神經網路設計程序
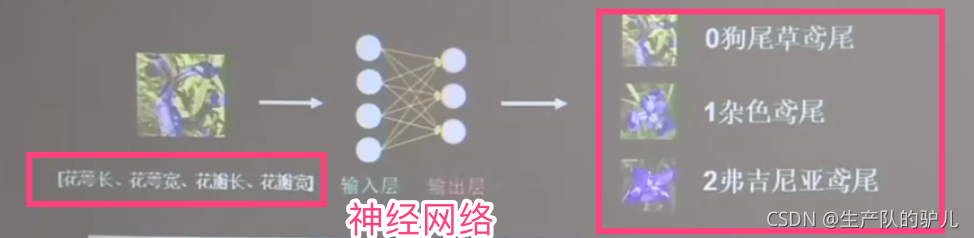
案例: 鳶尾花分類
鳶尾花三種類別:
三種: 狗尾巴 雜草 小腹肌
 通過搭建一個神經網路來對鳶尾花進行分類
通過搭建一個神經網路來對鳶尾花進行分類
收集花朵 的特征值: 四種
花萼長
花萼寬
花瓣長
花瓣寬

以及:
三種輸出結果
狗尾巴 雜草 小腹肌
操作方法:
1.收集資料集,花的特征,以及這些花是什么品種,即 標簽,
2.將資料集 訓練模型,通過反向傳播訓練,
3.將不知道品種的花的特征輸入模型,自動出來花的種類,
神經網路模型:
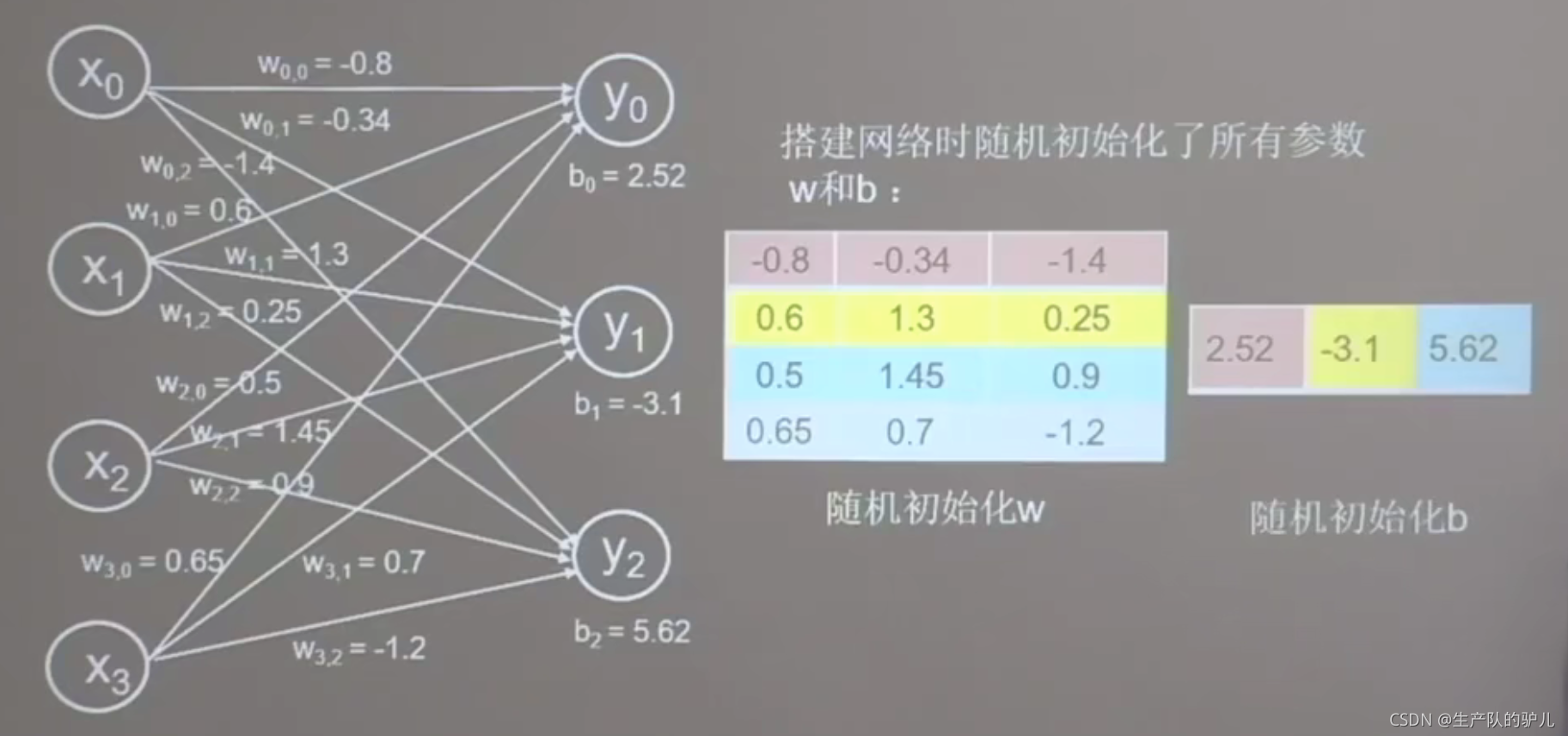
輸入神經元 4個,輸出神經元3個
4個是花的四個特征
3個是三種花
連接關系是12個,全連接,也成為全連接網路,
權重w和偏置b也會被隨機分配初始化為0-1的數,
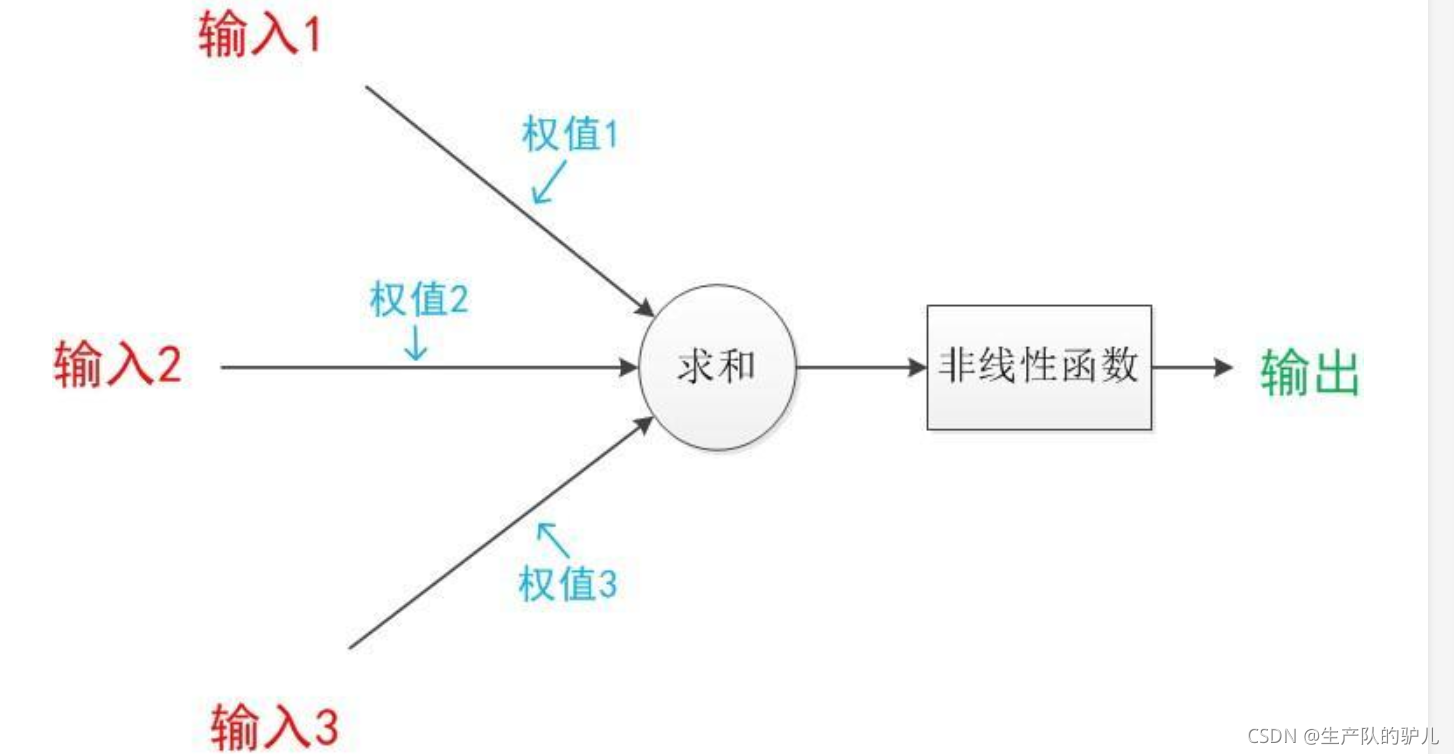
神經網路是由多個神經元組成的,
單個神經元結構圖:
如下圖,注意非線性函式也叫激活函式,
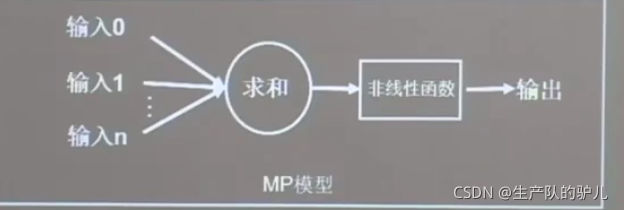
前面的輸入到求和部分,細分為下圖

前向傳播:
代入訓練集 的 x ,到模型里面,輸出y的程序,稱之為 前向傳播,
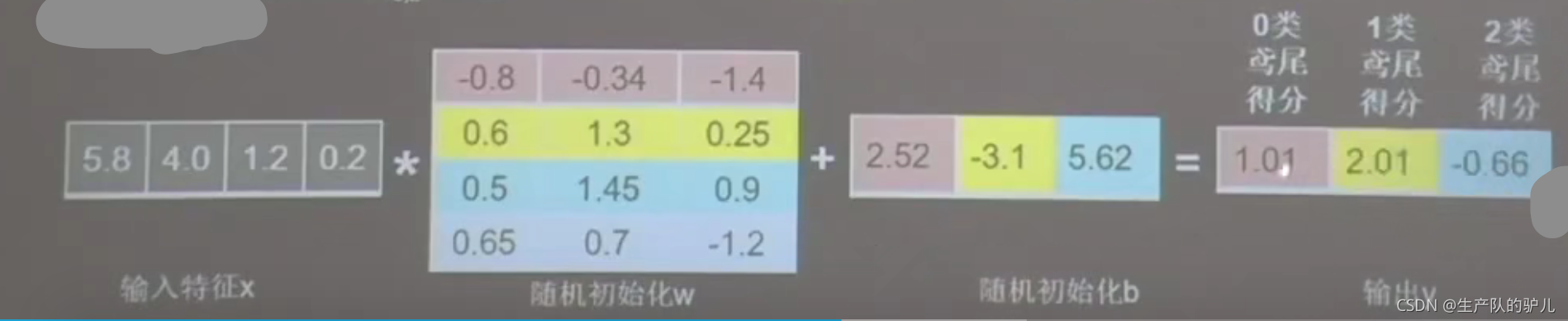
最初的引數w和b是隨機產生的,所以,剛開始模型輸出的結果很可能不對,是隨便的,
但是要將模型輸出的結果和真實值進行做差,平方求和,從而得到損失函式,
損失函式:
當損失函式最小,出現的w和b即為最優解,

損失函式有多個方式: 均方誤差是最常見的,
因此,目的變成了 尋找一組w和b,讓損失函式最小,
最常見的方法,即為 梯度下降法,
梯度下降法:

梯度下降法 還涉及 一個新的概念 叫做 學習率:
公式如下
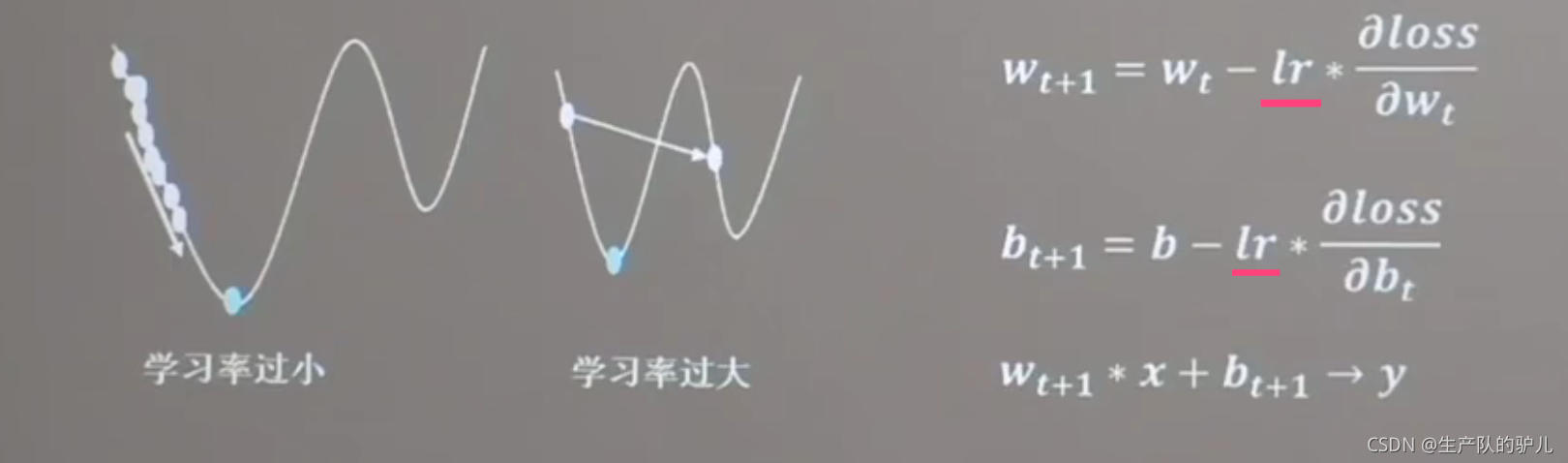
如果梯度下降比作,是從半山腰往下走的話,
學習率:就是下山的步幅長度,

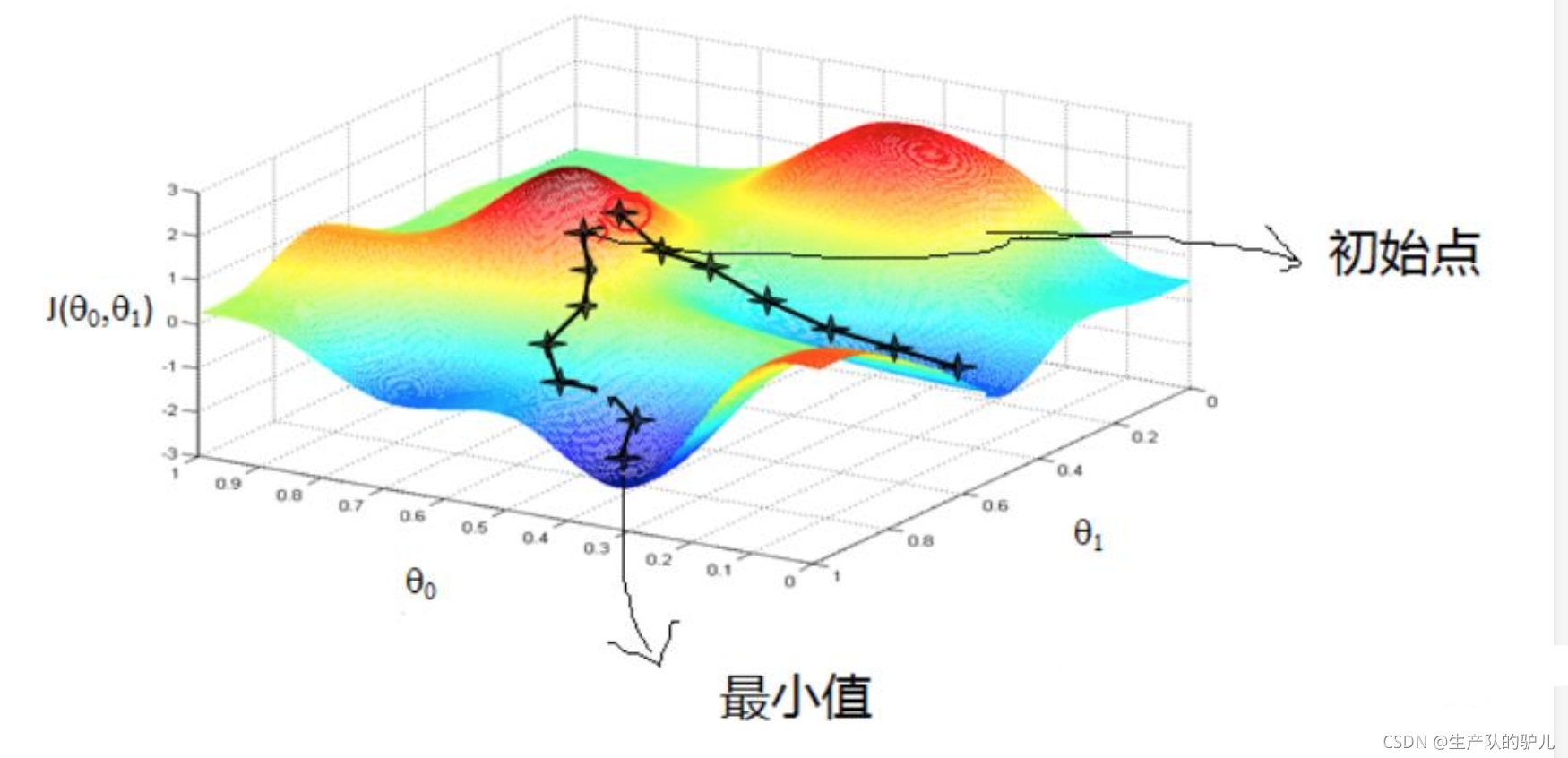
下面是一個經典的梯度下降示意圖
獲取資料代碼
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
# .data回傳iris資料集所有輸入特征
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# .target回傳iris資料集所有標簽
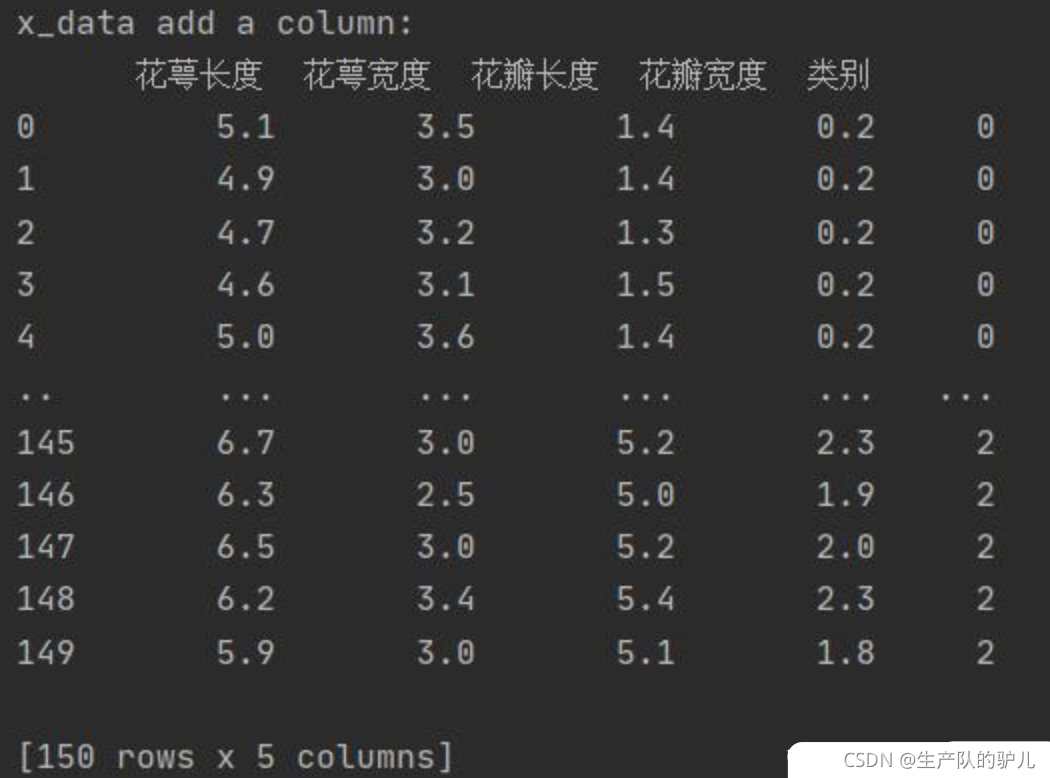
# 為表格增加行索引(左側)和列標簽(上方)
x_data = DataFrame(x_data, columns=['花萼長度', '花萼寬度', '花瓣長度', '花瓣寬度'])
# 設定列名對齊
pd.set_option('display.unicode.east_asian_width', True)
# 新加一列,列標簽為‘類別’,資料為y_data
x_data['類別'] = y_data
劃分 訓練集 和 測驗集
訓練集 訓練模型
測驗集 驗證模型
一共150行資料:其中75%作為訓練集,即120行;25%作為測驗集,即后30行,
注意這里使用了seed隨機種子函式,目的是為了在打亂x和y的同時,采用相同的亂數可以
保證其仍然是一一對應的關系,
之所以采用隨機,是因為 模仿人的大腦,這里人在學習如何辨識花朵種類的時候,輸入的也是無規律的資料,
# 匯入所需模塊
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 匯入資料,分別為輸入特征和標簽
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 隨機打亂資料(因為原始資料是順序的,順序不打亂會影響準確率)
# seed: 亂數種子,是一個整數,當設定之后,每次生成的亂數都一樣(為方便教學,以保每位同學結果一致)
np.random.seed(16) # 使用相同的seed,保證輸入特征和標簽一一對應
np.random.shuffle(x_data)
np.random.seed(16)
np.random.shuffle(y_data)
tf.random.set_seed(16)
# 將打亂后的資料集分割為訓練集和測驗集,訓練集為前120行,測驗集為后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 轉換x的資料型別,否則后面矩陣相乘時會因資料型別不一致報錯
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# from_tensor_slices函式使輸入特征和標簽值一一對應,(把資料集分批次,每個批次batch組資料)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
batch
這里的bach
是為了訓練更高效,通常會把資料變成batch(包),例如,把32行資料為一個小包batch,
這里一共有120個資料,32個資料打包為一個,分別是32,32,32,24.
最后一個包只有24個資料,
另外batch的選擇引數,推薦,32,64,128等,選2的冪次方,
當然也可以選其他的數字,
tf.cast()是強制轉換資料型別的函式
搭建神經網路
這里使用seed是為了確定每次生成的亂數是相同的,方便教學,實際情況可以洗掉seed=1
# 生成神經網路的引數,4個輸入特征故,輸入層為4個輸入節點;因為3分類,故輸出層為3個神經元
# 用tf.Variable()標記引數可訓練
# 使用seed使每次生成的亂數相同(方便教學,使大家結果都一致,在現實使用時不寫seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))

設定超引數
# 學習率為0.1
lr = 0.1
# 回圈500輪
# 這里的epoch是在對所有的訓練資料,整體回圈500次
# 一個epoch就是把所有訓練資料丟進網路訓練一次
epoch = 500 # 這里的epoch是在對所有的訓練資料,整體回圈500次
# batch_size是將多少個資料,扔進網路訓練
batch_size = 10 # 是指扔進回圈網路訓練的資料是10個
train_loss_results = [] # 將每輪的loss記錄在此串列中,為后續畫loss曲線提供資料
test_acc = [] # 將每輪的acc記錄在此串列中,為后續畫acc曲線提供資料
loss_all = 0 # 每輪分4個step,loss_all記錄四個step生成的4個loss的和
小tips:
epoch,batch_size和iteration區分
epoch:
當一個完整的資料集通過了神經網路一次并且回傳了一次,這個程序稱為一個 epoch,
因為
在神經網路中傳遞完整的資料集一次是不夠的,而且我們需要將完整的資料集在同樣的神經網路中傳遞多次,
我們使用一個迭代程序即梯度下降,優化學習程序和圖示,
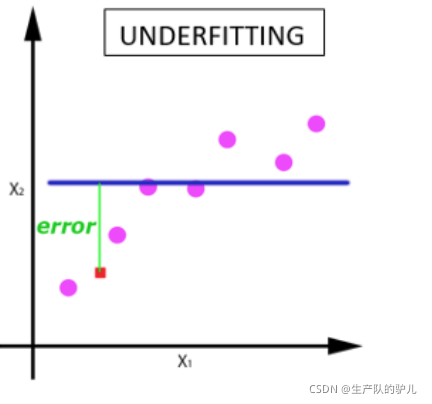
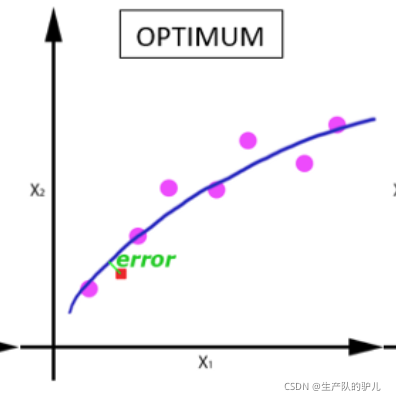
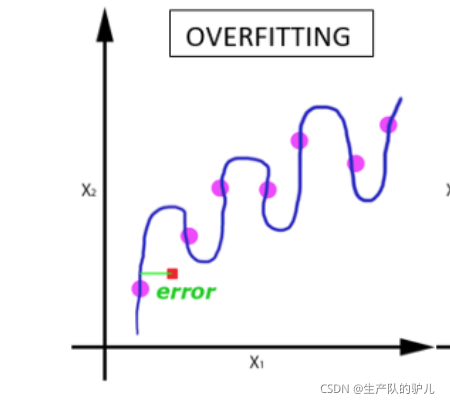
隨著 epoch 數量增加,神經網路中的權重的更新次數也增加,曲線從欠擬合變得過擬合,
batch_size
在不能將資料一次性通過神經網路的時候,就需要將資料集分成幾個 batch,
iteration 迭代次數
迭代是 batch 需要完成一個 epoch 的次數,
舉個例子:總資料100個,batch_size為10個打一個包,迭代次數iteration就為10次,
一個有 2000 個訓練樣本的資料集,將 2000 個樣本分成大小為 500 的 batch,那么完成一個 epoch 需要 4 個 iteration,
訓練模型
通過 兩層for回圈更新引數,進行梯度下降,反向傳播更新引數,
第一個for是針對將所有的資料,回圈多少次,
這里訓練集資料總共120個,epoch是500
意思是將這個120個資料,訓練500次,
第二個for回圈是針對包里面的資料進行回圈,然后對權重w和偏置b求導數,進行梯度下降,
主要是32個資料,求一次真實值和模型輸出之間的均方誤差,然后修正w和b
for epoch in range(epoch): # 資料集別的 回圈,每個epoch回圈一次資料集
for step, (x_train, y_train) in enumerate(train_db): # batch級別 的回圈
with tf.GradientTape() as tape: # with結構記錄梯度資訊
# 構建神經元
y = tf.matmul(x_train, w1) + b1 # 神經網路 乘加運算
y = tf.nn.softmax(y) # 使輸出y符合概率分布(此操作后與獨熱碼同量級,可相減求loss)
y_ = tf.one_hot(y_train, depth=3) # 將標簽值轉換為獨熱碼格式,方便計算loss和accuracy
loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方誤差損失函式mse = mean(sum(y-out)^2)
loss_all += loss.numpy() # 將每個step計算出的loss累加,為后續求loss平均值提供資料,這樣計算的loss更準確
損失函式,需要一個包回圈完畢之后,進行一次梯度下降的,同時更新一下w和b
32個資料一個包,一共120個資料,需要回圈4次,才能完成一次大回圈,
每進行1次32個資料的小回圈,根據loss更新一下w和b,同時記錄一下loss
# 根據損失函式計算梯度,進行梯度下降
grads = tape.gradient(loss, [w1, b1])
# 實作梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad
w1.assign_sub(lr * grads[0]) # 引數w1自更新
b1.assign_sub(lr * grads[1]) # 引數b自更新
# 每個epoch,列印loss資訊
這里loss_all是把每個小回圈的loss求和了,這里需要除以4,4個小回圈一個大回圈,來平均出,完成1次大回圈
所下降的loss值
print("Epoch {}, loss: {}".format(epoch, loss_all/4))
測驗部分,也要接在第一個for回圈內,驗證經過500次的整體大回圈的情況下,acc和loss的變化曲線
total_correct = 0
total_number = 0
for x_test, y_test in test_db:
# 使用更新后的引數進行訓練
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 回傳y中最大值的索引,即預測的分類
pred = tf.cast(pred, dtype=y_test.dtype) # 調整資料型別和標簽一致
# 如果預測值等于真實值,就輸出為1,否則為0
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
# 將每個batch的correct求和
correct = tf.reduce_sum(correct)
# 將batch中所有correct加起來求和
total_correct += int(correct)
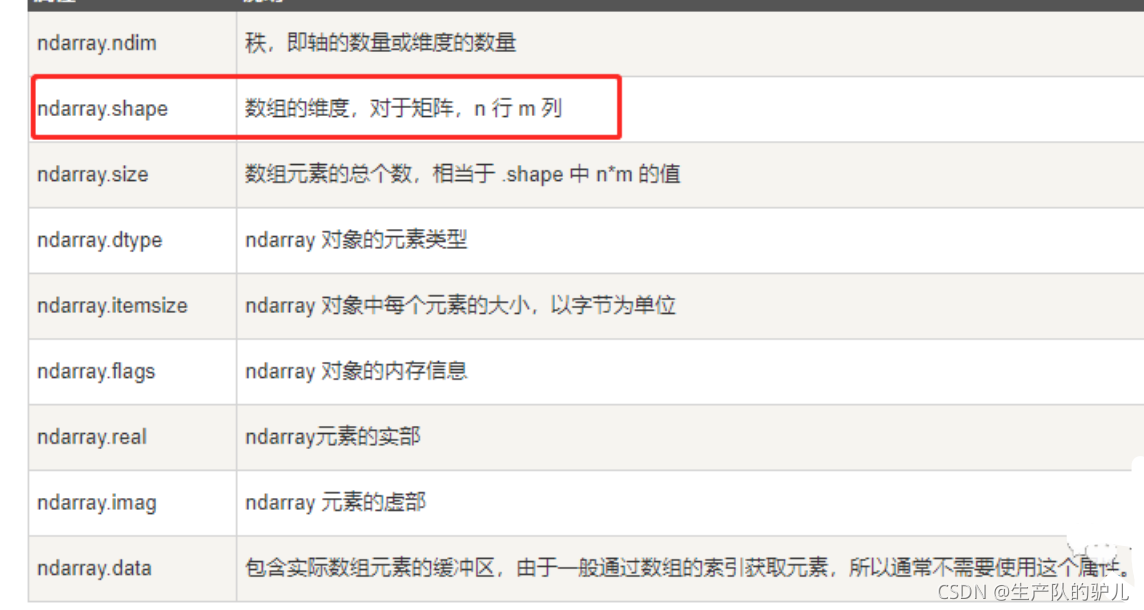
# total_number為測驗的總樣本數,也就是x_test的行數,shape[0]回傳變數的行數
total_number += x_test.shape[0]
# 總的準確率等于total_correct/total_number
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
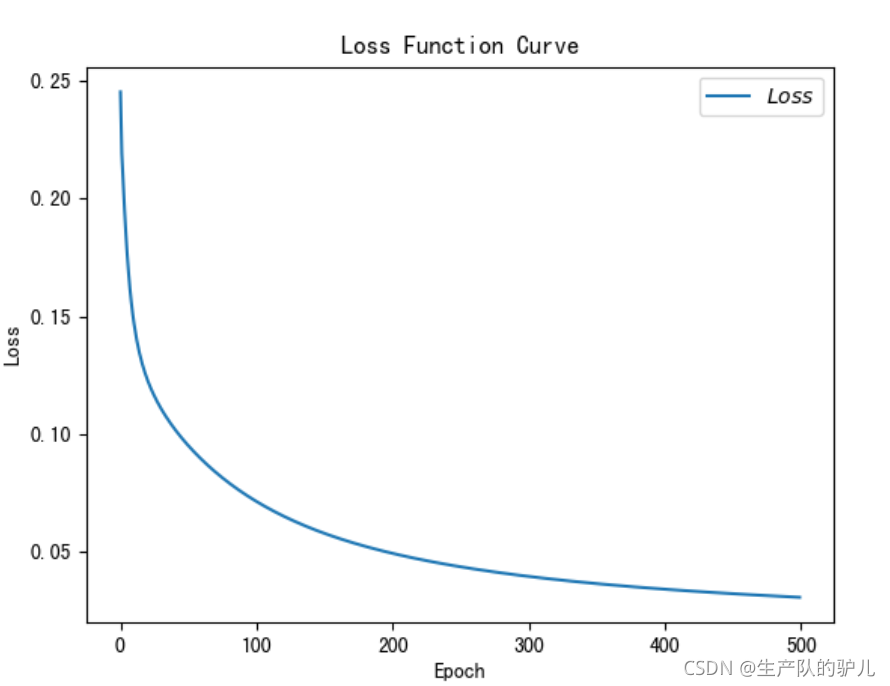
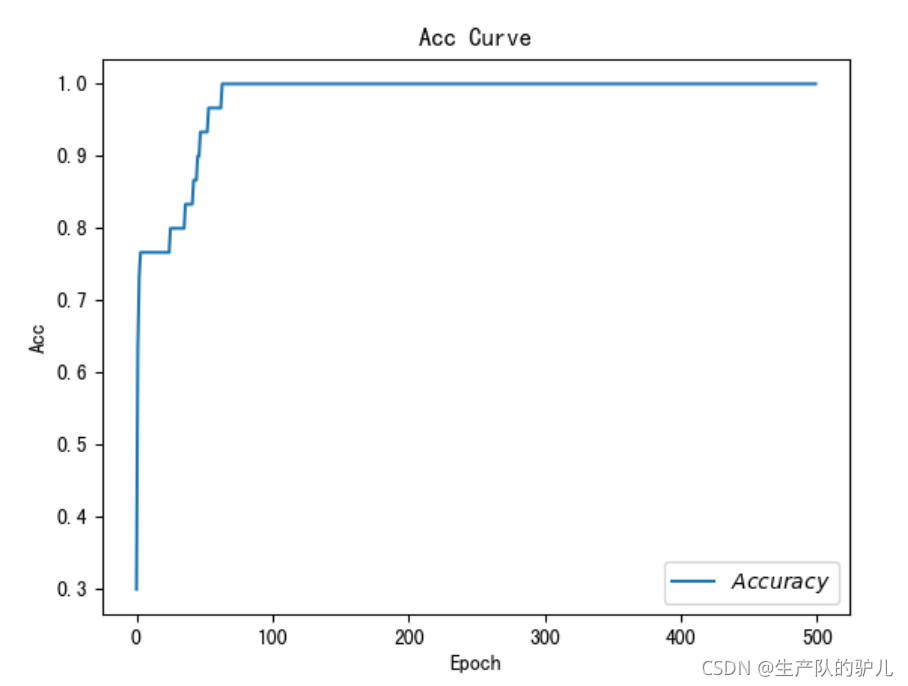
繪制loss和accuray曲線
# 繪制 loss 曲線
plt.title('Loss Function Curve') # 圖片標題
plt.xlabel('Epoch') # x軸變數名稱
plt.ylabel('Loss') # y軸變數名稱
plt.plot(train_loss_results, label="$Loss$") # 逐點畫出trian_loss_results值并連線,連線圖示是Loss
plt.legend() # 畫出曲線圖示
plt.show() # 畫出影像
# 繪制 Accuracy 曲線
plt.title('Acc Curve') # 圖片標題
plt.xlabel('Epoch') # x軸變數名稱
plt.ylabel('Acc') # y軸變數名稱
plt.plot(test_acc, label="$Accuracy$") # 逐點畫出test_acc值并連線,連線圖示是Accuracy
plt.legend()
plt.show()
額外知識單獨補充講解
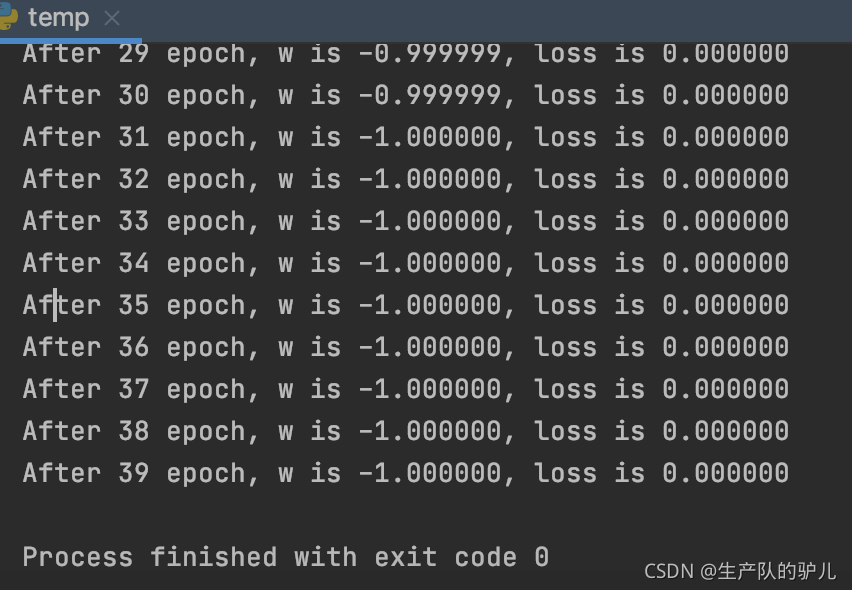
梯度下降的代碼
import tensorflow as tf
# 初始化權重
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 設定學習率為0.2
lr = 0.2
# 設定迭代次數為40
epoch = 40
# 開始回圈進行梯度下降,迭代40次,就是要執行40次下山
for epoch in range(epoch):
# 打開計算梯度的grads框架
with tf.GradientTape() as tape:
# 損失函式是 (w+1)的平方和
loss = tf.square(w + 1)
# 對損失函式中的w求偏導
grads = tape.gradient(loss, w)
# 根據求出的導數,進行反向傳播,即w減少 導數*學習率
w.assign_sub(lr * grads)
# 列印出結果
print("After %s epoch, w is %f, loss is %f" % (epoch, w.numpy(), loss))
三步實作鳶尾花的分類
準備資料
搭建網路
引數優化

關于神經網路入門的一些知識整理
神經網路訓練程序:
收集資料,整理資料
搭建神經網路,即 目標函式
真實值和目標函式值直接估計誤差的損失函式
用損失函式值前向輸入值求導
根據導數的反方向去更新網路引數(權重w和偏置b),目的是讓損失函式值最終為0,最終生成模型
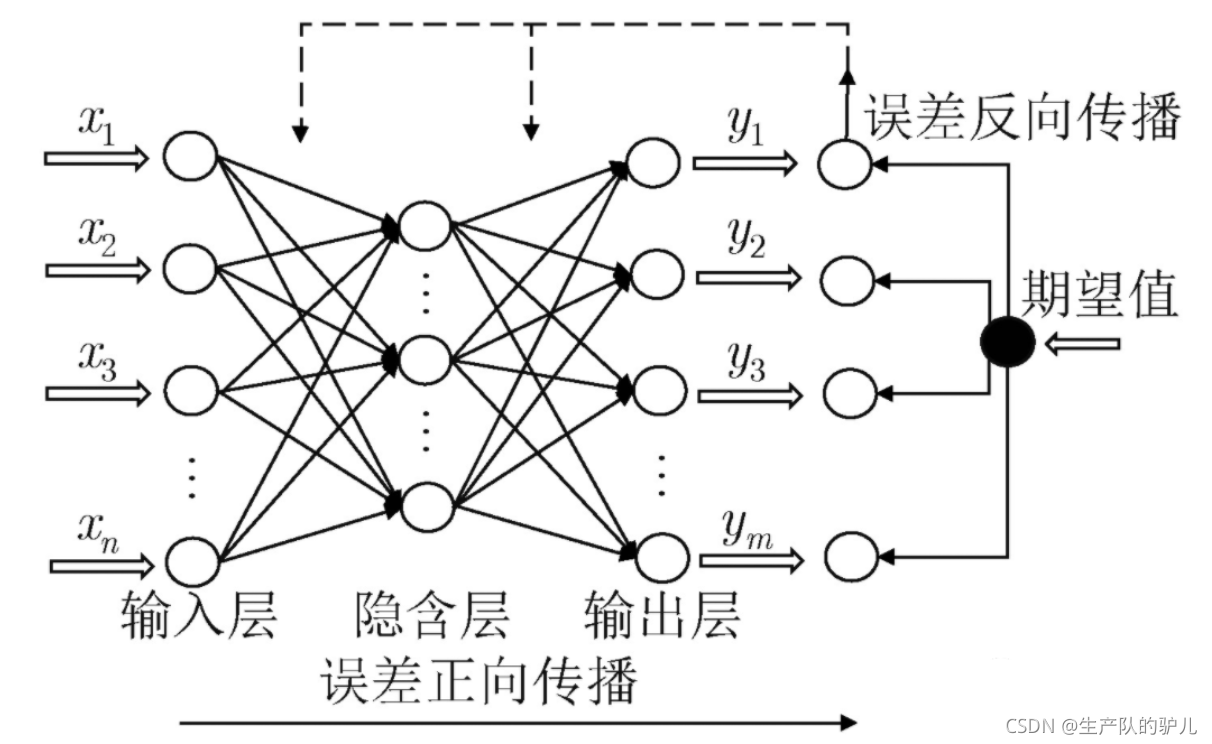
輸入層:就是引數輸入
輸出層:就是最后的輸出
隱藏層(隱含層):除去其他兩層之外的層都可以叫隱藏層
模型包含兩部分:神經網路結構,各個引數,
梯度:函式在該點處沿著該方向(此梯度的方向)變化最快,變化率最大,
前向傳播:前向傳播就是前向呼叫,就是把x代入到方程中,去求y值,
反向傳播:反向傳播就是根據誤差和學習率,將引數權重進行調整,
資料預處理:
資料按比例縮放
歸一化(normalization):將資料放縮到0~1區間,利用公式(x-min)/(max-min),
標準化(Standardization):將資料轉化為標準的正態分布,均值為0,方差為1,
正則化:正則化的主要作用是防止過擬合,
對模型添加正則化項可以限制模型的復雜度,使得模型在復雜度和性能達到平衡,
獨熱碼編碼 (one hot):
one hot編碼是將類別變數轉換為機器學習演算法易于使用的一種形式的程序,one-hot通常用于特征的轉換,
禮拜一,禮拜二,禮拜三,禮拜四,禮拜五,禮拜六,禮拜日,
寫成 【 0 , 0, 3, 0, 0, 0, 0】
比如:一周七天,第三天可以編碼為 [0,0,1,0,0,00]
資料處理庫:
numpy ,pandas, matplotlib
numpy
優化版的python的串列,一般在使用的時候表示矩陣,
pandas
Pandas 的主要資料結構是 Series (一維資料)與 DataFrame(二維資料).
[Series] 是一種類似于一維陣列的物件,它由一組資料(各種Numpy資料型別)以及一組與之相關的資料標簽(即索引)組成,
DataFrame 是一個表格型的資料結構,它含有一組有序的列,每列可以是不同的值型別(數值、字串、布爾型值),DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(共同用一個索引),
matplotlib
畫圖用的,可以用來在學習的程序中對資料進行可視化,
訓練集、測驗集,測驗集
訓練集:用來訓練模型的資料,用來學習的
驗證集:用來驗證模型的資料,主要是看下模型的訓練情況
測驗集: 訓練完成之后,驗證模型的資料
訓練集-----------學生的課本;學生 根據課本里的內容來掌握知識,
驗證集------------作業,通過作業可以知道 不同學生學習情況、進步的速度快慢,
測驗集-----------考試,考的題是平常都沒有見過,考察學生舉一反三的能力,
損失函式
損失函式用來評價模型的預測值和真實值不一樣的程度,損失函式越好,通常模型的性能越好,
f(x) 表示預測值,Y 表示真實值,

優化器
優化器就是在深度學習反向傳播程序中,指引損失函式(目標函式)的各個引數往正確的方向更新合適的大小,使得更新后的各個引數讓損失函式(目標函式)值不斷逼近全域最小,
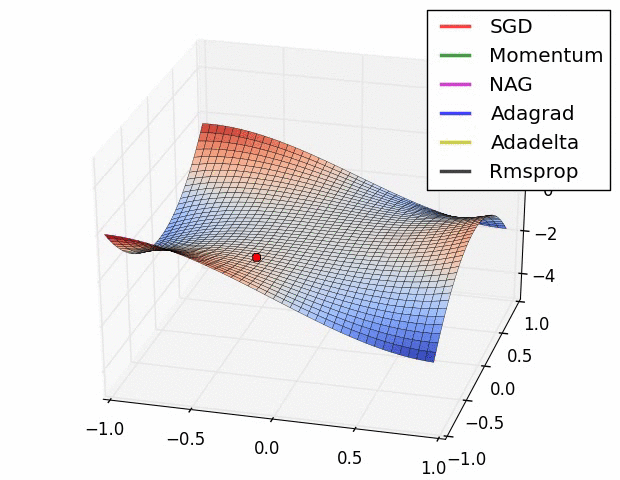
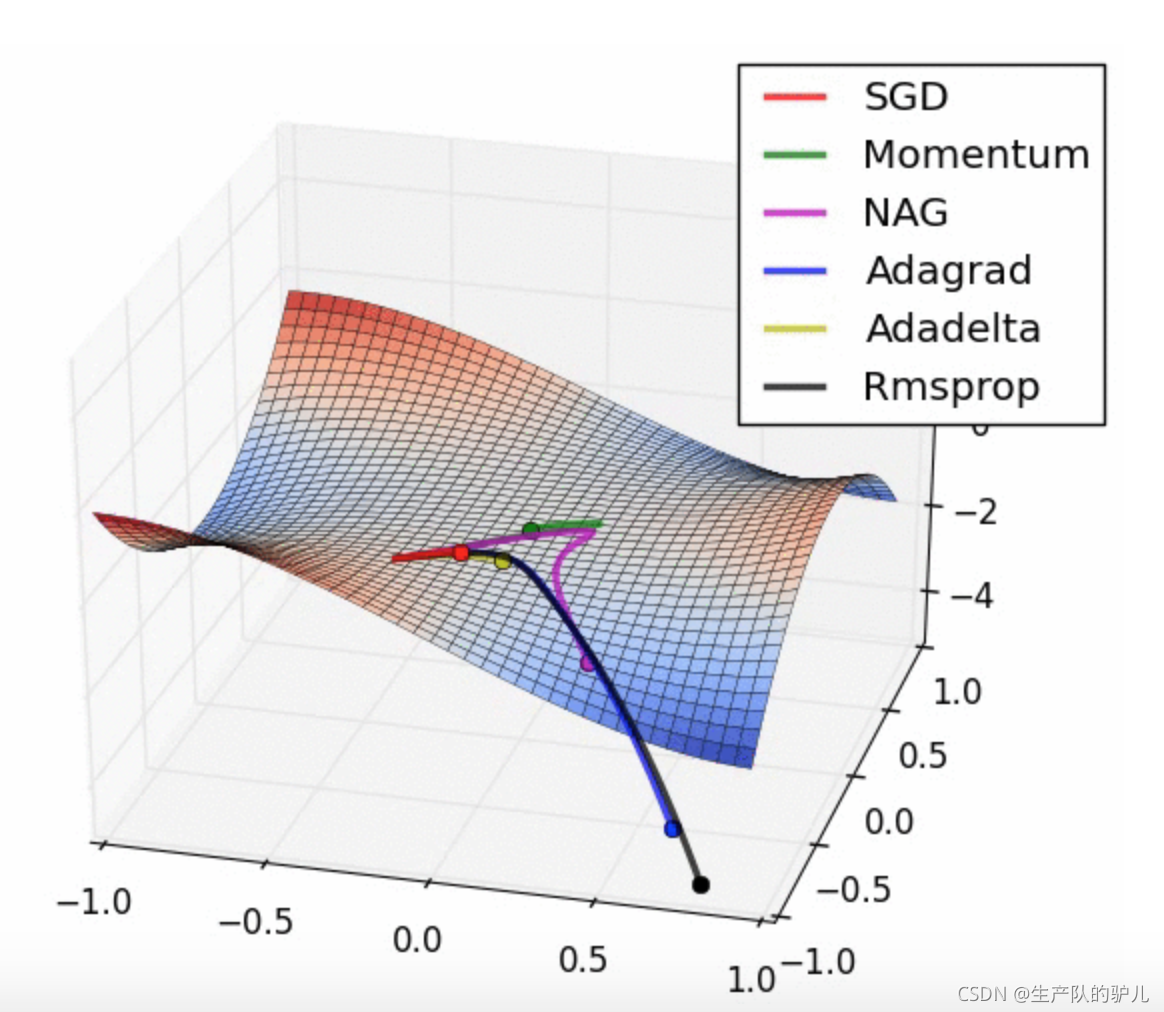
激活函式
激活函式就是對輸入進行過濾,可以理解為一個過濾器
常見的非線性激活函式通常可以分為兩類:
輸入單個變數輸出單個變數: sigmoid函式,Relu函式;
輸入多個變數輸出多個變數: 如Softmax函式,Maxout函式,
對于二分類問題,在輸出層可以選擇 sigmoid 函式,
對于多分類問題,在輸出層可以選擇 softmax 函式,
由于梯度消失問題,盡量sigmoid函式和tanh的使用,
tanh函式由于以0為中心,通常性能會比sigmoid函式好,
ReLU函式是一個通用的函式,一般在隱藏層都可以考慮使用,
有時候要適當對現有的激活函式稍作修改,以及考慮使用新發現的激活函式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345629.html
標籤:AI