??【專欄:資料集整理】?? 之【有效拒絕假資料】
👋 Follow me 👋,一起學更多有趣 AI、沖沖沖 🚀 🚀
文章目錄
- 🥇 資料集介紹
- 🔴 基礎資訊
- 🔵 WenetSpeech 簡介
- 🟣 WenetSpeech 收集程序
- 🟡 資料校驗
- 🔴 經典演算法對比
- 📘 下載正確打開方式
- 🟧 下載主頁
- 🟨 填寫郵箱資訊
- 🟦 提交成功界面如下
- 🟧 很快郵箱收到下載方式說明
- 🟨 開始下載
- 📙 致敬大佬
🥇 資料集介紹

🔴 基礎資訊
西北工業大學音頻語音和語言處理研究組(ASLP Lab)、出門問問、希爾貝殼聯合發布1萬小時多領域中文語音識別資料集 WenetSpeech
- 對應論文 :https://arxiv.org/pdf/2110.03370.pdf
- 官方主頁:https://wenet-e2e.github.io/WenetSpeech/
- 該部分介紹主要參考該文:
https://mp.weixin.qq.com/s/lR22WmI5G2mPSuloZUcWVA - 追求排版體驗的同學,可自行復制跳轉原文【上面鏈接】進行查閱

🔵 WenetSpeech 簡介
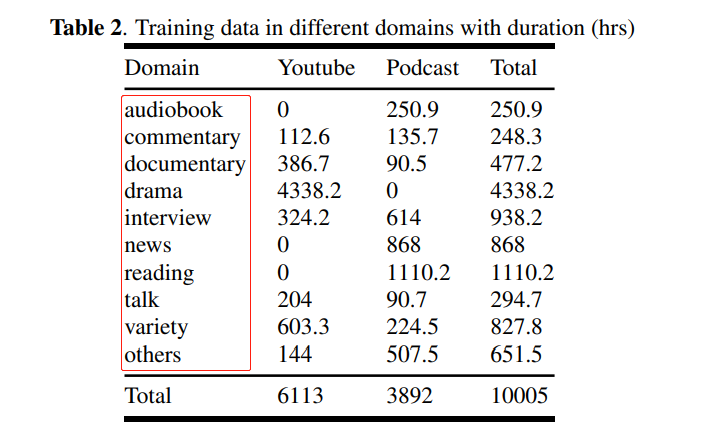
??WenetSpeech 除了含有 10000+ 小時的高質量標注資料之外,還包括2400+ 小時弱標注資料和 22400+ 小時的總音頻,覆寫各種互聯網音視頻、噪聲背景條件、講話方式,來源領域包括有聲書、解說、紀錄片、電視劇、訪談、新聞、朗讀、演講、綜藝和其他等10大場景,領域詳細統計資料如下圖所示,
🟣 WenetSpeech 收集程序
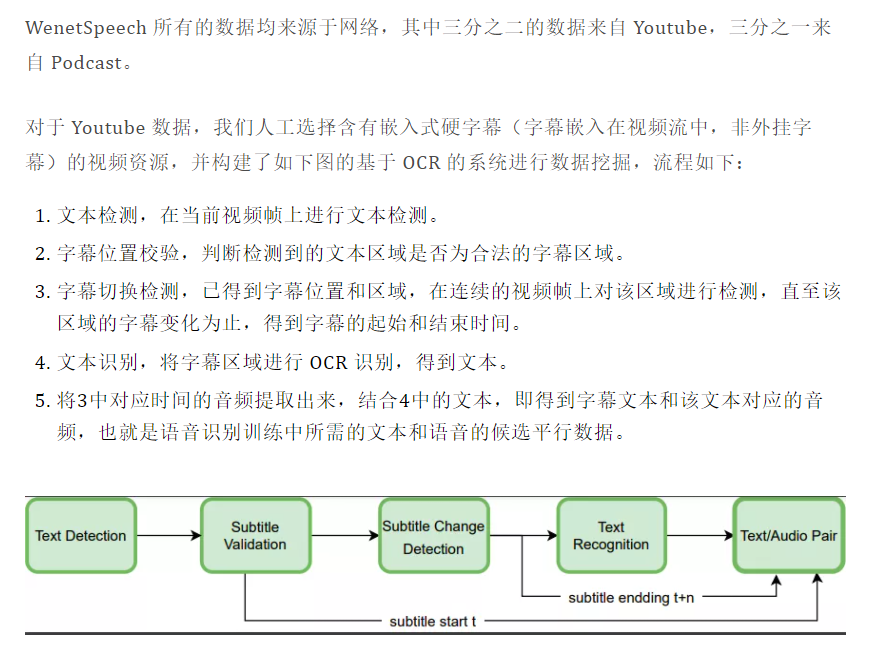
??下圖中給出該 OCR 系統在不同場景下的幾個典型示例,圖中綠色的框為檢測到的所有文字區域,紅色的框為判定為字幕的文字區域,紅色框上方的文本為 OCR 的識別結果, 可以看到,該系統正確的判定了字幕區域,并準確的識別了字幕文本,同時經過我們測驗,發現該系統也可以準確判定字幕的起始和結束時間,

🟡 資料校驗
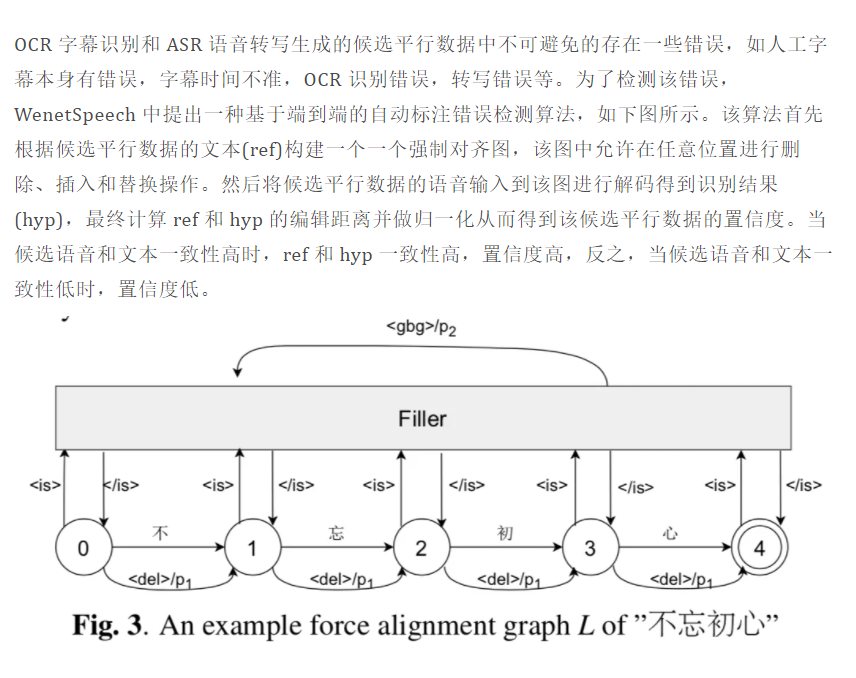
??WenetSpeech 中選取置信度>=95%的資料作為高質量標注資料,選取置信度在0.6和0.95之間的資料作為弱監督資料,
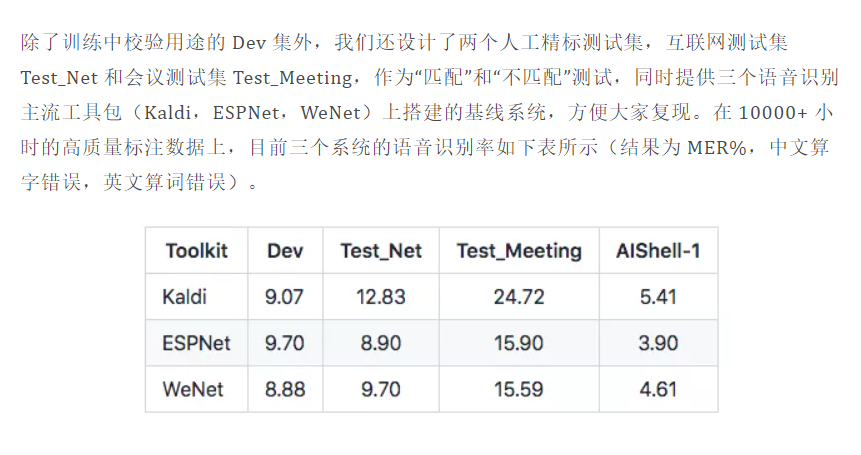
🔴 經典演算法對比
📘 下載正確打開方式
該下載方式記錄時間:【2021-10-22記錄】
🟧 下載主頁
- https://wenet-e2e.github.io/WenetSpeech/

🟨 填寫郵箱資訊
🟦 提交成功界面如下

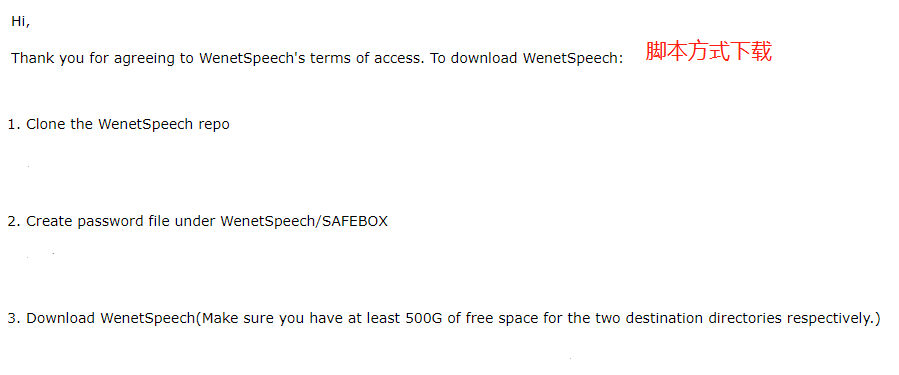
🟧 很快郵箱收到下載方式說明
讓準備,500G 磁盤空間

🟨 開始下載
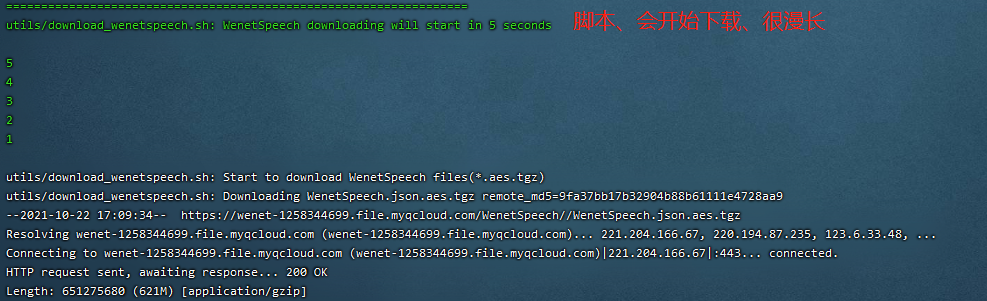
根據網速情況,下載大致需要 大半天吧
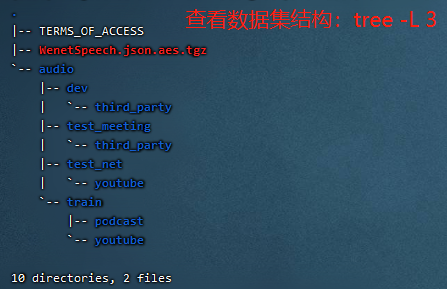
du -sh資料集壓縮包大小:309Gtree -L 3查看資料集結構如下
📙 致敬大佬
WenetSpeech 是目前最大的開源普通話語音語料庫,適用于產業級語音識別的研究
全人類的人工智能事業大概就是這樣一步一步向前推動的吧


語音資料集總結博文如下
- 👋 語音資料集下載地址匯總| 免費的漢語說話人識別語料庫 | Common Voice 資料集 | 下載總結
近期經典有趣博文推薦
- ?? 高效入門目標檢測之YOLO實戰系列精選——【1024專刊】
- ?? 初識超分重建——如何讓女神更清晰,我的白月光【ICCV, 2021 超分重建之 BSRGAN】
- ?? 多階段漸進式影像恢復 | 去雨、去噪、去模糊 | 有效教程(附原始碼)|【??CVPR 2021??】
- ?? 【深度學習入門專案】給學妹換個風格【??CVPR 2020 風格遷移之NICE-GAN??】
- ?? 【深度學習入門專案】將學妹的照片轉換為鉛筆素描 |【??Pattern Recognition 2020 之 U Square Net??】

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345598.html
標籤:其他
上一篇:OpenCV-Python實戰(15)——面部特征點檢測詳解(僅需5行代碼學會3種面部特征點檢測方法)
下一篇:HCIA: