VGG介紹:
由牛津大學著名研究所VGG提出,斬獲該年ImageNet競賽中Localization Task(定位任務)第一名和Classification Task(分類任務)第二名,
VGG網路的配置:(VGG-16是許多模型中的主干網路)
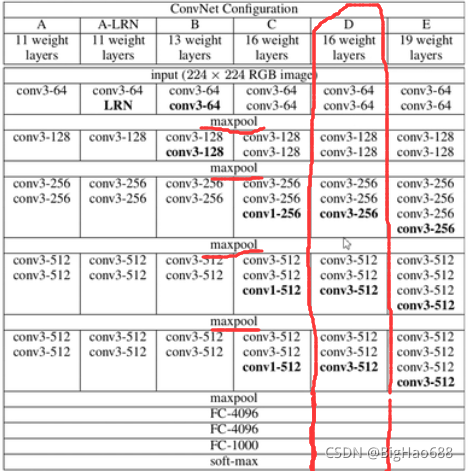
在原論文中,作者給了6個VGG網路的不同配置,并且嘗試了不同的深度(11、13、16、19層)以及是否采用LRN等,在實際使用程序中,我們一般都會采用D這個配置,即16層:13個卷積層以及最后3個全連接層,
VGG網路的亮點:
通過堆疊多個3*3的卷積核來代替大尺度卷積核(目的:減少所需引數),在原論文中提到,可以通過堆疊2個3*3的卷積核替代5*5卷積核(使得2個3*3的卷積核與5*5的卷積核擁有相同的感受野);堆疊3個3*3的卷積核替代7*7的卷積核(使得3個3*3的卷積核與7*7的卷積核擁有相同的感受野),

概念擴展-CNN感受野(receptive field):
在卷積神經網路中,決定某一層輸出結果中一個元素所對應的輸入層的區域大小,被稱作感受野,通俗的來說就是,輸出feature map 上的一個單元對應輸入層上的區域大小,
簡單例子:
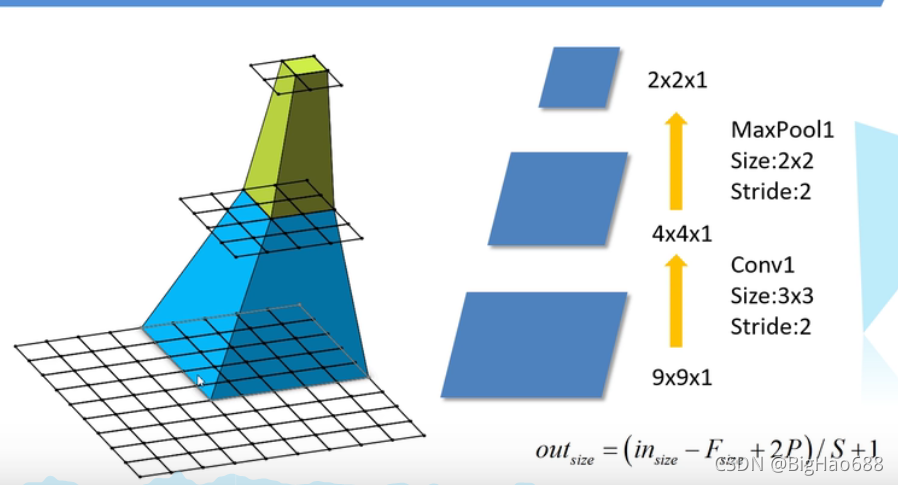
如上圖,最下層是一個9*9*1的特征矩陣 ,首先將其通過Conv1(大小為3*3,步距為1),通過計算公式,可以得到大小為4*4*1的特征矩陣;再將其通過最大池化下載量操作(大小為2*2,步距為2),得到一個2*2*1的大小,
接下來計算感受野:
Feature map(最后得到的特征圖):F=1
Pool1層:其輸出的是2*2大小,其輸入的是4*4大小,Ksize=2,Stride=2則F=(1-1)*2+2=2
Conv1:其輸出的是4*4大小,其輸入的是9*9大小,Ksize=3,Stride=2則F=(2-1)*2+3=5
VGG網路結構:
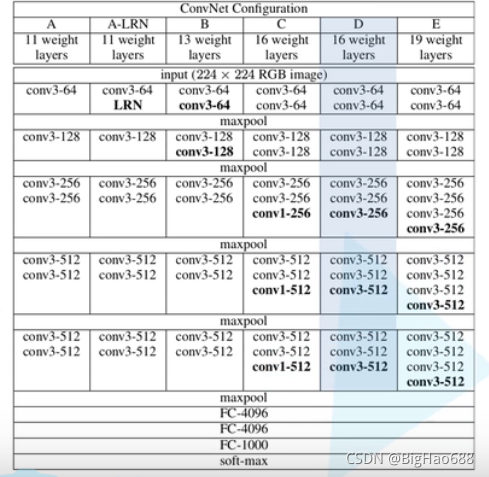
上面我們說過,我們常用的是D配置,即VGG-16,其程序為:①輸入224大小的RGB影像②通過兩層3*3的卷積核③通過maxpool(最大下載量)④通過兩層3*3的卷積核⑤通過maxpool⑥通過三層3*3的卷積核⑦通過maxpool⑧通過三層3*3的卷積核⑨通過maxpool⑩通過三層3*3的卷積核、通過maxpool、通過三個全連接層、通過soft-max處理,得到概率分布,
補充: (通過3*3的卷積核,輸入、輸出尺寸不變;通過maxpool,將特征矩陣的高和寬直接縮小一半),
(通過3*3的卷積核,輸入、輸出尺寸不變;通過maxpool,將特征矩陣的高和寬直接縮小一半),
結構圖:(通過D這個模型進行繪制的)
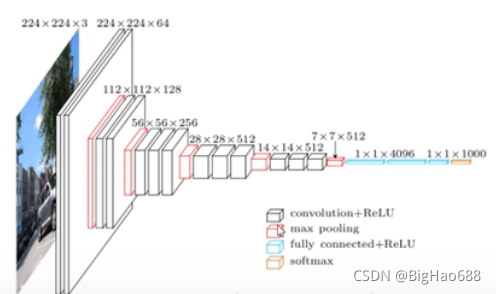
說明:白色矩形框:代表卷積和激活函式
紅色矩形框:代表最大池化下載量
藍色矩形框:全連接層和激活函式
橙色矩形框:softmax處理
結構程序:(配置表和結構圖一起觀察)
1、首先輸入一張224*224*3大小的影像,經過兩個3*3的卷積層之后,所得到的特征圖大小為224*224*64(尺寸大小不變,因為采用的是64個卷積核,所以深度也為64),
2、通過一個最大池化下載量層,得到的特征圖為112*112*64(大小縮小一半,不改變深度),
3、再通過兩個3*3*128的卷積層,得到的特征圖為112*112*128(深度變為128),
4、通過一個最大池化下載量層,得到的特征圖為56*56*128(大小縮小一半,不改變深度),
5、再通過三個3*3*256的卷積層,得到的特征圖為56*56*256(深度變為256),
6、通過一個最大池化下載量層,得到的特征圖為28*28*256(大小縮小一半,不改變深度),
7、再通過三個3*3*512的卷積層,得到的特征圖為28*28*512(深度變為512),
8、通過一個最大池化下載量層,得到的特征圖為14*14*512(大小縮小一半,不改變深度),
9、再通過三個3*3*512的卷積層,得到的特征圖為14*14*512(深度變為512),
10、通過一個最大池化下載量層,得到的特征圖為7*7*512(大小縮小一半,不改變深度),
11、再通過兩個為4000個節點的全連接層以及激活函式,得到1*1*4096向量
12、再通過一個為1000個節點的全連接層(因為1000個類別),注意不需要激活函式,得到1*1*1000向量,
13、最后將通過全連接層得到的一維向量,輸入到softmax激活函式,將預測結果轉化為概率分布,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345582.html
標籤:其他