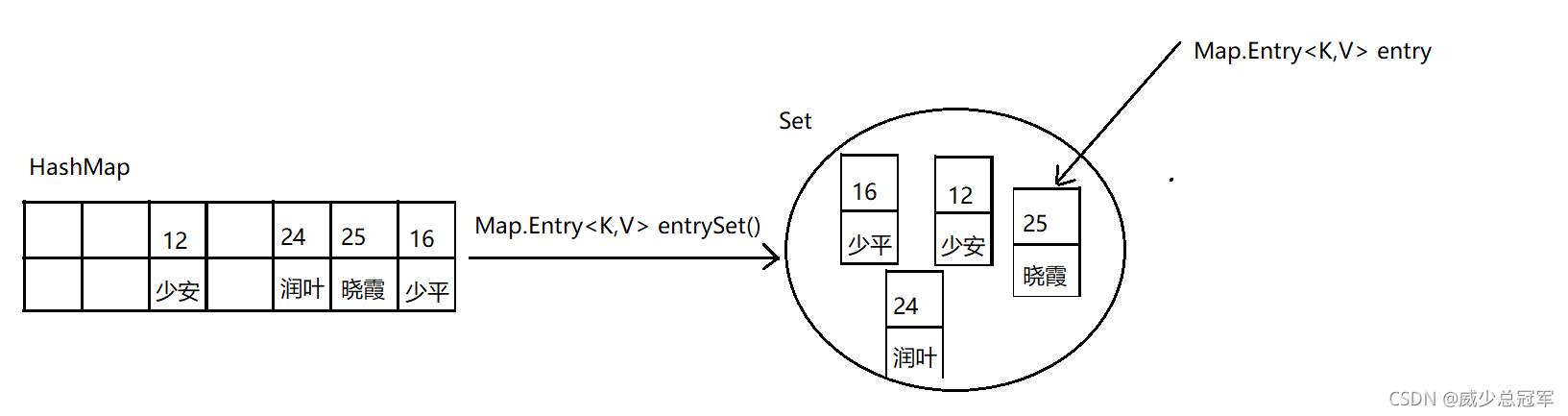
| Map.Entry< K,V >的方法 | |
|---|---|
| K getKey() | 回傳 entry中的key |
| V getValue() | 回傳entry中的value |
| V setValue(V value) | 替換value |
底層結構
| Map的底層結構 | HashMap | TreeMap |
|---|---|---|
| 增刪改查時間復雜度 | 通過哈希函式計算得到哈希地址 O(1) | 需要進行元素(key)的比較 O(log2N) |
| 底層結構 | 哈希表(陣列+鏈表+紅黑樹) | 紅黑樹 |
| 元素是否有序 | 無序 | 關于key有序(通過key的大小比較) |
| 比較和重寫 | 自定義型別要重寫equals和hashcode方法 | key要能夠進行比較,否則會拋出例外(如:put(null , value) 或 remove(null)…) |
| 應用場景 | 對時間復雜度要求高 | key需要有序 |
因為TreeMap是按照key進行組織的,所以查找key的時間復雜度為O(log2N),但是如果單純的查找value的話,需要遍歷所有元素,時間復雜度O(N)
觀察有序性
Map<Integer,String> treeMap = new TreeMap<>();
treeMap.put(1,"孫少安");
treeMap.put(12,"孫少平");
treeMap.put(6,"孫蘭花");
treeMap.put(52,"賀秀蓮");
System.out.println(treeMap);
Map<Integer,String> hashMap = new HashMap<>();
hashMap.put(1,"孫少安");
hashMap.put(12,"孫少平");
hashMap.put(6,"孫蘭花");
hashMap.put(52,"賀秀蓮");
System.out.println(hashMap);

應用
Map主要用于求資料的頻率(出現次數)
某陣列中有100,000個資料,求每個資料出現的次數
public static Map<Integer,Integer> findTimes(int[] array){
Map<Integer,Integer> map = new HashMap();
for (int count : array) {
if(map.get(count) == null){
map.put(count,1);
}else{
int value = map.get(count);
map.put(count,value+1);
}
//map.put(count,map.getOrDefault(count,0)+1);
}
return map;
// 重復的資料出現的此數
// for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
// if(entry.getValue() > 1){
// System.out.println("資料" + entry.getKey() + "出現的次數" + entry.getValue());
// }
// }
}
public static void main(String[] args) {
int[] array = new int[100000];
Random random = new Random();
for (int i = 0; i < array.length; i++) {
array[i] = random.nextInt(1000);
}
System.out.println(findTimes(array));
}
Set
概述
- Set是key型別,Set中的key值要求唯一
- Set是個介面,實體化一個物件要用HashSet或TreeSet類進行實體化
- Set繼承了Collection類,能通過Iterator列印Set中的元素
Set<Integer> set = new HashSet<>();
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
常用方法
| HashSet常用方法 | 解釋 |
|---|---|
| boolean add(E e) | 插入,但是重復元素不會插入成功 |
| boolean contains(Object e) | 判斷是否在集合中 |
| boolean remove(Object e) | 洗掉元素 |
| Object[ ] toArray() | set中的元素轉為陣列回傳 |
| boolean addAll(Collection<? extend E> c ) | 集合c中的元素添加到set中 |
| boolean containsAll(Collection<? extend E> c) | 判斷集合c中的元素是否在set中 |
| void clear() | 清空set中的元素 |
底層結構
| Set的底層結構 | HashSet | TreeSet |
|---|---|---|
| 增刪改查時間復雜度 | 通過哈希函式計算得到哈希地址 O(1) | 需要進行元素(key)的比較 O(log2N) |
| 底層結構 | 哈希表(陣列+鏈表+紅黑樹) | 紅黑樹 |
| 元素是否有序 | 無序 | 有序 |
| 比較和重寫 | 自定義型別要重寫equals和hashCode方法 | key要能夠進行比較,否則會拋出例外(如:add(null)或 remove(null)…) |
| 應用場景 | 對時間復雜度要求高 | key需要有序 |
作用
Set常用于去重
哈希表
順序結構及平衡樹中,關鍵碼和存盤位置之間沒有對應的關系,查找一個元素時,要經過一系列的比較;順序查找時間復雜度為O(N),平衡二叉樹中為O(log2N)
能否不經過比較,一次性的從表中得到想要的元素?
建立一種結構,通過哈希函式將元素的存盤位置與元素(關鍵碼)之間建立一一對應的映射關系[ 存盤位置=F(元素) ],查找的時間復雜度為O(1),這種結構就叫做哈希表
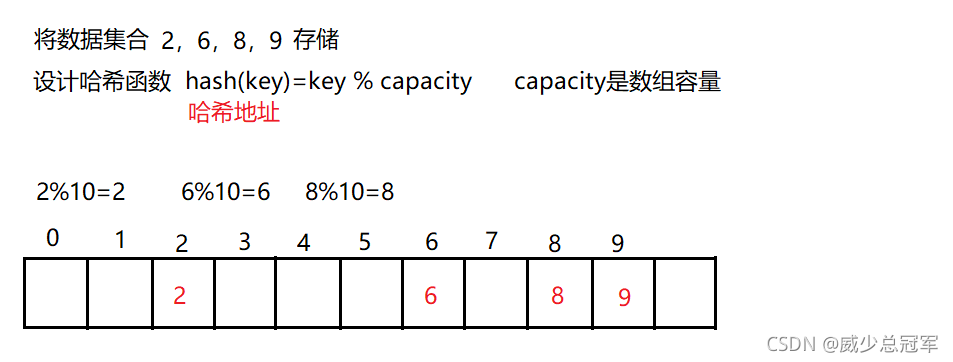
哈希沖突
不同的關鍵碼通過相同的哈希函式計算出相同的哈希地址,叫做哈希沖突或哈希碰撞
哈希沖突是必然存在的,不能從根本上解決
如上圖:14%10 =4 24%10=4 34%10=4
避免哈希沖突
- 設計合適的哈希函式
哈希函式的定義域包括需要存盤的所有關鍵碼,值域是0~m-1(哈希表有m個地址)
直接定制法:線性函式 Hash(key) = A*key+B
除數殘留法:Hash(key) = key%p(p<=m)
2.調節負載因子
哈希表的負載因子 = 填入的元素個數 / 哈希表的長度
0~1范圍內,負載因子越大,沖突率越高
由于填入的關鍵碼個數無法更改,通過調整哈希表中陣列的大小來實作對負載因子的調節
解決哈希沖突
- 閉散列
(1)線性探索
從沖突位置開始,依次向后探測,直到找到下一個空位置為止,遍歷完哈希表后,再從頭開始
缺點:沖突的元素會擠在一起的,而且不能隨便物理洗掉哈希表中已有的元素
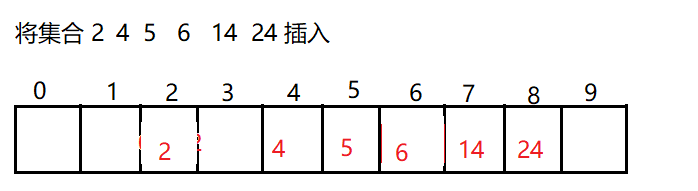
(2)二次探索
二次探索在線性探索的基礎上修改了 找下一個空位置的方法
Hi = (H0 + i^2 )%m
Hi = (H0 - i^2 )%m
H0是計算的得到的哈希地址
Hi 是插入的哈希地址 - 開散列(哈希桶)
具有相同哈希地址的關鍵碼通過一個單鏈表連接起來,各鏈表的頭節點存盤在哈希表中(哈希陣列中是一個單鏈表頭節點的參考)
當陣列長度超過64并且鏈表長度超過8,鏈表變成紅黑樹
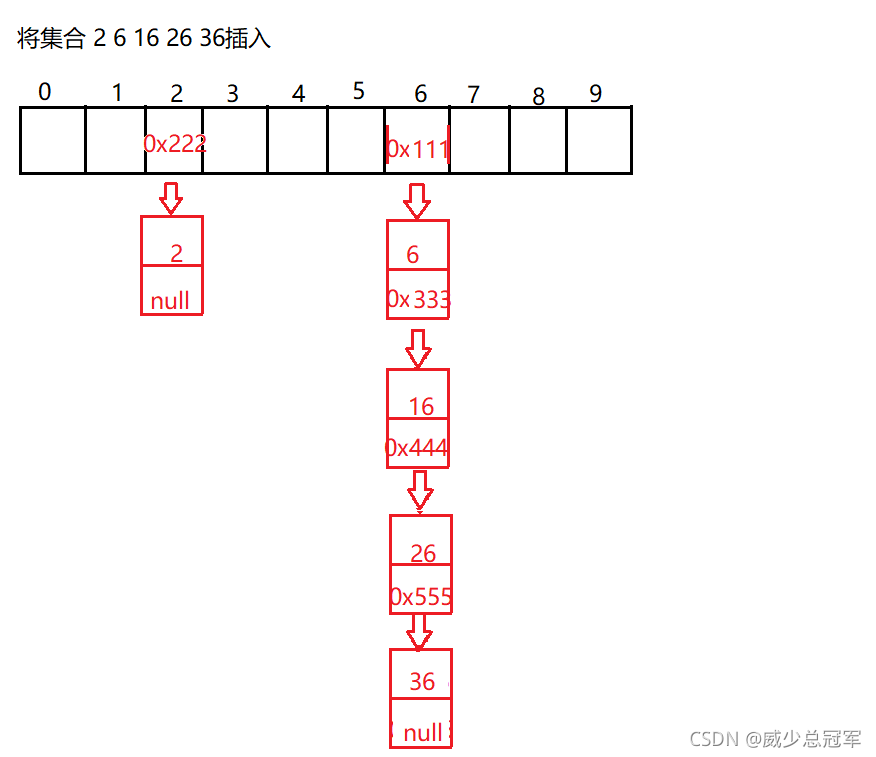
jdk1.8采用尾插法,jdk1.7以前采用頭插法
負載因子在,鏈表不會很長,找資料遍歷單鏈表
有沒有打NBA2k的老鐵?加個好友切磋切磋哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/344235.html
標籤:其他
上一篇:2:Jdbc工具類
下一篇:資料結構之鏈表(1)