作者
yuhuliu,騰訊研發工程師,關注存盤、大資料、云原生領域,
摘要
醫療資訊業務在高速發展程序中,形成了覆寫不同場景、不同用戶、不同渠道的幾十個業務,以及上千個服務,為了高效滿足用戶多樣化的需求,醫療技術團隊通過 TKE 上云,使用 Coding DevOps 平臺,以及云上可觀測技術,來提升研發效率、降低運營運維成本,本文介紹我們在上云程序中一些實踐和經驗,以及一些思考和選擇,
業務背景
- stage1: 醫療資訊主要包括了醫典、醫生、醫藥等核心業務,其中醫典主要提供醫療相關內容獲取、醫療知識科普傳遞;醫生滿足醫生和患者的互聯;醫藥服務了廣大藥企,在業務發展程序中我們原來基于 taf 平臺構建了大量后臺服務,完成了初期業務的快速搭建,由于業務數量較多,大量業務有多地域的述求,最終我們在 taf 平臺部署多個業務集群,這個時候發布、運維、問題排查純靠人工階段,效率較低,
業務上云
-
stage2: 隨著業務規模的急速擴張,傳統的開發、運維方式在敏捷、資源、效率方面對業務迭代形成較大的制約,隨著公司自研上云專案推進,擁抱云原生化,基于 K8s 來滿足業務對不同資源多樣化需求和彈性調度,基于現有成熟 devops 平臺來進行敏捷迭代,越來越成為業務正確的選擇,醫療后臺團隊開始了整體服務上云的遷移,
-
上云之前,還有幾個問題需要考慮
? 1:服務眾多,代碼如何管理
? 2:上云后怎么快速進行問題定位、排查
? 3:監控告警平臺如何選擇
? 4:基礎鏡像怎么選擇
關于服務代碼管理
使用 git 做代碼版本控制,按業務建立專案組,每個服務使用單獨的代碼倉庫,倉庫名使用同一命名規范,
關于問題排查
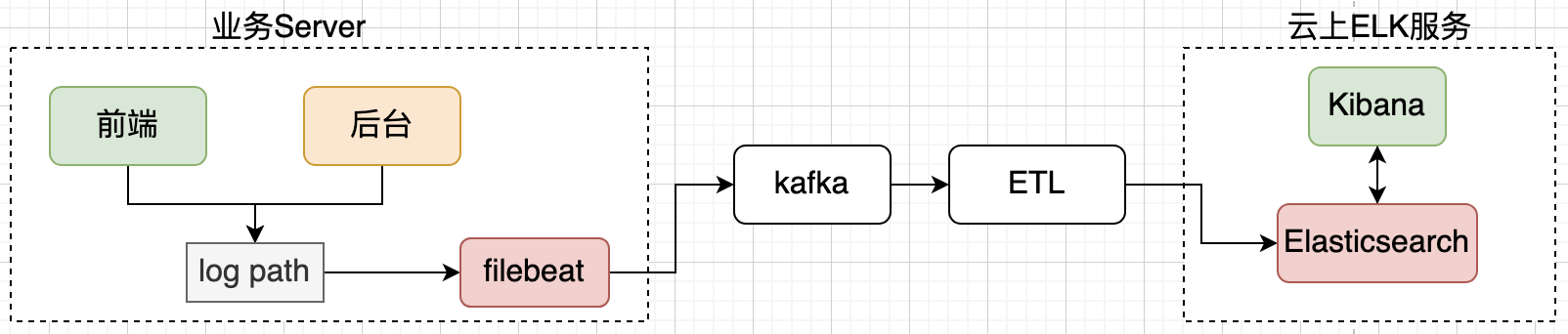
調研云上有成熟的 elk 服務,業務只需要把日志放到同一目錄,通過 filebeat 采集后,通過 ETL 邏輯可以把日志方便匯入 Elasticsearch,這樣的做法還有個優點就是可以同時支持前后端服務日志的采集,技術較為成熟,復用了組件能力,通過在請求中埋點加入 traceid,方便在全鏈路定位問題,
關于監控告警平臺
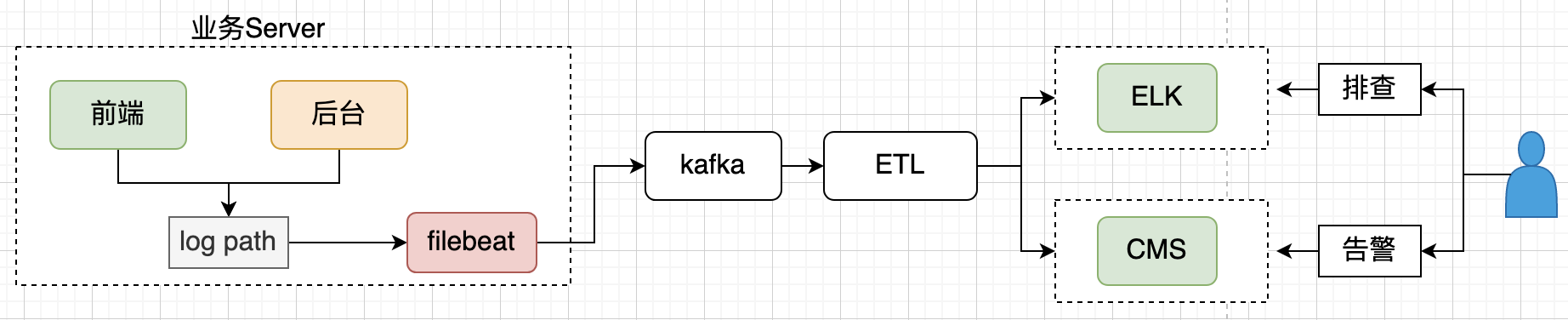
CSIG 提供了基于日志監控的 CMS 平臺,將業務日志匯入到 CMS 后,可以基于上報的日志配置監控和告警,監控維度、指標業務可以自己定義,我們采用了主調、被調、介面名等維度,呼叫量、耗時、失敗率等指標,滿足業務監控告警訴求,基于日志的監控可以復用同一條資料采集鏈路,系統架構統一簡潔,
關于基礎鏡像
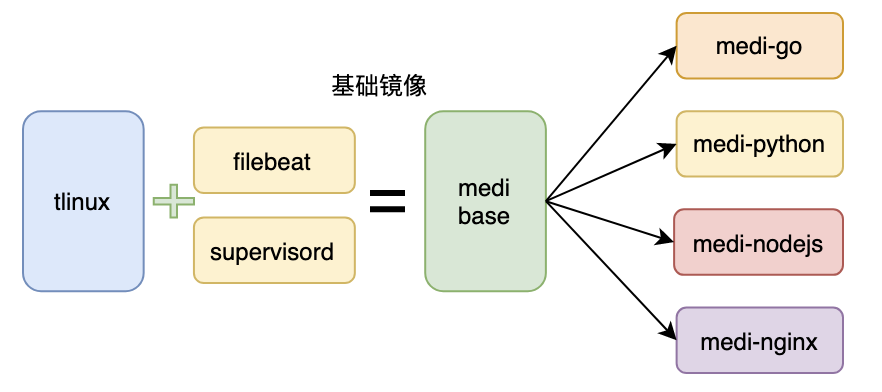
為了方便業務初期快速上云,以及統一服務啟動、資料采集上報,有必要對業務的基礎鏡像進行處理,預先建立對應目錄,提供腳本和工具,方便業務快速接入,這里我們提供了不同語言、版本的基礎鏡像,封裝了 supervisord 和 filebeat,通過 supervisord 來拉起 filebeat 和業務服務,
Devops
- stage2: 在上云程序中,也通過和質量同學逐步完善,將開發程序中原有人工操作的步驟 pipeline 化,來提高迭代效率,規范開發流程;通過單測和自動化撥測,提升服務穩定性,采用統一的流水線后,開發、部署效率從原來的小時級別降低到分鐘級別,
這里主要使用了 coding 平臺,為了區分不同環境,建立了開發、測驗、預發布、測驗四套不同流水線模板,還引入了合流機制來加入人工 code review 階段,
在合流階段:通過 MR HOOK,自動輪詢 code review 結果,確保代碼在 review 通過后才能進行下一步(不同團隊可能要求不一樣),

在 CI 階段:通過代碼質量分析,來提升代碼規范性,通過單元測驗,來保證服務質量,
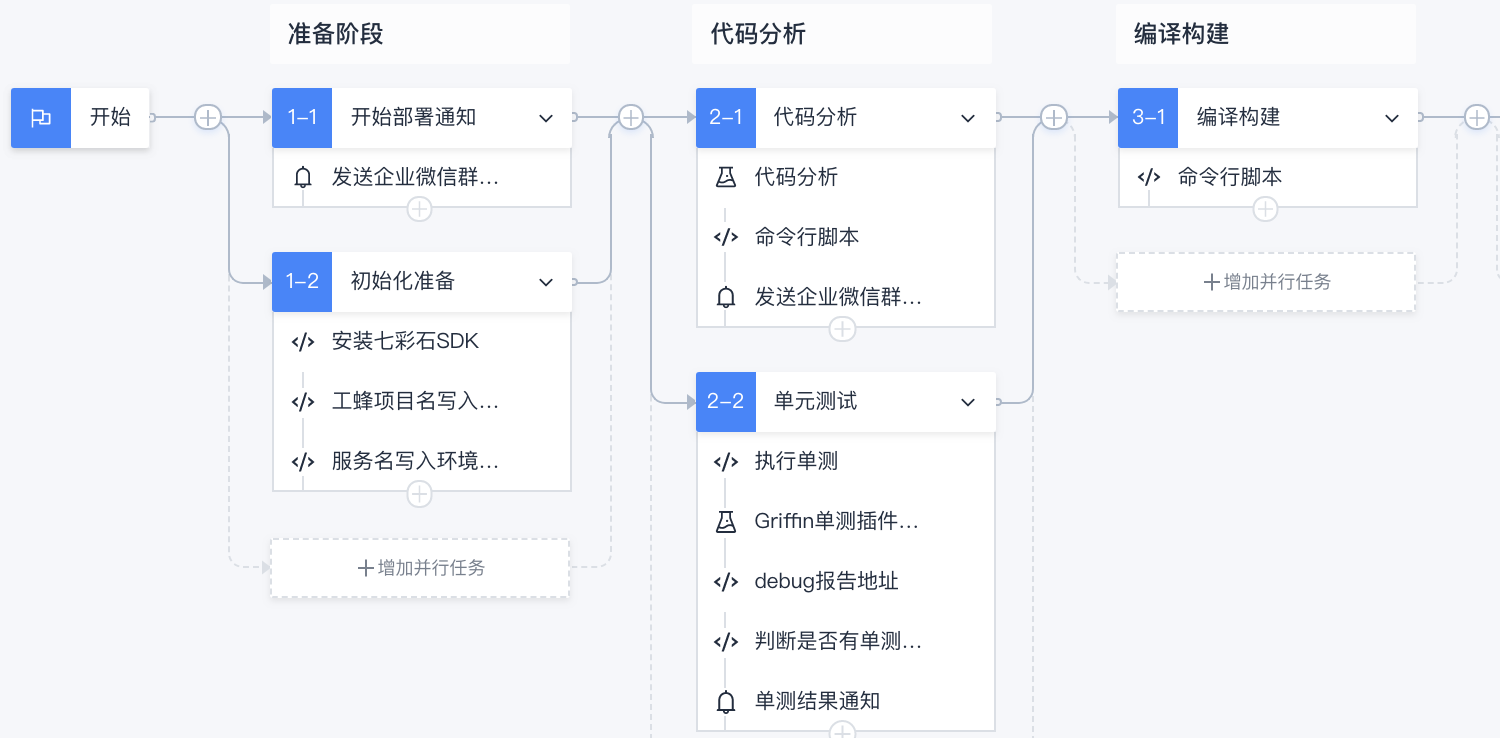
在 CD 階段:通過引入人工審批和自動化撥測,提高服務穩定性,

資源利用率提升
- stage3:在業務整體上云后,由于不少業務有多地域部署(廣州、南京、天津、香港)的述求,加上每個服務需要四套(開發、測驗、預發布、正式)不同的環境,上云后我們初步整理,一共有3000+不同 workload,由于不同業務訪問量具有很大不確定性,初期基本上按照理想狀態來配置資源,存在不少的浪費,
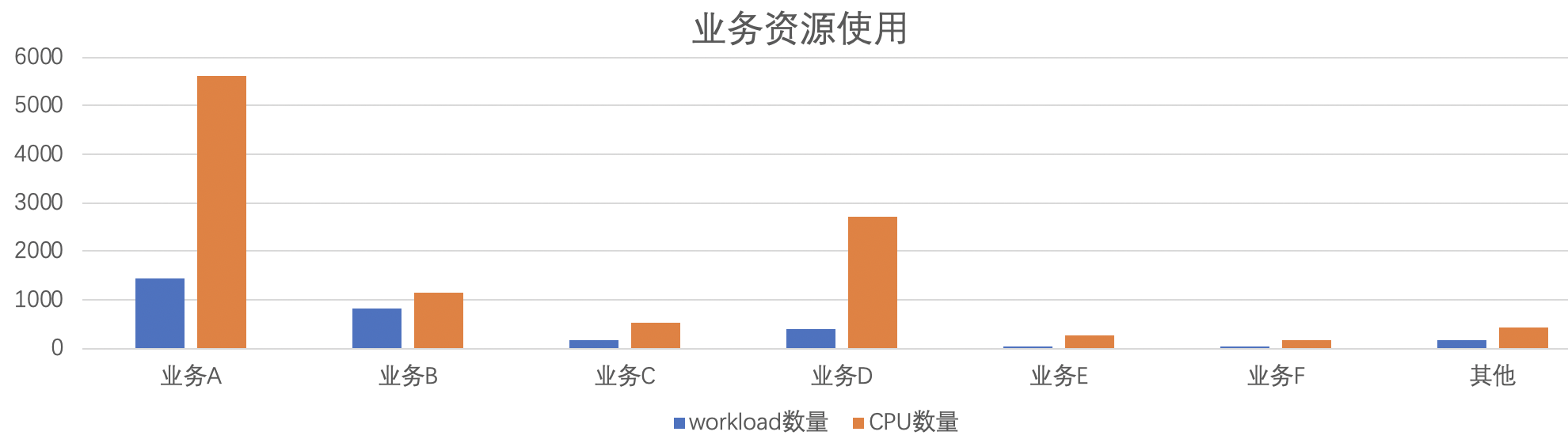
為了提高資源整體利用率,我們進行了一系列優化,大致遵循如下規范:

這里由于 HPA 會導致業務容器動態擴縮,在停止程序中如果原有流量還在訪問,或者啟動還未完成就匯入流量,會導致業務的失敗,因此需要需要預先開啟 TKE 上 preStop 以及就緒檢測等配置,
1:優雅停止,行程停止前等北極星、cl5 路由快取過期;
入口:tke->作業負載->具體業務->更新作業負載
如果使用的服務發現是 CL5,推薦 preStop70s,北極星配置 10s 足夠了
2:就緒、存活檢測,行程啟動完成后再調配流量;
入口:tke->作業負載->具體業務->更新作業負載,根據不同業務配置不同探測方式和時間間隔,
通過上面一系列調整優化,我們的資源利用率大幅提升,通過 TKE 上彈性升縮,在保證業務正常訪問同時,區域高峰訪問資源不足的問題基本解決,避免了資源浪費,也提升了服務穩定性;但多環境問題還是會導致存在一定損耗,
可觀測性技術
-
stage4:初期使用基于日志的方式來做(log/metric/tracing),滿足了業務快速上云、問題排查效率提升的初步述求,但隨著業務規模增長,愈加龐大的日志流占用了越來越多的資源,日志堆積在高峰期成為常態, CMS 告警可能和實際發生時已經間隔了半個小時,ELK的維護成本也急劇上升,云原生的可觀測技術已經成為必要,這里我們引入了 Coding 應用管理所推薦的可觀測技術方案,通過統一的 coding-sidecar 對業務資料進行采集:
?
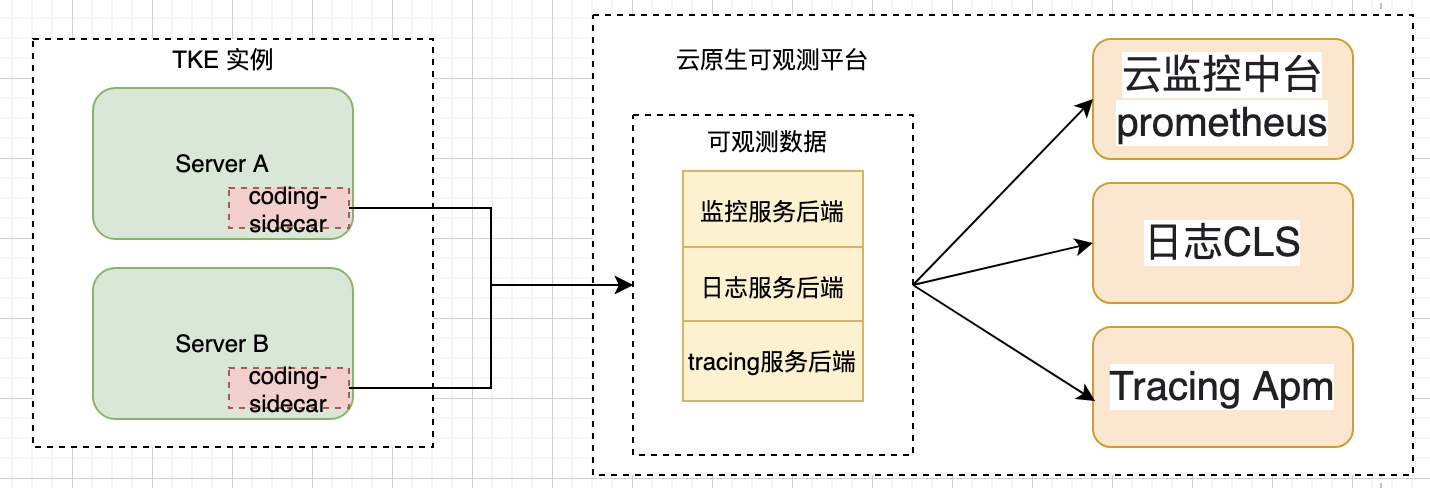
監控:云監控中臺
日志:CLS
Tracing:APM
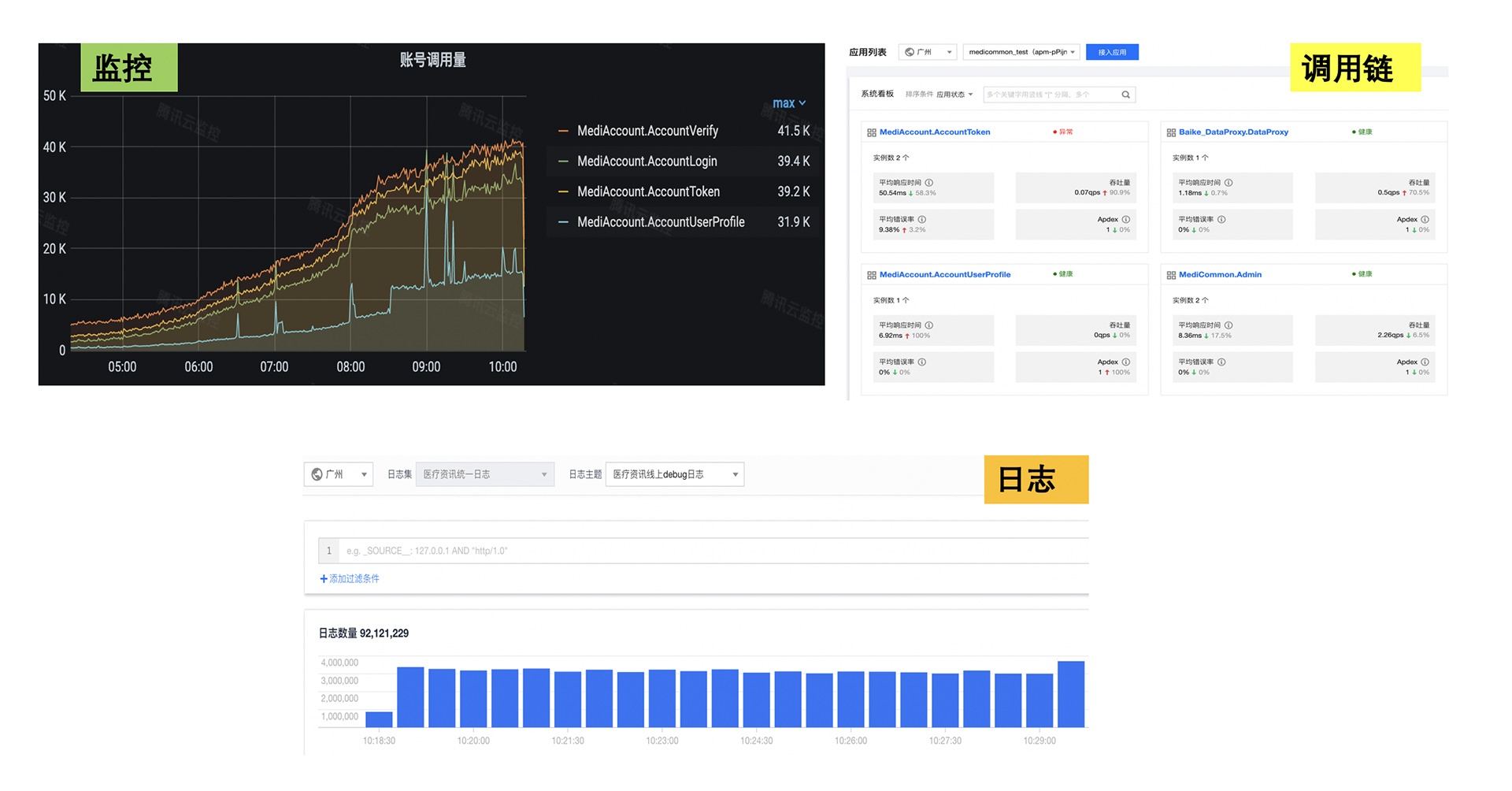
通過接入這些平臺的能力,我們的問題發現、定位、排查效率有了極大的提高,業務的運營維護成本較大降低,通過監控、和 tracing,也發現了不少系統潛在的問題,提高了服務質量,
結尾
最后,要感謝上云程序中全體開發同學的辛勤付出,以及各位研發 leader 的大力支持,
關于我們
更多關于云原生的案例和知識,可關注同名【騰訊云原生】公眾號~
福利:
①公眾號后臺回復【手冊】,可獲得《騰訊云原生路線圖手冊》&《騰訊云原生最佳實踐》~
②公眾號后臺回復【系列】,可獲得《15個系列100+篇超實用云原生原創干貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列,
【騰訊云原生】云說新品、云研新術、云游新活、云賞資訊,掃碼關注同名公眾號,及時獲取更多干貨!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345530.html
標籤:其他