一、概念
神經網路是已知自變數x和真實結果y,
神經網路的架構可以看做是黑箱測驗,但你不知道黑箱指代的F(x)到底是什么,不過沒關系,我們知道其中的引數(是隨機初始化的),即神經元之間做連接的那些個邊指代的權值,一個神經網路的引數是非常龐大的,自變數一般是非常多個,以至于引數也是有很多,且神經網路一般會有很多個隱藏層,所以一個神經網路是一個多元復合函式,
我們向黑箱中輸入你的自變數x后得到一個預測值y拔,和真實值y做對比,怎么比呢?答:通過損失函式G(y拔,y),
我們假設一個比較簡單的損失函式如下:
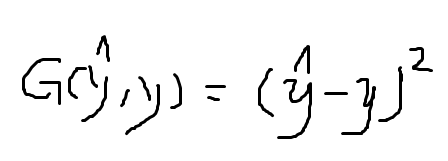
可見,我們希望的是預測值y拔與y相差不大,所以整個架構的優化目標是讓G(y拔,y)達到最小值,
二、人話版
我們以最簡單的一元函式舉例,
由于黑箱指代的F(x)是隨機初始化的,即F(x)的引數wi,bi是隨機初始化的,
因為我們這里假設神經網路是最簡單的一元函式y = wx + b,所以有一個引數w和b,
假設w和b被分別隨機初始化成5和1,即目前黑箱指代的F(x)=5x +1,
假設我們現在有自變數x = 2, 真實值y =14,
把x = 2傳入黑箱F(x)得到一個預測值y拔 = 5*2+1 = 11,
呼叫上面的損失函式G,得到一個損失loss = (11-14)2 = 9,
我們有x和y,優化w,所以神經網路指代的函式可看是F(w)=w*2 +b,
因為x=2是已知的,引數w是變化的,
這里引入梯度的帶概念,一個引數梯度是函式對這個引數的導數,
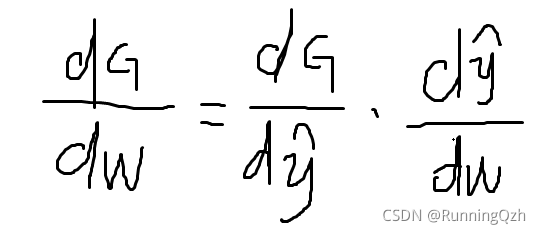
由此鏈式求導可以求得損失函式G對w的導數是(22-28)x2= -12
所以w的梯度r = -12.
引數更新一般是:引數=引數 - 學習率*梯度,我們假設學習率lr=0.1.
所以w = 5 - [0.1x(-12)] = 6.2,
可見,通過優化w,我們的w由之前的5變為了更新后的6.2,此時黑箱指代函式變為F(x)=6.2x +1
我們再來看一下現在的loss,傳入引數x=2,得到預測值y拔=13.4,
帶入損失函式G求得loss = (13.4-14)2 = 0.36,
可見 ,loss已經由剛才的9降低到0.36,
可見我們的引數更新是很有用的,當然我們這里只對w更新,b其實也要更新,但為了簡單舉例,咱們只考慮w,
question:
至于為什么引數更新公式是:引數=引數 - 學習率*梯度
為什么要減去梯度(導數)?
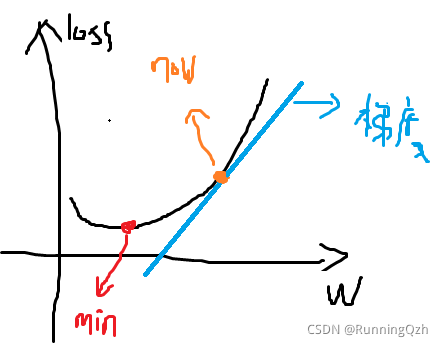
假設我們現在的引數w導致的損失loss在橙色點,
我們計算的loss對w的導數(梯度),我可以直觀的發現,w順著導數的方向減小一定的步長,才能夠離loss的最小值點更接近,
所以公式是用引數=引數 - 學習率*梯度,說白了就是為了更接近min,
我們這里只舉例最簡單的一元函式,實際上龐大的神經網路是一個多元復合函式,我們對一個引數w求梯度就是在求G對wi的偏導數,換湯不換藥~
over~我可真是是大聰明,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/344997.html
標籤:AI