目錄
前言
二叉搜索樹的概念
二叉搜索樹的操作
樹的節點實作
搜索樹的基本結構
插入資料
查找
洗掉
拷貝建構式
二叉搜索樹的應用
前言
在c++中的容器里map和set的學習需要二叉搜索樹的鋪墊,也為后邊的的紅黑樹和AVL樹做鋪墊,也就是說,今天主要講搜索樹的基本結構和應用,
二叉搜索樹的概念
所有的根節點大于左子樹的節點,小于右子樹的節點的二叉樹就叫做二叉搜索樹,
二叉搜索的性質:
- 如果左子樹不為空,則左子樹上的所有節點都小于根節點,
- 如果右子樹不為空,則右子樹上的所有節點都大于根節點,
- 左右子樹也為搜索二叉樹,
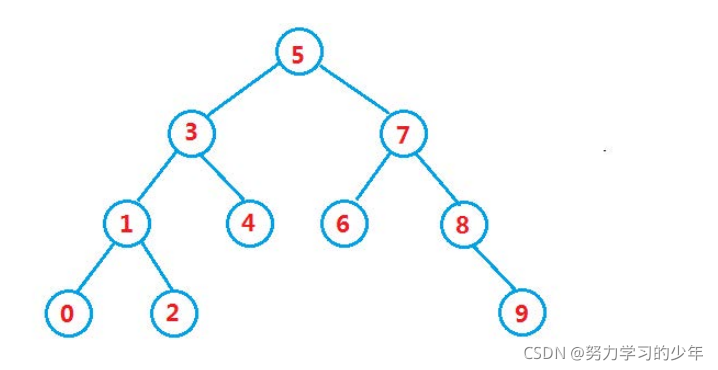
假設我們要查找8,我們從根節點開始查找,這該怎樣查找呢?
首先我們先與根節點5對比,發現比根節點5大,所以我們就到它的右子樹查找,根節點就變為7,然后我們再與根節點7對比,發現比根節點大,再到根節點7的右子樹查找,根節點就變為8,找到該節點之后我們在回傳,
二叉搜索樹的搜索的時間復雜度:
對于同一個元素的集合,如果元素的插入順序不同的,則會出現不同結構的二叉搜索樹,也就是說樹的結構與元素插入的順序有關,
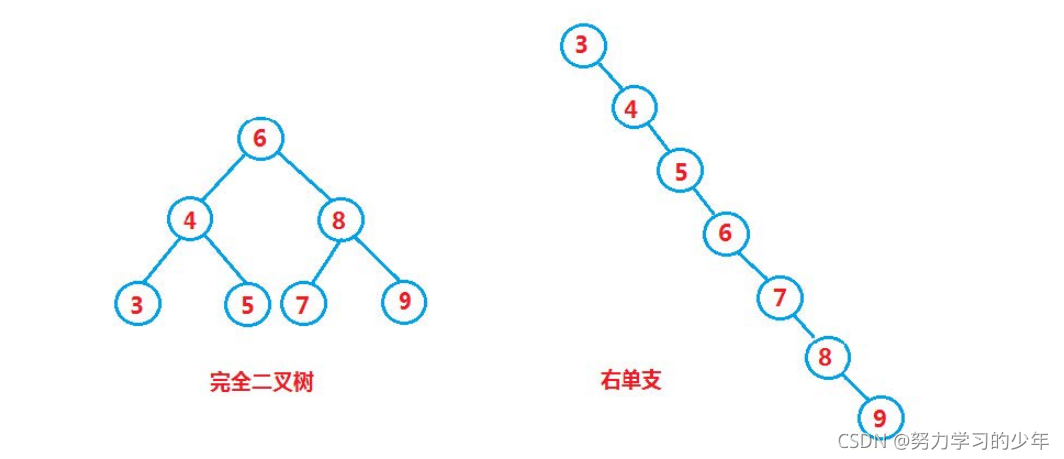
搜索效率最優的情況下:完全二叉樹,其平均比較的次數是O (logN),
搜索效率最壞的情況:單支二叉樹,其平均的比較次數是O(N)
所以搜索二叉樹的搜索的時間復雜度是O(N),時間復雜度看的是最壞的情況,
樹的搜索次數與樹的層次有關.
二叉搜索樹的操作
樹的節點實作
template<class T>
struct TreeNode
{
TreeNode* _left;
TreeNode* _right;
T _key;
TreeNode(const T& x)
:_key(x)
,_left(nullptr)
,_right(nullptr)
{
}
};搜索樹的基本結構
template<class T>
class BinarySearchTree
{
public:
typedef TreeNode<T> Node ;
//需要建構式將根節點初始化為空
BinarySearchTree()
:_root(nullptr)
{
}
.....
private:
//為什么是定義Node變數?
//1.插入洗掉時,好判斷該節點是否為空,
//2.節點的左右孩子都是指標,方便賦值
Node* _root;//根節點
};
插入資料
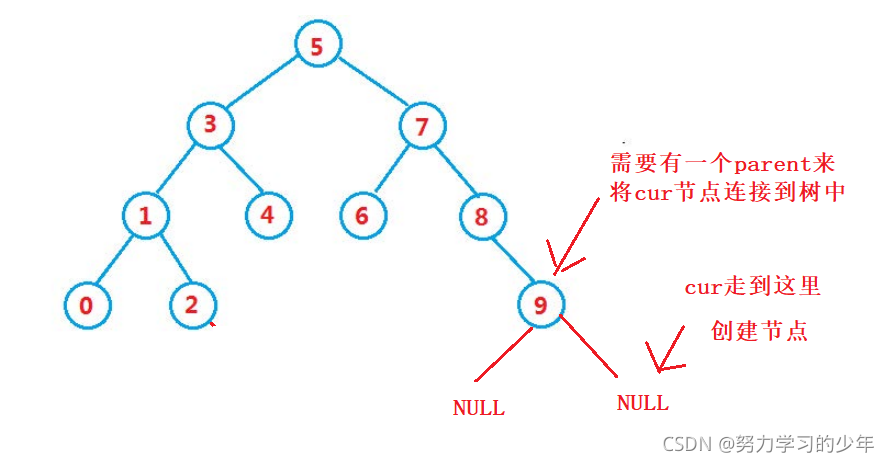
a.樹為空,則直接插入

b.樹不為空,按二叉樹搜索的性質插入的位置,插入的位置都會是葉子節點,
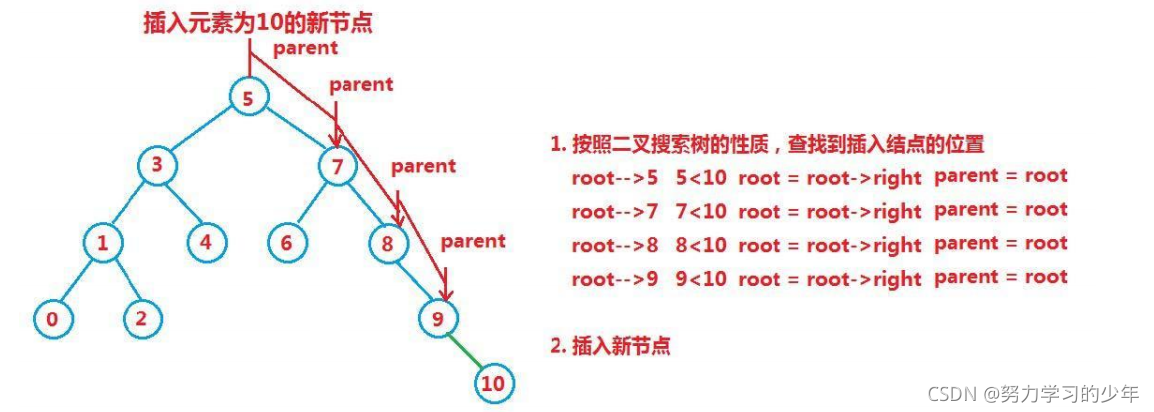
c.如果插入的資料在樹中已存在,則不將資料插入到樹中,并回傳false,搜索樹的資料都是獨一無二的,
代碼實作:
非遞回版本
bool _Insert( const T& key)
{
//如果樹中已存在key,則回傳false
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
//遍歷搜索樹
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key<key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else
{
return false;
}
}
//創建節點,這里用了匿名物件
cur = new Node(key);
//判斷cur節點要連接到parent的哪個節點
if (parent->_key > key)
{
parent->_left = cur;
}
else if (parent->_key < key)
{
parent->_right = cur;
}
return true;
}遞回的版本:
//注意root是指標的參考
bool _InsertR(Node* &root, const T& key)
{
//如果節點為空,則創建節點給給它
if (root == nullptr)
{
root = new Node(key);
}
if (root->_key > key)
{
_InsertR(root->_left, key);
}
else if(root->_key<key)
{
_InsertR(root->_right, key);
}
else {
return false;
}
return true;
}
bool InsertR(const T& key)
{
return _InsertR(_root, key);
}_Insert是在private里面的,而Insert是public里的,
查找
找到了就回傳該節點的地址,找不到就回傳空,
Node* find(const T& key)
{
if (_root == nullptr)
return nullptr;
Node* cur = _root;
while (cur)
{
if (cur->_key > key)
{
cur = cur->_left;
}
else if (cur->_key < key)
{
cur = cur->_right;
}
else {
return cur;
}
}
return nullptr;
}
洗掉
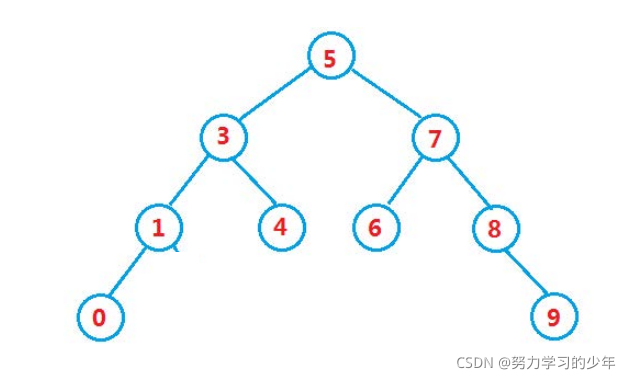
當我們要洗掉搜索樹中某個節點的時候,洗掉后的樹的結構也需要保持著搜索的性質,所以洗掉有有以下4種情況、
- 要洗掉的節點無孩子節點,例如 0 4 6 9
只要我們找到該值,直接洗掉掉就行,
- 要洗掉的節點有左孩子的節點,例如 1
找到該值,先讓該值的父親節點區連接它的左孩子節點,然后再洗掉掉,父親節點要連接該值的左孩子節點時,需要判斷孩子節點是連接在父親的左邊還是右邊
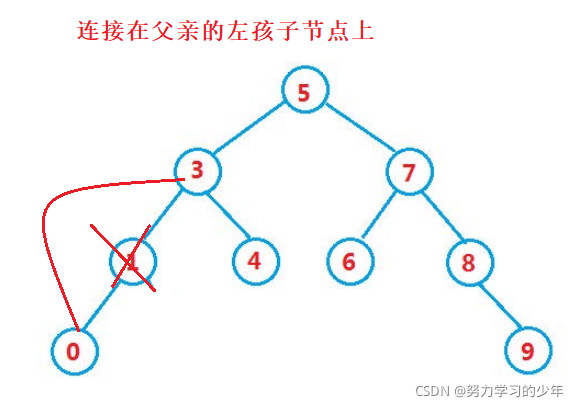
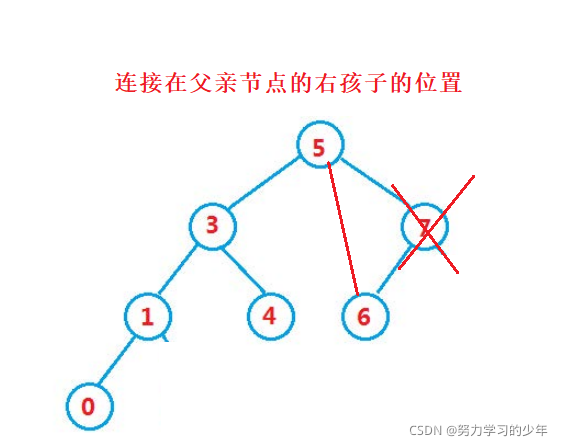
- 要洗掉的節點有右孩子的節點,例如 8
找到該值,先讓該值的父親節點區連接它的右孩子節點,然后再洗掉掉,父親節點要連接該值的右孩子節點時,需要判斷孩子節點是連接在父親的左邊還是右邊
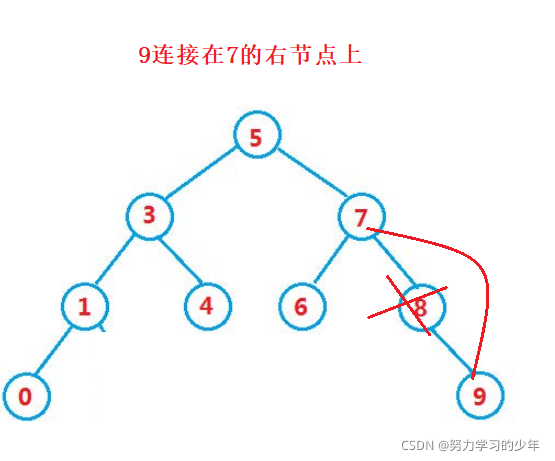
- 要洗掉的節點有左右孩子的節點,例如 3 5 7
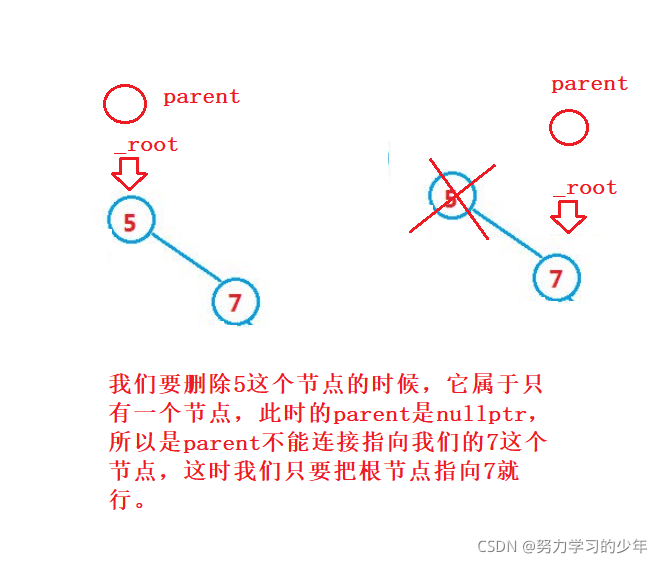
如果我們直接洗掉這樣的節點時,就會讓使它的左右子樹沒有根節點,所以我們怎樣洗掉這樣的節點,并保持搜索二叉樹的特性?
我們可以找出該值左子樹最大的節點或者右子樹最小的節點,去替換根節點,然后將替換的節點給洗掉掉,(左子樹最大的節點或者右子樹最小的節點去替換的根節點依舊可以保持著搜索二叉樹的性質),
洗掉5這個資料的程序;,找出左子樹最大的值,也就是左子樹最右的值,替換到根節點,然后直接將 替換的節點洗掉即可,
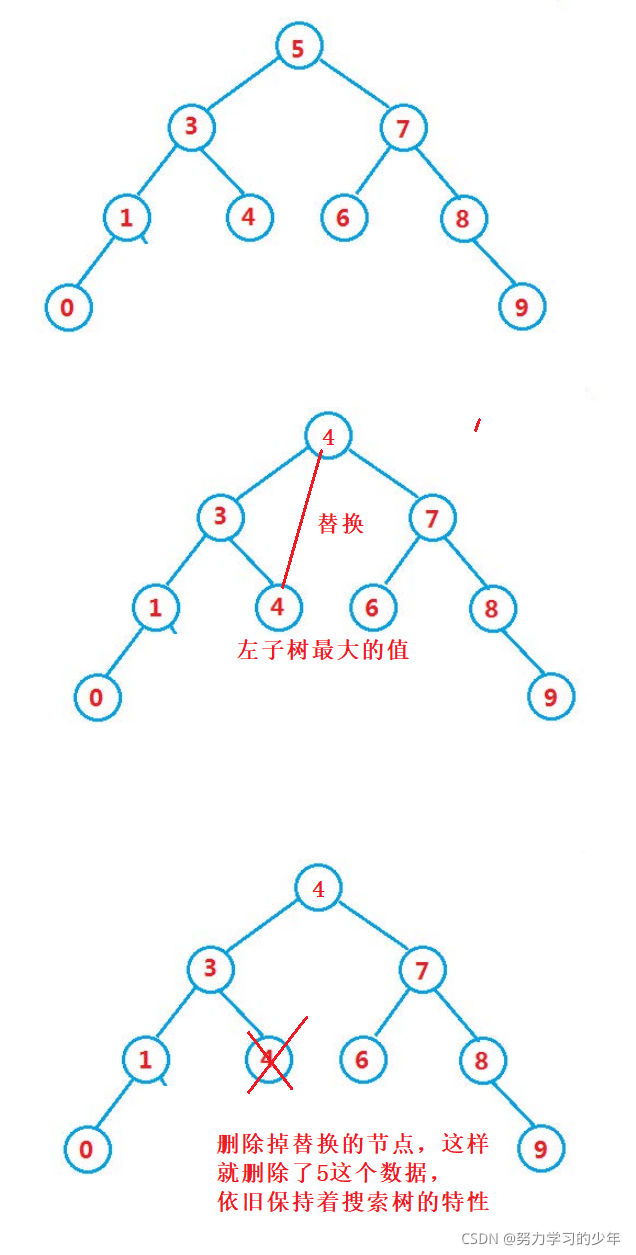
洗掉3的程序,找出左子樹最大的值,也就是左子樹最右的值,
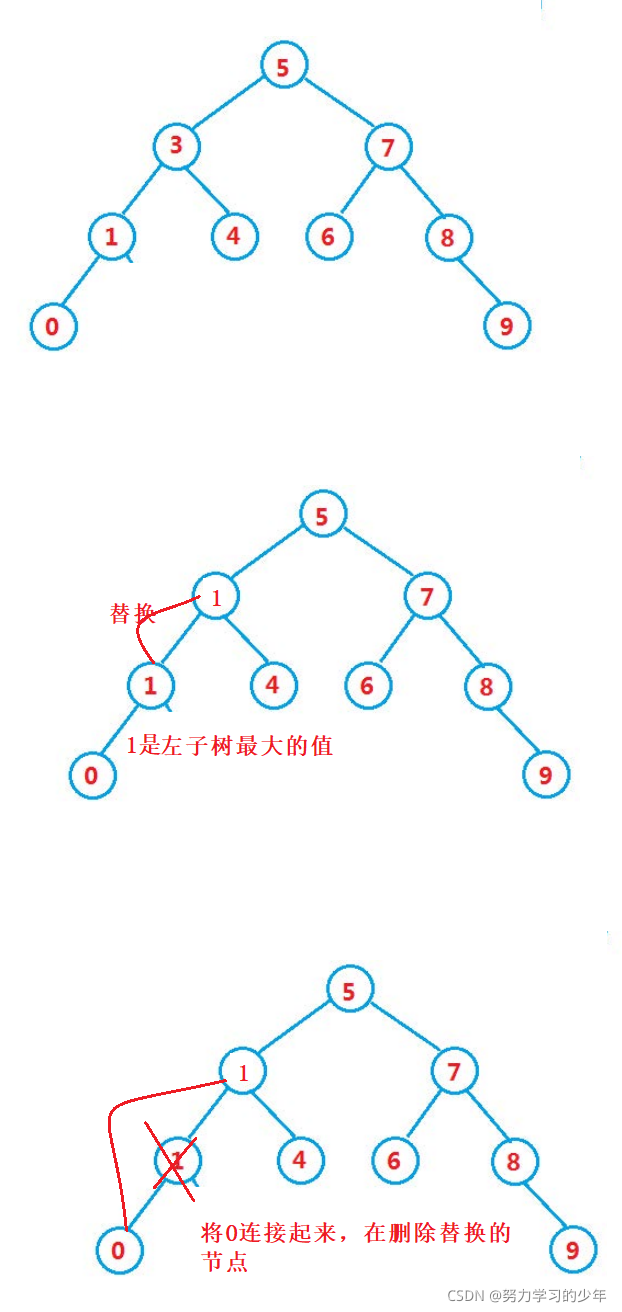
代碼:
bool _erase(const T key)
{
if (_root == nullptr)
return false;
//找出key的節點
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
}
else {
break;
}
}
//第一種:刪掉的是葉子節點
//第二種:刪掉只有一個孩子的節點
//第三種:刪掉的是有兩個孩子的節點
//洗掉只有右孩子的節點
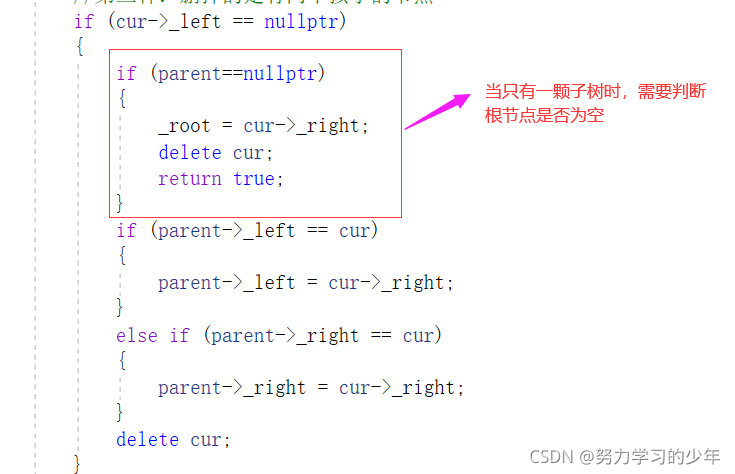
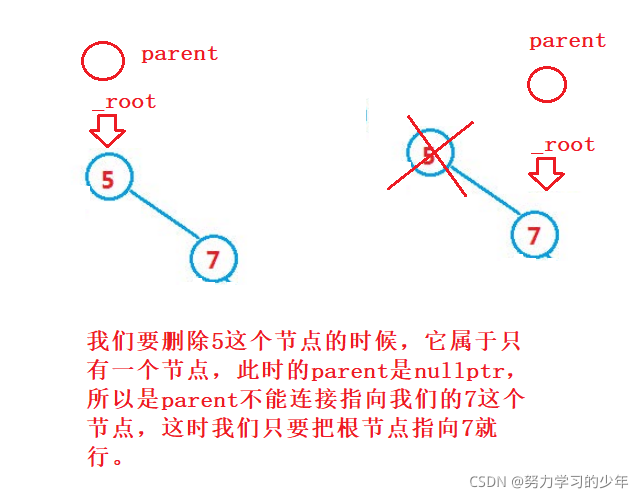
if (cur->_left == nullptr)
{
if (parent==nullptr)
{
_root = cur->_right;
delete cur;
return true;
}
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
else if (parent->_right == cur)
{
parent->_right = cur->_right;
}
delete cur;
}
//洗掉只有左孩子的節點
else if (cur->_right == nullptr)
{
if (parent == nullptr)
{
_root = cur->_left;
delete cur;
return true;
}
if (parent->_left == cur)
{
parent->_left = cur->_left;
}
else if (parent->_right == cur)
{
parent->_right = cur->_left;
}
delete cur;
}
//洗掉有左右孩子的節點
else
{
//第三種情況
Node* leftmax = cur->_left;
Node* leftmaxparent = cur;//左子樹最大節點
//找出左子樹最大的節點
while (leftmax->_right)
{
leftmaxparent = leftmax;
leftmax = leftmax->_right;
}
//賦給根節點
cur->_key = leftmax->_key;
//洗掉節點
if (leftmaxparent->_left == leftmax)
{
leftmaxparent->_left = leftmax->_left;
}
else {
leftmaxparent->_right = leftmax->_left;
}
delete leftmax;
return true;
}
return false;
}
這段代碼的含義:
遞回版本:
bool _eraseR(Node* &root,const T key)
{
//查找key相對應的值
if (root == nullptr)
return false;
if (root->_key < key)
_eraseR(root->_right, key);
else if (root->_key > key)
_eraseR(root->_left, key);
else {
if (root->_left == nullptr)
{
Node* tmp = root;
root = root->_right;
delete tmp;
}
else if (root->_right == nullptr)
{
Node* tmp = root;
root = root->_left;
delete tmp;
}
else
{
//第三種情況
Node* leftmax = root->_left;
Node* leftmaxparent = root;
//找出左子樹最大的節點
while (leftmax->_right)
{
leftmaxparent = leftmax;
leftmax = leftmax->_right;
}
//賦給根節點
root->_key = leftmax->_key;
//洗掉節點
if (leftmaxparent->_left == leftmax)
{
leftmaxparent->_left = leftmax->_left;
}
else {
leftmaxparent->_right = leftmax->_left;
}
delete leftmax;
return true;
}
}
return false;
}
bool eraseR(const T& x)
{
return _eraseR(_root, x);
}_eraseR是private里面的,eraseR是public里面的,
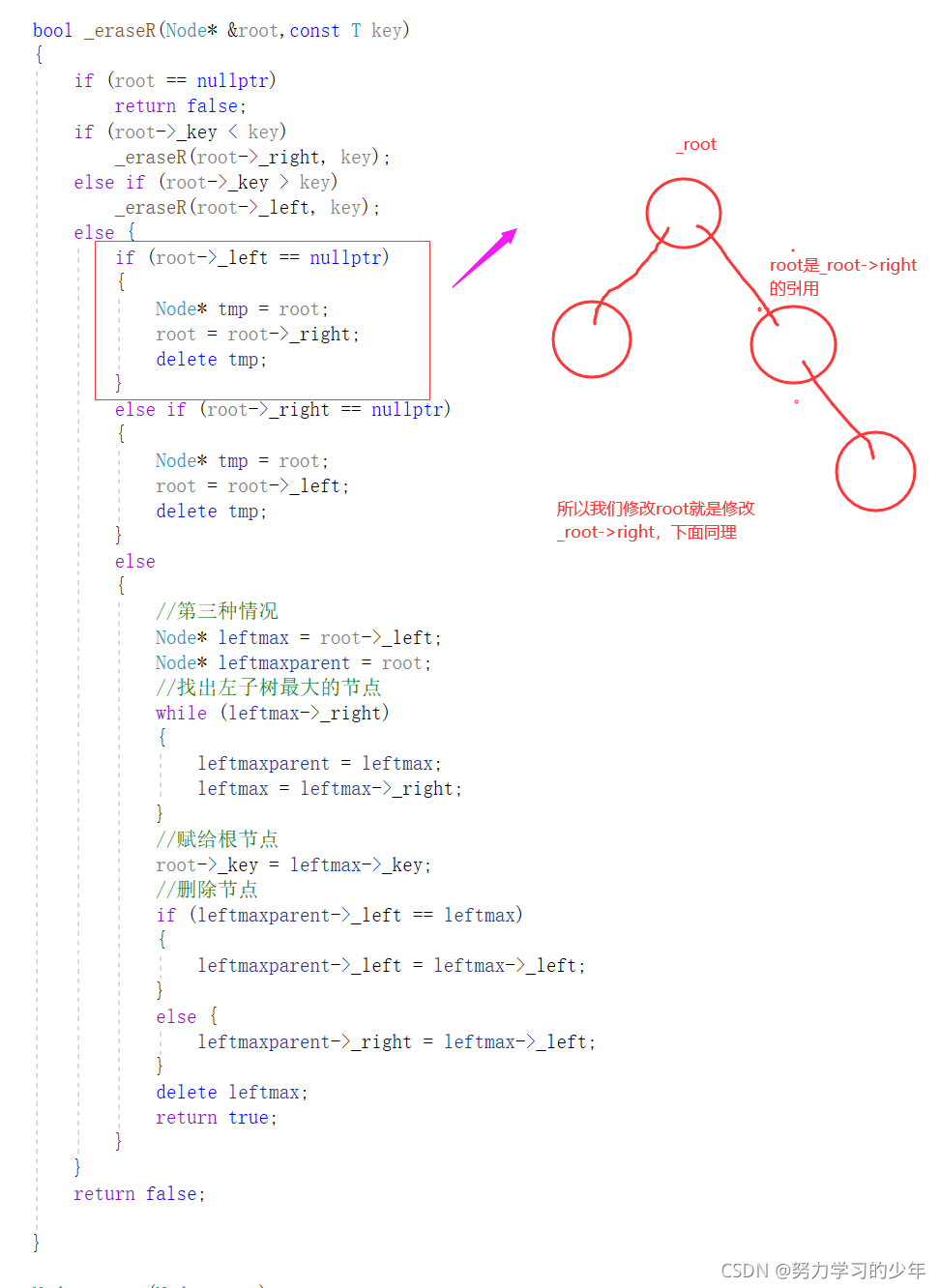
eraseR是對_eraseR的封裝,方便被呼叫,
拷貝建構式
Node* _copy(Node* root)
{
if (root == nullptr)
return nullptr;
Node* copyroot = new Node(root->_key);
copyroot->_left=_copy(root->_left);
copyroot->_right=_copy(root->_right);
return copyroot;
}
BinarySearchTree(BinarySearchTree<T>& t)
{
_root=_copy(t._root);
}
賦值多載函式

解構式:
void Destory(Node* root)
{
if (root == nullptr)
return;
Destory(root->_left);
Destory(root->_right);
delete root;
}
~BinarySearchTree()
{
Destory(_root);
_root = nullptr;
}2.4 二叉搜索樹的應用
1.K模型:K模型只有key作為關鍵碼,也就是定義樹的節點只需要存_key一個即可,關鍵碼即為搜索到的值,如上我們寫的搜索樹就是k模型,因為樹的節點就只有一個key可以存盤資料,

比如:我們要進學校的圖書館就需要刷我們的學生卡,通過磁感應將門打開,如下:

此時我們就需要先將學生的學號錄入到該門的管理系統,然后將資料建立起搜索樹,我們的學號在學校是唯一的,當我們刷卡的時候,就會去管理系統快速查找我們的學號,找到了門就開了,
k模型在實際應用中就是就是查找在不在的問題,
2.kv模型:每一個關鍵碼key都有一個對應的value值,也就是說樹的節點中有兩個值,一個是key,一個是value的值,我們通過key找到對應的節點,然后將相對應的value給映射出來,也就是說,我們增刪查改的時候也是按key進行插入或者洗掉,只是創建節點,增加了一個value值,

場景1:我們去網上買高鐵票,每張高鐵票的資訊都有與一個身份證號系結在一起的,當我們進高鐵站都需要刷身份證在搜索樹中查找有沒有你的身份證號,找到了,通過身份證號映射你的高鐵資訊,看看有沒有你的班次,門才是否可以被開,在這里_key是身份證,它是獨一無二的,_value是高鐵資訊,通過身份證將它給映射出來,
場景2:
英漢詞典就是英文與中文的對應關系,我們只需要查找有沒有該英文,找到了,就通過映射關系,將該英文的單詞的中文給映射出來,
用kv模型的搜索樹寫一個簡單的詞典:
int main()
{
BinarySearchTree<string ,string> v;
v._Insert("string","字串");
v._Insert("apple","蘋果");
v._Insert("automate", "n.自動化,v.使自動化");
v._Insert("voluntary", "adj.自愿的主動的,n.志愿者");
string s;
while (cin>>s)
{
struct TreeNode<string,string>* ret = v.find(s);
if (ret == nullptr)
{
cout << "沒有找到該單詞" << endl;
}
else
{
cout <<endl << " 中文:" << ret->_value << endl;
}
}
return 0;
}運行結果:

場景3:
統計水果次數,
如下
int main()
{
const string str[] = { "蘋果","西瓜","芒果","蘋果","西瓜","西瓜","西瓜","蘋果","芒果" };
BinarySearchTree<const string, int> count;
for (auto s : str)
{
auto ret = count.find(s);
if (ret == nullptr)
{
count._Insert(s, 1);
}
else {
ret->_value++;
}
}
count.Inorder();
return 0;
}輸出結果:

其中Inorder是將樹中所有的節點都給列印出來,代碼如下:
void _Inorder(Node* root)
{
if (root == nullptr)
return;
_Inorder(root->_left);
cout << root->_key << ":" << root->_value << endl;
_Inorder(root->_right);
}
void Inorder()
{
_Inorder(_root);
}_Inorder是private里面的,而Inorder是public里面的,
好了,今天分享的知識就到這里了,喜歡的小伙伴們,麻煩幫我點個三連,謝謝你們了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/344246.html
標籤:其他